


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (6): 1848-1854.DOI: 10.11772/j.issn.1001-9081.2023060830
所属专题: 数据科学与技术
孟繁珺1, 韩斌1( ), 黄树成1, 梅向东2
), 黄树成1, 梅向东2
收稿日期:2023-06-28
修回日期:2023-08-26
接受日期:2023-08-30
发布日期:2023-09-11
出版日期:2024-06-10
通讯作者:
韩斌
作者简介:孟繁珺(1994—),男,河北沧州人,硕士研究生,主要研究方向:时态大数据基金资助:
Fanjun MENG1, Bin HAN1(), Shucheng HUANG1, Xiangdong MEI2
Received:2023-06-28
Revised:2023-08-26
Accepted:2023-08-30
Online:2023-09-11
Published:2024-06-10
Contact:
Bin HAN
About author:MENG Fanjun, born in 1994, M. S. candidate. His research interests include temporal big data.Supported by:摘要:
在大数据与云计算时代,时态大数据的查询分析面临许多重要挑战。针对其中时态聚合范围查询性能不佳和不能有效利用索引等问题,提出一种用于时态聚合范围查询的分布式时态索引(DTI)。首先,采用随机或轮询策略对时态数据分区;其次,采用基于时间位数组前缀的分区内索引构造算法建立索引,同时记录包括时间跨度在内的分区统计信息;再次,利用谓词下推筛选时间跨度与查询时间区间重叠的数据分区,扫描索引进行预聚合;最后,将各分区得到的预聚合值按时间归并并聚合。实验结果表明,索引的分区内构造算法处理时间密度2 400条每单位时间和0.001条每单位时间的数据的执行时间相近。索引的聚合查询算法相较于ParTime算法:在查询时间线前75%的数据时,每一步用时都至少减少22%;执行选择型聚合函数时,每一步用时都至少减少11%。因此,索引在多数时态聚合范围查询任务中具有更高的速度,它的分区内构造算法能解决数据稀疏问题且执行效率高。
中图分类号:
孟繁珺, 韩斌, 黄树成, 梅向东. 用于时态聚合范围查询的分布式时态索引[J]. 计算机应用, 2024, 44(6): 1848-1854.
Fanjun MENG, Bin HAN, Shucheng HUANG, Xiangdong MEI. Distributed temporal index for temporal aggregation range query[J]. Journal of Computer Applications, 2024, 44(6): 1848-1854.
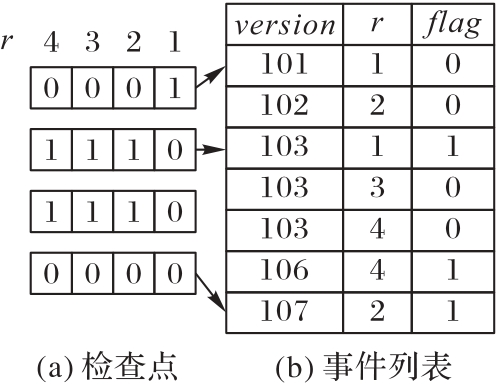
图1 Timeline索引结构
Fig.1 Timeline index structure
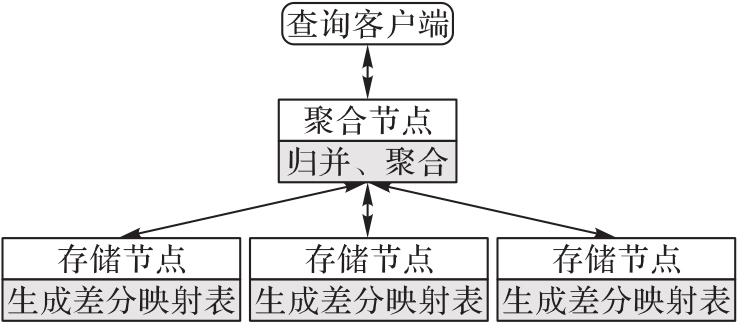
图2 ParTime架构
Fig.2 ParTime architecture
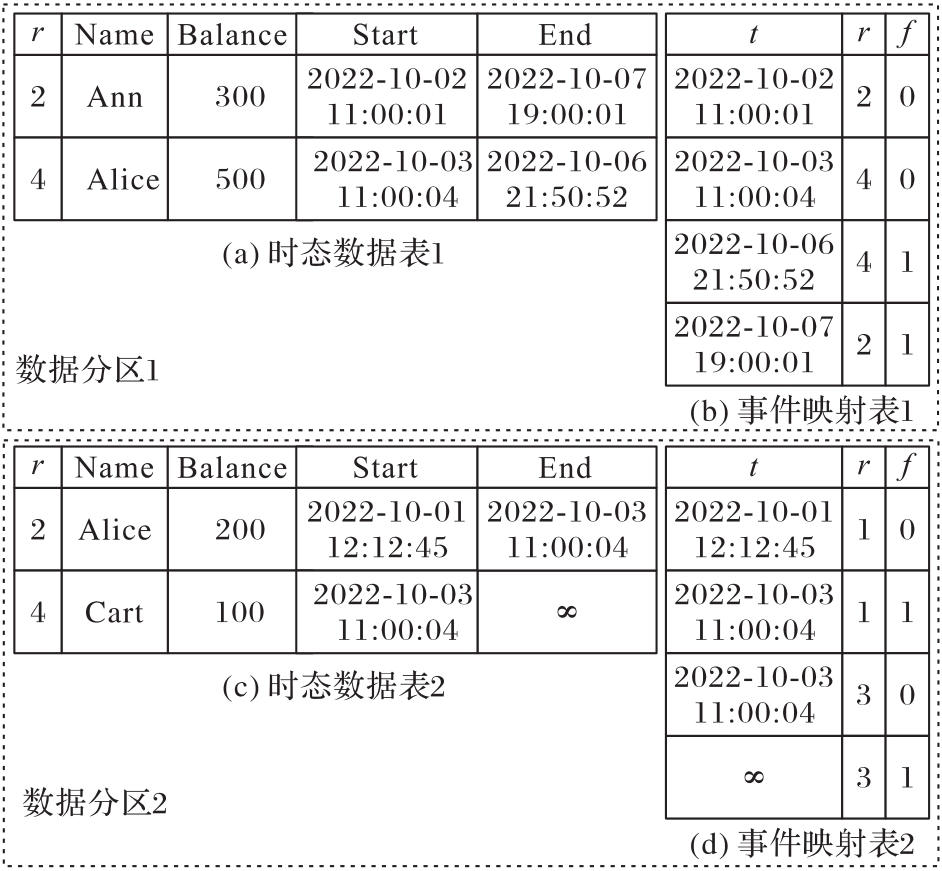
图3 数据分区内数据结构
Fig.3 Structure within data partition

图4 计数数据分布
Fig.4 Count data distribution
| 数据集 | 数据记录 大小/GB | 数据记录 条数/106 | 最大时间跨度 |
|---|---|---|---|
| TPC-BiH(SF=1) | 0.83 | 6 | 2.5×103 |
| TPC-BiH(SF=10) | 8.47 | 60 | 2.5×103 |
| YTTR | 3.89 | 39 | 31.6×109 |
表1 实验数据集
Tab.1 Datasets used in experiment
| 数据集 | 数据记录 大小/GB | 数据记录 条数/106 | 最大时间跨度 |
|---|---|---|---|
| TPC-BiH(SF=1) | 0.83 | 6 | 2.5×103 |
| TPC-BiH(SF=10) | 8.47 | 60 | 2.5×103 |
| YTTR | 3.89 | 39 | 31.6×109 |
| 查询序号 | 查询时间段 长度/% | 查询时间段位置 | 时态聚合 函数及数量 |
|---|---|---|---|
| A1 | 1.0 | [0.25,0.75) | SUM×1 |
| A2 | 1.0 | [0.25,0.75) | MAX×1 |
| B1 | 0.1 | [0.00,0.25) | SUM×1 |
| B2 | 0.1 | [0.75,1.00) | SUM×1 |
| B3 | 1.0 | [0.00,0.25) | SUM×1 |
| B4 | 1.0 | [0.75,1.00) | SUM×1 |
| B5 | 100.0 | [0.00,1.00) | SUM×1 |
| C1 | 0.1 | [0.25,0.75) | MAX×8 |
表2 时态聚合范围查询
Tab.2 Temporal aggregation range queries
| 查询序号 | 查询时间段 长度/% | 查询时间段位置 | 时态聚合 函数及数量 |
|---|---|---|---|
| A1 | 1.0 | [0.25,0.75) | SUM×1 |
| A2 | 1.0 | [0.25,0.75) | MAX×1 |
| B1 | 0.1 | [0.00,0.25) | SUM×1 |
| B2 | 0.1 | [0.75,1.00) | SUM×1 |
| B3 | 1.0 | [0.00,0.25) | SUM×1 |
| B4 | 1.0 | [0.75,1.00) | SUM×1 |
| B5 | 100.0 | [0.00,1.00) | SUM×1 |
| C1 | 0.1 | [0.25,0.75) | MAX×8 |
| 数据集名称 | 分区内构造平均用时/ms | 辅助结构平均大小/KB | 数据加载平均用时/s | |||||
|---|---|---|---|---|---|---|---|---|
| PCS | B Tree | Counting Sort | PCS | B Tree | Counting Sort | DTI | ParTime | |
| TPC-BiH (SF=1) | 260.00 | 2 207.70 | 240.50 | 8 379.38 | 136 432.32 | 19.98 | 49.04 | 27.54 |
| YTTR | 240.90 | 452.70 | NaN | 5 428.24 | 77 912.47 | N/A | 308.82 | 94.96 |
表3 分区内索引构造与数据加载性能
Tab. 3 Performance of intra-partition index construction and data loading
| 数据集名称 | 分区内构造平均用时/ms | 辅助结构平均大小/KB | 数据加载平均用时/s | |||||
|---|---|---|---|---|---|---|---|---|
| PCS | B Tree | Counting Sort | PCS | B Tree | Counting Sort | DTI | ParTime | |
| TPC-BiH (SF=1) | 260.00 | 2 207.70 | 240.50 | 8 379.38 | 136 432.32 | 19.98 | 49.04 | 27.54 |
| YTTR | 240.90 | 452.70 | NaN | 5 428.24 | 77 912.47 | N/A | 308.82 | 94.96 |
| 数据集 | 查询序号 | DTI执行时间/ms | ParTime执行时间/ms | ||||
|---|---|---|---|---|---|---|---|
| 部分聚合 | 归并 | 总用时 | 生成DM | 归并 | 总用时 | ||
| TPC-BiH (SF=1) | A1 | 461.67 | 23.50 | 22 058.67 | 1 076.33 | 30.00 | 22 616.00 |
| A2 | 666.00 | 26.33 | 21 949.33 | 943.00 | 108.00 | 21 413.67 | |
| B1 | 56.00 | 5.00 | 21 755.33 | 797.33 | 10.33 | 21 388.00 | |
| B2 | 783.00 | 5.00 | 21 572.00 | 762.33 | 24.33 | 20 918.00 | |
| B3 | 112.00 | 23.00 | 20 843.00 | 781.33 | 21.67 | 20 883.00 | |
| B4 | 760.67 | 25.00 | 22 235.67 | 753.00 | 27.33 | 21 118.67 | |
| B5 | 2 392.33 | 275.00 | 23 661.00 | 2 793.33 | 138.67 | 22 921.00 | |
| C1 | 974.00 | 16.33 | 21 886.33 | 1 624.00 | 226.67 | 22 210.67 | |
| TPC-BiH (SF=10) | A1 | 1 284.00 | 58.33 | 34 009.67 | 1 799.67 | 91.00 | 37 005.33 |
| A2 | 1 411.33 | 59.00 | 34 790.00 | 2 015.67 | 1 210.67 | 38 914.33 | |
| B1 | 366.00 | 20.33 | 31 684.67 | 1 419.33 | 28.00 | 33 826.67 | |
| B2 | 1 373.33 | 21.67 | 34 103.67 | 1 594.67 | 69.00 | 34 663.67 | |
| B3 | 176.00 | 53.00 | 31 216.33 | 1 511.67 | 45.33 | 34 235.67 | |
| B4 | 1 495.67 | 52.67 | 34 452.33 | 1 582.33 | 86.67 | 33 870.00 | |
| B5 | 7 080.33 | 1 331.67 | 48 504.00 | 8 191.00 | 611.00 | 52 531.33 | |
| C1 | 1 666.67 | 38.33 | 36 184.33 | 4 040.00 | 4 097.00 | 49 294.67 | |
| YTTR | A1 | 560.00 | 625.00 | 31 440.67 | 1 015.67 | 983.00 | 32 373.00 |
| A2 | 1 054.33 | 719.33 | 29 639.33 | 927.33 | 1 174.33 | 31 132.33 | |
| B1 | 259.67 | 103.00 | 29 247.33 | 400.00 | 167.67 | 30 738.00 | |
| B2 | 215.67 | 90.00 | 28 859.67 | 319.33 | 160.33 | 29 336.00 | |
| B3 | 416.67 | 394.33 | 28 937.00 | 700.00 | 762.67 | 30 966.67 | |
| B4 | 430.33 | 365.33 | 29 272.67 | 516.67 | 778.67 | 29 740.67 | |
| B5 | 14 921.00 | 65 289.33 | 162 593.00 | 21 724.33 | 87 942.00 | 233 179.67 | |
| C1 | 768.00 | 522.67 | 30 788.00 | 1 394.67 | 592.00 | 31 746.67 | |
表4 时态聚合范围查询执行时间
Tab. 4 Execution time of temporal aggregation range query
| 数据集 | 查询序号 | DTI执行时间/ms | ParTime执行时间/ms | ||||
|---|---|---|---|---|---|---|---|
| 部分聚合 | 归并 | 总用时 | 生成DM | 归并 | 总用时 | ||
| TPC-BiH (SF=1) | A1 | 461.67 | 23.50 | 22 058.67 | 1 076.33 | 30.00 | 22 616.00 |
| A2 | 666.00 | 26.33 | 21 949.33 | 943.00 | 108.00 | 21 413.67 | |
| B1 | 56.00 | 5.00 | 21 755.33 | 797.33 | 10.33 | 21 388.00 | |
| B2 | 783.00 | 5.00 | 21 572.00 | 762.33 | 24.33 | 20 918.00 | |
| B3 | 112.00 | 23.00 | 20 843.00 | 781.33 | 21.67 | 20 883.00 | |
| B4 | 760.67 | 25.00 | 22 235.67 | 753.00 | 27.33 | 21 118.67 | |
| B5 | 2 392.33 | 275.00 | 23 661.00 | 2 793.33 | 138.67 | 22 921.00 | |
| C1 | 974.00 | 16.33 | 21 886.33 | 1 624.00 | 226.67 | 22 210.67 | |
| TPC-BiH (SF=10) | A1 | 1 284.00 | 58.33 | 34 009.67 | 1 799.67 | 91.00 | 37 005.33 |
| A2 | 1 411.33 | 59.00 | 34 790.00 | 2 015.67 | 1 210.67 | 38 914.33 | |
| B1 | 366.00 | 20.33 | 31 684.67 | 1 419.33 | 28.00 | 33 826.67 | |
| B2 | 1 373.33 | 21.67 | 34 103.67 | 1 594.67 | 69.00 | 34 663.67 | |
| B3 | 176.00 | 53.00 | 31 216.33 | 1 511.67 | 45.33 | 34 235.67 | |
| B4 | 1 495.67 | 52.67 | 34 452.33 | 1 582.33 | 86.67 | 33 870.00 | |
| B5 | 7 080.33 | 1 331.67 | 48 504.00 | 8 191.00 | 611.00 | 52 531.33 | |
| C1 | 1 666.67 | 38.33 | 36 184.33 | 4 040.00 | 4 097.00 | 49 294.67 | |
| YTTR | A1 | 560.00 | 625.00 | 31 440.67 | 1 015.67 | 983.00 | 32 373.00 |
| A2 | 1 054.33 | 719.33 | 29 639.33 | 927.33 | 1 174.33 | 31 132.33 | |
| B1 | 259.67 | 103.00 | 29 247.33 | 400.00 | 167.67 | 30 738.00 | |
| B2 | 215.67 | 90.00 | 28 859.67 | 319.33 | 160.33 | 29 336.00 | |
| B3 | 416.67 | 394.33 | 28 937.00 | 700.00 | 762.67 | 30 966.67 | |
| B4 | 430.33 | 365.33 | 29 272.67 | 516.67 | 778.67 | 29 740.67 | |
| B5 | 14 921.00 | 65 289.33 | 162 593.00 | 21 724.33 | 87 942.00 | 233 179.67 | |
| C1 | 768.00 | 522.67 | 30 788.00 | 1 394.67 | 592.00 | 31 746.67 | |
| 1 | HUANG Y, LI X, ZHANG G-Q. ELII: a novel inverted index for fast temporal query, with application to a large Covid-19 EHR dataset[J]. Journal of Biomedical Informatics, 2021, 117: 103744. |
| 2 | DONG X, WONG R, LYU W, et al. An integrated LSTM-HeteroRGNN model for interpretable opioid overdose risk prediction[J]. Artificial Intelligence in Medicine, 2023, 135: 102439. |
| 3 | HU X, SINTOS S, GAO J, et al. Computing complex temporal join queries efficiently[C]// Proceedings of the 2022 International Conference on Management of Data. New York: ACM, 2022: 2076-2090. |
| 4 | BOUROS P, MAMOULIS N, TSITSIGKOS D, et al. In-memory interval joins[J]. The VLDB Journal, 2021, 30(4): 667-691. |
| 5 | DIGNÖS A, BÖHLEN M H, GAMPER J, et al. Leveraging range joins for the computation of overlap joins[J]. The VLDB Journal, 2022, 31(1): 75-99. |
| 6 | LUO J-Z, SHI S-F, YANG G, et al. O2iJoin: an efficient index-based algorithm for overlap interval join [J]. Journal of Computer Science and Technology, 2018, 33(5): 1023-1038. |
| 7 | 张伟, 王志杰. 分布式环境下时态大数据的连接操作研究[J]. 计算机工程, 2019, 45(3): 20-25,31. |
| ZHANG W, WANG Z J. Research on join operation of temporal big data in distributed environment [J]. Computer Engineering, 2019,45(3):20-25,31. | |
| 8 | WANG L, CAI R, FU T Z J, et al. Waterwheel: realtime indexing and temporal range query processing over massive data streams[C]// Proceedings of the 2018 IEEE 34th International Conference on Data Engineering. Piscataway: IEEE, 2018: 269-280. |
| 9 | BEHREND A, DIGNÖS A, GAMPER J, et al. Period index: a learned 2D hash index for range and duration queries[C]// Proceedings of the 16th International Symposium on Spatial and Temporal Databases. New York: ACM, 2019: 100-109. |
| 10 | CECCARELLO M, DIGNÖS A, GAMPER J, et al. Indexing temporal relations for range-duration queries [EB/OL]. (2022-06-15) [2023-04-03]. . |
| 11 | 杨佐希, 汤娜, 汤庸, 等. 基于时序分区的时态索引与查询[J]. 软件学报, 2020, 31(11): 3519-3539. |
| YANG Z X, TANG N, TANG Y, et al. Temporal index and query based on timing partition [J]. Journal of Software, 2020,31(11):3519-3539. | |
| 12 | SUZANNE A, RASCHIA G, MARTINEZ J, et al. Slicing techniques for temporal aggregation in spanning event streams [J]. Information and Computation, 2021, 281: 104807. |
| 13 | GRANDI F, MANDREOLI F, MARTOGLIA R, et al. Unleashing the power of querying streaming data in a temporal database world: a relational algebra approach[J]. Information Systems, 2022, 103: 101872. |
| 14 | SUZANNE A, RASCHIA G, MARTINEZ J, et al. Window-slicing techniques extended to spanning-event streams[C]// Proceedings of the 27th International Symposium on Temporal Representation and Reasoning. Dagstuhl, Germany: Dagstuhl Publishing, 2020: 10:1-10:14. |
| 15 | GAO Q, LEE M L, LING T W. Temporal keyword search with aggregates and group-by[C]// Proceedings of the 40th International Conference on Conceptual Modeling. Cham: Springer, 2021: 160-175. |
| 16 | YAO B, ZHANG W, WANG Z-J, et al. Distributed in-memory analytics for big temporal data[C]// Proceedings of the 23rd International Conference on Database Systems for Advanced Applications. Cham: Springer, 2018: 549-565. |
| 17 | KLINE N, SNODGRASS R T. Computing temporal aggregates[C]// Proceedings of the 11th International Conference on Data Engineering. Washington, DC: IEEE Computer Society, 1995: 222-231. |
| 18 | MAHLKNECHT G, DIGNÖS A, KOZMINA N. Modeling and querying facts with period timestamps in data warehouses[J]. International Journal of Applied Mathematics and Computer Science, 2019, 29(1): 31-49. |
| 19 | KAUFMANN M, MANJILI A A, VAGENAS P, et al. Timeline index: a unified data structure for processing queries on temporal data in SAP HANA[C]// Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2013: 1173-1184. |
| 20 | PILMAN M, KAUFMANN M, KÖHL F, et al. ParTime: parallel temporal aggregation[C]// Proceedings of the 2016 International Conference on Management of Data. New York: ACM, 2016: 999-1010. |
| 21 | LU W, ZHAO Z, WANG X, et al. A lightweight and efficient temporal database management system in TDSQL[J]. Proceedings of the VLDB Endowment, 2019, 12(12): 2035-2046. |
| 22 | QIAO J, HUANG X, WANG J, et al. Dual-PISA: an index for aggregation operations on time series data[J]. Information Systems, 2020, 87: 101427. |
| 23 | ZHENG X, LIU H-K, WEI L-N, et al. Timo: in-memory temporal query processing for big temporal data [C]// Proceedings of the 2019 Seventh International Conference on Advanced Cloud and Big Data . Piscataway: IEEE, 2019: 121-126. |
| 24 | CHRISTODOULOU G, BOUROS P, MAMOULIS N. HINT: a hierarchical index for intervals in main memory[C]// Proceedings of the 2022 International Conference on Management of Data. New York: ACM, 2022: 1257-1270. |
| 25 | 陈瑛, 吴明珠, 卢莉, 等. 时态拟序数据索引TQD-tree更新技术[J]. 华南师范大学学报(自然科学版), 2019, 51(2): 123-127. |
| CHEN Y, WU M Z, LU L, et al. Updating technique of temporal quasi-order data index[J]. Journal of South China Normal University (Natural Science Edition), 2019,51(2):123-127. | |
| 26 | KAUFMANN M, FISCHER P M, MAY N, et al. TPC-BiH: a benchmark for bitemporal databases[C]// Performance Characterization and Benchmarking. TPCTC 2013. Cham: Springer, 2013: 16-31. |
| [1] | 庞川林, 唐睿, 张睿智, 刘川, 刘佳, 岳士博. D2D通信系统中基于图卷积网络的分布式功率控制算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2855-2862. |
| [2] | 张治政, 张啸剑, 王俊清, 冯光辉. 结合差分隐私与安全聚集的联邦空间数据发布方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2777-2784. |
| [3] | 李旭, 何玉林, 崔来中, 黄哲学, PHILIPPE Fournier‑Viger. 基于大数据随机样本划分的分布式观测点分类器[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1727-1733. |
| [4] | 魏凤凤, 陈伟能. 分布式数据驱动的多约束进化优化算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1393-1400. |
| [5] | 倪瑞轩, 蔡淼, 叶保留. 内存高效的持久性分布式文件系统客户端缓存DFS-Cache[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1172-1180. |
| [6] | 张鑫, 张金全, 刘德渊, 万武南, 张仕斌, 秦智. 基于身份代理重加密的跨链身份管理方案[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3723-3730. |
| [7] | 曾蠡, 杨婧如, 黄罡, 景翔, 罗超然. 超图应用方法综述:问题、进展与挑战[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3315-3326. |
| [8] | 陈国祥, 于自强, 赵浩宇. 面向动态路网的移动对象分布式k近邻查询算法[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3403-3410. |
| [9] | 王昱, 关智慧, 李远鹏. 基于轨迹预测和分布式MADDPG的无人机集群追击决策[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3623-3628. |
| [10] | 尹春勇, 周永成. 双端聚类的自动调整聚类联邦学习[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3011-3020. |
| [11] | 葛晨洋, 刘勤让, 裴雪, 魏帅, 朱正彬. 软件定义网络中高效协同防御分布式拒绝服务攻击的方案[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2477-2485. |
| [12] | 蓝梦婕, 蔡剑平, 孙岚. 非独立同分布数据下的自正则化联邦学习优化方法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2073-2081. |
| [13] | 龙运波, 唐聃. 分布式存储中基于局部修复码的负载均衡方法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 767-775. |
| [14] | 杨力, 陈建廷, 向阳. 基于HBase的工业时序大数据分布式存储性能优化策略[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 759-766. |
| [15] | 华夏, 朱铮皓, 徐聪, 张曦煌, 柴志雷, 陈闻杰. 基于精准通信建模的脉冲神经网络工作负载自动映射器[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 827-834. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||