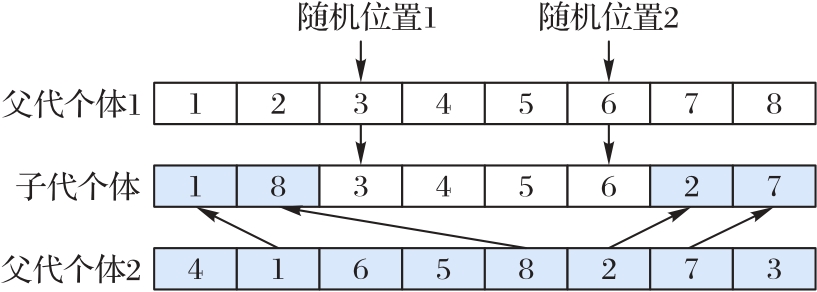
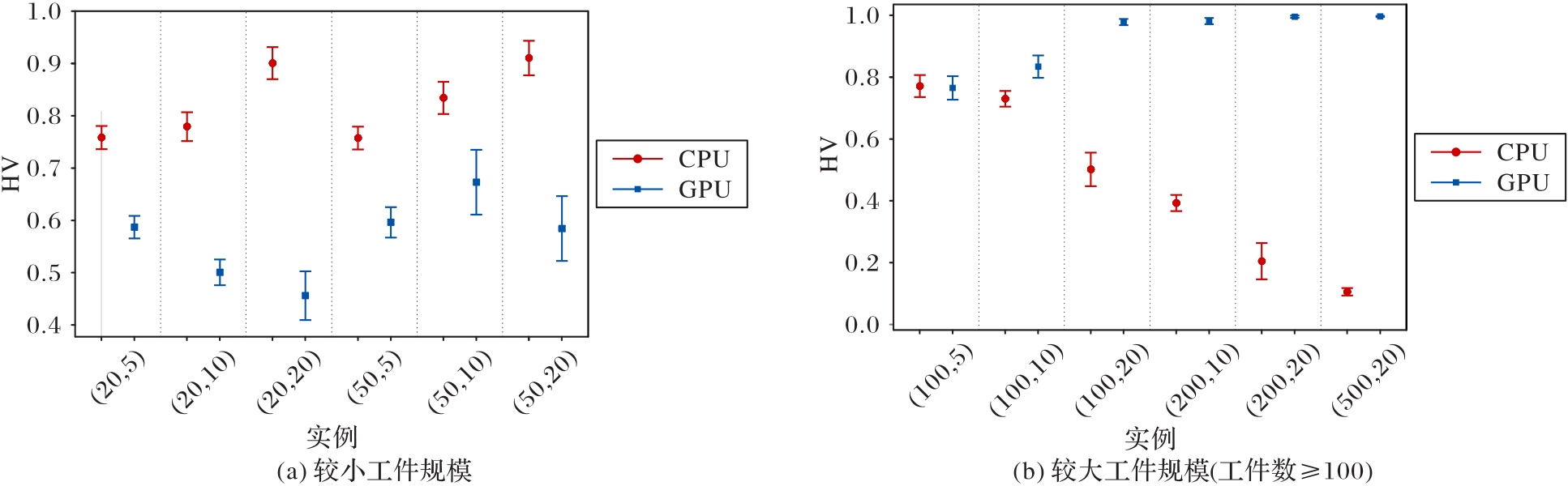
| 1 |
ZHONG R Y, XU X, KLOTZ E, et al. Intelligent manufacturing in the context of Industry 4.0: a review[J]. Engineering, 2017, 3(5): 616-630. 10.1016/j.eng.2017.05.015
|
| 2 |
MITTAL S, KHAN M A, ROMERO D, et al. A critical review of smart manufacturing & Industry 4.0 maturity models: implications for Small and Medium-sized Enterprises (SMEs)[J]. Journal of Manufacturing Systems, 2018, 49: 194-214. 10.1016/j.jmsy.2018.10.005
|
| 3 |
ZHAO Z, ZHOU M, LIU S. Iterated greedy algorithms for flow-shop scheduling problems: a tutorial[J]. IEEE Transactions on Automation Science and Engineering, 2021, 19(3): 1941-1959. 10.1109/tase.2021.3062994
|
| 4 |
KOMAKI G, SHEIKH S, MALAKOOTI B. Flow shop scheduling problems with assembly operations: a review and new trends[J]. International Journal of Production Research, 2019, 57(10): 2926-2955. 10.1080/00207543.2018.1550269
|
| 5 |
ZHAO F, JIANG T, WANG L. A reinforcement learning driven cooperative meta-heuristic algorithm for energy-efficient distributed no-wait flow-shop scheduling with sequence-dependent setup time[J]. IEEE Transactions on Industrial Informatics, 2023, 19(7): 1-12. 10.1109/tii.2022.3218645
|
| 6 |
PAN Q-K, WANG L, ZHAO B-H. An improved iterated greedy algorithm for the no-wait flow shop scheduling problem with makespan criterion[J]. The International Journal of Advanced Manufacturing Technology, 2008, 38: 778-786. 10.1007/s00170-007-1120-y
|
| 7 |
李浩然,高亮,李新宇.基于离散人工蜂群算法的多目标分布式异构零等待流水车间调度方法[J].机械工程学报,2023,59(2):291-306. 10.3901/jme.2023.02.291
|
|
LI H R, GAO L, LI X Y. Discrete artificial bee colony algorithm for multi-objective distributed heterogeneous no-wait flowshop scheduling problem[J]. Journal of Mechanical Engineering, 2023, 59(2): 291-306. 10.3901/jme.2023.02.291
|
| 8 |
WEI Y-M, CHEN K, KANG J-N, et al. Policy and management of carbon peaking and carbon neutrality: a literature review[J]. Engineering, 2022, 14: 52-63. 10.1016/j.eng.2021.12.018
|
| 9 |
LI M, WANG G-G. A review of green shop scheduling problem[J]. Information Sciences, 2022, 589: 478-496. 10.1016/j.ins.2021.12.122
|
| 10 |
WANG J-J, WANG L. A cooperative memetic algorithm with learning-based agent for energy-aware distributed hybrid flow-shop scheduling [J]. IEEE Transactions on Evolutionary Computation, 2021, 26(3): 461-475. 10.1109/tevc.2021.3106168
|
| 11 |
罗聪,龚文引.混合分解多目标进化算法求解绿色置换流水车间调度问题[J/OL].控制与决策,2023 (2023-07-20) [2024-02-19]. .
|
|
LUO C, GONG W Y. A hybrid multi-objective evolutionary algorithm based on decomposition for green permutation flow shop-scheduling problem[J]. Control and Decision, 2023 (2023-07-20) [2024-02-19]. .
|
| 12 |
ZHAO F, HE X, WANG L. A two-stage cooperative evolutionary algorithm with problem-specific knowledge for energy-efficient scheduling of no-wait flow-shop problem [J]. IEEE Transactions on Cybernetics, 2020, 51(11): 5291-5303. 10.1109/tcyb.2020.3025662
|
| 13 |
GAREY M R, SETHI J R. The complexity of flowshop and jobshop scheduling [J]. Mathematics of Operations Research, 1976, 1(2): 117-129. 10.1287/moor.1.2.117
|
| 14 |
闫红超,汤伟,姚斌.求解置换流水车间调度问题的混合鸟群算法[J].计算机应用,2022,42(9):2952-2959. 10.11772/j.issn.1001-9081.2021091650
|
|
YAN H C, TANG W, YAO B. Hybrid bird swarm algorithm for solving permutation flowshop scheduling problem[J]. Journal of Computer Applications, 2022, 42(9): 2952-2959. 10.11772/j.issn.1001-9081.2021091650
|
| 15 |
ZHAO F, XU Z, WANG L, et al. A population-based iterated greedy algorithm for distributed assembly no-wait flow-shop scheduling problem [J]. IEEE Transactions on Industrial Informatics, 2022, 19(5): 6692-6705. 10.1109/tii.2022.3192881
|
| 16 |
DEB K, PRATAP A, AGARWAL S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-Ⅱ[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182-197. 10.1109/4235.996017
|
| 17 |
OWENS J D, HOUSTON M, LUEBKE D, et al. GPU computing [J]. Proceedings of the IEEE, 2008, 96(5): 879-899. 10.1109/jproc.2008.917757
|
| 18 |
LEI S-C, XIAO X, GONG Y-J, et al. Tensorial evolutionary computation for spatial optimization problems [J]. IEEE Transactions on Artificial Intelligence, 2022, 5(1): 154-166.
|
| 19 |
VAN LUONG T, MELAB N, E-G TALBI. GPU-based approaches for multiobjective local search algorithms. a case study: the flowshop scheduling problem[C]// Proceedings of the 11th European Conference on Evolutionary Computation in Combinatorial Optimization. Berlin: Springer, 2011: 155-166. 10.1007/978-3-642-20364-0_14
|
| 20 |
GMYS J. Exactly solving hard permutation flowshop scheduling problems on peta-scale GPU-accelerated supercomputers[J]. INFORMS Journal on Computing, 2022, 34(5): 2502-2522. 10.1287/ijoc.2022.1193
|
| 21 |
HUANG L-T, S-S JHAN, LI Y-J, et al. Solving the permutation problem efficiently for Tabu search on CUDA GPUs[C]// Proceedings of the 2014 International Conference on Computational Collective Intelligence, LNAI 8733. Cham: Springer, 2014: 342-352.
|
| 22 |
CZAPIŃSKI M, BARNES S. Tabu search with two approaches to parallel flowshop evaluation on CUDA platform [J]. Journal of Parallel and Distributed Computing, 2011, 71(6): 802-811. 10.1016/j.jpdc.2011.02.006
|
| 23 |
HUANG B, CHENG R, LI Z, et al. EvoX: a distributed GPU-accelerated library towards scalable evolutionary computation [EB/OL]. [2023-10-25]. . 10.1109/tevc.2024.3388550
|
| 24 |
BRADBURY J, FROSTIG R, HAWKINS P, et al. JAX: composable transformations of Python+NumPy programs [EB/OL]. [2023-10-11]. .
|
| 25 |
TAILLARD E. Benchmarks for basic scheduling problems [J]. European Journal of Operational Research, 1993, 64(2): 278-285. 10.1016/0377-2217(93)90182-m
|
| 26 |
WANG J-J, WANG L. A knowledge-based cooperative algorithm for energy-efficient scheduling of distributed flow-shop [J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2018, 50(5): 1805-1819.
|


 ), 金耀初3
), 金耀初3