


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (2): 385-392.DOI: 10.11772/j.issn.1001-9081.2023020179
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Xinran LUO, Tianrui LI( ), Zhen JIA
), Zhen JIA
Received:2023-02-27
Revised:2023-04-11
Accepted:2023-04-13
Online:2024-02-22
Published:2024-02-10
Contact:
Tianrui LI
About author:LUO Xinran, born in 1997, M. S. candidate. Her research interests include natural language processing.Supported by:
罗歆然, 李天瑞(), 贾真
通讯作者:
李天瑞
作者简介:罗歆然(1997—),女,四川德阳人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Xinran LUO, Tianrui LI, Zhen JIA. Chinese medical named entity recognition based on self-attention mechanism and lexicon enhancement[J]. Journal of Computer Applications, 2024, 44(2): 385-392.
罗歆然, 李天瑞, 贾真. 基于自注意力机制与词汇增强的中文医学命名实体识别[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 385-392.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023020179
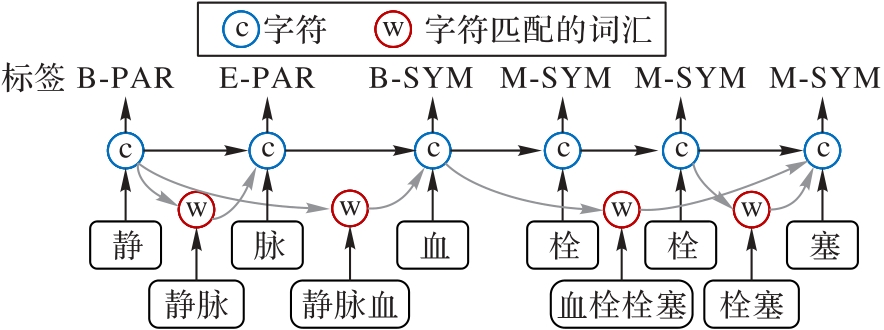
Fig. 1 Architecture of Lattice-LSTM
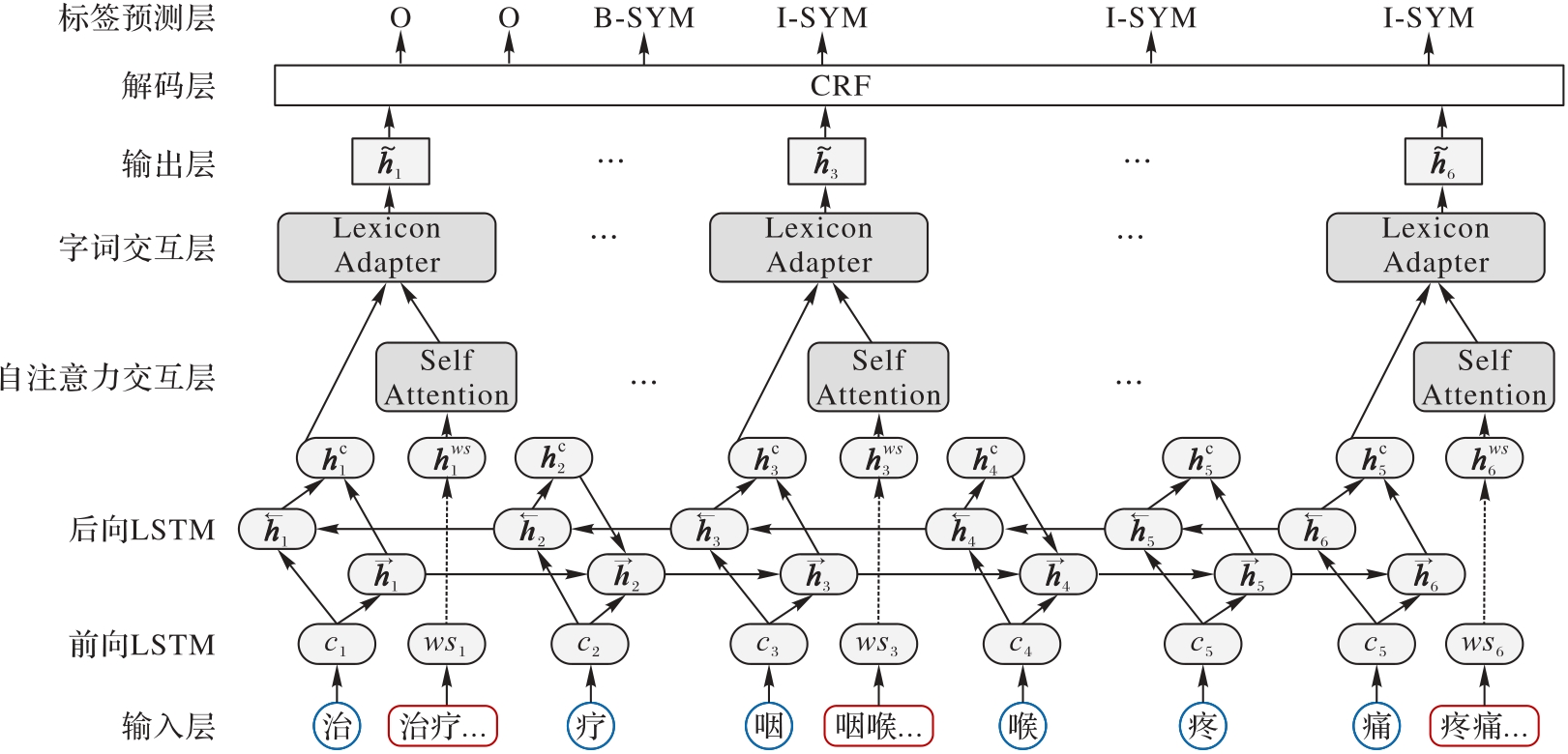
Fig. 2 Overall architecture of AMLEA
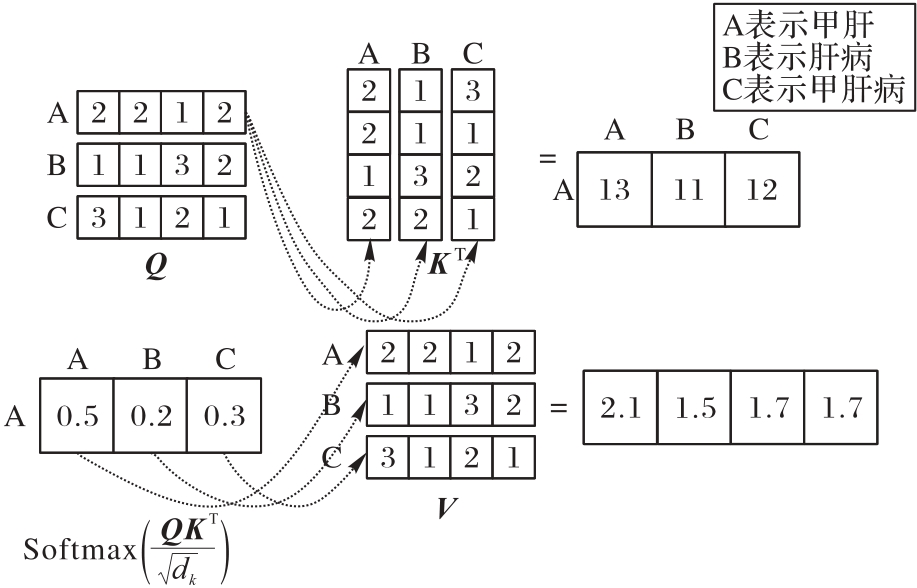
Fig. 3 Computational process of self-attention
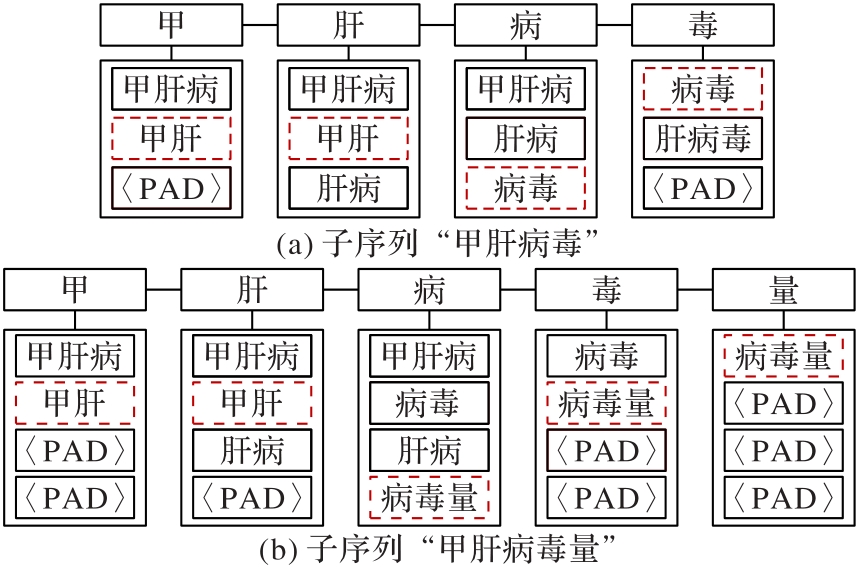
Fig. 4 Character-word pair sequence
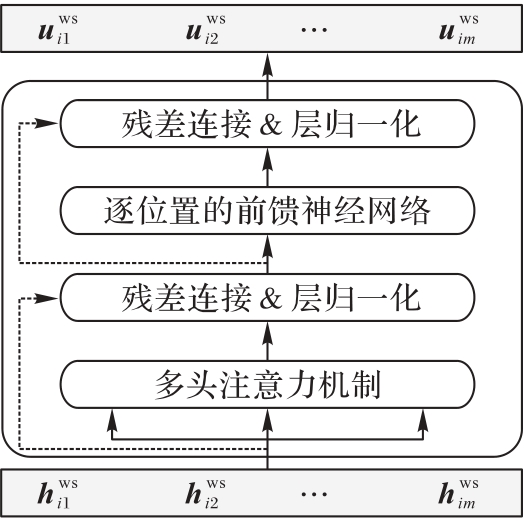
Fig. 5 Structure of Transformer encoder
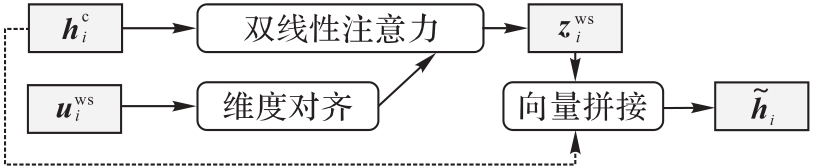
Fig. 6 Structure of lexicon adapter
| 类型 | 样本数 | ||
|---|---|---|---|
| 训练集 | 验证集 | 测试集 | |
| 句子数 | 10 037 | 2 150 | 2 152 |
| 疾病(DIS) | 17 942 | 3 821 | 3 845 |
| 药物(DRU) | 3 243 | 730 | 714 |
| 检查(EXA) | 2 939 | 723 | 656 |
| 部位(PAR) | 1 098 | 157 | 217 |
| 预后(PRO) | 196 | 31 | 36 |
| 症状(SYM) | 8 180 | 1 566 | 1 604 |
| 流行病学(EPI) | 1 263 | 263 | 232 |
| 其他治疗(OTH) | 1 266 | 277 | 276 |
| 手术治疗(OPE) | 625 | 149 | 127 |
| 社会学(SOC) | 3 228 | 679 | 580 |
| 其他(ELS) | 474 | 70 | 84 |
Tab. 1 Dataset statistical results
| 类型 | 样本数 | ||
|---|---|---|---|
| 训练集 | 验证集 | 测试集 | |
| 句子数 | 10 037 | 2 150 | 2 152 |
| 疾病(DIS) | 17 942 | 3 821 | 3 845 |
| 药物(DRU) | 3 243 | 730 | 714 |
| 检查(EXA) | 2 939 | 723 | 656 |
| 部位(PAR) | 1 098 | 157 | 217 |
| 预后(PRO) | 196 | 31 | 36 |
| 症状(SYM) | 8 180 | 1 566 | 1 604 |
| 流行病学(EPI) | 1 263 | 263 | 232 |
| 其他治疗(OTH) | 1 266 | 277 | 276 |
| 手术治疗(OPE) | 625 | 149 | 127 |
| 社会学(SOC) | 3 228 | 679 | 580 |
| 其他(ELS) | 474 | 70 | 84 |
| 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| BiLSTM-CRF | 65.93 | 66.12 | 66.02 |
| Lattice-LSTM | 63.43 | 59.81 | 61.57 |
| ATT-BiLSTM-CRF | 65.42 | 65.74 | 65.58 |
| BGRU-att-CRF | 66.14 | 66.37 | 66.25 |
| FLAT | 64.51 | 63.28 | 63.89 |
| CAN-NER | 66.87 | 66.32 | 66.59 |
| AMLEA | 66.95 | 69.01 | 67.96 |
| BERT+BiLSTM-CRF | 68.70 | 69.29 | 68.99 |
| BERT+AMLEA | 71.78 | 69.47 | 70.61 |
Tab. 2 Experimental results of different models
| 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| BiLSTM-CRF | 65.93 | 66.12 | 66.02 |
| Lattice-LSTM | 63.43 | 59.81 | 61.57 |
| ATT-BiLSTM-CRF | 65.42 | 65.74 | 65.58 |
| BGRU-att-CRF | 66.14 | 66.37 | 66.25 |
| FLAT | 64.51 | 63.28 | 63.89 |
| CAN-NER | 66.87 | 66.32 | 66.59 |
| AMLEA | 66.95 | 69.01 | 67.96 |
| BERT+BiLSTM-CRF | 68.70 | 69.29 | 68.99 |
| BERT+AMLEA | 71.78 | 69.47 | 70.61 |
| 类别 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| 疾病(DIS) | 74.79 | 78.98 | 76.82 |
| 药物(DRU) | 62.03 | 67.22 | 64.52 |
| 检查(EXA) | 58.16 | 65.50 | 61.61 |
| 部位(PAR) | 55.68 | 50.24 | 52.82 |
| 预后(PRO) | 50.00 | 16.67 | 25.00 |
| 症状(SYM) | 66.61 | 68.01 | 67.30 |
| 流行病学(EPI) | 51.15 | 50.45 | 50.80 |
| 其他治疗(OTH) | 44.74 | 42.20 | 43.43 |
| 手术治疗(OPE) | 58.40 | 50.69 | 54.28 |
| 社会学(SOC) | 54.36 | 51.76 | 53.03 |
| 其他(ELS) | 53.85 | 31.34 | 39.62 |
Tab. 3 Experimental results of fine-grained entity recognition
| 类别 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| 疾病(DIS) | 74.79 | 78.98 | 76.82 |
| 药物(DRU) | 62.03 | 67.22 | 64.52 |
| 检查(EXA) | 58.16 | 65.50 | 61.61 |
| 部位(PAR) | 55.68 | 50.24 | 52.82 |
| 预后(PRO) | 50.00 | 16.67 | 25.00 |
| 症状(SYM) | 66.61 | 68.01 | 67.30 |
| 流行病学(EPI) | 51.15 | 50.45 | 50.80 |
| 其他治疗(OTH) | 44.74 | 42.20 | 43.43 |
| 手术治疗(OPE) | 58.40 | 50.69 | 54.28 |
| 社会学(SOC) | 54.36 | 51.76 | 53.03 |
| 其他(ELS) | 53.85 | 31.34 | 39.62 |
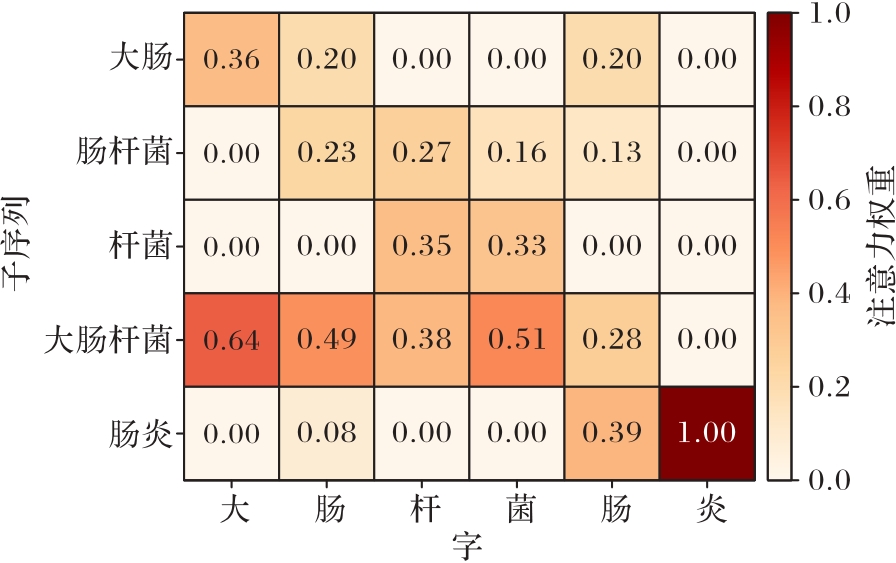
Fig.7 Example of attention visualization
| 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| AMLEA | 66.95 | 69.01 | 67.96 |
| w/o self-attn | 66.42 | 68.55 | 67.47 |
| w/o LA | 64.14 | 67.28 | 65.67 |
| repl concat | 66.67 | 68.73 | 67.68 |
Tab. 4 Results of ablation study
| 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| AMLEA | 66.95 | 69.01 | 67.96 |
| w/o self-attn | 66.42 | 68.55 | 67.47 |
| w/o LA | 64.14 | 67.28 | 65.67 |
| repl concat | 66.67 | 68.73 | 67.68 |
| 1 | ZUO C, ACHARYA N, BANERJEE R. Querying across genres for medical claims in news[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 1783-1789. 10.18653/v1/2020.emnlp-main.139 |
| 2 | 武小平,张强,赵芳,等. 基于BERT的心血管医疗指南实体关系抽取方法[J]. 计算机应用, 2021, 41(1):145-149. 10.11772/j.issn.1001-9081.2020061008 |
| WU X P, ZHANG Q, ZHAO F, et al. Entity relation extraction method for guidelines of cardiovascular disease based on bidirectional encoder representation from Transformers[J]. Journal of Computer Applications, 2021, 41(1): 145-149. 10.11772/j.issn.1001-9081.2020061008 | |
| 3 | 张莹莹,钱胜胜,方全,等. 基于多模态知识感知注意力机制的问答方法[J]. 计算机研究与发展, 2020, 57(5):1037-1045. 10.7544/issn1000-1239.2020.20190474 |
| ZHANG Y Y, QIAN S S, FANG Q, et al. Multi-modal knowledge-aware attention network for question answering[J]. Journal of Computer Research and Development, 2020, 57(5): 1037-1045. 10.7544/issn1000-1239.2020.20190474 | |
| 4 | 殷章志, 李欣子, 黄德根, 等. 融合字词模型的中文命名实体识别研究[J]. 中文信息学报, 2019, 33(11):95-100, 106. 10.3969/j.issn.1003-0077.2019.11.011 |
| YIN Z Z, LI X Z, HUANG D G, et al. Chinese named entity recognition ensembled with character[J]. Journal of Chinese Information Processing, 2019, 33(11): 95-100, 106. 10.3969/j.issn.1003-0077.2019.11.011 | |
| 5 | LIU Y, CHE W, GUO J, et al. Exploring segment representations for neural segmentation models[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2016: 2880-2886. |
| 6 | LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural architectures for named entity recognition[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2016: 260-270. 10.18653/v1/n16-1030 |
| 7 | ZHU Y, WANG G. CAN-NER: convolutional attention network for Chinese named entity recognition[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies(Volume 1: Long and Short Papers). Stroudsburg, PA: ACL, 2019: 3384-3393. 10.18653/v1/N19-1342 |
| 8 | ZHANG Y, YANG J. Chinese NER using lattice LSTM[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2018: 1554-1564. 10.18653/v1/p18-1144 |
| 9 | XUE M, YU B, LIU T, et al. Porous lattice Transformer encoder for Chinese NER[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 3831-3841. 10.18653/v1/2020.coling-main.340 |
| 10 | LI X, YAN H, QIU X, et al. FLAT: Chinese NER using flat-lattice transformer[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 6836-6842. 10.18653/v1/2020.acl-main.611 |
| 11 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. |
| 12 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 13 | 崔博文,金涛,王建民. 自由文本电子病历信息抽取综述[J]. 计算机应用, 2021, 41(4):1055-1063. |
| CUI B W, JIN T, WANG J M. Overview of information extraction of free-text electronic medical records[J]. Journal of Computer Applications, 2021, 41(4): 1055-1063. | |
| 14 | 鄂海红,张文静,肖思琪,等. 深度学习实体关系抽取研究综述[J]. 软件学报, 2019, 30(6):1793-1818. 10.13328/j.cnki.jos.005817 |
| E H H, ZHANG W J, XIAO S Q, et al. Survey of entity relationship extraction based on deep learning[J]. Journal of Software, 2019, 30(6): 1793-1818. 10.13328/j.cnki.jos.005817 | |
| 15 | GUI T, MA R, ZHANG Q, et al. CNN-based Chinese NER with lexicon rethinking[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2019: 4982-4988. 10.24963/ijcai.2019/692 |
| 16 | GUI T, ZOU Y, ZHANG Q, et al. A lexicon-based graph neural network for Chinese NER[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 1040-1050. 10.18653/v1/d19-1096 |
| 17 | SUI D, CHEN Y, LIU K, et al. Leverage lexical knowledge for Chinese named entity recognition via collaborative graph network[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 3830-3840. 10.18653/v1/d19-1396 |
| 18 | LI Y, WANG X, HUI L, et al. Chinese clinical named entity recognition in electronic medical records: development of a lattice long short-term memory model with contextualized character representations[J]. JMIR Medical Informatics, 2020, 8(9): No.e19848. 10.2196/19848 |
| 19 | JU M, MIWA M, ANANIADOU S. A neural layered model for nested named entity recognition[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2018: 1446-1459. 10.18653/v1/n18-1131 |
| 20 | 罗凌,杨志豪,宋雅文,等. 基于笔画ELMo和多任务学习的中文电子病历命名实体识别研究[J]. 计算机学报, 2020, 43(10):1943-1957. 10.11897/SP.J.1016.2020.01943 |
| LUO L, YANG Z H, SONG Y W, et al. Chinese clinical named entity recognition based on stroke ELMo and multi-task learning[J]. Chinese Journal of Computers, 2020, 43(10): 1943-1957. 10.11897/SP.J.1016.2020.01943 | |
| 21 | XU K, YANG Z, KANG P, et al. Document-level attention-based BiLSTM-CRF incorporating disease dictionary for disease named entity recognition[J]. Computers in Biology and Medicine, 2019, 108: 122-132. 10.1016/j.compbiomed.2019.04.002 |
| 22 | 吴炳潮, 邓成龙, 关贝,等. 动态迁移实体块信息的跨领域中文实体识别模型[J]. 软件学报, 2022, 33(10):3776-3792. |
| WU B C, DENG C L, GUAN B, et al. Dynamically transfer entity span information for cross-domain Chinese named entity recognition[J]. Journal of Software, 2022, 33(10): 3776-3792. | |
| 23 | LI X, ZHANG H, ZHOU X H. Chinese clinical named entity recognition with variant neural structures based on BERT methods[J]. Journal of Biomedical Informatics, 2020, 107: No.103422. 10.1016/j.jbi.2020.103422 |
| 24 | 西南交通大学. 基于注意力机制的医学命名实体识别建模方法: 202110667423.9[P]. 2021-09-07. |
| Southwest Jiaotong University. Modeling method of medical named entity recognition based on attention mechanism: 202110667423.9[P]. 2021-09-07. | |
| 25 | SUN Z, LI X, SUN X, et al. ChineseBERT: Chinese pretraining enhanced by Glyph and Pinyin information[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 2065-2075. 10.18653/v1/2021.acl-long.161 |
| 26 | LIU W, FU X, ZHANG Y, et al. Lexicon enhanced Chinese sequence labeling using BERT adapter[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 5847-5858. 10.18653/v1/2021.acl-long.454 |
| 27 | LUO L, YANG Z, YANG P, et al. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition[J]. Bioinformatics, 2018, 34(8): 1381-1388. 10.1093/bioinformatics/btx761 |
| [1] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [2] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [3] | Yue LIU, Fang LIU, Aoyun WU, Qiuyue CHAI, Tianxiao WANG. 3D object detection network based on self-attention mechanism and graph convolution [J]. Journal of Computer Applications, 2024, 44(6): 1972-1977. |
| [4] | Zexin XU, Lei YANG, Kangshun LI. Shorter long-sequence time series forecasting model [J]. Journal of Computer Applications, 2024, 44(6): 1824-1831. |
| [5] | Rong HUANG, Junjie SONG, Shubo ZHOU, Hao LIU. Image aesthetic quality evaluation method based on self-supervised vision Transformer [J]. Journal of Computer Applications, 2024, 44(4): 1269-1276. |
| [6] | Ziqi HUANG, Jianpeng HU. Entity category enhanced nested named entity recognition in automotive domain [J]. Journal of Computer Applications, 2024, 44(2): 377-384. |
| [7] | Liqing QIU, Xiaopan SU. Personalized multi-layer interest extraction click-through rate prediction model [J]. Journal of Computer Applications, 2024, 44(11): 3411-3418. |
| [8] | Xingyao YANG, Hongtao SHEN, Zulian ZHANG, Jiong YU, Jiaying CHEN, Dongxiao WANG. Sequential recommendation based on hierarchical filter and temporal convolution enhanced self-attention network [J]. Journal of Computer Applications, 2024, 44(10): 3090-3096. |
| [9] | Yanbo LI, Qing HE, Shunyi LU. Aspect sentiment triplet extraction integrating semantic and syntactic information [J]. Journal of Computer Applications, 2024, 44(10): 3275-3280. |
| [10] | Li’an CHEN, Yi GUO. Text sentiment analysis model based on individual bias information [J]. Journal of Computer Applications, 2024, 44(1): 145-151. |
| [11] | Jia CHEN, Hong ZHANG. Image text retrieval method based on feature enhancement and semantic correlation matching [J]. Journal of Computer Applications, 2024, 44(1): 16-23. |
| [12] | Hanxiao SHI, Leichun WANG. Short-term power load forecasting by graph convolutional network combining LSTM and self-attention mechanism [J]. Journal of Computer Applications, 2024, 44(1): 311-317. |
| [13] | Guolong YUAN, Yujin ZHANG, Yang LIU. Image tampering forensics network based on residual feedback and self-attention [J]. Journal of Computer Applications, 2023, 43(9): 2925-2931. |
| [14] | Yi ZHANG, Zhenmei WANG. circRNA-disease association prediction by two-stage fusion on graph auto-encoder [J]. Journal of Computer Applications, 2023, 43(6): 1979-1986. |
| [15] | Hao SUN, Jian CAO, Haisheng LI, Dianhui MAO. Session-based recommendation model based on enhanced capsule network [J]. Journal of Computer Applications, 2023, 43(4): 1043-1049. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||