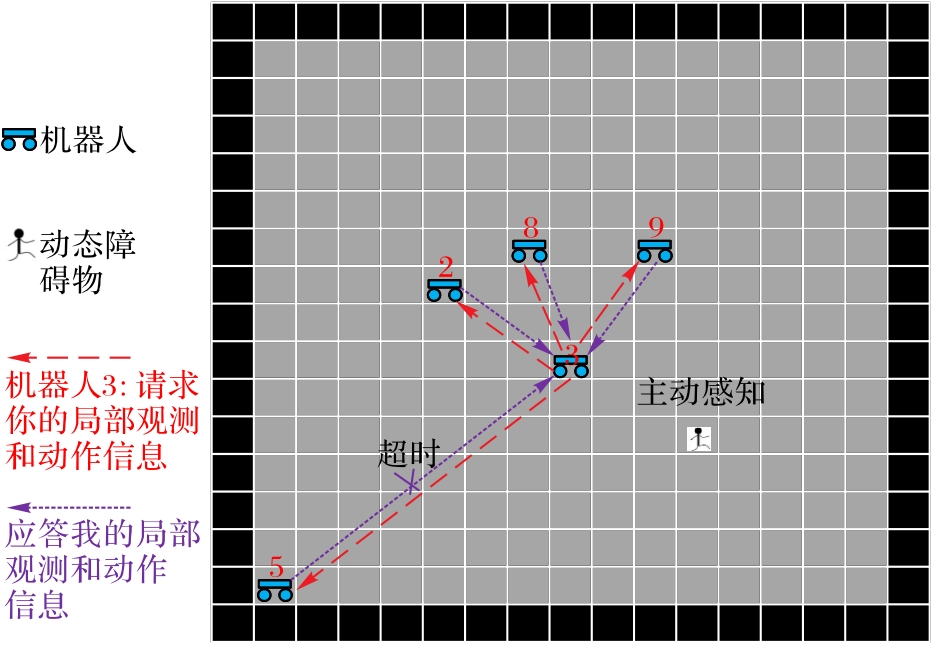
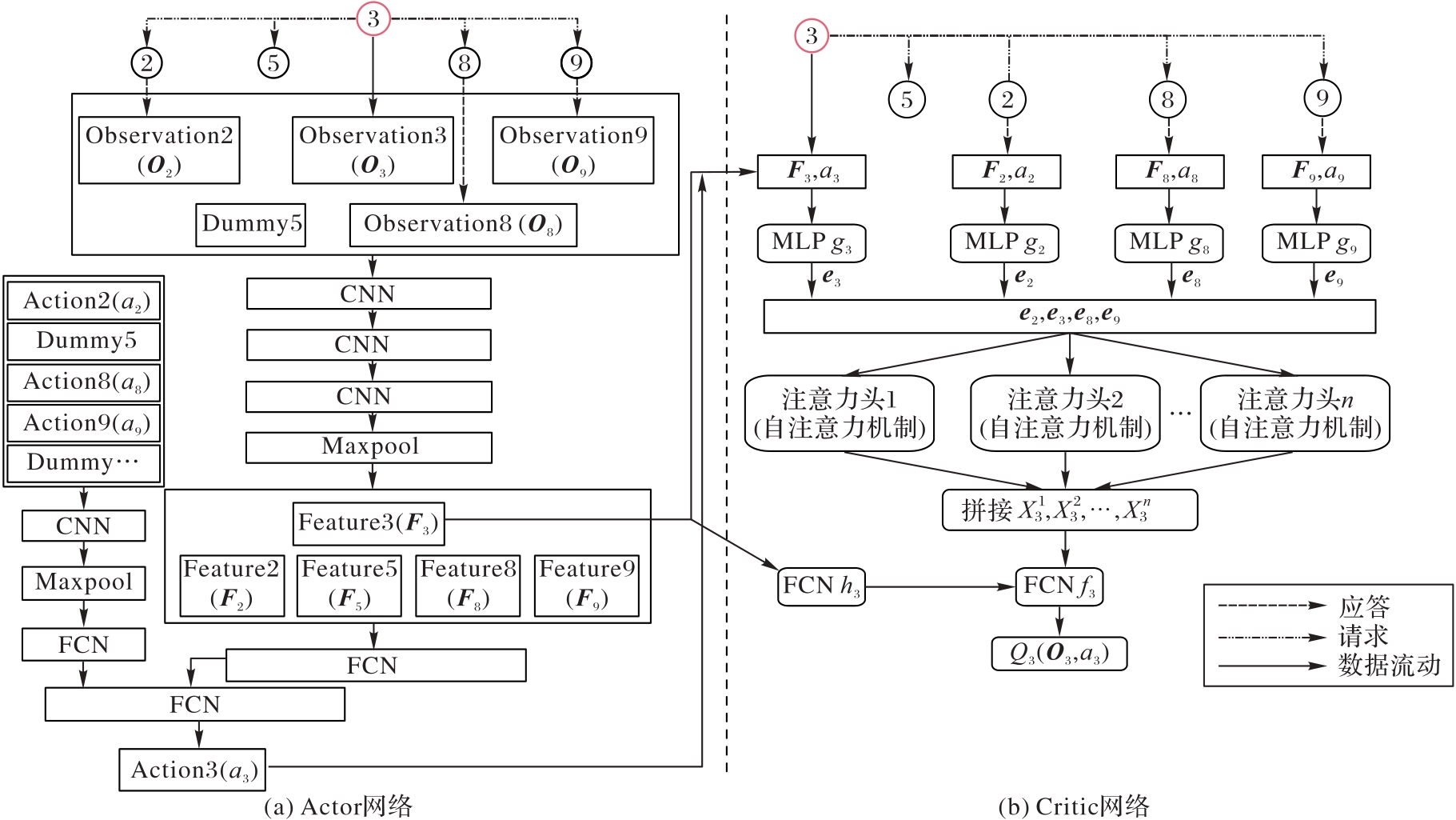
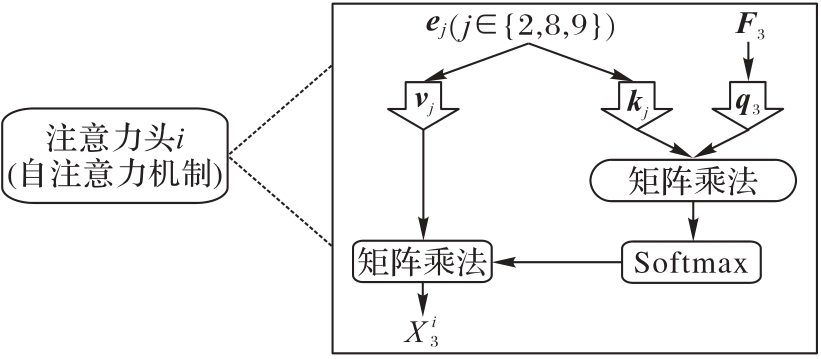
| 1 |
郑延斌,李波,安德宇,等.基于分层强化学习及人工势场的多Agent路径规划方法 [J]. 计算机应用, 2015, 35(12): 3491-3496. 10.11772/j.issn.1001-9081.2015.12.3491
|
|
ZHENG Y B, LI B, AN D Y, et al. Multi-agent path planning method based on hierarchical reinforcement learning and artificial potential field [J]. Journal of Computer Applications, 2015, 35(12): 3491-3496. 10.11772/j.issn.1001-9081.2015.12.3491
|
| 2 |
LESTER P. A* pathfinding for beginners [EB/OL]. [2023-02-01]. .
|
| 3 |
KOENIG S, LIKHACHEV M. D* Lite [C]// Proceedings of the 18th National Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2002: 476-483.
|
| 4 |
SHARON G, STERN R, FELNER A, et al. Conflict-based search for optimal multi-agent pathfinding [J]. Artificial Intelligence, 2015, 219: 40-66. 10.1016/j.artint.2014.11.006
|
| 5 |
祁玄玄, 黄家骏, 曹建安. 基于改进A*算法的无人车路径规划 [J]. 计算机应用, 2020, 40(7): 2021-2027. 10.11772/j.issn.1001-9081.2019112016
|
|
QI X X, HUANG J J, CAO J A. Path planning for unmanned vehicle based on improved A* algorithm [J]. Journal of Computer Applications, 2020, 40(7): 2021-2027. 10.11772/j.issn.1001-9081.2019112016
|
| 6 |
王维,裴东,冯璋. 改进A*算法的移动机器人最短路径规划 [J]. 计算机应用, 2018, 38(5): 1523-1526. 10.11772/j.issn.1001-9081.2017102446
|
|
WANG W, PEI D, FENG Z. The shortest path planning for mobile robots using improved A* algorithm [J]. Journal of Computer Applications, 2018, 38(5): 1523-1526. 10.11772/j.issn.1001-9081.2017102446
|
| 7 |
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning [J]. Nature, 2019, 575: 350-354. 10.1038/s41586-019-1724-z
|
| 8 |
SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search [J]. Nature, 2016, 529: 484-489. 10.1038/nature16961
|
| 9 |
DAMANI M, LUO Z, WENZEL E, et al. PRIMAL2: pathfinding via reinforcement and imitation multi-agent learning-lifelong [J]. IEEE Robotics and Automation Letters, 2021, 6(2): 2666-2673. 10.1109/lra.2021.3062803
|
| 10 |
SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning[EB/OL].[2023-02-01]. .
|
| 11 |
RASHID T, SAMVELYAN M, SCHROEDER C, et al. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning[J] . The Journal of Machine Learning Research, 2020, 21(1): 1-51.
|
| 12 |
邓晖奕, 李勇振, 尹奇跃. 引入通信与探索的多智能体强化学习QMIX算法[J]. 计算机应用, 2023, 43(1): 202-208.
|
|
DENG H Y, LI Y Z, YIN Q Y. Improved QMIX algorithm from communication and exploration for multi-agent reinforcement learning[J].Journal of Computer Applications, 2023, 43(1): 202-208.
|
| 13 |
SON K, KIM D, KANG W J, et al. QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning [C]// Proceedings of the36th International Conference on Machine Learning. New York: PMLR, 2019: 5887-5896. 10.48550/arXiv.1905.05408
|
| 14 |
LIU Z, CHEN B, ZHOU H, et al. MAPPER: multi-agent path planning with evolutionary reinforcement learning in mixed dynamic environments[C]// Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2020: 11748-11754. 10.1109/iros45743.2020.9340876
|
| 15 |
GUAN H, GAO Y, ZHAO M, et al. AB-MAPPER: Attention and BicNet based multi-agent path planning for dynamic environment[C]// Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2022: 13799-13806. 10.1109/iros47612.2022.9981513
|
| 16 |
SUKHBAATAR S, SZLAM A, FERGUS R. Learning multiagent communication with backpropagation [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 2252-2260.
|
| 17 |
PENG P, WEN Y, YANG Y, et al. Multiagent bidirectionally-coordinated nets: emergence of human-level coordination in learning to play StarCraft combat games [EB/OL]. (2019-03-29) [2023-02-01]. .
|
| 18 |
KIM D, MOON S, HOSTALLERO D, et al. Learning to schedule communication in multi-agent reinforcement learning [EB/OL]. (2019-02-05) [2023-02-01]. .
|
| 19 |
JIANG J, LU Z. Learning attentional communication for multi-agent cooperation [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 7265-7275.
|
| 20 |
DAS A, GERVET T, ROMOFF J, et al. TarMAC: targeted multi-agent communication[C]// Proceedings of the 36th International Conference on Machine Learning. New York: PMLR, 2019:1538-1546.
|
| 21 |
DING Z, HUANG T, LU Z. Learning individually inferred communication for multi-agent cooperation [C/OL]// Proceedings of the 34th International Conference on Neural Information Processing Systems, 2020[2023-02-01]. .
|
| 22 |
PARNIKA P, DIDDIGI R B, DANDA S K R, et al. Attention actor-critic algorithm for multi-agent constrained co-operative reinforcement learning [EB/OL]. (2021-01-07) [2023-02-01]..
|
| 23 |
LIU S, TANG J. Modified deep reinforcement learning with efficient convolution feature for small target detection in VHR remote sensing imagery [J]. ISPRS International Journal of Geo-Information, 2021, 10(3): 170. 10.3390/ijgi10030170
|
| 24 |
CHOI J, DANCE C, KIM J-E, et al. Fast adaptation of deep reinforcement learning-based navigation skills to human preference[C]// Proceedings of the 2020 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2020: 3363-3370. 10.1109/icra40945.2020.9197159
|
| 25 |
XU C, ZHAO W, CHEN Q, et al. An actor-critic based learning method for decision-making and planning of autonomous vehicles [J]. Science China Technological Sciences, 2021, 64: 984-994. 10.1007/s11431-020-1729-2
|
| 26 |
IQBAL S, SHA F. Actor-attention-critic for multi-agent reinforcement learning[C]// Proceedings of the 36th International Conference on Machine Learning. New York: PMLR, 2019: 2961-2970.
|


 )
)