


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (3): 713-723.DOI: 10.11772/j.issn.1001-9081.2021040911
所属专题: 人工智能; 2021年中国计算机学会人工智能会议(CCFAI 2021)
• 2021年中国计算机学会人工智能会议(CCFAI 2021) • 上一篇 下一篇
轩书婷, 刘惊雷( )
)
收稿日期:2021-05-31
修回日期:2021-06-27
接受日期:2021-06-29
发布日期:2022-04-09
出版日期:2022-03-10
通讯作者:
刘惊雷
作者简介:轩书婷(1997—),女,山东济宁人,硕士研究生,主要研究方向:基于离散哈希的聚类分析;
基金资助:Received:2021-05-31
Revised:2021-06-27
Accepted:2021-06-29
Online:2022-04-09
Published:2022-03-10
Contact:
Jinglei LIU
About author:XUAN Shuting, born in 1997, M. S. candidate. Her research interests include clustering analysis based on discrete hashing.
Supported by:摘要:
传统的聚类方法是在数据空间进行,且聚类数据的维度较高。为了解决这两个问题,提出了一种新的二进制图像聚类方法——基于离散哈希的聚类(CDH)。该框架通过
中图分类号:
轩书婷, 刘惊雷. 基于离散哈希的聚类[J]. 计算机应用, 2022, 42(3): 713-723.
Shuting XUAN, Jinglei LIU. Clustering based on discrete hashing[J]. Journal of Computer Applications, 2022, 42(3): 713-723.

图 1 所提方法的主要框架
Fig. 1 Main framework of proposed method
| 符号 | 维度 | 含义 | 符号 | 维度 | 含义 | 符号 | 维度 | 含义 | 符号 | 维度 | 含义 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | 哈希码矩阵 | 对角矩阵 | Y1, Y2, D | 辅助变量 | µi | 聚类质心 | |||||
| Y | 数据矩阵 | L | 图的拉普拉斯矩阵 | n | 数据样本个数 | 符号函数 | |||||
| I | 单位矩阵 | A | 加权邻接矩阵 | d | 原始数据维度 | 矩阵的迹 | |||||
| C | 聚类中心矩阵 | E | 错误矩阵 | l | 二进制哈希码长度 | 矩阵 W 的 | |||||
| G | {0,1} c×n | 标签矩阵 | S | 相似矩阵 | c | 聚类个数 | 矩阵 W 的 | ||||
| W | 映射矩阵 | F | 图片标签关系矩阵 | m | 非线性嵌入维数 |
表1 基本符号
Tab. 1 Basic symbols
| 符号 | 维度 | 含义 | 符号 | 维度 | 含义 | 符号 | 维度 | 含义 | 符号 | 维度 | 含义 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | 哈希码矩阵 | 对角矩阵 | Y1, Y2, D | 辅助变量 | µi | 聚类质心 | |||||
| Y | 数据矩阵 | L | 图的拉普拉斯矩阵 | n | 数据样本个数 | 符号函数 | |||||
| I | 单位矩阵 | A | 加权邻接矩阵 | d | 原始数据维度 | 矩阵的迹 | |||||
| C | 聚类中心矩阵 | E | 错误矩阵 | l | 二进制哈希码长度 | 矩阵 W 的 | |||||
| G | {0,1} c×n | 标签矩阵 | S | 相似矩阵 | c | 聚类个数 | 矩阵 W 的 | ||||
| W | 映射矩阵 | F | 图片标签关系矩阵 | m | 非线性嵌入维数 |
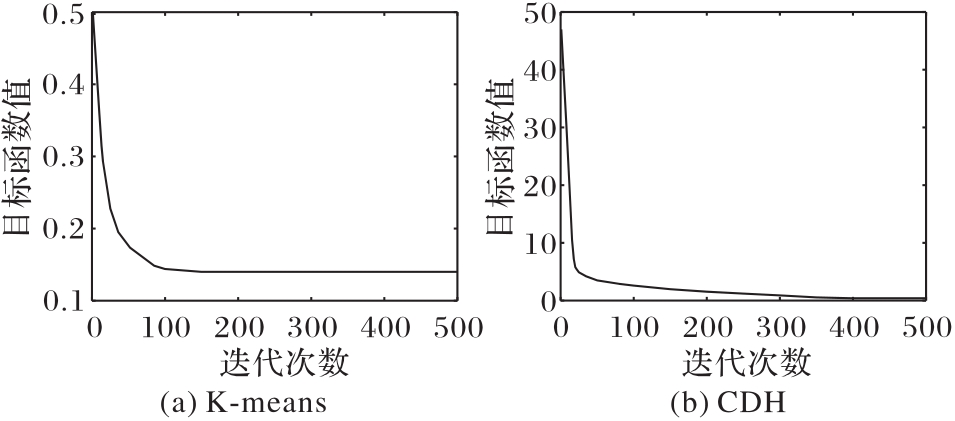
图2 两种方法在COIL20数据集上的收敛曲线
Fig. 2 Convergence curves of two methods on COIL20 dataset

图3 α和γ值对Caltech101数据集的HOG视图Acc、NMI、纯度的影响
Fig. 3 Effects of α and γ values on HOG view Acc,NMI,Purity for Caltech101 dataset

图4 Acc、NMI和纯度相对于不同λ的变化
Fig. 4 Acc, NMI and Purity changes with respect to different λ

图5 用于实验的数据样本集示例
Fig. 5 Samples of datasets for experiments
| 数据集 | 特征名 | 样本数量 | 维度 | 类数 |
|---|---|---|---|---|
| Caltech101 | Gabor | 9 144 | 48 | 102 |
| WM | 9 144 | 40 | 102 | |
| CENTRIST | 9 144 | 254 | 102 | |
| HOG | 9 144 | 1 984 | 102 | |
| GIST | 9 144 | 512 | 102 | |
| LBP | 9 144 | 928 | 102 | |
| Yale | 165 | 4 096 | 15 | |
| COIL20 | 1 440 | 1 024 | 20 | |
| ORL | 400 | 1 024 | 40 |
表2 数据集特征
Tab. 2 Dataset characteristics
| 数据集 | 特征名 | 样本数量 | 维度 | 类数 |
|---|---|---|---|---|
| Caltech101 | Gabor | 9 144 | 48 | 102 |
| WM | 9 144 | 40 | 102 | |
| CENTRIST | 9 144 | 254 | 102 | |
| HOG | 9 144 | 1 984 | 102 | |
| GIST | 9 144 | 512 | 102 | |
| LBP | 9 144 | 928 | 102 | |
| Yale | 165 | 4 096 | 15 | |
| COIL20 | 1 440 | 1 024 | 20 | |
| ORL | 400 | 1 024 | 40 |
| 方法 | Gabor | WM | CENTRIST | HOG | GIST | LBP |
|---|---|---|---|---|---|---|
| K-means | 0.101 3 | 0.122 9 | 0.135 8 | 0.248 8 | 0.236 2 | 0.207 2 |
| SC | 0.116 7 | 0.119 8 | 0.105 0 | 0.230 4 | 0.230 8 | 0.192 9 |
| LSC-K | 0.103 3 | 0.124 7 | 0.121 8 | 0.246 6 | 0.229 6 | 0.194 3 |
| LSH+bk-means | 0.102 1 | 0.112 8 | 0.107 2 | 0.191 4 | 0.193 5 | 0.131 2 |
| CKM | 0.115 0 | 0.121 7 | 0.118 5 | 0.200 6 | 0.178 9 | 0.265 7 |
| AMGL | 0.098 9 | 0.119 2 | 0.142 1 | 0.220 4 | 0.197 4 | 0.224 1 |
| MVKM | 0.103 1 | 0.129 9 | 0.128 3 | 0.246 8 | 0.239 6 | 0.227 4 |
| CDH | 0.118 9 | 0.131 1 | 0.139 8 | 0.275 9 | 0.257 1 | 0.234 4 |
表3 不同方法在Caltech101数据集上的精度对比
Tab.3 Accuracy comparison of different methods on Caltech101 dataset
| 方法 | Gabor | WM | CENTRIST | HOG | GIST | LBP |
|---|---|---|---|---|---|---|
| K-means | 0.101 3 | 0.122 9 | 0.135 8 | 0.248 8 | 0.236 2 | 0.207 2 |
| SC | 0.116 7 | 0.119 8 | 0.105 0 | 0.230 4 | 0.230 8 | 0.192 9 |
| LSC-K | 0.103 3 | 0.124 7 | 0.121 8 | 0.246 6 | 0.229 6 | 0.194 3 |
| LSH+bk-means | 0.102 1 | 0.112 8 | 0.107 2 | 0.191 4 | 0.193 5 | 0.131 2 |
| CKM | 0.115 0 | 0.121 7 | 0.118 5 | 0.200 6 | 0.178 9 | 0.265 7 |
| AMGL | 0.098 9 | 0.119 2 | 0.142 1 | 0.220 4 | 0.197 4 | 0.224 1 |
| MVKM | 0.103 1 | 0.129 9 | 0.128 3 | 0.246 8 | 0.239 6 | 0.227 4 |
| CDH | 0.118 9 | 0.131 1 | 0.139 8 | 0.275 9 | 0.257 1 | 0.234 4 |
| 方法 | Gabor | WM | CENTRIST | HOG | GIST | LBP |
|---|---|---|---|---|---|---|
| K-means | 0.257 9 | 0.291 3 | 0.302 3 | 0.470 0 | 0.446 2 | 0.399 6 |
| SC | 0.284 0 | 0.300 2 | 0.325 1 | 0.471 0 | 0.448 1 | 0.405 1 |
| LSC-K | 0.250 9 | 0.291 9 | 0.302 5 | 0.466 4 | 0.438 4 | 0.383 7 |
| LSH+bk-means | 0.250 3 | 0.261 4 | 0.268 0 | 0.369 6 | 0.369 0 | 0.287 0 |
| CKM | 0.254 3 | 0.204 3 | 0.251 7 | 0.226 0 | 0.226 1 | 0.161 0 |
| AMGL | 0.252 7 | 0.292 1 | 0.303 0 | 0.415 7 | 0.403 8 | 0.375 9 |
| MVKM | 0.253 6 | 0.292 7 | 0.305 6 | 0.286 9 | 0.356 9 | 0.354 0 |
| CDH | 0.301 2 | 0.317 2 | 0.356 | 0.462 6 | 0.490 0 | 0.403 2 |
表4 不同方法在Caltech101数据集上的NMI对比
Tab.4 NMI comparison of different methods on Caltech101 dataset
| 方法 | Gabor | WM | CENTRIST | HOG | GIST | LBP |
|---|---|---|---|---|---|---|
| K-means | 0.257 9 | 0.291 3 | 0.302 3 | 0.470 0 | 0.446 2 | 0.399 6 |
| SC | 0.284 0 | 0.300 2 | 0.325 1 | 0.471 0 | 0.448 1 | 0.405 1 |
| LSC-K | 0.250 9 | 0.291 9 | 0.302 5 | 0.466 4 | 0.438 4 | 0.383 7 |
| LSH+bk-means | 0.250 3 | 0.261 4 | 0.268 0 | 0.369 6 | 0.369 0 | 0.287 0 |
| CKM | 0.254 3 | 0.204 3 | 0.251 7 | 0.226 0 | 0.226 1 | 0.161 0 |
| AMGL | 0.252 7 | 0.292 1 | 0.303 0 | 0.415 7 | 0.403 8 | 0.375 9 |
| MVKM | 0.253 6 | 0.292 7 | 0.305 6 | 0.286 9 | 0.356 9 | 0.354 0 |
| CDH | 0.301 2 | 0.317 2 | 0.356 | 0.462 6 | 0.490 0 | 0.403 2 |
| 算法 | Gabor | WM | CENTRIST | HOG | GIST | LBP |
|---|---|---|---|---|---|---|
| K-means | 0.244 0 | 0.283 0 | 0.293 6 | 0.462 3 | 0.439 0 | 0.380 8 |
| SC | 0.138 0 | 0.297 4 | 0.230 9 | 0.428 0 | 0.401 3 | 0.405 8 |
| LSC-K | 0.227 9 | 0.262 0 | 0.277 0 | 0.404 6 | 0.401 0 | 0.378 9 |
| LSH+bk-means | 0.235 9 | 0.245 2 | 0.250 7 | 0.366 3 | 0.364 1 | 0.283 4 |
| CKM | 0.245 7 | 0.210 2 | 0.232 9 | 0.291 1 | 0.265 2 | 0.238 5 |
| AMGL | 0.244 1 | 0.281 6 | 0.295 6 | 0.415 7 | 0.420 4 | 0.383 1 |
| MVKM | 0.241 4 | 0.283 4 | 0.294 2 | 0.298 8 | 0.367 3 | 0.346 7 |
| CDH | 0.252 5 | 0.305 0 | 0.336 7 | 0.478 2 | 0.453 1 | 0.413 1 |
表5 不同方法在Caltech101数据集上的纯度对比
Tab.5 Purity comparison of different methods on Caltech101 dataset
| 算法 | Gabor | WM | CENTRIST | HOG | GIST | LBP |
|---|---|---|---|---|---|---|
| K-means | 0.244 0 | 0.283 0 | 0.293 6 | 0.462 3 | 0.439 0 | 0.380 8 |
| SC | 0.138 0 | 0.297 4 | 0.230 9 | 0.428 0 | 0.401 3 | 0.405 8 |
| LSC-K | 0.227 9 | 0.262 0 | 0.277 0 | 0.404 6 | 0.401 0 | 0.378 9 |
| LSH+bk-means | 0.235 9 | 0.245 2 | 0.250 7 | 0.366 3 | 0.364 1 | 0.283 4 |
| CKM | 0.245 7 | 0.210 2 | 0.232 9 | 0.291 1 | 0.265 2 | 0.238 5 |
| AMGL | 0.244 1 | 0.281 6 | 0.295 6 | 0.415 7 | 0.420 4 | 0.383 1 |
| MVKM | 0.241 4 | 0.283 4 | 0.294 2 | 0.298 8 | 0.367 3 | 0.346 7 |
| CDH | 0.252 5 | 0.305 0 | 0.336 7 | 0.478 2 | 0.453 1 | 0.413 1 |
| 方法 | 数据集 | ||
|---|---|---|---|
| Yale | COIL20 | ORL | |
| K-means | 0.48±0.01 | 0.14±0.01 | 0.56±0.01 |
| RPCA | 0.53±0.01 | 0.10±0.01 | 0.61±0.02 |
| NMF | 0.35±0.02 | 0.25±0.01 | 0.23±0.01 |
| GNMF | 0.53±0.01 | 0.29±0.01 | 0.62±0.01 |
| RMNMF | 0.46±0.01 | 0.30±0.01 | 0.62±0.01 |
| CDH | 0.63±0.01 | 0.33±0.03 | 0.49±0.01 |
表6 不同方法在不同数据集的精度对比
Tab. 6 Accuracy comparison of different methods on different datasets
| 方法 | 数据集 | ||
|---|---|---|---|
| Yale | COIL20 | ORL | |
| K-means | 0.48±0.01 | 0.14±0.01 | 0.56±0.01 |
| RPCA | 0.53±0.01 | 0.10±0.01 | 0.61±0.02 |
| NMF | 0.35±0.02 | 0.25±0.01 | 0.23±0.01 |
| GNMF | 0.53±0.01 | 0.29±0.01 | 0.62±0.01 |
| RMNMF | 0.46±0.01 | 0.30±0.01 | 0.62±0.01 |
| CDH | 0.63±0.01 | 0.33±0.03 | 0.49±0.01 |
| 方法 | 数据集 | ||
|---|---|---|---|
| Yale | COIL20 | ORL | |
| K-means | 0.39±0.02 | 0.44±0.01 | 0.68±0.01 |
| RPCA | 0.46±0.01 | 0.30±0.01 | 0.72±0.01 |
| NMF | 0.23±0.03 | 0.40±0.01 | 0.33±0.02 |
| GNMF | 0.42±0.02 | 0.39±0.01 | 0.73±0.02 |
| RMNMF | 0.45±0.01 | 0.40±0.01 | 0.71±0.01 |
| CDH | 0.56±0.02 | 0.51±0.01 | 0.70±0.01 |
表7 不同方法在不同数据集的NMI对比
Tab. 7 NMI comparison of different methods on different datasets
| 方法 | 数据集 | ||
|---|---|---|---|
| Yale | COIL20 | ORL | |
| K-means | 0.39±0.02 | 0.44±0.01 | 0.68±0.01 |
| RPCA | 0.46±0.01 | 0.30±0.01 | 0.72±0.01 |
| NMF | 0.23±0.03 | 0.40±0.01 | 0.33±0.02 |
| GNMF | 0.42±0.02 | 0.39±0.01 | 0.73±0.02 |
| RMNMF | 0.45±0.01 | 0.40±0.01 | 0.71±0.01 |
| CDH | 0.56±0.02 | 0.51±0.01 | 0.70±0.01 |
| 方法 | 数据集 | ||
|---|---|---|---|
| Yale | COIL20 | ORL | |
| K-means | 0.49±0.02 | 0.14±0.01 | 0.63±0.01 |
| RPCA | 0.54±0.03 | 0.10±0.01 | 0.39±0.01 |
| NMF | 0.38±0.03 | 0.32±0.01 | 0.25±0.02 |
| GNMF | 0.53±0.02 | 0.19±0.01 | 0.67±0.02 |
| RMNMF | 0.51±0.01 | 0.28±0.01 | 0.65±0.01 |
| CDH | 0.54±0.01 | 0.29±0.02 | 0.69±0.01 |
表8 不同方法在不同数据集的纯度对比
Tab. 8 Purity comparison of different methods on different datasets
| 方法 | 数据集 | ||
|---|---|---|---|
| Yale | COIL20 | ORL | |
| K-means | 0.49±0.02 | 0.14±0.01 | 0.63±0.01 |
| RPCA | 0.54±0.03 | 0.10±0.01 | 0.39±0.01 |
| NMF | 0.38±0.03 | 0.32±0.01 | 0.25±0.02 |
| GNMF | 0.53±0.02 | 0.19±0.01 | 0.67±0.02 |
| RMNMF | 0.51±0.01 | 0.28±0.01 | 0.65±0.01 |
| CDH | 0.54±0.01 | 0.29±0.02 | 0.69±0.01 |
| 1 | ZHANG R, NIE F P, GUO M H, et al. Joint learning of fuzzy k-means and nonnegative spectral clustering with side information [J]. IEEE Transactions on Image Processing, 2019, 28(5): 2152-2162. 10.1109/tip.2018.2882925 |
| 2 | ZHAO W L, DENG C H, NGO C W. k-means: a revisit [J]. Neurocomputing, 2018, 291: 195-206. 10.1016/j.neucom.2018.02.072 |
| 3 | NIE F P, WANG C L, LI X L. K-multiple-means: a multiple-means clustering method with specified k clusters[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 959-967. 10.1145/3292500.3330846 |
| 4 | IOANNIS T, GIORGOS B, PAVLOS K, et al. A greedy feature selection algorithm for big data of high dimensionality [J]. Machine Learning, 2019, 108(2): 149-202. 10.1007/s10994-018-5748-7 |
| 5 | GONG Y, PAWLOWSKI M, FEI Y, et al. Web scale photo hash clustering on a single machine[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 19-27. 10.1109/cvpr.2015.7298596 |
| 6 | ADOLFSSON A, ACKERMAN M, BROWNSTEIN N C. To cluster, or not to cluster: an analysis of clusterability methods-ScienceDirect[J]. Pattern Recognition, 2019, 88(6): 13-26. 10.1016/j.patcog.2018.10.026 |
| 7 | HAYASHI N. Variational approximation error in non-negative matrix factorization[J]. Neural Networks, 2020, 126: 65-75. 10.1016/j.neunet.2020.03.009 |
| 8 | WANG Y T, WANG J D, HAO L, et al. An efficient semi-supervised representatives feature selection algorithm based on information theory [J]. Pattern Recognition Society Pattern Recognition, 2017, 61: 511-523. 10.1016/j.patcog.2016.08.011 |
| 9 | ARTHUR D, VASSILVITSKII S. k-means++: the advantages of careful seeding [C]// Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia, PA :Society for Industrial and Applied Mathematics, 2007:1027-1035. |
| 10 | SCHLKOPF B, PLATT J, HOFMANN T. Efficient sparse coding algorithms [C]// Proceedings of the 19th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2007:801-808. 10.7551/mitpress/7503.003.0105 |
| 11 | LIU W, HE J, CHANG S F. Large graph construction for scalable semi-supervised learning[C]// Proceedings of the 27th International Conference on Machine Learning. Madison: Omni Press, 2010: 679-686. |
| 12 | CAPÓ M, PÉREZ A, LOZANO J A. An efficient approximation to the K-means clustering for massive data [J]. Knowledge-Based Systems, 2017, 117(2): 56-69. 10.1016/j.knosys.2016.06.031 |
| 13 | BOUTSIDIS C, ZOUZIAS A, MAHONEY M W. Randomized dimensionality reduction for k-means clustering[J]. IEEE Transactions on Information Theory, 2015,61(2):1045-1062. 10.1109/tit.2014.2375327 |
| 14 | SINHA K. K-means clustering using random matrix sparsification[C]// Proceedings of the 35th International Conference on Machine Learning. New York: ACM, 2018:4684-4692. 10.1109/indicon45594.2018.8986990 |
| 15 | 马雷. 面向大规模图像哈希学习的理论与方法研究 [D].成都: 电子科技大学,2019: 1. |
| MA L. Research on theory and method of large-scale image hashing learning[D].Chengdu: University of Electronic Science and Technology of China, 2019: 1. | |
| 16 | HUANG S, WANG H, LI T, et al. Robust graph regularized nonnegative matrix factorization for clustering [J]. Data Mining and Knowledge Discovery, 2018,32(3):483-503. 10.1007/s10618-017-0543-9 |
| 17 | TAO H, HOU C, NIE F, et al. Effective discriminative feature selection with nontrivial solution [J]. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(4): 796-808. 10.1109/tnnls.2015.2424721 |
| 18 | CHE J, YANG Y, LI L, et al. Maximum relevance minimum common redundancy feature selection for nonlinear data [J]. Information Sciences, 2017, 409/410: 68-86. 10.1016/j.ins.2017.05.013 |
| 19 | ALELYANI S, TANG J, LIU H. Feature selection for clustering: a review [J]. Encyclopedia of Database Systems, 2016, 21(3): 110-121. |
| 20 | SHEN F, YANG Y, LI L, et al. Asymmetric binary coding for image search [J]. IEEE Transactions on Multimedia, 2017, 19(9): 2022-2032. 10.1109/tmm.2017.2699863 |
| 21 | NIE F P, YANG S, ZHANG R,et al. A general framework for auto-weighted feature selection via global redundancy minimization [J]. IEEE Transactions on Image Processing,2019,28(5): 2428-2438. 10.1109/tip.2018.2886761 |
| 22 | SHEN F M, ZHOU X, YANG Y,et al. A fast optimization method for general binary code learning [J]. IEEE Transactions on Image Processing, 2016, 25(12):5610-5621. 10.1109/tip.2016.2612883 |
| 23 | LI Y, ZHANG S, CHENG D, et al. Spectral clustering based on hypergraph and self-representation[J]. Multimedia Tools & Applications, 2017, 76(16):17559-17576. 10.1007/s11042-016-4131-6 |
| 24 | DU X Z, NIE F P, WANG W Q, et.al. Exploiting combination effect for unsupervised feature selection by l2,0 norm[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(1):201-214. 10.1109/tnnls.2018.2837100 |
| 25 | HOU C P, NIE F P, LI X L, et al. Joint embedding learning and sparse regression: a framework for unsupervised feature selection [J]. IEEE Transactions on Cybernetics, 2014,44(6):793-804. 10.1109/tcyb.2013.2272642 |
| 26 | XI P, TANG H, LEI Z, et al. A unified framework for representation-based subspace clustering of out-of-sample and large-scale data [J]. IEEE Transactions on Neural Networks & Learning Systems, 2015, 27(12): 2499-2512. 10.1109/tnnls.2015.2490080 |
| 27 | 李来, 刘光灿, 孙玉宝, 等. 各向同性的迭代量化哈希算法 [J]. 电子学报, 2017, 45(7): 1707-1714. 10.3969/j.issn.0372-2112.2017.07.022 |
| LI L, LIU G C, SUN Y B, et al.Isotropic iterative quantization hashing [J]. Acta Electronic Sinica,2017, 45(7): 1707-1714. 10.3969/j.issn.0372-2112.2017.07.022 | |
| 28 | WEN J, XU Y, LI Z, et al. Inter-class sparsity based discriminative least square regression [J]. Neural Networks, 2018, 102: 36-47. 10.1016/j.neunet.2018.02.002 |
| 29 | ELHAMIFAR E, VIDAL R. Sparse subspace clustering: algorithm, theory, and applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(11): 2765-2781. 10.1109/tpami.2013.57 |
| 30 | CAI D, CHEN X. Large scale spectral clustering via landmark-based sparse representation [J]. IEEE Transactions on Cybernetics, 2015, 45(8): 1669-1680. 10.1109/tcyb.2014.2358564 |
| 31 | ZHU X F, ZHANG S C, LI Y G, et.al. Low-rank sparse subspace for spectral clustering [J]. IEEE Transactions on Knowledge and Data Engineering, 2019,31(8):1532-1543. 10.1109/tkde.2018.2858782 |
| 32 | WANG Y L, TANG Y Y, LUO Q. Minimum error entropy based sparse representation for robust subspace clustering [J]. IEEE Transactions on Signal Processing, 2015, 63(15):4010-4021. 10.1109/tsp.2015.2425803 |
| 33 | WAN Y, ZHONG Y, MA A, et al. Multi-objective sparse subspace clustering for hyperspectral imagery [J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(4): 2290-2307. 10.1109/tgrs.2019.2947253 |
| 34 | LI Y, NIE F, HUANG H, et al. Large-scale multi-view spectral clustering via bipartite graph [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence.Menlo Park, CA:AAAI, 2015: 2750-2756. |
| 35 | CAI X, NIE F P, HUANG H.Multi-view k-means clustering on big data[C]// Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Menlo Park, CA:AAAI, 2010: 2598-2604. |
| 36 | NIE F P, JING L, LI X L. Parameter-free auto-weighted multiple graph learning: a framework for multiview clustering and semi-supervised classification [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. Menlo Park, CA:AAAI, 2016:1881-1887. 10.24963/ijcai.2017/357 |
| 37 | ZHANG T, YANG Y. Robust PCA by manifold optimization[J]. Journal of Machine Learning Research,2018,19: 1-39. |
| 38 | LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature,1999,401(6755):788-791. 10.1038/44565 |
| 39 | 章永来, 周耀鉴. 聚类算法综述[J]. 计算机应用, 2019,39(7):1869-1882. 10.11772/j.issn.1001-9081.2019010174 |
| ZHANG Y L, ZHOU Y J.Review of clustering algorithms[J]. Journal of Computer Applications, 2019,39(7):1869-1882. 10.11772/j.issn.1001-9081.2019010174 |
| [1] | 柳兴华, 曹桂涛, 林秋斌, 曹文明. 自适应混合注意力深度跨模态哈希[J]. 《计算机应用》唯一官方网站, 2022, 42(12): 3663-3670. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||