《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (4): 1050-1055.DOI: 10.11772/j.issn.1001-9081.2022020317
所属专题: 人工智能
张旭1, 生龙1,2, 张海芳3, 田丰4( ), 王巍1,2
), 王巍1,2
Xu ZHANG1, Long SHENG1,2, Haifang ZHANG3, Feng TIAN4(), Wei WANG1,2
摘要:
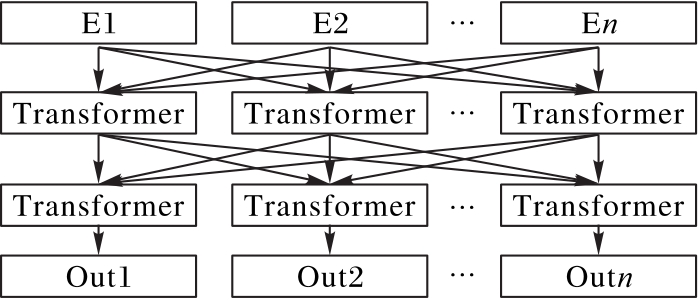
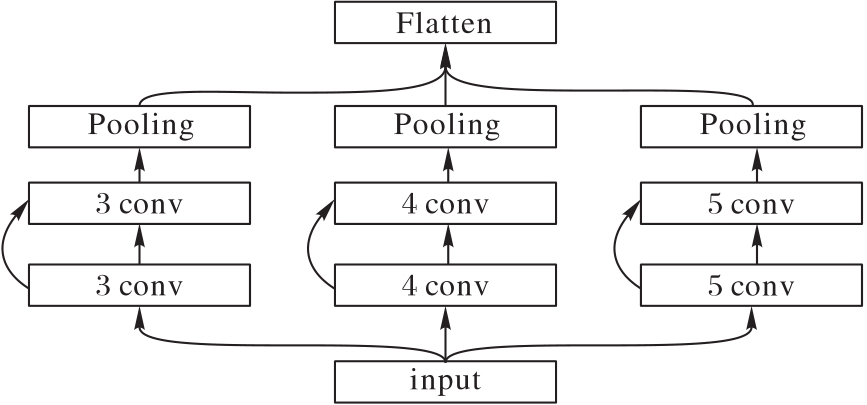
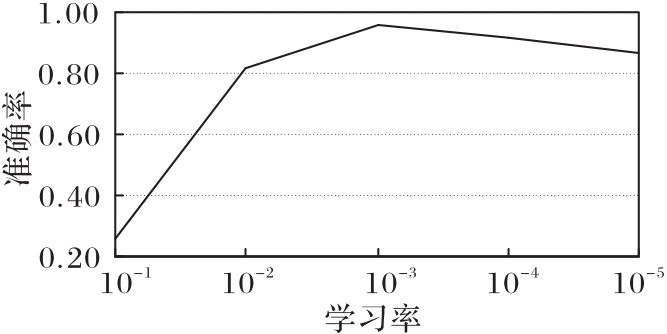
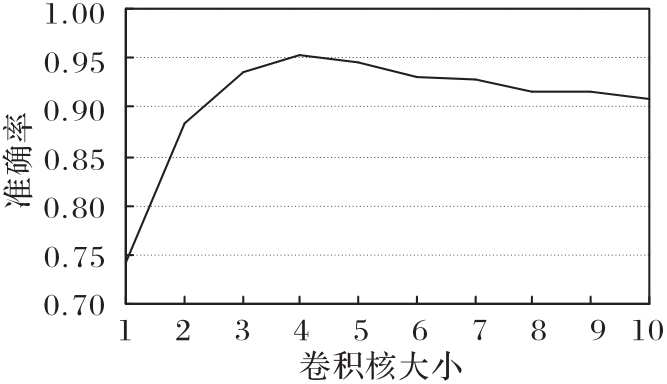
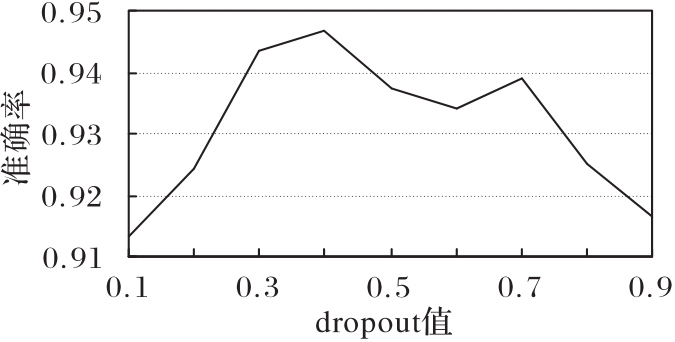
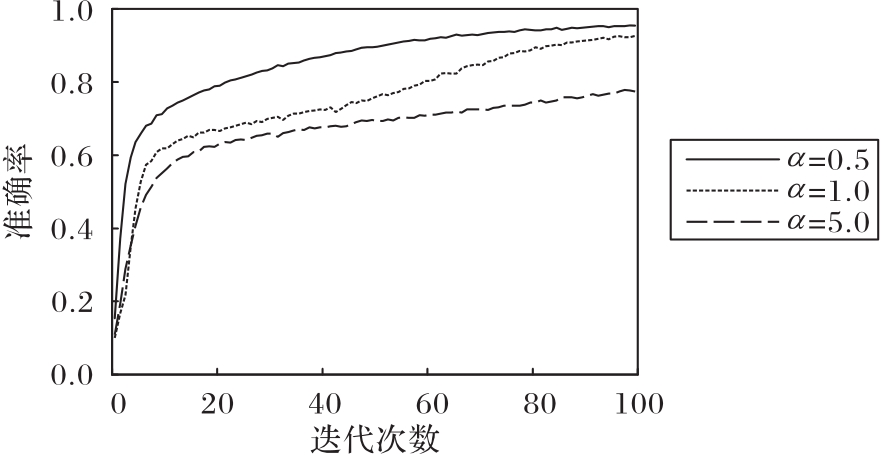
针对院前急救文本专业词汇丰富、特征稀疏和标签混淆程度大等问题,提出一种基于标签混淆模型(LCM)的文本分类模型。首先,利用BERT获得动态词向量并充分挖掘专业词汇的语义信息;然后,通过融合双向长短期记忆(BiLSTM)网络、加权卷积和注意力机制生成文本表示向量,提高模型的特征提取能力;最后,采用LCM获取文本与标签间的语义联系、标签与标签间的依赖关系,从而解决标签混淆程度大的问题。在院前急救文本和公开新闻文本数据集THUCNews上进行实验,所提模型的F1值分别达到了93.46%和97.08%,相较于TextCNN(Text Convolutional Neural Network)、BiLSTM、BiLSTM-Attention等模型分别提升了0.95%~7.01%和0.38%~2.00%。实验结果表明,所提模型能够获取专业词汇的语义信息,更加精准地提取文本特征,并能有效解决标签混淆程度大的问题,同时具有一定的泛化能力。
中图分类号: