


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (9): 2865-2875.DOI: 10.11772/j.issn.1001-9081.2021081386
所属专题: 多媒体计算与计算机仿真
张文涛, 王园宇( ), 李赛泽
), 李赛泽
收稿日期:2021-08-03
修回日期:2021-11-22
接受日期:2021-11-22
发布日期:2022-01-07
出版日期:2022-09-10
通讯作者:
王园宇
作者简介:张文涛(1995—),男,山西忻州人,硕士研究生,CCF会员,主要研究方向:计算机视觉、深度估计;基金资助:
Wentao ZHANG, Yuanyu WANG(), Saize LI
Received:2021-08-03
Revised:2021-11-22
Accepted:2021-11-22
Online:2022-01-07
Published:2022-09-10
Contact:
Yuanyu WANG
About author:ZHANG Wentao, born in 1995, M. S. candidate. His research interests include computer vision, depth estimation.Supported by:摘要:
针对霾环境中图像降质导致的传统深度估计模型退化问题,提出了一种融合双注意力机制的基于条件生成对抗网络(CGAN)的单幅霾图像深度估计模型。首先,对于模型的生成器的网络结构,提出了融合双注意力机制的DenseUnet结构,其中DenseUnet将密集块作为U-net编码和解码过程中的基本模块,并利用密集连接和跳跃连接在加强信息流动的同时,提取直接传输率图的底层结构特征和高级深度信息。然后,通过双注意力模块自适应地调整空间特征和通道特征的全局依赖关系,同时将最小绝对值损失、感知损失、梯度损失和对抗损失融合为新的结构保持损失函数。最后,将霾图像的直接传输率图作为CGAN的条件,通过生成器和鉴别器的对抗学习估计出霾图像的深度图。在室内数据集NYU Depth v2和室外数据集DIODE上进行训练和测试。实验结果表明,该模型具有更精细的几何结构和更丰富的局部细节。在NYU Depth v2上,与全卷积残差网络相比,对数平均误差(LME)和均方根误差(RMSE)分别降低了7%和10%;在DIODE上,与深度有序回归网络相比,精确度(阈值小于1.25)提高了7.6%。可见,所提模型提高了在霾干扰下深度估计的准确性和泛化能力。
中图分类号:
张文涛, 王园宇, 李赛泽. 基于条件对抗网络的单幅霾图像深度估计模型[J]. 计算机应用, 2022, 42(9): 2865-2875.
Wentao ZHANG, Yuanyu WANG, Saize LI. Depth estimation model of single haze image based on conditional generative adversarial network[J]. Journal of Computer Applications, 2022, 42(9): 2865-2875.
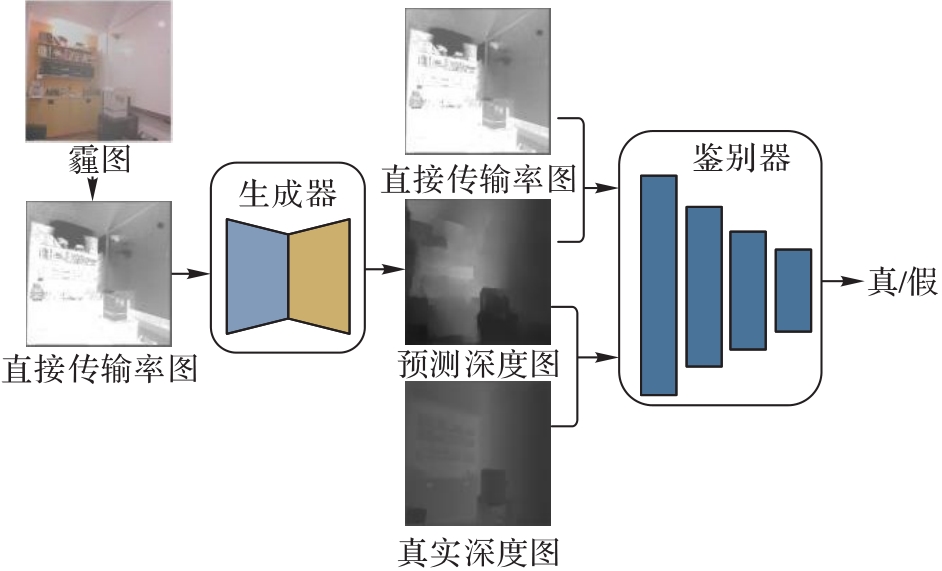
图1 条件生成对抗网络结构
Fig. 1 Structure of CGAN
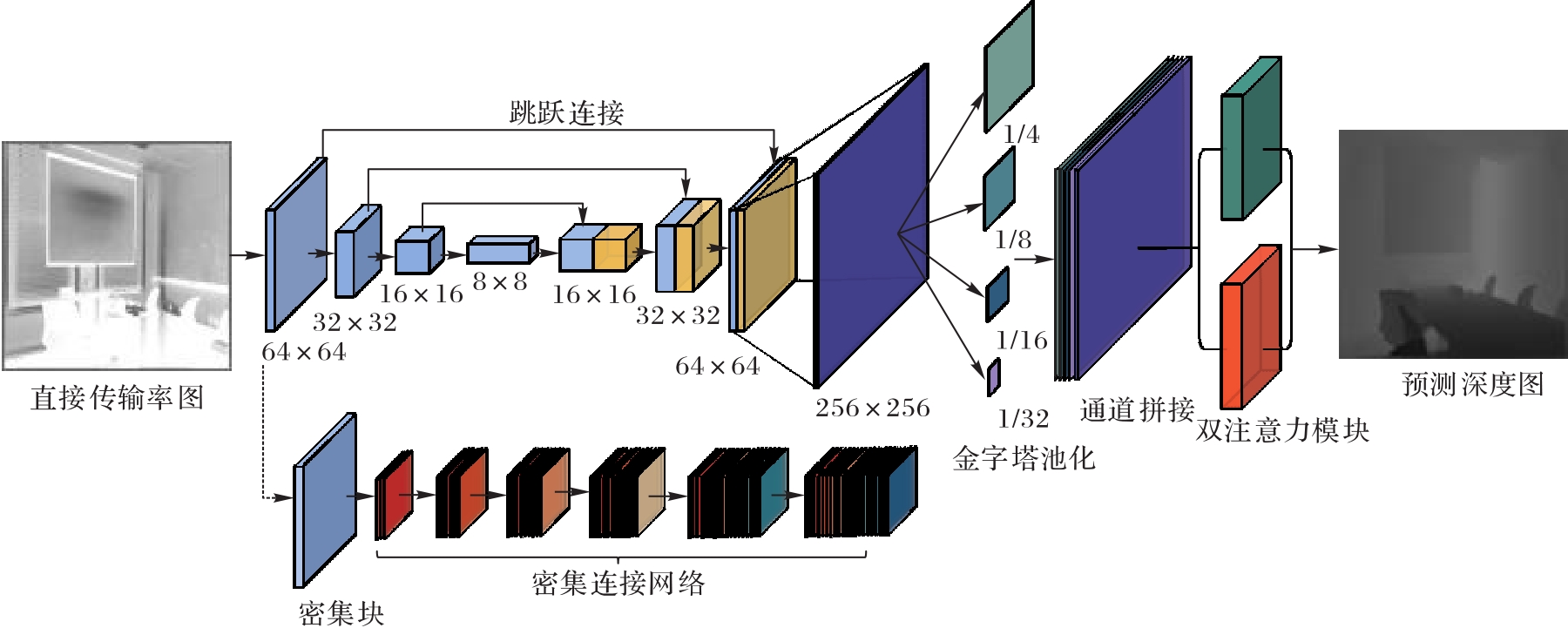
图2 生成器的网络结构
Fig. 2 Network structure of generator
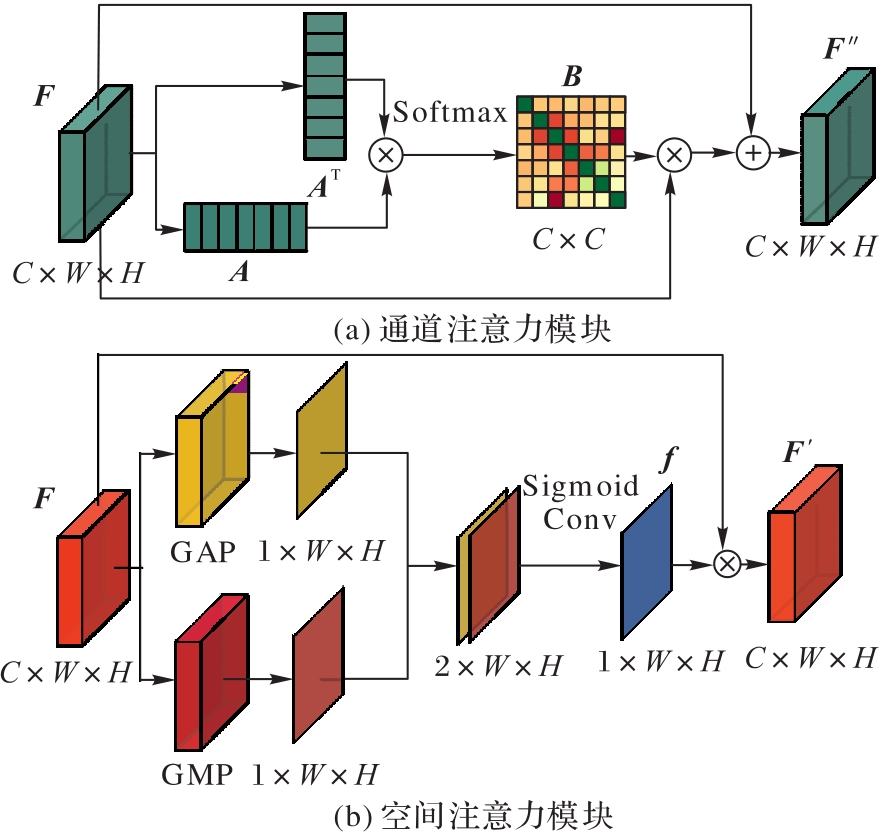
图3 双注意力模块
Fig. 3 Dual attention module
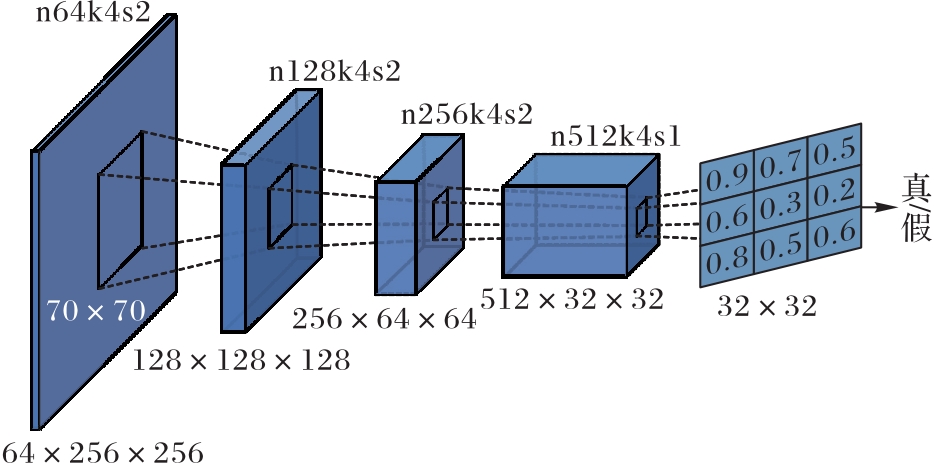
图4 鉴别器的网络结构
Fig. 4 Network structure of discriminator

图5 梯度可视化
Fig. 5 Gradient visualization
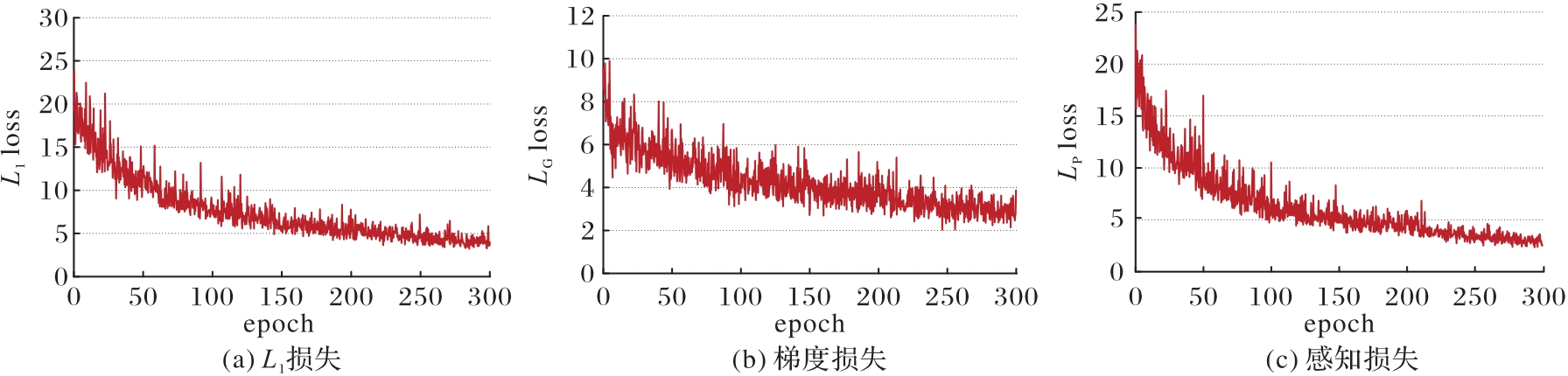
图6 NYU v2 数据集上损失函数的收敛情况
Fig. 6 Convergence of loss function on NYU v2 dataset

图7 NYU v2数据集上损失函数的对比结果
Fig. 7 Comparison results of loss functions on NYU v2 dataset

图8 NYU v2数据集上有无双注意力模块结果对比
Fig. 8 Comparison of results with and without dual attention modules on NYU v2 dataset

图9 NYU v2数据集上的实验结果对比
Fig. 9 Comparison of experimental results on NYU v2 dataset
| 方法 | MRE | LME | RMSE | 精确度 | |||
|---|---|---|---|---|---|---|---|
| 文献[ | 0.215 | — | 0.907 | 0.611 | 0.887 | 0.971 | |
| 文献[ | 0.127 | 0.055 | 0.573 | 0.811 | 0.953 | 0.988 | |
| 文献[ | 0.232 | 0.094 | 0.821 | 0.621 | 0.886 | 0.968 | |
| 本文方法 | 0.421 | 0.093 | 0.725 | 0.596 | 0.853 | 0.944 | |
| 0.212 | 0.063 | 0.567 | 0.768 | 0.860 | 0.958 | ||
| 0.207 | 0.060 | 0.572 | 0.793 | 0.863 | 0.951 | ||
| 无双注意力模块( | 0.151 | 0.056 | 0.571 | 0.836 | 0.959 | 0.987 | |
| 有双注意力模块( | 0.146 | 0.051 | 0.514 | 0.843 | 0.963 | 0.991 | |
表1 NYU v2数据集上的评价指标对比
Tab. 1 Comparison of evaluation metrics on NYU v2 dataset
| 方法 | MRE | LME | RMSE | 精确度 | |||
|---|---|---|---|---|---|---|---|
| 文献[ | 0.215 | — | 0.907 | 0.611 | 0.887 | 0.971 | |
| 文献[ | 0.127 | 0.055 | 0.573 | 0.811 | 0.953 | 0.988 | |
| 文献[ | 0.232 | 0.094 | 0.821 | 0.621 | 0.886 | 0.968 | |
| 本文方法 | 0.421 | 0.093 | 0.725 | 0.596 | 0.853 | 0.944 | |
| 0.212 | 0.063 | 0.567 | 0.768 | 0.860 | 0.958 | ||
| 0.207 | 0.060 | 0.572 | 0.793 | 0.863 | 0.951 | ||
| 无双注意力模块( | 0.151 | 0.056 | 0.571 | 0.836 | 0.959 | 0.987 | |
| 有双注意力模块( | 0.146 | 0.051 | 0.514 | 0.843 | 0.963 | 0.991 | |
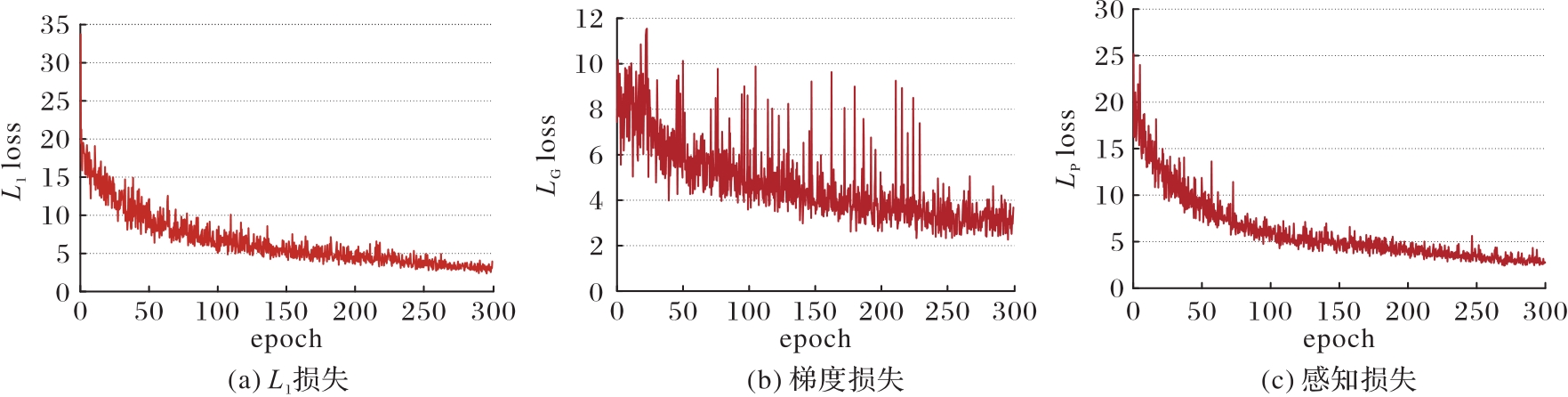
图10 DIODE数据集上损失函数的收敛情况
Fig. 10 Convergence of loss function on DIODE dataset

图11 DIODE数据集上损失函数的对比结果
Fig. 11 Comparison results of loss functions on DIODE dataset

图12 DIODE数据集上有无双注意力模块结果的对比
Fig. 12 Comparison of results with and without dual attention modules on DIODE dataset

图13 DIODE数据集上的实验结果对比
Fig. 13 Experimental results comparison on DIODE dataset
| 方法 | MRE | RMSE | RMSElog | 精确度 | |||
|---|---|---|---|---|---|---|---|
| 文献[ | 0.161 | 4.152 | 0.175 | 0.793 | 0.894 | 0.972 | |
| 文献[ | 0.237 | 6.523 | 0.281 | 0.648 | 0.867 | 0.967 | |
| 文献[ | 0.225 | 5.342 | 0.216 | 0.627 | 0.835 | 0.959 | |
| 本文方法 | 0.352 | 8.869 | 0.352 | 0.601 | 0.796 | 0.925 | |
| 0.235 | 6.876 | 0.287 | 0.753 | 0.873 | 0.964 | ||
| 0.212 | 6.491 | 0.275 | 0.748 | 0.865 | 0.962 | ||
| 无双注意力模块( | 0.162 | 5.351 | 0.259 | 0.837 | 0.893 | 0.970 | |
| 有双注意力模块( | 0.159 | 4.344 | 0.207 | 0.853 | 0.917 | 0.989 | |
表2 DIODE数据集上的评价指标对比
Tab. 2 Evaluation metrics comparison on DIODE dataset
| 方法 | MRE | RMSE | RMSElog | 精确度 | |||
|---|---|---|---|---|---|---|---|
| 文献[ | 0.161 | 4.152 | 0.175 | 0.793 | 0.894 | 0.972 | |
| 文献[ | 0.237 | 6.523 | 0.281 | 0.648 | 0.867 | 0.967 | |
| 文献[ | 0.225 | 5.342 | 0.216 | 0.627 | 0.835 | 0.959 | |
| 本文方法 | 0.352 | 8.869 | 0.352 | 0.601 | 0.796 | 0.925 | |
| 0.235 | 6.876 | 0.287 | 0.753 | 0.873 | 0.964 | ||
| 0.212 | 6.491 | 0.275 | 0.748 | 0.865 | 0.962 | ||
| 无双注意力模块( | 0.162 | 5.351 | 0.259 | 0.837 | 0.893 | 0.970 | |
| 有双注意力模块( | 0.159 | 4.344 | 0.207 | 0.853 | 0.917 | 0.989 | |

图14 真实霾图的实验结果对比
Fig. 14 Comparison of experimental results of real haze images
| 1 | HU G, HUANG S D, ZHAO L, et al. A robust RGB-D SLAM algorithm[C]// Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2012: 1714-1719. 10.1109/iros.2012.6386103 |
| 2 | SHOTTON J, GIRSHICK R, FITZGIBBON A, et al. Efficient human pose estimation from single depth images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2821-2840. 10.1109/tpami.2012.241 |
| 3 | LI Q, ZHU J S, LIU J, et al. 3D map-guided single indoor image localization refinement[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 161: 13-26. 10.1016/j.isprsjprs.2020.01.008 |
| 4 | SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from RGBD images[C]// Proceedings of the 2012 European Conference on Computer Vision, LNCS 7576. Berlin: Springer, 2012: 746-760. |
| 5 | YONEDA K, TEHRANI H, OGAWA T, et al. Lidar scan feature for localization with highly precise 3-D map[C]// Proceedings of the 2014 IEEE Intelligent Vehicles Symposium. Piscataway: IEEE, 2014: 1345-1350. 10.1109/ivs.2014.6856596 |
| 6 | ZOU L, LI Y. A method of stereo vision matching based on OpenCV[C]// Proceedings of the 2010 International Conference on Audio, Language and Image Processing. Piscataway: IEEE, 2010: 185-190. 10.1109/icalip.2010.5684978 |
| 7 | EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2366-2374. |
| 8 | LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]// Proceedings of the 4th International Conference on 3D Vision. Piscataway: IEEE, 2016: 239-248. 10.1109/3dv.2016.32 |
| 9 | LI B, SHEN C H, DAI Y C, et al. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1119-1127. 10.1109/cvpr.2015.7298715 |
| 10 | FU H, GONG M M, WANG C H, et al. Deep ordinal regression network for monocular depth estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2002-2011. 10.1109/cvpr.2018.00214 |
| 11 | LORE K G, REDDY K, GIERING M, et al. Generative adversarial networks for depth map estimation from RGB video[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2018: 1258-1266. 10.1109/cvprw.2018.00163 |
| 12 | LIU F Y, SHEN C H, LIN G S, et al. Learning depth from single monocular images using deep convolutional neural fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2024-2039. 10.1109/tpami.2015.2505283 |
| 13 | ISOLA P, ZHU J Y, ZHOU T H, et al. Image-to-image translation with conditional adversarial networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5967-5976. 10.1109/cvpr.2017.632 |
| 14 | NARASIMHAN S G, NAYAR S K. Contrast restoration of weather degraded images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(6): 713-724. 10.1109/tpami.2003.1201821 |
| 15 | CHEN X T, WANG Y W, CHEN X J, et al. S2R-DepthNet: learning a generalizable depth-specific structural representation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3033-3042. 10.1109/cvpr46437.2021.00305 |
| 16 | HUANGG, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. 10.1109/cvpr.2017.243 |
| 17 | RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| 18 | ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. 10.1109/cvpr.2017.660 |
| 19 | ZHANG H, GOODFELLOW I, METAXAS D, et al. Self-attention generative adversarial networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 7354-7363. |
| 20 | FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3141-3149. 10.1109/cvpr.2019.00326 |
| 21 | WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7794-7803. 10.1109/cvpr.2018.00813 |
| 22 | PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2536-2544. 10.1109/cvpr.2016.278 |
| 23 | JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 694-711. |
| 24 | LI J, KLEIN R, YAO A. A two-streamed network for estimating fine-scaled depth maps from single RGB images[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3392-3400. 10.1109/iccv.2017.365 |
| 25 | MA C, RAO Y M, CHENG Y A, et al. Structure-preserving super resolution with gradient guidance[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 7766-7775. 10.1109/cvpr42600.2020.00779 |
| 26 | VASILJEVIC I, KOLKIN N, ZHANG S Y, et al. DIODE: a Dense Indoor and Outdoor DEpth dataset[DS/OL]. [2021-04-15].. |
| 27 | HE K M, SUN J, TANG X O. Single image haze removal using dark channel prior[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(12): 2341-2353. 10.1109/tpami.2010.168 |
| 28 | KIM S E, PARK T H, EOM I K. Fast single image dehazing using saturation based transmission map estimation[J]. IEEE Transactions on Image Processing, 2020, 29: 1985-1998. 10.1109/tip.2019.2948279 |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [3] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [9] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [10] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [11] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [12] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [13] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| [14] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [15] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||