


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (9): 2828-2835.DOI: 10.11772/j.issn.1001-9081.2022081177
尚绍法1, 蒋林1( ), 李远成1, 朱筠2
), 李远成1, 朱筠2
收稿日期:2022-08-10
修回日期:2022-12-01
接受日期:2022-12-08
发布日期:2023-01-18
出版日期:2023-09-10
通讯作者:
蒋林
作者简介:尚绍法(1998—),男,陕西渭南人,硕士研究生,主要研究方向:编译优化、深度学习基金资助:
Shaofa SHANG1, Lin JIANG1(), Yuancheng LI1, Yun ZHU2
Received:2022-08-10
Revised:2022-12-01
Accepted:2022-12-08
Online:2023-01-18
Published:2023-09-10
Contact:
Lin JIANG
About author:SHANG Shaofa, born in 1998, M. S. candidate. His research interests include compiling optimization, deep learning.Supported by:摘要:
针对卷积神经网络(CNN)在异构平台执行推理时存在硬件资源利用率低、延迟高等问题,提出一种CNN推理模型自适应划分和调度方法。首先,通过遍历计算图提取CNN的关键算子完成模型的自适应划分,增强调度策略灵活性;然后,基于性能实测与关键路径-贪婪搜索算法,在CPU-GPU异构平台上根据子模型运行特征选取最优运行负载,提高子模型推理速度;最后利用张量虚拟机(TVM)中跨设备调度机制,配置子模型的依赖关系与运行负载,实现模型推理的自适应调度,降低设备间通信延迟。实验结果表明,与TVM算子优化方法在GPU和CPU上的推理速度相比,所提方法在模型推理准确度无损前提下,推理速度提升了5.88%~19.05%和45.45%~311.46%。
中图分类号:
尚绍法, 蒋林, 李远成, 朱筠. 异构平台下卷积神经网络推理模型自适应划分和调度方法[J]. 计算机应用, 2023, 43(9): 2828-2835.
Shaofa SHANG, Lin JIANG, Yuancheng LI, Yun ZHU. Adaptive partitioning and scheduling method of convolutional neural network inference model on heterogeneous platforms[J]. Journal of Computer Applications, 2023, 43(9): 2828-2835.
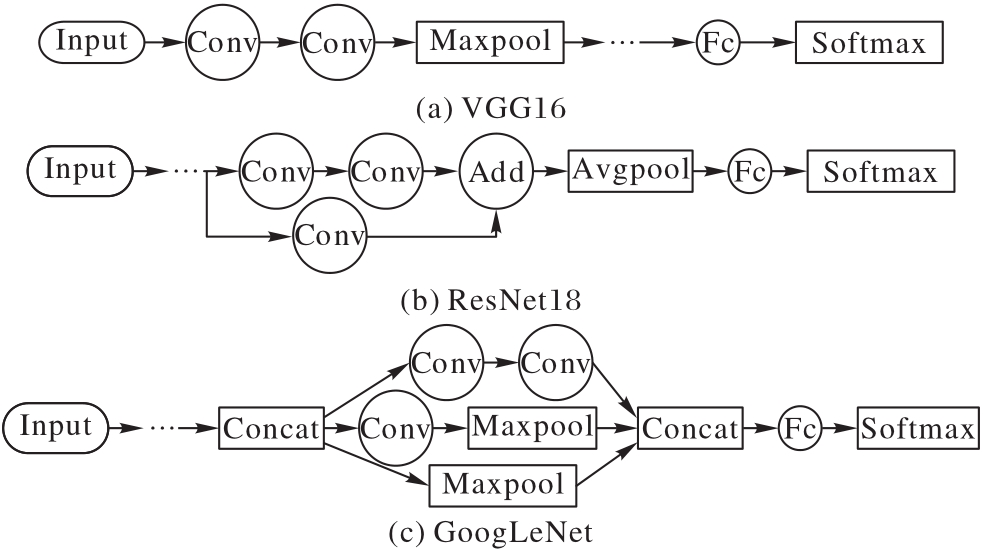
图1 三种典型CNN模型结构
Fig. 1 Structures of three typical CNN models
| 模型 | 主要组成 |
|---|---|
| VGG16 | 5×Conv_Block+3×Fc |
| ResNet18 | 1×Conv_Block+4×Residual_Block(含19×Conv_Block)+1×Fc |
| GoogLeNet | 3×Conv_Block+9×Inception_Block(含64×Conv_Block)+1×Fc |
表1 三类CNN模型的组成结构
Tab.1 Composition structures of three CNN models
| 模型 | 主要组成 |
|---|---|
| VGG16 | 5×Conv_Block+3×Fc |
| ResNet18 | 1×Conv_Block+4×Residual_Block(含19×Conv_Block)+1×Fc |
| GoogLeNet | 3×Conv_Block+9×Inception_Block(含64×Conv_Block)+1×Fc |
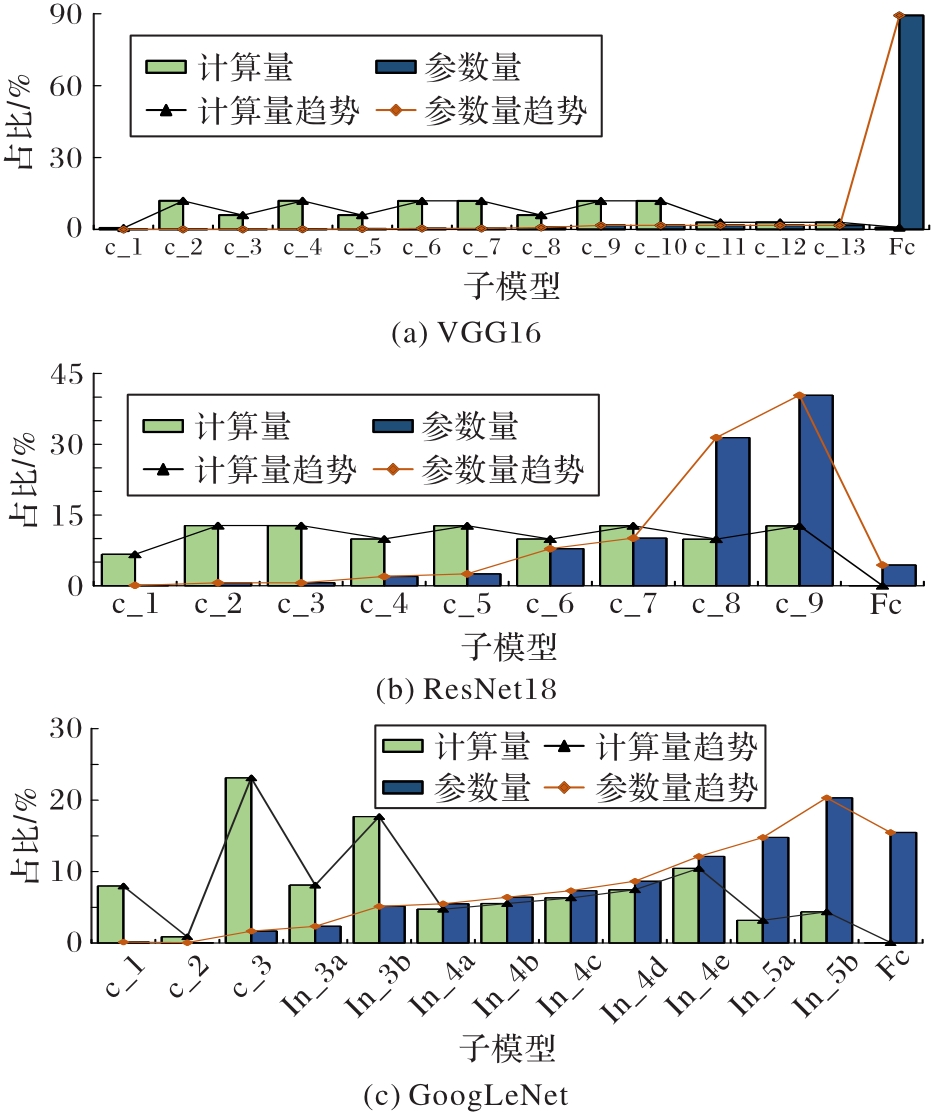
图2 三种CNN模型计算量和参数量分布
Fig. 2 Distribution of computational amount and parameters of three CNN models
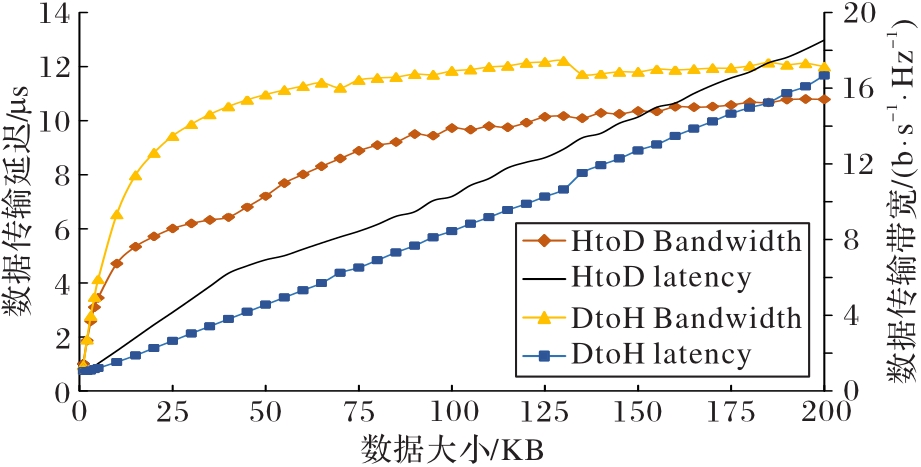
图3 CPU与GPU间的通信消耗
Fig. 3 Consumption of communication between CPU and GPU
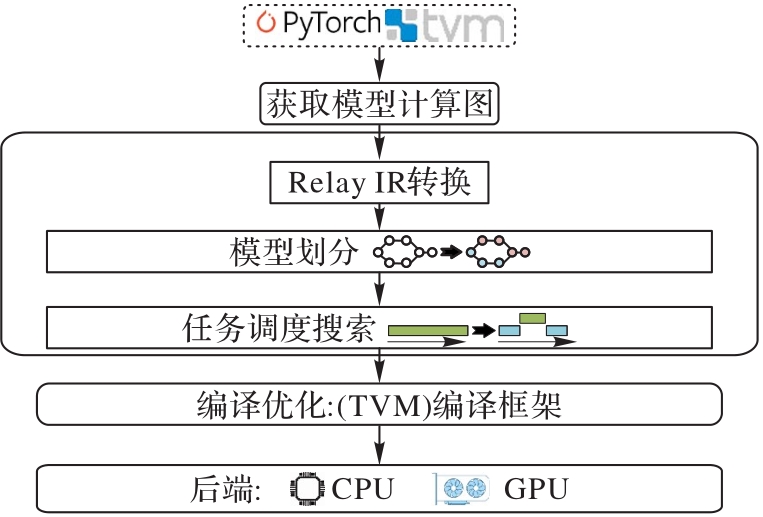
图4 本文方法的总体流程
Fig. 4 Overall flow of the proposed method

图5 两种模型划分方法效果对比
Fig. 5 Comparison between two model partitioning methods
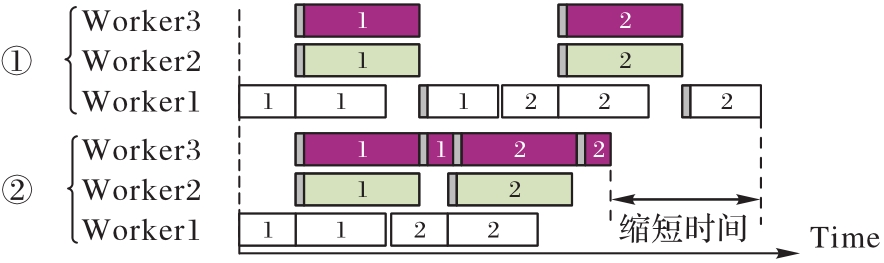
图6 两种模型划分方法的调度效果对比
Fig. 6 Comparison of scheduling effect between two model partitioning methods
| 模块 | CPU | GPU |
|---|---|---|
| C_1 | 1.08 | 0.35 |
| C_2 | 7.62 | 0.75 |
| C_3 | 5.46 | 1.56 |
| C_4 | 2.19 | 1.85 |
| C_5 | 0.84 | 0.96 |
| FC | 0.46 | 3.75 |
表2 VGG16子模型在不同设备上的执行时间对比 (ms)
Tab. 2 Comparison of execution time of VGG16 submodels on different devices
| 模块 | CPU | GPU |
|---|---|---|
| C_1 | 1.08 | 0.35 |
| C_2 | 7.62 | 0.75 |
| C_3 | 5.46 | 1.56 |
| C_4 | 2.19 | 1.85 |
| C_5 | 0.84 | 0.96 |
| FC | 0.46 | 3.75 |
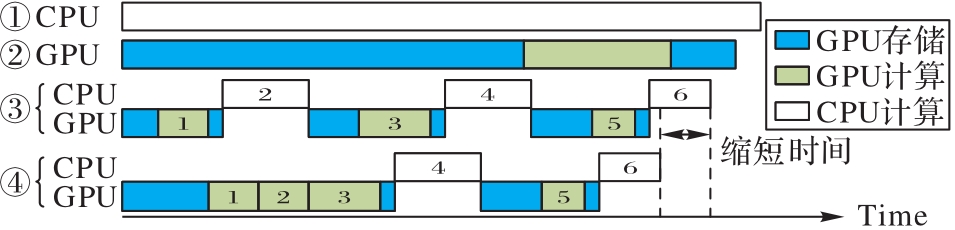
图7 异构平台的调度策略
Fig. 7 Scheduling strategies for heterogeneous platforms
| 标签 | 描述 | |
|---|---|---|
| CPU | 型号 | 2×Intel Xeon Gold 6248R |
| 物理核心数 | 48 | |
| 线程数 | 96 | |
| L3缓存 | 35.75 MB | |
| 内存容量 | 256 GB DDR4 | |
| 内存频率 | 3 200 MHz | |
| GPU | 型号 | 1*Nvidia Quadro P2200 |
| 核心数 | 1280 CUDA 并行运算处理核心 | |
| 显存容量 | 5 GB DDR5x | |
| 单精度运算性能 | 最高3.8 TFLOPs | |
| 系统环境 | Ubuntu18.04 | |
| 系统内核 | 5.40-96-generic | |
| 深度学习框架 | PyTorch3.6 | |
| 深度学习编译器 | TVM9.0 | |
表3 测试平台配置信息
Tab. 3 Experimental platform configuration information
| 标签 | 描述 | |
|---|---|---|
| CPU | 型号 | 2×Intel Xeon Gold 6248R |
| 物理核心数 | 48 | |
| 线程数 | 96 | |
| L3缓存 | 35.75 MB | |
| 内存容量 | 256 GB DDR4 | |
| 内存频率 | 3 200 MHz | |
| GPU | 型号 | 1*Nvidia Quadro P2200 |
| 核心数 | 1280 CUDA 并行运算处理核心 | |
| 显存容量 | 5 GB DDR5x | |
| 单精度运算性能 | 最高3.8 TFLOPs | |
| 系统环境 | Ubuntu18.04 | |
| 系统内核 | 5.40-96-generic | |
| 深度学习框架 | PyTorch3.6 | |
| 深度学习编译器 | TVM9.0 | |
| 模型 | 卷积层 | 分类层 | ||
|---|---|---|---|---|
| 计算量/FLOPs | 参数量/MB | 计算量/FLOPs | 参数量/MB | |
| VGG11 | 7.506 | 9.220 | 0.124 | 123.643 |
| AlexNet | 0.657 | 2.470 | 0.059 | 58.631 |
| MobileNet | 0.319 | 2.224 | 0.001 | 1.281 |
| SqueezeNet | 0.269 | 0.722 | 0.513 | 0.087 |
| ResNet18 | 1.821 | 11.177 | 0.001 | 0.513 |
| GoogLeNet | 1.507 | 5.600 | 0.001 | 1.025 |
表4 不同模型的卷积层、分类层的计算量与参数量
Tab. 4 Computational amount and parameters of convolutional and classification layers of different models
| 模型 | 卷积层 | 分类层 | ||
|---|---|---|---|---|
| 计算量/FLOPs | 参数量/MB | 计算量/FLOPs | 参数量/MB | |
| VGG11 | 7.506 | 9.220 | 0.124 | 123.643 |
| AlexNet | 0.657 | 2.470 | 0.059 | 58.631 |
| MobileNet | 0.319 | 2.224 | 0.001 | 1.281 |
| SqueezeNet | 0.269 | 0.722 | 0.513 | 0.087 |
| ResNet18 | 1.821 | 11.177 | 0.001 | 0.513 |
| GoogLeNet | 1.507 | 5.600 | 0.001 | 1.025 |
| 模型 | 层数 | 划分结果 | 设备分配结果 | |
|---|---|---|---|---|
| CPU | GPU | |||
| AlexNet | 32 | 0-3,4-7,8-17,18-31 | 0-3,18-31 | 4-7,8-17 |
| VGG11 | 43 | 0-3,4-7,8-14,15-21,22-28,29-42 | 0-3,29-42 | 4-7,8-14,15-21,22-28 |
| ResNet18 | 72 | 0-3,4-10,11-17,18-26,27-33,34-42, 43-50,51-59,60-66,67-71 | 67-71 | 0-3,4-10,11-17,18-26,27-33, 34-42,43-50,51-59,60-66 |
表5 CNN模型划分与设备分配
Tab. 5 Partitioning and device assignment of CNN models
| 模型 | 层数 | 划分结果 | 设备分配结果 | |
|---|---|---|---|---|
| CPU | GPU | |||
| AlexNet | 32 | 0-3,4-7,8-17,18-31 | 0-3,18-31 | 4-7,8-17 |
| VGG11 | 43 | 0-3,4-7,8-14,15-21,22-28,29-42 | 0-3,29-42 | 4-7,8-14,15-21,22-28 |
| ResNet18 | 72 | 0-3,4-10,11-17,18-26,27-33,34-42, 43-50,51-59,60-66,67-71 | 67-71 | 0-3,4-10,11-17,18-26,27-33, 34-42,43-50,51-59,60-66 |
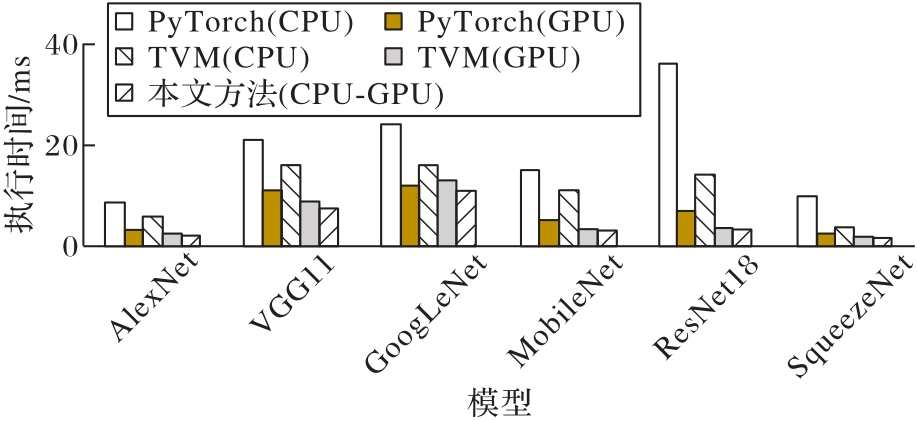
图8 不同模型执行时间对比
Fig. 8 Comparison of execution time of different models
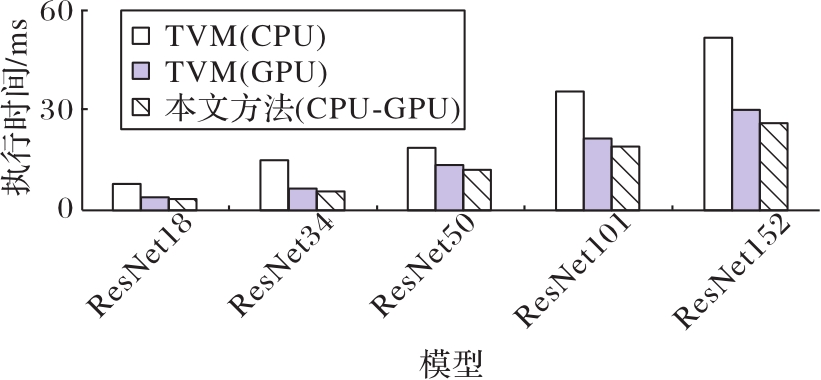
图9 不同深度的CNN模型推理执行时间对比
Fig. 9 Comparison of inference execution time of CNN models with different depths
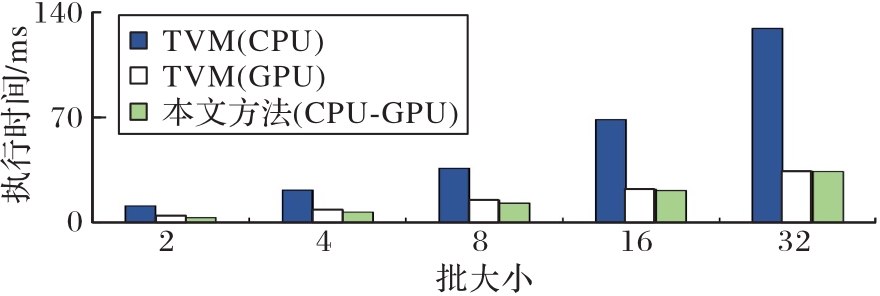
图10 不同批大小下CNN模型的推理执行时间延迟对比结果
Fig. 10 Comparison of CNN models inference excution time with different batch sizes
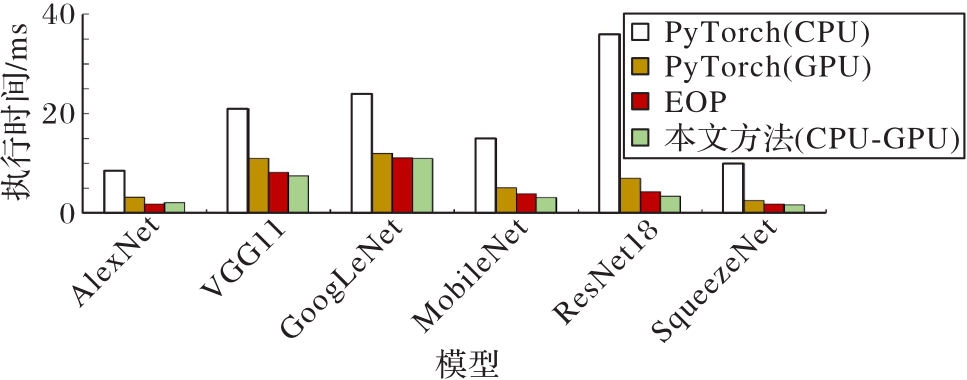
图11 本文方法与EOP方法的推理执行时间对比
Fig. 11 Comparison of inference execution time between proposed method and EOP method
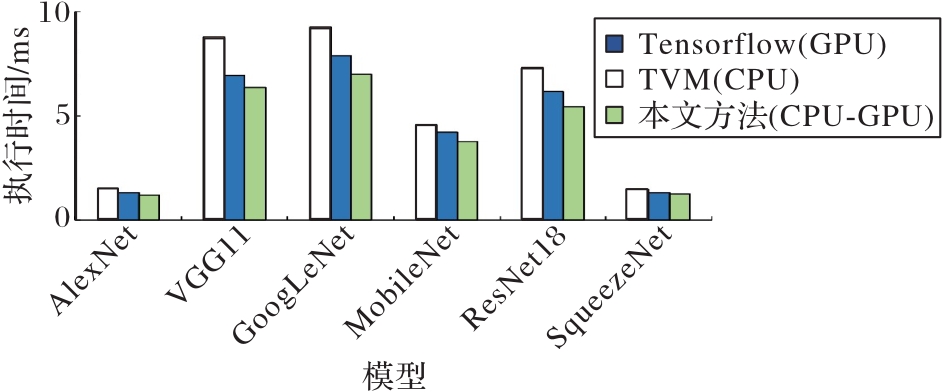
图12 本文方法与Tensorflow框架的推理执行时间对比
Fig. 12 Comparison of inference execution time between proposed method and Tensorflow method
| 1 | ZENG Q S, DU Y Q, HUANG K B, et al. Energy-efficient resource management for federated edge learning with CPU-GPU heterogeneous computing[J]. IEEE Transactions on Wireless Communications, 2021, 20(12): 7947-7962. 10.1109/twc.2021.3088910 |
| 2 | 郭棉,张锦友. 移动边缘计算环境中面向机器学习的计算迁移策略[J]. 计算机应用, 2021, 41(9): 2639-2645. 10.11772/j.issn.1001-9081.2020111734 |
| GUO M, ZHANG J Y. Computation offloading policy for machine learning in mobile edge computing environments[J]. Journal of Computer Applications, 2021, 41(9): 2639-2645. 10.11772/j.issn.1001-9081.2020111734 | |
| 3 | LI M Z, LIU Y, LIU X Y, et al. The deep learning compiler: a comprehensive survey[J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32(3): 708-727. 10.1109/tpds.2020.3030548 |
| 4 | 宋冰冰,张浩,吴子锋,等. 自动化张量分解加速卷积神经网络[J]. 软件学报, 2021, 32(11):3468-3481. |
| SONG B B, ZHANG H, WU Z F, et al. Automated tensor decomposition to accelerate convolutional neural networks[J]. Journal of Software, 2021, 32(11): 3468-3481. | |
| 5 | HOU X Y, GUAN Y J, HAN T, et al. DistrEdge: speeding up convolutional neural network inference on distributed edge devices[C]// Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium. Piscataway: IEEE, 2022: 1097-1107. 10.1109/ipdps53621.2022.00110 |
| 6 | TANAKA M, TAURA K, HANAWA T, et al. Automatic graph partitioning for very large-scale deep learning[C]// Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium. Piscataway: IEEE, 2021: 1004-1013. 10.1109/ipdps49936.2021.00109 |
| 7 | XU Y J, WU H, ZHANG W B, et al. EOP: efficient operator partition for deep learning inference over edge servers[C]// Proceedings of the 18th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments. New York: ACM, 2022: 45-57. 10.1145/3516807.3516820 |
| 8 | 邝祝芳,陈清林,李林峰,等. 基于深度强化学习的多用户边缘计算任务卸载调度与资源分配算法[J]. 计算机学报, 2022, 45(4):812-824. 10.11897/SP.J.1016.2022.00812 |
| KUANG Z F, CHEN Q L, LI L F, et al. Multi-user edge computing task offloading scheduling and resource allocation based on deep reinforcement learning[J]. Chinese Journal of Computers, 2022, 45(4): 812-824. 10.11897/SP.J.1016.2022.00812 | |
| 9 | PARK J H, YUN G, YI C M, et al. HetPipe: enabling large DNN training on (whimpy) heterogeneous GPU clusters through integration of pipelined model parallelism and data parallelism[C]// Proceedings of the 2020 USENIX Annual Technical Conference. Berkeley: USENIX Association, 2020: 307-321. 10.48550/arXiv.2005.14038 |
| 10 | WANG S Q, ANANTHANARAYANAN G, ZENG Y F, et al. High-throughput CNN inference on embedded ARM big.LITTLE multicore processors[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(10): 2254-2267. 10.1109/tcad.2019.2944584 |
| 11 | BEAUMONT O, EYRAUD-DUBOIS L, SHILOVA A. MadPipe: memory aware dynamic programming algorithm for pipelined model parallelism[C]// Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium Workshops. Piscataway: IEEE, 2022: 1063-1073. 10.1109/ipdpsw55747.2022.00174 |
| 12 | LU J M, FANG C, XU M Y, et al. Evaluations on deep neural networks training using posit number system[J]. IEEE Transactions on Computers, 2021, 70(2): 174-187. 10.1109/tc.2020.2985971 |
| 13 | CHEN T Q, MOREAU T, JIANG Z H, et al. TVM: an automated end-to-end optimizing compiler for deep learning[C]// Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation. Berkeley: USENIX Association, 2018: 579-594. |
| 14 | 赵旭,黄光球,江晋,等. 基于深度强化学习的资源受限条件下的DIDS任务调度优化方法[J]. 控制与决策, 2022, 37(11): 3052-3057. |
| ZHAO X, HUANG G Q, JIANG J, et al. An optimization method for DIDS task scheduling under resource-constrained conditions based on deep reinforcement learning[J]. Control and Decision, 2022, 37(11): 3052-3057. | |
| 15 | TARNAWSKI J M, PHANISHAYEE A, DEVANUR N, et al. Efficient algorithms for device placement of DNN graph operators[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 15451-15463. |
| 16 | NARAYANAN D, PHANISHAYEE A, SHI K Y, et al. Memory-efficient pipeline-parallel DNN training[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 7937-7947. |
| 17 | SHEN H C, ROESCH J, CHEN Z, et al. Nimble: efficiently compiling dynamic neural networks for model inference[C/OL]// Proceedings of the 4th Conference on Machine Learning and Systems [2022-11-12].. |
| 18 | 刘瑞奇,李博扬,高玉金,等. 新型分布式计算系统中的异构任务调度框架[J]. 软件学报, 2022, 33(3):1005-1017. |
| LIU R Q, LI B Y, GAO Y J, et al. Heterogeneous task scheduling framework in emerging distributed computing systems[J]. Journal of Software, 2022, 33(3): 1005-1017. | |
| 19 | YIN J, HAN J, ZHANG X D. An optimization toolchain design of deep learning deployment based on heterogeneous computing platform[C]// Proceedings of the 2020 International Conference on Wireless Communications and Signal Processing. Piscataway: IEEE, 2020: 631-635. 10.1109/wcsp49889.2020.9299844 |
| 20 | YU F X, BRAY S, WANG D, et al. Automated runtime-aware scheduling for multi-tenant DNN inference on GPU[C]// Proceedings of the 2021 IEEE/ACM International Conference on Computer Aided Design. Piscataway: IEEE, 2021: 1-9. 10.1109/iccad51958.2021.9643501 |
| 21 | HU C, LI B. Distributed inference with deep learning models across heterogeneous edge devices[C]// Proceedings of the 2022 IEEE Conference on Computer Communications. Piscataway: IEEE, 2022: 330-339. 10.1109/infocom48880.2022.9796896 |
| 22 | HEMMAT M, DAVOODI A, HU Y H. Edge n AI: distributed inference with local edge devices and minimal latency[C]// Proceedings of the 27th Asia and South Pacific Design Automation Conference. Piscataway: IEEE, 2022: 544-549. 10.1109/asp-dac52403.2022.9712496 |
| 23 | LI Q, HUANG L, TONG Z, et al. DISSEC: a distributed deep neural network inference scheduling strategy for edge clusters[J]. Neurocomputing, 2022, 500: 449-460. 10.1016/j.neucom.2022.05.084 |
| 24 | JIA Z H, LIN S N, QI C R, et al. Exploring hidden dimensions in parallelizing convolutional neural networks[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 2274-2283. |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 王娜, 蒋林, 李远成, 朱筠. 基于图形重写和融合探索的张量虚拟机算符融合优化[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2802-2809. |
| [3] | 李云, 王富铕, 井佩光, 王粟, 肖澳. 基于不确定度感知的帧关联短视频事件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2903-2910. |
| [4] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [5] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| [6] | 陈虹, 齐兵, 金海波, 武聪, 张立昂. 融合1D-CNN与BiGRU的类不平衡流量异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2493-2499. |
| [7] | 王东炜, 刘柏辰, 韩志, 王艳美, 唐延东. 基于低秩分解和向量量化的深度网络压缩方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1987-1994. |
| [8] | 高阳峄, 雷涛, 杜晓刚, 李岁永, 王营博, 闵重丹. 基于像素距离图和四维动态卷积网络的密集人群计数与定位方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2233-2242. |
| [9] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [10] | 姚梓豪, 栗远明, 马自强, 李扬, 魏良根. 基于机器学习的多目标缓存侧信道攻击检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1862-1871. |
| [11] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [12] | 李健京, 李贯峰, 秦飞舟, 李卫军. 基于不确定知识图谱嵌入的多关系近似推理模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1751-1759. |
| [13] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| [14] | 孙敏, 成倩, 丁希宁. 基于CBAM-CGRU-SVM的Android恶意软件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1539-1545. |
| [15] | 席治远, 唐超, 童安炀, 王文剑. 基于双路时空网络的驾驶员行为识别[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1511-1519. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||