


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (10): 3077-3085.DOI: 10.11772/j.issn.1001-9081.2022091438
所属专题: 人工智能
虞资兴1, 瞿绍军1( ), 何鑫2, 王卓1
), 何鑫2, 王卓1
收稿日期:2022-09-29
修回日期:2022-12-06
接受日期:2022-12-12
发布日期:2023-03-23
出版日期:2023-10-10
通讯作者:
瞿绍军
作者简介:虞资兴(1997—),男,湖南株洲人,硕士研究生,CCF会员,主要研究方向:计算机视觉、深度学习基金资助:
Zixing YU1, Shaojun QU1(), Xin HE2, Zhuo WANG1
Received:2022-09-29
Revised:2022-12-06
Accepted:2022-12-12
Online:2023-03-23
Published:2023-10-10
Contact:
Shaojun QU
About author:YU Zixing, born in 1997, M. S. candidate. His research interests include computer vision, deep learning.Supported by:摘要:
多数语义分割网络利用双线性插值将高级特征图的分辨率恢复至与低级特征图一样的分辨率再进行融合操作,导致部分高级语义信息在空间上无法与低级特征图对齐,进而造成语义信息的丢失。针对以上问题,改进双边分割网络(BiSeNet),并基于此提出一种高低维特征引导的实时语义分割网络(HLFGNet)。首先,提出高低维特征引导模块(HLFGM)来通过低级特征图的空间位置信息引导高级语义信息在上采样过程中的位移;同时,利用高级特征图来获取强特征表达,并结合注意力机制来消除低级特征图中冗余的边缘细节信息以及减少像素误分类的情况。其次,引入改进后的金字塔池化引导模块(PPGM)来获取全局上下文信息并加强不同尺度局部上下文信息的有效融合。在Cityscapes验证集和CamVid测试集上的实验结果表明,HLFGNet的平均交并比(mIoU)分别为76.67%与70.90%,每秒传输帧数分别为75.0、96.2;而相较于BiSeNet,HLFGNet的mIoU分别提高了1.76和3.40个百分点。可见,HLFGNet能够较为准确地识别场景信息,并能满足实时性要求。
中图分类号:
虞资兴, 瞿绍军, 何鑫, 王卓. 高低维特征引导的实时语义分割网络[J]. 计算机应用, 2023, 43(10): 3077-3085.
Zixing YU, Shaojun QU, Xin HE, Zhuo WANG. High-low dimensional feature guided real-time semantic segmentation network[J]. Journal of Computer Applications, 2023, 43(10): 3077-3085.
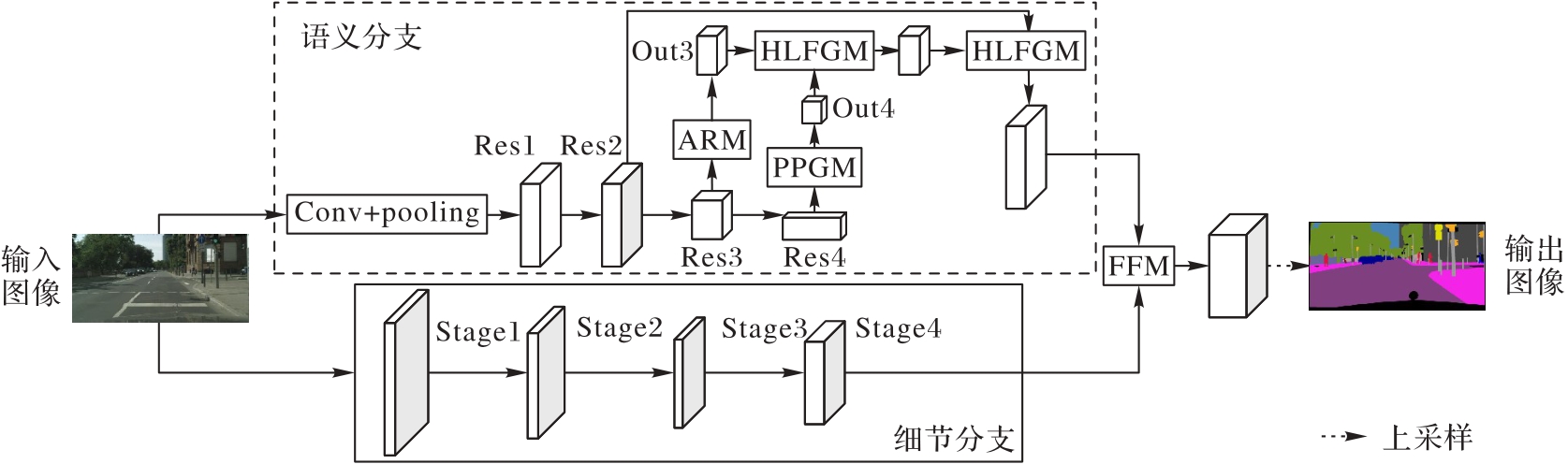
图1 高低维特征引导的实时语义分割网络
Fig. 1 High-low dimensional feature guided real-time semantic segmentation network
| 名称 | 操作 | 输出尺寸 |
|---|---|---|
| 输入 | 18-layer | 1 024×1 024 |
| Conv | 512×512 | |
| Pooling | 256×256 | |
| Res1 | 256×256 | |
| Res2 | 128×128 | |
| Res3 | 64×64 | |
| Res4 | 32×32 |
表1 ResNet-18的详细结构
Tab. 1 Detail structure of ResNet-18
| 名称 | 操作 | 输出尺寸 |
|---|---|---|
| 输入 | 18-layer | 1 024×1 024 |
| Conv | 512×512 | |
| Pooling | 256×256 | |
| Res1 | 256×256 | |
| Res2 | 128×128 | |
| Res3 | 64×64 | |
| Res4 | 32×32 |
| 输入 | 操作 | 卷积核大小 | 输出通道大小 | 步长 | 输出尺寸 |
|---|---|---|---|---|---|
| Stage1 | Conv2d | 7 | 64 | 2 | 512×512 |
| Stage2 | Conv2d | 3 | 64 | 2 | 256×256 |
| Stage3 | Conv2d | 3 | 64 | 2 | 128×128 |
| Stage4 | Conv2d | 1 | 128 | 1 | 128×128 |
表2 细节分支的详细结构
Tab. 2 Detail structure of detail branch
| 输入 | 操作 | 卷积核大小 | 输出通道大小 | 步长 | 输出尺寸 |
|---|---|---|---|---|---|
| Stage1 | Conv2d | 7 | 64 | 2 | 512×512 |
| Stage2 | Conv2d | 3 | 64 | 2 | 256×256 |
| Stage3 | Conv2d | 3 | 64 | 2 | 128×128 |
| Stage4 | Conv2d | 1 | 128 | 1 | 128×128 |
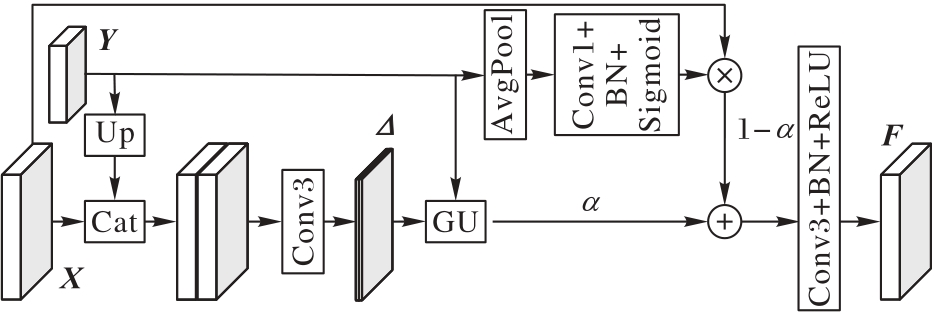
图2 高低维特征引导模块
Fig. 2 High-low dimensional feature guided module

图3 高层特征图的可视化对比
Fig. 3 Visual comparison of high-level feature map

图4 金字塔池化引导模块
Fig. 4 Pyramid pooling guided module
| 分割模型 | UP | HLFGM | AVG | PPM | PPGM | 参数量/MB | mIoU/% | 帧率/(frame·s-1) |
|---|---|---|---|---|---|---|---|---|
| BiSeNet | √ | √ | 51.35 | 74.91 | 83.0 | |||
| √ | √ | 50.28 | 75.21 | 79.0 | ||||
| √ | √ | 50.35 | 76.25 | 76.0 | ||||
| HLFGNet | √ | √ | 51.14 | 75.10 | 71.0 | |||
| √ | √ | 50.29 | 76.01 | 78.0 | ||||
| √ | √ | 50.53 | 76.67 | 75.0 |
表3 在Cityscapes 验证集上验证不同设置下的性能
Tab. 3 Performance validation on Cityscapes validation set under different settings
| 分割模型 | UP | HLFGM | AVG | PPM | PPGM | 参数量/MB | mIoU/% | 帧率/(frame·s-1) |
|---|---|---|---|---|---|---|---|---|
| BiSeNet | √ | √ | 51.35 | 74.91 | 83.0 | |||
| √ | √ | 50.28 | 75.21 | 79.0 | ||||
| √ | √ | 50.35 | 76.25 | 76.0 | ||||
| HLFGNet | √ | √ | 51.14 | 75.10 | 71.0 | |||
| √ | √ | 50.29 | 76.01 | 78.0 | ||||
| √ | √ | 50.53 | 76.67 | 75.0 |
| α | mIoU/% | α | mIoU/% |
|---|---|---|---|
| 1.0 | 75.82 | 0.5 | 76.51 |
| 0.9 | 75.64 | 0.4 | 76.42 |
| 0.8 | 76.40 | 0.3 | 76.29 |
| 0.7 | 76.67 | 0.0 | 63.80 |
| 0.6 | 76.52 |
表4 权重系数实验结果
Tab. 4 Weighting coefficient experiment results
| α | mIoU/% | α | mIoU/% |
|---|---|---|---|
| 1.0 | 75.82 | 0.5 | 76.51 |
| 0.9 | 75.64 | 0.4 | 76.42 |
| 0.8 | 76.40 | 0.3 | 76.29 |
| 0.7 | 76.67 | 0.0 | 63.80 |
| 0.6 | 76.52 |
| 模块 | 1×1 | 2×2 | 3×3 | 6×6 | 参数量/MB | mIoU/% | 帧率/(frame·s-1) |
|---|---|---|---|---|---|---|---|
| PPGM-1 | √ | √ | √ | √ | 50.53 | 76.09 | 68.0 |
| PPGM-2 | √ | √ | √ | 50.53 | 76.88 | 70.0 | |
| PPGM-3 | √ | √ | 50.53 | 76.67 | 75.0 | ||
| PPGM-4 | √ | 50.53 | 75.51 | 76.0 | |||
| PPM | 50.29 | 76.01 | 78.0 |
表5 对不同尺度特征图进行Guide操作的对比实验结果
Tab. 5 Comparison experiment results of Guide operation on feature maps with different scales
| 模块 | 1×1 | 2×2 | 3×3 | 6×6 | 参数量/MB | mIoU/% | 帧率/(frame·s-1) |
|---|---|---|---|---|---|---|---|
| PPGM-1 | √ | √ | √ | √ | 50.53 | 76.09 | 68.0 |
| PPGM-2 | √ | √ | √ | 50.53 | 76.88 | 70.0 | |
| PPGM-3 | √ | √ | 50.53 | 76.67 | 75.0 | ||
| PPGM-4 | √ | 50.53 | 75.51 | 76.0 | |||
| PPM | 50.29 | 76.01 | 78.0 |
| 网络 | 输入尺寸 | 骨干网络 | 参数量/MB | mIoU/% | 帧率/(frame·s-1) | |
|---|---|---|---|---|---|---|
| 验证集 | 测试集 | |||||
| ICNet | 1 024×2 048 | PSPNet50 | 28.30 | 71.70 | 69.50 | 15.2 |
| DFANet-A | 1 024×1 024 | Xception | 7.80 | 71.90 | 71.30 | 50.0 |
| FasterSeg | 1 024×2 048 | 无 | 4.40 | 73.10 | 71.50 | 94.2 |
| DF2-Seg2 | 1 024×2 048 | DF2 | 56.55 | 76.90 | 75.30 | 28.2 |
| STDC2-Seg75 | 768×1 536 | STDC | 61.67 | 77.00 | 76.80 | 48.9 |
| STDC2-Seg75* | 768×1 536 | STDC | 61.67 | 74.20 | 73.20 | 48.9 |
| BiSeNet | 1 024×2 048 | ResNet18 | 51.35 | 74.91 | 74.50 | 83.0 |
| BiSeNet V2 | 1 024×2 048 | 无 | 20.16 | 74.20 | 72.90 | 83.4 |
| BASeNet | 1 024×2 048 | 无 | — | 77.50 | 74.90 | 47.2 |
| BiSeNet V2-L | 512×1 024 | 无 | 123.75 | 75.80 | 75.30 | 23.6 |
| HLFGNet | 1 024×2 048 | ResNet18 | 50.53 | 76.67 | 75.40 | 75.0 |
表6 不同网络在Cityscapes数据集上的实验结果对比
Tab. 6 Comparison of experimental results of different networks on Cityscapes dataset
| 网络 | 输入尺寸 | 骨干网络 | 参数量/MB | mIoU/% | 帧率/(frame·s-1) | |
|---|---|---|---|---|---|---|
| 验证集 | 测试集 | |||||
| ICNet | 1 024×2 048 | PSPNet50 | 28.30 | 71.70 | 69.50 | 15.2 |
| DFANet-A | 1 024×1 024 | Xception | 7.80 | 71.90 | 71.30 | 50.0 |
| FasterSeg | 1 024×2 048 | 无 | 4.40 | 73.10 | 71.50 | 94.2 |
| DF2-Seg2 | 1 024×2 048 | DF2 | 56.55 | 76.90 | 75.30 | 28.2 |
| STDC2-Seg75 | 768×1 536 | STDC | 61.67 | 77.00 | 76.80 | 48.9 |
| STDC2-Seg75* | 768×1 536 | STDC | 61.67 | 74.20 | 73.20 | 48.9 |
| BiSeNet | 1 024×2 048 | ResNet18 | 51.35 | 74.91 | 74.50 | 83.0 |
| BiSeNet V2 | 1 024×2 048 | 无 | 20.16 | 74.20 | 72.90 | 83.4 |
| BASeNet | 1 024×2 048 | 无 | — | 77.50 | 74.90 | 47.2 |
| BiSeNet V2-L | 512×1 024 | 无 | 123.75 | 75.80 | 75.30 | 23.6 |
| HLFGNet | 1 024×2 048 | ResNet18 | 50.53 | 76.67 | 75.40 | 75.0 |
| 类别 | FasterSeg | HLFGNet | BiSeNet |
|---|---|---|---|
| 平均值 | 71.45 | 75.43 | 74.56 |
| road | 98.02 | 98.27 | 98.20 |
| sidewalk | 83.48 | 83.74 | 83.17 |
| building | 91.13 | 91.82 | 91.62 |
| wall | 39.13 | 45.19 | 44.99 |
| fence | 48.70 | 52.77 | 50.69 |
| pole | 58.60 | 61.53 | 61.99 |
| traffic light | 66.73 | 71.04 | 71.29 |
| traffic sign | 71.60 | 74.21 | 74.63 |
| vegetation | 92.33 | 92.81 | 92.78 |
| terrain | 69.11 | 71.51 | 70.44 |
| sky | 94.49 | 95.19 | 94.91 |
| person | 81.47 | 83.63 | 83.40 |
| rider | 61.78 | 66.09 | 66.19 |
| car | 93.68 | 95.25 | 94.98 |
| truck | 54.95 | 64.53 | 61.38 |
| bus | 67.09 | 77.86 | 75.45 |
| train | 61.11 | 72.14 | 67.03 |
| motorcycle | 54.90 | 63.05 | 61.22 |
| bicycle | 69.21 | 72.58 | 72.34 |
表7 Cityscapes测试集上各个类别的准确率 (%)
Tab. 7 Accuracy for each category on Cityscapes test set
| 类别 | FasterSeg | HLFGNet | BiSeNet |
|---|---|---|---|
| 平均值 | 71.45 | 75.43 | 74.56 |
| road | 98.02 | 98.27 | 98.20 |
| sidewalk | 83.48 | 83.74 | 83.17 |
| building | 91.13 | 91.82 | 91.62 |
| wall | 39.13 | 45.19 | 44.99 |
| fence | 48.70 | 52.77 | 50.69 |
| pole | 58.60 | 61.53 | 61.99 |
| traffic light | 66.73 | 71.04 | 71.29 |
| traffic sign | 71.60 | 74.21 | 74.63 |
| vegetation | 92.33 | 92.81 | 92.78 |
| terrain | 69.11 | 71.51 | 70.44 |
| sky | 94.49 | 95.19 | 94.91 |
| person | 81.47 | 83.63 | 83.40 |
| rider | 61.78 | 66.09 | 66.19 |
| car | 93.68 | 95.25 | 94.98 |
| truck | 54.95 | 64.53 | 61.38 |
| bus | 67.09 | 77.86 | 75.45 |
| train | 61.11 | 72.14 | 67.03 |
| motorcycle | 54.90 | 63.05 | 61.22 |
| bicycle | 69.21 | 72.58 | 72.34 |
| 模型 | 输入尺寸 | mIoU/% | 帧率/(frame·s-1) |
|---|---|---|---|
| SegNet | 720×960 | 60.10 | 4.6 |
| ICNet | 720×960 | 67.10 | 34.5 |
| ENet | 720×960 | 51.30 | 61.2 |
| BiSeNet V2 | 720×960 | 70.80 | 81.9 |
| BiSeNet | 720×960 | 67.50 | 115.0 |
| HLFGNet | 720×960 | 70.90 | 96.2 |
表8 不同模型在CamVid测试集上的对比分析
Tab. 8 Comparison and analysis of different models on CamVid test set
| 模型 | 输入尺寸 | mIoU/% | 帧率/(frame·s-1) |
|---|---|---|---|
| SegNet | 720×960 | 60.10 | 4.6 |
| ICNet | 720×960 | 67.10 | 34.5 |
| ENet | 720×960 | 51.30 | 61.2 |
| BiSeNet V2 | 720×960 | 70.80 | 81.9 |
| BiSeNet | 720×960 | 67.50 | 115.0 |
| HLFGNet | 720×960 | 70.90 | 96.2 |

图5 语义分割实验效果的可视化对比
Fig. 5 Visual comparison of semantic segmentation experimental effects
| 1 | 罗会兰,张云. 基于深度网络的图像语义分割综述[J]. 电子学报, 2019, 47(10):2211-2220. 10.3969/j.issn.0372-2112.2019.10.024 |
| LUO H L, ZHANG Y. A survey of image semantic segmentation based on deep network[J]. Acta Electronica Sinica, 2019, 47(10): 2211-2220. 10.3969/j.issn.0372-2112.2019.10.024 | |
| 2 | 张新明,李振云,郑颖. 融合Fisher准则和势函数的多阈值图像分割[J]. 计算机应用, 2012, 32(10):2843-2847. 10.3724/sp.j.1087.2012.02843 |
| ZHANG X M, LI Z Y, ZHENG Y. Multi-threshold image segmentation based on combining Fisher criterion and potential function[J]. Journal of Computer Applications, 2012, 32(10): 2843-2847. 10.3724/sp.j.1087.2012.02843 | |
| 3 | 柳萍,阳爱民. 一种基于区域的彩色图像分割方法[J]. 计算机工程与应用, 2007, 43(6):37-39, 64. 10.3321/j.issn:1002-8331.2007.06.012 |
| LIU P, YANG A M. A method of region-based color image segmentation[J]. Computer Engineering and Applications, 2007, 43(6): 37-39, 64. 10.3321/j.issn:1002-8331.2007.06.012 | |
| 4 | 李翠锦,瞿中. 基于深度学习的图像边缘检测算法综述[J]. 计算机应用, 2020, 40(11):3280-3288. |
| LI C J, QU Z. Review of image edge detection algorithms based on deep learning[J]. Journal of Computer Applications, 2020, 40(11): 3280-3288. | |
| 5 | 宋杰,于裕,骆起峰. 基于RCF的跨层融合特征的边缘检测[J]. 计算机应用, 2020, 40(7):2053-2058. |
| SONG J, YU Y, LUO Q F. Cross-layer fusion feature based on richer convolutional features for edge detection[J]. Journal of Computer Applications, 2020, 40(7): 2053-2058. | |
| 6 | 瞿绍军. 基于最优化理论的图像分割方法研究[D]. 长沙:湖南师范大学, 2018:32-66. |
| QU S J. Research on image segmentation based on optimization theory[D]. Changsha: Hunan Normal University, 2018: 32-66. | |
| 7 | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440. 10.1109/cvpr.2015.7298965 |
| 8 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. 10.1145/3065386 |
| 9 | 张鑫,姚庆安,赵健,等. 全卷积神经网络图像语义分割方法综述[J]. 计算机工程与应用, 2022, 58(8):45-57. 10.3778/j.issn.1002-8331.2109-0091 |
| ZHANG X, YAO Q A, ZHAO J, et al. Image semantic segmentation based on fully convolutional neural network[J]. Computer Engineering and Applications, 2022, 58(8): 45-57. 10.3778/j.issn.1002-8331.2109-0091 | |
| 10 | ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. 10.1109/cvpr.2017.660 |
| 11 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. 10.1109/tpami.2017.2699184 |
| 12 | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| 13 | YU C, WANG J, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 334-349. |
| 14 | LI X, YOU A, ZHU Z, et al. Semantic flow for fast and accurate scene parsing[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 775-793. |
| 15 | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223. 10.1109/cvpr.2016.350 |
| 16 | BROSTOW G J, SHOTTON J, FAUQUEUR J, et al. Segmentation and recognition using structure from motion point clouds[C]// Proceedings of 2008 the European Conference on Computer Vision, LNCS 5302. Berlin: Springer, 2008: 44-57. |
| 17 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[EB/OL]. (2016-06-07) [2022-10-01].. 10.1109/tpami.2017.2699184 |
| 18 | CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05) [2022-10-24].. 10.1007/978-3-030-01234-2_49 |
| 19 | CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 801-818. 10.1007/978-3-030-01234-2_49 |
| 20 | PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation[EB/OL]. (2016-06-07) [2022-04-10].. 10.48550/arXiv.1606.02147 |
| 21 | ZHAO H, QI X, SHEN X, et al. ICNet for real-time semantic segmentation on high-resolution images[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer 2018: 418-434. |
| 22 | YU C, GAO C, WANG J, et al. BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129(11): 3051-3068. 10.1007/s11263-021-01515-2 |
| 23 | FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9711-9720. 10.1109/cvpr46437.2021.00959 |
| 24 | PENG J, LIU Y, TANG S, et al. PP-LiteSeg: a superior real-time semantic segmentation model[EB/OL]. (2022-04-06) [2022-08-06].. |
| 25 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:7132-7141. 10.1109/cvpr.2018.00745 |
| 26 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 27 | FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3141-3149. 10.1109/cvpr.2019.00326 |
| 28 | WANG D, LI N, ZHOU Y, et al. Bilateral attention network for semantic segmentation[J]. IET Image Processing, 2021, 15(8): 1607-1616. 10.1049/ipr2.12129 |
| 29 | 文凯,唐伟伟,熊俊臣. 基于注意力机制和有效分解卷积的实时分割算法[J]. 计算机应用, 2022, 42(9):2659-266. |
| WEN K, TANG W W, XIONG J C. Real-time segmentation algorithm based on attention mechanism and effective factorized convolution[J]. Journal of Computer Applications, 2022, 42(9): 2659-266. | |
| 30 | 吴琼,瞿绍军. 融合注意力机制的端到端的街道场景语义分割[J]. 小型微型计算机系统, 2023, 44(7):1514-1520. |
| WU Q, QU S J. End-to-end semantic segmentation of street scene with attention mechanism[J]. Journal of Chinese Computer Systems, 2023, 44(7): 1514-1520. | |
| 31 | 欧阳柳,贺禧,瞿绍军. 全卷积注意力机制神经网络的图像语义分割 [J]. 计算机科学与探索, 2022, 16(5):1136-1145. 10.3778/j.issn.1673-9418.2105095 |
| OU Y L, HE X, QU S J. Fully convolutional neural network with attention module for semantic segmentation[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1136-1145. 10.3778/j.issn.1673-9418.2105095 | |
| 32 | ZHANG X, DU B, WU Z, et al. LAANet: lightweight attention-guided asymmetric network for real-time semantic segmentation[J]. Neural Computing and Applications, 2022, 34(5): 3573-3587. 10.1007/s00521-022-06932-z |
| 33 | LIU J, XU X, SHI Y, et al. RELAXNet: residual efficient learning and attention expected fusion network for real-time semantic segmentation[J]. Neurocomputing, 2022, 474: 115-127. 10.1016/j.neucom.2021.12.003 |
| 34 | LI H, XIONG P, FAN H, et al. DFANet: deep feature aggregation for real-time semantic segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9514-9523. 10.1109/cvpr.2019.00975 |
| 35 | HUANG Z, WEI Y, WANG X, et al. AlignSeg: feature-aligned segmentation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 550-557. |
| 36 | WU Y, JIANG J, HUANG Z, et al. FPANet: feature pyramid aggregation network for real-time semantic segmentation[J]. Applied Intelligence, 2022, 52(3): 3319-3336. 10.1007/s10489-021-02603-z |
| 37 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 38 | ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs[EB/OL]. (2015-04-15) [2022-05-12].. |
| 39 | 霍占强,贾海洋,乔应旭,等. 边界感知的实时语义分割网络[J]. 计算机工程与应用, 2022, 58(17):165-173. 10.3778/j.issn.1002-8331.2112-0247 |
| HUO Z Q, JIA H Y, QIAO Y X, et al. Boundary-aware real-time semantic segmentation network[J]. Computer Engineering and Applications, 2022, 58(17): 165-173. 10.3778/j.issn.1002-8331.2112-0247 | |
| 40 | CHEN W, GONG X, LIU X, et al. FasterSeg: searching for faster real-time semantic segmentation[EB/OL]. (2020-01-16) [2022-06-14].. |
| [1] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [2] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [3] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [9] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [10] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [11] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [12] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| [13] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [14] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [15] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||