《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (1): 217-222.DOI: 10.11772/j.issn.1001-9081.2023010019
所属专题: 网络空间安全
徐雪冉1( ), 杨庚1,2, 黄喻先1
), 杨庚1,2, 黄喻先1
Xueran XU1(), Geng YANG1,2, Yuxian HUANG1
摘要:
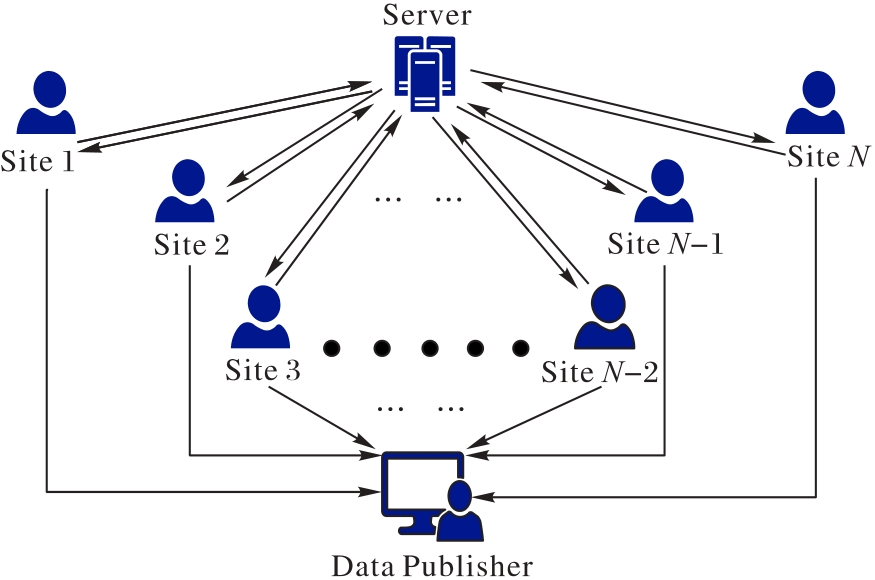
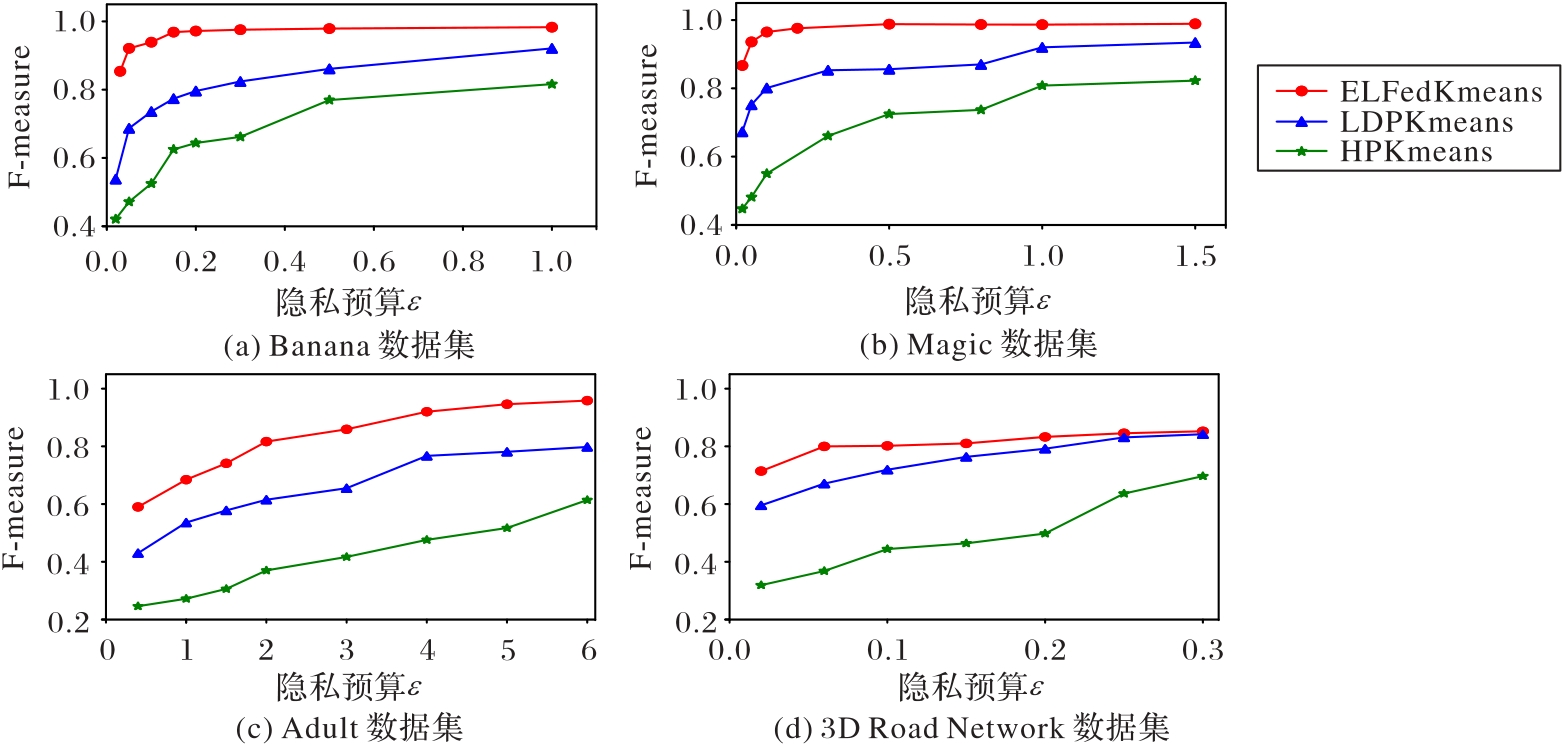
聚类分析能够挖掘出数据间隐藏的内在联系并对数据进行多指标划分,从而促进个性化和精细化运营。然而,数据孤岛造成的数据碎片化和孤立化严重影响了聚类分析的应用效果。为了解决数据孤岛问题的同时保护相关数据隐私,提出本地均分扰动联邦K-means算法(ELFedKmeans)。针对横向联邦学习模式,设计了一种基于网格的初始簇心选择方法和一种隐私预算分配方案。在ELFedKmeans算法中,各站点联合协商随机种子,以较小的通信代价生成相同的随机噪声,保护了本地数据的隐私。通过理论分析证明了该算法满足差分隐私保护,并将该算法与本地差分隐私K-means(LDPKmeans)算法和混合型隐私保护K-means (HPKmeans)算法在不同的数据集上进行了对比实验分析。实验结果表明,随着隐私预算不断增大,三个算法的F-measure值均逐渐升高;误差平方和(SSE)均逐渐减小。从整体上看,ELFedKmeans算法的F-measure值比LDPKmeans算法和HPKmeans算法分别高了1.794 5%~57.066 3%和21.245 2%~132.048 8%;ELFedKmeans算法的Log(SSE)值比LDPKmeans算法和HPKmeans算法分别减少了1.204 2%~12.894 6%和5.617 5%~27.575 2%。在相同的隐私预算下,ELFedKmeans算法在聚类质量和可用性指标上优于对比算法。
中图分类号: