


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (6): 1920-1926.DOI: 10.11772/j.issn.1001-9081.2023060866
所属专题: 多媒体计算与计算机仿真
邴雅星1( ), 王阳萍1,2, 雍玖2, 白浩谋3
), 王阳萍1,2, 雍玖2, 白浩谋3
收稿日期:2023-07-03
修回日期:2023-09-06
接受日期:2023-09-11
发布日期:2023-10-07
出版日期:2024-06-10
通讯作者:
邴雅星
作者简介:王阳萍(1973—),女,四川达州人,教授,博士,主要研究方向:数字图像处理、虚拟现实基金资助:
Yaxing BING1(), Yangping WANG1,2, Jiu YONG2, Haomou BAI3
Received:2023-07-03
Revised:2023-09-06
Accepted:2023-09-11
Online:2023-10-07
Published:2024-06-10
Contact:
Yaxing BING
About author:WANG Yangping, born in 1973, Ph. D., professor. Her research interests include digital image processing, virtual reality.Supported by:摘要:
针对在复杂场景下对弱纹理目标位姿估计的准确性和实时性问题,提出基于筛选学习网络的六自由度(6D)目标位姿估计算法。首先,将标准卷积替换为蓝图可分离卷积(BSConv)以减少模型参数,并使用GeLU(Gaussian error Linear Unit)激活函数,能够更好地逼近正态分布,以提高网络模型的性能;其次,提出上采样筛选编码信息模块(UFAEM),弥补了上采样关键信息丢失的缺陷;最后,提出一种全局注意力机制(GAM),增加上下文信息,更有效地提取输入特征图的信息。在公开数据集LineMOD、YCB-Video和Occlusion LineMOD上测试,实验结果表明,所提算法在网络参数大幅度减少的同时提升了精度。所提算法网络参数量减少近3/4,采用ADD(-S) metric指标,在lineMOD数据集下较Dual-Stream算法精度提升约1.2个百分点,在YCB-Video数据集下较DenseFusion算法精度提升约5.2个百分点,在Occlusion LineMOD数据集下较像素投票网络(PVNet)算法精度提升约6.6个百分点。通过实验结果可知,所提算法对弱纹理目标位姿估计具有较好的效果,对遮挡物体位姿估计具有一定的鲁棒性。
中图分类号:
邴雅星, 王阳萍, 雍玖, 白浩谋. 基于筛选学习网络的六自由度目标位姿估计算法[J]. 计算机应用, 2024, 44(6): 1920-1926.
Yaxing BING, Yangping WANG, Jiu YONG, Haomou BAI. Six degrees of freedom object pose estimation algorithm based on filter learning network[J]. Journal of Computer Applications, 2024, 44(6): 1920-1926.
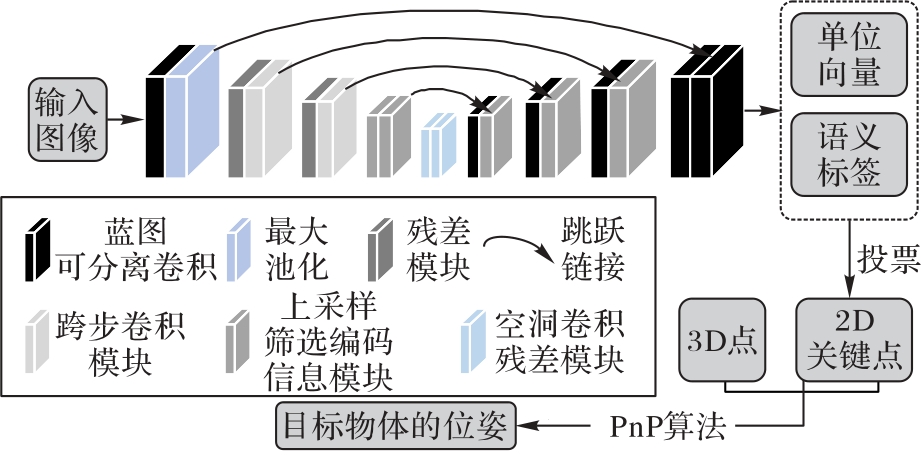
图1 筛选学习网络模型的总体框架
Fig.1 Overall framework of filter learning network model
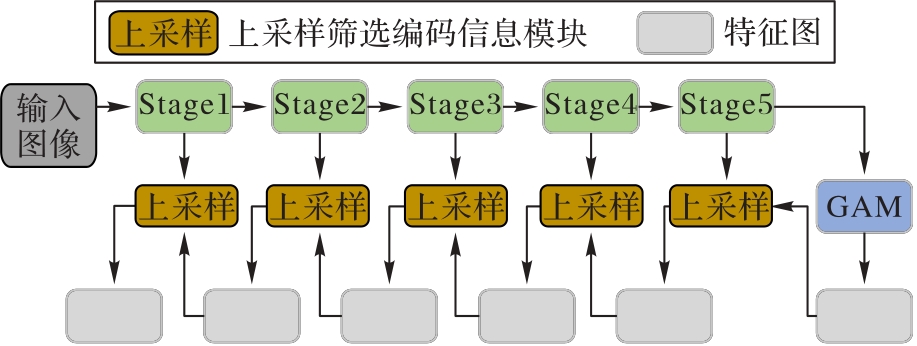
图2 上采样筛选编码信息网络结构
Fig.2 Network structure for upsampling, filtering and encoding information
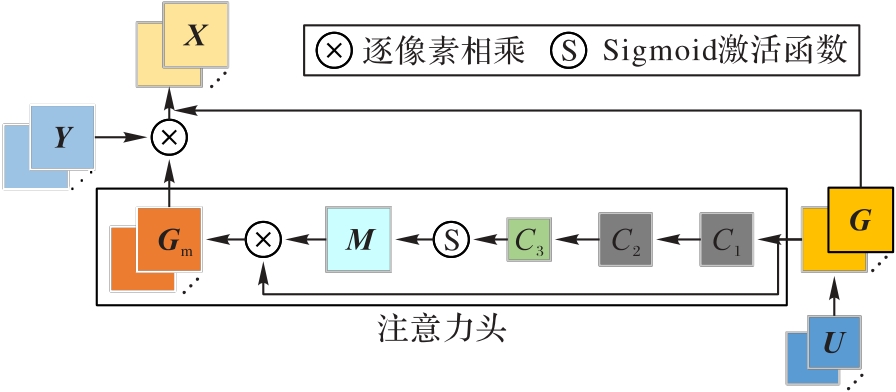
图3 UFAEM的结构
Fig.3 Structure of UFAEM
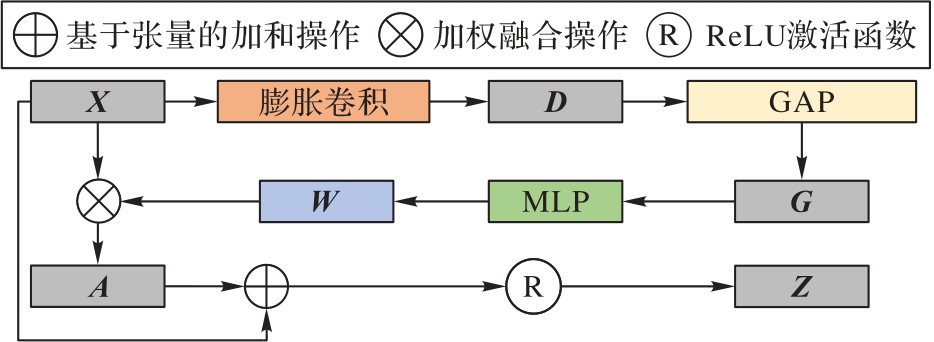
图4 GAM结构
Fig.4 Structure of GAM
| 算法 | 测试物体 | 平均值 | |||||
|---|---|---|---|---|---|---|---|
| ape | cam | cat | duck | holepuncher | phone | ||
| ResNet18 | 43.6 | 86.9 | 79.3 | 52.6 | 81.9 | 92.4 | 72.8 |
| BSConv+GeLU | 55.2 | 89.4 | 85.6 | 67.8 | 83.2 | 93.5 | 79.1 |
BSConv+GeLU+ UFAEM | 85.1 | 94.8 | 90.7 | 84.3 | 88.1 | 95.1 | 89.7 |
BSConv+GeLU+ UFAEM+GAM | 89.7 | 95.6 | 93.1 | 90.8 | 89.7 | 95.9 | 92.5 |
表1 不同模块对模型的精度影响 (%)
Tab.1 Impact of different modules on model accuracy
| 算法 | 测试物体 | 平均值 | |||||
|---|---|---|---|---|---|---|---|
| ape | cam | cat | duck | holepuncher | phone | ||
| ResNet18 | 43.6 | 86.9 | 79.3 | 52.6 | 81.9 | 92.4 | 72.8 |
| BSConv+GeLU | 55.2 | 89.4 | 85.6 | 67.8 | 83.2 | 93.5 | 79.1 |
BSConv+GeLU+ UFAEM | 85.1 | 94.8 | 90.7 | 84.3 | 88.1 | 95.1 | 89.7 |
BSConv+GeLU+ UFAEM+GAM | 89.7 | 95.6 | 93.1 | 90.8 | 89.7 | 95.9 | 92.5 |
| 函数 | 测试物体 | 平均值 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ape | bench-wise | cam | can | cat | driller | duck | egg-box | glue | holepuncher | iron | lamp | phone | ||
| Sigmoid | 86.7 | 99.8 | 91.2 | 93.1 | 90.8 | 98.4 | 85.1 | 99.5 | 95.2 | 85.2 | 96.3 | 99.1 | 94.0 | 93.4 |
| ReLU | 87.9 | 100.0 | 90.2 | 94.6 | 93.0 | 99.5 | 88.2 | 100.0 | 90.9 | 88.4 | 97.1 | 99.0 | 94.2 | 94.1 |
| GeLU | 89.7 | 100.0 | 95.6 | 96.2 | 93.1 | 99.8 | 90.8 | 100.0 | 98.5 | 89.7 | 99.8 | 99.4 | 95.9 | 96.0 |
表2 不同激活函数对模型精度的影响 (%)
Tab.2 Impact of different activation functions on model accuracy
| 函数 | 测试物体 | 平均值 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ape | bench-wise | cam | can | cat | driller | duck | egg-box | glue | holepuncher | iron | lamp | phone | ||
| Sigmoid | 86.7 | 99.8 | 91.2 | 93.1 | 90.8 | 98.4 | 85.1 | 99.5 | 95.2 | 85.2 | 96.3 | 99.1 | 94.0 | 93.4 |
| ReLU | 87.9 | 100.0 | 90.2 | 94.6 | 93.0 | 99.5 | 88.2 | 100.0 | 90.9 | 88.4 | 97.1 | 99.0 | 94.2 | 94.1 |
| GeLU | 89.7 | 100.0 | 95.6 | 96.2 | 93.1 | 99.8 | 90.8 | 100.0 | 98.5 | 89.7 | 99.8 | 99.4 | 95.9 | 96.0 |

图5 不同数据集上的可视化结果
Fig. 5 Visualization results on different datasets
| 算法 | 测试物体 | 平均值 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ape | bench-wise | cam | can | cat | driller | duck | egg-box | glue | holepuncher | iron | lamp | phone | ||
| real-time | 21.6 | 81.8 | 36.6 | 68.8 | 41.8 | 63.5 | 27.2 | 69.9 | 80.0 | 42.6 | 74.9 | 71.1 | 47.7 | 55.9 |
| PoseCNN | 77.0 | 97.5 | 93.5 | 96.5 | 82.1 | 95.0 | 77.7 | 97.1 | 99.4 | 52.8 | 98.3 | 97.5 | 87.7 | 88.6 |
| Dense-Fusion | 92.3 | 93.2 | 94.4 | 93.1 | 96.5 | 87.0 | 92.3 | 99.8 | 100 | 92.1 | 97.0 | 95.3 | 92.8 | 94.3 |
| Dual-Stream | 91.3 | 93.5 | 94.0 | 94.3 | 95.8 | 92.9 | 94.7 | 99.9 | 99.9 | 92.8 | 95.1 | 94.6 | 94.0 | 94.8 |
| PVNet | 43.6 | 99.9 | 86.9 | 95.5 | 79.3 | 96.4 | 52.6 | 99.2 | 95.7 | 81.9 | 98.9 | 99.3 | 92.4 | 86.3 |
| 本文算法 | 89.7 | 100.0 | 95.6 | 96.2 | 93.1 | 99.8 | 90.8 | 100.0 | 98.5 | 89.7 | 99.8 | 99.4 | 95.9 | 96.0 |
表3 LineMOD数据集上精度结果对比 (%)
Tab.3 Comparison of accuracy results on LineMOD dataset
| 算法 | 测试物体 | 平均值 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ape | bench-wise | cam | can | cat | driller | duck | egg-box | glue | holepuncher | iron | lamp | phone | ||
| real-time | 21.6 | 81.8 | 36.6 | 68.8 | 41.8 | 63.5 | 27.2 | 69.9 | 80.0 | 42.6 | 74.9 | 71.1 | 47.7 | 55.9 |
| PoseCNN | 77.0 | 97.5 | 93.5 | 96.5 | 82.1 | 95.0 | 77.7 | 97.1 | 99.4 | 52.8 | 98.3 | 97.5 | 87.7 | 88.6 |
| Dense-Fusion | 92.3 | 93.2 | 94.4 | 93.1 | 96.5 | 87.0 | 92.3 | 99.8 | 100 | 92.1 | 97.0 | 95.3 | 92.8 | 94.3 |
| Dual-Stream | 91.3 | 93.5 | 94.0 | 94.3 | 95.8 | 92.9 | 94.7 | 99.9 | 99.9 | 92.8 | 95.1 | 94.6 | 94.0 | 94.8 |
| PVNet | 43.6 | 99.9 | 86.9 | 95.5 | 79.3 | 96.4 | 52.6 | 99.2 | 95.7 | 81.9 | 98.9 | 99.3 | 92.4 | 86.3 |
| 本文算法 | 89.7 | 100.0 | 95.6 | 96.2 | 93.1 | 99.8 | 90.8 | 100.0 | 98.5 | 89.7 | 99.8 | 99.4 | 95.9 | 96.0 |
| 算法 | 测试物体 | 平均值 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ape | can | cat | driller | duck | eggbox | glue | holepuncher | ||
| HybridPose | 20.9 | 75.3 | 24.9 | 70.2 | 27.9 | 52.4 | 53.8 | 54.2 | 47.5 |
| SSPE | 19.2 | 65.1 | 18.9 | 69.0 | 25.3 | 52.0 | 51.4 | 45.6 | 43.3 |
| RePOSE | 31.1 | 80.0 | 25.6 | 73.1 | 43.0 | 51.7 | 54.3 | 53.6 | 51.6 |
| SegDriven | 12.1 | 39.9 | 8.2 | 45.2 | 17.2 | 22.1 | 35.8 | 36.0 | 27.0 |
| PoseCNN | 9.6 | 45.2 | 0.9 | 41.4 | 19.6 | 22.0 | 38.5 | 22.1 | 24.9 |
| PVNet | 15.8 | 63.3 | 16.7 | 65.7 | 25.2 | 50.2 | 49.6 | 39.7 | 40.8 |
| 本文算法 | 23.1 | 72.6 | 24.4 | 74.4 | 26.0 | 53.1 | 54.5 | 50.7 | 47.4 |
表4 Occlusion LineMOD数据集上精度结果对比 (%)
Tab.4 Comparison of accuracy results on Occlusion LineMOD dataset
| 算法 | 测试物体 | 平均值 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ape | can | cat | driller | duck | eggbox | glue | holepuncher | ||
| HybridPose | 20.9 | 75.3 | 24.9 | 70.2 | 27.9 | 52.4 | 53.8 | 54.2 | 47.5 |
| SSPE | 19.2 | 65.1 | 18.9 | 69.0 | 25.3 | 52.0 | 51.4 | 45.6 | 43.3 |
| RePOSE | 31.1 | 80.0 | 25.6 | 73.1 | 43.0 | 51.7 | 54.3 | 53.6 | 51.6 |
| SegDriven | 12.1 | 39.9 | 8.2 | 45.2 | 17.2 | 22.1 | 35.8 | 36.0 | 27.0 |
| PoseCNN | 9.6 | 45.2 | 0.9 | 41.4 | 19.6 | 22.0 | 38.5 | 22.1 | 24.9 |
| PVNet | 15.8 | 63.3 | 16.7 | 65.7 | 25.2 | 50.2 | 49.6 | 39.7 | 40.8 |
| 本文算法 | 23.1 | 72.6 | 24.4 | 74.4 | 26.0 | 53.1 | 54.5 | 50.7 | 47.4 |

图6 位姿估计可视化结果
Fig.6 Visualization results of pose estimation
| 测试物体 | PoseCNN | DenseFusion | 本文算法 | |||
|---|---|---|---|---|---|---|
| ADD-S | ADD(S) | ADD-S | ADD(S) | ADD-S | ADD(S) | |
| 平均值 | 75.9 | 59.9 | 91.2 | 82.9 | 92.5 | 88.1 |
| 02 master chef can | 83.9 | 50.2 | 95.3 | 70.7 | 95.0 | 76.9 |
| 03 cracker box | 76.9 | 53.1 | 92.5 | 86.9 | 94.2 | 90.2 |
| 04 sugar box | 84.2 | 68.4 | 95.1 | 90.8 | 96.1 | 93.9 |
| 05 tomato soup can | 81.0 | 66.2 | 93.8 | 84.7 | 94.7 | 88.1 |
| 06 mustard bottle | 90.4 | 81.0 | 95.8 | 90.9 | 96.3 | 93.2 |
| 07 tuna fish can | 88.0 | 70.7 | 95.7 | 79.6 | 95.1 | 89.5 |
| 08 pudding box | 79.1 | 62.7 | 94.3 | 89.3 | 93.7 | 88.1 |
| 09 gelatin box | 87.2 | 75.2 | 97.2 | 95.8 | 96.0 | 94.6 |
| 10 potted meat can | 78.5 | 59.5 | 89.3 | 79.6 | 90.2 | 82.0 |
| 11 banana | 86.0 | 72.3 | 90.0 | 76.7 | 93.2 | 91.0 |
| 19 pitcher base | 77.0 | 53.3 | 93.6 | 87.1 | 91.2 | 86.0 |
| 21 bleach cleanser | 71.6 | 50.3 | 94.4 | 87.5 | 95.5 | 86.7 |
| 24 bowl* | 69.6 | 69.6 | 86.0 | 86.0 | 87.8 | 87.8 |
| 25 mug | 78.2 | 58.5 | 95.3 | 83.8 | 96.9 | 92.1 |
| 35 power drill | 72.7 | 55.3 | 92.1 | 83.7 | 95.4 | 92.3 |
| 36 wood block* | 64.3 | 64.3 | 89.5 | 89.5 | 88.7 | 88.7 |
| 37 scissors | 56.9 | 35.8 | 90.1 | 77.4 | 92.1 | 88.1 |
| 40 large marker | 71.7 | 58.3 | 95.1 | 89.1 | 93.2 | 84.0 |
| 51 large clamp* | 50.2 | 50.2 | 71.5 | 71.5 | 79.3 | 79.3 |
| 52 extra large clamp* | 44.1 | 44.1 | 70.2 | 70.2 | 86.0 | 86.0 |
| 61 foam brick* | 88.0 | 88.0 | 92.2 | 92.2 | 92.1 | 92.1 |
表5 YCB-Video数据集上精度结果对比 (%)
Tab.5 Comparison of accuracy results on YCB-Video dataset
| 测试物体 | PoseCNN | DenseFusion | 本文算法 | |||
|---|---|---|---|---|---|---|
| ADD-S | ADD(S) | ADD-S | ADD(S) | ADD-S | ADD(S) | |
| 平均值 | 75.9 | 59.9 | 91.2 | 82.9 | 92.5 | 88.1 |
| 02 master chef can | 83.9 | 50.2 | 95.3 | 70.7 | 95.0 | 76.9 |
| 03 cracker box | 76.9 | 53.1 | 92.5 | 86.9 | 94.2 | 90.2 |
| 04 sugar box | 84.2 | 68.4 | 95.1 | 90.8 | 96.1 | 93.9 |
| 05 tomato soup can | 81.0 | 66.2 | 93.8 | 84.7 | 94.7 | 88.1 |
| 06 mustard bottle | 90.4 | 81.0 | 95.8 | 90.9 | 96.3 | 93.2 |
| 07 tuna fish can | 88.0 | 70.7 | 95.7 | 79.6 | 95.1 | 89.5 |
| 08 pudding box | 79.1 | 62.7 | 94.3 | 89.3 | 93.7 | 88.1 |
| 09 gelatin box | 87.2 | 75.2 | 97.2 | 95.8 | 96.0 | 94.6 |
| 10 potted meat can | 78.5 | 59.5 | 89.3 | 79.6 | 90.2 | 82.0 |
| 11 banana | 86.0 | 72.3 | 90.0 | 76.7 | 93.2 | 91.0 |
| 19 pitcher base | 77.0 | 53.3 | 93.6 | 87.1 | 91.2 | 86.0 |
| 21 bleach cleanser | 71.6 | 50.3 | 94.4 | 87.5 | 95.5 | 86.7 |
| 24 bowl* | 69.6 | 69.6 | 86.0 | 86.0 | 87.8 | 87.8 |
| 25 mug | 78.2 | 58.5 | 95.3 | 83.8 | 96.9 | 92.1 |
| 35 power drill | 72.7 | 55.3 | 92.1 | 83.7 | 95.4 | 92.3 |
| 36 wood block* | 64.3 | 64.3 | 89.5 | 89.5 | 88.7 | 88.7 |
| 37 scissors | 56.9 | 35.8 | 90.1 | 77.4 | 92.1 | 88.1 |
| 40 large marker | 71.7 | 58.3 | 95.1 | 89.1 | 93.2 | 84.0 |
| 51 large clamp* | 50.2 | 50.2 | 71.5 | 71.5 | 79.3 | 79.3 |
| 52 extra large clamp* | 44.1 | 44.1 | 70.2 | 70.2 | 86.0 | 86.0 |
| 61 foam brick* | 88.0 | 88.0 | 92.2 | 92.2 | 92.1 | 92.1 |
| 1 | 刘泽洋,贾迪.面向目标6DoF姿态与尺寸估计的全卷积神经网络模型[J].计算机应用研究,2023,40(3):938-942. |
| LIU Z Y, JIA D. Full convolution neural network model for 6DoF attitude and size estimation[J]. Application Research of Computers, 2023,40(3): 938-942. | |
| 2 | LINDEBERG T. Scale invariant feature transform[J]. Scholarpedia, 2012, 7(5):10491. |
| 3 | BAY H, TUYTELAARS T, VAN G L.SURF: speeded up robust features[C]// Proceedings of the 9th European Conference on Computer Vision. Berlin: Springer, 2006:404-417. |
| 4 | RUBLEE E, RABAUD V, KONOLIGE K, et al. ORB: an efficient alternative to SIFT or SURF[C]// Proceedings of the 2011 International Conference on Computer Vision. Piscataway:IEEE, 2011: 2564-2571. |
| 5 | MAIR E, HAGER G D, BURSCHKA D, et al. Adaptive and generic corner detection based on the accelerated segment test[C]// Proceedings of the 11th European Conference on Computer Vision. Berlin: Springer, 2010:183-196. |
| 6 | CALONDER M, LEPETIT V, STRECHA C, et al. BRIEF: binary robust independent elementary features[C]// Proceedings of the 11th European Conference on Computer Vision. Berlin:Springer, 2010:778-792. |
| 7 | KEHL W, MANHARDT F, TOMBARI F, et al. SSD-6D: making RGB-based 3D detection and 6D pose estimation great again[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway:IEEE, 2017: 1530-1538. |
| 8 | HE Y, HUANG H, FAN H, et al. FFB6D: a full flow bidirectional fusion network for 6D pose estimation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2021: 3002-3012. |
| 9 | BUKSCHAT Y, VETTER M. EfficientPose: an efficient, accurate and scalable end-to-end 6D multi object pose estimation approach[EB/OL]. (2020-11-18)[2023-06-08].. |
| 10 | XU Y, LIN K-Y, ZHANG G, et al. RNNPose: recurrent 6-DoF object pose refinement with robust correspondence field estimation and pose optimization [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2022: 14860-14870. |
| 11 | PENG S, ZHOU X, LIU Y, et al. PVNet: pixel-wise voting network for 6DoF object pose estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 3212-3223. |
| 12 | 帅昊.基于深度学习的机械产品AR跟踪注册方法研究[D].重庆:重庆邮电大学, 2021:37-38. |
| SHUAI H. Research on tracking registration of mechanical product assembly augmented reality based on deep learning[D].Chongqing: Chongqing University of Posts and Telecommunications, 2021:37-38. | |
| 13 | RAD M, LEPETIT V. BB8: a scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway:IEEE,2017: 3848-3856. |
| 14 | 马康哲,皮家甜,熊周兵,等.融合注意力特征的遮挡物体6D姿态估计[J].计算机应用,2022,42(12):3715-3722. |
| MA K Z, PI J T, XIONG Z B, et al. 6D pose estimation incorporating attentional features for occluded objects[J]. Journal of Computer Applications, 2022, 42(12): 3715-3722. | |
| 15 | YANG Z X, YU X, YANG Y. DSC-PoseNet: learning 6DoF object pose estimation via dual-scale consistency[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2021: 3906-3915. |
| 16 | HAASE D, AMTHOR M. Rethinking depthwise separable convolutions: how intra-kernel correlations lead to improved mobilenets[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2020:14588-14597. |
| 17 | ZHAO Z, PENG G, WANG H, et al. Estimating 6D pose from localizing designated surface keypoints [EB/OL]. (2018-12-04)[2023-06-08]. . |
| 18 | HINTERSTOISSER S, LEPETIT V, ILIC S, et al. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes[C]// Proceedings of the 11th Asian Conference on Computer Vision. Berlin:Springer, 2013: 548-562. |
| 19 | TEKIN B, SINHA S N, FUA P. Real-time seamless single shot 6D object pose prediction [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 292-301. |
| 20 | XIANG Y, SCHMIDT T, NARAYANAN V, et al. PoseCNN: a convolution neural network for 6D object pose estimation in cluttered scenes [EB/OL]. (2018-05-26)[2023-06-08] . |
| 21 | WANG C, XU D, ZHU Y, et al. DenseFusion: 6D object pose estimation by iterative dense fusion[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3338-3347. |
| 22 | LI Q, HU R, XIAO J, et al. Learning latent geometric consistency for 6D object pose estimation in heavily cluttered scenes[J]. Journal of Visual Communication and Image Representation, 2020, 70: 175-184. |
| 23 | SONG C, SONG J, HUANG Q. HybridPose: 6D object pose estimation under hybrid representations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 428-437. |
| 24 | HU Y, FUA P, WANG W,et al. Single-stage 6D object pose estimations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2020:2927-2936. |
| 25 | IWASE S, LIU X, KHIRODKAR R, et al. RePOSE: fast 6D object pose refinement via deep texture rendering[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 3283-3292. |
| 26 | HU Y, HUGONOT J, FUA P,et al. Segmentation-driven 6D object pose estimation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3380-3389. |
| [1] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| [2] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [3] | 李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703. |
| [4] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [5] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [6] | 王熙源, 张战成, 徐少康, 张宝成, 罗晓清, 胡伏原. 面向手术导航3D/2D配准的无监督跨域迁移网络[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2911-2918. |
| [7] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [8] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [9] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [10] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [11] | 刘禹含, 吉根林, 张红苹. 基于骨架图与混合注意力的视频行人异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2551-2557. |
| [12] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [13] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [14] | 顾焰杰, 张英俊, 刘晓倩, 周围, 孙威. 基于时空多图融合的交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2618-2625. |
| [15] | 石乾宏, 杨燕, 江永全, 欧阳小草, 范武波, 陈强, 姜涛, 李媛. 面向空气质量预测的多粒度突变拟合网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2643-2650. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||