《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (5): 1528-1534.DOI: 10.11772/j.issn.1001-9081.2024050628
• 人工智能 • 上一篇
张庆1,2, 杨凡1,2( ), 方宇涵1,2
), 方宇涵1,2
Qing ZHANG1,2, Fan YANG1,2(), Yuhan FANG1,2
摘要:
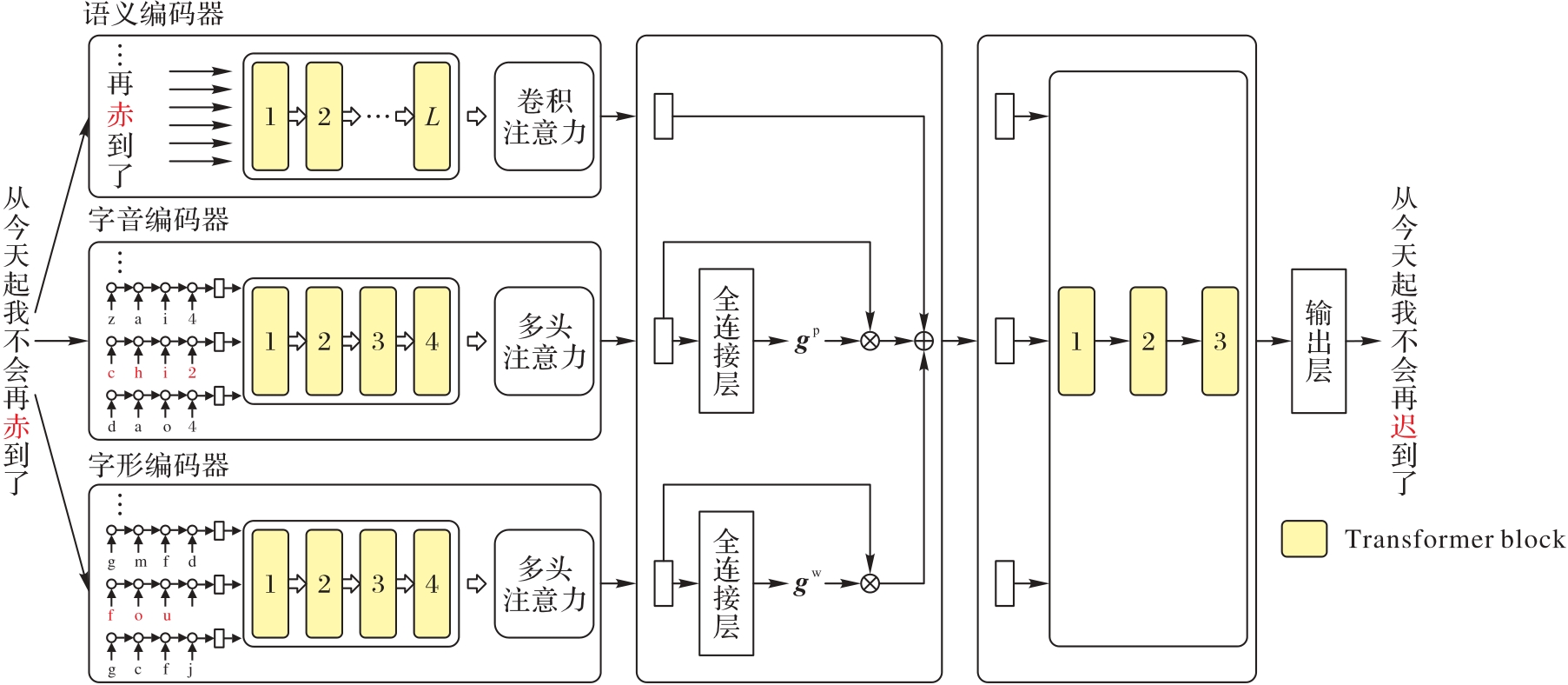
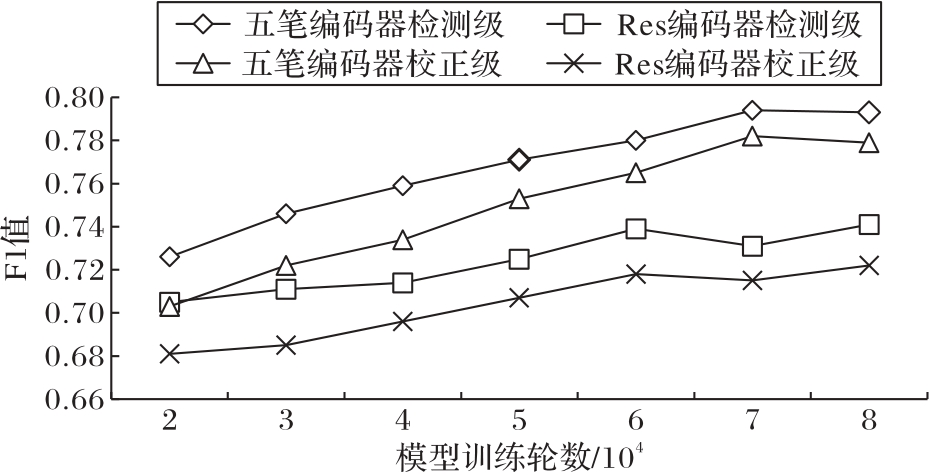
中文拼写纠错(CSC)的目标是检测和修正用户输入中文文本中的字或词级别的错误,这些错误通常是由于汉字之间的语义、字音或字形相似而导致的误用。然而,现有模型通常忽略了局部信息,无法充分捕捉不同汉字之间的字音和字形相似性,也无法有效地将这些信息与语义信息结合起来。为了解决这些问题,提出一种基于多模态信息融合的CSC算法PWSpell。该算法利用卷积注意力机制关注局部语义信息,利用拼音编码捕捉汉字之间的字音相似关系,并首次将五笔编码引入CSC领域,用于捕捉汉字之间的字形相似关系。此外,将这2种相似关系与经过BERT(Bidirectional Encoder Representation from Transformers)处理的语义信息进行选择性融合。实验结果表明,PWSpell在SIGHAN 2015测试集的检测级指标上准确率、精确率、F1值以及校正级指标精确率、F1值上均有提升,其中校正级的精确率至少提升了1个百分点;消融实验结果也验证了算法中各个模块的设计都能有效提升模型的性能。
中图分类号: