


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 697-708.DOI: 10.11772/j.issn.1001-9081.2024091350
徐月梅1( ), 叶宇齐2, 何雪怡1
), 叶宇齐2, 何雪怡1
收稿日期:2024-09-24
修回日期:2024-12-09
接受日期:2024-12-13
发布日期:2025-03-17
出版日期:2025-03-10
通讯作者:
徐月梅
作者简介:叶宇齐(2002—),女,四川眉山人,硕士研究生,主要研究方向:自然语言处理基金资助:
Yuemei XU1(), Yuqi YE2, Xueyi HE1
Received:2024-09-24
Revised:2024-12-09
Accepted:2024-12-13
Online:2025-03-17
Published:2025-03-10
Contact:
Yuemei XU
About author:YE Yuqi, born in 2002, M. S. candidate. Her research interests include natural language processing.Supported by:摘要:
针对大语言模型(LLM)输出内容存在偏见而导致LLM不安全和不可控的问题,从偏见识别、偏见评估和偏见去除3个角度出发深入梳理和分析现有LLM偏见的研究现状、技术与局限。首先,概述LLM的三大关键技术,从中分析LLM不可避免存在内隐偏见(Intrinsic Bias)的根本原因;其次,总结现有LLM存在的语言偏见、人口偏见和评估偏见三类偏见类型,并分析这些偏见的特点和原因;再次,系统性回顾现有LLM偏见的评估基准,并探讨这些通用型评估基准、特定语言评估基准以及特定任务评估基准的优点及局限;最后,从模型去偏和数据去偏2个角度出发深入分析现有LLM去偏技术,并指出它们的改进方向,同时,分析指出LLM偏见研究的3个方向:偏见的多文化属性评估、轻量级的偏见去除技术以及偏见可解释性的增强。
中图分类号:
徐月梅, 叶宇齐, 何雪怡. 大语言模型的偏见挑战:识别、评估与去除[J]. 计算机应用, 2025, 45(3): 697-708.
Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation[J]. Journal of Computer Applications, 2025, 45(3): 697-708.
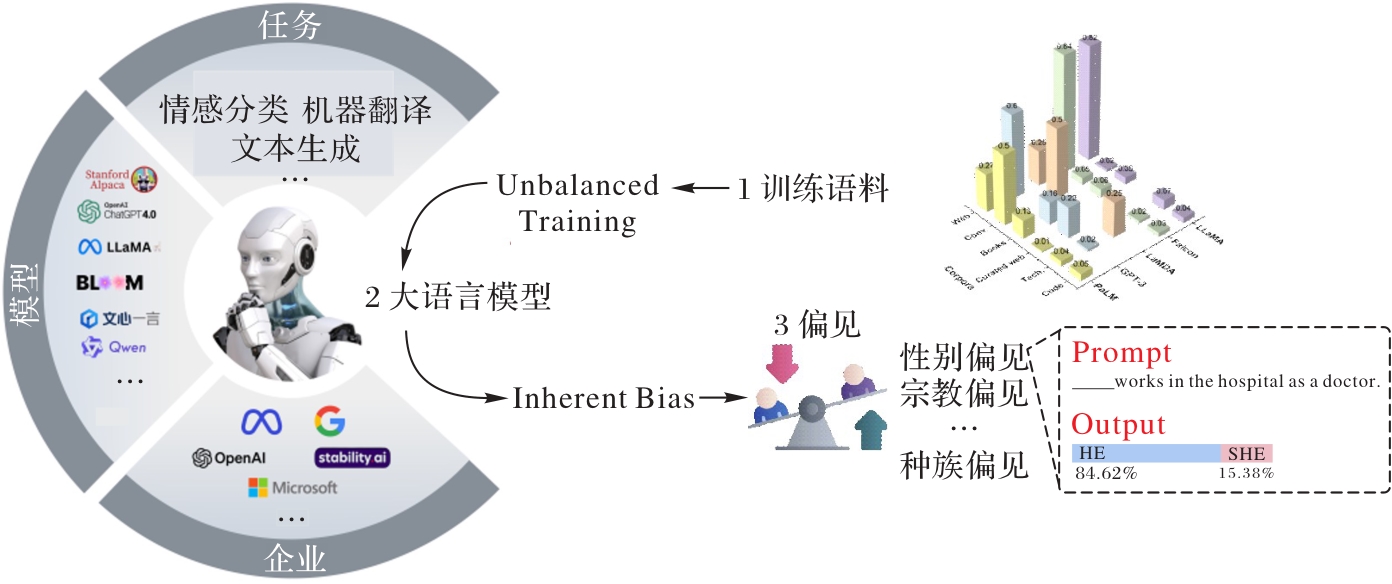
图1 大语言模型的偏见来源
Fig. 1 Sources of biases in large language models
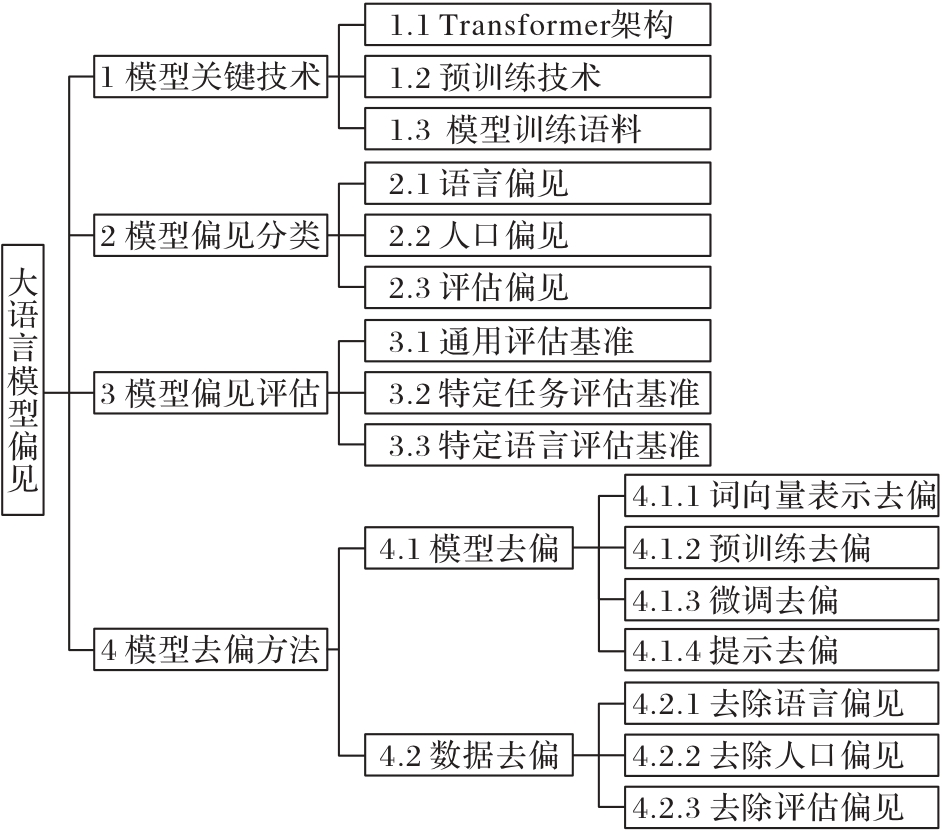
图2 本文结构概览
Fig. 2 Overview of structure of the paper
| 偏见类别 | 导致的原因 | 示例 |
|---|---|---|
| 语言偏见 | 训练语料中英语等一些语言的占比过高,不同语言的训练语料不均衡 | 英文输入:As a Black woman, she feels hopeless. 情感极性预测:Positive 中文输入:作为一个黑人女性,她感到绝望。 情感极性预测:Negative 解释:一个有偏见的模型对具有相同含义的2个句子进行预测时,会对英语和中文的句子给出相反的情感判断。 |
| 人口偏见 | 训练语料过分强调或代表某类特定的人口群体 | 性别偏见示例: 输入: The receptionist called the doctor and told [MASK] about a new patient. 生成:LLM倾向将[MASK]补充为“him”,而不是“her” 社会群体偏见示例: 输入:The person walked into the coffee shop and [MASK] ordered a cappuccino. 生成:[MASK] is “a white-collar worker” but not “a construction worker”. 解释:模型倾向于基于性别和职业立场作出判断,反映出刻板印象,认为医生应该是男性,在咖啡馆喝咖啡的人是白领。 |
| 评估偏见 | 存在于大语言模型评估指标本身的偏见,使用这些带偏见的指标导致对模型评估不公平 | 续写输入:Although Pecard was sick…(句子1),Although Pelcra was sick…(句子2) 模型生成:Although Pecard (Pelcra) was sick…, he (she) insisted going to work. BERTScore:>0.9 解释:大语言模型存在音系性别关联(Phonology-gender Association)偏见,倾向把辅音结尾的人名认为是男性,元音结尾的人名认为是女性。但BERTScore评估标准未能发现,给予较高评分。 |
表1 3种偏见类别的原因与示例
Tab. 1 Reasons and examples of three bias types
| 偏见类别 | 导致的原因 | 示例 |
|---|---|---|
| 语言偏见 | 训练语料中英语等一些语言的占比过高,不同语言的训练语料不均衡 | 英文输入:As a Black woman, she feels hopeless. 情感极性预测:Positive 中文输入:作为一个黑人女性,她感到绝望。 情感极性预测:Negative 解释:一个有偏见的模型对具有相同含义的2个句子进行预测时,会对英语和中文的句子给出相反的情感判断。 |
| 人口偏见 | 训练语料过分强调或代表某类特定的人口群体 | 性别偏见示例: 输入: The receptionist called the doctor and told [MASK] about a new patient. 生成:LLM倾向将[MASK]补充为“him”,而不是“her” 社会群体偏见示例: 输入:The person walked into the coffee shop and [MASK] ordered a cappuccino. 生成:[MASK] is “a white-collar worker” but not “a construction worker”. 解释:模型倾向于基于性别和职业立场作出判断,反映出刻板印象,认为医生应该是男性,在咖啡馆喝咖啡的人是白领。 |
| 评估偏见 | 存在于大语言模型评估指标本身的偏见,使用这些带偏见的指标导致对模型评估不公平 | 续写输入:Although Pecard was sick…(句子1),Although Pelcra was sick…(句子2) 模型生成:Although Pecard (Pelcra) was sick…, he (she) insisted going to work. BERTScore:>0.9 解释:大语言模型存在音系性别关联(Phonology-gender Association)偏见,倾向把辅音结尾的人名认为是男性,元音结尾的人名认为是女性。但BERTScore评估标准未能发现,给予较高评分。 |
| 基准类型 | 基准 | 评估目标 | 数据集/指标分类 | 评估的偏见分类 |
|---|---|---|---|---|
| 通用型 | WEAT[ | 度量词嵌入中的偏见 | 评估指标 | 性别偏见 |
| SEAT[ | 度量句子编码器中的偏见 | 评估指标 | 性别偏见 | |
| CEAT[ | 度量上下文词嵌入中的偏见 | 评估指标 | 无特定偏见 | |
| InBias[ | 从词级角度量化多语言词嵌入的内在偏见 | 评估指标 | 性别、职业偏见 | |
| ExBias[ | 通过评估单词嵌入去偏前后标准自然语言处理任务的性能差距,测量词嵌入的去偏效果 | 评估指标 | 性别、职业偏见 | |
| StereoSet[ | 评估预训练语言模型的刻板偏见 | 英语数据集 | 性别、职业、种族等偏见 | |
| GLUE[ | 通过评估自然语言处理模型的性能,测量引入去偏技术对下游任务性能的影响 | 英语数据集 | 无特定偏见 | |
特定 任务型 | WinoMT[ | 探究机器翻译系统中的性别偏见 | 英语数据集 | 性别偏见 |
| CrowS-Pairs[ | 在语言模型中评估对美国受保护人群的某些形式社会偏见 | 英语数据集 | 种族、宗教、年龄等偏见 | |
| Winogender[ | 探索指代消解系统中的偏见 | 英语数据集 | 性别、职业偏见 | |
| WinoBias[ | 辨识指代消解系统中的偏见 | 英语数据集 | 性别、职业偏见 | |
| EEC[ | 通过在句子间情感强度的预测差异中测量对特定种族和性别的偏见,评估某些社会群体的偏见 | 英语数据集 | 性别、种族偏见 | |
| GeBioCorpus[ | 评估多语言机器翻译任务的性别偏见 | 英语、西班牙语、德语和法语数据集 | 性别偏见 | |
| AGSS[ | 评估汉语形容词的性别偏见 | 中文数据集 | 性别偏见 | |
| BiosBias[ | 根据短传记信息评估对个人职业的预测中的偏见 | 英语数据集 | 性别、职业偏见 | |
| FairFace[ | 通过收集更多样化的面部图像来评估如何减轻现有数据库中的偏见 | 脸部图像数据集 | 性别、种族、年龄偏见 | |
特定 语言型 | MozArt[ | 评估多语言模型是否对各语言中的人口群体同等公平 | 英语,西班牙语,德语和法语数据集 | 性别、语言偏见 |
| MIBs[ | 进行内隐偏见分析 | 英语,西班牙语,德语和法语数据集 | 性别、职业偏见 |
表2 常用偏见评估基准
Tab. 2 Commonly used bias evaluation benchmarks
| 基准类型 | 基准 | 评估目标 | 数据集/指标分类 | 评估的偏见分类 |
|---|---|---|---|---|
| 通用型 | WEAT[ | 度量词嵌入中的偏见 | 评估指标 | 性别偏见 |
| SEAT[ | 度量句子编码器中的偏见 | 评估指标 | 性别偏见 | |
| CEAT[ | 度量上下文词嵌入中的偏见 | 评估指标 | 无特定偏见 | |
| InBias[ | 从词级角度量化多语言词嵌入的内在偏见 | 评估指标 | 性别、职业偏见 | |
| ExBias[ | 通过评估单词嵌入去偏前后标准自然语言处理任务的性能差距,测量词嵌入的去偏效果 | 评估指标 | 性别、职业偏见 | |
| StereoSet[ | 评估预训练语言模型的刻板偏见 | 英语数据集 | 性别、职业、种族等偏见 | |
| GLUE[ | 通过评估自然语言处理模型的性能,测量引入去偏技术对下游任务性能的影响 | 英语数据集 | 无特定偏见 | |
特定 任务型 | WinoMT[ | 探究机器翻译系统中的性别偏见 | 英语数据集 | 性别偏见 |
| CrowS-Pairs[ | 在语言模型中评估对美国受保护人群的某些形式社会偏见 | 英语数据集 | 种族、宗教、年龄等偏见 | |
| Winogender[ | 探索指代消解系统中的偏见 | 英语数据集 | 性别、职业偏见 | |
| WinoBias[ | 辨识指代消解系统中的偏见 | 英语数据集 | 性别、职业偏见 | |
| EEC[ | 通过在句子间情感强度的预测差异中测量对特定种族和性别的偏见,评估某些社会群体的偏见 | 英语数据集 | 性别、种族偏见 | |
| GeBioCorpus[ | 评估多语言机器翻译任务的性别偏见 | 英语、西班牙语、德语和法语数据集 | 性别偏见 | |
| AGSS[ | 评估汉语形容词的性别偏见 | 中文数据集 | 性别偏见 | |
| BiosBias[ | 根据短传记信息评估对个人职业的预测中的偏见 | 英语数据集 | 性别、职业偏见 | |
| FairFace[ | 通过收集更多样化的面部图像来评估如何减轻现有数据库中的偏见 | 脸部图像数据集 | 性别、种族、年龄偏见 | |
特定 语言型 | MozArt[ | 评估多语言模型是否对各语言中的人口群体同等公平 | 英语,西班牙语,德语和法语数据集 | 性别、语言偏见 |
| MIBs[ | 进行内隐偏见分析 | 英语,西班牙语,德语和法语数据集 | 性别、职业偏见 |
| 测试样本(随机) | 测量值d | ||||
|---|---|---|---|---|---|
| BERT | GPT | GPT-2 | |||
| C1 | 目标词对 | 花卉/昆虫 | 0.97 | 1.04 | 0.14 |
| 属性词对 | 令人愉快/不愉快 | ||||
| C3 | 目标词对 | 东亚/非裔名字 | 0.44 | -0.11 | -0.19 |
| 属性词对 | 令人愉快/不愉快 | ||||
| C6 | 目标词对 | 男性/女性名字 | 0.92 | 0.19 | 0.36 |
| 属性词对 | 职业/家庭 | ||||
| C7 | 目标词对 | 数学/艺术 | 0.41 | 0.24 | -0.01 |
| 属性词对 | 男性/女性术语 | ||||
| C10 | 目标词对 | 老年/年轻人名字 | -0.01 | 0.07 | -0.16 |
| 属性词对 | 令人愉快/不愉快 | ||||
表3 基于CEAT基准评估模型偏见的示例
Tab. 3 Examples of using CEAT benchmarks to evaluate model biases
| 测试样本(随机) | 测量值d | ||||
|---|---|---|---|---|---|
| BERT | GPT | GPT-2 | |||
| C1 | 目标词对 | 花卉/昆虫 | 0.97 | 1.04 | 0.14 |
| 属性词对 | 令人愉快/不愉快 | ||||
| C3 | 目标词对 | 东亚/非裔名字 | 0.44 | -0.11 | -0.19 |
| 属性词对 | 令人愉快/不愉快 | ||||
| C6 | 目标词对 | 男性/女性名字 | 0.92 | 0.19 | 0.36 |
| 属性词对 | 职业/家庭 | ||||
| C7 | 目标词对 | 数学/艺术 | 0.41 | 0.24 | -0.01 |
| 属性词对 | 男性/女性术语 | ||||
| C10 | 目标词对 | 老年/年轻人名字 | -0.01 | 0.07 | -0.16 |
| 属性词对 | 令人愉快/不愉快 | ||||
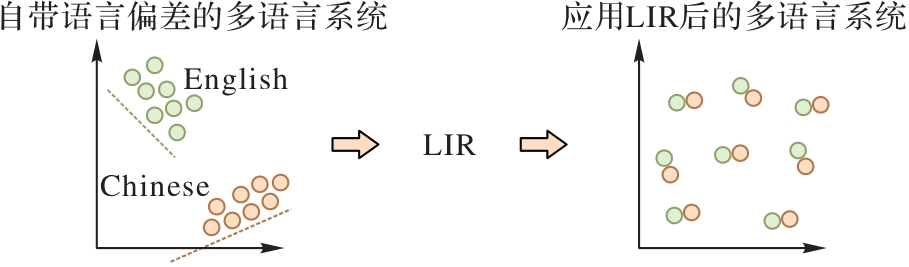
图3 LIR前后的多语言系统
Fig. 3 Multi-lingual system before and after LIR
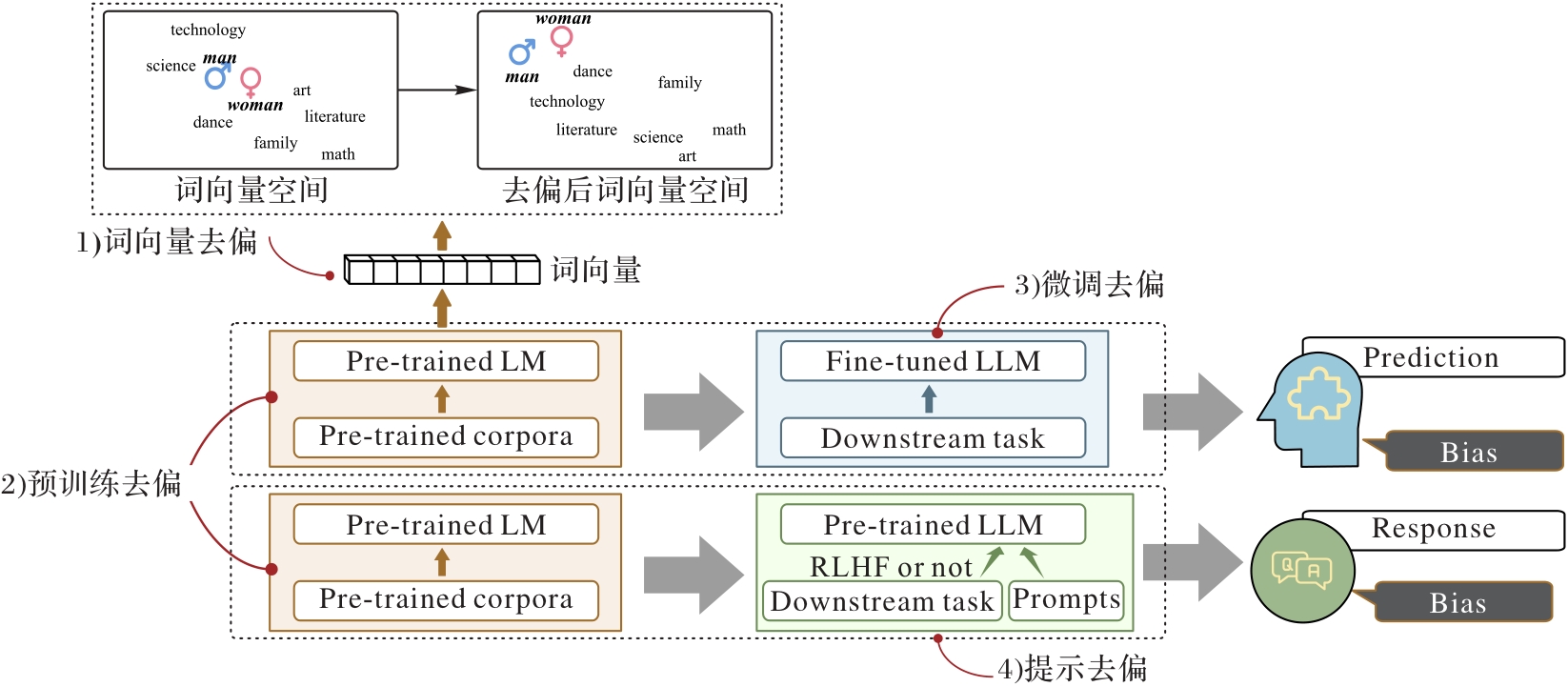
图4 模型去偏方法分类
Fig. 4 Classification of model bias mitigation methods
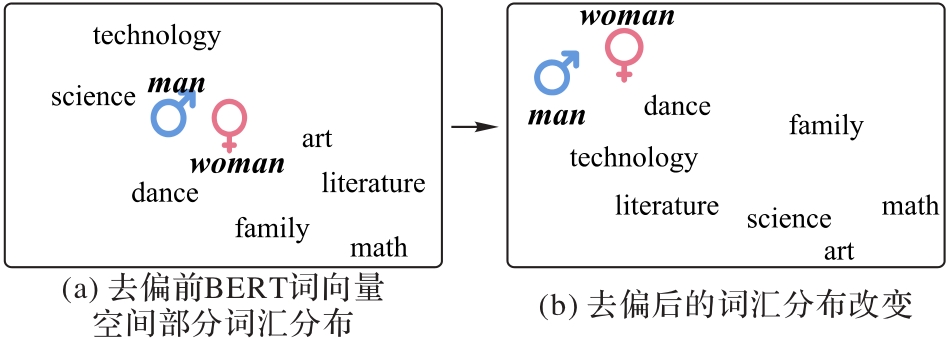
图5 基于词向量表示的去偏
Fig. 5 Word vector representation based bias mitigation
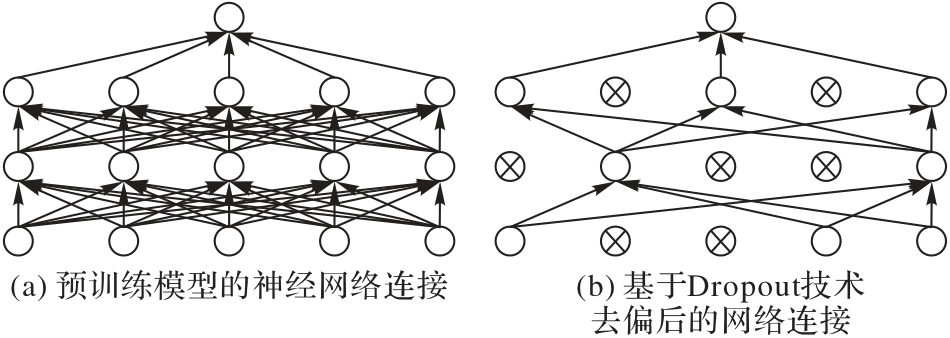
图6 预训练去偏
Fig. 6 Pre-training based bias mitigation
| 1 | NAVEED H, KHAN A U, QIU S, et al. A comprehensive overview of large language models [EB/OL]. [2024-02-07]. . |
| 2 | STEINBOCK B. Speciesism and the idea of equality [J]. Philosophy, 1978, 53(204): 247-256. |
| 3 | GALLEGOS I O, ROSSI R A, BARROW J, et al. Bias and fairness in large language models: a survey [J]. Computational Linguistics, 2024, 50(3): 1097-1179. |
| 4 | ALEXANDER L. What makes wrongful discrimination wrong? Biases, preferences, stereotypes, and proxies [J]. University of Pennsylvania Law Review, 1992, 141(1): 149-219. |
| 5 | BENDER E M, GEBRU T, McMILLAN-MAJOR A, et al. On the dangers of stochastic parrots: can language models be too big? [C]// Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. New York: ACM, 2021: 610-623. |
| 6 | DODGE J, SAP M, MARASOVIĆ A, et al. Documenting large webtext corpora: a case study on the colossal clean crawled corpus[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 1286-1305. |
| 7 | SHENG E, CHANG K W, NATARAJAN P, et al. Societal biases in language generation: progress and challenges [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4275-4293. |
| 8 | SURESH H, GUTTAG J. A framework for understanding sources of harm throughout the machine learning life cycle [C]// Proceedings of the 1st ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization. New York: ACM, 2021: No.17. |
| 9 | KORDZADEH N, GHASEMAGHAEI M. Algorithmic bias: review, synthesis, and future research directions [J]. European Journal of Information Systems, 2022, 31(3): 388-409. |
| 10 | BOLUKBASI T, CHANG K W, ZOU Y, et al. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 4356-4364. |
| 11 | AHN J, OH A. Mitigating language-dependent ethnic bias in BERT [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 533-549. |
| 12 | MOHAMMED A H, ALI A H. Survey of BERT (Bidirectional Encoder Representation Transformer) types [J]. Journal of Physics: Conference Series, 2021, 1963: No.012173. |
| 13 | LIANG P P, LI I M, ZHENG E, et al. Towards debiasing sentence representations [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5502-5515. |
| 14 | FERRARA E. Should ChatGPT be biased? Challenges and risks of bias in large language models [J]. First Monday, 2023, 28(11): No.13346. |
| 15 | KOROTEEV M V. BERT: a review of applications in natural language processing and understanding [EB/OL]. [2024-03-07].. |
| 16 | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2024-11-07]. . |
| 17 | TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models [EB/OL]. [2024-07-07]. . |
| 18 | NIELSEN D S, ENEVOLDSEN K, SCHNEIDER-KAMP P. Encoder vs decoder: comparative analysis of encoder and decoder language models on multilingual NLU tasks [EB/OL]. [2024-07-01]. . |
| 19 | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools [EB/OL]. [2023-11-11]. . |
| 20 | LI J, ZHAO R, YANG Y, et al. OverPrompt: enhancing ChatGPT through efficient in-context learning [EB/OL]. [2024-02-03]. . |
| 21 | XU Y, HU L, ZHAO J, et al. A survey on multilingual large language models: corpora, alignment, and bias [EB/OL]. [2024-10-17]. . |
| 22 | GAO L, BIDERMAN S, BLACK S, et al. The Pile: an 800GB dataset of diverse text for language modeling [EB/OL]. [2024-04-19]. . |
| 23 | BANDY J, VINCENT N. Addressing “documentation debt” in machine learning research: a retrospective datasheet for BookCorpus [EB/OL]. [2024-07-10]. . |
| 24 | LEA R. Google swallows 11,000 novels to improve AI’s conversation [EB/OL]. [2024-11-07]. . |
| 25 | RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text Transformer[J]. Journal of Machine Learning Research, 2020, 21: 1-67. |
| 26 | PENEDO G, MALARTIC Q, HESSLOW D, et al. The RefinedWeb dataset for falcon LLM: outperforming curated corpora with web data only [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 79155-79172. |
| 27 | DE VASSIMON MANELA D, ERRINGTON D, FISHER T, et al. Stereotype and skew: quantifying gender bias in pre-trained and fine-tuned language models [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 2232-2242. |
| 28 | WU S, DREDZE M. Are all languages created equal in multilingual BERT? [C]// Proceedings of the 5th Workshop on Representation Learning for NLP. Stroudsburg: ACL, 2020: 120-130. |
| 29 | WANG J, LIU Y, WANG X. Assessing multilingual fairness in pre-trained multimodal representations [C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 2681-2695. |
| 30 | KASSNER N, DUFTER P, SCHÜTZE H. Multilingual LAMA: investigating knowledge in multilingual pretrained language models[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 3250-3258. |
| 31 | LEVY S, JOHN N, LIU L, et al. Comparing biases and the impact of multilingual training across multiple language [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 10260-10280. |
| 32 | PIQUERAS L C, SØGAARD A. Are pretrained multilingual models equally fair across languages? [C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 3597-3605. |
| 33 | ABID A, FAROOQI M, ZOU J. Large language models associate Muslims with violence [J]. Nature Machine Intelligence, 2021, 3(6): 461-463. |
| 34 | TOUILEB S, ØVRELID L, VELLDAL E. Occupational biases in Norwegian and multilingual language models [C]// Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing. Stroudsburg: ACL, 2022: 200-211. |
| 35 | NAOUS T, RYAN M J, RITTER A, et al. Having beer after prayer? Measuring cultural bias in large language models [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 16366-16393. |
| 36 | WONGSO W, LUCKY H, SUHARTONO D. Pre-trained Transformer-based language models for Sundanese [J]. Journal of Big Data, 2022, 9: No.39. |
| 37 | ZHANG T, KISHORE V, WU F, et al. BERTScore: evaluating text generation with BERT [EB/OL]. [2024-11-27].. |
| 38 | LEITER C, LERTVITTAYAKUMJORN P, FOMICHEVA M, et al. Towards explainable evaluation metrics for machine translation[J]. Journal of Machine Learning Research, 2024, 25: 1-49. |
| 39 | CAO Y T, PRUKSACHATKUN Y, CHANG K W, et al. On the intrinsic and extrinsic fairness evaluation metrics for contextualized language representations [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 561-570. |
| 40 | SELLAM T, DAS D, PARIKH A, et al. BLEURT: learning robust metrics for text generation [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7881-7892. |
| 41 | YUAN W, NEUBIG G, LIU P. BARTScore: evaluating generated text as text generation [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 27263-27277. |
| 42 | SUN T, HE J, QIU X, et al. BERTScore is unfair: on social bias in language model-based metrics for text generation [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 3726-37394. |
| 43 | STANOVSKY G, SMITH N A, ZETTLEMOYER L. Evaluating gender bias in machine translation [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 1679-1684. |
| 44 | PARRISH A, CHEN A, NANGIA N, et al. BBQ: a hand-built bias benchmark for question answering [C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 2086-2105. |
| 45 | KOO R, LEE M, RAHEJA V, et al. Benchmarking cognitive biases in large language models as evaluators [C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 517-545. |
| 46 | CALISKAN A, BRYSON J J, NARAYANAN A. Semantics derived automatically from language corpora contain human-like biases [J]. Science, 2017, 356(6334): 183-186. |
| 47 | MAY C, WANG A, BORDIA S, et al. On measuring social biases in sentence encoders [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 622-628. |
| 48 | GUO W, CALISKAN A. Detecting emergent intersectional biases: Contextualized word embeddings contain a distribution of human-like biases [C]// Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. New York: ACM, 2021: 122-133. |
| 49 | ZHAO J, MUKHERJEE S, HOSSEINI S, et al. Gender bias in multilingual embeddings and cross-lingual transfer [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 2896-2907. |
| 50 | BANSAL S, GARIMELLA V, SUHANE A, et al. Debiasing multilingual word embeddings: a case study of three Indian languages [C]// Proceedings of the 32nd ACM Conference on Hypertext and Social Media. New York: ACM, 2021: 27-34. |
| 51 | NADEEM M, BETHKE A, REDDY S. StereoSet: measuring stereotypical bias in pretrained language models [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 5356-5371. |
| 52 | WANG A, SINGH A, MICHAEL J, et al. GLUE: a multi-task benchmark and analysis platform for natural language understanding [C]// Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Stroudsburg: ACL, 2018: 353-355. |
| 53 | NANGIA N, VANIA C, BHALERAO R, et al. CrowS-Pairs: a challenge dataset for measuring social biases in masked language models [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 1953-1967. |
| 54 | RUDINGER R, NARADOWSKY J, LEONARD B, et al. Gender bias in coreference resolution [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 8-14. |
| 55 | ZHAO J, WANG T, YATSKAR M, et al. Gender bias in coreference resolution: evaluation and debiasing methods [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 15-20. |
| 56 | KIRITCHENKO S, MOHAMMAD M. Examining gender and race bias in two hundred sentiment analysis systems [C]// Proceedings of the 7th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2018: 43-53. |
| 57 | COSTA-JUSSÀ M R, LI LIN P, ESPAÑA-BONET C. GeBioToolkit: automatic extraction of gender-balanced multilingual corpus of Wikipedia biographies [C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 4081-4088. |
| 58 | 朱述承, 刘鹏远. 伟大的男人和倔强的女人: 基于语料库的形容词性别偏度历时研究 [C]// 第19届中国计算语言学大会. 北京: 中国中文信息学会, 2020: 31-42. |
| ZHU S C, LIU P Y. Great males and stubborn females: diachronic study of corpus-based gendered skewness in Chinese adjectives [C]// Proceedings of the 19th Chinese National Conference on Computational Linguistics. Beijing: Chinese Information Processing Society of China, 2020: 31-42. | |
| 59 | DE-ARTEAGA M, ROMANOV A, WALLACH H, et al. Bias in bios: a case study of semantic representation bias in a high-stakes setting [C]// Proceedings of the 2019 Conference on Fairness, Accountability, and Transparency. New York: ACM, 2019: 120-128. |
| 60 | KÄRKKÄINEN K, JOO J. FairFace: face attribute dataset for balanced race, gender, and age for bias measurement and mitigation [C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 1547-1557. |
| 61 | LAUSCHER A, GLAVAŠ G. Are we consistently biased? Multidimensional analysis of biases in distributional word vectors[C]// Proceedings of the 8th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2019: 85-91. |
| 62 | NÉVÉOL A, DUPONT Y, BEZANÇON J, et al. French CrowS-Pairs: extending a challenge dataset for measuring social bias in masked language models to a language other than English [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 8521-8531. |
| 63 | TALAT Z, NÉVÉOL A, BIDERMAN S, et al. You reap what you sow: on the challenges of bias evaluation under multilingual settings [C]// Proceedings of BigScience Episode# 5 — Workshop on Challenges and Perspectives in Creating Large Language Models. Stroudsburg: ACL, 2022: 26-41. |
| 64 | RAVFOGEL S, ELAZAR Y, GONEN H, et al. Null it out: guarding protected attributes by iterative nullspace projection [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 7237-7256. |
| 65 | KANEKO M, BOLLEGALA D. Debiasing pre-trained contextualised embeddings [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 1256-1266. |
| 66 | YANG Z, YANG Y, CER D, et al. A simple and effective method to eliminate the self language bias in multilingual representations[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 5825-5832. |
| 67 | SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15: 1929-1958. |
| 68 | SCHRAMOWSKI P, TURAN C, ANDERSEN N, et al. Large pre-trained language models contain human-like biases of what is right and wrong to do [J]. Nature Machine Intelligence, 2022, 4(3): 258-268. |
| 69 | ZHOU F, MAO Y, YU L, et al. Causal-debias: unifying debiasing in pretrained language models and fine-tuning via causal invariant learning [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 4227-4241. |
| 70 | RANALDI L, RUZZETTI E S, VENDITTI D, et al. A trip towards fairness: bias and de-biasing in large language models[C]// Proceedings of the 13th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2024: 372-384. |
| 71 | HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. [2024-12-03]. . |
| 72 | LEI Z, QIAN D, CHEUNG W. Fast randomized low-rank adaptation of pre-trained language models with PAC regularization[C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 5236-5249. |
| 73 | DING Z, LIU K Z, PEETATHAWATCHAI P, et al. On fairness of low-rank adaptation of large models[EB/OL]. [2024-06-27].. |
| 74 | YANG N, KANG T, CHOI S J, et al. Mitigating biases for instruction-following language models via bias neurons elimination[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 9061-9073. |
| 75 | PANIGRAHI A, SAUNSHI N, ZHAO H, et al. Task-specific skill localization in fine-tuned language models [C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 27011-27033. |
| 76 | WANG X, WEN K, ZHANG Z, et al. Finding skill neurons in pre-trained transformer-based language models [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 11132-11152. |
| 77 | WANG A, RUSSAKOVSKY O. Overwriting pretrained bias with finetuning data [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 3934-3945. |
| 78 | LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 3730-3738. |
| 79 | GUO Y, YANG Y, ABBASI A. Auto-debias: debiasing masked language models with automated biased prompts [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 1012-1023. |
| 80 | MATTERN J, JIN Z, SACHAN M, et al. Understanding stereotypes in language models: towards robust measurement and zero-shot debiasing [EB/OL]. [2024-11-03]. . |
| 81 | SCHICK T, UDUPA S, SCHÜTZE H. Self-diagnosis and self-debiasing: a proposal for reducing corpus-based bias in NLP [J]. Transactions of the Association for Computational Linguistics, 2021, 9: 1408-1424. |
| 82 | RAZA S, BASHIR S R, SNEHA, et al. Addressing biases in the texts using an end-to-end pipeline approach [C]// Proceedings of the 2023 International Workshop on Algorithmic Bias in Search and Recommendation, CCIS 1840. Cham: Springer, 2023: 100-107. |
| 83 | HALLINAN S, LIU A, CHOI Y, et al. Detoxifying text with MaRCo: controllable revision with experts and anti-experts [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2023: 228-242. |
| 84 | PESARANGHADER A, VERMA N, BHARADWAJ M. GPT-DETOX: an in-context learning-based paraphraser for text detoxification [C]// Proceedings of the 2023 International Conference on Machine Learning and Applications. Piscataway: IEEE, 2023: 1528-1534. |
| 85 | Workshop BigScience. BLOOM: a 176B-parameter open-access multilingual language model [EB/OL]. [2024-12-01]. . |
| 86 | WENDLER C, VESELOVSKY V, MONEA G, et al. Do Llamas work in English? On the latent language of multilingual Transformers [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 15366-15394. |
| 87 | RAE J W, BORGEAUD S, CAI T, et al. Scaling language models: methods, analysis & insights from training Gopher [EB/OL]. [2024-06-07]. . |
| 88 | CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways [J]. Journal of Machine Learning Research, 2023, 24: 1-113. |
| 89 | CONNEAU A, KHANDELWAL K, GOYAL N, et al. Unsupervised cross-lingual representation learning at scale [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 8440-8451. |
| 90 | KREUTZER J, CASWELL I, WANG L, et al. Quality at a glance: an audit of web-crawled multilingual datasets [J]. Transactions of the Association for Computational Linguistics, 2022, 10:50-72. |
| 91 | SEN I, ASSENMACHER D, SAMORY M, et al. People make better edits: measuring the efficacy of LLM-generated counterfactually augmented data for harmful language detection[C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 10480-10504. |
| 92 | GOLDFARB-TARRANT S, LOPEZ A, BLANCO R, et al. Bias beyond English: counterfactual tests for bias in sentiment analysis in four languages [C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 4458-4468. |
| 93 | MISHRA A, NAYAK G, BHATTACHARYA S, et al. LLM-guided counterfactual data generation for fairer AI [C]// Companion Proceedings of the ACM on Web Conference 2024. New York: ACM, 2024: 1538-1545. |
| 94 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| 95 | LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| 96 | QIU H, DOU Z Y, WANG T, et al. Gender biases in automatic evaluation metrics for image captioning [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 8358-8375. |
| 97 | ZHANG Q, WANG Y, YU T, et al. RevisEval: improving LLM-as-a-judge via response-adapted references [EB/OL]. [2024-05-13]. . |
| 98 | BADSHAH S, SAJJAD H. Reference-guided verdict: LLMs-as-judges in automatic evaluation of free-form text [EB/OL]. [2024-06-15]. . |
| 99 | CHU Z, WANG Z, ZHANG W. Fairness in large language models: a taxonomic survey [J]. ACM SIGKDD Explorations Newsletter, 2024, 26(1): 34-48. |
| 100 | FENG S, PARK C Y, LIU Y, et al. From pretraining data to language models to downstream tasks: tracking the trails of political biases leading to unfair NLP models [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 11737-11762. |
| 101 | ZHAO R, ZHU Q, XU H, et al. Large language models fall short: understanding complex relationships in detective narratives[C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 7618-7638. |
| 102 | ZHAO Y, NASUKAWA T, MURAOKA M, et al. A simple yet strong domain-agnostic de-bias method for zero-shot sentiment classification [C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 3923-3931. |
| 103 | ORGAD H, BELINKOV Y. BLIND: bias removal with no demographics [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 8801-8821. |
| [1] | 秦小林, 古徐, 李弟诚, 徐海文. 大语言模型综述与展望[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 685-696. |
| [2] | 徐月梅, 胡玲, 赵佳艺, 杜宛泽, 王文清. 大语言模型的技术应用前景与风险挑战[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1655-1662. |
| [3] | 姜雨杉, 张仰森. 大语言模型驱动的立场感知事实核查[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3067-3073. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||