


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (3): 683-695.DOI: 10.11772/j.issn.1001-9081.2025030294
• 人工智能 • 下一篇
张昊洋, 张丽萍( ), 闫盛, 李娜, 张学飞
), 闫盛, 李娜, 张学飞
收稿日期:2025-03-24
修回日期:2025-06-27
接受日期:2025-06-30
发布日期:2025-07-18
出版日期:2026-03-10
通讯作者:
张丽萍
作者简介:张昊洋(2000—),男,内蒙古包头人,硕士研究生,主要研究方向:教育数据挖掘、智慧教育基金资助:
Haoyang ZHANG, Liping ZHANG(), Sheng YAN, Na LI, Xuefei ZHANG
Received:2025-03-24
Revised:2025-06-27
Accepted:2025-06-30
Online:2025-07-18
Published:2026-03-10
Contact:
Liping ZHANG
About author:ZHANG Haoyang, born in 2000, M. S. candidate. His research interests include educational data mining, smart education.Supported by:摘要:
知识图谱(KG)可从海量数据中提取并结构化表示先验知识,在智能系统的构建与应用中发挥着关键作用。知识图谱补全(KGC)旨在预测KG中缺失的三元组以提升完整性和可用性,通常涵盖编码环节与预测环节。然而,传统的KGC方法在编码环节存在难以有效利用额外信息与语义信息的问题,而在预测环节存在知识覆盖不完全及封闭世界问题,且先编码后预测的框架会受到嵌入表示形式和计算效率的限制。大语言模型(LLM)凭借丰富的知识和强大的理解力能够解决这些问题。因此,对面向知识图谱补全的大模型方法进行综述。首先,概述KG与LLM的基本概念及研究现状,并阐述KGC的流程;其次,将现有基于LLM的KGC方法从将LLM作为编码器、将LLM作为生成器以及基于提示引导三方面进行总结和梳理;最后,总结模型在不同数据集上的性能表现并探讨基于LLM的KGC研究面临的问题与挑战。
中图分类号:
张昊洋, 张丽萍, 闫盛, 李娜, 张学飞. 面向知识图谱补全的大模型方法综述[J]. 计算机应用, 2026, 46(3): 683-695.
Haoyang ZHANG, Liping ZHANG, Sheng YAN, Na LI, Xuefei ZHANG. Review of large language model methods for knowledge graph completion[J]. Journal of Computer Applications, 2026, 46(3): 683-695.
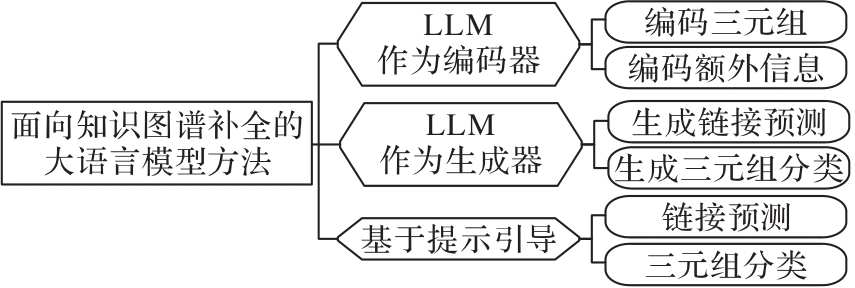
图1 面向知识图谱补全的大模型方法分类
Fig. 1 Classification of large language models methods for knowledge graph completion

图2 基于大语言模型的知识图谱补全的流程
Fig. 2 Flow of knowledge graph completion based on large language model
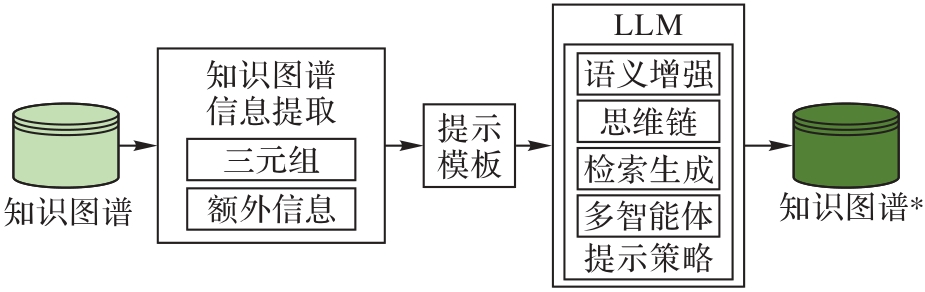
图3 基于提示引导的知识图谱补全方法的流程
Fig. 3 Flow of knowledge graph completion based on prompt guidance

图4 直接三元组编码
Fig. 4 Direct triple encoding
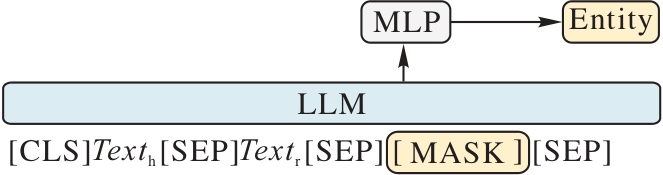
图5 掩码语言模型编码的流程
Fig. 5 Flow of masked language model encoding
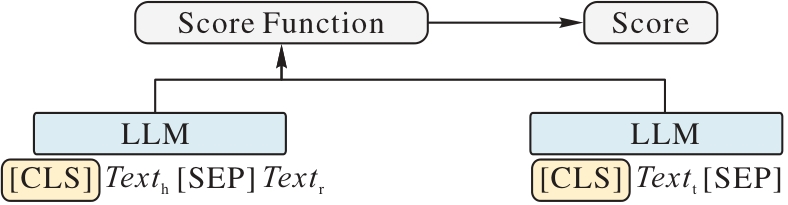
图6 分离编码
Fig. 6 Separated encoding
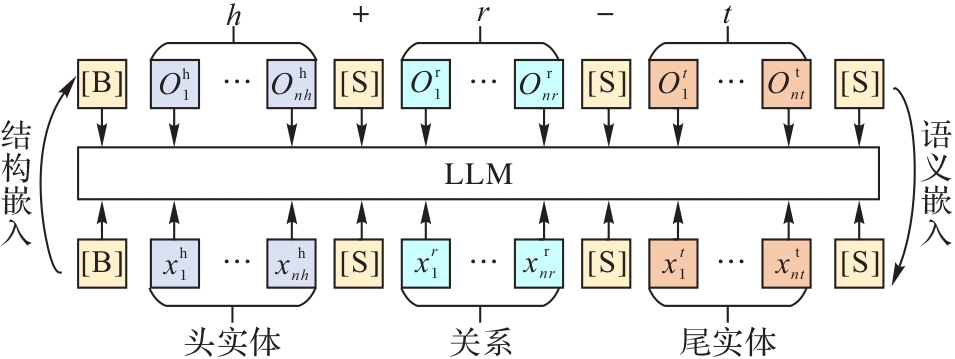
图7 LASS的框架
Fig. 7 LASS framework
| 编码对象 | 模型 | 优点 | 缺点 | |
|---|---|---|---|---|
| 三元组 | KG-BERT[ | 利用BERT语言建模能力提高了实体预测性能 | 依赖关系信息,难以处理低频相似实体 | |
| MTL-KGC[ | 多任务学习增强关系建模与词汇辨析能力 | 模型结构更复杂,训练成本较高 | ||
| PKGC[ | 通过提示句生成有效利用LLM中的隐含知识 | 依赖提示模板设计,生成质量对结果影响较大 | ||
| RPLLM[ | 仅依赖节点名称,适用于归纳实体预测设置 | 无法处理训练集中未出现过的关系类型 | ||
| FuseLinker[ | 融合文本、结构与领域知识提升链接预测性能 | 融合过程较复杂,计算和调参成本高 | ||
| MEM-KGC[ | 借助上下文掩码机制,有效处理未见实体预测 | 忽视知识图谱中关系结构信息 | ||
| LP-BERT[ | 融合多种掩码策略与对比学习增强三元组建模 | 仍主要适用于封闭世界,泛化能力有限 | ||
| OpenWorld KGC[ | 支持零样本学习,有效扩展知识图谱新实体 | 依赖复杂的多任务学习架构,训练难度较高 | ||
| StAR[ | 采用孪生编码结构结合语言与图信息提升扩展性与语义理解能力 | 结构信息建模较弱,依赖空间特征抽取的效果 | ||
| SimKGC[ | 利用关系感知对比学习策略提升实体表示能力 | 训练复杂度高,对负样本设计依赖较强 | ||
额外 信息 | 描述 | KEPLER[ | 通过多任务学习增强语言建模与知识提取能力 | 依赖长实体描述,限制在短文本图谱的适用性 |
| BLP[ | 训练目标简洁,实体表示具备良好迁移能力 | 任务信息有限,可能影响复杂语义建模 | ||
| 文献[ | 解耦实体表示并多策略提升适应性与扩展性 | 需协调多种表示与训练策略 | ||
| PDKGC[ | 无需微调LLM即可完成补全任务 | 受限于模板设计表达能力 | ||
| 结构 | LASS[ | 结合语义嵌入与结构重建提升补全性能 | 结构信息依赖损失建模,映射过程可能有误差 | |
| CSProm-KG[ | 通过条件软提示有效融合文本与结构信息 | 提示生成依赖知识嵌入质量,泛化能力受限 | ||
| 路径 | FTL-LM[ | 结合路径采样与逻辑蒸馏有效建模拓扑上下文 | 路径生成复杂,易引入噪声 | |
| RALM[ | 引入检索机制提升多标签链接预测效果 | 邻居信息利用有限,多跳推理能力较弱 | ||
| MGCS[ | 融合路径建模、自然语言转换与对比学习增强多跳语义理解 | 模型结构复杂,路径筛选与子图编码计算开销大 | ||
表1 基于大语言模型编码器的知识图谱补全方法
Tab. 1 Knowledge graph completion methods using large language models as encoders
| 编码对象 | 模型 | 优点 | 缺点 | |
|---|---|---|---|---|
| 三元组 | KG-BERT[ | 利用BERT语言建模能力提高了实体预测性能 | 依赖关系信息,难以处理低频相似实体 | |
| MTL-KGC[ | 多任务学习增强关系建模与词汇辨析能力 | 模型结构更复杂,训练成本较高 | ||
| PKGC[ | 通过提示句生成有效利用LLM中的隐含知识 | 依赖提示模板设计,生成质量对结果影响较大 | ||
| RPLLM[ | 仅依赖节点名称,适用于归纳实体预测设置 | 无法处理训练集中未出现过的关系类型 | ||
| FuseLinker[ | 融合文本、结构与领域知识提升链接预测性能 | 融合过程较复杂,计算和调参成本高 | ||
| MEM-KGC[ | 借助上下文掩码机制,有效处理未见实体预测 | 忽视知识图谱中关系结构信息 | ||
| LP-BERT[ | 融合多种掩码策略与对比学习增强三元组建模 | 仍主要适用于封闭世界,泛化能力有限 | ||
| OpenWorld KGC[ | 支持零样本学习,有效扩展知识图谱新实体 | 依赖复杂的多任务学习架构,训练难度较高 | ||
| StAR[ | 采用孪生编码结构结合语言与图信息提升扩展性与语义理解能力 | 结构信息建模较弱,依赖空间特征抽取的效果 | ||
| SimKGC[ | 利用关系感知对比学习策略提升实体表示能力 | 训练复杂度高,对负样本设计依赖较强 | ||
额外 信息 | 描述 | KEPLER[ | 通过多任务学习增强语言建模与知识提取能力 | 依赖长实体描述,限制在短文本图谱的适用性 |
| BLP[ | 训练目标简洁,实体表示具备良好迁移能力 | 任务信息有限,可能影响复杂语义建模 | ||
| 文献[ | 解耦实体表示并多策略提升适应性与扩展性 | 需协调多种表示与训练策略 | ||
| PDKGC[ | 无需微调LLM即可完成补全任务 | 受限于模板设计表达能力 | ||
| 结构 | LASS[ | 结合语义嵌入与结构重建提升补全性能 | 结构信息依赖损失建模,映射过程可能有误差 | |
| CSProm-KG[ | 通过条件软提示有效融合文本与结构信息 | 提示生成依赖知识嵌入质量,泛化能力受限 | ||
| 路径 | FTL-LM[ | 结合路径采样与逻辑蒸馏有效建模拓扑上下文 | 路径生成复杂,易引入噪声 | |
| RALM[ | 引入检索机制提升多标签链接预测效果 | 邻居信息利用有限,多跳推理能力较弱 | ||
| MGCS[ | 融合路径建模、自然语言转换与对比学习增强多跳语义理解 | 模型结构复杂,路径筛选与子图编码计算开销大 | ||
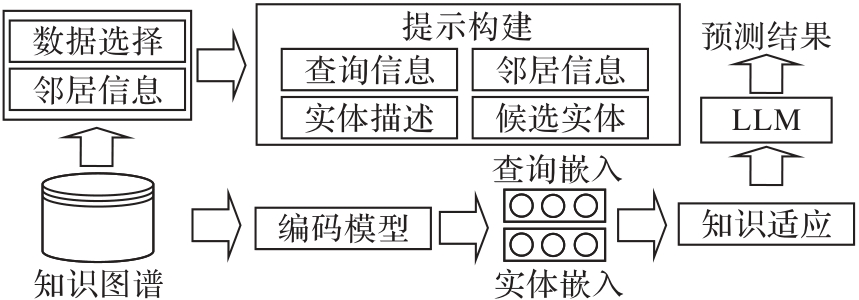
图8 DIFT框架
Fig. 8 DIFT framework
| 生成目标 | 模型 | 优点 | 缺点 | |
|---|---|---|---|---|
| 链接预测 | 实体或关系预测 | KGT5[ | 将补全转为生成任务,统一多任务处理 | 依赖实体描述,难处理缺失信息场景 |
| KG-S2S[ | 扁平化建模适应结构多样,预测能力强 | 忽略原始结构,语义一致性较弱 | ||
| GenKGC[ | 分层解码加速推理,建模语义交互 | 低频实体需额外约束 | ||
| DIFT[ | 结合判别指令降低实体对齐错误 | 需候选生成与微调,流程复杂 | ||
| 候选实体或关系排名 | KICGPT[ | 结合知识提示提升候选重排效果 | 易出现候选不匹配与遗漏问题 | |
| KC-GenRe[ | 引入交互训练与约束推理提升排序准确性 | 训练复杂,依赖标识符规范性 | ||
| 三元组集合预测 | GS-KGC[ | 结合子图信息增强生成上下文与推理能力 | 子图提取与负采样复杂,易引入冗余 | |
| LLM-TSPF[ | 融合规则挖掘与图划分指导生成预测 | 依赖规则质量,划分误差影响结果 | ||
| 三元组分类 | KoPA[ | 结构嵌入引入语言空间,提升三元组分类准确性 | 结构-文本映射复杂,虚拟标记依赖质量 | |
| KGValidator[ | 结合多源信息验证三元组有效性,提升评估效率 | 依赖上下文信息,复杂场景偏差可能较大 | ||
表2 将大语言模型作为生成器的知识图谱补全方法汇总
Tab. 2 Summary of knowledge graph completion methods using large language models as generators
| 生成目标 | 模型 | 优点 | 缺点 | |
|---|---|---|---|---|
| 链接预测 | 实体或关系预测 | KGT5[ | 将补全转为生成任务,统一多任务处理 | 依赖实体描述,难处理缺失信息场景 |
| KG-S2S[ | 扁平化建模适应结构多样,预测能力强 | 忽略原始结构,语义一致性较弱 | ||
| GenKGC[ | 分层解码加速推理,建模语义交互 | 低频实体需额外约束 | ||
| DIFT[ | 结合判别指令降低实体对齐错误 | 需候选生成与微调,流程复杂 | ||
| 候选实体或关系排名 | KICGPT[ | 结合知识提示提升候选重排效果 | 易出现候选不匹配与遗漏问题 | |
| KC-GenRe[ | 引入交互训练与约束推理提升排序准确性 | 训练复杂,依赖标识符规范性 | ||
| 三元组集合预测 | GS-KGC[ | 结合子图信息增强生成上下文与推理能力 | 子图提取与负采样复杂,易引入冗余 | |
| LLM-TSPF[ | 融合规则挖掘与图划分指导生成预测 | 依赖规则质量,划分误差影响结果 | ||
| 三元组分类 | KoPA[ | 结构嵌入引入语言空间,提升三元组分类准确性 | 结构-文本映射复杂,虚拟标记依赖质量 | |
| KGValidator[ | 结合多源信息验证三元组有效性,提升评估效率 | 依赖上下文信息,复杂场景偏差可能较大 | ||
| 任务 | 模型 | 优点 | 缺点 |
|---|---|---|---|
| 链接预测 | Contextualization Distillation[ | 生成上下文描述增强语义理解 | 生成文本需结构一致性 |
| MPIKGC[ | 多角度提示提升语义与结构理解 | 策略设计复杂,依赖提示质量 | |
| KG-RAG[ | 从文本提取信息补全图谱内容 | 实体抽取与整合易引入噪声 | |
| FrozenLLM-KGC[ | 中间层特征提升理解与分类性能 | 依赖提示上下文构造质量 | |
| CP-KGC[ | 上下文约束解决歧义,提升描述质量 | 清洗流程繁琐,信息易丢失 | |
| LLM-KGC-Topo[ | 中间推理增强可解释性与准确性 | 长序列推理易出错,缺少纠错机制 | |
| Think-on-Graph 2.0[ | 图文联合检索提升长程推理能力 | 迭代过程复杂,需大量外部信息 | |
| Auto-KG[ | 多智能体协作挖掘潜在关系 | 智能体协调复杂,成本较高 | |
| 三元组分类 | KG-LLM[ | 自然语言转化增强推理与分类能力 | 表达方式依赖模型语言理解能力 |
表3 基于提示引导的知识图谱补全方法汇总
Tab. 3 Summary of knowledge graph completion methods based on prompt guidance
| 任务 | 模型 | 优点 | 缺点 |
|---|---|---|---|
| 链接预测 | Contextualization Distillation[ | 生成上下文描述增强语义理解 | 生成文本需结构一致性 |
| MPIKGC[ | 多角度提示提升语义与结构理解 | 策略设计复杂,依赖提示质量 | |
| KG-RAG[ | 从文本提取信息补全图谱内容 | 实体抽取与整合易引入噪声 | |
| FrozenLLM-KGC[ | 中间层特征提升理解与分类性能 | 依赖提示上下文构造质量 | |
| CP-KGC[ | 上下文约束解决歧义,提升描述质量 | 清洗流程繁琐,信息易丢失 | |
| LLM-KGC-Topo[ | 中间推理增强可解释性与准确性 | 长序列推理易出错,缺少纠错机制 | |
| Think-on-Graph 2.0[ | 图文联合检索提升长程推理能力 | 迭代过程复杂,需大量外部信息 | |
| Auto-KG[ | 多智能体协作挖掘潜在关系 | 智能体协调复杂,成本较高 | |
| 三元组分类 | KG-LLM[ | 自然语言转化增强推理与分类能力 | 表达方式依赖模型语言理解能力 |
| 模型类别 | 模型 | FB15K-237 | WN18RR | ||||
|---|---|---|---|---|---|---|---|
| Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | ||
将大语言模型 作为编码器的 知识图谱 补全方法 | KG-BERT | — | 0.420 | — | — | 0.524 | — |
| MTL-KGC | 0.172 | 0.458 | 0.267 | 0.203 | 0.597 | 0.331 | |
| MEM-KGC | 0.266 | 0.576 | 0.341 | 0.428 | 0.658 | 0.505 | |
| LP-BERT | 0.223 | 0.490 | 0.310 | 0.343 | 0.752 | 0.482 | |
| StAR | 0.205 | 0.482 | 0.296 | 0.243 | 0.709 | 0.401 | |
| SimKGC | 0.249 | 0.511 | 0.336 | 0.587 | 0.800 | 0.666 | |
| BLP | 0.113 | 0.363 | 0.195 | 0.135 | 0.580 | 0.285 | |
| 文献[ | 0.287 | 0.564 | 0.377 | 0.531 | 0.742 | 0.600 | |
| PDKGC | 0.285 | 0.566 | 0.379 | 0.505 | 0.713 | 0.577 | |
| LASS | — | 0.527 | — | — | 0.769 | — | |
| CSProm-KG | 0.269 | 0.393 | 0.358 | 0.522 | 0.678 | 0.575 | |
| FTL-LM | 0.253 | 0.521 | 0.348 | 0.452 | 0.773 | 0.543 | |
将大语言模型 作为生成器的 知识图谱 补全方法 | KGT5 | 0.210 | 0.414 | 0.276 | 0.487 | 0.544 | 0.508 |
| KG-S2S | 0.257 | 0.498 | 0.336 | 0.531 | 0.661 | 0.574 | |
| KG-LLM | — | — | — | 0.315 | — | — | |
| DIFT | 0.364 | 0.586 | 0.439 | 0.569 | 0.708 | 0.617 | |
| KICGPT | 0.321 | 0.581 | 0.410 | 0.478 | 0.677 | 0.564 | |
| GS-KGC | 0.334 | — | — | 0.352 | — | — | |
基于提示引导的 知识图谱补全方法 | Contextualization Distillation | — | — | — | 0.526 | 0.672 | 0.576 |
| MPIKGC | 0.264 | 0.537 | 0.355 | 0.491 | 0.628 | 0.538 | |
| CP-KGC | 0.243 | 0.503 | 0.329 | 0.580 | 0.773 | 0.648 | |
表4 部分应用大语言模型进行知识图谱补全方法的链接预测结果
Tab. 4 Partial link prediction results of knowledge graph completion methods using large language models
| 模型类别 | 模型 | FB15K-237 | WN18RR | ||||
|---|---|---|---|---|---|---|---|
| Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | ||
将大语言模型 作为编码器的 知识图谱 补全方法 | KG-BERT | — | 0.420 | — | — | 0.524 | — |
| MTL-KGC | 0.172 | 0.458 | 0.267 | 0.203 | 0.597 | 0.331 | |
| MEM-KGC | 0.266 | 0.576 | 0.341 | 0.428 | 0.658 | 0.505 | |
| LP-BERT | 0.223 | 0.490 | 0.310 | 0.343 | 0.752 | 0.482 | |
| StAR | 0.205 | 0.482 | 0.296 | 0.243 | 0.709 | 0.401 | |
| SimKGC | 0.249 | 0.511 | 0.336 | 0.587 | 0.800 | 0.666 | |
| BLP | 0.113 | 0.363 | 0.195 | 0.135 | 0.580 | 0.285 | |
| 文献[ | 0.287 | 0.564 | 0.377 | 0.531 | 0.742 | 0.600 | |
| PDKGC | 0.285 | 0.566 | 0.379 | 0.505 | 0.713 | 0.577 | |
| LASS | — | 0.527 | — | — | 0.769 | — | |
| CSProm-KG | 0.269 | 0.393 | 0.358 | 0.522 | 0.678 | 0.575 | |
| FTL-LM | 0.253 | 0.521 | 0.348 | 0.452 | 0.773 | 0.543 | |
将大语言模型 作为生成器的 知识图谱 补全方法 | KGT5 | 0.210 | 0.414 | 0.276 | 0.487 | 0.544 | 0.508 |
| KG-S2S | 0.257 | 0.498 | 0.336 | 0.531 | 0.661 | 0.574 | |
| KG-LLM | — | — | — | 0.315 | — | — | |
| DIFT | 0.364 | 0.586 | 0.439 | 0.569 | 0.708 | 0.617 | |
| KICGPT | 0.321 | 0.581 | 0.410 | 0.478 | 0.677 | 0.564 | |
| GS-KGC | 0.334 | — | — | 0.352 | — | — | |
基于提示引导的 知识图谱补全方法 | Contextualization Distillation | — | — | — | 0.526 | 0.672 | 0.576 |
| MPIKGC | 0.264 | 0.537 | 0.355 | 0.491 | 0.628 | 0.538 | |
| CP-KGC | 0.243 | 0.503 | 0.329 | 0.580 | 0.773 | 0.648 | |
| [1] | SINGHAL A. Introducing the knowledge graph: things, not strings[R/OL]. [2025-03-02]. . |
| [2] | 高茂,张丽萍. 融合多模态资源的教育知识图谱的内涵、技术与应用研究[J]. 计算机应用研究, 2022, 39(8): 2257-2267. |
| GAO M, ZHANG L P. Research on connotation, technology and application of educational knowledge graph based on multi-modal resources [J]. Application Research of Computers, 2022, 39(8): 2257-2267. | |
| [3] | 梁佳,张丽萍,闫盛,等. 基于大语言模型的命名实体识别研究进展[J]. 计算机科学与探索, 2024, 18(10): 2594-2615. |
| LIANG J, ZHANG L P, YAN S, et al. Research progress of named entity recognition based on large language model [J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(10): 2594-2615. | |
| [4] | 赵宇博,张丽萍,闫盛,等. 个性化学习中学科知识图谱构建与应用综述[J]. 计算机工程与应用, 2023, 59(10): 1-21. |
| ZHAO Y B, ZHANG L P, YAN S, et al. Construction and application of discipline knowledge graph in personalized learning [J]. Computer Engineering and Applications, 2023, 59(10): 1-21. | |
| [5] | AUER S, BIZER C, KOBILAROV G, et al. DBpedia: a nucleus for a web of open data [C]// Proceedings of the 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, LNCS 4825. Berlin: Springer, 2007: 722-735. |
| [6] | SUCHANEK F M, KASNECI G, WEIKUM G. YAGO: a core of semantic knowledge [C]// Proceedings of the 16th International Conference on World Wide Web. New York: ACM, 2007: 697-706. |
| [7] | BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge [C]// Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2008: 1247-1250. |
| [8] | DONG X, GABRILOVICH E, HEITZ G, et al. Knowledge vault: a web-scale approach to probabilistic knowledge fusion [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 601-610. |
| [9] | CAO E, WANG D, HUANG J, et al. Open knowledge enrichment for long-tail entities [C]// Proceedings of the Web Conference 2020. New York: ACM, 2020: 384-394. |
| [10] | CHEN Z, WANG Y, ZHAO B, et al. Knowledge graph completion: a review [J]. IEEE Access, 2020, 8: 192435-192456. |
| [11] | BORDES A, USUNIER N, GARCIA-DURÁN A, et al. Translating embeddings for modeling multi-relational data [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Red Hook: Curran Associates Inc., 2013: 2787-2795. |
| [12] | LIANG X, SI G, LI J, et al. A survey of inductive knowledge graph completion [J]. Neural Computing and Applications, 2024, 36(8): 3837-3858. |
| [13] | OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 27730-27744. |
| [14] | DEHAL R S, SHARMA M, RAJABI E. Knowledge graphs and their reciprocal relationship with large language models [J]. Machine Learning and Knowledge Extraction, 2025, 7(2): No.38. |
| [15] | 黄勃,吴申奥,王文广,等. 图模互补:知识图谱与大模型融合综述[J]. 武汉大学学报(理学版), 2024, 70(4): 397-412. |
| HUANG B, WU S A, WANG W G, et al. KG-LLM-MCom: a survey on integration of knowledge graph and large language model[J]. Journal of Wuhan University (Natural Science Edition), 2024, 70(4): 397-412. | |
| [16] | PAN S, LUO L, WANG Y, et al. Unifying large language models and knowledge graphs: a roadmap [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(7): 3580-3599. |
| [17] | 曾泽凡,胡星辰,成清,等. 基于预训练语言模型的知识图谱研究综述[J]. 计算机科学, 2025, 52(1): 1-33. |
| ZENG Z F, HU X C, CHENG Q, et al. Survey of research on knowledge graph based on pre-trained language models [J]. Computer Science, 2025, 52(1): 1-33. | |
| [18] | 曹荣荣,柳林,于艳东,等. 融合知识图谱的大语言模型研究综述[J]. 计算机应用研究, 2025, 42(8): 2255-2266. |
| CAO R R, LIU L, YU Y D, et al. Review of large language models integrating knowledge graph [J]. Application Research of Computers, 2025, 42(8): 2255-2266. | |
| [19] | 张学飞,张丽萍,闫盛,等. 知识图谱与大语言模型协同的个性化学习推荐[J]. 计算机应用, 2025, 45(3): 773-784. |
| ZHANG X F, ZHANG L P, YAN S, et al. Personalized learning recommendation based in collaboration of knowledge graphs and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. | |
| [20] | 昂格鲁玛,王斯日古楞,斯琴图. 知识图谱补全研究综述[J]. 计算机科学与探索, 2025, 19(9): 2302-2318. |
| ANGGELUMA, WANG S, SI Q. Overview of research on knowledge graph completion [J]. Journal of Frontiers of Computer Science and Technology, 2025, 19(9): 2302-2318. | |
| [21] | LIN Y, LIU Z, SUN M, et al. Learning entity and relation embeddings for knowledge graph completion [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2015: 2181-2187. |
| [22] | BALAŽEVIĆ I, ALLEN C, HOSPEDALES T. TuckER: tensor factorization for knowledge graph completion [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 5185-5194. |
| [23] | DETTMERS T, MINERVENI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 1811-1818. |
| [24] | TROUILLON T, WELBL J, RIEDEL S, et al. Complex embeddings for simple link prediction [C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 2071-2080. |
| [25] | WU Y, WANG Z. Knowledge graph embedding with numeric attributes of entities [C]// Proceedings of the 3rd Workshop on Representation Learning for NLP. Stroudsburg: ACL, 2018: 132-136. |
| [26] | DAS R, NEELAKANTAN A, BELANGER D, et al. Chains of reasoning over entities, relations, and text using recurrent neural networks [C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. Stroudsburg: ACL, 2017: 132-141. |
| [27] | SHI B, WENINGER T. Open-world knowledge graph completion[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 1957-1964. |
| [28] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [29] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [30] | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. [2025-02-02]. . |
| [31] | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools [EB/OL]. [2025-02-23]. . |
| [32] | TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models [EB/OL]. [2025-02-11]. . |
| [33] | DeepSeek-AI. DeepSeek-R1: incentivizing reasoning capability in LLMs via reinforcement learning [EB/OL]. [2025-02-09]. . |
| [34] | DeepSeek-AI. DeepSeek-V3 technical report [R/OL]. [2025-03-14].. |
| [35] | 陈娟,赵新潮,隋京言,等. 故事启发大语言模型的时序知识图谱预测[J]. 模式识别与人工智能, 2024, 37(8): 715-728. |
| CHEN J, ZHAO X C, SUI J Y, et al. Narrative-driven large language model for temporal knowledge graph prediction [J]. Pattern Recognition and Artificial Intelligence, 2024, 37(8): 715-728. | |
| [36] | YAO L, MAO C, LUO Y. KG-BERT: BERT for knowledge graph completion [EB/OL]. [2025-01-23].. |
| [37] | KIM B, HONG T, KO Y, et al. Multi-task learning for knowledge graph completion with pre-trained language models [C]// Proceedings of the 28th International Conference on Computational Linguistics. Stroudsburg: ACL, 2020: 1737-1743. |
| [38] | LV X, LIN Y, CAO Y, et al. Do pre-trained models benefit knowledge graph completion? a reliable evaluation and a reasonable approach [C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 3570-3581. |
| [39] | ALQAAIDI S K, KOCHUT K J. Relations prediction for knowledge graph completion using large language models [C]// Proceedings of the 8th International Conference on Information Systems and Data Mining. New York: ACM, 2024: 122-127. |
| [40] | XIAO Y, ZHANG S, ZHOU H, et al. FuseLinker: leveraging LLM’s pre-trained text embeddings and domain knowledge to enhance GNN-based link prediction on biomedical knowledge graphs [J]. Journal of Biomedical Informatics, 2024, 158: No.104730. |
| [41] | SALAZAR J, LIANG D, NGUYEN T Q, et al. Masked language model scoring [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 2699-2712. |
| [42] | CHOI B, JANG D, KO Y. MEM-KGC: masked entity model for knowledge graph completion with pre-trained language model [J]. IEEE Access, 2021, 9: 132025-132032. |
| [43] | LI D, YI M, HE Y. LP-BERT: multi-task pre-training knowledge graph BERT for link prediction [EB/OL]. [2025-02-12]. . |
| [44] | CHOI B, KO Y. Knowledge graph extension with a pre-trained language model via unified learning method [J]. Knowledge-Based Systems, 2023, 262: No.110245. |
| [45] | LV X, HOU L, LI J, et al. Differentiating concepts and instances for knowledge graph embedding [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 1971-1979. |
| [46] | WANG B, SHEN T, LONG G, et al. Structure-augmented text representation learning for efficient knowledge graph completion[C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 1737-1748. |
| [47] | WANG L, ZHAO W, WEI Z, et al. SimKGC: simple contrastive knowledge graph completion with pre-trained language models[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 4281-4294. |
| [48] | XIE R, LIU Z, JIA J, et al. Representation learning of knowledge graphs with entity descriptions [C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2016: 2659-2665. |
| [49] | WANG X, GAO T, ZHU Z, et al. KEPLER: a unified model for knowledge embedding and pre-trained language representation [J]. Transactions of the Association for Computational Linguistics, 2021, 9: 176-194. |
| [50] | DAZA D, COCHEZ M, GROTH P. Inductive entity representations from text via link prediction [C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 798-808. |
| [51] | LOVELACE J, ROSÉ C. A framework for adapting pre-trained language models to knowledge graph completion [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 5937-5955. |
| [52] | GENG Y, CHEN J, ZENG Y, et al. Prompting disentangled embeddings for knowledge graph completion with pre-trained language model [J]. Expert Systems with Applications, 2025, 265: No.126175. |
| [53] | EHRLINGER L, WÖß W. Towards a definition of knowledge graphs [C]// Proceedings of the 12th International Conference on Semantic Systems: Posters and Demos Track. Aachen: CEUR-WS.org, 2016: No.4. |
| [54] | SHEN J, WANG C, GONG L, et al. Joint language semantic and structure embedding for knowledge graph completion [C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2021: 1965-1978. |
| [55] | CHEN C, WANG Y, SUN A, et al. Dipping PLMs sauce: bridging structure and text for effective knowledge graph completion via conditional soft prompting [C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 11489-11503. |
| [56] | NICKEL M, MURPHY K, TRESP V, et al. A review of relational machine learning for knowledge graphs [J]. Proceedings of the IEEE, 2016, 104(1): 11-33. |
| [57] | LIN Q, MAO R, LIU J, et al. Fusing topology contexts and logical rules in language models for knowledge graph completion[J]. Information Fusion, 2023, 90: 253-264. |
| [58] | LIN Y H, SHIEH H T, LIU C Y, et al. Retrieval-augmented language model for extreme multi-label knowledge graph link prediction [EB/OL]. [2025-03-12]. . |
| [59] | YANG F, YANG Z, COHEN W W. Differentiable learning of logical rules for knowledge base reasoning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 2316-2325. |
| [60] | WANG J, LI W, LUVEMBE A M, et al. Exploring multi-granularity contextual semantics for fully inductive knowledge graph completion [J]. Expert Systems with Applications, 2025, 260: No.125407. |
| [61] | CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways [J]. Journal of Machine Learning Research, 2023, 24: 1-113. |
| [62] | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| [63] | WANG C, ZHOU X, PAN S, et al. Exploring relational semantics for inductive knowledge graph completion [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 4184-4192. |
| [64] | SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 3104-3112. |
| [65] | SAXENA A, KOCHSIEK A, GEMULLA R. Sequence-to-sequence knowledge graph completion and question answering[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 2814-2828. |
| [66] | CHEN C, WANG Y, LI B, et al. Knowledge is flat: a Seq2Seq generative framework for various knowledge graph completion [C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 4005-4017. |
| [67] | XIE X, ZHANG N, LI Z, et al. From discrimination to generation: knowledge graph completion with generative Transformer [C]// Companion Proceedings of the Web Conference 2022. New York: ACM, 2022: 162-165. |
| [68] | LIU Y, TIAN X, SUN Z, et al. Finetuning generative large language models with discrimination instructions for knowledge graph completion [C]// Proceedings of the 2024 International Semantic Web Conference, LNCS 15231. Cham: Springer, 2025: 199-217. |
| [69] | WEI Y, HUANG Q, ZHANG Y, et al. KICGPT: large language model with knowledge in context for knowledge graph completion[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 8667-8683. |
| [70] | WANG Y, HU M, HUANG Z, et al. KC-GenRe: a knowledge-constrained generative re-ranking method based on large language models for knowledge graph completion [C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA and ICCL, 2024: 9668-9680. |
| [71] | ZHANG W, XU Y, YE P, et al. Start from zero: triple set prediction for automatic knowledge graph completion [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(11): 7087-7101. |
| [72] | YANG R, ZHU J, MAN J, et al. Exploiting large language models capabilities for question answer-driven knowledge graph completion across static and temporal domains [EB/OL]. [2024-11-14].. |
| [73] | YUAN Y, XU Y, ZHANG W. Is large language model good at triple set prediction? an empirical study [EB/OL]. [2025-02-15]. . |
| [74] | ZHANG Y, CHEN Z, GUO L, et al. Making large language models perform better in knowledge graph completion [C]// Proceedings of the 32nd ACM International Conference on Multimedia. New York: ACM, 2024: 233-242. |
| [75] | BOYLAN J, MANGLA S, THORN D, et al. KGValidator: a framework for automatic validation of knowledge graph construction[C]// Joint Proceedings of the 3rd International Workshop One Knowledge Graph Generation from Text and Data Quality Meets Machine Learning and Knowledge Graphs co-located with the Extended Semantic Web Conference. Aachen: CEUR-WS.org, 2024: No.5. |
| [76] | WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 24824-24837. |
| [77] | LI D, TAN Z, CHEN T, et al. Contextualization distillation from large language model for knowledge graph completion [C]// Findings of the Association for Computational Linguistics: EACL 2024. Stroudsburg: ACL, 2024: 458-477. |
| [78] | XU D, ZHANG Z, LIN Z, et al. Multi-perspective improvement of knowledge graph completion with large language models [C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA and ICCL, 2024: 11956-11968. |
| [79] | SANMARTÍN D. KG-RAG: bridging the gap between knowledge and creativity [EB/OL]. [2025-01-23].. |
| [80] | XUE B, XU Y, SONG Y, et al. Unlock the power of frozen LLMs in knowledge graph completion [EB/OL]. [2025-01-24].. |
| [81] | YANG R, ZHU J, MAN J, et al. Enhancing text-based knowledge graph completion with zero-shot large language models: a focus on semantic enhancement [J]. Knowledge-Based Systems, 2024, 300: No.112155. |
| [82] | SEHWAG U M, PAPASOTIRIOU K, VANN J, et al. In-context learning with topological information for LLM-based knowledge graph completion [EB/OL]. [2025-01-29].. |
| [83] | MA S, XU C, JIANG X, et al. Think-on-Graph 2.0: deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation [EB/OL]. [2025-03-14].. |
| [84] | ZHU Y, WANG X, CHEN J, et al. LLMs for knowledge graph construction and reasoning: recent capabilities and future opportunities [J]. World Wide Web, 2024, 27(5): No.58. |
| [85] | YAO L, PENG J, MAO C, et al. Exploring large language models for knowledge graph completion [C]// Proceedings of the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2025: 1-5. |
| [1] | 王日龙, 李振平, 李晓松, 高强, 何亚, 钟勇, 赵英潇. 多Agent协作的知识推理框架[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 708-714. |
| [2] | 吴定佳, 崔喆. 增强模式链接与多生成器协同的SQL生成框架MG-SQL[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 723-731. |
| [3] | 郗恩康, 范菁, 金亚东, 董华, 俞浩, 孙伊航. 联邦学习在隐私安全领域面临的威胁综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 798-808. |
| [4] | 黄奕明, 邹喜华, 邓果, 郑狄. 预回答与召回过滤:双阶段RAG问答系统优化方法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 696-707. |
| [5] | 沈斌, 陈晓宁, 程华, 房一泉, 王慧锋. 基于大语言模型的本科教学评估智能系统[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 993-1003. |
| [6] | 何金栋, 及宇轩, 陈天赐, 许恒铭, 耿技, 曹明生, 梁员宁. 基于知识图谱和大模型的非智能传感器的实体发现方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 354-360. |
| [7] | 高飞, 陈董, 边帝行, 范文强, 刘起东, 吕培, 张朝阳, 徐明亮. 面向学科撤销后科研人员重分配的多阶段耦合决策框架[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 416-426. |
| [8] | 王雪, 张丽萍, 闫盛, 李娜, 张学飞. 多模态知识图谱补全方法综述[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 341-353. |
| [9] | 王菲, 陶冶, 刘家旺, 李伟, 秦修功, 张宁. 面向智慧家庭空间的时空知识图谱的双模态融合构建方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 52-59. |
| [10] | 林怡, 夏冰, 王永, 孟顺达, 刘居宠, 张书钦. 基于AI智能体的隐藏RESTful API识别与漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 135-143. |
| [11] | 谢欣冉, 崔喆, 陈睿, 彭泰来, 林德坤. 基于层次过滤与标签语义扩展的大模型零样本重排序方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 60-68. |
| [12] | 刘超, 余岩化. 融合降噪策略与多视图对比学习的知识感知推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2827-2837. |
| [13] | 张滨滨, 秦永彬, 黄瑞章, 陈艳平. 结合大语言模型与动态提示的裁判文书摘要方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2783-2789. |
| [14] | 冯涛, 刘晨. 自动化偏好对齐的双阶段提示调优方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2442-2447. |
| [15] | 彭一峰, 朱焱. 结合预处理方法和对抗学习的公平链接预测[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2566-2571. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||