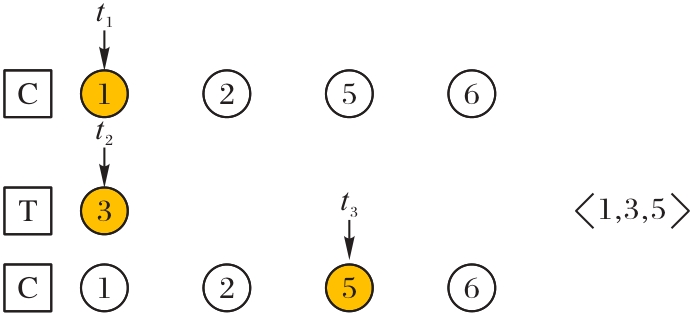
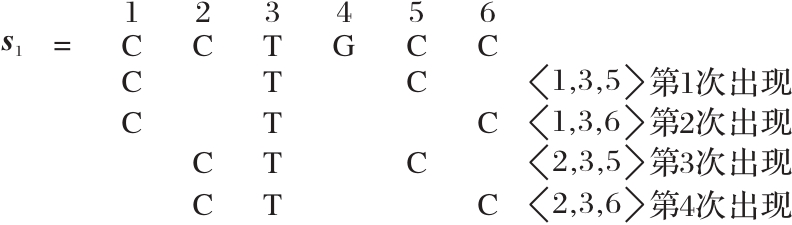| [1] |
LIU Y, WANG L, YANG P, et al. Mining interpretable regional co-location patterns based on urban functional region division [J]. Data Science and Engineering, 2024, 9(4): 464-485.
|
| [2] |
代震龙,韩萌,杨文艳,等. 序列模式挖掘综述[J]. 计算机应用, 2025, 45(7): 2056-2069.
|
|
DAI Z L, HAN M, YANG W Y, et al. Survey of sequential pattern mining [J]. Journal of Computer Applications, 2025, 45(7): 2056-2069.
|
| [3] |
LI Y, MA C, GAO R, et al. OPF-Miner: order-preserving pattern mining with forgetting mechanism for time series [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(12): 8981-8995.
|
| [4] |
YAN H, LI F, HSIEH M C, et al. High-utility sequential pattern mining in incremental database [J]. The Journal of Supercomputing, 2025, 81: No.81.
|
| [5] |
DONG X, QIU P, LU J, et al. Mining top-k useful negative sequential patterns via learning [J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(9): 2764-2778.
|
| [6] |
MIN F, ZHANG Z H, ZHAI W J, et al. Frequent pattern discovery with tri-partition alphabets [J]. Information Sciences, 2020, 507: 715-732.
|
| [7] |
孟玉飞,武优西,王珍,等. 对比保序模式挖掘算法[J]. 计算机应用, 2023, 43(12): 3740-3746.
|
|
MENG Y F, WU Y X, WANG Z, et al. Contrast order-preserving pattern mining algorithm [J]. Journal of Computer Applications, 2023, 43(12): 3740-3746.
|
| [8] |
FOURNIER-VIGER P, GAN W, WU Y, et al. Pattern mining: current challenges and opportunities [C]// Proceedings of the 2022 International Conference on Database Systems for Advanced Applications, LNCS 13248. Cham: Springer, 2022: 34-49.
|
| [9] |
GENG M, WU Y, LI Y, et al. RNP-Miner: repetitive nonoverlapping sequential pattern mining [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(9): 4874-4889.
|
| [10] |
GAN W, LIN J C W, FOURNIER-VIGER P, et al. A survey of parallel sequential pattern mining [J]. ACM Transactions on Knowledge Discovery from Data, 2019, 13(3): No.25.
|
| [11] |
SUN C, GONG Y, GUO Y, et al. SN-RNSP: mining self-adaptive nonoverlapping repetitive negative sequential patterns in transaction sequences [J]. Knowledge-Based Systems, 2024, 287: No.111449.
|
| [12] |
WU Y, WANG X, LI Y, et al. OWSP-Miner: self-adaptive one-off weak-gap strong pattern mining [J]. ACM Transactions on Management Information Systems, 2022, 13(3): No.25.
|
| [13] |
CAI S, CHEN J, CHEN H, et al. An efficient anomaly detection method for uncertain data based on minimal rare patterns with the consideration of anti-monotonic constraints [J]. Information Sciences, 2021, 580: 620-642.
|
| [14] |
WU X, ZHU X, HE Y, et al. PMBC: pattern mining from biological sequences with wildcard constraints [J]. Computers in Biology and Medicine, 2013, 43(5): 481-492.
|
| [15] |
周忠玉,皮德常. 面向购物篮数据的稀有序列模式挖掘算法[J]. 小型微型计算机系统, 2019, 40(3): 683-688.
|
|
ZHOU Z Y, PI D C. Rare sequence pattern mining algorithm for shopping basket data [J]. Journal of Chinese Computer Systems, 2019, 40(3): 683-688.
|
| [16] |
JAYSAWAL B P, HUANG J W. PSP-AMS: progressive mining of sequential patterns across multiple streams[J]. ACM Transactions on Knowledge Discovery from Data, 2019, 13(1): No.5.
|
| [17] |
DONG X, GONG Y, CAO L. e-RNSP: An efficient method for mining repetition negative sequential patterns [J]. IEEE Transactions on Cybernetics, 2020, 50(5): 2084-2096.
|
| [18] |
LI Y, WANG Z, LIU J, et al. Mining repetitive negative sequential patterns with gap constraints [J]. ACM Transactions on Knowledge Discovery from Data, 2025, 19(4): No.86.
|
| [19] |
杨鸿茜,武优西,耿萌,等. 高效的一次性弱间隙序列模式挖掘算法[J]. 计算机工程, 2024, 50(3): 60-67.
|
|
YANG H X, WU Y X, GENG M, et al. Efficient one-off weak gap sequential pattern mining algorithm [J]. Computer Engineering, 2024, 50(3): 60-67.
|
| [20] |
SALETI S, SUBRAMANYAM R B V. A MapReduce solution for incremental mining of sequential patterns from big data [J]. Expert Systems with Applications, 2019, 133: 109-125.
|
| [21] |
HUANG G, GAN W, YU P S. TaSPM: targeted sequential pattern mining [J]. ACM Transactions on Knowledge Discovery from Data, 2024, 18(5): No.114.
|
| [22] |
GAN W, LIN J C W, ZHANG J, et al. Fast utility mining on sequence data [J]. IEEE Transactions on Cybernetics, 2021, 51(2): 487-500.
|
| [23] |
LI G, XIANG J, FANG W, et al. HUPSP-LAL: efficiently mining utility-driven sequential patterns in uncertain sequences[J]. Expert Systems with Applications, 2025, 270: No.126536.
|
| [24] |
WAN X, HAN X. Efficient top-k frequent itemset mining on massive data [J]. Data Science and Engineering, 2024, 9(2): 177-203.
|
| [25] |
LI Y, ZHANG S, GUO L, et al. NetNMSP: nonoverlapping maximal sequential pattern mining [J]. Applied Intelligence, 2022, 52(9): 9861-9884.
|
| [26] |
张洪泽,洪征,王辰,等. 基于闭合序列模式挖掘的未知协议格式推断方法[J]. 计算机科学, 2019, 46(6): 80-89.
|
|
ZHANG H Z, HONG Z, WANG C, et al. Closed sequential patterns mining based unknown protocol format inference method [J]. Computer Science, 2019, 46(6): 80-89.
|
| [27] |
雷雨,李曼,胡卫松,等. 高效的稀有序列模式挖掘方法[J]. 计算机科学与探索, 2015, 9(4): 429-437.
|
|
LEI Y, LI M, HU W S, et al. Efficient methods for rare sequential pattern mining [J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(4): 429-437.
|
| [28] |
ZHANG P, CHEN J, WAN S, et al. Targeted mining of rare high-utility patterns [C]// Proceedings of the 2022 IEEE International Conference on Big Data. Piscataway: IEEE, 2022: 6271-6280.
|
| [29] |
WANG T, DUAN L, DONG G, et al. Efficient mining of outlying sequence patterns for analyzing outlierness of sequence data [J]. ACM Transactions on Knowledge Discovery from Data, 2020, 14(5): No.62.
|
| [30] |
WU Y, LEI R, LI Y, et al. HAOP-Miner: self-adaptive high-average utility one-off sequential pattern mining [J]. Expert Systems with Applications, 2021, 184: No.115449.
|


 )
)