


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (3): 741-749.DOI: 10.11772/j.issn.1001-9081.2025040414
刘汉卿, 桑国明( ), 张益嘉
), 张益嘉
收稿日期:2025-04-18
修回日期:2025-06-25
接受日期:2025-06-26
发布日期:2025-07-03
出版日期:2026-03-10
通讯作者:
桑国明
作者简介:刘汉卿(2001—),男,山东济南人,硕士研究生,CCF会员,主要研究方向:遥感图像描述、多模态基金资助:
Hanqing LIU, Guoming SANG(), Yijia ZHANG
Received:2025-04-18
Revised:2025-06-25
Accepted:2025-06-26
Online:2025-07-03
Published:2026-03-10
Contact:
Guoming SANG
About author:LIU Hanqing, born in 2001, M. S. candidate. His research interests include remote sensing image captioning, multimodal.Supported by:摘要:
针对遥感图像描述任务中多尺度特征利用不足、纹理重复区域细节关联度低及多目标特征协同建模困难等问题,提出一种结合密集多尺度特征融合和特征知识增强Transformer的遥感图像描述模型DMFKF-T(Dense Multi-scale Feature and Knowledge Fusion Transformer)。设计密集多尺度特征融合模块(DMFFM),通过跨层级跳跃连接动态聚合不同尺度的特征图,同步捕获全局场景特征与局部细节信息;在解码阶段,引入语义融合增强(SFA)模块增强模型捕捉长距离依赖关系与理解上下文信息的能力,并结合离散余弦变换(DCT)的频率增强通道注意力机制分析频域特征的相关性,从而强化对复杂空间拓扑和非线性关系的建模能力。实验结果表明,在RSICD(Remote Sensing Image Captioning Dataset)上,与SD-RSIC(Summarization-driven Deep Remote Sensing Image Captioning)模型相比,DMFKF-T的BLEU-4(BiLingual Evaluation Understudy with 4-grams)和CIDEr(Consensus-based Image Description Evaluation)指标分别提升了8.6%和14.4%。可见,DMFKF-T可以准确地生成语义丰富的遥感图像描述语句。
中图分类号:
刘汉卿, 桑国明, 张益嘉. 结合密集多尺度特征融合和特征知识增强Transformer的遥感图像描述模型[J]. 计算机应用, 2026, 46(3): 741-749.
Hanqing LIU, Guoming SANG, Yijia ZHANG. Remote sensing image captioning model combining dense multi-scale feature fusion and feature knowledge-enhanced Transformer[J]. Journal of Computer Applications, 2026, 46(3): 741-749.
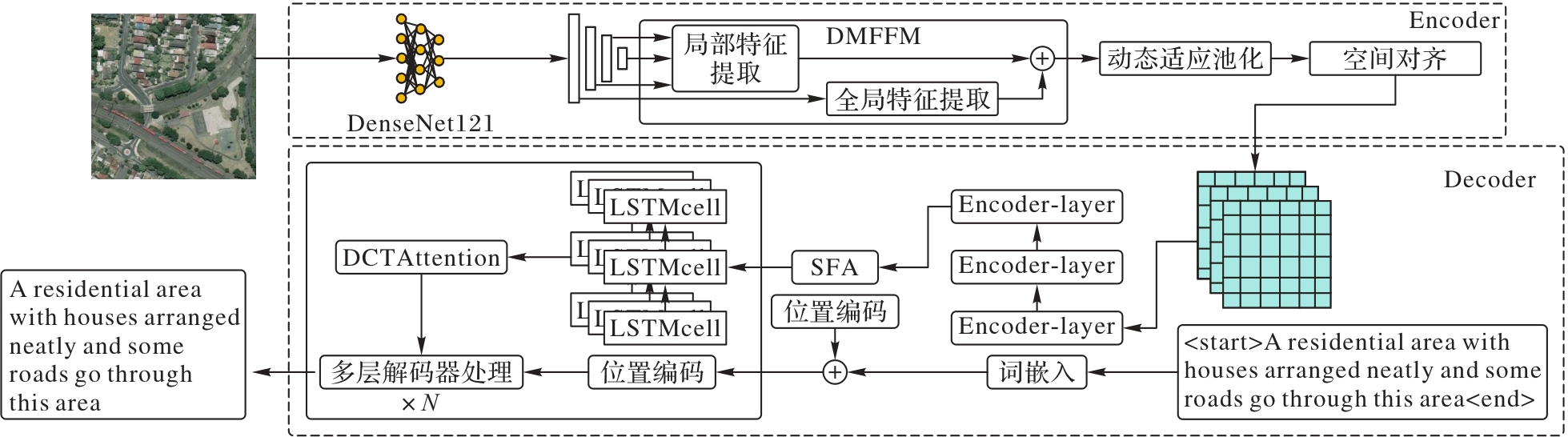
图1 DMFKF-T的整体结构
Fig. 1 Overall structure of DMFKF-T
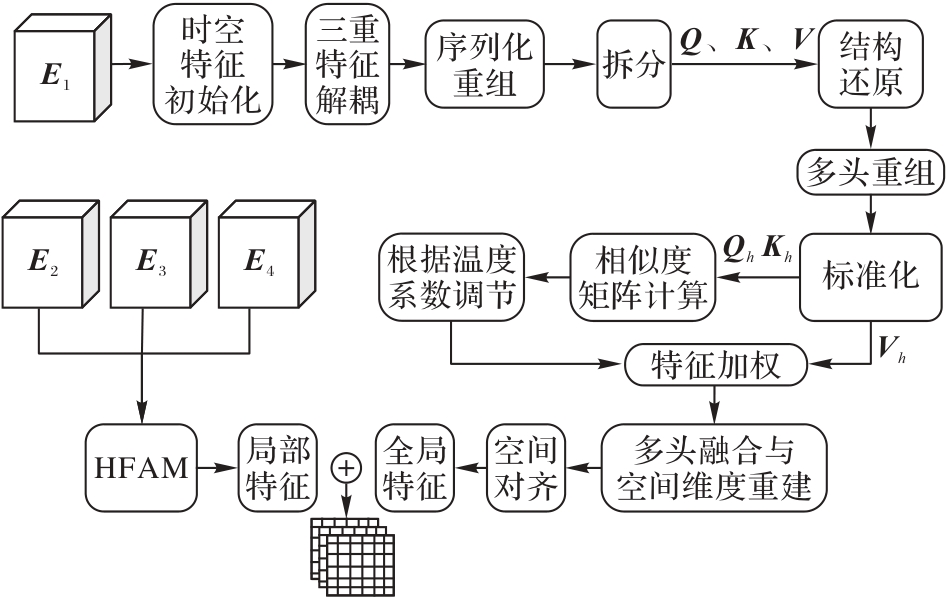
图2 DMFFM的结构
Fig. 2 Structure of DMFFM
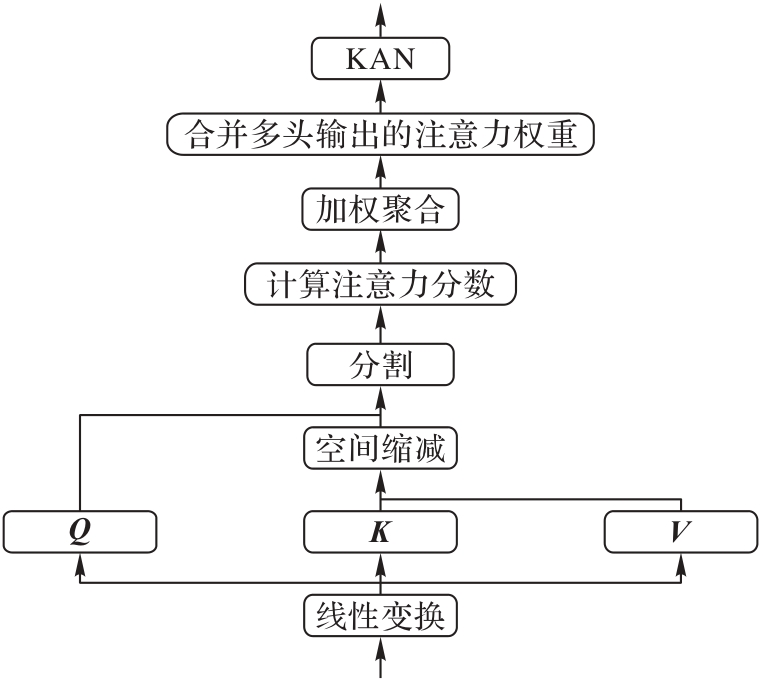
图3 SFA模块的结构
Fig. 3 Structure of SFA module
| 模型 | BLEU-1/% | BLEU-2/% | BLEU-3/% | BLEU-4/% | METEOR/% | ROUGE-L/% | CIDEr |
|---|---|---|---|---|---|---|---|
| VLAD-LSTM | 50.6 | 31.1 | 23.5 | 17.7 | 20.3 | 43.4 | 118.6 |
| VLAD-RNN | 49.3 | 30.8 | 22.4 | 16.6 | 19.6 | 42.3 | 103.4 |
| mRNN | 45.3 | 28.2 | 18.1 | 12.1 | 15.4 | 31.5 | 19.5 |
| mLSTM | 50.2 | 32.5 | 23.5 | 17.5 | 17.8 | 35.4 | 31.3 |
| mGRU | 42.7 | 30.0 | 23.0 | 18.0 | 19.3 | 37.8 | 125.0 |
| CSMLF | 57.7 | 38.7 | 28.9 | 22.3 | 21.3 | 44.4 | 53.0 |
| Sound-fa | 59.3 | 45.1 | 35.3 | 28.1 | 26.0 | 49.0 | 132.3 |
| SD-RSIC | 63.9 | 47.7 | 36.9 | 30.2 | 24.7 | 52.0 | 79.4 |
| SVM | 59.8 | 43.0 | 31.5 | 24.4 | 23.3 | 46.0 | 68.0 |
| Post-processing | 62.8 | 46.0 | 35.7 | 28.8 | 25.4 | 47.4 | 75.3 |
| DMFKF-T | 65.9 | 49.2 | 39.0 | 32.8 | 26.8 | 49.6 | 90.8 |
表1 不同模型在RSICD上的比较分析
Tab. 1 Comparative analysis of different models on RSICD
| 模型 | BLEU-1/% | BLEU-2/% | BLEU-3/% | BLEU-4/% | METEOR/% | ROUGE-L/% | CIDEr |
|---|---|---|---|---|---|---|---|
| VLAD-LSTM | 50.6 | 31.1 | 23.5 | 17.7 | 20.3 | 43.4 | 118.6 |
| VLAD-RNN | 49.3 | 30.8 | 22.4 | 16.6 | 19.6 | 42.3 | 103.4 |
| mRNN | 45.3 | 28.2 | 18.1 | 12.1 | 15.4 | 31.5 | 19.5 |
| mLSTM | 50.2 | 32.5 | 23.5 | 17.5 | 17.8 | 35.4 | 31.3 |
| mGRU | 42.7 | 30.0 | 23.0 | 18.0 | 19.3 | 37.8 | 125.0 |
| CSMLF | 57.7 | 38.7 | 28.9 | 22.3 | 21.3 | 44.4 | 53.0 |
| Sound-fa | 59.3 | 45.1 | 35.3 | 28.1 | 26.0 | 49.0 | 132.3 |
| SD-RSIC | 63.9 | 47.7 | 36.9 | 30.2 | 24.7 | 52.0 | 79.4 |
| SVM | 59.8 | 43.0 | 31.5 | 24.4 | 23.3 | 46.0 | 68.0 |
| Post-processing | 62.8 | 46.0 | 35.7 | 28.8 | 25.4 | 47.4 | 75.3 |
| DMFKF-T | 65.9 | 49.2 | 39.0 | 32.8 | 26.8 | 49.6 | 90.8 |
| 模型 | BLEU-1/% | BLEU-2/% | BLEU-3/% | BLEU-4/% | METEOR/% | ROUGE-L/% | CIDEr |
|---|---|---|---|---|---|---|---|
| Model1 | 64.1 | 47.0 | 36.4 | 29.4 | 25.2 | 48.3 | 82.5 |
| Model2 | 65.4 | 47.7 | 38.1 | 31.2 | 25.9 | 48.4 | 84.8 |
| Model3 | 65.6 | 48.6 | 38.8 | 31.9 | 26.3 | 48.8 | 86.9 |
| Model4 | 65.9 | 49.2 | 39.0 | 32.8 | 26.8 | 49.6 | 90.8 |
表2 消融实验结果
Tab. 2 Ablation experimental results
| 模型 | BLEU-1/% | BLEU-2/% | BLEU-3/% | BLEU-4/% | METEOR/% | ROUGE-L/% | CIDEr |
|---|---|---|---|---|---|---|---|
| Model1 | 64.1 | 47.0 | 36.4 | 29.4 | 25.2 | 48.3 | 82.5 |
| Model2 | 65.4 | 47.7 | 38.1 | 31.2 | 25.9 | 48.4 | 84.8 |
| Model3 | 65.6 | 48.6 | 38.8 | 31.9 | 26.3 | 48.8 | 86.9 |
| Model4 | 65.9 | 49.2 | 39.0 | 32.8 | 26.8 | 49.6 | 90.8 |

图4 DMFKF-T生成的描述、人工标注的描述和基线模型生成的描述的对比
Fig. 4 Comparison of descriptions generated by DMFKF-T, human-annotated descriptions, and descriptions generated by baseline model
| [1] | 任秋如,杨文忠,汪传建,等. 遥感影像变化检测综述[J]. 计算机应用, 2021, 41(8): 2294-2305. |
| REN Q R, YANG W Z, WANG C J, et al. Review of remote sensing image change detection[J]. Journal of Computer Applications, 2021, 41(8): 2294-2305. | |
| [2] | 邓棋,雷印杰,田锋. 用于肺炎图像分类的优化卷积神经网络方法[J]. 计算机应用, 2020, 40(1): 71-76. |
| DENG Q, LEI Y J, TIAN F. Optimized convolutional neural network method for classification of pneumonia images [J]. Journal of Computer Applications, 2020, 40(1): 71-76. | |
| [3] | CHANG S, GHAMISI P. Changes to captions: an attentive network for remote sensing change captioning [J]. IEEE Transactions on Image Processing, 2023, 32: 6047-6060. |
| [4] | ZHANG K, LI P, WANG J. A review of deep learning-based remote sensing image caption: methods, models, comparisons and future directions [J]. Remote Sensing, 2024, 16(21): No.4113. |
| [5] | SILVA J D, MAGALHÃES J, TUIA D, et al. Large language models for captioning and retrieving remote sensing images [EB/OL]. [2025-06-06].. |
| [6] | LeCUN Y, BENGIO Y, HINTON G. Deep learning [J]. Nature, 2015, 521(7553): 436-444. |
| [7] | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| [8] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2017: 6000-6010. |
| [9] | HOPFIELD J J. Neural networks and physical systems with emergent collective computational abilities [J]. Proceedings of the National Academy of Sciences of the United States of America, 1982, 79(8): 2554-2558. |
| [10] | ZHAO K, XIONG W. Exploring region features in remote sensing image captioning [J]. International Journal of Applied Earth Observation and Geoinformation, 2024, 127: No.103672. |
| [11] | WANG Q, YANG Z, NI W, et al. Semantic-spatial collaborative perception network for remote sensing image captioning [J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: No.5649912. |
| [12] | MENG L, WANG J, MENG R, et al. A multiscale grouping Transformer with CLIP latents for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: No.4703515. |
| [13] | ZHOU H, DU X, XIA L, et al. Self-learning for few-shot remote sensing image captioning [J]. Remote Sensing, 2022, 14(18): No.4606. |
| [14] | JIANG M, ZENG P, WANG K, et al. FECAM: frequency enhanced channel attention mechanism for time series forecasting[J]. Advanced Engineering Informatics, 2023, 58: No.102158. |
| [15] | LU X, WANG B, ZHENG X, et al. Exploring models and data for remote sensing image caption generation [J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183-2195. |
| [16] | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3156-3164. |
| [17] | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. |
| [18] | WANG C, GU X. Local-global visual interaction attention for image captioning [J]. Digital Signal Processing, 2022, 130: No.103707. |
| [19] | LI Y, ZHANG X, GU J, et al. Recurrent attention and semantic gate for remote sensing image captioning [J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: No.5608816. |
| [20] | CHENG K, WU Z, JIN H, et al. Remote sensing image captioning with multi-scale feature and small target attention [C]// Proceedings of the 2024 IEEE International Geoscience and Remote Sensing Symposium. Piscataway: IEEE, 2024: 7436-7439. |
| [21] | WANG W, XIE E, LI X, et al. Pyramid Vision Transformer: a versatile backbone for dense prediction without convolutions [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 548-558. |
| [22] | CHEN Z, WANG J, MA A, et al. TypeFormer: multi-scale Transformer with type controller for remote sensing image caption[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: No.6514005. |
| [23] | LIU C, ZHAO R, SHI Z. Remote-sensing image captioning based on multilayer aggregated Transformer [J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: No.6506605. |
| [24] | ZHAO J, WANG Y, ZHOU Y, et al. GLFRNet: global-local feature refusion network for remote sensing image instance segmentation [J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: No.5610112. |
| [25] | LIU Z, WANG Y, VAIDYA S, et al. KAN: Kolmogorov-Arnold networks [EB/OL]. [2025-06-06].. |
| [26] | 赵洋,桑国明,张益嘉. 结合特征图矫正和改进Transformer的地物遥感图像描述生成[J]. 小型微型计算机系统, 2025, 46(7): 1666-1673. |
| ZHAO Y, SANG G M, ZHANG Y J. Culture remote sensing image captioning based on feature map correction and improved Transformer [J]. Journal of Chinese Computer Systems, 2025, 46(7): 1666-1673. | |
| [27] | 姚志远,桑国明,张益嘉. 结合多尺度特征增强与记忆引导Transformer的遥感图像描述算法[J]. 小型微型计算机系统, 2025, 46(8): 1978-1985. |
| YAO Z Y, SANG G M, ZHANG Y J. Remote sensing image captioning algorithm based on multiscale feature enhancement and memory-guided Transformer [J]. Journal of Chinese Computer Systems, 2025, 46(8): 1978-1985. | |
| [28] | QU B, LI X, TAO D, et al. Deep semantic understanding of high resolution remote sensing image [C]// Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems. Piscataway: IEEE, 2016: 1-5. |
| [29] | LI X, YUAN A, LU X. Multi-modal gated recurrent units for image description [J]. Multimedia Tools and Applications, 2018, 77(22): 29847-29869. |
| [30] | WANG B, LU X, ZHENG X, et al. Semantic descriptions of high-resolution remote sensing images [J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(8): 1274-1278. |
| [31] | LU X, WANG B, ZHENG X. Sound active attention framework for remote sensing image captioning [J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(3): 1985-2000. |
| [32] | SUMBUL G, NAYAK S, DEMIR B. SD-RSIC: summarization-driven deep remote sensing image captioning [J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(8): 6922-6934. |
| [33] | HOXHA G, MELGANI F. A novel SVM-based decoder for remote sensing image captioning [J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-14. |
| [34] | HOXHA G, SCUCCATO G, MELGANI F. Improving image captioning systems with post-processing strategies [J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: No.5612013. |
| [1] | 段佳欣 胡靖 文武 余贞侠. 基于两阶段协同优化的全色锐化[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [2] | 姚华 杨高明 李雪莲 陆凯旋. 基于动态感知和交叉调制的遥感小目标检测[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [3] | 喻小芹 单武扬 邱骏颖 林宇 杨容浩 田茂. 亮度对比度扰动下的图像篡改定位检测网络[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [4] | 邢长征 郑鑫 贾迪 梁浚锋. 基于自适应注意力与感受野嵌套改进DeepLabV3+方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [5] | 杨静, 赵建斌, 陈路, 池浩田, 闫涛, 陈斌. 基于动态字典学习的含噪高光谱图像空谱融合[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2941-2948. |
| [6] | 刘澳龄, 单武扬, 邱骏颖, 田茂, 李军. 基于图像恢复和空间通道注意力的下采样图像取证网络[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1582-1588. |
| [7] | 周阳, 李辉. 基于语义和细节特征双促进的遥感影像建筑物提取网络[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1310-1316. |
| [8] | 张传浩, 屠晓涵, 谷学汇, 轩波. 基于多模态信息相互引导补充的雷达-相机三维目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 946-952. |
| [9] | 张众维, 王俊, 刘树东, 王志恒. 多尺度特征融合与加权框融合的遥感图像目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 633-639. |
| [10] | 刘赏, 周煜炜, 代娆, 董林芳, 刘猛. 融合注意力和上下文信息的遥感图像小目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 292-300. |
| [11] | 杨博然, 蔺素珍, 李大威, 禄晓飞, 崔晨辉. 基于信息补偿的红外弱小目标检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 284-291. |
| [12] | 周仿荣, 王一帆, 马仪, 文刚, 王国芳, 马御棠, 耿浩. 基于深度卷积网络的电力设施遥感图像融合增强模型[J]. 《计算机应用》唯一官方网站, 0, (): 212-216. |
| [13] | 王朋博, 单武扬, 李军, 田茂, 邹登, 范占锋. 抗高强度椒盐噪声的鲁棒拼接取证算法[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3177-3184. |
| [14] | 黄荣, 宋俊杰, 周树波, 刘浩. 基于自监督视觉Transformer的图像美学质量评价方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1269-1276. |
| [15] | 吴宁, 罗杨洋, 许华杰. 基于多尺度特征融合的遥感图像语义分割方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 737-744. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||