


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (5): 1433-1440.DOI: 10.11772/j.issn.1001-9081.2025050657
• 人工智能 • 上一篇
郑嘉丽1,2, 周刚1,2( ), 陈静1,2, 李顺航1,2
), 陈静1,2, 李顺航1,2
收稿日期:2025-06-16
修回日期:2025-07-16
接受日期:2025-07-23
发布日期:2025-08-12
出版日期:2026-05-10
通讯作者:
周刚
作者简介:郑嘉丽(2002—),女,河南郑州人,硕士研究生,主要研究方向:数据挖掘、自然语言处理、知识图谱
Jiali ZHENG1,2, Gang ZHOU1,2(), Jing CHEN1,2, Shunhang LI1,2
Received:2025-06-16
Revised:2025-07-16
Accepted:2025-07-23
Online:2025-08-12
Published:2026-05-10
Contact:
Gang ZHOU
About author:ZHENG Jiali, born in 2002, M. S. candidate. Her research interests include data mining, natural language processing, knowledge graph.摘要:
针对大语言模型(LLM)快速发展导致智能生成文本信息高度拟真、传统检测方法性能下降的问题,提出一种基于多特征自适应融合的智能生成文本检测方法。该方法首先构建涵盖文本统计特征、语言结构性特征及语言不确定性特征的语言风格特征集,捕捉真实文本与生成文本的差异;再利用独立编码技术提取文本的深层语义特征。在此基础上,设计一种双路映射特征自适应融合策略,先将语言风格特征与深层文本语义特征初步融合,再基于深度学习方法进行二次融合,增强特征自适应融合能力。实验结果表明:所提方法在中文SocialAI-Detect数据集与英文TuringBench数据集上的检测准确率分别达到98.1%和98.5%,与基线方法中性能表现最好的J-Guard(Journalism Guided adversarially robust detection of AI-generated news)相比,分别提升了2.3与2.1个百分点,验证了所提方法的有效性。
中图分类号:
郑嘉丽, 周刚, 陈静, 李顺航. 基于多特征自适应融合的智能生成文本检测方法[J]. 计算机应用, 2026, 46(5): 1433-1440.
Jiali ZHENG, Gang ZHOU, Jing CHEN, Shunhang LI. Adaptive multi-feature fusion detection method for AI-generated text[J]. Journal of Computer Applications, 2026, 46(5): 1433-1440.
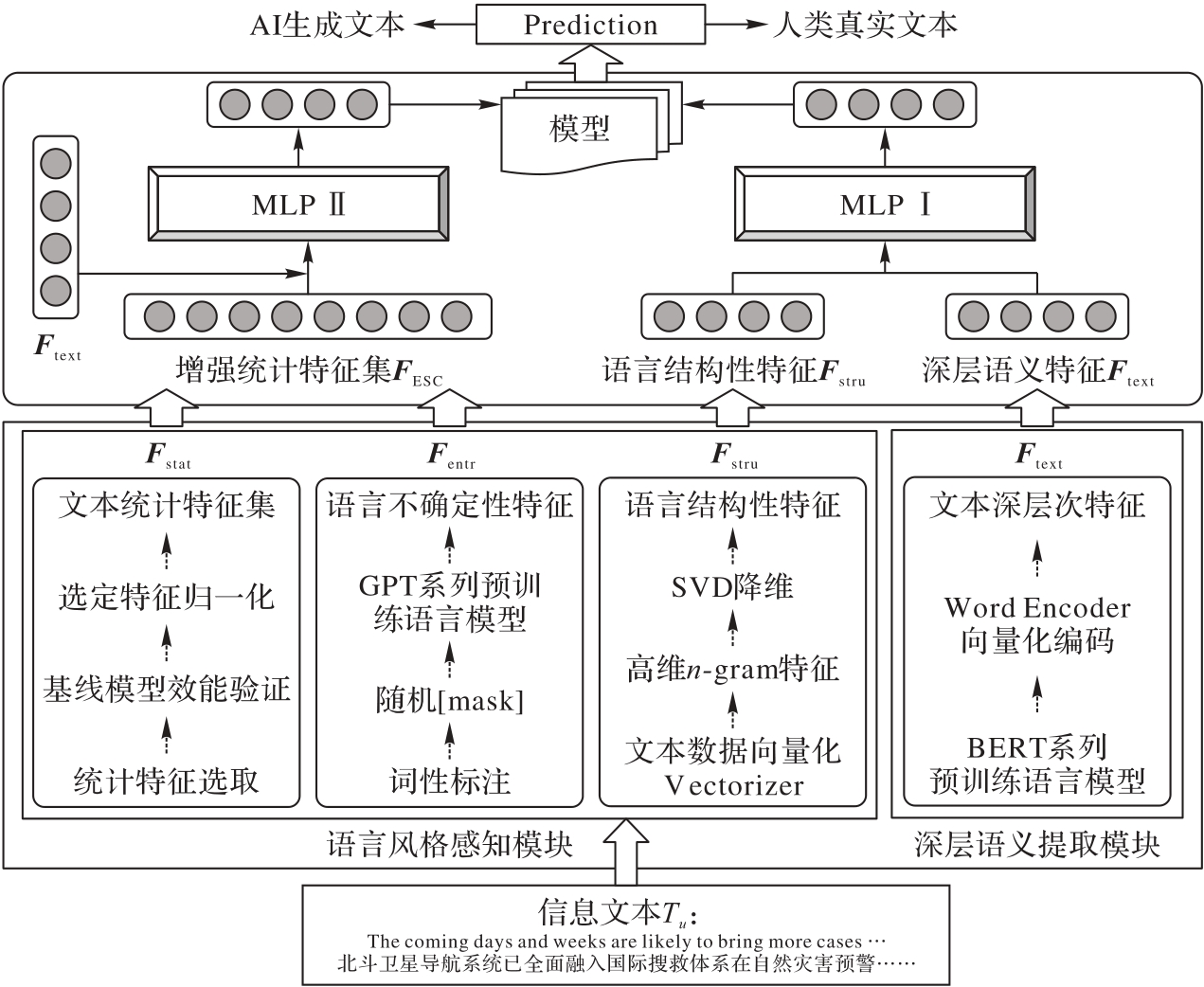
图1 本文方法的框架
Fig. 1 Framework of proposed method
| 特征 | 特征描述 |
|---|---|
| 字符数 | 表示文本中字符的总数 |
| 重复字符数 | 反映文本中字符重复程度 |
| 不重复字符数 | 反映文本多样性与词汇丰富度 |
| 不重复字符占比 | 反映文本不重复字符所占比例 |
| 原始字符长度 | 反映文本长度,生成文本可能因算法限制呈现某种规律 |
| 字符频率极值、平均值、标准差与极差 | 描述文本中字符出现频率的分布情况,捕捉文本隐含信息 |
表1 文本统计特征描述
Tab. 1 Description of text statistical features
| 特征 | 特征描述 |
|---|---|
| 字符数 | 表示文本中字符的总数 |
| 重复字符数 | 反映文本中字符重复程度 |
| 不重复字符数 | 反映文本多样性与词汇丰富度 |
| 不重复字符占比 | 反映文本不重复字符所占比例 |
| 原始字符长度 | 反映文本长度,生成文本可能因算法限制呈现某种规律 |
| 字符频率极值、平均值、标准差与极差 | 描述文本中字符出现频率的分布情况,捕捉文本隐含信息 |
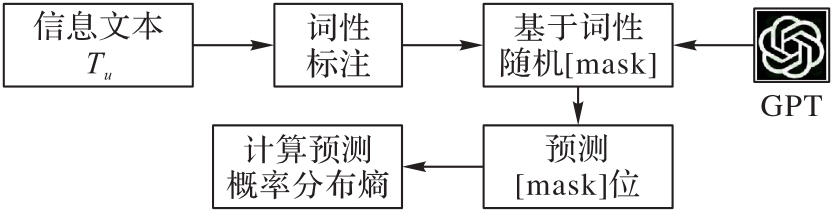
图2 基于词性偏好的预测熵计算流程
Fig. 2 Workflow of prediction entropy computation based on part-of-speech preferences
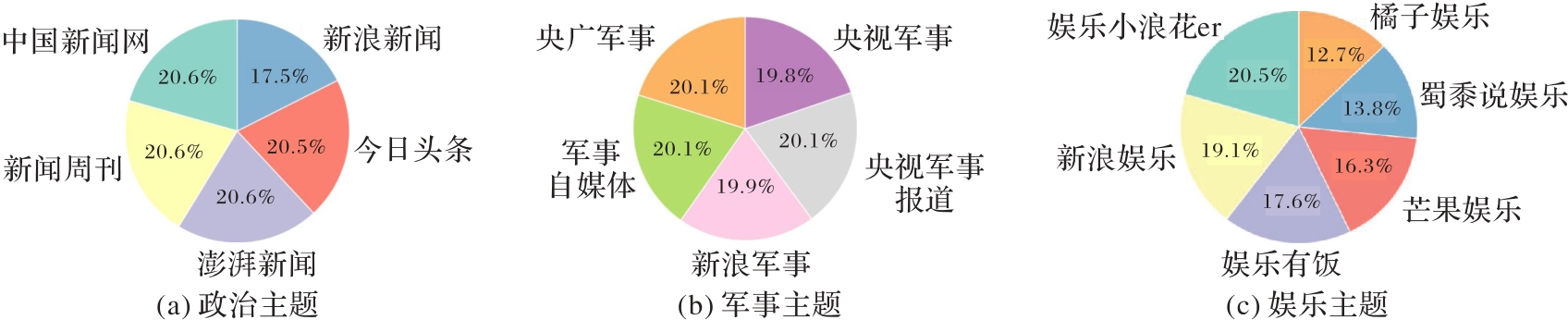
图3 官媒发布推文数据分布组合图
Fig. 3 Combination chart of data distribution for official media released tweets
| 主题 | Prompt提示语 |
|---|---|
| 政治 | 请你扮演一名[资深政治评论员][官方发言人],结合时事,模仿社交媒体上真实热门的推文风格,撰写一篇高度仿真的[政治]主题推文,要求内容仿真度高,语言风格贴近真实用户 |
| 军事 | 请你一名扮演[军事爱好达人][军事专家学者],结合时事,模仿社交媒体上真实热门的推文风格,撰写一条高度仿真的[军事]主题推文,要求内容仿真度高,语言风格贴近真实用户 |
| 娱乐 | 请你扮演一名[资深娱乐博主][娱乐记者],结合时事,模仿社交媒体上真实热门的推文风格,撰写一条高度仿真的[娱乐]主题推文,要求内容仿真度高,语言风格贴近真实用户 |
表2 不同主题的Prompt提示
Tab. 2 Prompts for different themes
| 主题 | Prompt提示语 |
|---|---|
| 政治 | 请你扮演一名[资深政治评论员][官方发言人],结合时事,模仿社交媒体上真实热门的推文风格,撰写一篇高度仿真的[政治]主题推文,要求内容仿真度高,语言风格贴近真实用户 |
| 军事 | 请你一名扮演[军事爱好达人][军事专家学者],结合时事,模仿社交媒体上真实热门的推文风格,撰写一条高度仿真的[军事]主题推文,要求内容仿真度高,语言风格贴近真实用户 |
| 娱乐 | 请你扮演一名[资深娱乐博主][娱乐记者],结合时事,模仿社交媒体上真实热门的推文风格,撰写一条高度仿真的[娱乐]主题推文,要求内容仿真度高,语言风格贴近真实用户 |
| 硬件 | 配置/值 | 硬件 | 配置/值 |
|---|---|---|---|
| GPU | RTX 4090 (24 GB) | 系统盘 | 30 GB |
| 内存 | 90 GB | 数据盘 | 50 GB |
表3 实验环境设置
Tab. 3 Experimental environment setting
| 硬件 | 配置/值 | 硬件 | 配置/值 |
|---|---|---|---|
| GPU | RTX 4090 (24 GB) | 系统盘 | 30 GB |
| 内存 | 90 GB | 数据盘 | 50 GB |
| 类别 | 方法 | TuringBench | SocialAI-Detect | ||
|---|---|---|---|---|---|
| ACC | AUROC | ACC | AUROC | ||
基于统计的 方法 | GLTR | 0.834 | 0.849 | 0.827 | 0.833 |
| LLMDet | 0.881 | 0.893 | 0.874 | 0.865 | |
机器学习 方法 | BERT-LR | 0.922 | 0.921 | 0.864 | 0.867 |
| BERT-SVM | 0.936 | 0.938 | 0.908 | 0.893 | |
| BERT-RF | 0.873 | 0.874 | 0.929 | 0.912 | |
深度学习 方法 | TextCNN | 0.835 | 0.868 | 0.873 | 0.893 |
| Bi-LSTM | 0.931 | 0.952 | 0.939 | 0.949 | |
| BiGRU | 0.929 | 0.934 | 0.918 | 0.941 | |
| DetectGPT | 0.967 | 0.958 | 0.942 | 0.928 | |
| PECOLA | 0.943 | 0.937 | 0.921 | 0.916 | |
| J-Guard | 0.964 | 0.968 | 0.958 | 0.961 | |
| 本文方法 | 0.985 | 0.982 | 0.981 | 0.979 | |
表4 本文方法与基线方法的性能对比
Tab. 4 Performance comparison between proposed method and baseline methods
| 类别 | 方法 | TuringBench | SocialAI-Detect | ||
|---|---|---|---|---|---|
| ACC | AUROC | ACC | AUROC | ||
基于统计的 方法 | GLTR | 0.834 | 0.849 | 0.827 | 0.833 |
| LLMDet | 0.881 | 0.893 | 0.874 | 0.865 | |
机器学习 方法 | BERT-LR | 0.922 | 0.921 | 0.864 | 0.867 |
| BERT-SVM | 0.936 | 0.938 | 0.908 | 0.893 | |
| BERT-RF | 0.873 | 0.874 | 0.929 | 0.912 | |
深度学习 方法 | TextCNN | 0.835 | 0.868 | 0.873 | 0.893 |
| Bi-LSTM | 0.931 | 0.952 | 0.939 | 0.949 | |
| BiGRU | 0.929 | 0.934 | 0.918 | 0.941 | |
| DetectGPT | 0.967 | 0.958 | 0.942 | 0.928 | |
| PECOLA | 0.943 | 0.937 | 0.921 | 0.916 | |
| J-Guard | 0.964 | 0.968 | 0.958 | 0.961 | |
| 本文方法 | 0.985 | 0.982 | 0.981 | 0.979 | |
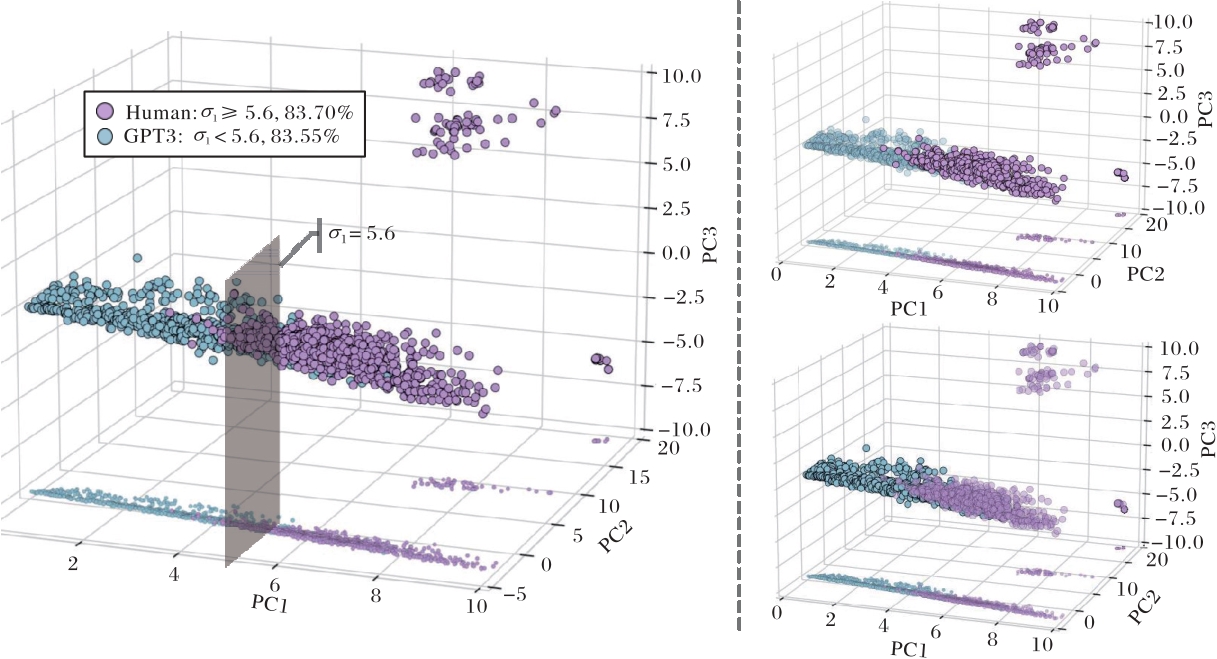
图4 英文数据集Fstru特征降维可视图
Fig. 4 Dimension-reduced visualization of feature Fstru for English dataset
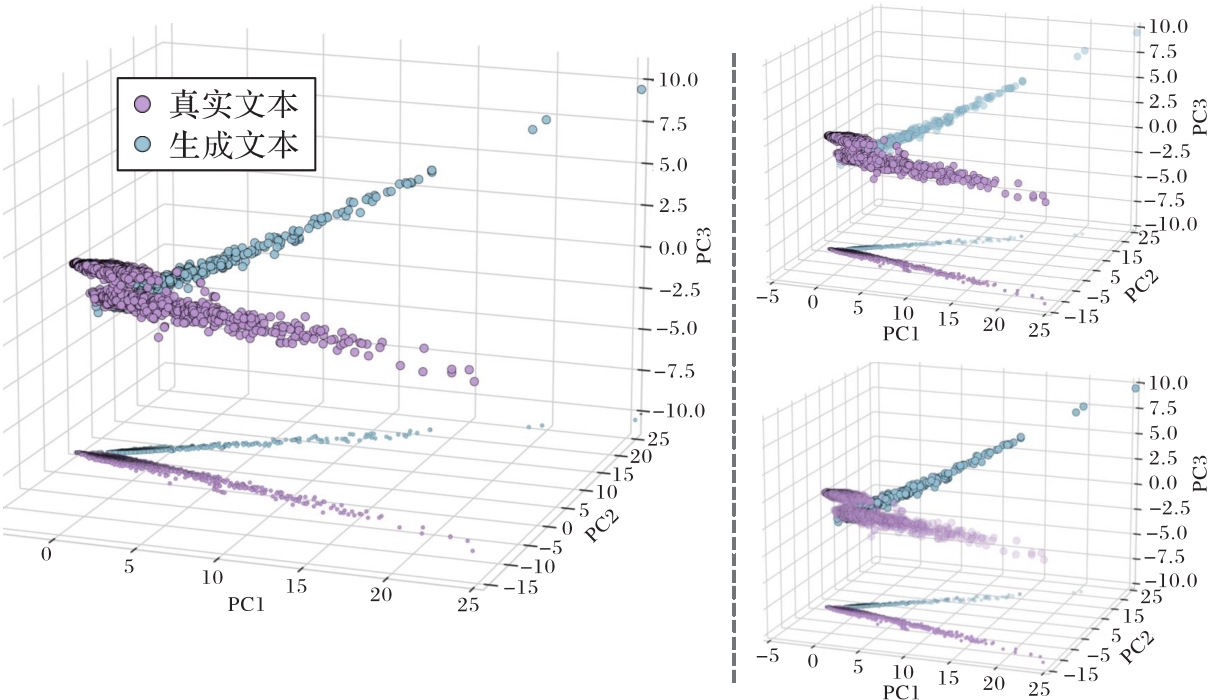
图5 中文数据集FESC特征降维可视图
Fig. 5 Dimension-reduced visualization of feature FESC for Chinese dataset
| 特征 | TuringBench | SocialAI-Detect |
|---|---|---|
| -w/o文本统计特征 | 0.954 9 | 0.940 3 |
| -w/o语言不确定性特征 | 0.927 1 | 0.934 7 |
| -w/o ESC融合特征集 | 0.910 3 | 0.901 8 |
表5 FESC子特征消融实验的检测准确率对比
Tab. 5 Comparison of detection accuracy in FESC sub-feature ablation experiments
| 特征 | TuringBench | SocialAI-Detect |
|---|---|---|
| -w/o文本统计特征 | 0.954 9 | 0.940 3 |
| -w/o语言不确定性特征 | 0.927 1 | 0.934 7 |
| -w/o ESC融合特征集 | 0.910 3 | 0.901 8 |
| 特征融合策略 | TuringBench | SocialAI-Detect | ||
|---|---|---|---|---|
| ACC | AUROC | ACC | AUROC | |
| 直接融合策略 | 0.963 | 0.962 | 0.960 | 0.957 |
| 双路特征映射融合策略 | 0.985 | 0.982 | 0.981 | 0.979 |
表6 不同数据集上不同融合策略性能对比
Tab. 6 Performance comparison of different fusion strategies on different datasets
| 特征融合策略 | TuringBench | SocialAI-Detect | ||
|---|---|---|---|---|
| ACC | AUROC | ACC | AUROC | |
| 直接融合策略 | 0.963 | 0.962 | 0.960 | 0.957 |
| 双路特征映射融合策略 | 0.985 | 0.982 | 0.981 | 0.979 |
| 序号 | 模型架构 | AUROC | ACC |
|---|---|---|---|
| 1 | BERT | 0.893 2 | 0.891 6 |
| 2 | +隐藏层 | 0.908 6 | 0.904 0 |
| 3 | +AEC+隐藏层 | 0.945 8 | 0.940 3 |
| 4 | +AEC+ normalize +隐藏层 | 0.932 8 | 0.933 1 |
| 5 | +扩维ESC+隐藏层 | 0.954 9 | 0.957 3 |
| 6 | ESC +隐藏层 | 0.951 0 | 0.956 7 |
| 7 | 扩维ESC +自注意力+隐藏层 | 0.900 8 | 0.914 4 |
| 8 | 扩维ESC +GAT+隐藏层 | 0.894 8 | 0.883 3 |
表7 F1融合策略性能对比
Tab. 7 Performance comparison of F1 fusion strategy
| 序号 | 模型架构 | AUROC | ACC |
|---|---|---|---|
| 1 | BERT | 0.893 2 | 0.891 6 |
| 2 | +隐藏层 | 0.908 6 | 0.904 0 |
| 3 | +AEC+隐藏层 | 0.945 8 | 0.940 3 |
| 4 | +AEC+ normalize +隐藏层 | 0.932 8 | 0.933 1 |
| 5 | +扩维ESC+隐藏层 | 0.954 9 | 0.957 3 |
| 6 | ESC +隐藏层 | 0.951 0 | 0.956 7 |
| 7 | 扩维ESC +自注意力+隐藏层 | 0.900 8 | 0.914 4 |
| 8 | 扩维ESC +GAT+隐藏层 | 0.894 8 | 0.883 3 |
| 序号 | 模型架构 | AUROC | ACC |
|---|---|---|---|
| 1 | BERT | 0.896 4 | 0.893 1 |
| 2 | +隐藏层 | 0.905 3 | 0.902 2 |
| 3 | +SVD+隐藏层 | 0.934 1 | 0.938 2 |
| 4 | + normalize_SVD+隐藏层 | 0.933 6 | 0.939 0 |
| 5 | +降维SVD+自注意力+隐藏层 | 0.889 8 | 0.875 0 |
| 6 | +SVD+GAT+隐藏层 | 0.906 6 | 0.911 5 |
| 7 | +降维SVD+隐藏层 | 0.897 2 | 0.901 3 |
表8 F2融合策略性能对比
Tab. 8 Performance comparison of F2 fusion strategy
| 序号 | 模型架构 | AUROC | ACC |
|---|---|---|---|
| 1 | BERT | 0.896 4 | 0.893 1 |
| 2 | +隐藏层 | 0.905 3 | 0.902 2 |
| 3 | +SVD+隐藏层 | 0.934 1 | 0.938 2 |
| 4 | + normalize_SVD+隐藏层 | 0.933 6 | 0.939 0 |
| 5 | +降维SVD+自注意力+隐藏层 | 0.889 8 | 0.875 0 |
| 6 | +SVD+GAT+隐藏层 | 0.906 6 | 0.911 5 |
| 7 | +降维SVD+隐藏层 | 0.897 2 | 0.901 3 |
| [1] | 罗文,王厚峰.大语言模型评测综述[J].中文信息学报,2024,38(1):1-23. |
| LUO W, WANG H F. Evaluating large language models: a survey of research progress[J]. Journal of Chinese Information Processing, 2024, 38(1): 1-23. | |
| [2] | 陈慧敏,刘知远,孙茂松.大语言模型时代的社会机遇与挑战[J].计算机研究与发展,2024,61(1):1094-1103. |
| CHEN H M, LIU Z Y, SUN M S. The social opportunities and challenges in the era of large language models[J]. Journal of Computer Research and Development, 2024, 61(1): 1094-1103. | |
| [3] | 漆晨航.生成式人工智能的虚假信息风险特征及其治理路径[J].情报理论与实践,2024,47(3):112-120. |
| QI C H. Research on the risks of disinformation from generative artificial intelligence and its governance paths[J]. Information Studies: Theory and Application, 2024, 47(3): 112-120. | |
| [4] | CINGILLIOGLU I. Detecting AI-generated essays: the ChatGPT challenge[J]. International Journal of Information and Learning Technology, 2023, 40(3): 259-268. |
| [5] | 蔺琛皓,沈超,邓静怡,等.虚假数字人脸内容生成与检测技术[J].计算机学报,2023,46(3):469-498. |
| LIN C H, SHEN C, DENG J Y, et al. Digitally forged face content creation and detection[J]. Chinese Journal of Computers, 2023, 46(3): 469-498. | |
| [6] | CHEN W, LIU B, GUAN W. ERNIE and multi-feature fusion for news topic classification[J]. Artificial Intelligence and Applications, 2024, 2(2): 135-140. |
| [7] | LIU A, PAN L, LU Y, et al. A survey of text watermarking in the era of large language models[J]. ACM Computing Surveys, 2025, 57(2): No.47. |
| [8] | WEBER-WULFF D, ANOHINA-NAUMECA A, BJELOBABA S, et al. Testing of detection tools for AI-generated text[J]. International Journal for Educational Integrity, 2023, 19: No.26. |
| [9] | WANG Y, MANSUROV J, IVANOV P, et al. M4GT-Bench: evaluation benchmark for black-box machine-generated text detection[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 3964-3992. |
| [10] | QAZI Z, SHIAO W, PAPALEXAKIS E E. GPT-generated text detection: benchmark dataset and tensor-based detection method[C]// Companion Proceedings of the ACM Web Conference 2024. New York: ACM, 2024: 842-846. |
| [11] | KUMARAGE T, BHATTACHARJEE A, PADEJSKI D, et al. J‑Guard: journalism guided adversarially robust detection of AI-generated news[C]// Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 484-497. |
| [12] | YANG Z, FENG Z, HUO R, et al. The Imitation Game revisited: a comprehensive survey on recent advances in AI-generated text detection[J]. Expert Systems with Applications, 2025, 272: No.126694. |
| [13] | TANG R, CHUANG Y N, HU X. The science of detecting LLM-generated text[J]. Communications of the ACM, 2024, 67(4): 50-59. |
| [14] | SU J, ZHUO T, WANG D, et al. DetectLLM: leveraging log rank information for zero-shot detection of machine-generated text[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 12395-12412. |
| [15] | YANG X, CHENG W, WU Y, et al. DNA-GPT: divergent N‑gram analysis for training-free detection of GPT-generated text[EB/OL]. [2024-12-27]. . |
| [16] | 项慧,薛鋆豪,郝玲昕. 基于语言特征集成学习的大语言模型生成文本检测[J]. 信息网络安全, 2024, 24(7): 1098-1109. |
| XIANG H, XUE Y H, HAO L X. Large language model-generated text detection based on linguistic feature ensemble learning[J]. Netinfo Security, 2024, 24(7): 1098-1109. | |
| [17] | MITCHELL E, LEE Y, KHAZATSKY A, et al. DetectGPT: zero-shot machine-generated text detection using probability curvature[C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 24950-24962. |
| [18] | COTTON D R E, COTTON P A, SHIPWAY J R. Chatting and cheating: ensuring academic integrity in the era of ChatGPT[J]. Innovations in Education and Teaching International, 2024, 61(2): 228-239. |
| [19] | KIRCHENBAUER J, GEIPING J, WEN Y, et al. A watermark for large language models[C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 17061-17084. |
| [20] | LIU Y, BU Y. Adaptive text watermark for large language models[C]// Proceedings of the 41st International Conference on Machine Learning. New York: JMLR.org, 2024: 30718-30737. |
| [21] | LI L, WANG P, REN K, et al. Origin tracing and detecting of LLMs[EB/OL]. [2025-02-09]. . |
| [22] | Workshop BigScience. BLOOM: a 176B-parameter open-access multilingual language model[EB/OL]. [2025-03-12].. |
| [23] | CROTHERS E, JAPKOWICZ N, VIKTOR H, et al. Adversarial robustness of neural-statistical features in detection of generative Transformers[C]// Proceedings of the 2022 International Joint Conference on Neural Networks. Piscataway: IEEE, 2022: 1-8. |
| [24] | 郑嘉丽.面向社交媒体的恶意账号检测技术研究[D].郑州:信息工程大学,2024:37-42. |
| ZHENG J L. Research on malicious account detection technology for social media[D]. Zhengzhou: Information Engineering University, 2024: 37-42. | |
| [25] | 范志武,姚金良.基于深度金字塔卷积神经网络的ChatGPT生成文本检测方法[J].数据分析与知识发现,2024,8(7):14-22. |
| FAN Z W, YAO J L. Detecting ChatGPT generated texts based on deep pyramid convolutional neural network[J]. Data Analysis and Knowledge Discovery, 2024, 8(7): 14-22. | |
| [26] | 刘冬,陈一民.基于Shapley加性解释的ChatGPT生成文本检测模型研究[J].计算机应用与软件,2024,41(10):212-220. |
| LIU D, CHEN Y M. ChatGPT generated text detection model based on Shapley additive explanations[J]. Computer Applications and Software, 2024, 41(10): 212-220. | |
| [27] | 帅奇,王海瑞,朱贵富.基于双向对比训练的中文故事结尾生成模型[J].计算机应用,2024,44(9):2683-2688. |
| SHUAI Q, WANG H R, ZHU G F. Chinese story ending generation model based on bidirectional contrastive training[J]. Journal of Computer Applications, 2024, 44(9): 2683-2688. | |
| [28] | 朱君辉,王梦焰,杨尔弘,等.大模型生成回答与人类回答文本的语言特征比较研究[J].中文信息学报,2024,38(4):17-27. |
| ZHU J H, WANG M Y, YANG E H, et al. A comparative study of language between artificial intelligence and human: a case study of ChatGPT[J]. Journal of Chinese Information Processing, 2024, 38(4): 17-27. | |
| [29] | 王舰,孙宇清.可控文本生成技术研究综述[J].中文信息学报,2024,38(10):1-23. |
| WANG J, SUN Y Q. Survey on controllable text generation[J]. Journal of Chinese Information Processing, 2024, 38(10): 1-23. | |
| [30] | GEHRMANN S, STROBELT H, RUSH A M. GLTR: statistical detection and visualization of generated text[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Stroudsburg: ACL, 2019: 111-116. |
| [31] | WU K, PANG L, SHEN H, et al. LLMDet: a third party large language models generated text detection tool[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 2113-2133. |
| [32] | LIU S, LIU X, WANG Y, et al. Does DetectGPT fully utilize perturbation? bridging selective perturbation to fine-tuned contrastive learning detector would be better[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 1874-1889. |
| [1] | 王晓宇, 李欣, 薛迪, 蒋章涛, 王威, 肖岩军. 基于大语言模型的视频监控网络安全漏洞分类框架[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1158-1170. |
| [2] | 师凯洲, 何旋, 候国义, 李根, 李泷杲, 黄翔. 基于大语言模型的机载产品计量溯源知识图谱构建方法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1086-1095. |
| [3] | 李文浩, 郭银章. 基于双层多尺度动态GCN模型的城市交通流量预测[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1323-1333. |
| [4] | 刘欢娴, 王洪涛, 王宪奥, 王洪梅, 徐伟峰. 跨模态语义关联的多模态事实验证[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1069-1076. |
| [5] | 何帅, 邓春华. 基于YOLO-World的少样本学习目标检测算法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1275-1282. |
| [6] | 陈浩轩, 叶培昌, 刘磊, 刘承明, 胡文华. 自动代码编辑推荐综述[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1227-1237. |
| [7] | 严心怡, 朱灵龙, 张永宏. 面向复杂交通场景的多尺度实时人车检测方法CDC-DETR[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1283-1291. |
| [8] | 王日龙, 李振平, 李晓松, 高强, 何亚, 钟勇, 赵英潇. 多Agent协作的知识推理框架[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 708-714. |
| [9] | 张昊洋, 张丽萍, 闫盛, 李娜, 张学飞. 面向知识图谱补全的大模型方法综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 683-695. |
| [10] | 吴定佳, 崔喆. 增强模式链接与多生成器协同的SQL生成框架MG-SQL[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 723-731. |
| [11] | 刘汉卿, 桑国明, 张益嘉. 结合密集多尺度特征融合和特征知识增强Transformer的遥感图像描述模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 741-749. |
| [12] | 郗恩康, 范菁, 金亚东, 董华, 俞浩, 孙伊航. 联邦学习在隐私安全领域面临的威胁综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 798-808. |
| [13] | 黄奕明, 邹喜华, 邓果, 郑狄. 预回答与召回过滤:双阶段RAG问答系统优化方法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 696-707. |
| [14] | 沈斌, 陈晓宁, 程华, 房一泉, 王慧锋. 基于大语言模型的本科教学评估智能系统[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 993-1003. |
| [15] | 付锦程, 杨仕友. 基于贝叶斯优化和特征融合混合模型的短期风电功率预测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 652-658. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||