


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (6): 1732-1740.DOI: 10.11772/j.issn.1001-9081.2024070909
• 第十二届CCF大数据学术会议 • 上一篇
余明峰1,2,3, 秦永彬1,2,3( ), 黄瑞章1,2,3, 陈艳平1,2,3, 林川1,2,3
), 黄瑞章1,2,3, 陈艳平1,2,3, 林川1,2,3
收稿日期:2024-06-29
修回日期:2024-08-04
接受日期:2024-08-20
发布日期:2024-09-25
出版日期:2025-06-10
通讯作者:
秦永彬
作者简介:余明峰(1999—),男,四川成都人,硕士研究生,CCF会员,主要研究方向:自然语言处理、文本分类基金资助:
Mingfeng YU1,2,3, Yongbin QIN1,2,3(), Ruizhang HUANG1,2,3, Yanping CHEN1,2,3, Chuan LIN1,2,3
Received:2024-06-29
Revised:2024-08-04
Accepted:2024-08-20
Online:2024-09-25
Published:2025-06-10
Contact:
Yongbin QIN
About author:YU Mingfeng, born in 1999, M. S. candidate. His research interests include natural language processing, text classification.Supported by:摘要:
针对现有的基于注意力机制的方法难以捕捉文本之间复杂的依赖关系的问题,提出一种基于对比学习增强双注意力机制的多标签文本分类方法。首先,分别学习基于自注意力和基于标签注意力的文本表示,并融合二者以获得更全面的文本表示捕捉文本的结构特征以及文本与标签之间的语义关联;其次,给定一个多标签对比学习目标,利用标签引导的文本相似度监督文本表示的学习,以捕捉文本之间在主题、内容和结构层面上复杂的依赖关系;最后,使用前馈神经网络作为分类器进行文本分类。实验结果表明,相较于LDGN(Label-specific Dual Graph neural Network),所提方法在EUR-Lex(European Union Law Document)数据集与Reuters-21578数据集上的排名第5处的归一化折现累积收益(nDCG@5)值分别提升了1.81和0.86个百分点,在AAPD(Arxiv Academic Paper Dataset)数据集与RCV1(Reuters Corpus Volume Ⅰ)数据集上也都取得了有竞争力的结果。可见,所提方法能有效捕捉文本之间在主题、内容和结构层面上复杂的依赖关系,从而在多标签文本分类任务上取得较优结果。
中图分类号:
余明峰, 秦永彬, 黄瑞章, 陈艳平, 林川. 基于对比学习增强双注意力机制的多标签文本分类方法[J]. 计算机应用, 2025, 45(6): 1732-1740.
Mingfeng YU, Yongbin QIN, Ruizhang HUANG, Yanping CHEN, Chuan LIN. Multi-label text classification method based on contrastive learning enhanced dual-attention mechanism[J]. Journal of Computer Applications, 2025, 45(6): 1732-1740.
| RCV1数据集中的文本 | 标签 |
|---|---|
Lecour Corp第四季度净利润下降 每股收益……净利润……销售额……平均股数……12个月每股收益…… 净利润……销售额……平均股数…… | CCAT、C15、C151、C313 |
| General Kinetics Inc. 5月31日 第四季度净亏损季度……(未经审计)收入……营业利润(亏损)……净利润(亏损)……每股净利润(亏损)……财政年度结束日期……(已审计)收入……营业亏损……净亏损……每股净亏损…… | CCAT、C15、C151、C1511 |
萨斯喀彻温西南部和中阿尔伯塔地区出现轻微霜冻风险,加拿大环境部表示,萨斯喀彻温省的瓦尔玛丽地区在周五 凌晨06:00 CDT…… | GCAT、GWEA |
表1 标签引导的文本相似示例
Tab. 1 Examples of label-guided text similarity
| RCV1数据集中的文本 | 标签 |
|---|---|
Lecour Corp第四季度净利润下降 每股收益……净利润……销售额……平均股数……12个月每股收益…… 净利润……销售额……平均股数…… | CCAT、C15、C151、C313 |
| General Kinetics Inc. 5月31日 第四季度净亏损季度……(未经审计)收入……营业利润(亏损)……净利润(亏损)……每股净利润(亏损)……财政年度结束日期……(已审计)收入……营业亏损……净亏损……每股净亏损…… | CCAT、C15、C151、C1511 |
萨斯喀彻温西南部和中阿尔伯塔地区出现轻微霜冻风险,加拿大环境部表示,萨斯喀彻温省的瓦尔玛丽地区在周五 凌晨06:00 CDT…… | GCAT、GWEA |

图1 本文方法的总体框架
Fig. 1 Overall framework of proposed method
| 数据集 | 训练样本数 | 测试样本数 | 标签总数 | 样本平均 单词数 | 样本平均标签数 |
|---|---|---|---|---|---|
| AAPD | 54 840 | 1 000 | 54 | 163.57 | 2.41 |
| RCV1 | 23 149 | 781 265 | 103 | 268.95 | 3.18 |
| EUR-Lex | 11 585 | 3 865 | 3 956 | 1 230.92 | 5.32 |
| Reuters-21578 | 12 865 | 5 458 | 90 | 146.62 | 1.13 |
表2 数据集简介
Tab. 2 Dataset description
| 数据集 | 训练样本数 | 测试样本数 | 标签总数 | 样本平均 单词数 | 样本平均标签数 |
|---|---|---|---|---|---|
| AAPD | 54 840 | 1 000 | 54 | 163.57 | 2.41 |
| RCV1 | 23 149 | 781 265 | 103 | 268.95 | 3.18 |
| EUR-Lex | 11 585 | 3 865 | 3 956 | 1 230.92 | 5.32 |
| Reuters-21578 | 12 865 | 5 458 | 90 | 146.62 | 1.13 |
| 方法 | AAPD | RCV1 | EUR-Lex | Reuters-21578 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P@1 | P@3 | P@5 | P@1 | P@3 | P@5 | P@1 | P@3 | P@5 | P@1 | P@3 | P@5 | |
| XML-CNN | 74.38 | 53.84 | 37.79 | 95.75 | 78.63 | 54.94 | 70.40 | 44.86 | 44.86 | 77.30 | 32.00 | 19.99 |
| SGM | 75.67 | 56.75 | 35.65 | 95.37 | 81.36 | 53.06 | 70.45 | 60.37 | 43.88 | 79.44 | 34.02 | 21.01 |
| DXML | 80.54 | 56.30 | 39.16 | 94.04 | 78.65 | 54.38 | 75.63 | 60.13 | 48.65 | 80.59 | 34.04 | 21.14 |
| AttentionXML | 83.02 | 58.72 | 40.56 | 96.41 | 80.91 | 56.38 | 67.34 | 52.52 | 47.72 | 82.50 | 34.33 | 21.19 |
| EXAM | 83.26 | 59.77 | 40.66 | 93.67 | 75.80 | 52.73 | 74.40 | 61.93 | 50.98 | 82.48 | 34.68 | 21.32 |
| LSAN | 85.28 | 61.12 | 41.84 | 96.81 | 81.89 | 56.92 | 79.17 | 64.99 | 53.67 | |||
| LDGN | 42.29 | 81.03 | 67.79 | 56.36 | 82.52 | 34.52 | 21.26 | |||||
| GATTN | 83.85 | 59.91 | 40.95 | 95.42 | 78.71 | 55.14 | 81.80 | 34.52 | 21.21 | |||
| 本文方法 | 87.00 | 62.37 | 97.23 | 82.71 | 57.35 | 83.55 | 70.46 | 58.24 | 83.72 | 35.00 | 21.52 | |
表3 在4个数据集上关于P@k(k=1,3,5)的文本分类结果的对比 (%)
Tab. 3 Comparison of text classification results on four datasets in term of P@k(k=1,3,5)
| 方法 | AAPD | RCV1 | EUR-Lex | Reuters-21578 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P@1 | P@3 | P@5 | P@1 | P@3 | P@5 | P@1 | P@3 | P@5 | P@1 | P@3 | P@5 | |
| XML-CNN | 74.38 | 53.84 | 37.79 | 95.75 | 78.63 | 54.94 | 70.40 | 44.86 | 44.86 | 77.30 | 32.00 | 19.99 |
| SGM | 75.67 | 56.75 | 35.65 | 95.37 | 81.36 | 53.06 | 70.45 | 60.37 | 43.88 | 79.44 | 34.02 | 21.01 |
| DXML | 80.54 | 56.30 | 39.16 | 94.04 | 78.65 | 54.38 | 75.63 | 60.13 | 48.65 | 80.59 | 34.04 | 21.14 |
| AttentionXML | 83.02 | 58.72 | 40.56 | 96.41 | 80.91 | 56.38 | 67.34 | 52.52 | 47.72 | 82.50 | 34.33 | 21.19 |
| EXAM | 83.26 | 59.77 | 40.66 | 93.67 | 75.80 | 52.73 | 74.40 | 61.93 | 50.98 | 82.48 | 34.68 | 21.32 |
| LSAN | 85.28 | 61.12 | 41.84 | 96.81 | 81.89 | 56.92 | 79.17 | 64.99 | 53.67 | |||
| LDGN | 42.29 | 81.03 | 67.79 | 56.36 | 82.52 | 34.52 | 21.26 | |||||
| GATTN | 83.85 | 59.91 | 40.95 | 95.42 | 78.71 | 55.14 | 81.80 | 34.52 | 21.21 | |||
| 本文方法 | 87.00 | 62.37 | 97.23 | 82.71 | 57.35 | 83.55 | 70.46 | 58.24 | 83.72 | 35.00 | 21.52 | |
| 方法 | AAPD | RCV1 | EUR-Lex | Reuters-21578 | ||||
|---|---|---|---|---|---|---|---|---|
| nDCG@3 | nDCG@5 | nDCG@3 | nDCG@5 | nDCG@3 | nDCG@5 | nDCG@3 | nDCG@5 | |
| XML-CNN | 71.12 | 75.93 | 89.89 | 90.77 | 58.62 | 53.10 | 85.24 | 86.35 |
| SGM | 72.36 | 75.30 | 91.76 | 90.69 | 60.72 | 55.24 | 89.08 | 89.74 |
| DXML | 77.23 | 80.99 | 89.83 | 90.21 | 63.96 | 53.60 | 89.08 | 89.95 |
| AttentionXML | 78.01 | 82.31 | 91.88 | 92.70 | 56.21 | 50.78 | 90.54 | 91.13 |
| EXAM | 79.10 | 82.79 | 86.85 | 87.71 | 65.12 | 59.43 | 91.04 | 91.49 |
| LSAN | 80.84 | 84.78 | 92.83 | 93.43 | 68.32 | 62.47 | ||
| LDGN | 83.32 | 86.85 | 93.80 | 95.03 | 91.04 | 91.54 | ||
| GATTN | 79.45 | 81.24 | 89.43 | 90.42 | 71.44 | 65.01 | 90.52 | 91.01 |
| 本文方法 | 73.91 | 67.90 | 91.99 | 92.40 | ||||
表4 在4个数据集上关于nDCG@k(k=3,5)的文本分类结果对比 (%)
Tab. 4 Comparison of text classification results on four datasets in term of nDCG@k(k=3,5)
| 方法 | AAPD | RCV1 | EUR-Lex | Reuters-21578 | ||||
|---|---|---|---|---|---|---|---|---|
| nDCG@3 | nDCG@5 | nDCG@3 | nDCG@5 | nDCG@3 | nDCG@5 | nDCG@3 | nDCG@5 | |
| XML-CNN | 71.12 | 75.93 | 89.89 | 90.77 | 58.62 | 53.10 | 85.24 | 86.35 |
| SGM | 72.36 | 75.30 | 91.76 | 90.69 | 60.72 | 55.24 | 89.08 | 89.74 |
| DXML | 77.23 | 80.99 | 89.83 | 90.21 | 63.96 | 53.60 | 89.08 | 89.95 |
| AttentionXML | 78.01 | 82.31 | 91.88 | 92.70 | 56.21 | 50.78 | 90.54 | 91.13 |
| EXAM | 79.10 | 82.79 | 86.85 | 87.71 | 65.12 | 59.43 | 91.04 | 91.49 |
| LSAN | 80.84 | 84.78 | 92.83 | 93.43 | 68.32 | 62.47 | ||
| LDGN | 83.32 | 86.85 | 93.80 | 95.03 | 91.04 | 91.54 | ||
| GATTN | 79.45 | 81.24 | 89.43 | 90.42 | 71.44 | 65.01 | 90.52 | 91.01 |
| 本文方法 | 73.91 | 67.90 | 91.99 | 92.40 | ||||

图2 在4个数据集上的消融实验结果
Fig. 2 Ablation study results on four datasets
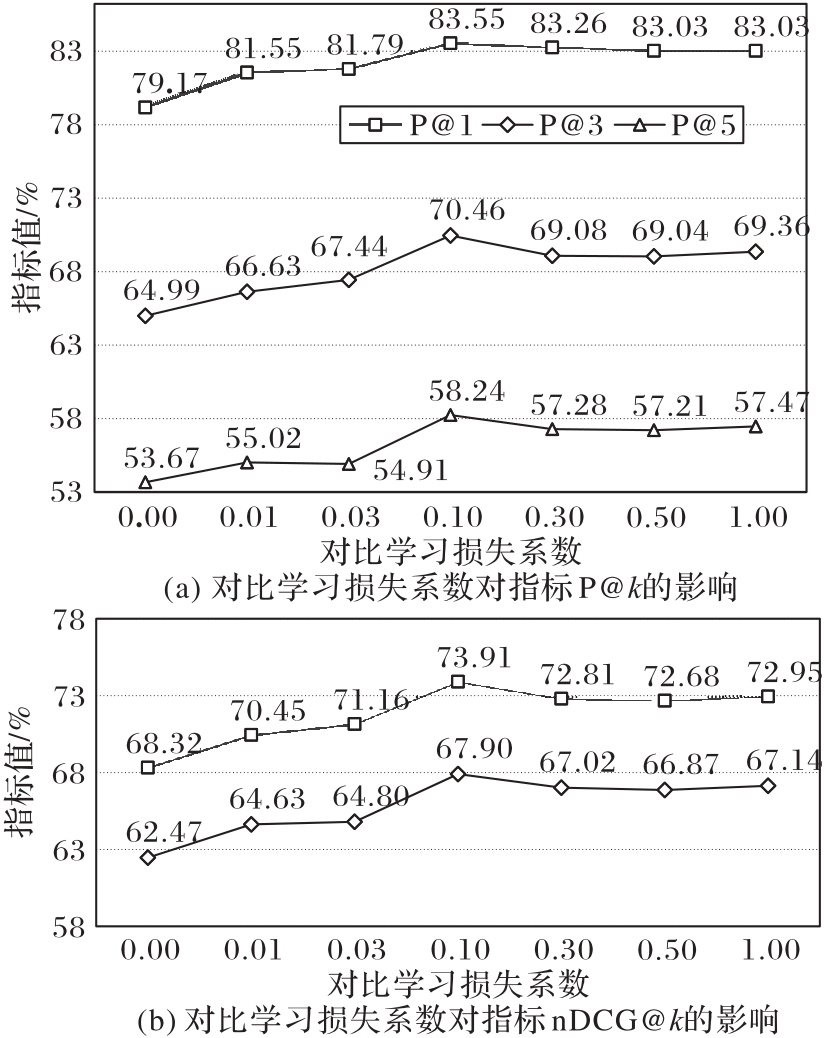
图3 在EUR-Lex数据集上的对比损失系数分析
Fig. 3 Analysis of contrastive loss coefficient on EUR-Lex dataset
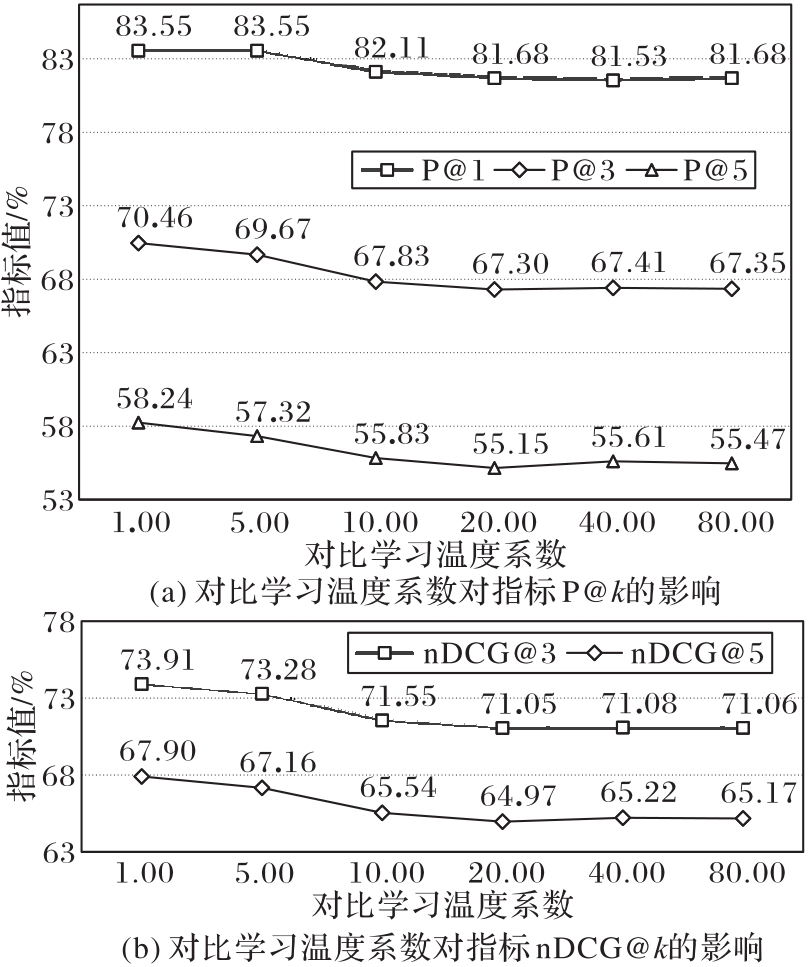
图4 在EUR-Lex数据集上的对比学习温度系数分析
Fig. 4 Analysis of contrastive learning temperature coefficient on EUR-Lex dataset
| 1 | JAIN H, PRABHU Y, VARMA M. Extreme multi-label loss functions for recommendation, tagging, ranking & other missing label applications[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 935-944. |
| 2 | WANG Y, FENG S, WANG D, et al. Multi-label Chinese microblog emotion classification via convolutional neural network[C]// Proceedings of the 2016 Asia-Pacific Web Conference, LNCS 9931. Cham: Springer, 2016: 567-580. |
| 3 | YANG Z, YANG D, DYER C, et al. Hierarchical attention networks for document classification[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2016: 1480-1489. |
| 4 | BOUTELL M R, LUO J, SHEN X, et al. Learning multi-label scene classification[J]. Pattern Recognition, 2004, 37(9): 1757-1771. |
| 5 | KATAKIS I, TSOUMAKAS G, VLAHAVAS I. Multilabel text classification for automated tag suggestion[EB/OL]. [2022-10-10].. |
| 6 | READ J, PFAHRINGER B, HOLMES G, et al. Classifier chains for multi-label classification[J]. Machine Learning, 2011, 85(3): 333-359. |
| 7 | ZHANG M L, ZHOU Z H. ML-KNN: a lazy learning approach to multi-label learning [J]. Pattern Recognition, 2007, 40(7): 2038-2048. |
| 8 | ELISSEEFF A, WESTON J. A kernel method for multi-labelled classification [C]// Proceedings of the 15th International Conference on Neural Information Processing Systems: Natural and Synthetic. Cambridge: MIT Press, 2001: 681-687. |
| 9 | ZHANG Q, ZHENG R, ZHAO Z, et al. A TextCNN based approach for multi-label text classification of power fault data[C]// Proceedings of the IEEE 5th International Conference on Cloud Computing and Big Data Analytics. Piscataway: IEEE, 2020: 179-183. |
| 10 | LIU J, CHANG W C, WU Y, et al. Deep learning for extreme multi-label text classification[C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2017: 115-124. |
| 11 | SHIMURA K, LI J, FUKUMOTO F. HFT-CNN: learning hierarchical category structure for multi-label short text categorization[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 811-816. |
| 12 | SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]// Proceedings of the 27nd International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 3104-3112. |
| 13 | NAM J, LOZA MENCÍA E, KIM H J, et al. Maximizing subset accuracy with recurrent neural networks in multi-label classification[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5419-5429. |
| 14 | LIN J, SU Q, YANG P, et al. Semantic-unit-based dilated convolution for multi-label text classification[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 4554-4564. |
| 15 | 陈文实,刘心惠,鲁明羽. 面向多标签文本分类的深度主题特征提取[J]. 模式识别与人工智能, 2019, 32(9):785-792. |
| CHEN W S, LIU X H, LU M Y. Feature extraction of deep topic model for multi-label text classification[J]. Pattern Recognition and Artificial Intelligence, 2019, 32(9): 785-792. | |
| 16 | YOU R, ZHANG Z, WANG Z, et al. AttentionXML: label tree-based attention-aware deep model for high-performance extreme multi-label text classification[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 5820-5830. |
| 17 | 刘海顺,王雷,孙媛媛,等. 基于预训练语言模型的案件要素识别方法[J]. 中文信息学报, 2021, 35(11):91-100. |
| LIU H S, WANG L, SUN Y Y, et al. Case factor recognition based on pre-trained language models[J]. Journal of Chinese Information Processing, 2021, 35(11): 91-100. | |
| 18 | YANG P, SUN X, LI W, et al. SGM: sequence generation model for multi-label Classification[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 3915-3926. |
| 19 | QIN K, LI C, PAVLU V, et al. Adapting RNN sequence prediction model to multi-label set prediction[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg: ACL, 2019: 3181-3190. |
| 20 | DU C, CHEN Z, FENG F, et al. Explicit interaction model towards text classification[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 6359-6366. |
| 21 | XIAO L, HUANG X, CHEN B, et al. Label-specific document representation for multi-label text classification[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 466-475. |
| 22 | LIU N, WANG Q, REN J. Label-embedding bi-directional attentive model for multi-label text classification[J]. Neural Processing Letters, 2021, 53(1): 375-389. |
| 23 | MA Q, YUAN C, ZHOU W, et al. Label-specific dual graph neural network for multi-label text classification[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2021: 3855-3864. |
| 24 | 杨春霞,吴佳君,瞿涛,等. 基于注意力机制和CNN的多标签文本分类模型[J]. 计算机应用与软件, 2024, 41(3):156-162. |
| YANG C X, WU J J, QU T, et al. Multi-label text classification model based on attention mechanism and CNN[J]. Computer Applications and Software, 2024, 41(3): 156-162. | |
| 25 | 李芳芳,苏朴真,段俊文,等. 多粒度信息关系增强的多标签文本分类[J]. 软件学报, 2023, 34(12):5686-5703. |
| LI F F, SU P Z, DUAN J W, et al. Multi-label text classification with enhancing multi-granularity information relations[J]. Journal of Software, 2023, 34(12): 5686-5703. | |
| 26 | 潘理虎,李小华,张睿,等. 基于互信息解决多标签文本分类中的长尾问题[J]. 计算机应用研究, 2024, 41(9): 2664-2669. |
| PAN L H, LI X H, ZHANG R, et al. Addressing long-tail problem in multi-label text classification based on mutual information[J]. Application Research of Computers, 2024, 41(9): 2664-2669. | |
| 27 | CHEN G, YE D, XING Z, et al. Ensemble application of convolutional and recurrent neural networks for multi-label text categorization[C]// Proceedings of the 2017 International Joint Conference on Neural Networks. Piscataway: IEEE, 2017: 2377-2383. |
| 28 | PENG H, LI J, WANG S, et al. Hierarchical taxonomy-aware and attentional graph capsule RCNNs for large-scale multi-label text classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2021, 33(6): 2505-2519. |
| 29 | 杨春霞,黄昱锟,闫晗,等. 融合GAT与头尾标签的多标签文本分类模型[J]. 计算机工程与应用, 2024, 60(15): 150-160. |
| YANG C X, HUANG Y K, YAN H, et al. Multi-label text classification model integrating GAT and head-tail label[J]. Computer Engineering and Applications, 2024, 60(15): 150-160. | |
| 30 | ZHAO S, WANG C, HU M, et al. MCL: multi-granularity contrastive learning framework for Chinese NER [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 14011-14019. |
| 31 | PAN X, WANG M, WU L, et al. Contrastive learning for many-to-many multilingual neural machine translation[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 244-258. |
| 32 | DISSANAYAKE V, SENEVIRATNE S, RANA R, et al. SigRep: toward robust wearable emotion recognition with contrastive representation learning[J]. IEEE Access, 2022, 10: 18105-18120. |
| 33 | SU X, WANG R, DAI X. Contrastive learning-enhanced nearest neighbor mechanism for multi-label text classification[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 672-679. |
| 34 | LIN N, QIN G, WANG G, et al. An effective deployment of contrastive learning in multi-label text classification[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 8730-8744. |
| 35 | ZHANG C, LIU P, XIAO Z, et al. Mao-Zedong at SemEval-2023 task 4: label representation multi-head attention model with contrastive learning-enhanced nearest neighbor mechanism for multi-label text classification[C]// Proceedings of the 17th International Workshop on Semantic Evaluation. Stroudsburg: ACL, 2023: 426-432. |
| 36 | LEWIS D D, YANG Y, ROSE T G, et al. RCV1: a new benchmark collection for text categorization research [J]. Journal of Machine Learning Research, 2004, 5: 361-397. |
| 37 | LOZA MENCÍA E, FÜRNKRANZ J. Efficient pairwise multilabel classification for large-scale problems in the legal domain[C]// Proceedings of the 2008 Joint European Conference on Machine Learning and Knowledge Discovery in Databases, LNCS 5212. Berlin: Springer, 2008: 50-65. |
| 38 | HAYES P J, WEINSTEIN S P. Construe/TIS: a system for content-based indexing of a database of news stories[C]// Proceedings of the 2nd Conference on Innovative Applications of Artificial Intelligence. Menlo Park: AAAI Press, 1990: 49-64. |
| 39 | ZHANG W, YAN J, WANG X, et al. Deep extreme multi-label learning [C]// Proceedings of the 8th ACM on International Conference on Multimedia Retrieval. New York: ACM, 2018: 100-107. |
| [1] | 胡文彬, 蔡天翔, 韩天乐, 仲兆满, 马常霞. 融合对比学习与情感分析的多模态反讽检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1432-1438. |
| [2] | 龙雨菲, 牟宇辰, 刘晔. 基于张量化图卷积网络和对比学习的多源数据表示学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1372-1378. |
| [3] | 李慧, 贾炳志, 王晨曦, 董子宇, 李纪龙, 仲兆满, 陈艳艳. 基于Swin Transformer的生成对抗网络水下图像增强模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1439-1446. |
| [4] | 胡婕, 郑启扬, 孙军, 张龑. 基于多标签关系图和局部动态重构学习的多标签分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1104-1112. |
| [5] | 田仁杰, 景明利, 焦龙, 王飞. 基于混合负采样的图对比学习推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1053-1060. |
| [6] | 姜坤元, 李小霞, 王利, 曹耀丹, 张晓强, 丁楠, 周颖玥. 引入解耦残差自注意力的边界交叉监督语义分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1120-1129. |
| [7] | 党伟超, 温鑫瑜, 高改梅, 刘春霞. 基于多视图多尺度对比学习的图协同过滤[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1061-1068. |
| [8] | 陈维, 施昌勇, 马传香. 基于多模态数据融合的农作物病害识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 840-848. |
| [9] | 王元龙, 刘亭华, 张虎. 基于跨模态对比学习的常识问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 732-738. |
| [10] | 杨晟, 李岩. 面向目标检测的对比知识蒸馏方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 354-361. |
| [11] | 严雪文, 黄章进. 基于对比学习的小样本图像分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 383-391. |
| [12] | 余肖生, 王智鑫. 基于多层次图对比学习的序列推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 106-114. |
| [13] | 宋鹏程, 郭立君, 张荣. 利用局部-全局时间依赖的弱监督视频异常检测[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 240-246. |
| [14] | 杨兴耀, 陈羽, 于炯, 张祖莲, 陈嘉颖, 王东晓. 结合自我特征和对比学习的推荐模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2704-2710. |
| [15] | 李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||