《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (4): 1029-1035.DOI: 10.11772/j.issn.1001-9081.2022030327
所属专题: 人工智能
袁泉1,2, 徐雲鹏1,2( ), 唐成亮1,2
), 唐成亮1,2
Quan YUAN1,2, Yunpeng XU1,2(), Chengliang TANG1,2
摘要:
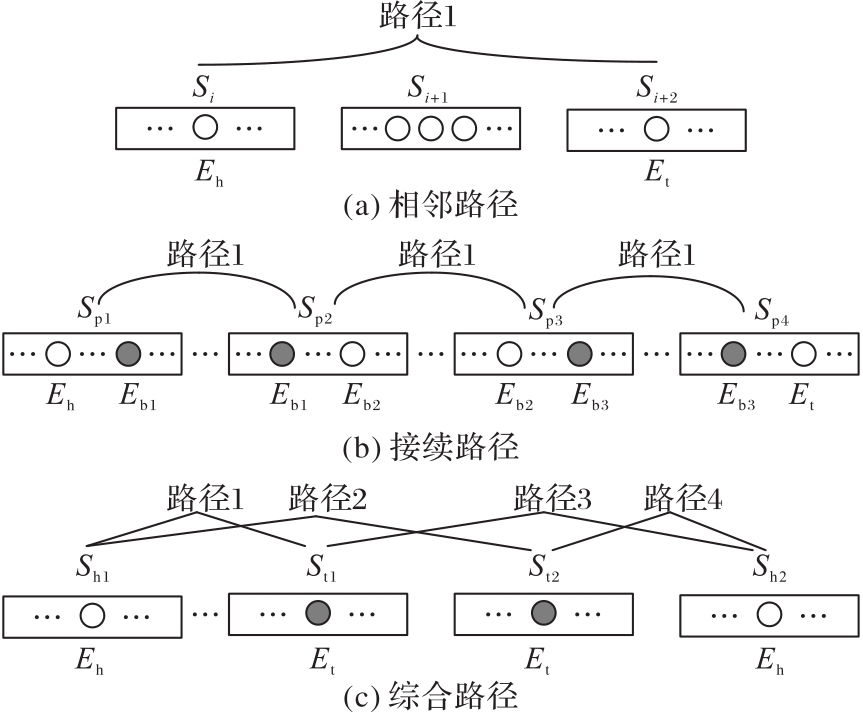
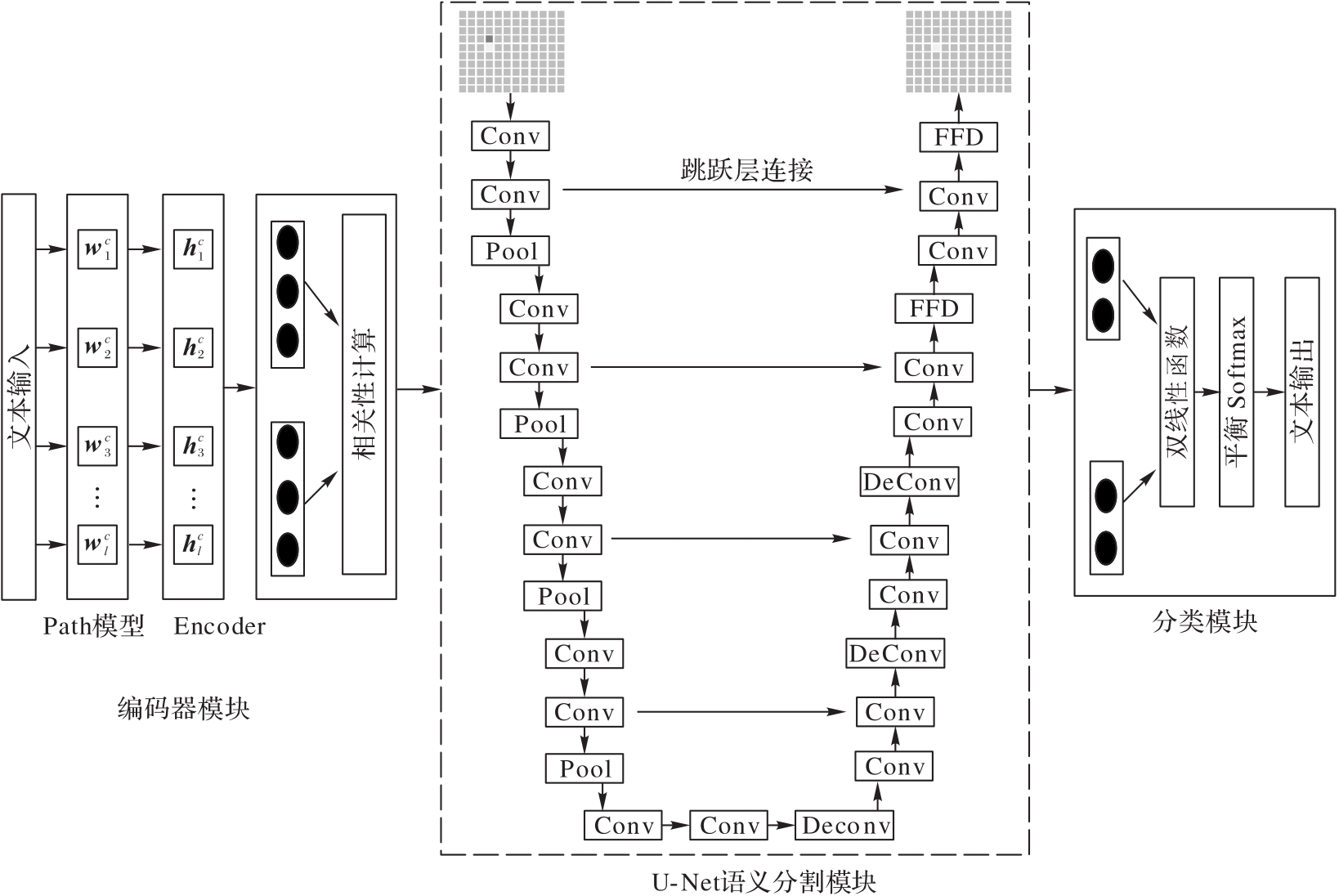
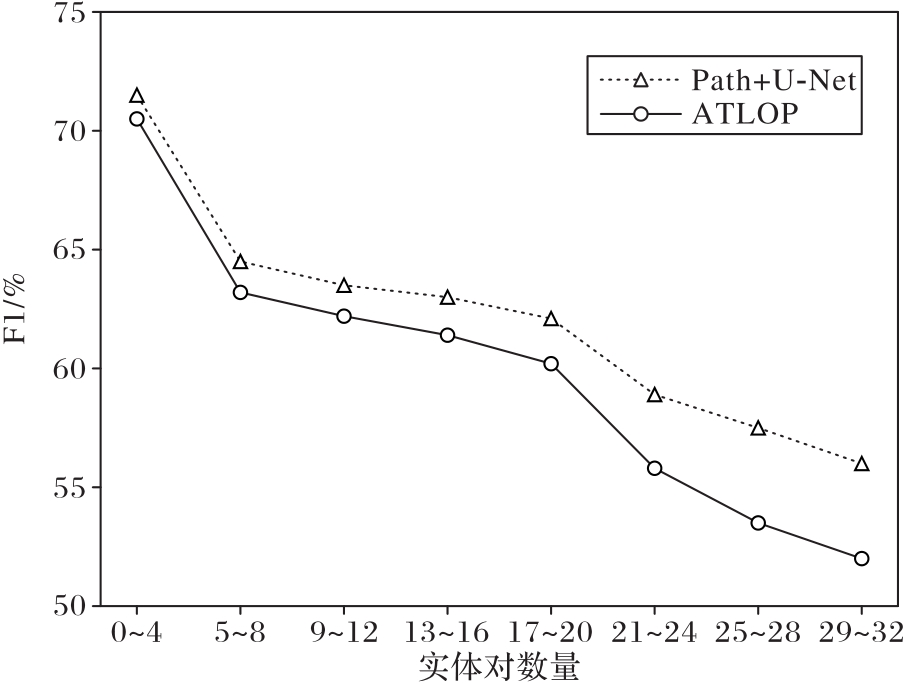
针对文档级关系抽取中文本处理复杂性过高,难以提取高效实体关系的问题,提出了一种基于路径标签的文档级关系抽取方法,抽取选择关键的证据句子。首先,引入路径(Path)标签代替实体句子作为处理过的文本数据集进行数据预处理;同时,结合语义分割的U-Net模型,利用输入端的编码模块捕获文档实体的上下文信息,并通过图像风格的U-Net语义分割模块捕获实体三元组之间的全局依赖性;最后,引入Softmax函数减少文本抽取时的噪声。理论分析和仿真结果表明,与基于图神经网络的RoBERTa(RoBERTa?ATLOP)关系抽取算法相比,Path+U-Net在基于文档级别的实体关系抽取数据集(DocRED)上的开发和测试的F1值分别提高了1.31、0.54个百分点,在化学疾病反应(CDR)数据集上的开发和测试的F1值分别提高了1.32、1.19个百分点;并且Path+U-Net在保证实体间的相关性与原始数据集的相关性一致的同时,对数据集的抽取成本更低、对文本的抽取精度更高。实验结果表明,所提出的基于路径标签的抽取方法能够有效提高长文本抽取效率。
中图分类号: