


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (5): 1409-1415.DOI: 10.11772/j.issn.1001-9081.2022040513
所属专题: 人工智能
隋佳宏1, 毛莺池1,2( ), 于慧敏1, 王子成3, 平萍1,2
), 于慧敏1, 王子成3, 平萍1,2
收稿日期:2022-04-05
修回日期:2022-07-11
接受日期:2022-07-14
发布日期:2023-05-08
出版日期:2023-05-10
通讯作者:
毛莺池
作者简介:隋佳宏(1998—),女,山东烟台人,硕士研究生,CCF会员,主要研究方向:计算机视觉基金资助:
Jiahong SUI1, Yingchi MAO1,2(), Huimin YU1, Zicheng WANG3, Ping PING1,2
Received:2022-04-05
Revised:2022-07-11
Accepted:2022-07-14
Online:2023-05-08
Published:2023-05-10
Contact:
Yingchi MAO
About author:SUI Jiahong, born in 1998, M. S. candidate. Her research interests include computer vision.Supported by:摘要:
现有图像描述生成方法仅考虑网格的空间位置特征,网格特征交互不足,并且未充分利用图像的全局特征。为生成更高质量的图像描述,提出一种基于图注意力网络(GAT)的全局图像描述生成方法。首先,利用多层卷积神经网络(CNN)进行视觉编码,提取给定图像的网格特征和整幅图像特征,并构建网格特征交互图;然后,通过GAT将特征提取问题转化成节点分类问题,包括一个全局节点和多个局部节点,更新优化后可以充分利用全局和局部特征;最后,基于Transformer的解码模块利用改进的视觉特征生成图像描述。在Microsoft COCO数据集上的实验结果表明,所提方法能有效捕捉图像的全局和局部特征,在CIDEr(Consensus-based Image Description Evaluation)指标上达到了133.1%。可见基于GAT的全局图像描述生成方法能有效提高文字描述图像的准确度,从而可以使用文字对图像进行分类、检索、分析等处理。
中图分类号:
隋佳宏, 毛莺池, 于慧敏, 王子成, 平萍. 基于图注意力网络的全局图像描述生成方法[J]. 计算机应用, 2023, 43(5): 1409-1415.
Jiahong SUI, Yingchi MAO, Huimin YU, Zicheng WANG, Ping PING. Global image captioning method based on graph attention network[J]. Journal of Computer Applications, 2023, 43(5): 1409-1415.
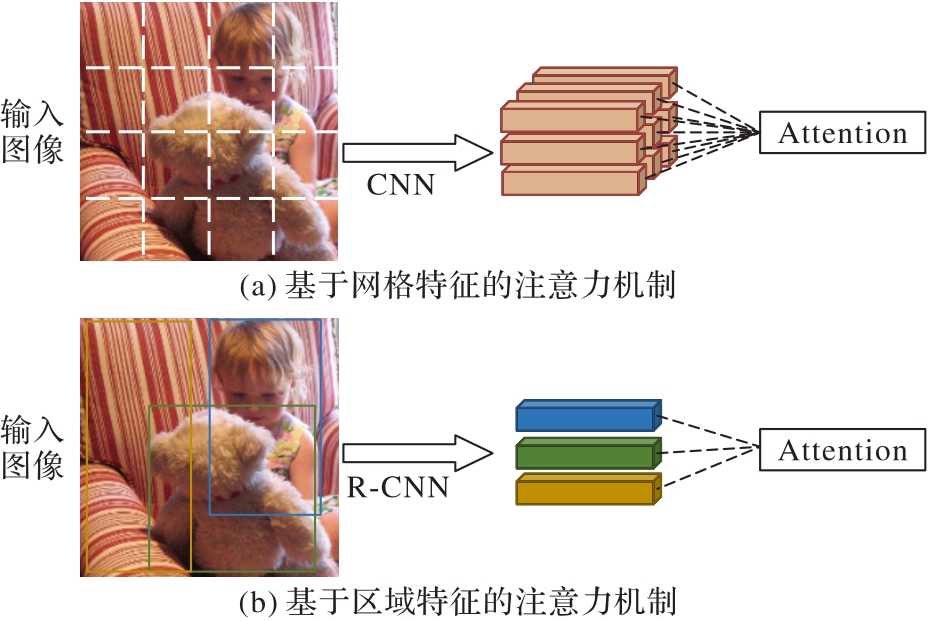
图1 网格特征与区域特征
Fig. 1 Grid features and region features
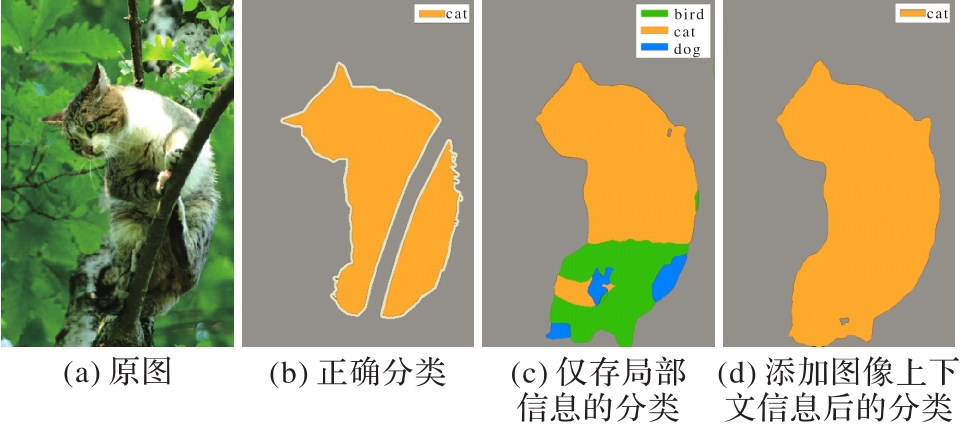
图2 图像分类结果比较
Fig. 2 Comparison of image classification results
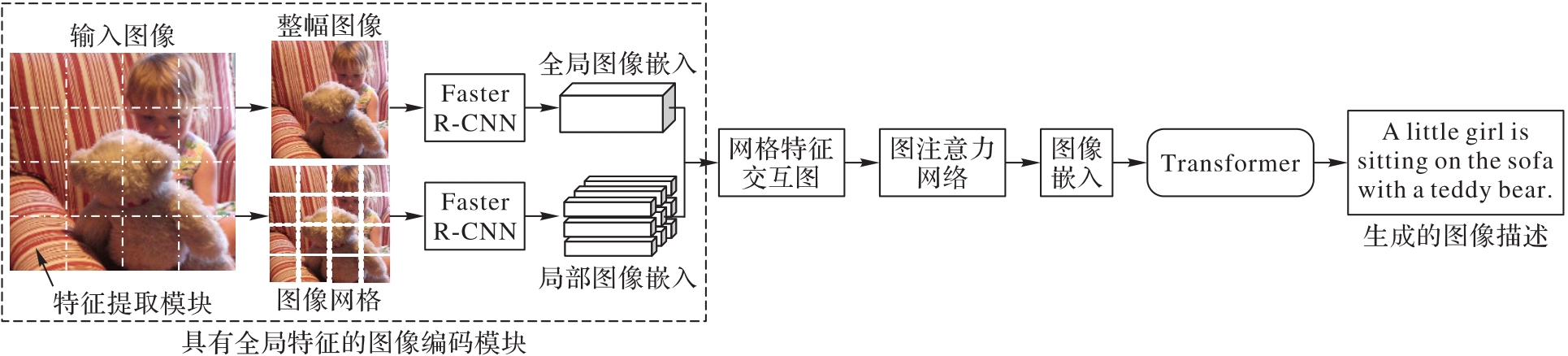
图3 方法总体框架
Fig. 3 Overall framework of method
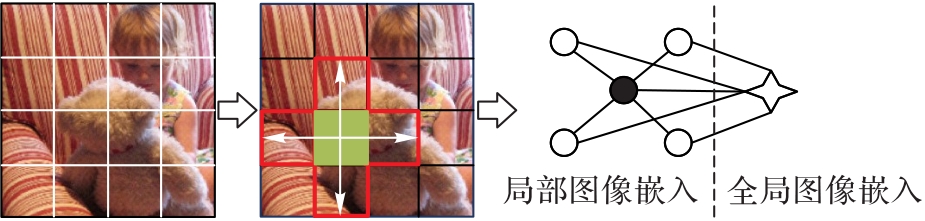
图4 网格特征交互图构建(与邻近4个网格进行交互)
Fig. 4 Construction of grid feature interaction graph (interact with 4 neighboring grids)
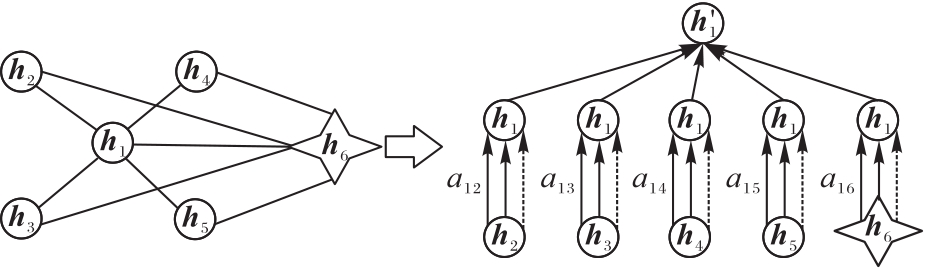
图5 G-GAT示意图
Fig. 5 Schematic diagram of G-GAT
| 方法 | B1 | B4 | METEOR | CIDEr | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|
| SCST[ | — | 34.2 | 26.7 | 114.0 | 55.7 | — |
| Up-Down[ | 79.8 | 36.3 | 27.7 | 120.1 | 56.9 | 21.4 |
| RFNet[ | 79.1 | 36.5 | 27.7 | 121.9 | 57.7 | 21.2 |
| GCN-LSTM[ | 80.5 | 38.2 | 28.5 | 127.6 | 58.3 | 22.0 |
| SGAE[ | 80.8 | 38.4 | 28.4 | 127.8 | 58.6 | 22.1 |
| ORT[ | 80.5 | 38.6 | 28.7 | 128.3 | 58.4 | 22.6 |
| CPTR[ | 81.7 | 40.0 | 29.1 | 129.4 | 59.4 | — |
| AoA[ | 80.2 | 38.9 | 29.2 | 129.8 | 58.8 | 22.4 |
| M2[ | 80.8 | 39.1 | 29.2 | 131.2 | 58.6 | 22.6 |
| GET[ | 81.5 | 38.8 | 29.0 | 131.6 | 58.9 | 22.8 |
| X-Transformer[ | 80.9 | 39.7 | 29.5 | 132.8 | 59.1 | 23.4 |
| 本文方法 | 81.2 | 39.3 | 29.7 | 133.1 | 59.2 | 22.8 |
表1 不同方法在MSCOCO分割数据集上的性能指标比较 单位:% ( %)
Tab. 1 Comparison of performance indicators of different methods on MSCOCO dataset
| 方法 | B1 | B4 | METEOR | CIDEr | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|
| SCST[ | — | 34.2 | 26.7 | 114.0 | 55.7 | — |
| Up-Down[ | 79.8 | 36.3 | 27.7 | 120.1 | 56.9 | 21.4 |
| RFNet[ | 79.1 | 36.5 | 27.7 | 121.9 | 57.7 | 21.2 |
| GCN-LSTM[ | 80.5 | 38.2 | 28.5 | 127.6 | 58.3 | 22.0 |
| SGAE[ | 80.8 | 38.4 | 28.4 | 127.8 | 58.6 | 22.1 |
| ORT[ | 80.5 | 38.6 | 28.7 | 128.3 | 58.4 | 22.6 |
| CPTR[ | 81.7 | 40.0 | 29.1 | 129.4 | 59.4 | — |
| AoA[ | 80.2 | 38.9 | 29.2 | 129.8 | 58.8 | 22.4 |
| M2[ | 80.8 | 39.1 | 29.2 | 131.2 | 58.6 | 22.6 |
| GET[ | 81.5 | 38.8 | 29.0 | 131.6 | 58.9 | 22.8 |
| X-Transformer[ | 80.9 | 39.7 | 29.5 | 132.8 | 59.1 | 23.4 |
| 本文方法 | 81.2 | 39.3 | 29.7 | 133.1 | 59.2 | 22.8 |
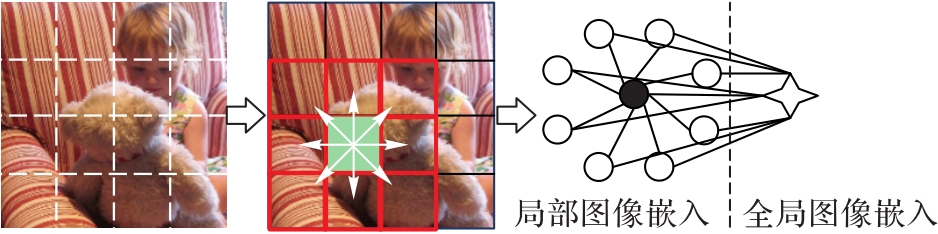
图6 邻域交互方式(与8个网格交互)
Fig. 6 Neighborhood interaction mode (interact with 8 grids)
| 全局节点 | 交互方式 | 区域特征 | B1 | B4 | METEOR | CIDEr | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|---|---|
| w/o | 相邻 | w/o | 80.5 | 38.7 | 29.5 | 129.2 | 58.6 | 22.4 |
| w/ | 邻域 | w/o | 80.8 | 39.2 | 29.4 | 130.5 | 59.0 | 22.1 |
| w/ | 相邻 | w/ | 81.0 | 39.1 | 29.5 | 130.8 | 59.2 | 22.6 |
| w/ | 相邻 | w/o | 81.2 | 39.3 | 29.7 | 133.1 | 59.2 | 22.8 |
表2 消融实验结果 ( %)
Tab. 2 Ablation experimental results
| 全局节点 | 交互方式 | 区域特征 | B1 | B4 | METEOR | CIDEr | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|---|---|
| w/o | 相邻 | w/o | 80.5 | 38.7 | 29.5 | 129.2 | 58.6 | 22.4 |
| w/ | 邻域 | w/o | 80.8 | 39.2 | 29.4 | 130.5 | 59.0 | 22.1 |
| w/ | 相邻 | w/ | 81.0 | 39.1 | 29.5 | 130.8 | 59.2 | 22.6 |
| w/ | 相邻 | w/o | 81.2 | 39.3 | 29.7 | 133.1 | 59.2 | 22.8 |

图7 典型样例图
Fig. 7 Typical samples
| 图序 | 描述方法 | 描述结果 |
|---|---|---|
| (a) | GT | A man catching a baseball as another slides into the base. |
| Base | A baseball player is | |
| 本文方法 | A man is catching the baseball, and another is throwing the ball . | |
| (b) | GT | A black bird standing on top of a power pole. |
| Base | ||
| 本文方法 | A black birtd sitting on top of a wire. | |
| (c) | GT | A polar bear is standing in some snow. |
| Base | A polar bear is standing in the | |
| 本文方法 | A polar bear is standing in the snow . | |
| (d) | GT | A child feeding a giraffe from the palm of his hand. |
| Base | A young boy feeding a giraffe | |
| 本文方法 | A young boy feeding a giraffe with a hand . |
表3 图7样例图的描述结果
Tab. 3 Image captioning results of Fig. 7
| 图序 | 描述方法 | 描述结果 |
|---|---|---|
| (a) | GT | A man catching a baseball as another slides into the base. |
| Base | A baseball player is | |
| 本文方法 | A man is catching the baseball, and another is throwing the ball . | |
| (b) | GT | A black bird standing on top of a power pole. |
| Base | ||
| 本文方法 | A black birtd sitting on top of a wire. | |
| (c) | GT | A polar bear is standing in some snow. |
| Base | A polar bear is standing in the | |
| 本文方法 | A polar bear is standing in the snow . | |
| (d) | GT | A child feeding a giraffe from the palm of his hand. |
| Base | A young boy feeding a giraffe | |
| 本文方法 | A young boy feeding a giraffe with a hand . |
| 1 | HOSSAIN M Z, SOHEL F, SHIRATUDDIN M F, et al. A comprehensive survey of deep learning for image captioning[J]. ACM Computing Surveys, 2019, 51(6): No.118. 10.1145/3295748 |
| 2 | MIKOLOV T, KARAFIÁT M, BURGET L, et al. Recurrent neural network based language model[C]// Proceedings of the INTERSPEECH 2010. [S.l.]: International Speech Communication Association, 2010: 1045-1048. 10.21437/interspeech.2010-343 |
| 3 | 李康康,张静. 基于注意力机制的多层次编码和解码的图像描述模型[J]. 计算机应用, 2021, 41(9):2504-2509. 10.11772/j.issn.1001-9081.2020111838 |
| LI K K, ZHANG J. Multi-layer encoding and decoding model for image captioning based on attention mechanism[J]. Journal of Computer Applications, 2021, 41(9): 2504-2509. 10.11772/j.issn.1001-9081.2020111838 | |
| 4 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 5 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149. 10.1109/tpami.2016.2577031 |
| 6 | ANDERSON P, HE X D, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. 10.1109/cvpr.2018.00636 |
| 7 | HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: transforming objects into words[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems [2022-02-19].. |
| 8 | HUANG L, WANG W M, CHEN J, et al. Attention on attention for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4633-4642. 10.1109/iccv.2019.00473 |
| 9 | JI J Y, LUO Y P, SUN X S, et al. Improving image captioning by leveraging intra- and inter-layer global representation in Transformer network[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 1655-1663. 10.1609/aaai.v35i2.16258 |
| 10 | GUO L T, LIU J, ZHU X X, et al. Normalized and geometry-aware self-attention network for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10324-10333. 10.1109/cvpr42600.2020.01034 |
| 11 | JIANG H Z, MISRA I, ROHRBACH M, et al. In defense of grid features for visual question answering[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10264-10273. 10.1109/cvpr42600.2020.01028 |
| 12 | KRISHNA R, ZHU Y K, GROTH O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. 10.1007/s11263-016-0981-7 |
| 13 | ZHANG X Y, SUN X S, LUO Y P, et al. RSTNet: captioning with adaptive attention on visual and non-visual words[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15460-15469. 10.1109/cvpr46437.2021.01521 |
| 14 | LUO Y P, JI J Y, SUN X S, et al. Dual-level collaborative Transformer for image captioning[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 2286-2293. 10.1609/aaai.v35i3.16328 |
| 15 | YAO T, PAN Y W, LI Y H, et al. Exploring visual relationship for image captioning[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 711-727. |
| 16 | GUO L T, LIU J, TANG J H, et al. Aligning linguistic words and visual semantic units for image captioning[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 765-773. 10.1145/3343031.3350943 |
| 17 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. (2017-02-22) [2022-02-17].. 10.48550/arXiv.1609.02907 |
| 18 | YAO T, PAN Y W, LI Y H, et al. Hierarchy parsing for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2621-2629. 10.1109/iccv.2019.00271 |
| 19 | TAI K S, SOCHER R, MANNING C D. Improved semantic representations from tree-structured long short-term memory networks[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2015: 1556-1566. 10.3115/v1/p15-1150 |
| 20 | ZHENG Q T, WANG Y P. Graph self-attention network for image captioning[C]// Proceedings of the IEEE/ACS 17th International Conference on Computer Systems and Applications. Piscataway: IEEE, 2020: 1-8. 10.1109/aiccsa50499.2020.9316518 |
| 21 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010. |
| 22 | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1179-1195. 10.1109/cvpr.2017.131 |
| 23 | CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10575-10584. 10.1109/cvpr42600.2020.01059 |
| 24 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 25 | KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3128-3137. 10.1109/cvpr.2015.7298932 |
| 26 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2002: 311-318. 10.3115/1073083.1073135 |
| 27 | BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments[C]// Proceedings of the 2005 ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg, PA: ACL, 2005: 65-72. |
| 28 | VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4566-4575. 10.1109/cvpr.2015.7299087 |
| 29 | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of 2004 ACL Workshop on Text Summarization Branches Out. Stroudsburg, PA: ACL, 2004: 74-81. 10.3115/1218955.1219032 |
| 30 | ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: semantic propositional image caption evaluation[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9909. Cham: Springer, 2016: 382-398. |
| 31 | KINGMA D P, BA J. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2022-02-19].. |
| 32 | JIANG W H, MA L, JIANG Y G, et al. Recurrent fusion network for image captioning[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11206. Cham: Springer, 2018: 510-526. |
| 33 | YANG X, TANG K H, ZHANG H W, et al. Auto-encoding scene graphs for image captioning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10677-10686. 10.1109/cvpr.2019.01094 |
| 34 | PAN Y W, YAO T, LI Y H, et al. X-Linear attention networks for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10968-10977. 10.1109/cvpr42600.2020.01098 |
| 35 | LIU W, CHEN S H, GUO L T, et al. CPTR: full Transformer network for image captioning[EB/OL]. (2021-01-28) [2022-02-11].. |
| [1] | 徐志刚, 张创. 基于门控位置编码的壁画图像多级色彩还原[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2931-2937. |
| [2] | 李云, 王富铕, 井佩光, 王粟, 肖澳. 基于不确定度感知的帧关联短视频事件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2903-2910. |
| [3] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [4] | 杨航, 李汪根, 张根生, 王志格, 开新. 基于图神经网络的多层信息交互融合算法用于会话推荐[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2719-2725. |
| [5] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [6] | 陈虹, 齐兵, 金海波, 武聪, 张立昂. 融合1D-CNN与BiGRU的类不平衡流量异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2493-2499. |
| [7] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| [8] | 丁宇伟, 石洪波, 李杰, 梁敏. 基于局部和全局特征解耦的图像去噪网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2571-2579. |
| [9] | 高阳峄, 雷涛, 杜晓刚, 李岁永, 王营博, 闵重丹. 基于像素距离图和四维动态卷积网络的密集人群计数与定位方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2233-2242. |
| [10] | 王东炜, 刘柏辰, 韩志, 王艳美, 唐延东. 基于低秩分解和向量量化的深度网络压缩方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1987-1994. |
| [11] | 柯添赐, 刘建华, 孙水华, 郑智雄, 蔡子杰. 融合强关联依赖和简洁语法的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1786-1795. |
| [12] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [13] | 李健京, 李贯峰, 秦飞舟, 李卫军. 基于不确定知识图谱嵌入的多关系近似推理模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1751-1759. |
| [14] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [15] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||