


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (10): 3217-3222.DOI: 10.11772/j.issn.1001-9081.2023101458
王晗, 赵腊生( ), 张强, 程银清, 邱泽鹏
), 张强, 程银清, 邱泽鹏
收稿日期:2023-10-27
修回日期:2024-02-22
接受日期:2024-02-26
发布日期:2024-10-15
出版日期:2024-10-10
通讯作者:
赵腊生
作者简介:王晗(1998—),女,辽宁铁岭人,硕士研究生,主要研究方向:深度学习、语音鉴伪基金资助:
Han WANG, Lasheng ZHAO(), Qiang ZHANG, Yinqing CHENG, Zepeng QIU
Received:2023-10-27
Revised:2024-02-22
Accepted:2024-02-26
Online:2024-10-15
Published:2024-10-10
Contact:
Lasheng ZHAO
About author:WANG Han, born in 1998, M. S. candidate. Her research interests include deep learning, spoof speech detection.Supported by:摘要:
合成语音攻击给人们的生活带来巨大的威胁。为了解决现有模型从冗余信息中提取关键信息能力不足和单一模型无法综合利用多检测模型优势的问题,提出一种基于注意力和挤压-激励(SE)模块Inception (SE-Inc)的双分支(Dual-ABIB)合成语音检测模型。首先,基于SincNet(Sinc-based convolutional neural Network)提取的初始特征图训练注意力分支合成语音检测模型,并输出注意力图;其次,将注意力图和初始特征图相乘后再叠加,并将结果作为SE-Inc分支的输入进行训练;最后,通过决策级加权融合处理2个分支获得的分类分数,从而实现合成语音检测。实验结果表明,所提模型在参数量为539×103的情况下,在ASVspoof2019数据集上获得了0.033 2的最小串联检测代价函数(min t-DCF)和1.15%的等错误率(EER);与SE-ResABNet (Squeeze-Excitation ResNet Attention Branch Network)相比,所提模型在参数量仅为它的56%的情况下,min t-DCF和EER分别下降了34.5%和39.2%;同时,在ASVspoof2015和ASVspoof2021数据集上所提模型表现了更好的泛化能力。以上结果验证了所提模型能够在参数量较小的情况下,获得更低的min t-DCF和EER。
中图分类号:
王晗, 赵腊生, 张强, 程银清, 邱泽鹏. 基于注意力和挤压‒激励Inception的双分支合成语音检测[J]. 计算机应用, 2024, 44(10): 3217-3222.
Han WANG, Lasheng ZHAO, Qiang ZHANG, Yinqing CHENG, Zepeng QIU. Dual branch synthetic speech detection based on attention and squeeze-excitation inception[J]. Journal of Computer Applications, 2024, 44(10): 3217-3222.
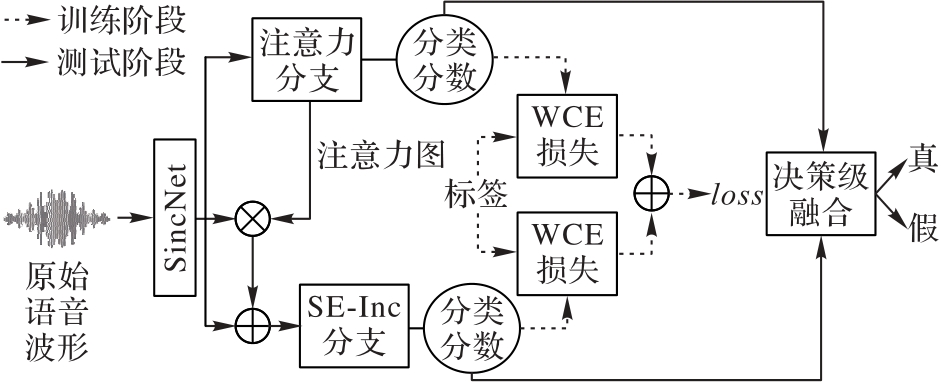
图1 Dual-ABIB模型的结构
Fig. 1 Structure of Dual-ABIB model
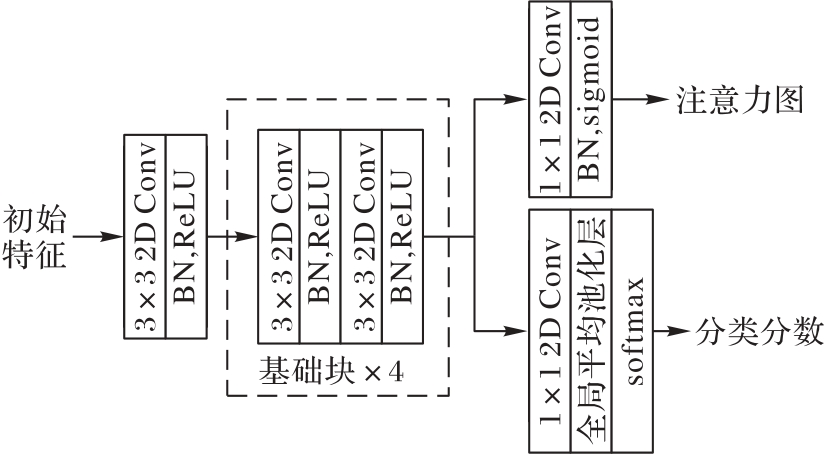
图2 注意力分支网络的结构
Fig. 2 Structure of attention branch network
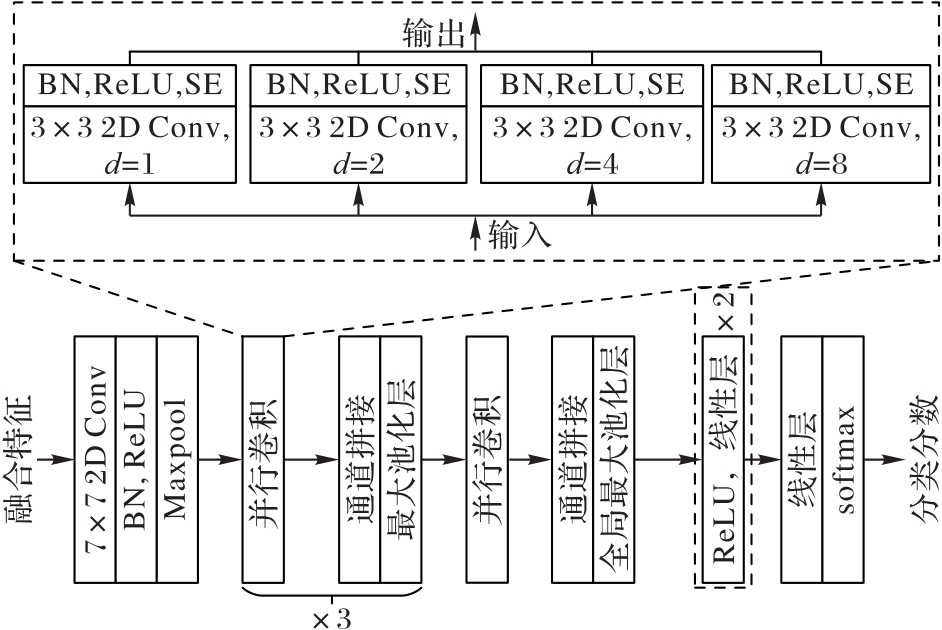
图3 SE-Inc分支网络的结构
Fig. 3 Structure of SE-Inc branch network
| 子集 | 真实语音样本数 | 合成语音样本数 | 伪造种类 |
|---|---|---|---|
| 训练集 | 2 580 | 22 800 | A01~A06 |
| 开发集 | 2 548 | 22 296 | A01~A06 |
| 测试集 | 7 355 | 63 882 | A07~A19 |
表1 ASVspoof2019LA数据集详情
Tab. 1 Details of ASVspoof2019LA dataset
| 子集 | 真实语音样本数 | 合成语音样本数 | 伪造种类 |
|---|---|---|---|
| 训练集 | 2 580 | 22 800 | A01~A06 |
| 开发集 | 2 548 | 22 296 | A01~A06 |
| 测试集 | 7 355 | 63 882 | A07~A19 |
| 模型 | EER |
|---|---|
| Inc-TSSDNet[ | 4.04 |
| Sinc-Attention | 3.89 |
| Sinc-Inception | 3.49 |
表2 单分支模型检测结果 (%)
Tab. 2 Detection results of single-branch models
| 模型 | EER |
|---|---|
| Inc-TSSDNet[ | 4.04 |
| Sinc-Attention | 3.89 |
| Sinc-Inception | 3.49 |
| 测试模型 | EER |
|---|---|
| AB分支 | 1.81 |
| IB分支 | 1.63 |
| 加权融合 | 1.15 |
表3 决策级融合的消融实验结果 (%)
Tab. 3 Ablation experimental results of decision-level fusion
| 测试模型 | EER |
|---|---|
| AB分支 | 1.81 |
| IB分支 | 1.63 |
| 加权融合 | 1.15 |
| 方法 | EER/% | min t-DCF | 计算效率/ms | |
|---|---|---|---|---|
| Att | SE | |||
| × | × | 3.49 | 0.086 9 | 5.67 |
| × | √ | 2.13 | 0.066 2 | 7.17 |
| √ | × | 1.33 | 0.037 2 | 6.28 |
| √ | √ | 1.15 | 0.033 2 | 9.97 |
表4 不同模块的消融实验结果
Tab. 4 Ablation experimental results of different modules
| 方法 | EER/% | min t-DCF | 计算效率/ms | |
|---|---|---|---|---|
| Att | SE | |||
| × | × | 3.49 | 0.086 9 | 5.67 |
| × | √ | 2.13 | 0.066 2 | 7.17 |
| √ | × | 1.33 | 0.037 2 | 6.28 |
| √ | √ | 1.15 | 0.033 2 | 9.97 |
| 模型 | 前端特征 | 测试集 | 参数量/103 | |
|---|---|---|---|---|
| EER/% | min t-DCF | |||
| RawNet2[ | Waveform | 4.66 | 0.129 4 | 25 430 |
| Inc-TSSDNet[ | Waveform | 4.04 | 0.097 6 | 92 |
| CapsNet[ | LFCC | 1.97 | 0.053 8 | — |
| LCNN-LSTM[ | LFCC | 1.92 | 0.052 4 | — |
| SE-ResABNet[ | LFCC | 1.89 | 0.050 7 | 964 |
| Raw PC-DARTS[ | Waveform | 1.77 | 0.051 7 | 24 480 |
| FPM+EM-Softmax[ | LFCC | 1.65 | 0.047 0 | — |
| LGF[ | Wav2Vec2.0 | 1.28 | 0.100 0 | — |
| Dual-ABIB | Waveform | 1.15 | 0.033 2 | 539 |
表5 不同模型在ASVspoof2019LA测试集上的性能比较
Tab. 5 Comparison of different models on ASVspoof2019LA test set
| 模型 | 前端特征 | 测试集 | 参数量/103 | |
|---|---|---|---|---|
| EER/% | min t-DCF | |||
| RawNet2[ | Waveform | 4.66 | 0.129 4 | 25 430 |
| Inc-TSSDNet[ | Waveform | 4.04 | 0.097 6 | 92 |
| CapsNet[ | LFCC | 1.97 | 0.053 8 | — |
| LCNN-LSTM[ | LFCC | 1.92 | 0.052 4 | — |
| SE-ResABNet[ | LFCC | 1.89 | 0.050 7 | 964 |
| Raw PC-DARTS[ | Waveform | 1.77 | 0.051 7 | 24 480 |
| FPM+EM-Softmax[ | LFCC | 1.65 | 0.047 0 | — |
| LGF[ | Wav2Vec2.0 | 1.28 | 0.100 0 | — |
| Dual-ABIB | Waveform | 1.15 | 0.033 2 | 539 |
| 模型 | EER | ||
|---|---|---|---|
| 19LA | 15LA | 21LA | |
| LFCC-GMM[ | 9.57 | 14.87 | 19.30 |
| CQCC-GMM[ | 8.09 | 36.31 | 15.62 |
| Inc-TSSDNet[ | 4.04 | 3.29 | 17.56 |
| AASIST[ | 1.13 | 3.22 | 10.90 |
| Dual-ABIB | 1.15 | 2.29 | 10.43 |
表6 跨数据集检测结果 (%)
Tab. 6 Cross-dataset test results
| 模型 | EER | ||
|---|---|---|---|
| 19LA | 15LA | 21LA | |
| LFCC-GMM[ | 9.57 | 14.87 | 19.30 |
| CQCC-GMM[ | 8.09 | 36.31 | 15.62 |
| Inc-TSSDNet[ | 4.04 | 3.29 | 17.56 |
| AASIST[ | 1.13 | 3.22 | 10.90 |
| Dual-ABIB | 1.15 | 2.29 | 10.43 |
| 1 | SNYDER D, GARCIA-ROMERO D, SELL G, et al. X-vectors: robust DNN embeddings for speaker recognition[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5329-5333. |
| 2 | KAUR N, SINGH P. Conventional and contemporary approaches used in text to speech synthesis: a review[J]. Artificial Intelligence Review, 2022, 56(7): 5837-5880. |
| 3 | SISMAN B, YAMAGISHI J, KING S, et al. An overview of voice conversion and its challenges: from statistical modeling to deep learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 132-157. |
| 4 | HU C, ZHOU R, YUAN Q. Replay speech detection based on dual-input hierarchical fusion network[J]. Applied Sciences, 2023, 13(9): No.5350. |
| 5 | 任延珍,刘晨雨,刘武洋,等. 语音伪造及检测技术研究综述[J]. 信号处理, 2021, 37(12): 2412-2439. |
| REN Y Z, LIU C Y, LIU W Y, et al. A survey on speech forgery and detection[J]. Journal of Signal Processing, 2021, 37(12): 2412-2439. | |
| 6 | WEI L, LONG Y, WEI H, et al. New acoustic features for synthetic and replay spoofing attack detection[J]. Symmetry, 2022, 14(2): No.274. |
| 7 | TODISCO M, DELGADO H, EVANS N. Constant Q cepstral coefficients: a spoofing countermeasure for automatic speaker verification[J]. Computer Speech and Language, 2017, 45: 516-535. |
| 8 | PATEL T B, PATIL H A. Combining evidences from mel cepstral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech[C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 2062-2066. |
| 9 | CUI S, HUANG B, HUANG J, et al. Synthetic speech detection based on local autoregression and variance statistics[J]. IEEE Signal Processing Letters, 2022, 29: 1462-1466. |
| 10 | RAVANELLI M, BENGIO Y. Speaker recognition from raw waveform with SincNet[C]// Proceedings of the 2018 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2018: 1021-1028. |
| 11 | DINKEL H, CHEN N, QIAN Y, et al. End-to-end spoofing detection with raw waveform CLDNNS[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 4860-4864. |
| 12 | MA Y, REN Z, XU S. RW-ResNet: a novel speech anti-spoofing model using raw waveform[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 4144-4148. |
| 13 | TAK H, PATINO J, TODISCO M, et al. End-to-end anti-spoofing with RawNet2[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6369-6373. |
| 14 | JUNG J W, HEO H S, TAK H, et al. AASIST: audio anti-spoofing using integrated spectro-temporal graph attention networks[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6367-6371. |
| 15 | ALZANTOT M, WANG Z, SRIVASTAVA M B. Deep residual neural networks for audio spoofing detection[C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 1078-1082. |
| 16 | WU Z, DAS R K, YANG J, et al. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 1101-1105. |
| 17 | LUO A, LI E, LIU Y, et al. A capsule network based approach for detection of audio spoofing attacks[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6359-6363. |
| 18 | HUA G, TEOH A B J, ZHANG H. Towards end-to-end synthetic speech detection[J]. IEEE Signal Processing Letters, 2021, 28: 1265-1269. |
| 19 | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. |
| 20 | LIU X, LIU M, WANG L, et al. Leveraging positional-related local-global dependency for synthetic speech detection[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 21 | FUKUI H, HIRAKAWA T, YAMASHITA T, et al. Attention branch network: learning of attention mechanism for visual explanation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10697-10706. |
| 22 | 张秋余,王煜坤. 基于改进Inception网络的语音分类模型[J]. 计算机应用, 2023, 43(3): 909-915. |
| ZHANG Q Y, WANG Y K. Speech classification model based on improved Inception network[J]. Journal of Computer Applications, 2023, 43(3):909-915. | |
| 23 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| 24 | WANG X, YAMAGISHI J, TODISCO M, et al. ASVspoof 2019: a large-scale public database of synthesized, converted and replayed speech[J]. Computer Speech and Language, 2020, 64: No.101114 . |
| 25 | WU Z, KINNUNEN T, EVANS N, et al. ASVspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge[C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 2037-2041. |
| 26 | LIU X, WANG X, SAHIDULLAH M, et al. ASVspoof 2021: towards spoofed and deepfake speech detection in the wild[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 2507-2522. |
| 27 | BRÜMMER N, DE VILLIERS E. The BOSARIS Toolkit user guide: theory, algorithms and code for binary classifier score processing[EB/OL]. (2013-04-10) [2023-08-10]. . |
| 28 | KINNUNEN T, DELGADO H, EVANS N, et al. Tandem assessment of spoofing countermeasures and automatic speaker verification: fundamentals[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2195-2210. |
| 29 | WANG X, YAMAGISHI J. A comparative study on recent neural spoofing countermeasures for synthetic speech detection[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 4259-4263. |
| 30 | ROSTAMI A M, HOMAYOUNPOUR M M, NICKABADI A. Efficient attention branch network with combined loss function for automatic speaker verification spoof detection[J]. Circuits, Systems, and Signal Processing, 2023, 42(7): 4252-4270. |
| 31 | GE W, PATINO J, TODISCO M, et al. Raw differentiable architecture Search for speech deepfake and spoofing detection[C]// Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge. [S.l.]: International Speech Communication Association, 2021: 22-28. |
| 32 | GONG J, CHEN N. Synthetic voice spoofing detection based on feature pyramid conformer[C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 2803-2807. |
| 33 | WANG X, YAMAGISHI J. Investigating self-supervised front ends for speech spoofing countermeasures[C]// Proceedings of the 2021 Speaker and Language Recognition Workshop. [S.l.]: International Speech Communication Association, 2022: 100-106. |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [3] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [9] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [10] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [11] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [12] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| [13] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [14] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [15] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||