


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (4): 1317-1324.DOI: 10.11772/j.issn.1001-9081.2023040452
所属专题: 多媒体计算与计算机仿真
• 多媒体计算与计算机仿真 • 上一篇
尤昕源, 王恒( )
)
收稿日期:2023-04-21
修回日期:2023-07-06
接受日期:2023-07-10
发布日期:2023-12-04
出版日期:2024-04-10
通讯作者:
王恒
作者简介:尤昕源(1998—),女,河南洛阳人,硕士研究生,CCF会员,主要研究方向:单声道语音增强; ∗基金资助:Received:2023-04-21
Revised:2023-07-06
Accepted:2023-07-10
Online:2023-12-04
Published:2024-04-10
Contact:
Heng WANG
About author:YOU Xinyuan, born in 1998, M. S. candidate. Her research interests include monaural speech enhancement.
Supported by:摘要:
上下文信息的使用在语音增强任务中具有重要作用。针对全局语音利用不充分的问题,提出一种用于复数频谱映射的门控膨胀卷积循环网络(GDCRN)。GDCRN包含编码器、门控时间卷积模块(GTCM)和解码器这3部分,编码器和解码器是非对称的网络结构。首先,编码器利用门控膨胀卷积模块(GDCM)扩大感受野,处理特征;其次,使用GTCM捕获更长的上下文信息,并选择性传递特征;最后,解码器使用结合门控线性单元(GLU)的反卷积,反卷积与编码器中对应层的卷积层使用跳跃连接,并引入通道时频注意力(CTFA)机制。实验结果表明,相较于时间卷积神经网络(TCNN)、门控卷积循环网络(GCRN)等网络,所提网络的参数量和训练时间更少,客观语音质量评估(PESQ)和短时客观可懂度(STOI)都有显著改善,最高可提升0.258 9和4.67个百分点,具有更好的增强效果与更强的泛化能力。
中图分类号:
尤昕源, 王恒. 基于门控膨胀卷积循环网络的单声道语音增强[J]. 计算机应用, 2024, 44(4): 1317-1324.
Xinyuan YOU, Heng WANG. Monaural speech enhancement based on gated dilated convolutional recurrent network[J]. Journal of Computer Applications, 2024, 44(4): 1317-1324.

图1 语音增强流程
Fig. 1 Speech enhancement flow
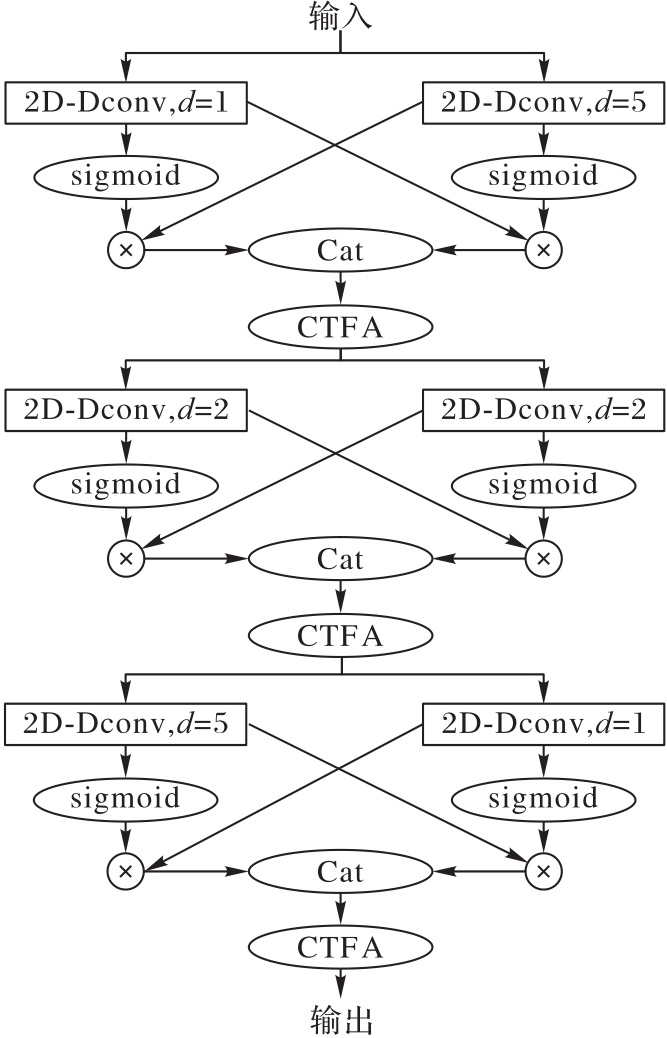
图2 门控膨胀卷积模块结构
Fig. 2 Structure of gated dilated convolution module
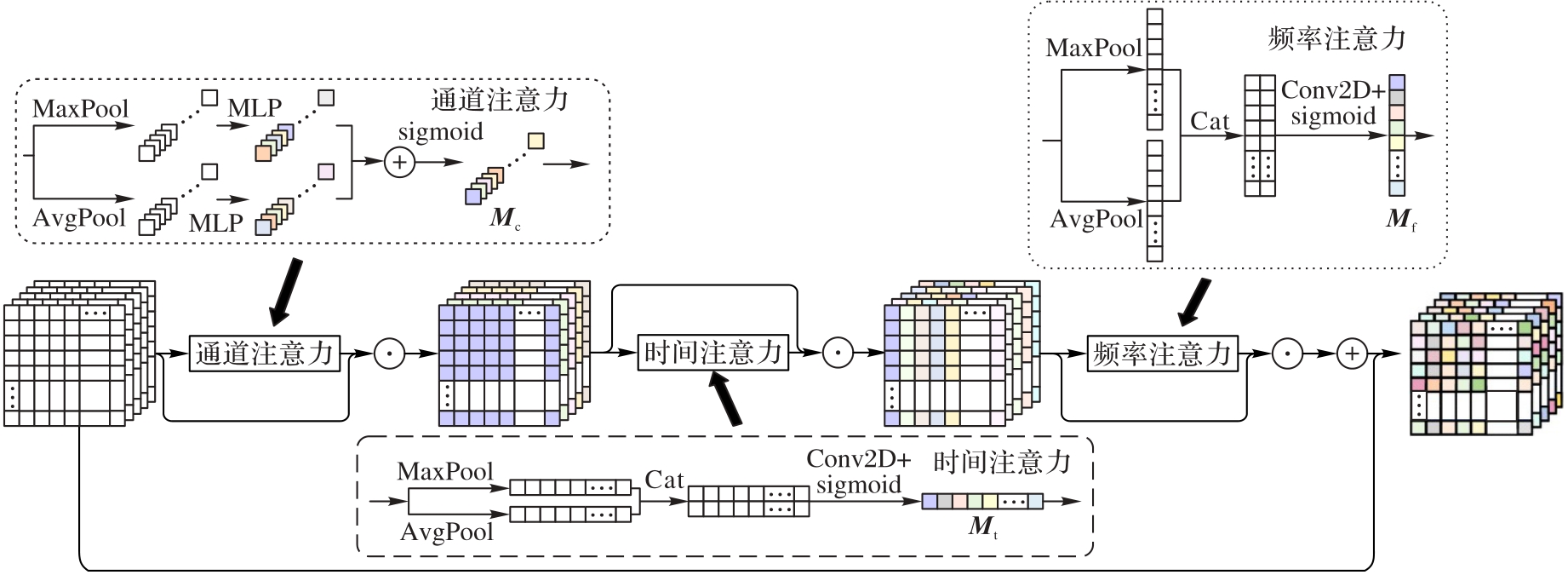
图3 通道时频注意力结构
Fig. 3 Structure of channel time-frequency attention

图4 门控时间卷积模块结构
Fig. 4 Structure of gated temporal convolution module

图5 GDCRN结构
Fig. 5 Structure of GDCRN
| 层 | 输入 维度 | 参数 | 输出 维度 | ||
|---|---|---|---|---|---|
| k | s | d | |||
| dilated conv2d_1(×2) | 2×T×161 | (3,3) | (1,2) | 1,5 | 16×T×80 |
| dilated conv2d_2(×2) | 32×T×80 | (3,3) | (1,2) | 2,2 | 32×T×39 |
| dilated conv2d_3(×2) | 64×T×39 | (3,3) | (1,2) | 5,1 | 32×T×19 |
| dilated conv2d_4(×2) | 64×T×19 | (3,3) | (1,2) | 1,5 | 64×T×9 |
| dilated conv2d_5(×2) | 128×T×9 | (3,3) | (1,2) | 2,2 | 64×T×4 |
| dilated conv2d_6(×2) | 128×T×4 | (3,3) | (1,2) | 5,1 | 128×T×4 |
| GTCM | 256×T×4 | (1,1), (3,3) | (1,1), (1,2) | 1 | 256×T×4 |
| 256×T×4 | (3,1) | (1,1) | 1 | 256×T×4 | |
| (3,1) | (1,1) | 1 | |||
| (3,1) | (1,1) | 2 | |||
| (3,1) | (1,1) | 2 | |||
| (3,1) | (1,1) | 4 | |||
| (3,1) | (1,1) | 4 | |||
| (3,1) | (1,1) | 8 | |||
| (3,1) | (1,1) | 8 | |||
| 256×T×4 | (1,1), (3,3) | (1,1), (1,2) | 1 | 256×T×4 | |
| deconv2d_glu_6(×2) | 512×T×4 | (3,1) | (1,1) | 1 | 128×T×4 |
| deconv2d_glu_5(×2) | 256×T×4 | (3,1) | (1,2) | 1 | 128×T×9 |
| deconv2d_glu_4(×2) | 256×T×9 | (3,1) | (1,2) | 1 | 64×T×19 |
| deconv2d_glu_3(×2) | 128×T×9 | (3,1) | (1,2) | 1 | 64×T×39 |
| deconv2d_glu_2(×2) | 128×T×39 | (3,1) | (1,2) | 1 | 32×T×80 |
| deconv2d_glu_1(×2) | 64×T×80 | (3,1) | (1,2) | 1 | 1×T×161 |
| linear(×2) | 1×T×161 | — | — | — | 1×T×161 |
表1 网络参数
Tab. 1 Parameters of network
| 层 | 输入 维度 | 参数 | 输出 维度 | ||
|---|---|---|---|---|---|
| k | s | d | |||
| dilated conv2d_1(×2) | 2×T×161 | (3,3) | (1,2) | 1,5 | 16×T×80 |
| dilated conv2d_2(×2) | 32×T×80 | (3,3) | (1,2) | 2,2 | 32×T×39 |
| dilated conv2d_3(×2) | 64×T×39 | (3,3) | (1,2) | 5,1 | 32×T×19 |
| dilated conv2d_4(×2) | 64×T×19 | (3,3) | (1,2) | 1,5 | 64×T×9 |
| dilated conv2d_5(×2) | 128×T×9 | (3,3) | (1,2) | 2,2 | 64×T×4 |
| dilated conv2d_6(×2) | 128×T×4 | (3,3) | (1,2) | 5,1 | 128×T×4 |
| GTCM | 256×T×4 | (1,1), (3,3) | (1,1), (1,2) | 1 | 256×T×4 |
| 256×T×4 | (3,1) | (1,1) | 1 | 256×T×4 | |
| (3,1) | (1,1) | 1 | |||
| (3,1) | (1,1) | 2 | |||
| (3,1) | (1,1) | 2 | |||
| (3,1) | (1,1) | 4 | |||
| (3,1) | (1,1) | 4 | |||
| (3,1) | (1,1) | 8 | |||
| (3,1) | (1,1) | 8 | |||
| 256×T×4 | (1,1), (3,3) | (1,1), (1,2) | 1 | 256×T×4 | |
| deconv2d_glu_6(×2) | 512×T×4 | (3,1) | (1,1) | 1 | 128×T×4 |
| deconv2d_glu_5(×2) | 256×T×4 | (3,1) | (1,2) | 1 | 128×T×9 |
| deconv2d_glu_4(×2) | 256×T×9 | (3,1) | (1,2) | 1 | 64×T×19 |
| deconv2d_glu_3(×2) | 128×T×9 | (3,1) | (1,2) | 1 | 64×T×39 |
| deconv2d_glu_2(×2) | 128×T×39 | (3,1) | (1,2) | 1 | 32×T×80 |
| deconv2d_glu_1(×2) | 64×T×80 | (3,1) | (1,2) | 1 | 1×T×161 |
| linear(×2) | 1×T×161 | — | — | — | 1×T×161 |
| 数据集 | 噪声 | test SNR/dB | Noisy | CRN | GCRN | TCNN | DARCN | GDCRN | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | |||
| WSJ0 | babble | -5 | 1.059 4 | 60.62 | 1.131 6 | 64.94 | 1.139 6 | 66.08 | 1.134 2 | 65.43 | 1.146 2 | 64.88 | 1.167 4 | 65.58 |
| 0 | 1.084 4 | 71.08 | 1.333 2 | 77.55 | 1.341 0 | 79.53 | 1.368 1 | 78.93 | 1.336 2 | 78.78 | 1.401 3 | 80.18 | ||
| 5 | 1.164 6 | 80.47 | 1.639 1 | 85.77 | 1.625 5 | 86.66 | 1.586 1 | 85.58 | 1.659 9 | 87.07 | 1.723 0 | 86.96 | ||
| factory2 | -5 | 1.041 4 | 58.92 | 1.115 9 | 61.81 | 1.124 9 | 62.57 | 1.112 5 | 63.50 | 1.126 9 | 63.97 | 1.137 9 | 66.06 | |
| 0 | 1.051 5 | 69.11 | 1.232 0 | 73.50 | 1.250 9 | 76.86 | 1.249 8 | 75.56 | 1.239 3 | 76.83 | 1.326 1 | 78.92 | ||
| 5 | 1.096 3 | 78.65 | 1.365 2 | 82.39 | 1.478 3 | 84.41 | 1.487 7 | 84.05 | 1.512 2 | 84.73 | 1.579 8 | 85.80 | ||
| TIMIT | babble | -5 | 1.059 4 | 60.62 | 1.095 0 | 61.27 | 1.124 8 | 60.83 | 1.063 4 | 61.10 | 1.120 2 | 60.87 | 1.160 5 | 61.36 |
| 0 | 1.084 4 | 71.08 | 1.169 9 | 71.87 | 1.259 9 | 72.54 | 1.164 8 | 71.13 | 1.171 3 | 72.38 | 1.319 3 | 73.36 | ||
| 5 | 1.164 6 | 80.47 | 1.288 5 | 79.27 | 1.479 9 | 80.52 | 1.294 7 | 78.48 | 1.418 8 | 80.93 | 1.553 6 | 81.15 | ||
| factory2 | -5 | 1.041 4 | 58.92 | 1.070 8 | 61.27 | 1.090 7 | 62.00 | 1.087 3 | 61.74 | 1.078 1 | 61.87 | 1.125 4 | 61.75 | |
| 0 | 1.051 5 | 69.11 | 1.137 4 | 71.87 | 1.183 0 | 72.97 | 1.140 7 | 71.96 | 1.212 4 | 72.94 | 1.252 3 | 73.23 | ||
| 5 | 1.096 3 | 78.65 | 1.239 9 | 79.27 | 1.309 0 | 79.64 | 1.290 2 | 79.68 | 1.377 8 | 80.12 | 1.423 4 | 80.49 | ||
| VoiceBank | babble | -5 | 1.059 4 | 60.62 | 1.067 4 | 62.48 | 1.122 1 | 64.36 | 1.102 0 | 63.72 | 1.113 8 | 63.81 | 1.144 4 | 66.83 |
| 0 | 1.084 4 | 71.08 | 1.155 0 | 75.50 | 1.295 1 | 79.03 | 1.183 9 | 77.56 | 1.277 0 | 75.05 | 1.336 8 | 79.47 | ||
| 5 | 1.164 6 | 80.47 | 1.365 8 | 84.35 | 1.554 2 | 86.08 | 1.417 1 | 81.68 | 1.459 9 | 86.56 | 1.618 8 | 86.35 | ||
| factory2 | -5 | 1.041 4 | 58.92 | 1.056 8 | 62.16 | 1.101 2 | 63.91 | 1.080 8 | 63.61 | 1.078 1 | 64.21 | 1.108 2 | 66.40 | |
| 0 | 1.051 5 | 69.11 | 1.133 5 | 73.10 | 1.244 6 | 77.45 | 1.181 3 | 74.12 | 1.177 5 | 75.35 | 1.240 8 | 78.39 | ||
| 5 | 1.096 3 | 78.65 | 1.283 5 | 81.55 | 1.417 3 | 84.18 | 1.294 8 | 83.70 | 1.375 8 | 84.28 | 1.422 9 | 85.13 | ||
表2 不同数据集上各网络STOI和PESQ
Tab. 2 STOI and PESQ for different networks on different datasets
| 数据集 | 噪声 | test SNR/dB | Noisy | CRN | GCRN | TCNN | DARCN | GDCRN | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | |||
| WSJ0 | babble | -5 | 1.059 4 | 60.62 | 1.131 6 | 64.94 | 1.139 6 | 66.08 | 1.134 2 | 65.43 | 1.146 2 | 64.88 | 1.167 4 | 65.58 |
| 0 | 1.084 4 | 71.08 | 1.333 2 | 77.55 | 1.341 0 | 79.53 | 1.368 1 | 78.93 | 1.336 2 | 78.78 | 1.401 3 | 80.18 | ||
| 5 | 1.164 6 | 80.47 | 1.639 1 | 85.77 | 1.625 5 | 86.66 | 1.586 1 | 85.58 | 1.659 9 | 87.07 | 1.723 0 | 86.96 | ||
| factory2 | -5 | 1.041 4 | 58.92 | 1.115 9 | 61.81 | 1.124 9 | 62.57 | 1.112 5 | 63.50 | 1.126 9 | 63.97 | 1.137 9 | 66.06 | |
| 0 | 1.051 5 | 69.11 | 1.232 0 | 73.50 | 1.250 9 | 76.86 | 1.249 8 | 75.56 | 1.239 3 | 76.83 | 1.326 1 | 78.92 | ||
| 5 | 1.096 3 | 78.65 | 1.365 2 | 82.39 | 1.478 3 | 84.41 | 1.487 7 | 84.05 | 1.512 2 | 84.73 | 1.579 8 | 85.80 | ||
| TIMIT | babble | -5 | 1.059 4 | 60.62 | 1.095 0 | 61.27 | 1.124 8 | 60.83 | 1.063 4 | 61.10 | 1.120 2 | 60.87 | 1.160 5 | 61.36 |
| 0 | 1.084 4 | 71.08 | 1.169 9 | 71.87 | 1.259 9 | 72.54 | 1.164 8 | 71.13 | 1.171 3 | 72.38 | 1.319 3 | 73.36 | ||
| 5 | 1.164 6 | 80.47 | 1.288 5 | 79.27 | 1.479 9 | 80.52 | 1.294 7 | 78.48 | 1.418 8 | 80.93 | 1.553 6 | 81.15 | ||
| factory2 | -5 | 1.041 4 | 58.92 | 1.070 8 | 61.27 | 1.090 7 | 62.00 | 1.087 3 | 61.74 | 1.078 1 | 61.87 | 1.125 4 | 61.75 | |
| 0 | 1.051 5 | 69.11 | 1.137 4 | 71.87 | 1.183 0 | 72.97 | 1.140 7 | 71.96 | 1.212 4 | 72.94 | 1.252 3 | 73.23 | ||
| 5 | 1.096 3 | 78.65 | 1.239 9 | 79.27 | 1.309 0 | 79.64 | 1.290 2 | 79.68 | 1.377 8 | 80.12 | 1.423 4 | 80.49 | ||
| VoiceBank | babble | -5 | 1.059 4 | 60.62 | 1.067 4 | 62.48 | 1.122 1 | 64.36 | 1.102 0 | 63.72 | 1.113 8 | 63.81 | 1.144 4 | 66.83 |
| 0 | 1.084 4 | 71.08 | 1.155 0 | 75.50 | 1.295 1 | 79.03 | 1.183 9 | 77.56 | 1.277 0 | 75.05 | 1.336 8 | 79.47 | ||
| 5 | 1.164 6 | 80.47 | 1.365 8 | 84.35 | 1.554 2 | 86.08 | 1.417 1 | 81.68 | 1.459 9 | 86.56 | 1.618 8 | 86.35 | ||
| factory2 | -5 | 1.041 4 | 58.92 | 1.056 8 | 62.16 | 1.101 2 | 63.91 | 1.080 8 | 63.61 | 1.078 1 | 64.21 | 1.108 2 | 66.40 | |
| 0 | 1.051 5 | 69.11 | 1.133 5 | 73.10 | 1.244 6 | 77.45 | 1.181 3 | 74.12 | 1.177 5 | 75.35 | 1.240 8 | 78.39 | ||
| 5 | 1.096 3 | 78.65 | 1.283 5 | 81.55 | 1.417 3 | 84.18 | 1.294 8 | 83.70 | 1.375 8 | 84.28 | 1.422 9 | 85.13 | ||
| 噪声 | test SNR/dB | Noisy | SENet | CBAM | CTFA-a | CTFA-b | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | ||
| babble | -5 | 1.059 4 | 60.62 | 1.123 2 | 62.84 | 1.157 3 | 65.13 | 1.148 1 | 64.77 | 1.167 4 | 65.58 |
| 0 | 1.084 4 | 71.08 | 1.293 1 | 77.25 | 1.399 6 | 80.10 | 1.382 | 79.40 | 1.401 3 | 80.18 | |
| 5 | 1.164 6 | 80.47 | 1.606 7 | 85.80 | 1.717 5 | 87.16 | 1.695 8 | 86.95 | 1.723 0 | 86.96 | |
| factory2 | -5 | 1.041 4 | 58.92 | 1.122 8 | 65.40 | 1.137 0 | 65.69 | 1.122 7 | 63.98 | 1.137 9 | 66.06 |
| 0 | 1.051 5 | 69.11 | 1.272 6 | 77.97 | 1.294 6 | 78.79 | 1.280 2 | 77.61 | 1.326 1 | 78.92 | |
| 5 | 1.096 3 | 78.65 | 1.466 8 | 85.01 | 1.492 9 | 85.36 | 1.502 1 | 84.79 | 1.579 8 | 85.80 | |
表3 WSJ0数据集下3种注意力机制的STOI和PESQ
Tab. 3 STOI and PESQ for three attention mechanisms under WSJ0 dataset
| 噪声 | test SNR/dB | Noisy | SENet | CBAM | CTFA-a | CTFA-b | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | PESQ | STOI/% | ||
| babble | -5 | 1.059 4 | 60.62 | 1.123 2 | 62.84 | 1.157 3 | 65.13 | 1.148 1 | 64.77 | 1.167 4 | 65.58 |
| 0 | 1.084 4 | 71.08 | 1.293 1 | 77.25 | 1.399 6 | 80.10 | 1.382 | 79.40 | 1.401 3 | 80.18 | |
| 5 | 1.164 6 | 80.47 | 1.606 7 | 85.80 | 1.717 5 | 87.16 | 1.695 8 | 86.95 | 1.723 0 | 86.96 | |
| factory2 | -5 | 1.041 4 | 58.92 | 1.122 8 | 65.40 | 1.137 0 | 65.69 | 1.122 7 | 63.98 | 1.137 9 | 66.06 |
| 0 | 1.051 5 | 69.11 | 1.272 6 | 77.97 | 1.294 6 | 78.79 | 1.280 2 | 77.61 | 1.326 1 | 78.92 | |
| 5 | 1.096 3 | 78.65 | 1.466 8 | 85.01 | 1.492 9 | 85.36 | 1.502 1 | 84.79 | 1.579 8 | 85.80 | |
| 网络 | 参数量/106 | 网络 | 参数量/106 |
|---|---|---|---|
| CRN | 17.58 | GDCRN | 4.52 |
| GCRN | 9.77 | DARCN | 1.23 |
| TCNN | 5.10 |
表4 5个网络的参数量
Tab. 4 Parameters of five networks
| 网络 | 参数量/106 | 网络 | 参数量/106 |
|---|---|---|---|
| CRN | 17.58 | GDCRN | 4.52 |
| GCRN | 9.77 | DARCN | 1.23 |
| TCNN | 5.10 |
| 1 | 蓝天,彭川,李森,等. 单声道语音降噪与去混响研究综述[J].计算机研究与发展,2020,57(5):928-953. 10.7544/issn1000-1239.2020.20190306 |
| LAN T, PENG C, LI S, et al. An overview of monaural speech denoising and dereverberation research[J]. Journal of Computer Research and Development, 2020,57(5):928-953. 10.7544/issn1000-1239.2020.20190306 | |
| 2 | ANDERSEN K T, MOONEN M. Robust speech-distortion weighted interframe Wiener filters for single-channel noise reduction[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(1): 97-107. 10.1109/taslp.2017.2761699 |
| 3 | WANG Y, BROOKES M. Model-based speech enhancement in the modulation domain[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(3): 580-594. 10.1109/taslp.2017.2786863 |
| 4 | 张青,吴进.基于多窗谱估计的改进维纳滤波语音增强[J].计算机应用与软件,2017,34(3):67-70, 118. 10.3969/j.issn.1000-386x.2017.03.011 |
| ZHANG Q, WU J. Improved Wiener filter speech enhancement based on multi-taper spectrum estimation[J]. Computer Applications and Software, 2017,34(3):67-70, 118. 10.3969/j.issn.1000-386x.2017.03.011 | |
| 5 | ZHONG X, DAI Y, DAI Y, et al. Study on processing of wavelet speech denoising in speech recognition system[J]. International Journal of Speech Technology, 2018, 21: 563-569. 10.1007/s10772-018-9516-7 |
| 6 | MARTIN R. Speech enhancement using MMSE short time spectral estimation with gamma distributed speech priors[C]// Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2002: I-253-I-256. 10.1109/icassp.2002.1005724 |
| 7 | FARAJI N, KOHANSAL A. MMSE and maximum a posteriori estimators for speech enhancement in additive noise assuming a t-location-scale clean speech prior[J]. IET Signal Processing, 2018, 12(4): 532-543. 10.1049/iet-spr.2017.0446 |
| 8 | DIVENYI P. Speech Separation by Humans and Machines[M]. [S.l.]: Kluwer Academic Publishers, 2005: 181-197. 10.1007/b99695 |
| 9 | WANG Y, NARAYANAN A, WANG D L. On training targets for supervised speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12): 1849-1858. 10.1109/taslp.2014.2352935 |
| 10 | MOWLAEE P, SAEIDI R, MARTIN R. Phase estimation for signal reconstruction in single-channel speech separation[C]// Proceedings of the Interspeech 2012. Grenoble, France: International Speech Communication Association, 2012: 1548-1551. 10.21437/interspeech.2012-436 |
| 11 | ERDOGAN H, HERSHEY J R, WATANABE S, et al. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks[C]// Proceedings of the 2015 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2015: 708-712. 10.1109/icassp.2015.7178061 |
| 12 | WILLIAMSON D S, WANG Y, WANG D. Complex ratio masking for monaural speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(3): 483-492. 10.1109/taslp.2015.2512042 |
| 13 | XU Y, DU J, DAI L-R, et al. An experimental study on speech enhancement based on deep neural networks[J]. IEEE Signal Processing Letters, 2014, 21(1): 65-68. 10.1109/lsp.2013.2291240 |
| 14 | LU X, TSAO Y, MATSUDA S, et al. Speech enhancement based on deep denoising autoencoder[C]// Proceedings of the Interspeech 2013. Grenoble, France: International Speech Communication Association, 2013: 436-440. 10.21437/interspeech.2013-130 |
| 15 | ZHOU L, GAO Y, WANG Z, et al. Complex spectral mapping with attention based convolution recurrent neural network for speech enhancement[EB/OL].[2023-04-01]. . |
| 16 | XU Y, DU J, DAI L-R, et al. A regression approach to speech enhancement based on deep neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1): 7-19. 10.1109/taslp.2014.2364452 |
| 17 | PARK S R, LEE J. A fully convolutional neural network for speech enhancement[EB/OL]. (2016-09-22) [2023-04-01]. . 10.21437/interspeech.2017-1465 |
| 18 | GERS F A, SCHMIDHUBER J, CUMMINS F. Learning to forget: continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451-2471. 10.1162/089976600300015015 |
| 19 | SALEEM N, KHATTAK M I, AL-HASAN M, et al. On learning spectral masking for single channel speech enhancement using feedforward and recurrent neural networks[J]. IEEE Access, 2020, 8: 160581-160595. 10.1109/access.2020.3021061 |
| 20 | CHEN J, WANG D L. Long short-term memory for speaker generalization in supervised speech separation[J]. The Journal of the Acoustical Society of America, 2017, 141(6): 4705-4714. 10.1121/1.4986931 |
| 21 | LI X, LI Y, DONG Y, et al. Bidirectional LSTM network with ordered neurons for speech enhancement[C]// Proceedings of the Interspeech 2020. Grenoble, France: International Speech Communication Association, 2020: 2702-2706. 10.21437/interspeech.2020-2245 |
| 22 | TAN K, WANG D L. A convolutional recurrent neural network for real-time speech enhancement[C]// Proceedings of the Interspeech 2018. Grenoble, France: International Speech Communication Association, 2018: 3229-3233. 10.21437/interspeech.2018-1405 |
| 23 | TAAL C H, HENDRIKS R C, HEUSDENS R, et al. A short-time objective intelligibility measure for time-frequency weighted noisy speech[C]// Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2010: 4214-4217. 10.1109/icassp.2010.5495701 |
| 24 | RIX A W, BEERENDS J G, HOLLIER M P, et al. Perceptual Evaluation of Speech Quality (PESQ) — a new method for speech quality assessment of telephone networks and codecs[C]// Proceedings of the 2001 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2001: 749-752. |
| 25 | HU Y, LIU Y, LV S, et al. DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement[EB/OL]. (2020-08-01) [2023-04-01]. . 10.21437/interspeech.2020-2537 |
| 26 | KRAWCZYK M, GERKMANN T. STFT phase reconstruction in voiced speech for an improved single-channel speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(12): 1931-1940. 10.1109/taslp.2014.2354236 |
| 27 | TAN K, WANG D L. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 28: 380-390. 10.1109/taslp.2019.2955276 |
| 28 | DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 933-941. |
| 29 | WANG P, CHEN P, YUAN Y, et al. Understanding convolution for semantic segmentation[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 1451-1460. 10.1109/wacv.2018.00163 |
| 30 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 31 | WOO S, PARK J, LEE J-Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 3-19. 10.1007/978-3-030-01234-2_1 |
| 32 | BAI S, KOLTER J Z, KOLTUN V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[EB/OL]. (2018-03-04) [2023-04-01]. . |
| 33 | 武汉轻工大学.基于注意力的复数卷积神经网络语音增强方法及系统: 202211448140.6[P]. 2022-11-18. |
| Wuhan Polytechnic University. Attention-based speech enhancement method and system for complex convolutional neural networks: 202211448140.6 [P]. 2022-11-18. | |
| 34 | GAROFOLO J, GRAFF D, PAUL D, et al. CSR-I (WSJ0) Complete LDC93S6A[R]. Philadelphia: Linguistic Data Consortium, 1993. |
| 35 | VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: Ⅱ. NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993, 12(3): 247-251. 10.1016/0167-6393(93)90095-3 |
| 36 | PANDEY A, WANG D L. TCNN: temporal convolutional neural network for real-time speech enhancement in the time domain[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2019: 6875-6879. 10.1109/icassp.2019.8683634 |
| 37 | LI A, ZHENG C, FAN C, et al. A recursive network with dynamic attention for monaural speech enhancement[EB/OL]. [2023-04-01]. . 10.21437/interspeech.2020-1513 |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [3] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [4] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [5] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [6] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [7] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [8] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [9] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| [10] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [11] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| [12] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [13] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [14] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [15] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||