


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (5): 1570-1578.DOI: 10.11772/j.issn.1001-9081.2023050651
所属专题: 多媒体计算与计算机仿真
盖彦辛1,2, 闫涛1,2,3,4( ), 张江峰1,2, 郭小英3, 陈斌4,5
), 张江峰1,2, 郭小英3, 陈斌4,5
收稿日期:2023-05-24
修回日期:2023-07-20
接受日期:2023-07-27
发布日期:2023-08-03
出版日期:2024-05-10
通讯作者:
闫涛
作者简介:盖彦辛(1997—),女,山西临汾人,硕士研究生,主要研究方向:深度学习、三维形貌重建基金资助:
Yanxin GE1,2, Tao YAN1,2,3,4(), Jiangfeng ZHANG1,2, Xiaoying GUO3, Bin CHEN4,5
Received:2023-05-24
Revised:2023-07-20
Accepted:2023-07-27
Online:2023-08-03
Published:2024-05-10
Contact:
Tao YAN
About author:GE Yanxin, born in 1997, M. S. candidate. Her research interests include deep learning, 3D shape reconstruction.Supported by:摘要:
聚焦形貌恢复通过对场景深度和散焦模糊之间的潜在关系进行建模实现三维形貌重建。但现有的三维形貌重建网络无法有效利用图像序列的时序关联进行表征学习,因此,提出一种基于多景深图像序列空间关联特征的深度网络框架——三维空间相关水平分析模型(3D SCHAM)进行三维形貌重建。该模型不仅可以精确捕获单帧图像中聚焦区域到离焦区域的边缘特征,而且可有效利用不同图像帧之间的空间依赖性特征。首先,通过构建深度、宽度和感受野复合扩展的网络构造三维形貌重建的时域连续模型,进而确定单点深度结果;其次,引入基于空间关联的注意力模块,充分学习帧与帧间的“邻接性”与“距离性”空间依赖关系;另外,利用残差反转瓶颈进行重采样,以保持跨尺度的语义丰富性。在DDFF 12-Scene真实场景数据集上的实验结果显示,相较于DfFintheWild模型,3D SCHAM在深度值准确度度量的3个阈值
中图分类号:
盖彦辛, 闫涛, 张江峰, 郭小英, 陈斌. 基于时空注意力的空间关联三维形貌重建[J]. 计算机应用, 2024, 44(5): 1570-1578.
Yanxin GE, Tao YAN, Jiangfeng ZHANG, Xiaoying GUO, Bin CHEN. 3D shape reconstruction with spatial correlation based on spatio-temporal attention[J]. Journal of Computer Applications, 2024, 44(5): 1570-1578.
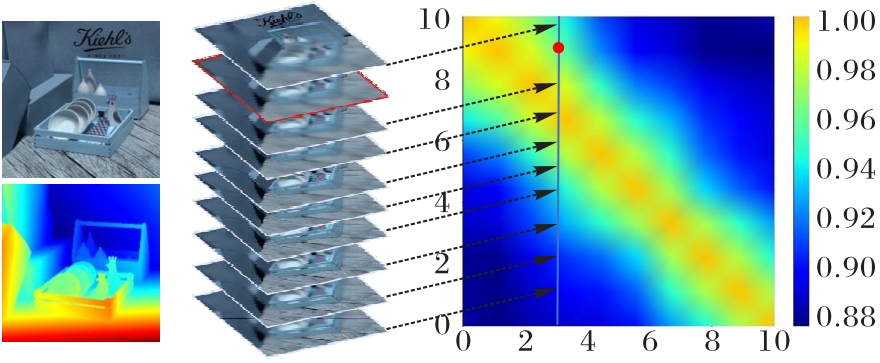
图1 Dishes样本中图像序列间相关系数热力图
Fig. 1 Correlation coefficient heat maps of Dishes sample
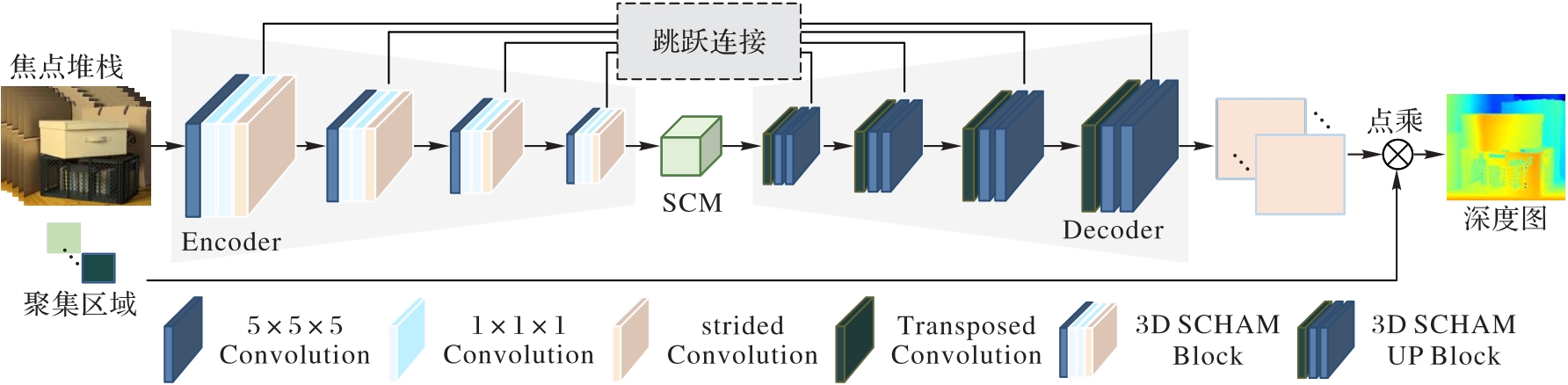
图2 3D SCHAM的整体结构
Fig. 2 Overall structure of 3D SCHAM
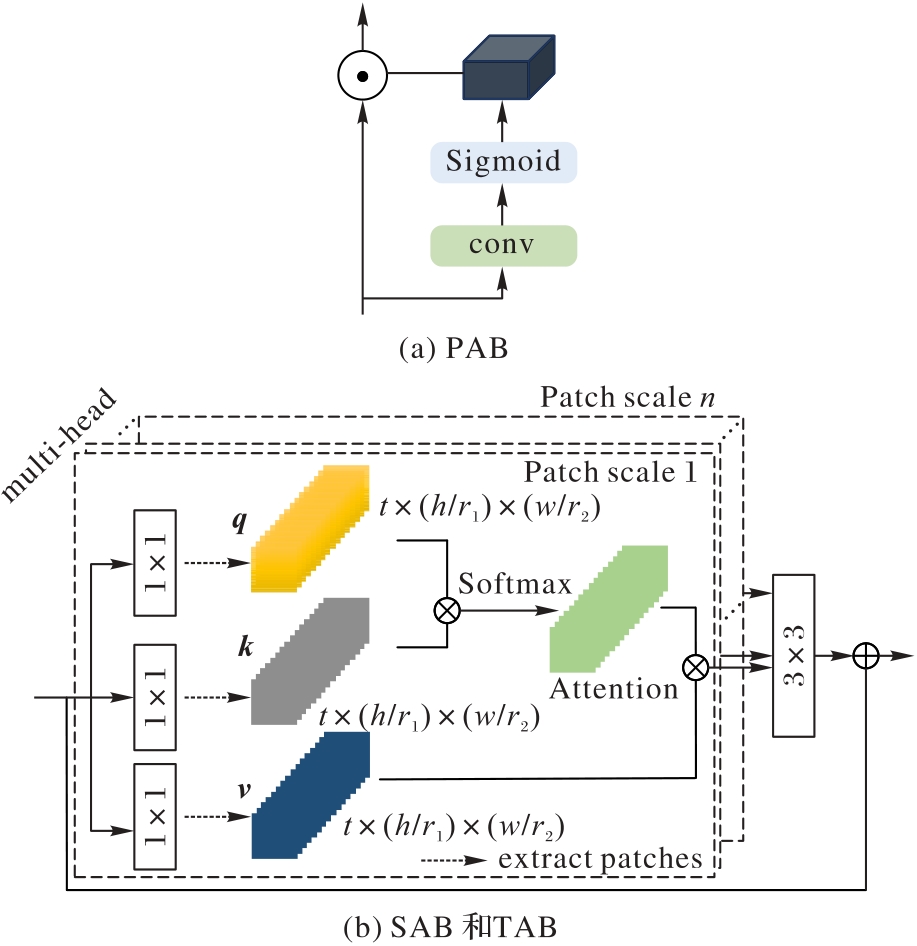
图3 SCM结构
Fig. 3 Structure of SCM
| 模型 | 网络结构 | MSE | MAE | AbsRel | |||||
|---|---|---|---|---|---|---|---|---|---|
| 卷积核大小 | B1∶B2∶B3∶B4 | R1∶R2∶R3∶R4 | |||||||
| 7×7×7 | 5×5×5 | 2∶2∶2∶2 | 2∶2∶4∶2 | 2∶2∶2∶2 | 4∶4∶4∶4 | ||||
| SCHAM-B | √ | √ | √ | 0.028 3 | 0.068 5 | 0.149 8 | |||
| SCHAM-M | √ | √ | √ | 0.025 6 | 0.062 8 | 0.149 8 | |||
| SCHAM-L | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | |||
| SCHAM | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | |||
表1 编码器中的参数配置及其消融实验结果
Tab. 1 Parameter configurations of encoder and corresponding ablation experimental results
| 模型 | 网络结构 | MSE | MAE | AbsRel | |||||
|---|---|---|---|---|---|---|---|---|---|
| 卷积核大小 | B1∶B2∶B3∶B4 | R1∶R2∶R3∶R4 | |||||||
| 7×7×7 | 5×5×5 | 2∶2∶2∶2 | 2∶2∶4∶2 | 2∶2∶2∶2 | 4∶4∶4∶4 | ||||
| SCHAM-B | √ | √ | √ | 0.028 3 | 0.068 5 | 0.149 8 | |||
| SCHAM-M | √ | √ | √ | 0.025 6 | 0.062 8 | 0.149 8 | |||
| SCHAM-L | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | |||
| SCHAM | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | |||
| 模型 | 网络结构 | MSE | MAE | AbsRel | 计算时间/s | ||||
|---|---|---|---|---|---|---|---|---|---|
| 3D U-Net | PAB | SAB | TAB | skip_res | |||||
| Base | √ | 0.031 3 | 0.068 9 | 0.180 3 | 1.448 2 | ||||
| SCHAM-P | √ | √ | 0.028 3 | 0.063 9 | 0.168 6 | 1.479 3 | |||
| SCHAM-S | √ | √ | √ | 0.027 1 | 0.063 4 | 0.144 6 | 1.503 2 | ||
| SCHAM-T | √ | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | 1.541 5 | |
| SCHAM-R | √ | √ | √ | √ | √ | 0.028 5 | 0.066 8 | 0.150 5 | 1.760 3 |
| SCHAM | √ | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | 1.541 5 | |
表2 模型架构消融实验结果
Tab. 2 Model architecture ablation experiment results
| 模型 | 网络结构 | MSE | MAE | AbsRel | 计算时间/s | ||||
|---|---|---|---|---|---|---|---|---|---|
| 3D U-Net | PAB | SAB | TAB | skip_res | |||||
| Base | √ | 0.031 3 | 0.068 9 | 0.180 3 | 1.448 2 | ||||
| SCHAM-P | √ | √ | 0.028 3 | 0.063 9 | 0.168 6 | 1.479 3 | |||
| SCHAM-S | √ | √ | √ | 0.027 1 | 0.063 4 | 0.144 6 | 1.503 2 | ||
| SCHAM-T | √ | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | 1.541 5 | |
| SCHAM-R | √ | √ | √ | √ | √ | 0.028 5 | 0.066 8 | 0.150 5 | 1.760 3 |
| SCHAM | √ | √ | √ | √ | 0.023 7 | 0.061 3 | 0.098 3 | 1.541 5 | |
| 模型 | MSE/10-4 | log-RMSE | AbsRel | δ | 模型 | MSE/10-4 | log-RMSE | AbsRel | δ | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.25 | 1.252 | 1.253 | 1.25 | 1.252 | 1.253 | ||||||||
| RDF | 91.81 | 0.91 | 1.00 | 0.156 5 | 0.330 8 | 0.474 8 | FV-Net | 6.49 | 0.23 | 0.14 | 0.719 3 | 0.928 0 | 0.978 6 |
| DDFF | 9.10 | 0.28 | 0.17 | 0.619 5 | 0.851 4 | 0.929 8 | DFV-Net | 5.70 | 0.21 | 0.13 | 0.767 4 | 0.942 3 | 0.981 4 |
| DefocusNet | 8.61 | 0.23 | 0.15 | 0.725 6 | 0.941 5 | 0.979 2 | DfFintheWild | 5.70 | 0.21 | 0.17 | 0.779 6 | 0.937 2 | 0.979 4 |
| AiFDepthNet | 8.60 | 0.29 | 0.25 | 0.683 3 | 0.874 0 | 0.939 6 | 3D SCHAM | 6.27 | 0.14 | 0.12 | 0.899 2 | 0.971 1 | 0.987 8 |
表3 不同模型在DDFF 12-Scene数据集的三维形貌重建性能对比
Tab. 3 3D shape restruction performance comparison among different models on DDFF 12-Scene dataset
| 模型 | MSE/10-4 | log-RMSE | AbsRel | δ | 模型 | MSE/10-4 | log-RMSE | AbsRel | δ | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.25 | 1.252 | 1.253 | 1.25 | 1.252 | 1.253 | ||||||||
| RDF | 91.81 | 0.91 | 1.00 | 0.156 5 | 0.330 8 | 0.474 8 | FV-Net | 6.49 | 0.23 | 0.14 | 0.719 3 | 0.928 0 | 0.978 6 |
| DDFF | 9.10 | 0.28 | 0.17 | 0.619 5 | 0.851 4 | 0.929 8 | DFV-Net | 5.70 | 0.21 | 0.13 | 0.767 4 | 0.942 3 | 0.981 4 |
| DefocusNet | 8.61 | 0.23 | 0.15 | 0.725 6 | 0.941 5 | 0.979 2 | DfFintheWild | 5.70 | 0.21 | 0.17 | 0.779 6 | 0.937 2 | 0.979 4 |
| AiFDepthNet | 8.60 | 0.29 | 0.25 | 0.683 3 | 0.874 0 | 0.939 6 | 3D SCHAM | 6.27 | 0.14 | 0.12 | 0.899 2 | 0.971 1 | 0.987 8 |
| 数据集 | 模型 | MSE/10-2 | RMSE | AbsRel | δ | ||
|---|---|---|---|---|---|---|---|
| 1.25 | 1.252 | 1.253 | |||||
| DefocusNet | DefocusNet | 1.75 | 0.134 2 | 0.150 2 | 0.811 4 | 0.933 1 | 0.966 2 |
| AiFDepthNet | 1.27 | 0.130 3 | 0.111 5 | 0.812 3 | 0.944 0 | 0.974 5 | |
| FV-Net | 1.88 | 0.125 0 | 0.141 0 | 0.811 6 | 0.949 7 | 0.980 8 | |
| DFV-Net | 2.05 | 0.129 0 | 0.130 0 | 0.819 0 | 0.946 8 | 0.980 5 | |
| GSTFC | 0.98 | 0.091 0 | — | — | — | — | |
| DfFintheWild | 0.86 | 0.085 9 | 0.080 9 | 0.913 6 | 0.976 0 | 0.989 9 | |
| 3D SCHAM | 0.96 | 0.109 4 | 0.103 9 | 0.889 2 | 0.966 4 | 0.974 2 | |
| 4D Light Field | DefocusNet | 5.93 | 0.235 5 | — | — | — | — |
| AiFDepthNet | 4.72 | 0.239 8 | 0.983 7 | 0.832 6 | 0.906 2 | 0.922 0 | |
| FV-Net | 3.01 | 0.153 7 | 0.189 9 | 0.854 9 | 0.924 1 | 0.950 3 | |
| DFV-Net | 3.17 | 0.154 9 | 0.191 5 | 0.862 3 | 0.922 5 | 0.947 6 | |
| DfFintheWild | 2.30 | 0.128 8 | 0.166 9 | 0.933 1 | 0.959 9 | 0.971 3 | |
| 3D SCHAM | 2.37 | 0.138 3 | 0.092 7 | 0.873 4 | 0.931 9 | 0.954 9 | |
表4 不同模型在DefocusNet和4D Light Field数据集上的三维形貌重建性能对比
Tab. 4 3D shape restruction performance comparison among different models on DefocusNet dataset and 4D Light Field datasets
| 数据集 | 模型 | MSE/10-2 | RMSE | AbsRel | δ | ||
|---|---|---|---|---|---|---|---|
| 1.25 | 1.252 | 1.253 | |||||
| DefocusNet | DefocusNet | 1.75 | 0.134 2 | 0.150 2 | 0.811 4 | 0.933 1 | 0.966 2 |
| AiFDepthNet | 1.27 | 0.130 3 | 0.111 5 | 0.812 3 | 0.944 0 | 0.974 5 | |
| FV-Net | 1.88 | 0.125 0 | 0.141 0 | 0.811 6 | 0.949 7 | 0.980 8 | |
| DFV-Net | 2.05 | 0.129 0 | 0.130 0 | 0.819 0 | 0.946 8 | 0.980 5 | |
| GSTFC | 0.98 | 0.091 0 | — | — | — | — | |
| DfFintheWild | 0.86 | 0.085 9 | 0.080 9 | 0.913 6 | 0.976 0 | 0.989 9 | |
| 3D SCHAM | 0.96 | 0.109 4 | 0.103 9 | 0.889 2 | 0.966 4 | 0.974 2 | |
| 4D Light Field | DefocusNet | 5.93 | 0.235 5 | — | — | — | — |
| AiFDepthNet | 4.72 | 0.239 8 | 0.983 7 | 0.832 6 | 0.906 2 | 0.922 0 | |
| FV-Net | 3.01 | 0.153 7 | 0.189 9 | 0.854 9 | 0.924 1 | 0.950 3 | |
| DFV-Net | 3.17 | 0.154 9 | 0.191 5 | 0.862 3 | 0.922 5 | 0.947 6 | |
| DfFintheWild | 2.30 | 0.128 8 | 0.166 9 | 0.933 1 | 0.959 9 | 0.971 3 | |
| 3D SCHAM | 2.37 | 0.138 3 | 0.092 7 | 0.873 4 | 0.931 9 | 0.954 9 | |
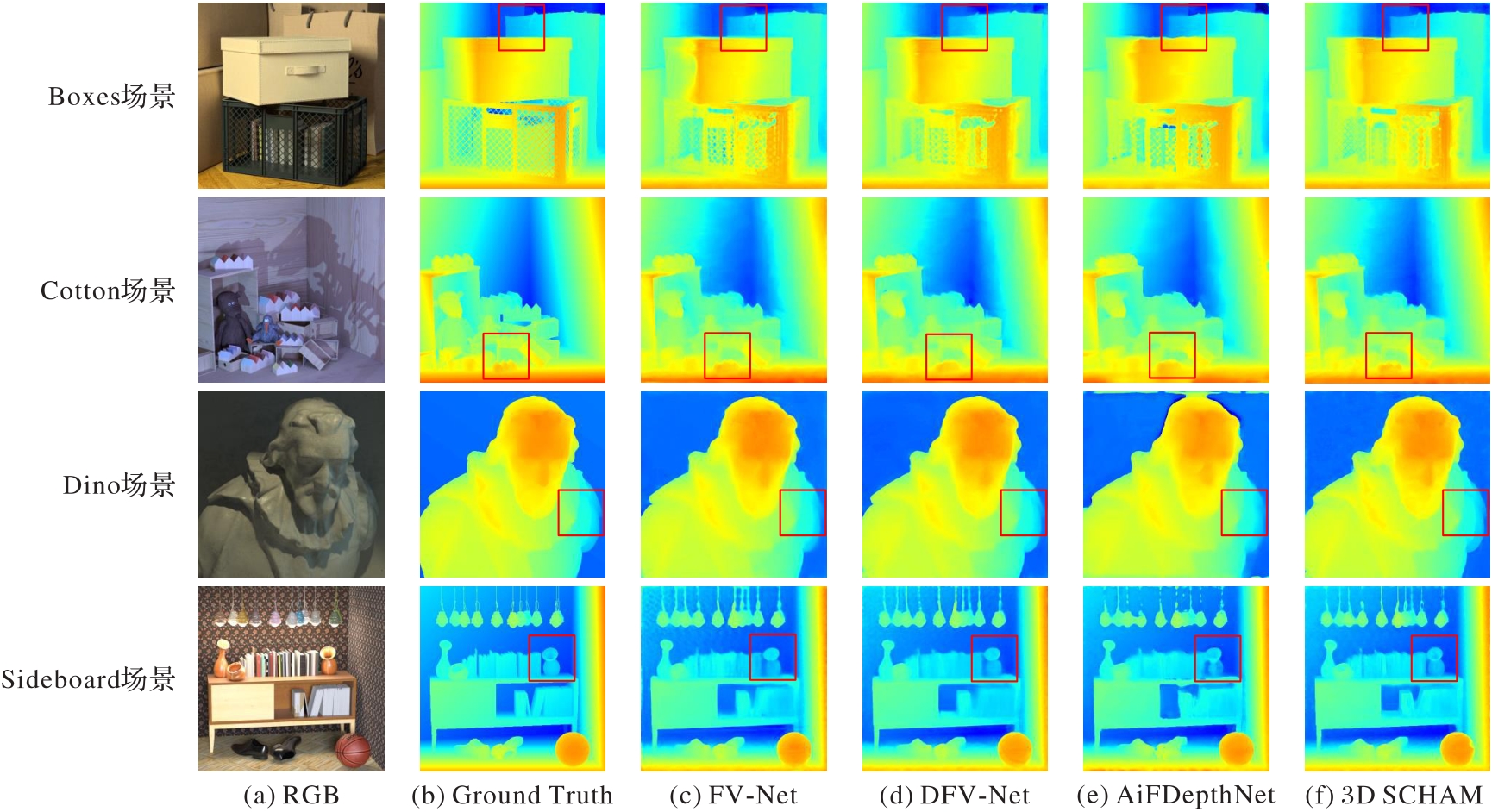
图4 不同模型在4D Light Field数据集上的深度预测结果对比
Fig. 4 Depth prediction results comparison among different models on 4D Light Field dataset

图5 AiFDepthNet和3D SCHAM在DefocusNet数据集上的深度预测结果对比
Fig. 5 Depth prediction results comparison of AiFDepthNet and 3D SCHAM on DefocusNet dataset
| 1 | NAYAR S K, NAKAGAWA Y. Shape from focus[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(8): 824-831. 10.1109/34.308479 |
| 2 | JEON H G, SURH J, IM S, et al. Ring difference filter for fast and noise robust depth from focus[J]. IEEE Transactions on Image Processing, 2020, 29: 1045-1060. 10.1109/tip.2019.2937064 |
| 3 | PERTUZ S, PUIG D, GARCÍA M Á D. Analysis of focus measure operators for shape-from-focus[J]. Pattern Recognition, 2013, 46(5): 1415-1432. 10.1016/j.patcog.2012.11.011 |
| 4 | SAKURIKAR P, NARAYANAN P J. Composite focus measure for high quality depth maps[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1623-1631. 10.1109/iccv.2017.179 |
| 5 | HONAUER K, JOHANNSEN O, KONDERMANN D, et al. A dataset and evaluation methodology for depth estimation on 4D light fields[C]// Proceedings of the 2016 Asian Conference on Computer Vision. Cham: Springer, 2017: 19-34. 10.1007/978-3-319-54187-7_2 |
| 6 | MAHMOOD M T, CHOI T S. Nonlinear approach for enhancement of image focus volume in shape from focus[J]. IEEE Transactions on Image Processing, 2012, 21(5): 2866-2873. 10.1109/tip.2012.2186144 |
| 7 | FAN T, YU H. A novel shape from focus method based on 3D steerable filters for improved performance on treating textureless region[J]. Optics Communications, 2018, 410: 254-261. 10.1016/j.optcom.2017.10.019 |
| 8 | TSENG C Y, WANG S J. Shape-from-focus depth reconstruction with a spatial consistency model[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2014, 24(12): 2063-2076. 10.1109/tcsvt.2014.2358873 |
| 9 | HAZIRBAS C, SOYER S G, STAAB M C, et al. Deep depth from focus[C]// Proceedings of the 2018 Asian Conference on Computer Vision. Cham: Springer, 2019: 525-541. 10.1007/978-3-030-20893-6_33 |
| 10 | MAXIMOV M, GALIM K, LEAL-TAIXÉ L. Focus on defocus: bridging the synthetic to real domain gap for depth estimation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1068-1077. 10.1109/cvpr42600.2020.00115 |
| 11 | WANG N H, WANG R, LIU Y L, et al. Bridging unsupervised and supervised depth from focus via all-in-focus supervision[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12621-12631. 10.1109/iccv48922.2021.01239 |
| 12 | YANG F, HUANG X, ZHOU Z. Deep depth from focus with differential focus volume[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12632-12641. 10.1109/cvpr52688.2022.01231 |
| 13 | 山西大学.一种全局时空聚焦特征耦合的多景深三维形貌重建方法:CN202211130317.8[P].2022-12-09. |
| Shanxi University. A global spatio-temporal focusing feature coupled multi-depth-of-field 3D shape reconstruction method: CN 202211130317.8[P]. 2022-12-09. | |
| 14 | 张江峰,闫涛,陈斌,等.全局时空特征耦合的多景深三维形貌重建[J].计算机应用,2023,43(3):894-902. |
| ZHANG J F, YAN T, CHEN B, et al. Multi-depth-of field 3D shape reconstruction with global spatio-temporal feature coupling[J]. Journal of Computer Applications, 2023, 43(3): 894-902. | |
| 15 | WON C, JEON H G. Learning depth from focus in the wild[C]// Proceedings of the 2022 European Conference on Computer Vision. Cham: Springer, 2022: 1-18. 10.1007/978-3-031-19769-7_1 |
| 16 | YAN T, WU P, QIAN Y, et al. Multiscale fusion and aggregation PCNN for 3D shape recovery[J]. Information Sciences, 2020, 536: 277-297. 10.1016/j.ins.2020.05.100 |
| 17 | HUANG W, JING Z. Evaluation of focus measures in multi-focus image fusion[J]. Pattern Recognition Letters, 2007, 28(4): 493-500. 10.1016/j.patrec.2006.09.005 |
| 18 | AHMAD M B, CHOI T S. Application of three dimensional shape from image focus in LCD/TFT displays manufacturing[J]. IEEE Transactions on Consumer Electronics, 2007, 53(1): 1-4. 10.1109/tce.2007.339492 |
| 19 | MALIK A S, CHOI T S. A novel algorithm for estimation of depth map using image focus for 3D shape recovery in the presence of noise[J]. Pattern Recognition, 2008, 41(7): 2200-2225. 10.1016/j.patcog.2007.12.014 |
| 20 | WEE C Y, PARAMESRAN R. Measure of image sharpness using eigenvalues[J]. Information Sciences, 2007, 177(12): 2533-2552. 10.1016/j.ins.2006.12.023 |
| 21 | YANG G, NELSON B J. Wavelet-based autofocusing and unsupervised segmentation of microscopic images[C]// Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems: Volume 3. Piscataway: IEEE, 2003: 2143-2148. 10.1109/iros.2003.1249176 |
| 22 | LEE S Y, YOO J T, KUMAR Y, et al. Reduced energy-ratio measure for robust autofocusing in digital camera[J]. IEEE Signal Processing Letters, 2009, 16(2): 133-136. 10.1109/lsp.2008.2008938 |
| 23 | MAHMOOD M T, CHOI T S. Focus measure based on the energy of high-frequency components in the S transform[J]. Optics Letters, 2010, 35(8): 1272-1274. 10.1364/ol.35.001272 |
| 24 | GAGANOV V, IGNATENKOO A. Robust shape from focus via Markov random fields[EB/OL]. [2023-01-20].. |
| 25 | MOELLER M, BENNING M, SCHÖNLIEB C B, et al. Variational depth from focus reconstruction[J]. IEEE Transactions on Image Processing, 2015, 24(12): 5369-5378. 10.1109/tip.2015.2479469 |
| 26 | BOSHTAYEVA M, HAFNER D, WEICKERT J. A focus fusion framework with anisotropic depth map smoothing[J]. Pattern Recognition, 2015, 48(11): 3310-3323. 10.1016/j.patcog.2014.10.008 |
| 27 | ALI U, PRUKS V, MAHMOOD M T. Image focus volume regularization for shape from focus through 3D weighted least squares[J]. Information Sciences, 2019, 489: 155-166. 10.1016/j.ins.2019.03.056 |
| 28 | ALI U, MAHMOOD M T. 3D shape recovery by aggregating 3D wavelet Transform-based image focus volumes through 3d weighted least squares[J]. Journal of Mathematical Imaging and Vision, 2020, 62(1): 54-72. 10.1007/s10851-019-00918-8 |
| 29 | THELEN A, FREY S, HIRSCHS, et al. Improvements in shape-from-focus for holographic reconstructions with regard to focus operators, neighborhood-size, and height value interpolation[J]. IEEE Transactions on Image Processing, 2009, 18(1): 151-157. 10.1109/tip.2008.2007049 |
| 30 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. [2023-01-20].. |
| 31 | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241. 10.1007/978-3-319-24574-4_28 |
| 32 | GUO J, HAN K, WU H, et al. CMT: convolutional neural networks meet vision Transformers[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12165-12175. 10.1109/cvpr52688.2022.01186 |
| 33 | GULATI A, QIN J, C-C CHIU, et al. Conformer: convolution-augmented Transformer for speech recognition[C/OL]// Proceedings of the INTERSPEECH 2020. [S.l.]: ISCA, 2020 [2023-02-17].. 10.21437/interspeech.2020-3015 |
| 34 | HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023. 10.1109/tpami.2019.2913372 |
| 35 | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. 10.1109/iccv48922.2021.00986 |
| 36 | SZEGEDY C, WEI L, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. 10.1109/cvpr.2015.7298594 |
| 37 | TAN M, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR, 2019: 6105-6114. |
| [1] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| [2] | 李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703. |
| [3] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [4] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [5] | 王熙源, 张战成, 徐少康, 张宝成, 罗晓清, 胡伏原. 面向手术导航3D/2D配准的无监督跨域迁移网络[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2911-2918. |
| [6] | 刘禹含, 吉根林, 张红苹. 基于骨架图与混合注意力的视频行人异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2551-2557. |
| [7] | 顾焰杰, 张英俊, 刘晓倩, 周围, 孙威. 基于时空多图融合的交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2618-2625. |
| [8] | 石乾宏, 杨燕, 江永全, 欧阳小草, 范武波, 陈强, 姜涛, 李媛. 面向空气质量预测的多粒度突变拟合网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2643-2650. |
| [9] | 赵亦群, 张志禹, 董雪. 基于密集残差物理信息神经网络的各向异性旅行时计算方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2310-2318. |
| [10] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [11] | 孙逊, 冯睿锋, 陈彦如. 基于深度与实例分割融合的单目3D目标检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2208-2215. |
| [12] | 吴筝, 程志友, 汪真天, 汪传建, 王胜, 许辉. 基于深度学习的患者麻醉复苏过程中的头部运动幅度分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2258-2263. |
| [13] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [14] | 张郅, 李欣, 叶乃夫, 胡凯茜. 基于暗知识保护的模型窃取防御技术DKP[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2080-2086. |
| [15] | 马天, 席润韬, 吕佳豪, 曾奕杰, 杨嘉怡, 张杰慧. 基于深度强化学习的移动机器人三维路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2055-2064. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||