


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (2): 528-535.DOI: 10.11772/j.issn.1001-9081.2025030311
• 多媒体计算与计算机仿真 • 上一篇
陈晓雷( ), 郑芷薇, 黄雪, 曲振彬
), 郑芷薇, 黄雪, 曲振彬
收稿日期:2025-03-25
修回日期:2025-04-25
接受日期:2025-04-27
发布日期:2025-05-07
出版日期:2026-02-10
通讯作者:
陈晓雷
作者简介:陈晓雷(1979—),男,河南灵宝人,教授,博士,CCF会员,主要研究方向:人工智能、计算机视觉 Email:chenxl703@lut.edu.cn基金资助:
Xiaolei CHEN(), Zhiwei ZHENG, Xue HUANG, Zhenbin QU
Received:2025-03-25
Revised:2025-04-25
Accepted:2025-04-27
Online:2025-05-07
Published:2026-02-10
Contact:
Xiaolei CHEN
About author:CHEN Xiaolei, born in 1979, Ph. D., professor. His research interests include artificial intelligence, computer vision. Email:chenxl703@lut.edu.cnSupported by:摘要:
现有的传统视频超分辨率(VSR)方法在处理全景视频时难以有效解决等距矩形投影带来的几何畸变问题,且在帧间对齐和特征融合方面存在不足,这些会导致重建效果不佳。为了进一步提升全景视频的超分辨率重建质量,提出一种结合球面对齐与自适应几何校正的全景视频超分辨率网络——360GeoVSR。该网络通过球面对齐模块(SAM)和几何融合块(GFB)实现帧间特征的精确对齐与高效融合。SAM结合空间变换和可变形卷积处理全局与局部几何畸变;GFB通过嵌入的自适应几何校正(AGC)子模块动态校正特征对齐,并融合多帧信息以捕捉复杂的帧间关系。在扩展的ODV360Extended全景视频数据集上的主客观对比实验结果表明,360GeoVSR在客观指标和主观视觉效果上均优于BasicVSR++和VRT(Video Restoration Transformer)等5种代表性超分辨率方法,验证了它的有效性。
中图分类号:
陈晓雷, 郑芷薇, 黄雪, 曲振彬. 结合球面对齐与自适应几何校正的全景视频超分辨率网络[J]. 计算机应用, 2026, 46(2): 528-535.
Xiaolei CHEN, Zhiwei ZHENG, Xue HUANG, Zhenbin QU. Panoramic video super-resolution network combining spherical alignment and adaptive geometric correction[J]. Journal of Computer Applications, 2026, 46(2): 528-535.
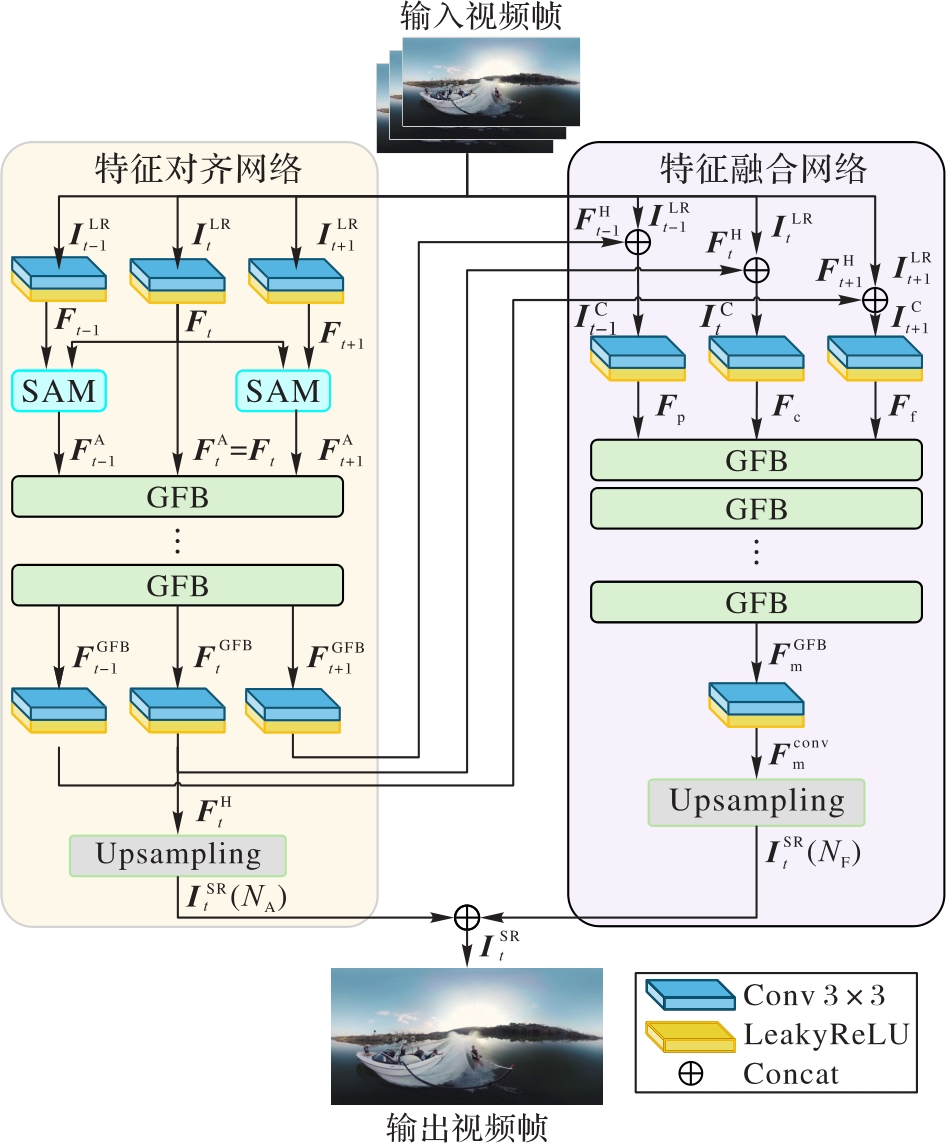
图1 360GeoVSR网络的架构
Fig. 1 Architecture of 360GeoVSR network
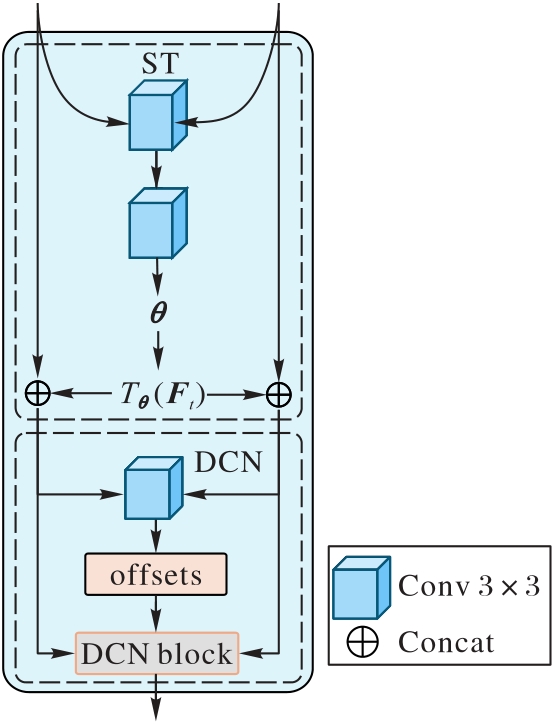
图2 SAM的结构
Fig. 2 Structure of SAM
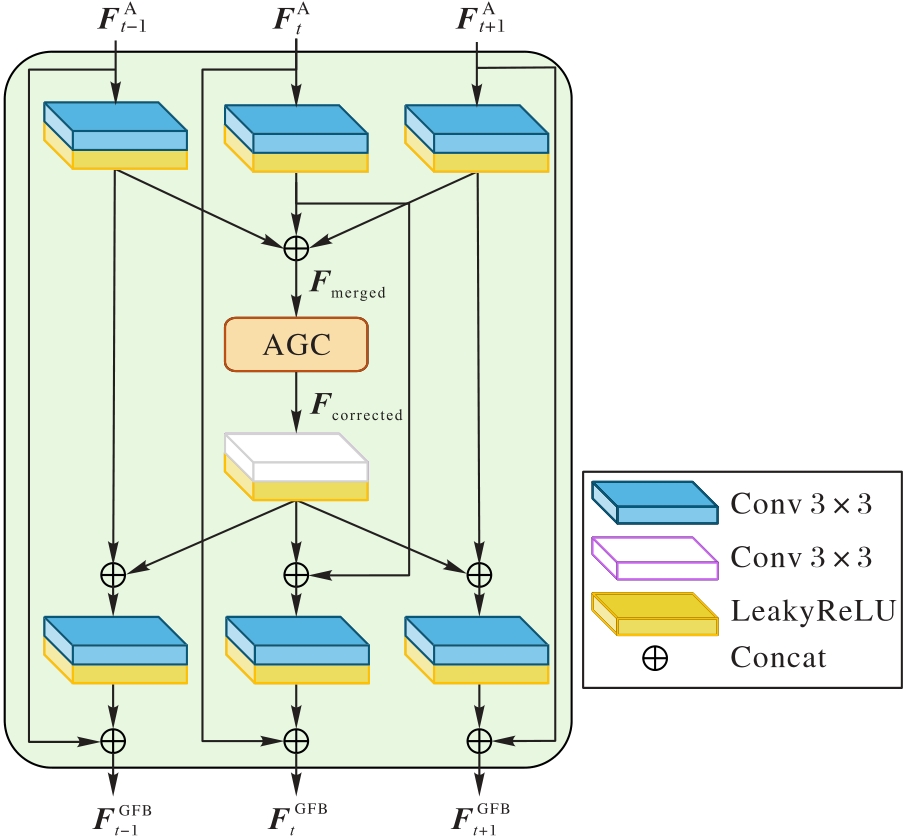
图3 GFB的结构
Fig. 3 Structure of GFB
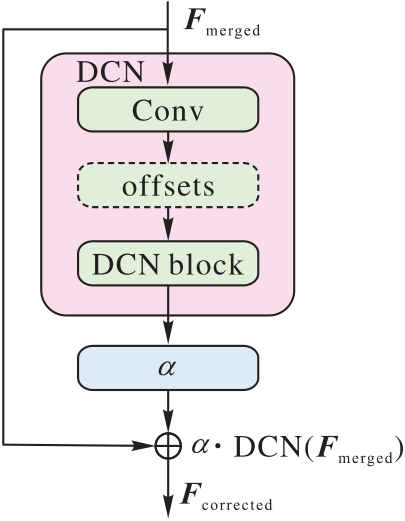
图4 AGC的结构
Fig. 4 Structure of AGC
| SAM | GFB | AGC | PSNR/dB | SSIM | WS-PSNR/dB | WS-SSIM |
|---|---|---|---|---|---|---|
| × | × | × | 34.45 | 0.935 9 | 33.44 | 0.932 0 |
| × | √ | × | 36.06 | 0.948 4 | 35.05 | 0.945 4 |
| √ | √ | × | 36.14 | 0.948 6 | 35.10 | 0.945 5 |
| × | √ | √ | 36.27 | 0.949 7 | 35.25 | 0.946 8 |
| √ | √ | √ | 36.42 | 0.950 6 | 35.37 | 0.947 5 |
表1 360GeoVSR的消融实验结果
Tab. 1 Ablation experimental results of 360GeoVSR
| SAM | GFB | AGC | PSNR/dB | SSIM | WS-PSNR/dB | WS-SSIM |
|---|---|---|---|---|---|---|
| × | × | × | 34.45 | 0.935 9 | 33.44 | 0.932 0 |
| × | √ | × | 36.06 | 0.948 4 | 35.05 | 0.945 4 |
| √ | √ | × | 36.14 | 0.948 6 | 35.10 | 0.945 5 |
| × | √ | √ | 36.27 | 0.949 7 | 35.25 | 0.946 8 |
| √ | √ | √ | 36.42 | 0.950 6 | 35.37 | 0.947 5 |
| GFB数(NA) | GFB数(NF) | PSNR/dB | SSIM | WS-PSNR/dB | WS-SSIM |
|---|---|---|---|---|---|
| 4 | 4 | 37.05 | 0.956 0 | 36.10 | 0.953 0 |
| 4 | 6 | 37.10 | 0.956 5 | 36.15 | 0.953 5 |
| 4 | 8 | 37.12 | 0.956 8 | 36.18 | 0.953 8 |
| 6 | 4 | 37.15 | 0.957 0 | 36.20 | 0.954 3 |
| 6 | 6 | 37.20 | 0.957 5 | 36.25 | 0.955 0 |
| 6 | 8 | 37.22 | 0.957 8 | 36.27 | 0.955 2 |
| 8 | 4 | 37.25 | 0.958 0 | 36.28 | 0.955 5 |
| 8 | 6 | 37.30 | 0.958 5 | 36.29 | 0.956 1 |
| 8 | 8 | 37.28 | 0.958 3 | 36.28 | 0.955 8 |
表2 NA和NF中的GFB 数量实验
Tab. 2 Experimental results of GFB quantities in NA and NF
| GFB数(NA) | GFB数(NF) | PSNR/dB | SSIM | WS-PSNR/dB | WS-SSIM |
|---|---|---|---|---|---|
| 4 | 4 | 37.05 | 0.956 0 | 36.10 | 0.953 0 |
| 4 | 6 | 37.10 | 0.956 5 | 36.15 | 0.953 5 |
| 4 | 8 | 37.12 | 0.956 8 | 36.18 | 0.953 8 |
| 6 | 4 | 37.15 | 0.957 0 | 36.20 | 0.954 3 |
| 6 | 6 | 37.20 | 0.957 5 | 36.25 | 0.955 0 |
| 6 | 8 | 37.22 | 0.957 8 | 36.27 | 0.955 2 |
| 8 | 4 | 37.25 | 0.958 0 | 36.28 | 0.955 5 |
| 8 | 6 | 37.30 | 0.958 5 | 36.29 | 0.956 1 |
| 8 | 8 | 37.28 | 0.958 3 | 36.28 | 0.955 8 |
| 方法 | 处理帧数 | 参数量/106 | PSNR/dB | SSIM | WS-PSNR/dB | WS-SSIM |
|---|---|---|---|---|---|---|
| Bicubic | — | — | 32.64 | 0.921 1 | 31.79 | 0.914 2 |
| EDVR[ | 5 | 20.6 | 33.60 | 0.949 6 | 32.69 | 0.939 7 |
| BasicVSR[ | 30 | 6.3 | 35.73 | 0.946 3 | 34.61 | 0.942 3 |
| GOVSR[ | 30 | 7.0 | 35.78 | 0.946 9 | 34.61 | 0.943 1 |
| BasicVSR++[ | 30 | 7.3 | ||||
| VRT[ | 6 | 35.6 | 37.10 | 0.957 6 | 36.10 | 0.954 1 |
| 360GeoVSR | 30 | 19.9 | 37.30 | 0.958 5 | 36.29 | 0.956 1 |
表3 360GeoVSR与不同超分辨率重建方法的客观评价指标对比
Tab. 3 Comparison of objective evaluation metrics of 360GeoVSR and different super-resolution reconstruction methods
| 方法 | 处理帧数 | 参数量/106 | PSNR/dB | SSIM | WS-PSNR/dB | WS-SSIM |
|---|---|---|---|---|---|---|
| Bicubic | — | — | 32.64 | 0.921 1 | 31.79 | 0.914 2 |
| EDVR[ | 5 | 20.6 | 33.60 | 0.949 6 | 32.69 | 0.939 7 |
| BasicVSR[ | 30 | 6.3 | 35.73 | 0.946 3 | 34.61 | 0.942 3 |
| GOVSR[ | 30 | 7.0 | 35.78 | 0.946 9 | 34.61 | 0.943 1 |
| BasicVSR++[ | 30 | 7.3 | ||||
| VRT[ | 6 | 35.6 | 37.10 | 0.957 6 | 36.10 | 0.954 1 |
| 360GeoVSR | 30 | 19.9 | 37.30 | 0.958 5 | 36.29 | 0.956 1 |

图5 不同方法重建质量的主观对比
Fig. 5 Subjective comparison of reconstruction qualities using different methods
| [1] | 卞鹏程,郑忠龙,李明禄,等. 基于注意力融合网络的视频超分辨率重建[J]. 计算机应用, 2021, 41(4): 1012-1019. |
| BIAN P C, ZHENG Z L, LI M L, et al. Attention fusion network based video super-resolution reconstruction[J]. Journal of Computer Applications, 2021, 41(4): 1012-1019. | |
| [2] | 刘扬,刘蓉,方可,等. 基于帧间跨越光流的视频超分辨率重建网络[J]. 计算机应用, 2024, 44(4): 1277-1284. |
| LIU Y, LIU R, FANG K, et al. Video super-resolution reconstruction network based on frame straddling optical flow[J]. Journal of Computer Applications, 2024, 44(4): 1277-1284. | |
| [3] | PI H, TIAN S, LU M, et al. A comprehensive comparison of projections in omnidirectional super-resolution[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [4] | DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2758-2766. |
| [5] | DAI J, QI H, XIONG Y, et al. Deformable convolutional networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 764-773. |
| [6] | CHAN K C K, WANG X, YU K, et al. Understanding deformable alignment in video super-resolution[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 973-981. |
| [7] | LUCAS B D, KANADE T. An iterative image registration technique with an application to stereo vision[C]// Proceedings of the 7th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 1981: 674-679. |
| [8] | CHAN K C K, WANG X, YU K, et al. BasicVSR: the search for essential components in video super-resolution and beyond[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 4945-4954. |
| [9] | LIU C, YANG H, FU J, et al. Learning trajectory-aware transformer for video super-resolution[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5677-5686. |
| [10] | CHEN Y H, CHEN S C, CHEN Y H, et al. MoTIF: learning motion trajectories with local implicit neural functions for continuous space-time video super-resolution[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 23074-23084. |
| [11] | SHI S, GU J, XIE L, et al. Rethinking alignment in video super-resolution Transformers[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 36081-36093. |
| [12] | WANG X, CHAN K C K, YU K, et al. EDVR: video restoration with enhanced deformable convolutional networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2019: 1954-1963. |
| [13] | CHAN K C K, ZHOU S, XU X, et al. BasicVSR++: improving video super-resolution with enhanced propagation and alignment[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5962-5971. |
| [14] | JO Y, OH S W, KANG J, et al. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3224-3232. |
| [15] | YI P, WANG Z, JIANG K, et al. Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3106-3115. |
| [16] | LI W, TAO X, GUO T, et al. MuCAN: multi-correspondence aggregation network for video super-resolution[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12355. Cham: Springer, 2020: 335-351. |
| [17] | ISOBE T, JIA X, TAO X, et al. Look back and forth: video super-resolution with explicit temporal difference modeling[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17390-17399. |
| [18] | LI F, ZHANG L, LIU Z, et al. Multi-frequency representation enhancement with privilege information for video super-resolution[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 12768-12779. |
| [19] | GENG Z, LIANG L, DING T, et al. RSTT: real-time spatial temporal transformer for space-time video super-resolution[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17420-17430. |
| [20] | ZHOU X, ZHANG L, ZHAO X, et al. Video super-resolution Transformer with masked inter&intra-frame attention[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 25399-25408. |
| [21] | YI P, WANG Z, JIANG K, et al. Omniscient video super-resolution[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 4409-4418. |
| [22] | LIANG J, CAO J, FAN Y, et al. VRT: a video restoration Transformer[J]. IEEE Transactions on Image Processing, 2024, 33: 2171-2182. |
| [23] | LIU H, MA W, RUAN Z, et al. A single frame and multi-frame joint network for 360-degree panorama video super-resolution[J]. Engineering Applications of Artificial Intelligence, 2024, 134: No.108601. |
| [24] | LI N, LIU Y. Applying VertexShuffle toward 360-degree video super-resolution[C]// Proceedings of the 32nd Workshop on Network and Operating Systems Support for Digital Audio and Video. New York: ACM, 2022: 71-77. |
| [25] | LI N, LIU Y. Vertexshuffle-based spherical super-resolution for 360-degree videos[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2024, 20(9): No.266. |
| [26] | AGRAHARI BANIYA A, LEE T K, EKLUND P W, et al. Omnidirectional video super-resolution using deep learning[J]. IEEE Transactions on Multimedia, 2024, 26: 540-554. |
| [27] | SHANG F, LIU H, MA W, et al. Lightweight super-resolution with self-calibrated convolution for panoramic videos[J]. Sensors, 2023, 23(1): No.392. |
| [28] | LUO Z, CHAI B, WANG Z, et al. Masked360: enabling robust 360-degree video streaming with ultra low bandwidth consumption[J]. IEEE Transactions on Visualization and Computer Graphics, 2023, 29(5): 2690-2699. |
| [29] | 陈晓雷,曹宝宁,卢禹冰,等. 联合视口预测和超分辨率重建的实时VR全景视频流式传输方法[J]. 计算机辅助设计与图形学学报, 2024, 36(9): 1394-1406. |
| CHEN X L, CAO B N, LU Y B, et al. Live VR panoramic video streaming method combining viewport prediction and super-resolution[J]. Journal of Computer-Aided Design and Computer Graphics, 2024, 36(9): 1394-1406. | |
| [30] | CAO M, MOU C, YU F, et al. NTIRE 2023 challenge on 360° omnidirectional image and video super-resolution: datasets, methods and results[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2023: 1731-1745. |
| [31] | SUN Y, LU A, YU L. Weighted-to-spherically-uniform quality evaluation for omnidirectional video[J]. IEEE Signal Processing Letters, 2017, 24(9): 1408-1412. |
| [32] | ZHOU Y, YU M, MA H, et al. Weighted-to-spherically-uniform SSIM objective quality evaluation for panoramic video[C]// Proceedings of the 14th IEEE International Conference on Signal Processing. Piscataway: IEEE, 2018: 54-57. |
| [33] | BARRON J T. A general and adaptive robust loss function[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4326-4334. |
| [34] | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2025-03-03].. |
| [1] | 林金娇, 张灿舜, 陈淑娅, 王天鑫, 连剑, 徐庸辉. 基于改进图注意力网络的车险欺诈检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 437-444. |
| [2] | 姜皓骞, 张东, 李冠宇, 陈恒. 基于结构增强的层次化任务导向提示策略的对话推荐系统SetaCRS[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 368-377. |
| [3] | 李名, 王孟齐, 张爱丽, 任花, 窦育强. 基于条件生成对抗网络和混合注意力机制的图像隐写方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 475-484. |
| [4] | 郭泽一, 李凤莲, 徐利春. 基于双重决策机制的深度符号回归算法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 406-415. |
| [5] | 边小勇, 袁培洋, 胡其仁. 双编码空频混合的红外小目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 252-259. |
| [6] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [7] | 张宏俊, 潘高军, 叶昊, 陆玉彬, 缪宜恒. 结合深度学习和张量分解的多源异构数据分析方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2838-2847. |
| [8] | 李进, 刘立群. 基于残差Swin Transformer的SAR与可见光图像融合[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2949-2956. |
| [9] | 殷兵, 凌震华, 林垠, 奚昌凤, 刘颖. 兼容缺失模态推理的情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2764-2772. |
| [10] | 景攀峰, 梁宇栋, 李超伟, 郭俊茹, 郭晋育. 基于师生学习的半监督图像去雾算法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2975-2983. |
| [11] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [12] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [13] | 彭鹏, 蔡子婷, 刘雯玲, 陈才华, 曾维, 黄宝来. 基于CNN和双向GRU混合孪生网络的语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2515-2521. |
| [14] | 张硕, 孙国凯, 庄园, 冯小雨, 王敬之. 面向区块链节点分析的eclipse攻击动态检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2428-2436. |
| [15] | 葛丽娜, 王明禹, 田蕾. 联邦学习的高效性研究综述[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2387-2398. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||