


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (2): 555-563.DOI: 10.11772/j.issn.1001-9081.2025020158
• 多媒体计算与计算机仿真 • 上一篇
张四中, 刘建阳( ), 李林峰
), 李林峰
收稿日期:2025-02-21
修回日期:2025-04-15
接受日期:2025-04-17
发布日期:2025-04-24
出版日期:2026-02-10
通讯作者:
刘建阳
作者简介:张四中(2000—),男,河南周口人,硕士研究生,CCF会员,主要研究方向:基于计算机视觉的动作质量评估
Sizhong ZHANG, Jianyang LIU(), Linfeng LI
Received:2025-02-21
Revised:2025-04-15
Accepted:2025-04-17
Online:2025-04-24
Published:2026-02-10
Contact:
Jianyang LIU
About author:ZHANG Sizhong, born in 2000, M. S. candidate. His research interests include computer vision based action quality assessment.Supported by:摘要:
动作质量评估(AQA)作为一项极具挑战性的视觉任务吸引了众多研究者的目光。当前研究方法主要集中于提升骨干网络的特征提取能力,忽略了运动轨迹的影响。然而,在现实中,动作的连贯性也是评价动作执行情况的重要因素。首先,通过引入轨迹信息,设计一种轨迹引导感知学习的AQA模型,以利用轨迹描述符引导模型感知学习动作连贯性信息,从而实现不同信息之间的交互学习;其次,针对当前数据集缺乏轨迹标签的问题,设计一种基于Farneback光流法的无监督光流轨迹提取方法获取运动轨迹信息,并将获取的光流轨迹特征作为引导词来引导模型感知学习视频特征;最后,利用KAN(Kolmogorov-Arnold Network)的可学习样条曲线拟合混合特征的数据分布,从而建立更精确的映射关系。所提模型在MTL-AQA、AQA-7、FineDiving和JIGSAWS数据集上进行实验,以斯皮尔曼秩相关系数(Sp.Corr)作为评价指标。结果表明,所提模型分别取得了0.910 1、0.912 0、0.882 0和0.990 0的Sp.Corr,与USDL(Uncertainty-aware Score Distribution Learning)模型相比分别提升了0.4%、12.6%、6.2%和57.1%。
中图分类号:
张四中, 刘建阳, 李林峰. 基于X3D的轨迹引导感知学习的动作质量评估模型[J]. 计算机应用, 2026, 46(2): 555-563.
Sizhong ZHANG, Jianyang LIU, Linfeng LI. Action quality assessment model based on trajectory-guided perceptual learning with X3D[J]. Journal of Computer Applications, 2026, 46(2): 555-563.
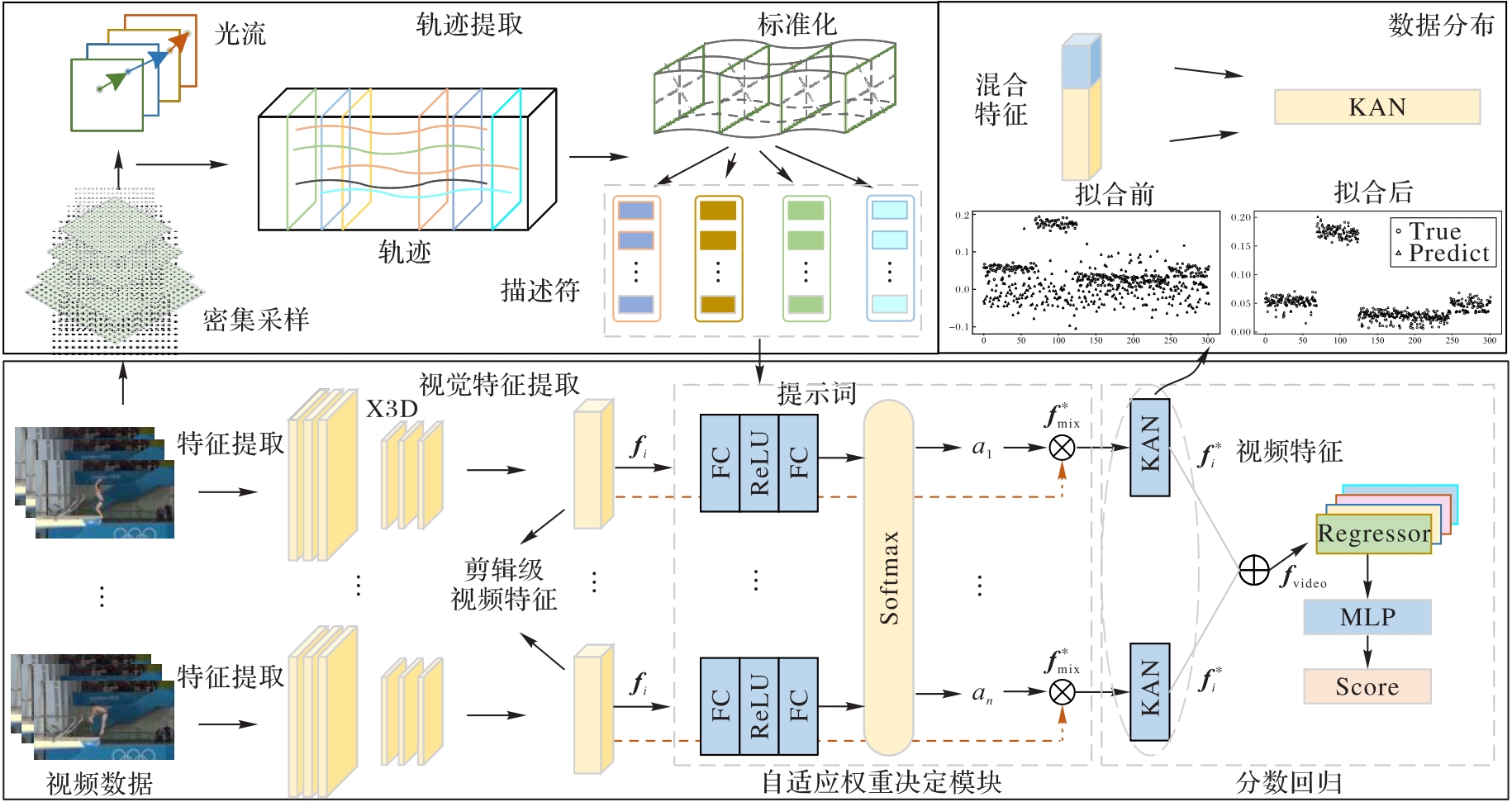
图1 本文模型框架
Fig. 1 Framework of proposed model

图2 相邻帧之间运动员的动作变化
Fig. 2 Changes in athlete’s movement between adjacent frames
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| ResNet50-3D-WD[ | 0.893 5 | USDL[ | 0.906 6 |
| C3D-AVG-STL[ | 0.896 0 | 本文模型 | 0.9101 |
表1 各个模型在MTL-AQA数据集上的对比实验结果
Tab. 1 Comparison experimental results of different models on MTL-AQA dataset
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| ResNet50-3D-WD[ | 0.893 5 | USDL[ | 0.906 6 |
| C3D-AVG-STL[ | 0.896 0 | 本文模型 | 0.9101 |
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| USDL[ | 0.810 2 | TSA-Net[ | 0.847 6 |
| NL-Net[ | 0.841 8 | 本文模型 | 0.9120 |
表2 各个模型在AQA-7数据集上的对比实验结果
Tab. 2 Comparison experimental results of different models on AQA-7 dataset
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| USDL[ | 0.810 2 | TSA-Net[ | 0.847 6 |
| NL-Net[ | 0.841 8 | 本文模型 | 0.9120 |
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| USDL[ | 0.830 2 | CoRe[ | 0.863 1 |
| MUSDL[ | 0.842 7 | 本文模型 | 0.8820 |
表3 各个模型在FineDiving数据集上的对比实验结果
Tab. 3 Comparison experimental results of different models on FineDiving dataset
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| USDL[ | 0.830 2 | CoRe[ | 0.863 1 |
| MUSDL[ | 0.842 7 | 本文模型 | 0.8820 |
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| USDL[ | 0.63 | 0.92 | |
| TPT[ | 0.89 | 本文模型 | 0.99 |
表4 各个模型在JIGSAWS数据集上的消融实验结果
Tab. 4 Comparison experimental results of different models on JIGSAWS dataset
| 模型 | Sp.Corr | 模型 | Sp.Corr |
|---|---|---|---|
| USDL[ | 0.63 | 0.92 | |
| TPT[ | 0.89 | 本文模型 | 0.99 |
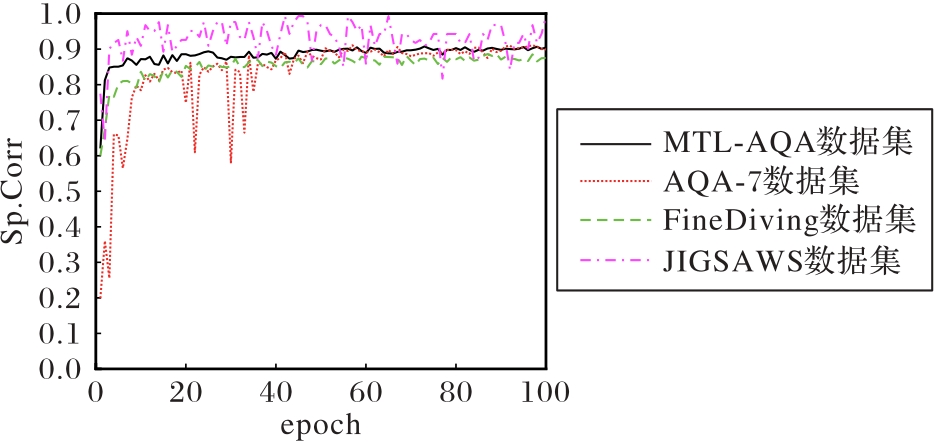
图3 本文模型在不同数据集上的训练过程
Fig. 3 Training processes of proposed model on different datasets

图4 不同数据集上的实验结果示例
Fig. 4 Presentation of experimental results on different datasets
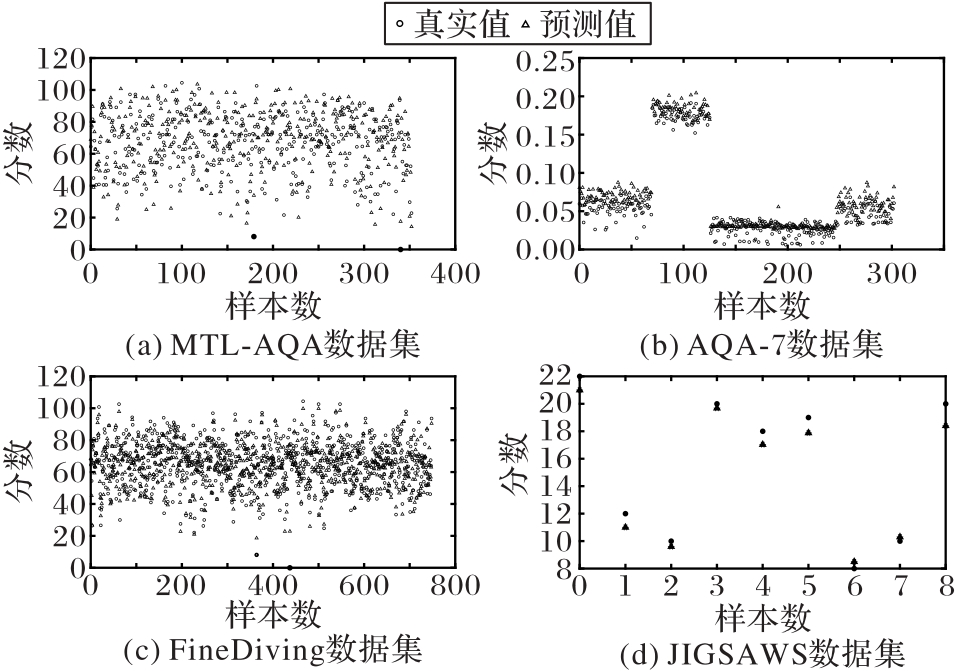
图5 各个数据集上的预测值和真实值分布
Fig. 5 Distribution of predicted and true values on different datasets
| 模型 | Sp.Corr | |
|---|---|---|
| MTL-AQA | FineDiving | |
| X3D | 0.864 0 | 0.839 0 |
| 只有轨迹 | 0.335 0 | 0.207 0 |
| X3D+注意力机制(无轨迹信息) | 0.889 0 | 0.865 0 |
| X3D+加性注意力机制+轨迹引导 | 0.898 0 | 0.875 0 |
| X3D+加性注意力机制+轨迹引导+KAN | 0.910 1 | 0.882 0 |
表5 本文模型在MTL-AQA数据集和FineDiving数据集上的消融实验结果
Tab. 5 Results of ablation experiments of proposed model on MTL-AQA dataset and FineDiving dataset
| 模型 | Sp.Corr | |
|---|---|---|
| MTL-AQA | FineDiving | |
| X3D | 0.864 0 | 0.839 0 |
| 只有轨迹 | 0.335 0 | 0.207 0 |
| X3D+注意力机制(无轨迹信息) | 0.889 0 | 0.865 0 |
| X3D+加性注意力机制+轨迹引导 | 0.898 0 | 0.875 0 |
| X3D+加性注意力机制+轨迹引导+KAN | 0.910 1 | 0.882 0 |
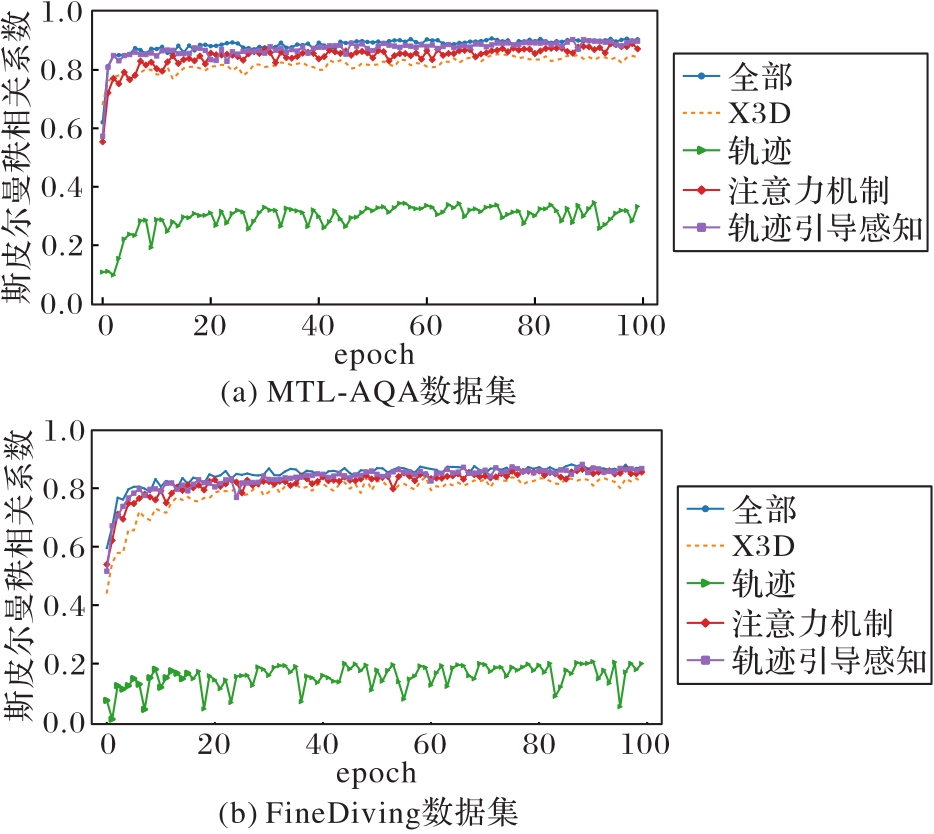
图6 消融实验结果
Fig. 6 Ablation experimental results
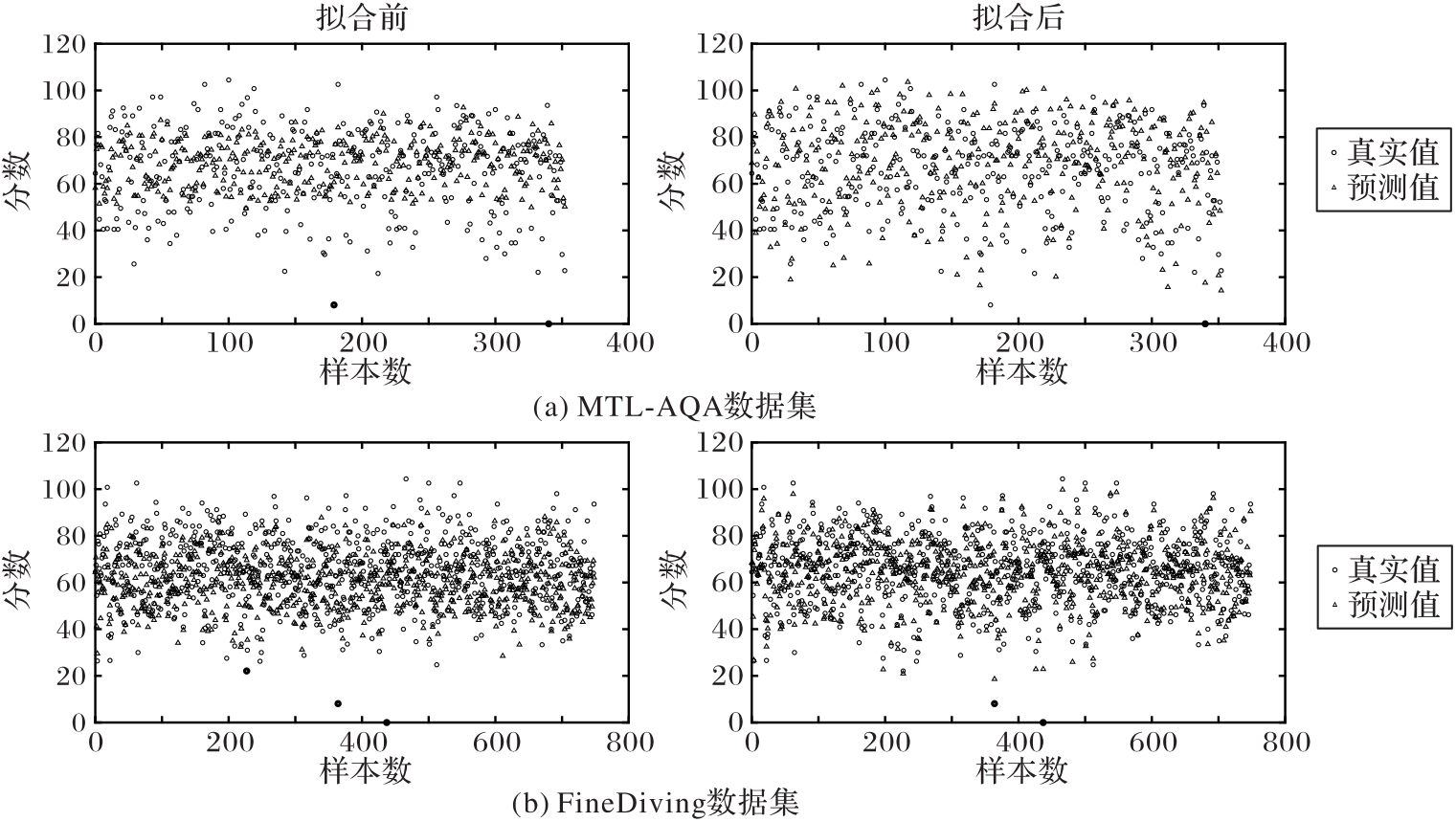
图7 在MTL-AQA和FineDiving数据集上数据拟合前后的效果对比
Fig. 7 Comparison of effects before and after data fitting on MTL-AQA and FineDiving datasets

图8 跳水轨迹分析
Fig. 8 Diving trajectory analysis
图9 各个数据样本轨迹的特征描述符
Fig. 9 Feature descriptors for individual data sample trajectories
| [1] | ZHANG S, DAI W, WANG S, et al. LOGO: a long-form video dataset for group action quality assessment[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2405-2414. |
| [2] | ZHANG B, CHEN J, XU Y, et al. Auto-encoding score distribution regression for action quality assessment[J]. Neural Computing and Applications, 2024, 36(2): 929-942. |
| [3] | 胡海晴,李建伟,薛珺,等. 基于动态视觉信息归一化的健身动作分析系统[J]. 计算机应用, 2024, 44(S1): 284-289. |
| HU H Q, LI J W, XUE J, et al. Fitness action analysis system based on dynamic visual information normalization[J]. Journal of Computer Applications, 2024, 44(S1): 284-289. | |
| [4] | 王丽芳,吴荆双,尹鹏亮,等. 基于注意力机制和能量函数的动作识别算法[J]. 计算机应用, 2025, 45(1): 234-239. |
| WANG L F, WU J S, YIN P L, et al. Action recognition algorithm based on attention mechanism and energy function[J]. Journal of Computer Applications, 2025, 45(1): 234-239. | |
| [5] | 张宇,徐天宇,米思娅. 标记分布与时空注意力感知的视频动作质量评估[J]. 中国图象图形学报, 2023, 28(12): 3810-3824. |
| ZHANG Y, XU T Y, MI S Y. Label distribution learning and spatio-temporal attentional awareness for video action quality assessment[J]. Journal of Image and Graphics, 2023, 28(12): 3810-3824. | |
| [6] | LI M Z, ZHANG H B, DONG L J, et al. Gaussian guided frame sequence encoder network for action quality assessment[J]. Complex and Intelligent Systems, 2023, 9(2): 1963-1974. |
| [7] | PARMAR P, MORRIS B. HalluciNet-ing spatiotemporal representations using a 2D-CNN[J]. Signals, 2021, 2(3): 604-618. |
| [8] | CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]// Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4724-4733. |
| [9] | XIANG X, TIAN Y, REITER A, et al. S3D: stacking segmental P3D for action quality assessment[C]// Proceedings of the 25th IEEE International Conference on Image Processing. Piscataway: IEEE, 2018: 928-932. |
| [10] | TANG Y, NI Z, ZHOU J, et al. Uncertainty-aware score distribution learning for action quality assessment[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9836-9845. |
| [11] | XU J, YIN S, ZHAO G, et al. FineParser: a fine-grained spatio-temporal action parser for human-centric action quality assessment[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 14628-14637. |
| [12] | PIRSIAVASH H, VONDRICK C, TORRALBA A. Assessing the quality of actions[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8694. Cham: Springer, 2014: 556-571. |
| [13] | WNUK K, SOATTO S. Analyzing diving: a dataset for judging action quality[C]// Proceedings of the 2010 Asian Conference on Computer Vision Workshops, LNCS 6468. Berlin: Springer, 2011: 266-276. |
| [14] | YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 7444-7452. |
| [15] | ZIA A, SHARMA Y, BETTADAPURA V, et al. Automated assessment of surgical skills using frequency analysis[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9349. Cham: Springer, 2015: 430-438. |
| [16] | PARMAR P, MORRIS B. Action quality assessment across multiple actions[C]// Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2019: 1468-1476. |
| [17] | PAN J H, GAO J, ZHENG W S. Action assessment by joint relation graphs[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6330-6339. |
| [18] | BAI Y, ZHOU D, ZHANG S, et al. Action quality assessment with temporal parsing Transformer[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13664. Cham: Springer, 2022: 422-438. |
| [19] | FARABI S, HIMEL H, GAZZALI F, et al. Improving action quality assessment using weighted aggregation[C]// Proceedings of the 2022 Iberian Conference on Pattern Recognition and Image Analysis, LNCS 13256. Cham: Springer, 2022: 576-587. |
| [20] | XU J, RAO Y, YU X, et al. FineDiving: a fine-grained dataset for procedure-aware action quality assessment[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 2939-2948. |
| [21] | SHI Z, LIANG J, LI Q, et al. Multi-modal multi-action video recognition[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13658-13667. |
| [22] | XIA Y, ZHAO Z. Cross-modal background suppression for audio-visual event localization[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19957-19966. |
| [23] | ZENG L A, ZHENG W S. Multimodal action quality assessment[J]. IEEE Transactions on Image Processing, 2024, 33: 1600-1613. |
| [24] | ZHANG S, BAI S, CHEN G, et al. Narrative action evaluation with prompt-guided multimodal interaction[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 18430-18439. |
| [25] | WANG S, YANG D, ZHAI P, et al. TSA-Net: tube self-attention network for action quality assessment[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 4902-4910. |
| [26] | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, Mass: MIT Press, 2014: 568-576. |
| [27] | FEICHTENHOFER C. X3D: expanding architectures for efficient video recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 200-210. |
| [28] | FARNEBÄCK G. Two-frame motion estimation based on polynomial expansion[C]// Proceedings of the 2003 Scandinavian Conference on Image Analysis, LNCS 2749. Berlin: Springer, 2003: 363-370. |
| [29] | WANG L, QIAO Y, TANG X. Action recognition with trajectory-pooled deep-convolutional descriptors[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4305-4314. |
| [30] | JAMALI A, ROY S K, HONG D, et al. How to learn more? exploring Kolmogorov-Arnold networks for hyperspectral image classification[J]. Remote Sensing, 2024, 16(21): No.4015. |
| [31] | PARMAR P, MORRIS B T. What and how well you performed? a multitask learning approach to action quality assessment[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 304-313. |
| [32] | GAO Y, VEDULA S S, REILEY C E, et al. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): a surgical activity dataset for human motion modeling[DS/OL]. [2024-11-13].. |
| [33] | YU X, RAO Y, ZHAO W, et al. Group-aware contrastive regression for action quality assessment[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 7899-7908. |
| [34] | MAJEEDI A, GAJJALA V R, GNVV S S S N, et al. RICA2: rubric-informed, calibrated assessment of actions[C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15121. Cham: Springer, 2025: 143-161. |
| [1] | 陈海乐, 易修文, 严山, 黎世骄, 李天瑞, 郑宇. 基于主体建模的病毒传播分析与可视化[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 497-504. |
| [2] | 李名, 王孟齐, 张爱丽, 任花, 窦育强. 基于条件生成对抗网络和混合注意力机制的图像隐写方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 475-484. |
| [3] | 张日丰, 李广明, 欧阳裕荣. 反射先验图引导的低光图像增强网络[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 546-554. |
| [4] | 徐千惠, 钮可, 朱顺哲, 石林, 李军. 增强型可逆神经网络视频隐写网络GAB3D-SEVSN[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 467-474. |
| [5] | 林金娇, 张灿舜, 陈淑娅, 王天鑫, 连剑, 徐庸辉. 基于改进图注意力网络的车险欺诈检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 437-444. |
| [6] | 罗虎, 张明书. 基于跨模态注意力机制与对比学习的谣言检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 361-367. |
| [7] | 吴俊锐, 杨江川, 喻海生, 邹赛, 汪文勇. 基于复增强注意力机制图神经网络的确定性网络性能评估方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 505-517. |
| [8] | 马英杰, 覃晶滢, 赵耿, 肖靖. 面向物联网图像的深度压缩感知网络及其混沌加密保护方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 144-151. |
| [9] | 樊娜, 罗闯, 张泽晖, 张梦瑶, 穆鼎. 基于改进生成对抗网络的车辆轨迹语义隐私保护机制[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 169-180. |
| [10] | 王丽芳, 任文婧, 郭晓东, 张荣国, 胡立华. 用于低剂量CT图像降噪的多路特征生成对抗网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 270-279. |
| [11] | 李亚男, 郭梦阳, 邓国军, 陈允峰, 任建吉, 原永亮. 基于多模态融合特征的并分支发动机寿命预测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 305-313. |
| [12] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [13] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [14] | 王翔, 陈志祥, 毛国君. 融合局部和全局相关性的多变量时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2806-2816. |
| [15] | 古松健, 吴福祥, 高向阳, 杨梦杰, 詹忆冰, 程俊. 基于几何模型预测控制的移动机器人轨迹跟踪算法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3026-3035. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||