


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1253-1263.DOI: 10.11772/j.issn.1001-9081.2025040488
• 多媒体计算与计算机仿真 • 上一篇
陈鹏1,2, 李旭1,2, 余肖生1,2( )
)
收稿日期:2025-05-02
修回日期:2025-07-25
接受日期:2025-07-28
发布日期:2025-07-30
出版日期:2026-04-10
通讯作者:
余肖生
作者简介:陈鹏(1973—),男,湖北恩施人,教授,博士,CCF会员,主要研究方向:计算机视觉、健康医疗大数据分析基金资助:
Peng CHEN1,2, Xu LI1,2, Xiaosheng YU1,2()
Received:2025-05-02
Revised:2025-07-25
Accepted:2025-07-28
Online:2025-07-30
Published:2026-04-10
Contact:
Xiaosheng YU
About author:CHEN Peng, born in 1973, Ph. D., professor. His research interests include computer vision, healthcare big data analysis.Supported by:摘要:
伪装目标因在纹理和颜色等视觉属性上与背景高度相似,导致RGB图像易受干扰,难以准确分辨目标位置,常导致分割结构不完整甚至目标缺失,从而影响检测性能。为了解决该问题,提出一种RGB-D双流镜像伪装目标检测(COD)网络——RDMNet(RGB-D Dual-stream Mirror Network)。首先,采用TransNeXt和Vision Mamba组成的混合主干提取特征,减少模型参数,并设计多模态特征融合(MFF)模块,利用RGB和深度信息融合增强深度特征。其次,设计深度定位模块(DPM)和定位引导完整性特征聚合(PGA)模块,前者用于生成完整的轮廓定位特征,后者用于快速地定位伪装目标,并高效地预测出完整的分割特征,两者交叉细化融合后,既关注伪装目标的整体结构,又不断细化分割特征和轮廓定位特征。最后,设计卷积门控通道注意力(CCA)模块,提取低层特征中的结构细节。实验结果显示:RDMNet在COD和RGB-D显著目标检测(SOD)数据集上优于当前15个代表性方法;在CAMO、COD10K和NC4K数据集上,与MVGNet(Multi-View Guided Network)相比,RDMNet在结构相似性度量(S-measure)、平均增强对齐度量(mean E-measure)、精度和召回率的加权平均值(weighted F-measure)方面分别平均提升了2.0%、1.5%和3.2%,而在平均绝对误差方面平均降低了17.2%。可见,RDMNet在COD中能够有效提高分割的完整性和准确性。
中图分类号:
陈鹏, 李旭, 余肖生. RGB-D双流镜像伪装目标检测网络[J]. 计算机应用, 2026, 46(4): 1253-1263.
Peng CHEN, Xu LI, Xiaosheng YU. RGB-D dual-stream mirror network for camouflaged object detection[J]. Journal of Computer Applications, 2026, 46(4): 1253-1263.

图1 伪装目标示例
Fig. 1 Examples of camouflaged objects
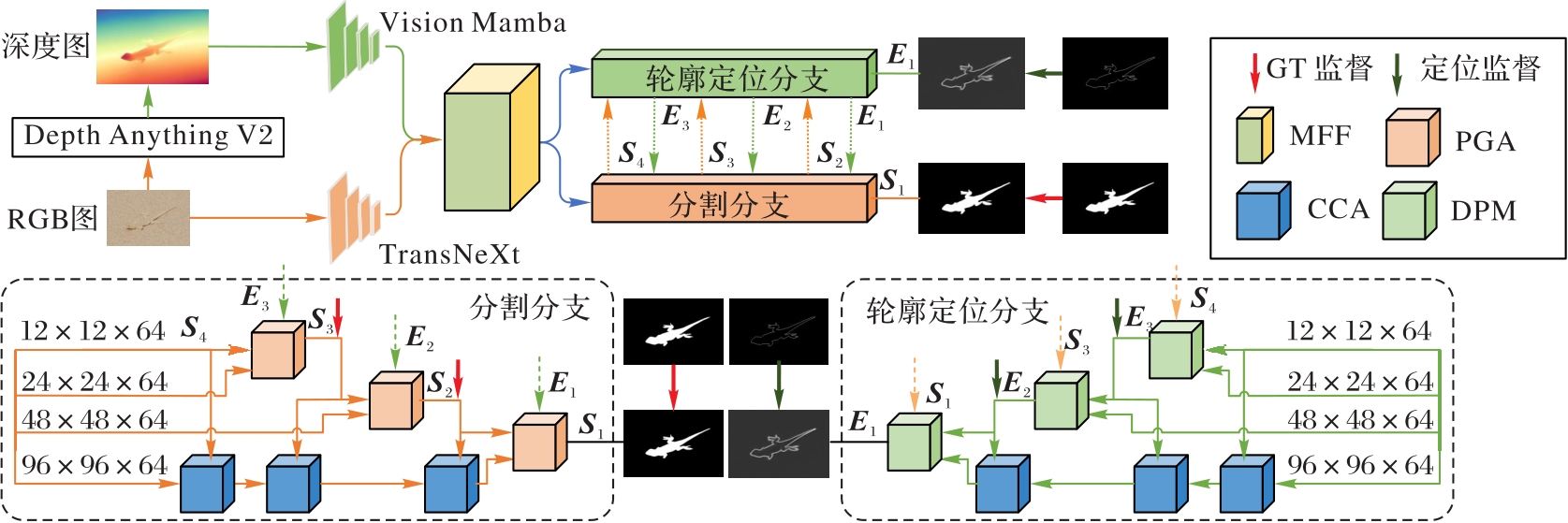
图2 RDMNet的网络结构
Fig. 2 Network structure of RDMNet
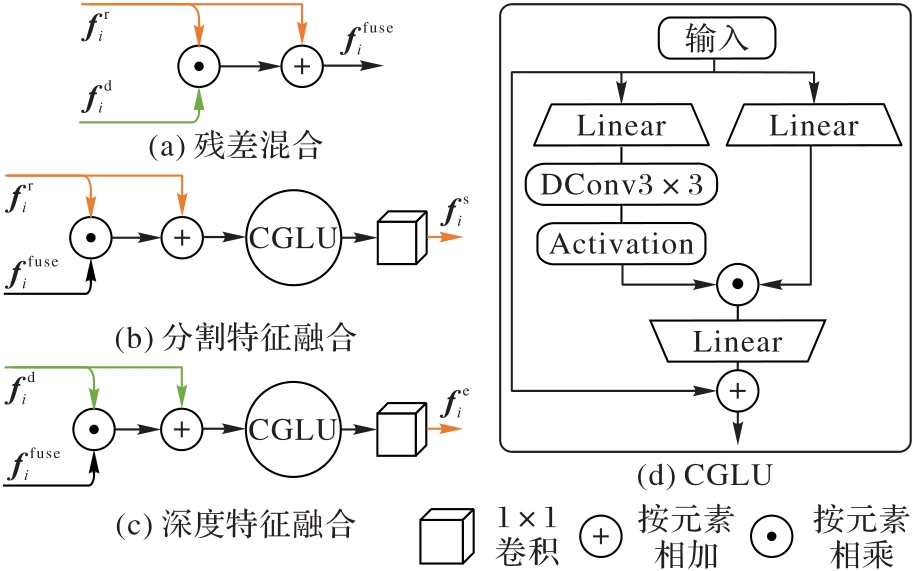
图3 多模态特征融合模块的结构
Fig. 3 Structure of multi-modal feature fusion module
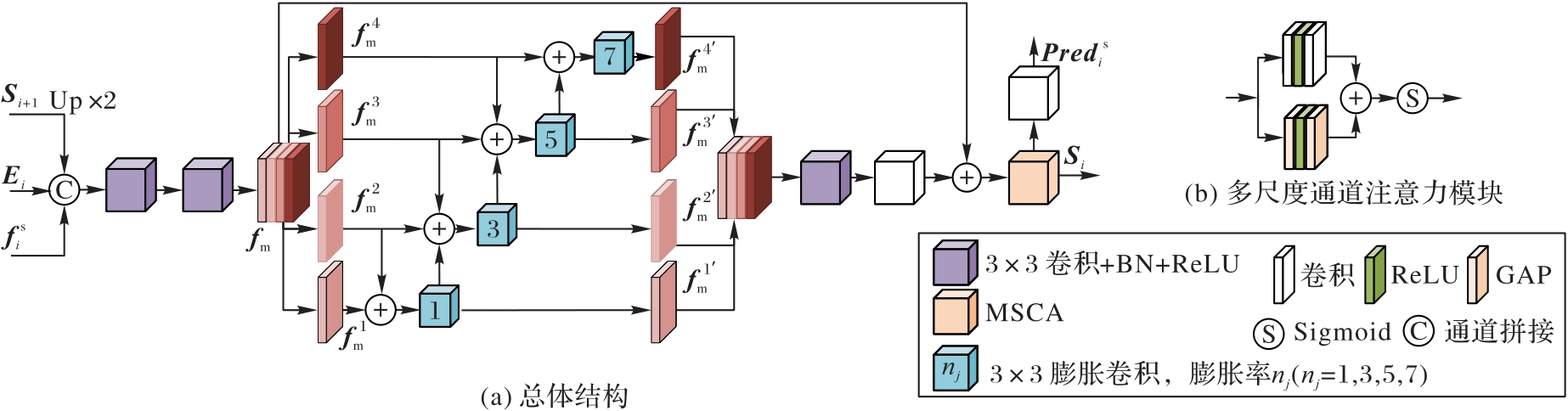
图4 定位引导完整性特征聚合模块的结构
Fig. 4 Structure of positioning-guided integrity feature aggregation module

图5 卷积门控通道注意力模块的结构
Fig. 5 Structure of convolutional gated channel attention module
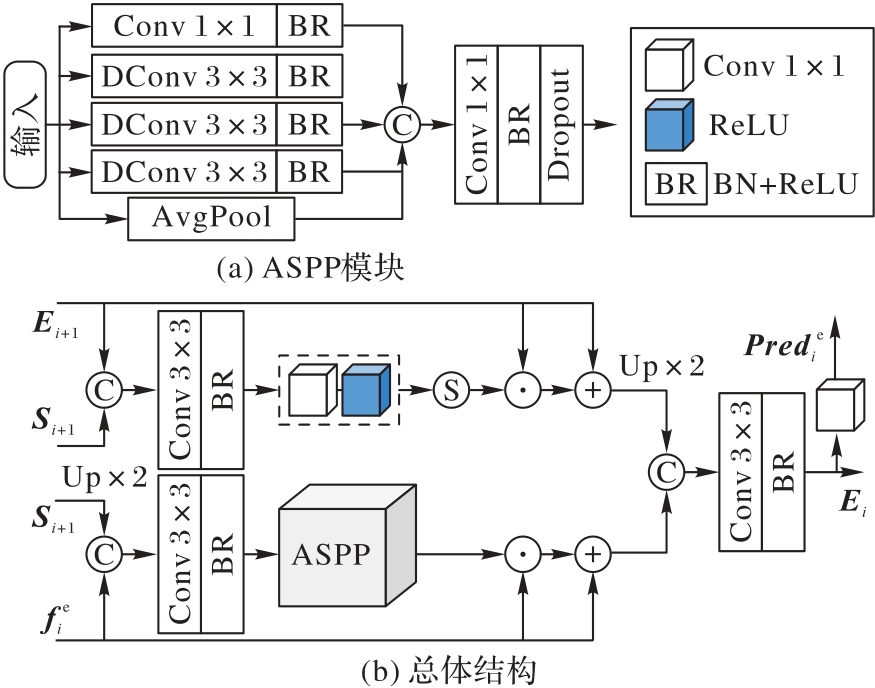
图6 深度定位模块的结构
Fig. 6 Structure of depth positioning module
| 类型 | 方法 | 参数量/ 106 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| COD | FSPNet[ | 273.79 | 0.856 | 0.899 | 0.799 | 0.050 | 0.851 | 0.895 | 0.735 | 0.026 | 0.879 | 0.915 | 0.816 | 0.035 |
| HitNet[ | 25.73 | 0.849 | 0.906 | 0.809 | 0.055 | 0.871 | 0.935 | 0.806 | 0.023 | 0.875 | 0.926 | 0.834 | 0.037 | |
| MSCAF-Net[ | 29.68 | 0.873 | 0.929 | 0.828 | 0.046 | 0.865 | 0.927 | 0.775 | 0.024 | 0.887 | 0.935 | 0.839 | 0.032 | |
| SARNet[ | 47.20 | 0.868 | 0.927 | 0.828 | 0.047 | 0.864 | 0.931 | 0.777 | 0.024 | 0.886 | 0.937 | 0.842 | 0.032 | |
| CamoFormer-S[ | 97.27 | 0.876 | 0.930 | 0.832 | 0.043 | 0.862 | 0.931 | 0.772 | 0.024 | 0.888 | 0.937 | 0.840 | 0.031 | |
| MVGNet[ | 56.11 | 0.879 | 0.930 | 0.839 | 0.045 | 0.877 | 0.936 | 0.799 | 0.022 | 0.894 | 0.938 | 0.850 | 0.030 | |
| RGB-D COD | PopNet[ | 188.05 | 0.808 | 0.859 | 0.744 | 0.077 | 0.851 | 0.910 | 0.757 | 0.028 | 0.861 | 0.910 | 0.802 | 0.042 |
| RISNet[ | — | 0.870 | 0.922 | 0.827 | 0.050 | 0.873 | 0.931 | 0.799 | 0.025 | 0.882 | 0.925 | 0.834 | 0.037 | |
| DaCOD[ | — | 0.855 | 0.911 | 0.796 | 0.051 | 0.840 | 0.908 | 0.729 | 0.028 | 0.874 | 0.923 | 0.814 | 0.035 | |
| VSCode[ | 74.72 | 0.873 | 0.925 | 0.820 | 0.046 | 0.869 | 0.931 | 0.780 | 0.023 | 0.891 | 0.935 | 0.841 | 0.032 | |
| SAM-COD[ | — | 0.875 | 0.952 | 0.849 | 0.044 | 0.887 | 0.948 | 0.827 | 0.022 | 0.896 | 0.959 | 0.866 | 0.029 | |
| RDMNet-R | 37.88 | 0.867 | 0.910 | 0.809 | 0.050 | 0.847 | 0.905 | 0.741 | 0.029 | 0.868 | 0.910 | 0.802 | 0.042 | |
| RDMNet | 74.65 | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 | |
表1 不同方法在COD数据集上的对比实验结果
Tab. 1 Comparison experimental results of different methods on COD datasets
| 类型 | 方法 | 参数量/ 106 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| COD | FSPNet[ | 273.79 | 0.856 | 0.899 | 0.799 | 0.050 | 0.851 | 0.895 | 0.735 | 0.026 | 0.879 | 0.915 | 0.816 | 0.035 |
| HitNet[ | 25.73 | 0.849 | 0.906 | 0.809 | 0.055 | 0.871 | 0.935 | 0.806 | 0.023 | 0.875 | 0.926 | 0.834 | 0.037 | |
| MSCAF-Net[ | 29.68 | 0.873 | 0.929 | 0.828 | 0.046 | 0.865 | 0.927 | 0.775 | 0.024 | 0.887 | 0.935 | 0.839 | 0.032 | |
| SARNet[ | 47.20 | 0.868 | 0.927 | 0.828 | 0.047 | 0.864 | 0.931 | 0.777 | 0.024 | 0.886 | 0.937 | 0.842 | 0.032 | |
| CamoFormer-S[ | 97.27 | 0.876 | 0.930 | 0.832 | 0.043 | 0.862 | 0.931 | 0.772 | 0.024 | 0.888 | 0.937 | 0.840 | 0.031 | |
| MVGNet[ | 56.11 | 0.879 | 0.930 | 0.839 | 0.045 | 0.877 | 0.936 | 0.799 | 0.022 | 0.894 | 0.938 | 0.850 | 0.030 | |
| RGB-D COD | PopNet[ | 188.05 | 0.808 | 0.859 | 0.744 | 0.077 | 0.851 | 0.910 | 0.757 | 0.028 | 0.861 | 0.910 | 0.802 | 0.042 |
| RISNet[ | — | 0.870 | 0.922 | 0.827 | 0.050 | 0.873 | 0.931 | 0.799 | 0.025 | 0.882 | 0.925 | 0.834 | 0.037 | |
| DaCOD[ | — | 0.855 | 0.911 | 0.796 | 0.051 | 0.840 | 0.908 | 0.729 | 0.028 | 0.874 | 0.923 | 0.814 | 0.035 | |
| VSCode[ | 74.72 | 0.873 | 0.925 | 0.820 | 0.046 | 0.869 | 0.931 | 0.780 | 0.023 | 0.891 | 0.935 | 0.841 | 0.032 | |
| SAM-COD[ | — | 0.875 | 0.952 | 0.849 | 0.044 | 0.887 | 0.948 | 0.827 | 0.022 | 0.896 | 0.959 | 0.866 | 0.029 | |
| RDMNet-R | 37.88 | 0.867 | 0.910 | 0.809 | 0.050 | 0.847 | 0.905 | 0.741 | 0.029 | 0.868 | 0.910 | 0.802 | 0.042 | |
| RDMNet | 74.65 | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 | |
| 方法 | DUT | NLPR | NJUD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MoADNet[ | 0.949 | 0.911 | 0.923 | 0.031 | 0.945 | 0.875 | 0.874 | 0.027 | 0.909 | 0.881 | 0.892 | 0.041 |
| LSNet[ | 0.891 | 0.775 | 0.831 | 0.074 | 0.955 | 0.881 | 0.882 | 0.024 | 0.922 | 0.885 | 0.899 | 0.038 |
| CAVER[ | 0.955 | 0.920 | 0.919 | 0.029 | 0.959 | 0.899 | 0.894 | 0.022 | 0.922 | 0.903 | 0.874 | 0.032 |
| LAFB[ | 0.957 | 0.919 | 0.930 | 0.027 | 0.958 | 0.902 | 0.905 | 0.021 | 0.924 | 0.910 | 0.919 | 0.028 |
| RDMNet | 0.972 | 0.948 | 0.952 | 0.018 | 0.946 | 0.863 | 0.881 | 0.029 | 0.939 | 0.874 | 0.894 | 0.039 |
表2 RGB-D SOD数据集上的对比实验结果
Tab. 2 Comparison experimental results on RGB-D SOD datasets
| 方法 | DUT | NLPR | NJUD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MoADNet[ | 0.949 | 0.911 | 0.923 | 0.031 | 0.945 | 0.875 | 0.874 | 0.027 | 0.909 | 0.881 | 0.892 | 0.041 |
| LSNet[ | 0.891 | 0.775 | 0.831 | 0.074 | 0.955 | 0.881 | 0.882 | 0.024 | 0.922 | 0.885 | 0.899 | 0.038 |
| CAVER[ | 0.955 | 0.920 | 0.919 | 0.029 | 0.959 | 0.899 | 0.894 | 0.022 | 0.922 | 0.903 | 0.874 | 0.032 |
| LAFB[ | 0.957 | 0.919 | 0.930 | 0.027 | 0.958 | 0.902 | 0.905 | 0.021 | 0.924 | 0.910 | 0.919 | 0.028 |
| RDMNet | 0.972 | 0.948 | 0.952 | 0.018 | 0.946 | 0.863 | 0.881 | 0.029 | 0.939 | 0.874 | 0.894 | 0.039 |
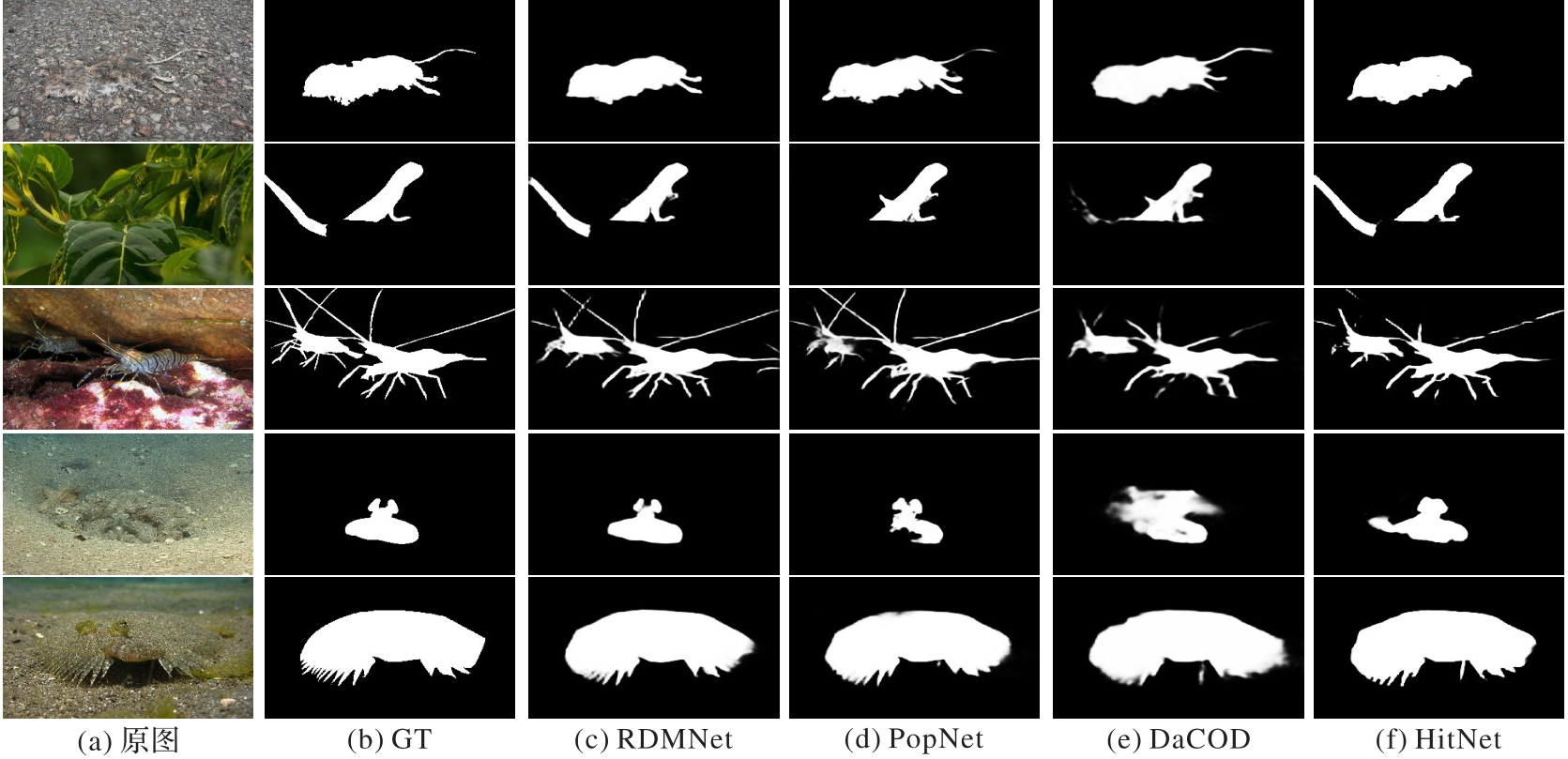
图7 RDMNet与3种先进方法的定性比较
Fig. 7 Qualitative comparison of RDMNet and three advanced methods

图8 RDMNet与RGB_D SOD先进方法的定性比较
Fig. 8 Qualitative comparison of RDMNet and RGB-D SOD advanced methods

图9 不同深度估计模型生成的深度图的定性比较
Fig. 9 Qualitative comparison of depth maps generated by different depth estimation models
| 方法 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| V1[ | 0.898 | 0.947 | 0.868 | 0.036 | 0.890 | 0.946 | 0.823 | 0.019 | 0.905 | 0.949 | 0.871 | 0.027 |
| V2[ | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 |
表3 不同深度估计模型生成的深度图的定量比较
Tab. 3 Quantitative comparison of depth maps generated by different depth estimation models
| 方法 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| V1[ | 0.898 | 0.947 | 0.868 | 0.036 | 0.890 | 0.946 | 0.823 | 0.019 | 0.905 | 0.949 | 0.871 | 0.027 |
| V2[ | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 |
| 模型 | GFLOPs | 参数量/106 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T+T | 68.40 | 94.64 | 0.899 | 0.942 | 0.865 | 0.036 | 0.895 | 0.946 | 0.827 | 0.019 | 0.911 | 0.948 | 0.872 | 0.026 |
| T+V | 43.59 | 74.65 | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 |
| V+V | 10.39 | 54.66 | 0.852 | 0.890 | 0.761 | 0.060 | 0.837 | 0.904 | 0.685 | 0.033 | 0.869 | 0.911 | 0.771 | 0.044 |
| R+R | 42.83 | 37.88 | 0.867 | 0.910 | 0.809 | 0.050 | 0.847 | 0.905 | 0.741 | 0.029 | 0.868 | 0.910 | 0.802 | 0.042 |
表4 不同主干网络的对比实验结果
Tab. 4 Comparison experimental results of different backbone networks
| 模型 | GFLOPs | 参数量/106 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T+T | 68.40 | 94.64 | 0.899 | 0.942 | 0.865 | 0.036 | 0.895 | 0.946 | 0.827 | 0.019 | 0.911 | 0.948 | 0.872 | 0.026 |
| T+V | 43.59 | 74.65 | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 |
| V+V | 10.39 | 54.66 | 0.852 | 0.890 | 0.761 | 0.060 | 0.837 | 0.904 | 0.685 | 0.033 | 0.869 | 0.911 | 0.771 | 0.044 |
| R+R | 42.83 | 37.88 | 0.867 | 0.910 | 0.809 | 0.050 | 0.847 | 0.905 | 0.741 | 0.029 | 0.868 | 0.910 | 0.802 | 0.042 |
模型 序号 | 模型构成 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | Baseline(B) | 0.871 | 0.923 | 0.807 | 0.050 | 0.842 | 0.917 | 0.712 | 0.030 | 0.872 | 0.926 | 0.798 | 0.039 |
| b | B+MFF | 0.876 | 0.924 | 0.813 | 0.048 | 0.840 | 0.919 | 0.710 | 0.030 | 0.871 | 0.927 | 0.800 | 0.038 |
| c | B+MFF+PGA | 0.882 | 0.929 | 0.817 | 0.046 | 0.843 | 0.916 | 0.711 | 0.030 | 0.874 | 0.925 | 0.798 | 0.039 |
| d | B+MFF+PGA+DPM | 0.900 | 0.948 | 0.872 | 0.035 | 0.893 | 0.950 | 0.827 | 0.018 | 0.907 | 0.950 | 0.872 | 0.026 |
| e | B+MFF+PGA+DPM+CCA | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 |
表5 消融实验结果
Tab. 5 Ablation study results
模型 序号 | 模型构成 | CAMO | COD10K | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | Baseline(B) | 0.871 | 0.923 | 0.807 | 0.050 | 0.842 | 0.917 | 0.712 | 0.030 | 0.872 | 0.926 | 0.798 | 0.039 |
| b | B+MFF | 0.876 | 0.924 | 0.813 | 0.048 | 0.840 | 0.919 | 0.710 | 0.030 | 0.871 | 0.927 | 0.800 | 0.038 |
| c | B+MFF+PGA | 0.882 | 0.929 | 0.817 | 0.046 | 0.843 | 0.916 | 0.711 | 0.030 | 0.874 | 0.925 | 0.798 | 0.039 |
| d | B+MFF+PGA+DPM | 0.900 | 0.948 | 0.872 | 0.035 | 0.893 | 0.950 | 0.827 | 0.018 | 0.907 | 0.950 | 0.872 | 0.026 |
| e | B+MFF+PGA+DPM+CCA | 0.899 | 0.946 | 0.866 | 0.036 | 0.895 | 0.950 | 0.828 | 0.018 | 0.909 | 0.951 | 0.874 | 0.026 |
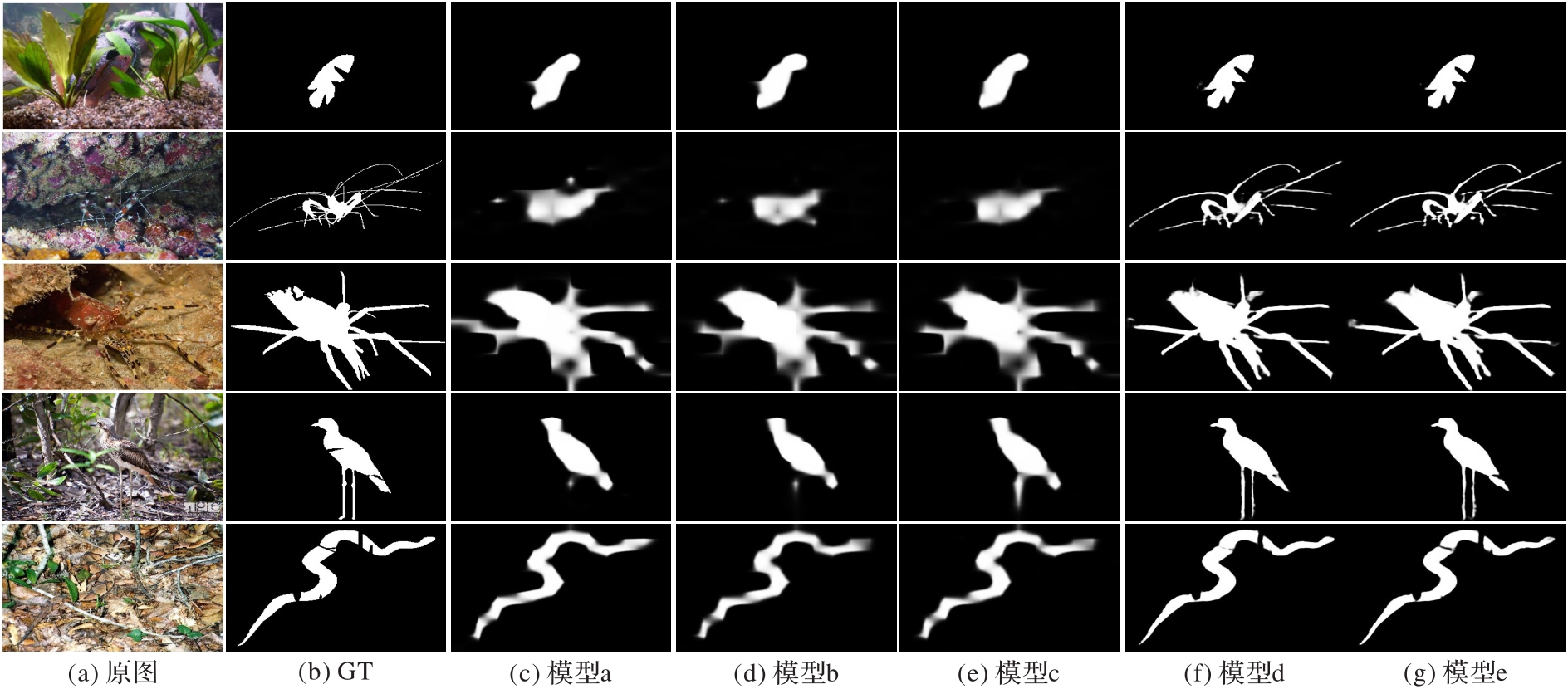
图10 消融实验中不同模型分割结果的可视化对比
Fig. 10 Visual comparison of segmentation results of different models in ablation study
| [1] | FAN D P, JI G P, SUN G, et al. Camouflaged object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 2774-2784. |
| [2] | JI G P, XIAO G, CHOU Y C, et al. Video polyp segmentation: a deep learning perspective[J]. Machine Intelligence Research, 2022, 19(6): 531-549. |
| [3] | LIU L, WANG R, XIE C, et al. PestNet: an end-to-end deep learning approach for large-scale multi-class pest detection and classification[J]. IEEE Access, 2019, 7: 45301-45312. |
| [4] | CHU H K, HSU W H, MITRA N J, et al. Camouflage images[J]. ACM Transactions on Graphics, 2010, 29(4): No.51. |
| [5] | JIA Q, YAO S, LIU Y, et al. Segment, magnify and reiterate: detecting camouflaged objects the hard way[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4703-4712. |
| [6] | REN J, HU X, ZHU L, et al. Deep texture-aware features for camouflaged object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(3): 1157-1167. |
| [7] | ZHU J, ZHANG X, ZHANG S, et al. Inferring camouflaged objects by texture-aware interactive guidance network[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 3599-3607. |
| [8] | ZHONG Y, LI B, TANG L, et al. Detecting camouflaged object in frequency domain[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4494-4503. |
| [9] | LIU X, QI L, SONG Y, et al. Depth awakens: a depth-perceptual attention fusion network for RGB-D camouflaged object detection[J]. Image and Vision Computing, 2024, 143: No.104924. |
| [10] | BORJI A, CHENG M M, HOU Q, et al. Salient object detection: a survey[J]. Computational Visual Media, 2019, 5(2): 117-150. |
| [11] | CHEN H, LI Y. Progressively complementarity-aware fusion network for RGB-D salient object detection[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3051-3060. |
| [12] | ZHAO J X, CAO Y, FAN D P, et al. Contrast prior and fluid pyramid integration for RGBD salient object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3922-3931. |
| [13] | LI C, CONG R, KWONG S, et al. ASIF-Net: attention steered interweave fusion network for RGB-D salient object detection[J]. IEEE Transactions on Cybernetics, 2021, 51(1): 88-100. |
| [14] | WANG L, YANG J, ZHANG Y, et al. Depth-aware concealed crop detection in dense agricultural scenes[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 17201-17211. |
| [15] | WANG Q, YANG J, YU X, et al. Depth-aided camouflaged object detection[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 3297-3306. |
| [16] | LIU Z, TAN Y, HE Q, et al. SwinNet: Swin Transformer drives edge-aware RGB-D and RGB-T salient object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(7): 4486-4497. |
| [17] | YUN Y K, LIN W. SelfReformer: self-refined network with Transformer for salient object detection[EB/OL]. [2025-07-23].. |
| [18] | YUAN W, GU X, DAI Z, et al. Neural window fully-connected CRFs for monocular depth estimation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 3906-3915. |
| [19] | SHI D. TransNeXt: robust foveal visual perception for Vision Transformers[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 17773-17783. |
| [20] | ZHU L, LIAO B, ZHANG Q, et al. Vision Mamba: efficient visual representation learning with bidirectional state space model[C]// Proceedings of the 41st International Conference on Machine Learning. New York: JMLR.org, 2024: 62429-62442. |
| [21] | LE T N, NGUYEN T V, NIE Z, et al. Anabranch network for camouflaged object segmentation[J]. Computer Vision and Image Understanding, 2019, 184: 45-56. |
| [22] | LV Y, ZHANG J, DAI Y, et al. Simultaneously localize, segment and rank the camouflaged objects[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11586-11596. |
| [23] | CHEN G, LIU S J, SUN Y J, et al. Camouflaged object detection via context-aware cross-level fusion[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(10): 6981-6993. |
| [24] | FAN D P, JI G P, CHENG M M, et al. Concealed object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10): 6024-6042. |
| [25] | YAN J, LE T N, NGUYEN K D, et al. MirrorNet: bio-inspired camouflaged object segmentation[J]. IEEE Access, 2021, 9: 43290-43300. |
| [26] | SUN Y, WANG S, CHEN C, et al. Boundary-guided camouflaged object detection[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 1335-1341. |
| [27] | ZHU H, LI P, XIE H, et al. I can find you! boundary guided separated attention network for camouflaged object detection[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 3608-3616. |
| [28] | SUN D, JIANG S, QI L. Edge-aware mirror network for camouflaged object detection[C]// Proceedings of the 2023 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2023: 2465-2470. |
| [29] | LANG C, NGUYEN T V, KATTI H, et al. Depth matters: influence of depth cues on visual saliency[C]// Proceedings of the 2012 European Conference on Computer Vision, LNCS 7573. Berlin: Springer, 2012: 101-115. |
| [30] | CIPTADI A, HERMANS T, REHG J M, et al. An in depth view of saliency[C]// Proceedings of the 2013 British Machine Vision Conference. Durham: BMVA Press, 2013: No.112. |
| [31] | PENG H, LI B, XIONG W, et al. RGBD salient object detection: a benchmark and algorithms[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8691. Cham: Springer, 2014: 92-109. |
| [32] | ZHANG M, REN W, PIAO Y, et al. Select, supplement and focus for RGB-D saliency detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3469-3478. |
| [33] | FU K, FAN D P, JI G P, et al. JL-DCF: joint learning and densely-cooperative fusion framework for RGB-D salient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3049-3059. |
| [34] | SUN P, ZHANG W, WANG H, et al. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1407-1417. |
| [35] | HUANG N, YANG Y, ZHANG D, et al. Employing bilinear fusion and saliency prior information for RGB-D salient object detection[J]. IEEE Transactions on Multimedia, 2021, 24: 1651-1664. |
| [36] | LIU N, ZHANG N, WAN K, et al. Visual saliency Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 4702-4712. |
| [37] | MEI H, JI G P, WEI Z, et al. Camouflaged object segmentation with distraction mining[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8768-8777. |
| [38] | XIANG M, ZHANG J, LV Y, et al. Exploring depth contribution for camouflaged object detection[EB/OL]. [2025-07-23].. |
| [39] | BIRKL R, WOFK D, MÜLLER M. MiDaS v3.1 — a model zoo for robust monocular relative depth estimation[EB/OL]. [2025-07-23].. |
| [40] | YANG L, KANG B, HUANG Z, et al. Depth anything: unleashing the power of large-scale unlabeled data[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 10371-10381. |
| [41] | YANG L, KANG B, HUANG Z, et al. Depth anything V2[C]// Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 21875-21911. |
| [42] | WU Z, PAUDEL D P, FAN D P, et al. Source-free depth for object pop-out[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 1032-1042. |
| [43] | DAI Y, GIESEKE F, QEHMCKE S, et al. Attentional feature fusion[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3559-3568. |
| [44] | PIAO Y R, JI W, LI J, et al. Depth-induced multi-scale recurrent attention network for saliency detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7253-7262. |
| [45] | JU R, GE L, GENG W, et al. Depth saliency based on anisotropic center-surround difference[C]// Proceedings of the 2014 IEEE International Conference on Image Processing. Piscataway: IEEE, 2014: 1115-1119. |
| [46] | FAN D P, CHENG M M, LIU Y, et al. Structure-measure: a new way to evaluate foreground maps[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 4558-4567. |
| [47] | FAN D P, GONG C, CAO Y, et al. Enhanced-alignment measure for binary foreground map evaluation[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2018: 698-704. |
| [48] | MARGOLIN R, ZELNIK-MANOR L, TAL A. How to evaluate foreground maps?[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 248-255. |
| [49] | PERAZZI F, KRÄHENBÜHL P, PRITCH Y, et al. Saliency filters: contrast based filtering for salient region detection[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2012: 733-740. |
| [50] | HUANG Z, DAI H, XIANG T Z, et al. Feature shrinkage pyramid for camouflaged object detection with Transformers[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 5557-5566. |
| [51] | HU X, WANG S, QIN X, et al. High-resolution iterative feedback network for camouflaged object detection[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 881-889. |
| [52] | LIU Y, LI H, CHENG J, et al. MSCAF-Net: a general framework for camouflaged object detection via learning multi-scale context-aware features[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 4936-4947. |
| [53] | XING H, GAO S, WANG Y, et al. Go closer to see better: camouflaged object detection via object area amplification and figure-ground conversion[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(10): 5444-5457. |
| [54] | YIN B, ZHANG X, FAN D P, et al. CamoFormer: masked separable attention for camouflaged object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10362-10374. |
| [55] | SONG X, ZHANG P, LU X, et al. A universal multi-view guided network for salient object and camouflaged object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(11): 11184-11197. |
| [56] | LUO Z, LIU N, ZHAO W, et al. VSCode: general visual salient and camouflaged object detection with 2D prompt learning[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 17169-17180. |
| [57] | LIU J, KONG L, CHEN G. Improving SAM for camouflaged object detection via dual stream adapters[C]// Proceedings of the 2025 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2025: 21906-21916. |
| [58] | JIN X, YI K, XU J. MoADNet: mobile asymmetric dual-stream networks for real-time and lightweight RGB-D salient object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(11): 7632-7645. |
| [59] | ZHOU W, ZHU Y, LEI J, et al. LSNet: lightweight spatial boosting network for detecting salient objects in RGB-thermal images[J]. IEEE Transactions on Image Processing, 2023, 32: 1329-1340. |
| [60] | PANG Y, ZHAO X, ZHANG L, et al. CAVER: cross-modal view-mixed Transformer for bi-modal salient object detection[J]. IEEE Transactions on Image Processing, 2023, 32: 892-904. |
| [61] | WANG K, TU Z, LI C, et al. Learning adaptive fusion bank for multi modal salient object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(8): 7344-7358. |
| [62] | GAO S H, CHEN M M, ZHAO K, et al. Res2Net: a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(2): 652-662. |
| [1] | 王文帅, 韩军, 胡广怡, 陈炣燏. 基于单目视觉输电线路精细化巡检方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1694-1702. |
| [2] | 李钟华, 钟庚辛, 范萍, 朱恒亮. 边界挖掘和背景引导的伪装目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3328-3335. |
| [3] | 谭湘粤, 胡晓, 杨佳信, 向俊将. 基于递进式特征增强聚合的伪装目标检测[J]. 《计算机应用》唯一官方网站, 2022, 42(7): 2192-2200. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||