


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1238-1252.DOI: 10.11772/j.issn.1001-9081.2025040419
• 多媒体计算与计算机仿真 • 上一篇
郭阳1,2, 王海亮1,2, 高需1,2( ), 王海涛1,2, 王翌博1,2
), 王海涛1,2, 王翌博1,2
收稿日期:2025-04-18
修回日期:2025-07-24
接受日期:2025-07-25
发布日期:2025-07-30
出版日期:2026-04-10
通讯作者:
高需
作者简介:郭阳(1983—),男,河南巩义人,工程师,博士,主要研究方向:人工智能、高性能计算基金资助:
Yang GUO1,2, Hailiang WANG1,2, Xu GAO1,2(), Haitao WANG1,2, Yibo WANG1,2
Received:2025-04-18
Revised:2025-07-24
Accepted:2025-07-25
Online:2025-07-30
Published:2026-04-10
Contact:
Xu GAO
About author:GUO Yang, born in 1983, Ph. D., engineer. His research interests include artificial intelligence, high-performance computing.Supported by:摘要:
视觉感知作为环境理解的核心技术之一,为智能移动系统(如自动驾驶)提供了精准的环境信息,是保障安全决策的重要前提。基于鸟瞰图(BEV)的三维目标检测技术因它的高效性和准确性已成为环境感知领域的主流范式。为进一步促进基于BEV的三维目标检测算法的研究,首先,针对BEV三维目标检测算法,根据输入数据的模态,将它们分为纯相机算法、纯激光雷达算法和相机?激光雷达融合算法这3类;其次,探讨预训练算法在提升检测性能中的作用;再次,分析融合时序特征的算法在动态场景中的优势和融合高度特征的算法在复杂环境下的表现;继次,梳理大模型协同BEV目标检测在目标检测精度与场景理解方面取得的突破性进展;最后,总结BEV三维目标检测算法的核心结论,并展望未来的研究方向,为该领域的研究工作提供新的思路。
中图分类号:
郭阳, 王海亮, 高需, 王海涛, 王翌博. BEV三维目标检测算法体系综述[J]. 计算机应用, 2026, 46(4): 1238-1252.
Yang GUO, Hailiang WANG, Xu GAO, Haitao WANG, Yibo WANG. Survey on BEV 3D object detection algorithm system[J]. Journal of Computer Applications, 2026, 46(4): 1238-1252.
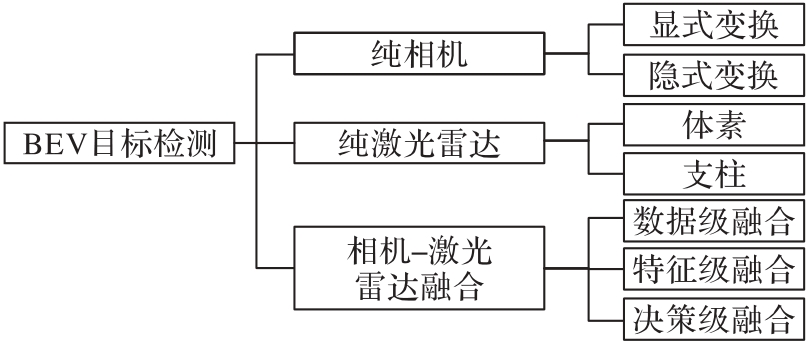
图1 BEV目标检测算法分类
Fig. 1 BEV object detection algorithm classification
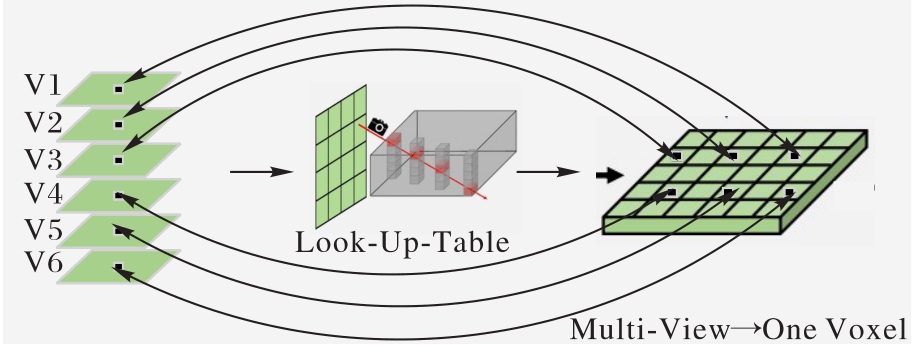
图2 Fast-Ray变换
Fig. 2 Fast-Ray transform
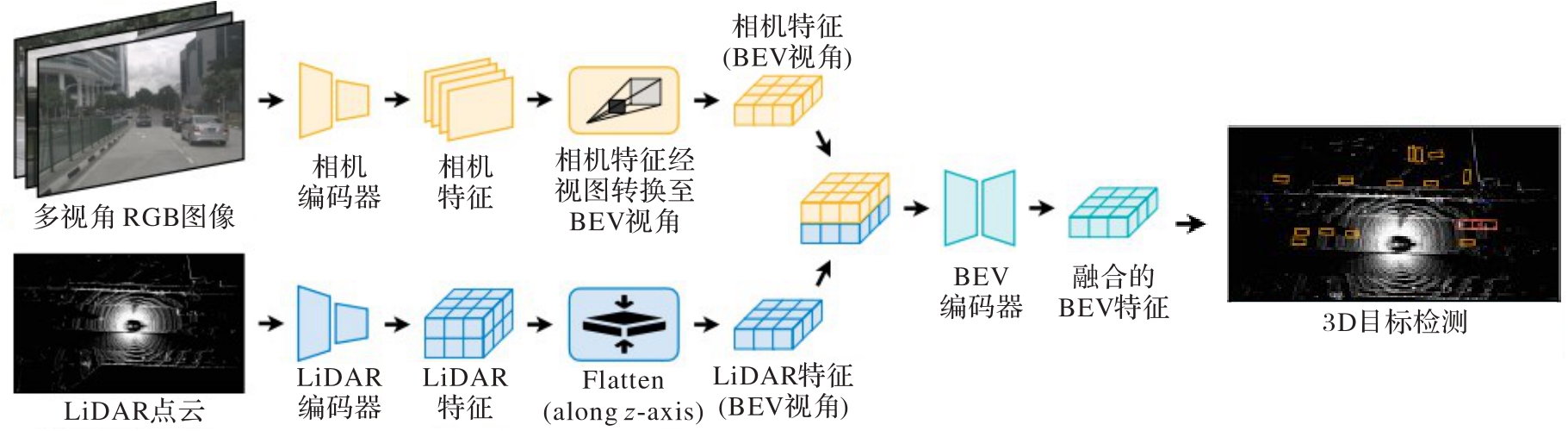
图3 相机?激光雷达的特征级深层融合
Fig. 3 Camera-LiDAR feature-level deep fusion
| 感知方式 | 类型 | 算法 | 核心思想 | 优势 | 局限性 | |
|---|---|---|---|---|---|---|
| 纯相机 | 显式 变换 | 2D-3D | BEVDet[ | 预测每个像素的深度分布,将2D图像特征提升到3D空间 | 内存需求少,偏向工业化 | 深度估计精确性不佳,过拟合问题严重 |
| Fast-BEV[ | 通过预计算投影索引操作和多视图到单体素操作,优化从2D图像到3D体素的投影过程 | 模型轻量化、高效、易部署 | 冗余信息多,对动态物体的运动预测能力较弱 | |||
| 3D-2D | OFTNet[ | 基于逆透视映射的视角转换,通过有条件地假设3D空间中的对应点位于水平面上,制定从3D空间到2D平面的投影关系 | 计算效率高,成本低 | 精度有限,数据依赖性较强 | ||
隐式 变换 | 基于 Transformer | BEVFormer[ | 采用密集查询,将多视角图像特征直接映射到BEV空间,利用Transformer的自注意力机制捕捉全局上下文信息,生成高质量的BEV表示 | 场景信息丰富,检测精确性高 | 计算复杂度高,推理效率受限 | |
| Far3D[ | 采用稀疏查询减少查询量,降低计算复杂度,同时利用稀疏性优化特征聚合过程,适用于大规模场景的高效处理 | 适合远距离检测,灵活性强 | 依赖稀疏特征的有效提取和聚合,可能会导致目标漏检和误检 | |||
| SparseBEV[ | 结合了密集查询和稀疏查询混合查询机制,既能保留全局信息完整性,又能在计算效率上平衡 | 计算效率和精度达到平衡,适合在边缘设备上部署 | 训练阶段耗费高,对初始化敏感 | |||
| 基于MLP | PowerBEV[ | 利用MLP的简单结构和高效计算能力,将多视角图像特征直接映射到BEV空间 | 避免了复杂的特征转换和冗余计算,显著提高了计算效率 | 小目标检测效果不佳 | ||
纯激光 雷达 | 基于体素 | AFDetV2[ | 在体素化数据上进行单阶段目标检测,减少了对第二阶段精细定位的依赖,从而在保持高精度的同时显著提高了检测速度 | 无需生成候选区域,处理过程简洁高效 | 小目标检测效果有限,过度依赖目标中心点 | |
| SECOND[ | 将点云划分为体素网格,并通过稀疏卷积网络提取特征,减少了计算量,同时保留了点云的空间结构信息 | 显著提高检测速度,充分保留空间结构信息 | 对体素分辨率敏感,小目标检测效果有限 | |||
| VoxelNet[ | 首次提出端到端体素化点云检测框架,通过体素特征编码和区域提议网络实现了高效的3D目标检测 | 检测过程简单,对点云的局部结构信息有较好的捕捉能力 | 内存消耗大,对体素分辨率敏感 | |||
| 基于Pillar | PointPillars[ | 将点云划分为Pillar,并通过多层感知机聚合每个Pillar内的点云特征 | 避免了3D卷积的高计算复杂度,显著提高了推理速度 | 划分参数对检测性能有显著影响,需仔细调整 | ||
| PillarNet[ | 优化了Pillar特征提取过程,通过引入多尺度特征融合和注意力机制,增强了特征表示能力,从而在复杂场景中实现更高的检测精度 | 增强了特征表达能力,提升了检测精度,适合大规模点云数据 | 对点云密度敏感,在稀疏点云场景中性能可能下降 | |||
相机‒ 激光雷达 融合 | 数据级融合 | ImVoteNet[ | 把几何特征、语义特征和纹理特征拼接形成的图像投票特征和点云数据进行结合,以提高3D目标检测的性能 | 图像投票机制增强了点云特征的表达能力,模块化设计扩展性强 | 计算复杂度高,数据依赖性强 | |
| PointPainting[ | 将3D点云投影到2D图像平面上,使得每个点云点对应到图像上的每个像素点 | 弥补点云数据在语义信息上的不足,尤其是在远距离或稀疏点云区域,提升3D目标检测的精度 | 计算复杂度较高,尤其在高分辨率图像和密集点云数据的情况下 | |||
| 特征级融合 | SFD[ | 通过深度补全技术生成密集深度图与图像特征融合,不仅保留了激光雷达的几何信息,还融入了图像的纹理信息 | 设计具有较好的模块化特性,可以灵活地与其他模块(如多传感器融合模块)结合,扩展性强 | 训练难度较大可能导致模型在实际应用中的部署和优化更复杂 | ||
| UVTR[ | 基于Transformer的特征融合方法,首先将激光雷达点云转换为体素表示,然后通过Transformer网络融合体素特征与图像特征 | 能够有效捕捉全局上下文信息,小目标检测方面表现出色,尤其是在激光雷达点云稀疏的情况下 | 模型参数量较大,需要较长的训练时间学习跨模态特征之间的关系 | |||
| PointFusion[ | 先通过独立网格提取点云和图像的特征,然后通过一个融合网格融合两种特征 | 直接提取对应的2D特征向量并与3D点特征拼接,实现了一种简单且高效的融合策略 | 依赖点云分辨率,计算复杂度较高,小目标检测性能受限 | |||
| 决策级融合 | CLOCs[ | 基于候选框,通过独立的检测器生成相机和激光雷达的候选框,然后用融合网格融合两种候选框 | 远距离目标检测效果好,架构简单,便于实现和扩展 | 数据对齐精度受限,训练过程相对复杂 | ||
| MV3D[ | 先通过相机和激光雷达生成多个视角的检测结果,然后通过一个融合网格融合不同视角的检测结果 | 能够显著提升复杂场景下的检测性能,尤其是在远距离或稀疏点云区域 | 需要同时优化多个模态的检测器和融合网络,训练过程相对复杂 | |||
表1 BEV目标检测算法的总结
Tab. 1 Summary of BEV object detection algorithms
| 感知方式 | 类型 | 算法 | 核心思想 | 优势 | 局限性 | |
|---|---|---|---|---|---|---|
| 纯相机 | 显式 变换 | 2D-3D | BEVDet[ | 预测每个像素的深度分布,将2D图像特征提升到3D空间 | 内存需求少,偏向工业化 | 深度估计精确性不佳,过拟合问题严重 |
| Fast-BEV[ | 通过预计算投影索引操作和多视图到单体素操作,优化从2D图像到3D体素的投影过程 | 模型轻量化、高效、易部署 | 冗余信息多,对动态物体的运动预测能力较弱 | |||
| 3D-2D | OFTNet[ | 基于逆透视映射的视角转换,通过有条件地假设3D空间中的对应点位于水平面上,制定从3D空间到2D平面的投影关系 | 计算效率高,成本低 | 精度有限,数据依赖性较强 | ||
隐式 变换 | 基于 Transformer | BEVFormer[ | 采用密集查询,将多视角图像特征直接映射到BEV空间,利用Transformer的自注意力机制捕捉全局上下文信息,生成高质量的BEV表示 | 场景信息丰富,检测精确性高 | 计算复杂度高,推理效率受限 | |
| Far3D[ | 采用稀疏查询减少查询量,降低计算复杂度,同时利用稀疏性优化特征聚合过程,适用于大规模场景的高效处理 | 适合远距离检测,灵活性强 | 依赖稀疏特征的有效提取和聚合,可能会导致目标漏检和误检 | |||
| SparseBEV[ | 结合了密集查询和稀疏查询混合查询机制,既能保留全局信息完整性,又能在计算效率上平衡 | 计算效率和精度达到平衡,适合在边缘设备上部署 | 训练阶段耗费高,对初始化敏感 | |||
| 基于MLP | PowerBEV[ | 利用MLP的简单结构和高效计算能力,将多视角图像特征直接映射到BEV空间 | 避免了复杂的特征转换和冗余计算,显著提高了计算效率 | 小目标检测效果不佳 | ||
纯激光 雷达 | 基于体素 | AFDetV2[ | 在体素化数据上进行单阶段目标检测,减少了对第二阶段精细定位的依赖,从而在保持高精度的同时显著提高了检测速度 | 无需生成候选区域,处理过程简洁高效 | 小目标检测效果有限,过度依赖目标中心点 | |
| SECOND[ | 将点云划分为体素网格,并通过稀疏卷积网络提取特征,减少了计算量,同时保留了点云的空间结构信息 | 显著提高检测速度,充分保留空间结构信息 | 对体素分辨率敏感,小目标检测效果有限 | |||
| VoxelNet[ | 首次提出端到端体素化点云检测框架,通过体素特征编码和区域提议网络实现了高效的3D目标检测 | 检测过程简单,对点云的局部结构信息有较好的捕捉能力 | 内存消耗大,对体素分辨率敏感 | |||
| 基于Pillar | PointPillars[ | 将点云划分为Pillar,并通过多层感知机聚合每个Pillar内的点云特征 | 避免了3D卷积的高计算复杂度,显著提高了推理速度 | 划分参数对检测性能有显著影响,需仔细调整 | ||
| PillarNet[ | 优化了Pillar特征提取过程,通过引入多尺度特征融合和注意力机制,增强了特征表示能力,从而在复杂场景中实现更高的检测精度 | 增强了特征表达能力,提升了检测精度,适合大规模点云数据 | 对点云密度敏感,在稀疏点云场景中性能可能下降 | |||
相机‒ 激光雷达 融合 | 数据级融合 | ImVoteNet[ | 把几何特征、语义特征和纹理特征拼接形成的图像投票特征和点云数据进行结合,以提高3D目标检测的性能 | 图像投票机制增强了点云特征的表达能力,模块化设计扩展性强 | 计算复杂度高,数据依赖性强 | |
| PointPainting[ | 将3D点云投影到2D图像平面上,使得每个点云点对应到图像上的每个像素点 | 弥补点云数据在语义信息上的不足,尤其是在远距离或稀疏点云区域,提升3D目标检测的精度 | 计算复杂度较高,尤其在高分辨率图像和密集点云数据的情况下 | |||
| 特征级融合 | SFD[ | 通过深度补全技术生成密集深度图与图像特征融合,不仅保留了激光雷达的几何信息,还融入了图像的纹理信息 | 设计具有较好的模块化特性,可以灵活地与其他模块(如多传感器融合模块)结合,扩展性强 | 训练难度较大可能导致模型在实际应用中的部署和优化更复杂 | ||
| UVTR[ | 基于Transformer的特征融合方法,首先将激光雷达点云转换为体素表示,然后通过Transformer网络融合体素特征与图像特征 | 能够有效捕捉全局上下文信息,小目标检测方面表现出色,尤其是在激光雷达点云稀疏的情况下 | 模型参数量较大,需要较长的训练时间学习跨模态特征之间的关系 | |||
| PointFusion[ | 先通过独立网格提取点云和图像的特征,然后通过一个融合网格融合两种特征 | 直接提取对应的2D特征向量并与3D点特征拼接,实现了一种简单且高效的融合策略 | 依赖点云分辨率,计算复杂度较高,小目标检测性能受限 | |||
| 决策级融合 | CLOCs[ | 基于候选框,通过独立的检测器生成相机和激光雷达的候选框,然后用融合网格融合两种候选框 | 远距离目标检测效果好,架构简单,便于实现和扩展 | 数据对齐精度受限,训练过程相对复杂 | ||
| MV3D[ | 先通过相机和激光雷达生成多个视角的检测结果,然后通过一个融合网格融合不同视角的检测结果 | 能够显著提升复杂场景下的检测性能,尤其是在远距离或稀疏点云区域 | 需要同时优化多个模态的检测器和融合网络,训练过程相对复杂 | |||
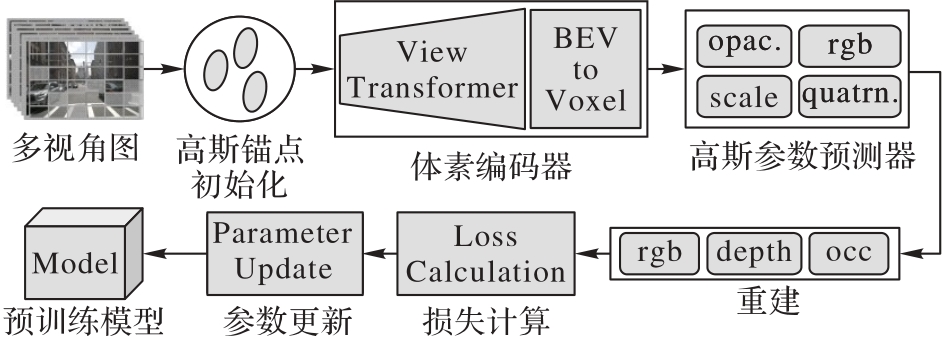
图4 高斯预训练
Fig. 4 Gaussian pre-training
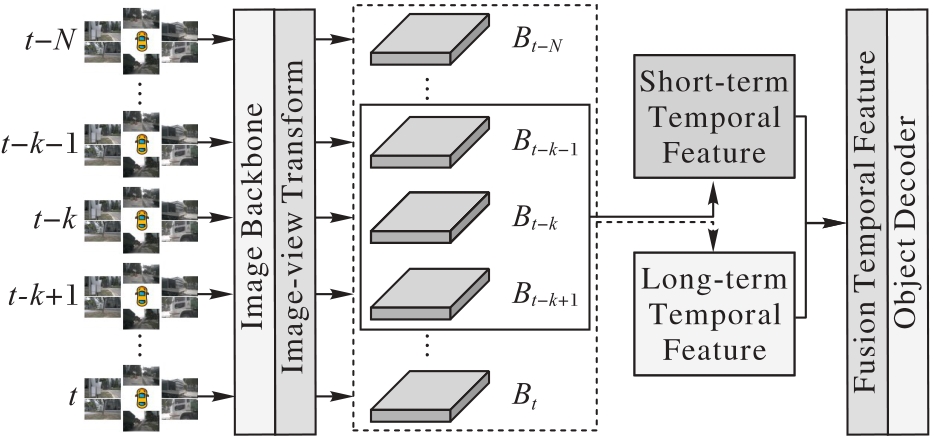
图5 混合时序特征
Fig. 5 Mixed temporal features

图6 融合单模态高度特征
Fig. 6 Fusion of single-modal height feature
| 数据集 | 创建单位 | 场景数 | 面积/km2 | 时长/h | 点云数/103 | 图像数/103 | 注释帧数/103 | 3D注释框数/103 |
|---|---|---|---|---|---|---|---|---|
| KITTI | TTIC and KIT | 22 | — | 1.5 | 15 | 15 | 15.0 | 80 |
| nuScenes | Motional | 1 000 | 5.00 | 5.5 | 390 | 1 400 | 40.0 | 1 400 |
| Lyft L5 | Lyft | 366 | — | 2.5 | 46 | 240 | 46.0 | 1 300 |
| H3D | HRI | 160 | — | 0.8 | 27 | 83 | 27.0 | 1 100 |
| A*3D | OpenData Lab | — | 728.00 | 55.0 | 39 | 39 | 39.0 | 230 |
| Waymo | Waymo | 1 150 | 76.00 | 6.4 | 230 | 12 000 | 230.0 | 12 000 |
| PandaSet | Scale AI | 179 | 1.58 | — | 16 | 41 | 12.5 | 43 |
| AIODrive | CMU | 100 | — | 2.8 | 100 | 1 000 | 100.0 | 26 000 |
| ONCE | HKU and Huawei | — | 210.00 | 144.0 | 1 000 | 7 000 | 15.0 | 417 |
| DeepAccident | HKU and Huawei | 464 | — | — | 131 | 786 | 131.0 | 1 800 |
| OpenLane | Shanghai AI | 1 000 | — | 6.4 | — | 200 | 200.0 | — |
| Argoverse 2 | Argo AI | 1 000 | 1.60 | 4.0 | 150 | 2 700 | 150.0 | — |
表2 BEV感知的自动驾驶数据集
Tab. 2 BEV perception based autonomous driving datasets
| 数据集 | 创建单位 | 场景数 | 面积/km2 | 时长/h | 点云数/103 | 图像数/103 | 注释帧数/103 | 3D注释框数/103 |
|---|---|---|---|---|---|---|---|---|
| KITTI | TTIC and KIT | 22 | — | 1.5 | 15 | 15 | 15.0 | 80 |
| nuScenes | Motional | 1 000 | 5.00 | 5.5 | 390 | 1 400 | 40.0 | 1 400 |
| Lyft L5 | Lyft | 366 | — | 2.5 | 46 | 240 | 46.0 | 1 300 |
| H3D | HRI | 160 | — | 0.8 | 27 | 83 | 27.0 | 1 100 |
| A*3D | OpenData Lab | — | 728.00 | 55.0 | 39 | 39 | 39.0 | 230 |
| Waymo | Waymo | 1 150 | 76.00 | 6.4 | 230 | 12 000 | 230.0 | 12 000 |
| PandaSet | Scale AI | 179 | 1.58 | — | 16 | 41 | 12.5 | 43 |
| AIODrive | CMU | 100 | — | 2.8 | 100 | 1 000 | 100.0 | 26 000 |
| ONCE | HKU and Huawei | — | 210.00 | 144.0 | 1 000 | 7 000 | 15.0 | 417 |
| DeepAccident | HKU and Huawei | 464 | — | — | 131 | 786 | 131.0 | 1 800 |
| OpenLane | Shanghai AI | 1 000 | — | 6.4 | — | 200 | 200.0 | — |
| Argoverse 2 | Argo AI | 1 000 | 1.60 | 4.0 | 150 | 2 700 | 150.0 | — |
| [1] | PHILION J, FIDLER S. Lift, splat, shoot: encoding images from arbitrary camera rigs by implicitly unprojecting to 3D[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12359. Cham: Springer, 2020: 194-210. |
| [2] | HUANG J, HUANG G, ZHU Z, et al. BEVDet: high-performance multi-camera 3D object detection in bird-eye-view[EB/OL]. [2024-12-23].. |
| [3] | LI Y, HUANG B, CHEN Z, et al. Fast-BEV: a fast and strong bird’s-eye view perception baseline[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 8665-8679. |
| [4] | MALLOT H A, BÜLTHOFF H H, LITTLE J J, et al. Inverse perspective mapping simplifies optical flow computation and obstacle detection[J]. Biological Cybernetics, 1991, 64(3): 177-185. |
| [5] | HARTLEY R, ZISSERMAN A. Multiple view geometry in computer vision[M]. Cambridge: Cambridge University Press, 2003. |
| [6] | RODDICK T, KENDALL A, CIPOLLA R. Orthographic feature transform for monocular 3D object detection[EB/OL]. [2024-12-23].. |
| [7] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [8] | RUMELHART D E, HINTON G E, WILLIAMS R J. Learning representations by back-propagating errors[J]. Nature, 1986, 323(6088): 533-536. |
| [9] | LI Z, WANG W, LI H, et al. BEVFormer: learning bird’s-eye-view representation from LiDAR-camera via spatiotemporal Transformers[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(3): 2020-2036. |
| [10] | JIANG X, LI S, LIU Y, et al. Far3D: expanding the horizon for surround-view 3D object detection[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 2561-2569. |
| [11] | YAO J, LAI Y. DynamicBEV: leveraging dynamic queries and temporal context for 3D object detection[EB/OL]. [2024-07-23].. |
| [12] | LI P, DING S, CHEN X, et al. PowerBEV: a powerful yet lightweight framework for instance prediction in bird’s-eye view[C]// Proceedings of the 32nd International Joint Conference on Artificial Intelligence. California: ijcai.org, 2023: 1080-1088. |
| [13] | ZHANG Z, XU M, ZHOU W, et al. BEV-Locator: an end-to-end visual semantic localization network using multi-view images[EB/OL]. [2024-12-23].. |
| [14] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [15] | MAO J, XUE Y, NIU M, et al. Voxel Transformer for 3D object detection[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 3144-3153. |
| [16] | HU Y, DING Z, GE R, et al. AFDetV2: rethinking the necessity of the second stage for object detection from point clouds[C]// Proceedings of the 2022 AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 969-979. |
| [17] | YAN Y, MAO Y, LI B. SECOND: sparsely embedded convolutional detection[J]. Sensors, 2018, 18(10): No.3337. |
| [18] | ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4490-4499. |
| [19] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. |
| [20] | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12689-12697. |
| [21] | SHI G, LI R, MA C. PillarNet: real-time and high-performance pillar-based 3D object detection[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13670. Cham: Springer, 2022: 35-52. |
| [22] | 贾明达,杨金明,孟维亮,等. 融合点云与图像的环境目标检测研究进展[J]. 中国图象图形学报, 2024, 29(6): 1765-1784. |
| JIA M D, YANG J M, MENG W L, et al. Survey on the fusion of point clouds and images for environmental object detection[J]. Journal of Image and Graphics, 2024, 29(6): 1765-1784. | |
| [23] | HAMILTON R. Deep Q learning with a multi-level vehicle perception for cooperative automated highway driving[D]. Hamilton: McMaster University, 2021. |
| [24] | QI C R, CHEN X, LITANY O, et al. ImVoteNet: boosting 3D object detection in point clouds with image votes[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4403-4412. |
| [25] | VORA S, LANG A H, HELOU B, et al. PointPainting: sequential fusion for 3D object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4603-4611. |
| [26] | WU X, PENG L, YANG H, et al. Sparse Fuse Dense: towards high quality 3D detection with depth completion[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5408-5417. |
| [27] | LI Y, CHEN Y, QI X, et al. Unifying voxel-based representation with Transformer for 3D object detection[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 18442-18455. |
| [28] | GUO J, HAN K, WU H, et al. CMT: convolutional neural networks meet vision Transformers[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12165-12175. |
| [29] | LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 2002, 86(11): 2278-2324. |
| [30] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-12-23].. |
| [31] | CHEN Z, LI Z, ZHANG S, et al. BEVDistill: cross-modal BEV distillation for multi-view 3D object detection[EB/OL]. [2024-12-23].. |
| [32] | WANG Z, LI D, LUO C, et al. DistillBEV: boosting multi-camera 3D object detection with cross-modal knowledge distillation[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 8637-8646. |
| [33] | XU D, ANGUELOV D, JAIN A. PointFusion: deep sensor fusion for 3D bounding box estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 244-253. |
| [34] | PANG S, MORRIS D, RADHA H. CLOCs: camera-LiDAR object candidates fusion for 3D object detection[C]// Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2020: 10386-10393. |
| [35] | CHEN X, MA H, WAN J, et al. Multi-view 3D object detection network for autonomous driving[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6526-6534. |
| [36] | SCHRÖDER E, MÄHLISCH M, VITAY J, et al. Fusion of camera and LiDAR data for object detection using neural networks[EB/OL]. [2024-12-23].. |
| [37] | RASMUSSEN C E. Evaluation of Gaussian processes and other methods for non-linear regression[D]. Toronto: University of Toronto, 1996: 1-200. |
| [38] | XU S, LI F, JIANG S, et al. GaussianPretrain: a simple unified 3D Gaussian representation for visual pre-training in autonomous driving[EB/OL]. [2024-12-23].. |
| [39] | ZHANG H, ZHOU W, ZHU Y, et al. VisionPAD: a vision-centric pre-training paradigm for autonomous driving[C]// Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2025: 17165-17175. |
| [40] | HE K, CHEN X, XIE S, et al. Masked autoencoders are scalable vision learners[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15979-15988. |
| [41] | CONG Y, KHANNA S, MENG C, et al. SatMAE: pre-training transformers for temporal and multi-spectral satellite imagery[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 197-211. |
| [42] | LI T, CHANG H, MISHRA S, et al. MAGE: masked generative encoder to unify representation learning and image synthesis[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2142-2152. |
| [43] | XIE Q, LUONG M T, HOVY E, et al. Self-training with noisy student improves ImageNet classification[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10687-10698. |
| [44] | YOU Y, WANG Y, CHAO W L, et al. Pseudo-LiDAR++: accurate depth for 3D object detection in autonomous driving[EB/OL]. [2024-12-23].. |
| [45] | CHEN Y, YANG Z, ZHENG X, et al. PointFormer: a dual perception attention-based network for point cloud classification[C]// Proceedings of the 2022 Asian Conference on Computer Vision, LNCS 13841. Cham: Springer, 2022: 432-449. |
| [46] | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 2672-2680. |
| [47] | ZHANG Y, ZHOU C, HUANG D. STAL3D: unsupervised domain adaptation for 3D object detection via collaborating self-training and adversarial learning[J]. IEEE Transactions on Intelligent Vehicles, 2024, 9(11): 7339-7350. |
| [48] | YANG J, SHI S, WANG Z, et al. ST3D: self-training for unsupervised domain adaptation on 3D object detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10363-10373. |
| [49] | YANG J, SHI S, WANG Z, et al. ST3D++: denoised self-training for unsupervised domain adaptation on 3D object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 6354-6371. |
| [50] | FAN H, YANG Y. PointRNN: point recurrent neural network for moving point cloud processing[EB/OL]. [2024-12-23].. |
| [51] | SHERSTINSKY A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network[J]. Physica D: Nonlinear Phenomena, 2020, 404: No.132306. |
| [52] | CAI H, ZHANG Z, ZHOU Z, et al. BEVFusion 4D: learning LiDAR-camera fusion under bird’s-eye-view via cross-modality guidance and temporal aggregation[EB/OL]. [2024-12-23].. |
| [53] | YANG C, CHEN Y, TIAN H, et al. BEVFormer v2: adapting modern image backbones to bird’s-eye-view recognition via perspective supervision[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 17830-17839. |
| [54] | GRAVES A. Long short-term memory[M]// Supervised sequence labelling with recurrent neural networks, SCI 385. Berlin: Springer, 2012: 37-45. |
| [55] | TONG A, HUANG J, WOLF G, et al. TrajectoryNet: a dynamic optimal transport network for modeling cellular dynamics[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 9526-9536. |
| [56] | WANG L, TIAN J, ZHOU S, et al. Memory-augmented appearance-motion network for video anomaly detection[J]. Pattern Recognition, 2023, 138: No.109335. |
| [57] | WANG S, LIU Y, WANG T, et al. Exploring object-centric temporal modeling for efficient multi-view 3D object detection[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 3598-3608. |
| [58] | HUANG J, HUANG G. BEVDet 4D: exploit temporal cues in multi-camera 3D object detection[EB/OL]. [2024-12-23].. |
| [59] | WANG X, YANG W, QI W, et al. STaRNet: a spatio-temporal and Riemannian network for high-performance motor imagery decoding[J]. Neural Networks, 2024, 178: No.106471. |
| [60] | LIN X, LIN T, PEI Z, et al. Sparse 4D: multi-view 3D object detection with sparse spatial-temporal fusion[EB/OL]. [2024-12-23].. |
| [61] | ZONG Z, JIANG D, SONG G, et al. Temporal enhanced training of multi-view 3D object detector via historical object prediction[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 3758-3767. |
| [62] | YANG L, YU K, TANG T, et al. BEVHeight: a robust framework for vision-based roadside 3D object detection[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 21611-21620. |
| [63] | YANG L, TANG T, LI J, et al. BEVHeight++: toward robust visual centric 3D object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(6): 5094-5111. |
| [64] | PAN L, WU T, CAI Z, et al. Multi-View Partial (MVP) Point Cloud Challenge 2021 on Completion and Registration: methods and results[EB/OL]. [2024-12-23].. |
| [65] | LI J, LUO C, YANG X. PillarNeXt: rethinking network designs for 3D object detection in LiDAR point clouds[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 17567-17576. |
| [66] | LI Y, BAO H, GE Z, et al. BEVStereo: enhancing depth estimation in multi-view 3D object detection with temporal stereo[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 1486-1494. |
| [67] | LIU Z, TANG H, AMINI A, et al. BEVFusion: multi-task multi-sensor fusion with unified bird’s-eye view representation[C]// Proceedings of the 2023 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2023: 2774-2781. |
| [68] | LI Y, YU A W, MENG T, et al. DeepFusion: LiDAR-camera deep fusion for multi-modal 3D object detection[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17161-17170. |
| [69] | YANG Z, CHEN J, MIAO Z, et al. DeepInteraction: 3D object detection via modality interaction[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 1992-2005. |
| [70] | LIU H, TENG Y, LU T, et al. SparseBEV: high-performance sparse 3D object detection from multi-camera videos[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 18534-18544. |
| [71] | LIU P, ZHANG Z, LIU H, et al. HeightFormer: a semantic alignment monocular 3D object detection method from roadside perspective[EB/OL]. [2024-12-23].. |
| [72] | MESCHEDER L, OECHSLE M, NIEMEYER M, et al. Occupancy networks: learning 3D reconstruction in function space[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4455-4465. |
| [73] | WEI Y, ZHAO L, ZHENG W, et al. SurroundOcc: multi-camera 3D occupancy prediction for autonomous driving[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 21672-21683. |
| [74] | LI Z, YU Z, AUSTIN D, et al. FB-OCC: 3D occupancy prediction based on forward-backward view transformation[EB/OL]. [2024-12-23].. |
| [75] | WANG X, ZHU Z, XU W, et al. OpenOccupancy: a large scale benchmark for surrounding semantic occupancy perception[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 17804-17813. |
| [76] | TIAN X, JIANG T, YUN L, et al. Occ3D: a large-scale 3D occupancy prediction benchmark for autonomous driving[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 64318-64330. |
| [77] | CHOUDHARY T, DEWANGAN V, CHANDHOK S, et al. Talk2BEV: language-enhanced bird’s-eye view maps for autonomous driving[C]// Proceedings of the 2024 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2024: 16345-16352. |
| [78] | SIMA C, RENZ K, CHITTA K, et al. DriveLM: driving with graph visual question answering[C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15110. Cham: Springer, 2025: 256-274. |
| [79] | HU A, RUSSELL L, YEO H, et al. GAIA-1: a generative world model for autonomous driving[EB/OL]. [2024-12-23].. |
| [80] | NGUYEN P, WANG T H, HONG Z W, et al. Text-to-Drive: diverse driving behavior synthesis via large language models[C]// Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2024: 10495-10502. |
| [81] | PARK S, LEE M, KANG J, et al. VLAAD: vision and language assistant for autonomous driving[C]// Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops. Piscataway: IEEE, 2024: 980-987. |
| [82] | TIAN X, GU J, LI B, et al. DriveVLM: the convergence of autonomous driving and large vision-language models[EB/OL]. [2024-12-23].. |
| [83] | SHI X, CUI B, DOBBIE G, et al. UniAD: a unified ad hoc data processing system[J]. ACM Transactions on Database Systems, 2017, 42(1): No.6. |
| [84] | 李昌财,陈刚,侯作勋,等. 自动驾驶中的三维目标检测算法研究综述[J]. 中国图象图形学报, 2024, 29(11): 3238-3264. |
| LI C C, CHEN G, HOU Z X, et al. Survey of 3D object detection algorithms for autonomous driving[J]. Journal of Image and Graphics, 2024, 29(11): 3238-3264. | |
| [85] | GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the KITTI vision benchmark suite[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2012: 3354-3361. |
| [86] | CAESAR H, BANKITI V, LANG A H, et al. nuScenes: a multimodal dataset for autonomous driving[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11618-11628. |
| [87] | HOUSTON J, ZUIDHOF G, BERGAMINI L, et al. One thousand and one hours: self-driving motion prediction dataset[C]// Proceedings of the 4th Conference on Robot Learning. New York: JMLR.org, 2021: 409-418. |
| [88] | PATIL A, MALLA S, GANG H, et al. The H3D dataset for full-surround 3D multi-object detection and tracking in crowded urban scenes[C]// Proceedings of the 2019 International Conference on Robotics and Automation. Piscataway: IEEE, 2019: 9552-9557. |
| [89] | PHAM Q H, SEVESTRE P, PAHWA R S, et al. A*3D dataset: towards autonomous driving in challenging environments[C]// Proceedings of the 2020 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2020: 2267-2273. |
| [90] | SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 2443-2451. |
| [91] | XIAO P, SHAO Z, HAO S, et al. PandaSet: advanced sensor suite dataset for autonomous driving[C]// Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference. Piscataway: IEEE, 2021: 3095-3101. |
| [92] | WENG X, MAN Y, PARK J, et al. All-In-One Drive: a large-scale comprehensive perception dataset with high-density long-range point clouds[EB/OL]. [2024-12-23].. |
| [93] | MAO J, NIU M, JIANG C, et al. One million scenes for autonomous driving: ONCE dataset[EB/OL]. [2024-12-23].. |
| [94] | WANG T, KIM S, JI W, et al. DeepAccident: a motion and accident prediction benchmark for V2X autonomous driving[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 5999-5606. |
| [95] | CHEN L, SIMA C, LI Y, et al. PersFormer: 3D lane detection via perspective Transformer and the OpenLane benchmark[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13698. Cham: Springer, 2022: 550-567. |
| [96] | WILSON B, QI W, AGARWAL T, et al. Argoverse 2: next generation datasets for self-driving perception and forecasting[EB/OL]. [2024-12-23].. |
| [1] | 肖毓航, 李贯峰, 陈昱胤, 秦晶. 基于图的多视角对比学习小样本关系抽取模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 732-740. |
| [2] | 陈敏, 秦小林, 李绍涵, 杨昊, 李韬弘. 深度学习应用于强对流天气预测的综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 980-992. |
| [3] | 何金栋, 及宇轩, 陈天赐, 许恒铭, 耿技, 曹明生, 梁员宁. 基于知识图谱和大模型的非智能传感器的实体发现方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 354-360. |
| [4] | 魏涵玥, 郭晨娟, 梅杰源, 田锦东, 陈鹏, 徐榕荟, 杨彬. 融合时频特征与混合文本的多模态股票预测框架MATCH[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 427-436. |
| [5] | 文洪建, 胡瑞娇, 吴保文, 孙家兴, 李环, 张晴, 刘杰. 基于图神经网络实现多尺度特征联合学习的中文作文自动评分[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 378-385. |
| [6] | 李明光, 陶重犇. 基于Mamba模型的分级跨模态融合三维目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 572-579. |
| [7] | 姜皓骞, 张东, 李冠宇, 陈恒. 基于结构增强的层次化任务导向提示策略的对话推荐系统SetaCRS[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 368-377. |
| [8] | 殷兵, 凌震华, 林垠, 奚昌凤, 刘颖. 兼容缺失模态推理的情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2764-2772. |
| [9] | 杨青, 朱焱. 改进语言规则中的表示的隐喻识别[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2491-2496. |
| [10] | 张伟, 牛家祥, 马继超, 沈琼霞. 深层语义特征增强的ReLM中文拼写纠错模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2484-2490. |
| [11] | 王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506. |
| [12] | 帅健, 王中卿, 陈嘉沥. 基于代码生成的细粒度情感分析方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1827-1832. |
| [13] | 孙海涛, 林佳瑜, 梁祖红, 郭洁. 结合标签混淆的中文文本分类数据增强技术[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1113-1119. |
| [14] | 刘天宇, 陶冶, 鲁超峰, 刘家旺. 融合叙事单元和可靠标签的小说说话人识别框架[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1190-1198. |
| [15] | 王利琴, 耿智雷, 李英双, 董永峰, 边萌. 基于路径和增强三元组文本的开放世界知识推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1177-1183. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||