


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (10): 3217-3223.DOI: 10.11772/j.issn.1001-9081.2021050808
所属专题: 多媒体计算与计算机仿真
柏财通1,2, 崔翛龙2,3, 郑会吉1,2, 李爱1,2
收稿日期:2021-05-20
修回日期:2021-09-13
接受日期:2021-09-22
发布日期:2022-10-14
出版日期:2022-10-10
通讯作者:
崔翛龙
作者简介:柏财通(1995—),男,山东济南人,硕士研究生,主要研究方向:深度边缘智能、鲁棒性语音识别;基金资助:Caitong BAI1,2, Xiaolong CUI2,3, Huiji ZHENG1,2, Ai LI1,2
Received:2021-05-20
Revised:2021-09-13
Accepted:2021-09-22
Online:2022-10-14
Published:2022-10-10
Contact:
Xiaolong CUI
About author:BAI Caitong, born in 1995, M. S. candidate. His research interests include deep edge intelligence, robust speech recognition.Supported by:摘要:
针对标注神经网络训练数据的成本日益增加与噪声干扰阻碍语音识别系统性能提升的问题,提出一种基于自监督知识迁移的鲁棒性语音识别模型的模型训练算法。首先,在预处理阶段提取原始语音样本的三个人工特征;然后,在训练阶段将特征提取网络生成的高级特征分别通过三个浅层网络来拟合预处理阶段提取的人工特征;同时,把特征提取前端与语音识别后端进行交叉训练,并合并它们的损失函数;最后,通过梯度反向传播令特征提取网络学会提取更有助于去噪语音识别的高级特征,从而实现人工知识迁移与去噪,并高效利用了训练数据。在军事装备控制的应用场景下,基于加噪后的THCHS-30、希尔贝壳数据集AISHELL-1与ST-CMDS这三个开源中文语音识别数据集以及军事装备控制指令的数据集上进行测试,实验结果表明,基于自监督知识迁移的鲁棒性语音识别模型的模型训练算法词错率可以降低到0.12,不仅可以实现对鲁棒性语音识别模型的模型训练,同时通过自监督知识迁移提高了训练样本的利用率,可完成装备控制任务。
中图分类号:
柏财通, 崔翛龙, 郑会吉, 李爱. 基于自监督知识迁移的鲁棒性语音识别技术[J]. 计算机应用, 2022, 42(10): 3217-3223.
Caitong BAI, Xiaolong CUI, Huiji ZHENG, Ai LI. Robust speech recognition technology based on self-supervised knowledge transfer[J]. Journal of Computer Applications, 2022, 42(10): 3217-3223.

图1 本文模型整体结构
Fig. 1 Overall structure of the proposed model
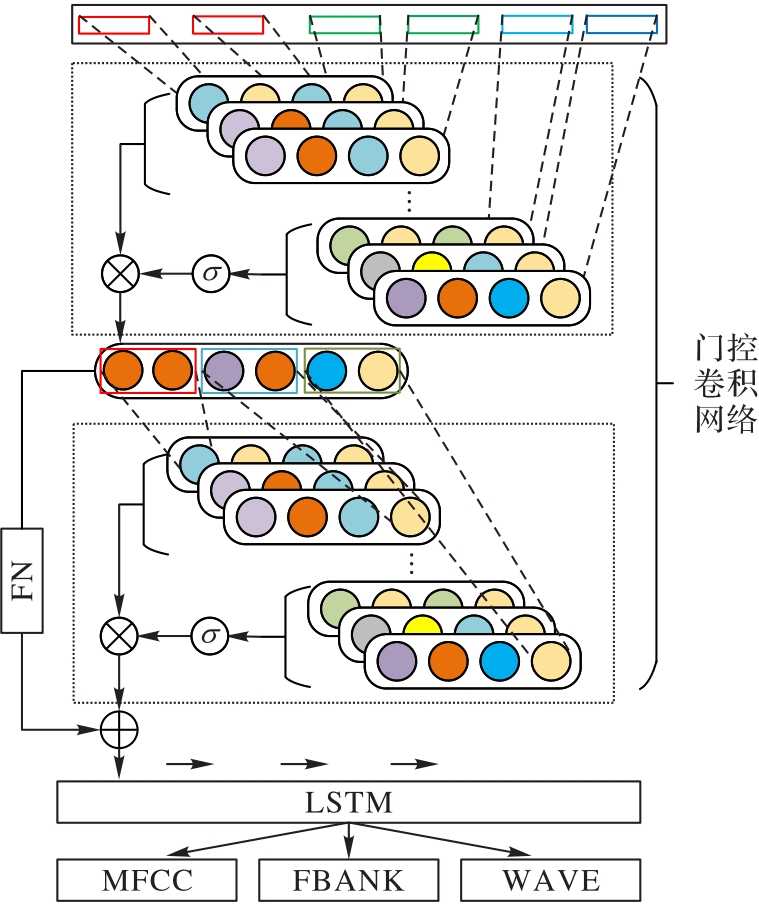
图2 特征提取前端的结构
Fig. 2 Structure of feature extraction front-end

图3 语音识别后端结构
Fig. 3 Structure of speech recognition back-end
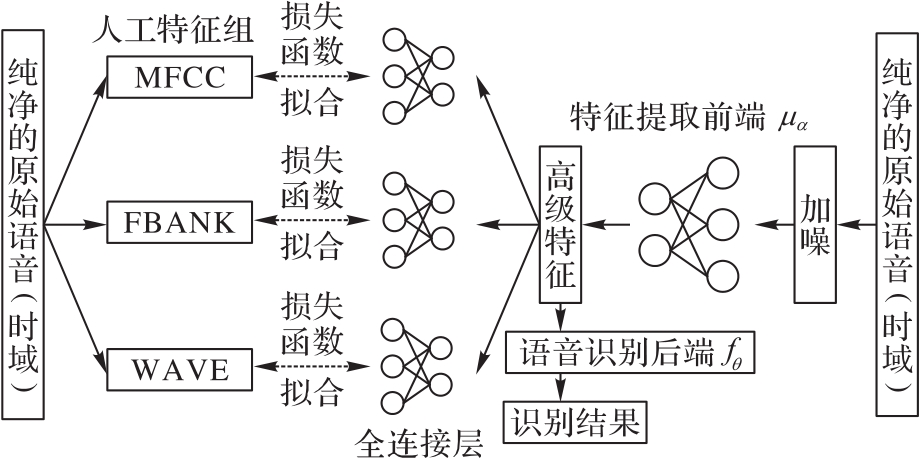
图4 GSDNet模型训练结构
Fig. 4 Training structure of GSDNet model
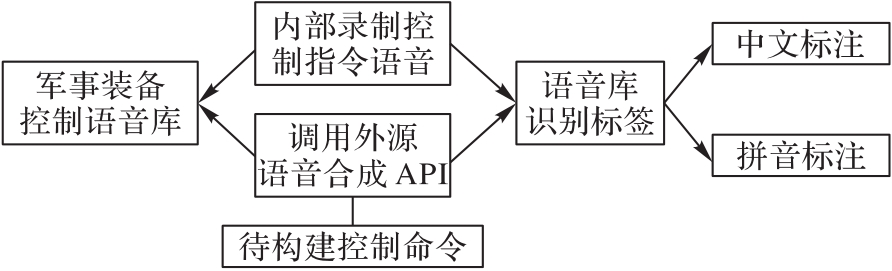
图5 数据集构建方法的逻辑图
Fig. 5 Logic diagram of dataset construction method
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (30,1,32 000) | — |
| Gated Block 1 | (1,64,1,1) | 64 |
| Gated Block 2 | (64,64,20,10) | 4 096 |
| Gated Block 3 | (64,128,11,2) | 8 192 |
| Gated Block 4 | (128,128,11,1) | 16 384 |
| Gated Block 5 | (128,256,11,2) | 32 768 |
| Gated Block 6 | (256,256,11,1) | 65 536 |
| Gated Block 7 | (256,512,11,2) | 131 072 |
| Gated Block 8 | (512,512,11,2) | 262 144 |
| LSTM | (512) | — |
| MFCC | (1,256) | — |
| FBANK | (1,256) | — |
| WAVE | (1,256) | — |
表1 特征提取前端网络参数
Tab. 1 Feature extraction front-end network parameters
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (30,1,32 000) | — |
| Gated Block 1 | (1,64,1,1) | 64 |
| Gated Block 2 | (64,64,20,10) | 4 096 |
| Gated Block 3 | (64,128,11,2) | 8 192 |
| Gated Block 4 | (128,128,11,1) | 16 384 |
| Gated Block 5 | (128,256,11,2) | 32 768 |
| Gated Block 6 | (256,256,11,1) | 65 536 |
| Gated Block 7 | (256,512,11,2) | 131 072 |
| Gated Block 8 | (512,512,11,2) | 262 144 |
| LSTM | (512) | — |
| MFCC | (1,256) | — |
| FBANK | (1,256) | — |
| WAVE | (1,256) | — |
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (64,161,601) | 6.0 |
| Gated Block 1 | (161,500,48,2,97) | 3.8 |
| 7*Gated Block 2 | (250,500,7,1) | 6.1 |
| Gated Block 3 | (250,2 000,32,1) | 16.0 |
| Gated Block 4 | (1 000,2 000,1,1) | 2.0 |
| Conv1d | (1 000,Output Units,1,1) | — |
| 中间张量 | (64,1 000, Output Units) | — |
| LSTM | (1 000,Dictionary Dim,2) | — |
| Softmax | (Output Units, Dictionary Dim) | — |
| 集束搜索器 | 3 | — |
表2 语音识别后端参数
Tab. 2 Speech recognition back-end parameters
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (64,161,601) | 6.0 |
| Gated Block 1 | (161,500,48,2,97) | 3.8 |
| 7*Gated Block 2 | (250,500,7,1) | 6.1 |
| Gated Block 3 | (250,2 000,32,1) | 16.0 |
| Gated Block 4 | (1 000,2 000,1,1) | 2.0 |
| Conv1d | (1 000,Output Units,1,1) | — |
| 中间张量 | (64,1 000, Output Units) | — |
| LSTM | (1 000,Dictionary Dim,2) | — |
| Softmax | (Output Units, Dictionary Dim) | — |
| 集束搜索器 | 3 | — |
| 结构变化 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Base structure | 0.320 | 0.370 | 0.320 | 0.400 | 0.450 | 0.580 |
| +gated cnn | 0.200 | 0.230 | 0.240 | 0.260 | 0.443 | 0.460 |
| +50 hours | 0.130 | 0.160 | 0.130 | 0.170 | 0.153 | 0.260 |
| +skip conection | 0.180 | 0.220 | 0.220 | 0.240 | 0.430 | 0.400 |
| +new workers | 0.160 | 0.140 | 0.120 | 0.140 | 0.150 | 0.200 |
表3 模型性能(词错率)受人工知识迁移模块影响的实验结果
Tab. 3 Experimental results of model performance (word error rate) affected by artificial knowledge transfer module
| 结构变化 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Base structure | 0.320 | 0.370 | 0.320 | 0.400 | 0.450 | 0.580 |
| +gated cnn | 0.200 | 0.230 | 0.240 | 0.260 | 0.443 | 0.460 |
| +50 hours | 0.130 | 0.160 | 0.130 | 0.170 | 0.153 | 0.260 |
| +skip conection | 0.180 | 0.220 | 0.220 | 0.240 | 0.430 | 0.400 |
| +new workers | 0.160 | 0.140 | 0.120 | 0.140 | 0.150 | 0.200 |
| 提取特征器 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| MFCC | 0.280 | 0.310 | 0.190 | 0.230 | 0.201 | 0.450 |
| FBANK | 0.300 | 0.400 | 0.200 | 0.300 | 0.300 | 0.500 |
| WAVE | 0.320 | 0.430 | 0.210 | 0.360 | 0.370 | 0.580 |
| GSDNet+(Supervised) | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
| GSDNet+(Finetuned) | 0.110 | 0.130 | 0.120 | 0.146 | 0.142 | 0.200 |
| GSDNet+(Frozen) | 0.123 | 0.160 | 0.126 | 0.160 | 0.150 | 0.270 |
表4 自监督提取特征与人工提取特征的性能(词错率)对比
Tab. 4 Performance (word error rate) comparison of self-supervised feature extraction and manual feature extraction
| 提取特征器 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| MFCC | 0.280 | 0.310 | 0.190 | 0.230 | 0.201 | 0.450 |
| FBANK | 0.300 | 0.400 | 0.200 | 0.300 | 0.300 | 0.500 |
| WAVE | 0.320 | 0.430 | 0.210 | 0.360 | 0.370 | 0.580 |
| GSDNet+(Supervised) | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
| GSDNet+(Finetuned) | 0.110 | 0.130 | 0.120 | 0.146 | 0.142 | 0.200 |
| GSDNet+(Frozen) | 0.123 | 0.160 | 0.126 | 0.160 | 0.150 | 0.270 |
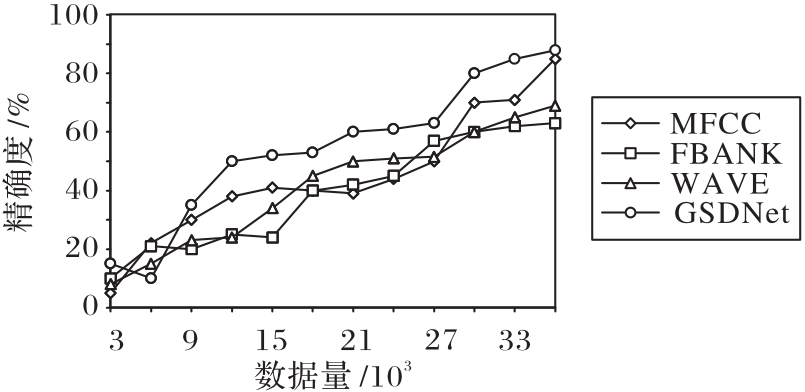
图6 数据量与性能对比
Fig. 6 Data volume vs performance comparison
| 训练方式 | 词错率 |
|---|---|
| 线性 | 0.4 |
| 交叉 | 0.2 |
表5 线性与交叉训练方式的词错率对比
Tab. 5 Word error rate comparison of linear and cross -training methods
| 训练方式 | 词错率 |
|---|---|
| 线性 | 0.4 |
| 交叉 | 0.2 |

图7 不同损失函数的GSDNet训练过程
Fig. 7 Training processes of GSDNet with different loss functions
| 算法 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Baseline | 0.170 | 0.180 | 0.200 | 0.270 | 0.250 | 0.450 |
| LAS | 0.150 | 0.160 | 0.160 | 0.190 | 0.201 | 0.443 |
| CTC | 0.130 | 0.156 | 0.140 | 0.160 | 0.160 | 0.420 |
| GSDNet | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
表6 不同算法的性能对比
Tab. 6 Performance comparison of different algorithms
| 算法 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Baseline | 0.170 | 0.180 | 0.200 | 0.270 | 0.250 | 0.450 |
| LAS | 0.150 | 0.160 | 0.160 | 0.190 | 0.201 | 0.443 |
| CTC | 0.130 | 0.156 | 0.140 | 0.160 | 0.160 | 0.420 |
| GSDNet | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
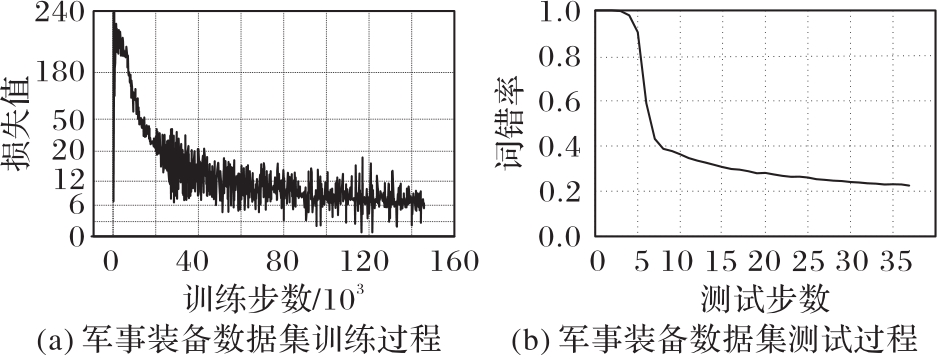
图8 本文模型训练结果
Fig. 8 Training results of the proposed model
| 1 | HE Y Z, SAINATH T N, PRABHAVALKAR R, et al. Streaming end-to-end speech recognition for mobile devices [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6381-6385. 10.1109/icassp.2019.8682336 |
| 2 | JUANG B H, RABINER L R. Hidden Markov models for speech recognition[J]. Technometrics, 1991, 33(3): 251-272. 10.1080/00401706.1991.10484833 |
| 3 | GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks, 2005, 18(5/6): 602-610. 10.1016/j.neunet.2005.06.042 |
| 4 | HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97. 10.1109/msp.2012.2205597 |
| 5 | CHAN W, JAITLY N, LE Q, et al. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 4960-4964. 10.1109/icassp.2016.7472621 |
| 6 | GRAVES A, FERNÁNDEZ S, GOMEZ F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks [C]// Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 369-376. 10.1145/1143844.1143891 |
| 7 | GRAVES A. Sequence transduction with recurrent neural networks[EB/OL]. (2012-11-14) [2021-05-01]. . 10.1007/978-3-642-24797-2_3 |
| 8 | JAITLY N, SUSSILLO D, LE Q V, et al. A neural transducer[EB/OL]. (2016-08-04) [2021-05-01]. . |
| 9 | CHIU C C, RAFFEL C. Monotonic chunkwise attention[EB/OL]. (2018-02-23) [2021-05-01]. . |
| 10 | ZHANG Z X, GEIGER J, POHJALAINEN J, et al. Deep learning for environmentally robust speech recognition: an overview of recent developments[J]. ACM Transactions on Intelligent Systems and Technology, 2018, 9(5): No.49. 10.1145/3178115 |
| 11 | 柏财通,高志强,李爱,等.基于门控网络的军事装备控制指令语音识别研究[J].计算机工程, 2021, 47(7): 301-306. 10.19678/j.issn.1000-3428.0058590 |
| BAI C T, GAO Z Q, LI A, et al. Research on voice recognition of military equipment control commands based on gated network[J]. Computer Engineering, 2021, 47(7): 301-306. 10.19678/j.issn.1000-3428.0058590 | |
| 12 | ZHAO X J, SHAO Y, WANG D L. CASA-based robust speaker identification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(5): 1608-1616. 10.1109/tasl.2012.2186803 |
| 13 | DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 933-941. |
| 14 | RAVANELLI M, OMOLOGO M. Contaminated speech training methods for robust DNN-HMM distant speech recognition [C]// Proceedings of the Interspeech 2015. [S.l.]: International Speech Communication Association, 2015: 756-760. 10.21437/interspeech.2015-251 |
| 15 | RAVANELLI M, ZHONG J Y, PASCUAL S, et al. Multi-task self-supervised learning for robust speech recognition [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6989-6993. 10.1109/icassp40776.2020.9053569 |
| 16 | ALLEN J B, BERKLEY D A. Image method for efficiently simulating small-room acoustics[J]. The Journal of the Acoustical Society of America, 1979, 65(4): 943-950. 10.1121/1.382599 |
| 17 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 18 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 19 | POLS L C W. Spectral analysis and identification of Dutch vowels in monosyllabic words[D]. Amsterdam: University of Amsterdam, 1977: 152. |
| 20 | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2021-05-01]. . |
| 21 | PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-05-01]. . 10.7551/mitpress/11474.003.0014 |
| 22 | WANG D, ZHANG X W. THCHS-30: a free Chinese speech corpus[EB/OL]. (2015-12-10) [2021-05-01]. . |
| 23 | BU H, DU J Y, NA X Y, et al. AISHELL-1: an open-source Mandarin speech corpus and a speech recognition baseline [C]// Proceedings of the 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment. Piscataway: IEEE, 2017: 1-5. 10.1109/icsda.2017.8384449 |
| 24 | ST-CMDS- 20170001_1, Free ST Chinese Mandarin corpus[DS/OL]. [2021-05-01]. . |
| 25 | KIM S, HORI T, WATANABE S. Joint CTC-attention based end-to-end speech recognition using multi-task learning [C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 4835-4839. 10.1109/icassp.2017.7953075 |
| 26 | KLAKOW D, PETERS J. Testing the correlation of word error rate and perplexity[J]. Speech Communication, 2002, 38(1/2): 19-28. 10.1016/s0167-6393(01)00041-3 |
| 27 | BA J L, KIROS J R, HINTON G E. Layer normalization[EB/OL]. (2016-07-21) [2021-05-01]. . |
| 28 | HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[EB/OL]. (2012-07-03) [2021-05-01]. . |
| [1] | 唐廷杰, 黄佳进, 秦进. 基于图辅助学习的会话推荐[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2711-2718. |
| [2] | 赵佳伟, 陈雪峰, 冯亮, 候亚庆, 朱泽轩, Yew‑Soon Ong. 优化场景视角下的进化多任务优化综述[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1325-1337. |
| [3] | 汪炅, 唐韬韬, 贾彩燕. 无负采样的正样本增强图对比学习推荐方法PAGCL[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1485-1492. |
| [4] | 韩贵金, 张馨渊, 张文涛, 黄娅. 基于多特征融合的自监督图像配准算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1597-1604. |
| [5] | 黄荣, 宋俊杰, 周树波, 刘浩. 基于自监督视觉Transformer的图像美学质量评价方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1269-1276. |
| [6] | 王晓兵, 张雄伟, 曹铁勇, 郑云飞, 王勇. 基于尺度注意知识迁移的自蒸馏目标分割方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 129-137. |
| [7] | 张雨宁, 阿布都克力木·阿布力孜, 梅悌胜, 徐春, 麦尔达娜·买买提热依木, 哈里旦木·阿布都克里木, 侯钰涛. 基于自监督特征提取的骨骼X线影像异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 175-181. |
| [8] | 马胜位, 黄瑞章, 任丽娜, 林川. 基于多层语义融合的结构化深度文本聚类模型[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2364-2369. |
| [9] | 刘磊, 伍鹏, 谢凯, 程贝芝, 盛冠群. 自监督学习HOG预测辅助任务下的车位检测方法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3933-3940. |
| [10] | 代雨柔, 杨庆, 张凤荔, 周帆. 基于自监督学习的社交网络用户轨迹预测模型[J]. 计算机应用, 2021, 41(9): 2545-2551. |
| [11] | 魏淳武, 赵涓涓, 唐笑先, 强彦. 基于多时期蒸馏网络的随访数据知识提取方法[J]. 计算机应用, 2021, 41(10): 2871-2878. |
| [12] | 吴崇数, 林霖, 薛蕴菁, 时鹏. 基于自监督学习的病理图像层次分割[J]. 计算机应用, 2020, 40(6): 1856-1862. |
| [13] | 俞璜悦, 王晗, 郭梦婷. 基于用户兴趣语义的视频关键帧提取[J]. 计算机应用, 2017, 37(11): 3139-3144. |
| [14] | 朱苏阳, 惠浩添, 钱龙华, 张民. 基于自监督学习的维基百科家庭关系抽取[J]. 计算机应用, 2015, 35(4): 1013-1016. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||