


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (10): 3099-3106.DOI: 10.11772/j.issn.1001-9081.2022101510
所属专题: 人工智能
毕以镇, 马焕, 张长青( )
)
收稿日期:2022-10-11
修回日期:2023-01-24
接受日期:2023-02-02
发布日期:2023-04-12
出版日期:2023-10-10
通讯作者:
张长青
作者简介:毕以镇(1998—),男,山东潍坊人,硕士研究生,主要研究方向:多模态学习、机器学习
Yizhen BI, Huan MA, Changqing ZHANG()
Received:2022-10-11
Revised:2023-01-24
Accepted:2023-02-02
Online:2023-04-12
Published:2023-10-10
Contact:
Changqing ZHANG
About author:BI Yizhen, born in 1998, M. S. candidate. His research interests include multimodal learning, machine learning.摘要:
针对获取新模态难度大、收益差异大的问题,提出了一种增广模态收益动态评估方法。首先,通过多模态融合网络得到中间特征表示和模态融合前后的预测结果;其次,将两个预测结果的真实类别概率(TCP)引入置信度估计,得到融合前后的置信度;最后,计算两种置信度的差异,并将该差异作为样本以获取新模态所带来的收益。在常用多模态数据集和真实的医学数据集如癌症基因组图谱(TCGA)上进行实验。在TCGA数据集上的实验结果表明,与随机收益评估方法和基于最大类别概率(MCP)的方法相比,所提方法的准确率分别提高了1.73~4.93和0.43~4.76个百分点,有效样本率(ESR)分别提升了2.72~11.26和1.08~25.97个百分点。可见,所提方法能够有效评估不同样本获取新模态所带来的收益,并具备一定可解释性。
中图分类号:
毕以镇, 马焕, 张长青. 增广模态收益动态评估方法[J]. 计算机应用, 2023, 43(10): 3099-3106.
Yizhen BI, Huan MA, Changqing ZHANG. Dynamic evaluation method for benefit of modality augmentation[J]. Journal of Computer Applications, 2023, 43(10): 3099-3106.
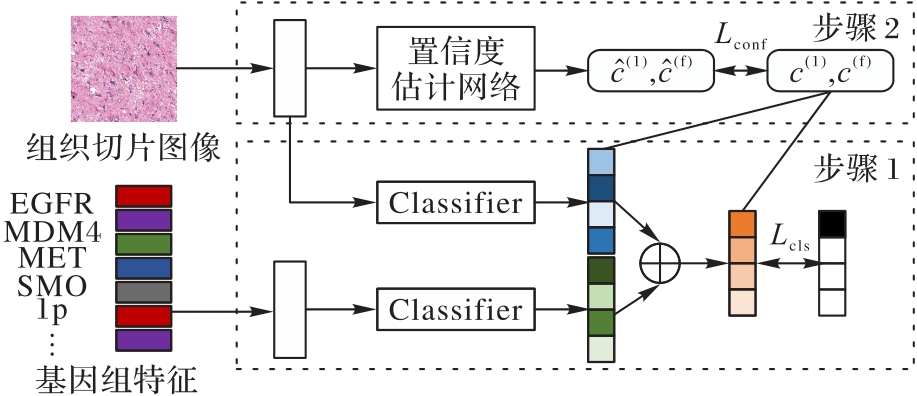
图1 多模态场景下的置信度估计的主要框架
Fig. 1 Main framework of multimodal confidence estimation

图2 两种多模态融合方法的框架
Fig. 2 Frameworks of two multimodal fusion methods

图3 组织切片图像
Fig. 3 Tissue section images
| 数据集 | 维度 | 类别数 | |
|---|---|---|---|
| 模态1 | 模态2 | ||
| hand | 216 | 76 | 10 |
| CMU-MOSEI | 50×300 | 50×35 | 7 |
| Dermatology | 11 | 23 | 6 |
| TCGA | 64×64×3 | 80 | 3 |
表1 数据集说明
Tab. 1 Description of datasets
| 数据集 | 维度 | 类别数 | |
|---|---|---|---|
| 模态1 | 模态2 | ||
| hand | 216 | 76 | 10 |
| CMU-MOSEI | 50×300 | 50×35 | 7 |
| Dermatology | 11 | 23 | 6 |
| TCGA | 64×64×3 | 80 | 3 |
| 数据集 | 模态1 | 模态2 | 融合后 |
|---|---|---|---|
| hand | 97.41±0.31 | 74.91±1.85 | 98.41±0.11 |
| CMU-MOSEI | 50.25±0.14 | 41.88±0.27 | 50.37±0.13 |
| Dermatology | 79.33±1.69 | 94.33±0.94 | 95.33±1.69 |
| TCGA | 47.73±2.68 | 61.87±0.62 | 62.74±1.08 |
表2 多模态与单模态准确率比较 (%)
Tab. 2 Accuracy comparison between unimodal and multimodal
| 数据集 | 模态1 | 模态2 | 融合后 |
|---|---|---|---|
| hand | 97.41±0.31 | 74.91±1.85 | 98.41±0.11 |
| CMU-MOSEI | 50.25±0.14 | 41.88±0.27 | 50.37±0.13 |
| Dermatology | 79.33±1.69 | 94.33±0.94 | 95.33±1.69 |
| TCGA | 47.73±2.68 | 61.87±0.62 | 62.74±1.08 |

图4 MSE变化趋势
Fig. 4 Change trend of MSE

图5 样本排序示意图
Fig. 5 Schematic diagram of sample sorting
| 数据集 | 模态1 | 模态2 | 测试集大小 |
|---|---|---|---|
| hand | × | √ | 400 |
| CMU-MOSEI | × | √ | 4 643 |
| Dermatology | √ | × | 100 |
| TCGA | √ | × | 231 |
表3 模态缺失说明
Tab. 3 Description of modality missing
| 数据集 | 模态1 | 模态2 | 测试集大小 |
|---|---|---|---|
| hand | × | √ | 400 |
| CMU-MOSEI | × | √ | 4 643 |
| Dermatology | √ | × | 100 |
| TCGA | √ | × | 231 |

图6 不同数据集上的准确率比较
Fig. 6 Comparison of accuracy on different datasets

图7 不同数据集上有效样本率比较
Fig. 7 Comparison of effective sample rate on different datasets
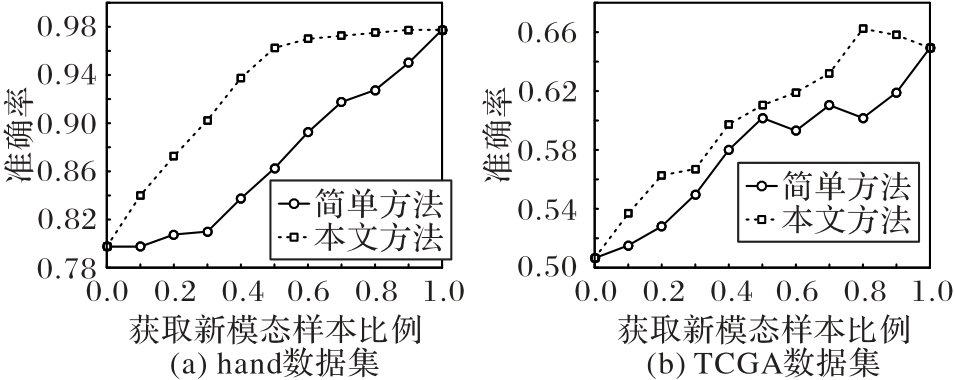
图8 本文方法与简单方法的准确率对比
Fig. 8 Accuracy comparison between the proposed method and simple method

图9 本文方法与简单方法的有效样本率对比
Fig. 9 Comparison of effective sample rate between the proposed method and simple method
| 数据集 | 平均融合 | 加权融合 |
|---|---|---|
| hand | 96.91±0.82 | 98.41±0.11 |
| CMU-MOSEI | 48.69±1.03 | 50.37±0.13 |
| Dermatology | 92.66±0.47 | 95.33±1.69 |
| TCGA | 59.71±2.31 | 62.74±1.08 |
表4 加权融合和平均融合的准确率对比 (%)
Tab. 4 Accuracy comparison between weighted fusion and average fusion
| 数据集 | 平均融合 | 加权融合 |
|---|---|---|
| hand | 96.91±0.82 | 98.41±0.11 |
| CMU-MOSEI | 48.69±1.03 | 50.37±0.13 |
| Dermatology | 92.66±0.47 | 95.33±1.69 |
| TCGA | 59.71±2.31 | 62.74±1.08 |
| 数据集 | 模态1的自适应权重( | 模态2的自适应权重( |
|---|---|---|
| hand | 0.624 5 | 0.375 5 |
| CMU-MOSEI | 0.897 0 | 0.103 0 |
| Dermatology | 0.431 8 | 0.568 2 |
| TCGA | 0.390 0 | 0.610 0 |
表5 α的训练结果
Tab. 5 Training result of α
| 数据集 | 模态1的自适应权重( | 模态2的自适应权重( |
|---|---|---|
| hand | 0.624 5 | 0.375 5 |
| CMU-MOSEI | 0.897 0 | 0.103 0 |
| Dermatology | 0.431 8 | 0.568 2 |
| TCGA | 0.390 0 | 0.610 0 |
| 1 | RAMACHANDRAM D, TAYLOR G W. Deep multimodal learning: a survey on recent advances and trends[J]. IEEE Signal Processing Magazine, 2017, 34(6):96-108. 10.1109/msp.2017.2738401 |
| 2 | LEE S, PARK S J, HONG K S. RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 4990-4999. 10.1109/iccv.2017.533 |
| 3 | VALADA A, MOHAN R, BURGARD W. Self-supervised model adaptation for multimodal semantic segmentation[J]. International Journal of Computer Vision, 2020, 128(5): 1239-1285. 10.1007/s11263-019-01188-y |
| 4 | FAN L, HUANG W, GAN C, et al. End-to-end learning of motion representation for video understanding[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6016-6025. 10.1109/cvpr.2018.00630 |
| 5 | GARCIA N C, MORERIO P, MURINO V. Modality distillation with multiple stream networks for action recognition[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11212. Cham: Springer, 2018: 106-121. |
| 6 | BALNTAS V, DOUMANOGLOU A, SAHIN C, et al. Pose guided RGBD feature learning for 3D object pose estimation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3876-3884. 10.1109/iccv.2017.416 |
| 7 | 吴明晖,张广洁,金苍宏. 基于多模态信息融合的时间序列预测模型[J]. 计算机应用, 2022, 42(8): 2326-2332. 10.11772/j.issn.1001-9081.2021061053 |
| WU M H, ZHANG G J, JIN C H. Time series prediction model based on multimodal information fusion[J]. Journal of Computer Applications, 2022, 42(8): 2326-2332. 10.11772/j.issn.1001-9081.2021061053 | |
| 8 | 余娜,刘彦,魏雄炬,等. 基于注意力机制和金字塔融合的RGB-D室内场景语义分割[J]. 计算机应用, 2022, 42(3): 844-853. 10.11772/j.issn.1001-9081.2021030392 |
| YU N, LIU Y, WEI X J, et al. Semantic segmentation of RGB-D indoor scenes based on attention mechanism and pyramid fusion[J]. Journal of Computer Applications, 2022, 42(3): 844-853. 10.11772/j.issn.1001-9081.2021030392 | |
| 9 | WANG Y, HUANG W, SUN F, et al. Deep multimodal fusion by channel exchanging[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 4835-4845. |
| 10 | HAZIRBAS C, MA L, DOMOKOS C, et al. FuseNet: incorporating depth into semantic segmentation via fusion-based cnn architecture[C]// Proceedings of the 2016 Asian Conference on Computer Vision, LNCS 10111. Cham: Springer, 2017: 213-228. |
| 11 | ZENG J, TONG Y, HUANG Y, et al. Deep surface normal estimation with hierarchical RGB-D fusion[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6146-6155. 10.1109/cvpr.2019.00631 |
| 12 | DU D, WANG L, WANG H, et al. Translate-to-recognize networks for RGB-D scene recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11828-11837. 10.1109/cvpr.2019.01211 |
| 13 | GRETTON A, BORGWARDT K M, RASCH M J, et al. A kernel two-sample test[J]. Journal of Machine Learning Research, 2012, 13: 723-773. |
| 14 | WANG J, WANG Z, TAO D, et al. Learning common and specific features for RGB-D semantic segmentation with deconvolutional networks[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9909. Cham: Springer, 2016: 664-679. |
| 15 | LIU Z, LI J, SHEN Z, et al. Learning efficient convolutional networks through network slimming[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2755-2763. 10.1109/iccv.2017.298 |
| 16 | BALTRUŠAITIS T, AHUJA C, MORENCY L P. Multimodal machine learning: a survey and taxonomy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423-443. 10.1109/tpami.2018.2798607 |
| 17 | CASTELLANO G, KESSOUS L, CARIDAKIS G. Emotion recognition through multiple modalities: face, body gesture, speech[M]// PETER C, BEALE R. Affect and Emotion in Human-Computer Interaction: From Theory to Applications, LNCS 4868. Berlin: Springer, 2008: 92-103. |
| 18 | RAMIREZ G A, BALTRUŠAITIS T, MORENCY L P. Modeling latent discriminative dynamic of multi-dimensional affective signals[C]// Proceedings of the 2011 International Conference on Affective Computing and Intelligent Interaction, LNCS 6975. Berlin: Springer, 2011: 396-406. |
| 19 | LAN Z Z, BAO L, YU S I, et al. Multimedia classification and event detection using double fusion[J]. Multimedia Tools and Applications, 2014, 71(1): 333-347. 10.1007/s11042-013-1391-2 |
| 20 | CAI T, CAI T T, ZHANG A. Structured matrix completion with applications to genomic data integration[J]. Journal of the American Statistical Association, 2016, 111(514): 621-633. 10.1080/01621459.2015.1021005 |
| 21 | TRAN L, LIU X, ZHOU J, et al. Missing modalities imputation via cascaded residual autoencoder[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4971-4980. 10.1109/cvpr.2017.528 |
| 22 | TSAI Y H H, LIANG P P, ZADEH A, et al. Learning factorized multimodal representations[EB/OL]. (2019-05-14) [2023-01-20].. |
| 23 | WU M, GOODMAN N. Multimodal generative models for scalable weakly-supervised learning[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 5580-5590. |
| 24 | ZHANG C, HAN Z, CUI Y, et al. CPM-Nets: cross partial multi-view networks[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 559-569. |
| 25 | AMODEI D, OLAH C, STEINHARDT J, et al. Concrete problems in AI safety[EB/OL]. (2016-07-25) [2023-01-20].. |
| 26 | JANAI J, GÜNEY F, BEHL A, et al. Computer vision for autonomous vehicles: problems, datasets and state of the art[J]. Foundations and Trends® in Computer Graphics and Vision, 2020, 12(1/2/3): 1-308. 10.1561/0600000079 |
| 27 | GUO C, PLEISS G, SUN Y, et al. On calibration of modern neural networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1321-1330. |
| 28 | LIANG S, LI Y, SRIKANT R. Enhancing the reliability of out-of-distribution image detection in neural networks[EB/OL]. (2020-08-30) [2023-01-20].. |
| 29 | CORBIÈRE C, THOME N, BAR-HEN A, et al. Addressing failure prediction by learning model confidence[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 2902-2913. |
| 30 | GAL Y, GHAHRAMANI Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1050-1059. |
| 31 | DUI R. Multiple Features dataset in UCI machine learning repository[DS/OL]. [2023-01-20].. |
| 32 | ZADEH A A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2018: 2236-2246. 10.18653/v1/p18-1208 |
| 33 | CHEN R J, LU M Y, WANG J, et al. Pathomic fusion: an integrated framework for fusing histopathology and genomic features for cancer diagnosis and prognosis[J]. IEEE Transactions on Medical Imaging, 2022, 41(4): 757-770. 10.1109/tmi.2020.3021387 |
| 34 | ILTER N, GUVENIR H. Dermatology dataset in UCI machine learning repository[DS/OL]. [2023-01-20].. |
| [1] | 黄颖, 杨佳宇, 金家昊, 万邦睿. 用于RGBT跟踪的孪生混合信息融合算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2878-2885. |
| [2] | 李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703. |
| [3] | 杜郁, 朱焱. 构建预训练动态图神经网络预测学术合作行为消失[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2726-2731. |
| [4] | 王清, 赵杰煜, 叶绪伦, 王弄潇. 统一框架的增强深度子空间聚类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1995-2003. |
| [5] | 黎施彬, 龚俊, 汤圣君. 基于Graph Transformer的半监督异配图表示学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1816-1823. |
| [6] | 朱云华, 孔兵, 周丽华, 陈红梅, 包崇明. 图对比学习引导的多视图聚类网络[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3267-3274. |
| [7] | 罗俊豪, 朱焱. 用于未对齐多模态语言序列情感分析的多交互感知网络[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 79-85. |
| [8] | 李牧, 杨宇恒, 柯熙政. 基于混合特征提取与跨模态特征预测融合的情感识别模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 86-93. |
| [9] | 王春雷, 王肖, 刘凯. 多模态知识图谱表示学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 1-15. |
| [10] | 赵强, 王中卿, 王红玲. 融合多模态信息的产品摘要抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 73-78. |
| [11] | 黄懿蕊, 罗俊玮, 陈景强. 基于对比学习和GIF标记的多模态对话回复检索[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 32-38. |
| [12] | 王静红, 周志霞, 王辉, 李昊康. 双路自编码器的属性网络表示学习[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2338-2344. |
| [13] | 张琨, 杨丰玉, 钟发, 曾广东, 周世健. 基于混合代码表示的源代码脆弱性检测[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2517-2526. |
| [14] | 富坤, 郝玉涵, 孙明磊, 刘赢华. 基于优化图结构自编码器的网络表示学习[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3054-3061. |
| [15] | 杜航原, 郝思聪, 王文剑. 结合图自编码器与聚类的半监督表示学习方法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2643-2651. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||