


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (9): 2683-2688.DOI: 10.11772/j.issn.1001-9081.2023091244
帅奇1, 王海瑞1, 朱贵富2( )
)
收稿日期:2023-09-12
修回日期:2023-11-25
接受日期:2023-12-01
发布日期:2024-03-21
出版日期:2024-09-10
通讯作者:
朱贵富
作者简介:帅奇(1999—),男,四川眉山人,硕士研究生,主要研究方向:自然语言处理基金资助:
Qi SHUAI1, Hairui WANG1, Guifu ZHU2()
Received:2023-09-12
Revised:2023-11-25
Accepted:2023-12-01
Online:2024-03-21
Published:2024-09-10
Contact:
Guifu ZHU
About author:SHUAI Qi, born in 1999, M. S. candidate. His research interests include natural language processing.Supported by:摘要:
中文故事结尾生成(SEG)是自然语言处理中的下游任务之一。基于全错误结尾的CLSEG(Contrastive Learning of Story Ending Generation)在故事的一致性方面表现较好。然而,由于错误结尾中也包含与原结尾文本相同的内容,仅使用错误结尾的对比训练会导致生成文本中原结尾正确的主要部分被剥离。因此,在CLSEG基础上增加正向结尾增强训练,以保留对比训练中损失的正确部分;同时,通过正向结尾的引入,使生成的结尾具有更强的多样性和关联性。基于双向对比训练的中文故事结尾生成模型包含两个主要部分:1)多结尾采样,通过不同的模型方法获取正向增强的结尾和反向对比的错误结尾;2)对比训练,在训练过程中修改损失函数,使生成的结尾接近正向结尾,远离错误结尾。在公开的故事数据集OutGen上的实验结果表明,相较于GPT2.ft和深层逐层隐变量融合(Della)等模型,所提模型的BERTScore、METEOR等指标均取得了较优的结果,生成的结尾具有更强的多样性和关联性。
中图分类号:
帅奇, 王海瑞, 朱贵富. 基于双向对比训练的中文故事结尾生成模型[J]. 计算机应用, 2024, 44(9): 2683-2688.
Qi SHUAI, Hairui WANG, Guifu ZHU. Chinese story ending generation model based on bidirectional contrastive training[J]. Journal of Computer Applications, 2024, 44(9): 2683-2688.
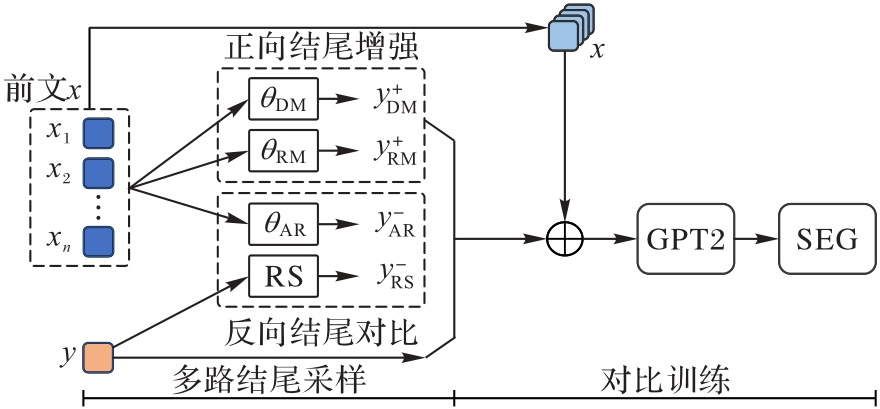
图1 正向增强与反向对比训练模型的结构
Fig. 1 Structure of forward enhancement and reverse contrast training model
| 方法 | 示例 |
|---|---|
| 原结尾 | 马得到了好处,不再贫困,却也失去了自由。 |
| DM | 这个国家的未来到底在哪里呢?于是,他决定去寻找答案。 |
| RM | 其他三位便把他们卖去了马,救下了背上的陷阱。 |
| RS | 失去了好处,继续贫困,却重获自由 |
| AR | 马赢了,结束了这场争吵,又恢复了往日的风貌,一家欢喜几家愁。 |
表1 不同方法生成的结尾示例
Tab. 1 Ending examples of different sampling methods
| 方法 | 示例 |
|---|---|
| 原结尾 | 马得到了好处,不再贫困,却也失去了自由。 |
| DM | 这个国家的未来到底在哪里呢?于是,他决定去寻找答案。 |
| RM | 其他三位便把他们卖去了马,救下了背上的陷阱。 |
| RS | 失去了好处,继续贫困,却重获自由 |
| AR | 马赢了,结束了这场争吵,又恢复了往日的风貌,一家欢喜几家愁。 |
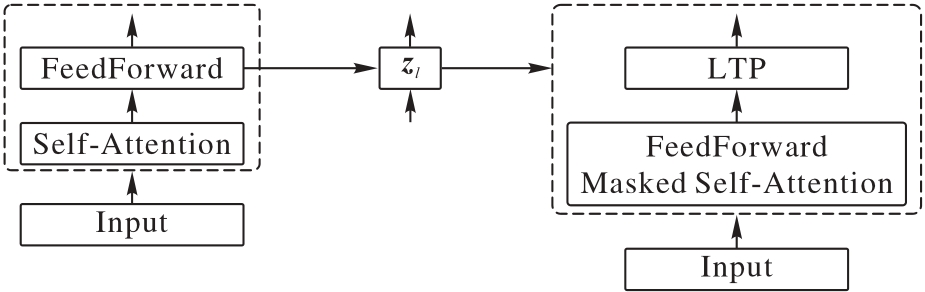
图2 Della模型结构
Fig. 2 Structure of Della model
| 超参数 | 值 | 超参数 | 值 |
|---|---|---|---|
| 总轮次 | 100 | 最大截断长度 | 256 |
| 批次量 | 8 | 预热步比例 | 10% |
| 学习率 | 2×10-5 | 生成文本长度 | 64 |
| 累积步率 | 8 |
表2 超参数设置
Tab. 2 Hyperparameter setting
| 超参数 | 值 | 超参数 | 值 |
|---|---|---|---|
| 总轮次 | 100 | 最大截断长度 | 256 |
| 批次量 | 8 | 预热步比例 | 10% |
| 学习率 | 2×10-5 | 生成文本长度 | 64 |
| 累积步率 | 8 |
| 数据集 | 类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
| OutGen | 样本数 | 1 456 | 729 | 242 |
| 字符数 | 274 654 | 138 311 | 45 662 | |
| 中文字数 | 231 733 | 116 799 | 38 567 | |
| CFT | 样本数 | 739 | 362 | — |
| 字符数 | 128 579 | 48 389 | — | |
| 中文字数 | 127 631 | 47 994 | — |
表3 更改后的OutGen与CFT数据集信息
Tab. 3 Information of changed OutGen and CFT datasets
| 数据集 | 类型 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
| OutGen | 样本数 | 1 456 | 729 | 242 |
| 字符数 | 274 654 | 138 311 | 45 662 | |
| 中文字数 | 231 733 | 116 799 | 38 567 | |
| CFT | 样本数 | 739 | 362 | — |
| 字符数 | 128 579 | 48 389 | — | |
| 中文字数 | 127 631 | 47 994 | — |
| 模型 | B-1 | B-2 | B-3 | B-4 | D-1 | D-2 | Cover | BERTScore/% | METEOR |
|---|---|---|---|---|---|---|---|---|---|
| Truth | 100.00 | 100.00 | 100.00 | 100.00 | 36.52 | 84.83 | 100.00 | 60.58 | 9.01 |
| GPT2 | 21.08 | 2.22 | 0.42 | 0.01 | 29.86 | 71.11 | 25.39 | 55.17 | 4.97 |
| GPT2.ft[ | 24.20 | 3.47 | 0.47 | 0.12 | 73.46 | 28.51 | 56.65 | 5.61 | |
| Embedding[ | 16.61 | 0.60 | 0.01 | 0.01 | 34.66 | 83.32 | 23.77 | 51.20 | 4.32 |
| Memory[ | 17.90 | 0.77 | 0.01 | 0.01 | 29.89 | 22.05 | 53.16 | 3.55 | |
| Softmax[ | 20.45 | 1.04 | 0.01 | 0.01 | 25.70 | 71.87 | 25.20 | 55.05 | 4.62 |
| LOT[ | 23.15 | 3.60 | 0.45 | 0.15 | 25.32 | 65.01 | 27.32 | 56.12 | 6.70 |
| 文献[ | 24.58 | 3.92 | 0.67 | 26.01 | 66.61 | 30.49 | 58.75 | ||
| Della[ | 21.79 | 3.21 | 0.22 | 30.61 | 75.26 | 22.96 | 55.82 | 4.00 | |
| Simctg[ | 0.76 | 0.22 | 29.88 | 72.99 | 7.51 | ||||
| 本文模型 | 26.48 | 6.43 | 1.40 | 0.45 | 20.83 | 54.86 | 32.35 | 60.27 | 8.38 |
表4 不同模型的自动评估结果
Tab. 4 Automatic evaluation results for comparative experiments
| 模型 | B-1 | B-2 | B-3 | B-4 | D-1 | D-2 | Cover | BERTScore/% | METEOR |
|---|---|---|---|---|---|---|---|---|---|
| Truth | 100.00 | 100.00 | 100.00 | 100.00 | 36.52 | 84.83 | 100.00 | 60.58 | 9.01 |
| GPT2 | 21.08 | 2.22 | 0.42 | 0.01 | 29.86 | 71.11 | 25.39 | 55.17 | 4.97 |
| GPT2.ft[ | 24.20 | 3.47 | 0.47 | 0.12 | 73.46 | 28.51 | 56.65 | 5.61 | |
| Embedding[ | 16.61 | 0.60 | 0.01 | 0.01 | 34.66 | 83.32 | 23.77 | 51.20 | 4.32 |
| Memory[ | 17.90 | 0.77 | 0.01 | 0.01 | 29.89 | 22.05 | 53.16 | 3.55 | |
| Softmax[ | 20.45 | 1.04 | 0.01 | 0.01 | 25.70 | 71.87 | 25.20 | 55.05 | 4.62 |
| LOT[ | 23.15 | 3.60 | 0.45 | 0.15 | 25.32 | 65.01 | 27.32 | 56.12 | 6.70 |
| 文献[ | 24.58 | 3.92 | 0.67 | 26.01 | 66.61 | 30.49 | 58.75 | ||
| Della[ | 21.79 | 3.21 | 0.22 | 30.61 | 75.26 | 22.96 | 55.82 | 4.00 | |
| Simctg[ | 0.76 | 0.22 | 29.88 | 72.99 | 7.51 | ||||
| 本文模型 | 26.48 | 6.43 | 1.40 | 0.45 | 20.83 | 54.86 | 32.35 | 60.27 | 8.38 |
| 模型 | B-1 | B-2 | B-3 | B-4 | D-1 | D-2 | Cover | BERTScore/% | METEOR |
|---|---|---|---|---|---|---|---|---|---|
| GPT2.ft | 24.20 | 3.47 | 0.47 | 0.12 | 31.29 | 73.46 | 28.51 | 56.65 | 5.61 |
| GPT2.ft +DM | 6.18 | 1.22 | 0.43 | 64.50 | 32.85 | ||||
| GPT2.ft +RM | 27.30 | 25.95 | 32.07 | 60.17 | 8.12 | ||||
| GPT2.ft +AR | 25.21 | 4.49 | 0.85 | 0.19 | 22.29 | 58.52 | 30.56 | 59.84 | 7.93 |
| GPT2.ft +RS | 26.14 | 4.25 | 0.95 | 0.24 | 22.03 | 56.83 | 31.66 | 59.17 | 7.69 |
| 本文模型 | 26.48 | 6.43 | 1.40 | 0.45 | 20.83 | 54.86 | 60.62 | 8.38 |
表5 消融实验中的自动评估结果
Tab. 5 Automatic evaluation results for ablation experiments
| 模型 | B-1 | B-2 | B-3 | B-4 | D-1 | D-2 | Cover | BERTScore/% | METEOR |
|---|---|---|---|---|---|---|---|---|---|
| GPT2.ft | 24.20 | 3.47 | 0.47 | 0.12 | 31.29 | 73.46 | 28.51 | 56.65 | 5.61 |
| GPT2.ft +DM | 6.18 | 1.22 | 0.43 | 64.50 | 32.85 | ||||
| GPT2.ft +RM | 27.30 | 25.95 | 32.07 | 60.17 | 8.12 | ||||
| GPT2.ft +AR | 25.21 | 4.49 | 0.85 | 0.19 | 22.29 | 58.52 | 30.56 | 59.84 | 7.93 |
| GPT2.ft +RS | 26.14 | 4.25 | 0.95 | 0.24 | 22.03 | 56.83 | 31.66 | 59.17 | 7.69 |
| 本文模型 | 26.48 | 6.43 | 1.40 | 0.45 | 20.83 | 54.86 | 60.62 | 8.38 |
| 模型 | 生成结尾 | BERTScore | METEOR |
|---|---|---|---|
| 原文 | 他回国后开始虚心学习,争取早日成为可以抵挡一面的将军。 | 56.32 | 5.95 |
| 本文模型 | 从此,赵括再也不敢随便出兵了,他认为自己的兵力不如别人。 | 64.67 | 9.97 |
| GPT2.ft | 从此,赵国便一直领先着赵国一大截,赵国再也没有丢失过兵书了。 | 61.53 | 7.46 |
| Embedding | 但其后来胡杨而此事被罢而得到了赵弘为人谦明白了什么也没识到就。 | 54.84 | 5.93 |
| Memory | 就这样还总几个学识渊博的深深敬佩地称赞赏下其鬼魂和楚明感谢礼。 | 51.02 | 3.21 |
| Softmax | 最终下令释放了那些能够救活着比赛的人前来救他的人。 | 53.31 | 4.41 |
| LOT | 赵奢死后,没有儿子,就让位于颍川郡的姑臧君主被封为驱车千户。 | 59.73 | 6.82 |
| 文献[ | 赵奢平时最爱读书,赵奢常到赵国拜著名诗人孟浩然为师 | 61.98 | 4.91 |
| Della | 从此,赵国便十分羡慕赵国的爱戴和对自己的精神激励。 | 60.60 | 5.96 |
| Simctg | 从此,赵国便一直领先着赵国近一步,赵国也越发强大了起来。 | 59.66 | 7.09 |
| GPT2 | 十年后,赵括再次登上王位,成为一个统一天下的君主。 | 58.28 | 7.25 |
| ChatGPT3.5 | 自负之心使赵括功败垂成,智者须懂变通。 | 59.26 | 6.47 |
表6 不同模型生成的结尾对比结果
Tab.6 Comparison results of endings generated by different models
| 模型 | 生成结尾 | BERTScore | METEOR |
|---|---|---|---|
| 原文 | 他回国后开始虚心学习,争取早日成为可以抵挡一面的将军。 | 56.32 | 5.95 |
| 本文模型 | 从此,赵括再也不敢随便出兵了,他认为自己的兵力不如别人。 | 64.67 | 9.97 |
| GPT2.ft | 从此,赵国便一直领先着赵国一大截,赵国再也没有丢失过兵书了。 | 61.53 | 7.46 |
| Embedding | 但其后来胡杨而此事被罢而得到了赵弘为人谦明白了什么也没识到就。 | 54.84 | 5.93 |
| Memory | 就这样还总几个学识渊博的深深敬佩地称赞赏下其鬼魂和楚明感谢礼。 | 51.02 | 3.21 |
| Softmax | 最终下令释放了那些能够救活着比赛的人前来救他的人。 | 53.31 | 4.41 |
| LOT | 赵奢死后,没有儿子,就让位于颍川郡的姑臧君主被封为驱车千户。 | 59.73 | 6.82 |
| 文献[ | 赵奢平时最爱读书,赵奢常到赵国拜著名诗人孟浩然为师 | 61.98 | 4.91 |
| Della | 从此,赵国便十分羡慕赵国的爱戴和对自己的精神激励。 | 60.60 | 5.96 |
| Simctg | 从此,赵国便一直领先着赵国近一步,赵国也越发强大了起来。 | 59.66 | 7.09 |
| GPT2 | 十年后,赵括再次登上王位,成为一个统一天下的君主。 | 58.28 | 7.25 |
| ChatGPT3.5 | 自负之心使赵括功败垂成,智者须懂变通。 | 59.26 | 6.47 |
| 指标 | Rate/% | 指标 | Rate/% |
|---|---|---|---|
| BLEU | +39.37 | BERTScore | +8.21 |
| Distinct | -26.08 | METEOR | +53.93 |
| Coverage | +22.62 |
表7 本文模型对不同指标的提升结果
Tab. 7 Enhancements of different indicators by proposed model
| 指标 | Rate/% | 指标 | Rate/% |
|---|---|---|---|
| BLEU | +39.37 | BERTScore | +8.21 |
| Distinct | -26.08 | METEOR | +53.93 |
| Coverage | +22.62 |
| 模型 | 流畅性 | 连贯性 | 顺序 | 因果 | 情感 |
|---|---|---|---|---|---|
| Embedding | 2.53 | 2.61 | 2.31 | 1.78 | 1.88 |
| Memory | 2.15 | 2.03 | 2.26 | 1.70 | 2.11 |
| Softmax | 2.35 | 2.40 | 2.55 | 2.20 | 2.10 |
| Della | 3.28 | 2.78 | |||
| Simctg | 3.60 | 3.02 | 3.10 | 2.55 | |
| LOT | 3.23 | 2.98 | 2.75 | 2.46 | 2.61 |
| 文献[ | 3.31 | 3.05 | 2.86 | 2.42 | 2.81 |
| 本文模型 | 3.22 | 2.86 | 2.72 | 3.04 |
表8 对比实验人工评估分数
Tab. 8 Manual evaluation scores of comparative experiments
| 模型 | 流畅性 | 连贯性 | 顺序 | 因果 | 情感 |
|---|---|---|---|---|---|
| Embedding | 2.53 | 2.61 | 2.31 | 1.78 | 1.88 |
| Memory | 2.15 | 2.03 | 2.26 | 1.70 | 2.11 |
| Softmax | 2.35 | 2.40 | 2.55 | 2.20 | 2.10 |
| Della | 3.28 | 2.78 | |||
| Simctg | 3.60 | 3.02 | 3.10 | 2.55 | |
| LOT | 3.23 | 2.98 | 2.75 | 2.46 | 2.61 |
| 文献[ | 3.31 | 3.05 | 2.86 | 2.42 | 2.81 |
| 本文模型 | 3.22 | 2.86 | 2.72 | 3.04 |
| 模型 | B | D | Cover | BERTScore/% | METEOR |
|---|---|---|---|---|---|
| ChatGPT3.5 | 8.03 | 54.64 | 31.21 | 59.26 | 8.54 |
| 本文模型 | 8.69 | 37.84 | 32.35 | 60.27 | 8.38 |
表9 本文模型与ChatGPT3.5的对比结果
Tab. 9 Comparison results between proposed model and ChatGPT3.5
| 模型 | B | D | Cover | BERTScore/% | METEOR |
|---|---|---|---|---|---|
| ChatGPT3.5 | 8.03 | 54.64 | 31.21 | 59.26 | 8.54 |
| 本文模型 | 8.69 | 37.84 | 32.35 | 60.27 | 8.38 |
| 1 | SHARMA R, ALLEN J, BAKHSHANDEH O, et al. Tackling the story ending biases in the story cloze test [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2018:752-757. |
| 2 | LI Z, DING X, LIU T. Generating reasonable and diversified story ending using sequence to sequence model with adversarial training[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 1033-1043. |
| 3 | ZHAO Y, LIU L, LIU C, et al. From plots to endings: a reinforced pointer generator for story ending generation [EB/OL]. (2019-01-11) [2023-10-26]. . |
| 4 | GUPTA P, KUMAR V B, BHUTANI M, et al. WriterForcing: generating more interesting story endings [EB/OL]. [2023-06-23]. . |
| 5 | MORI Y, YAMANE H, MUKUTA Y, et al. Toward a better story end: collecting human evaluation with reasons [C]// Proceedings of the 12th International Conference on Natural Language Generation. Stroudsburg: ACL, 2019: 383-390. |
| 6 | TU L, DING X, YU D, et al. Generating diverse story continuations with controllable semantics [C]// Proceedings of the 3rd Workshop on Neural Generation and Translation. Stroudsburg: ACL, 2019: 44-58. |
| 7 | GUAN J, WANG Y, HUANG M. Story ending generation with incremental encoding and commonsense knowledge [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 6473-6480. |
| 8 | XU P, PATWARY M, SHOEYBI M, et al. MEGATRON-CNTRL: controllable story generation with external knowledge using large-scale language models [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg:ACL, 2020: 2831-2845. |
| 9 | WANG J, ZOU B, LI Z, et al. Incorporating commonsense knowledge into story ending generation via heterogeneous graph networks [EB/OL]. [2023-10-26]. . |
| 10 | MO L, WEI J, HUANG Q, et al. Incorporating sentimental trend into gated mechanism based transformer network for story ending generation [J]. Neurocomputing, 2021, 453: 453-464. |
| 11 | LUO F, DAI D, YANG P, et al. Learning to control the fine-grained sentiment for story ending generation [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 6020-6026. |
| 12 | HUANG Q B, HUANG C, MO L, et al. IgSEG: image-guided story ending generation [C]// Proceedings of the 2021 Findings of the Association for Computational Linguistics. Stroudsburg: ACL, 2021: 3114-3123. |
| 13 | XIE Y, HU Y, XING L, et al. CLSEG: contrastive learning of story ending generation [EB/OL]. (2022-02-18) [2023-10-26]. . |
| 14 | GUAN J, HUANG F, ZHAO Z, et al. A knowledge-enhanced pretraining model for commonsense story generation[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 93-108. |
| 15 | ARORA S, KHANDEPARKAR H, KHODAK M, et al. A theoretical analysis of contrastive unsupervised representation learning [EB/OL]. (2019-02-25) [2023-10-06]. . |
| 16 | SU Y, LAN T, WANG Y, et al. A contrastive framework for neural text generation [EB/OL]. (2022-02-13) [2023-04-13]. . |
| 17 | HU J, YI X, LI W, et al. Fuse it more deeply! A variational transformer with layer-wise latent variable inference for text generation [EB/OL]. [2023-01-22]. . |
| 18 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. (2017-06-12) [2023-08-11]. . |
| 19 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2023-05-14]. . |
| 20 | GUAN J, FENG Z, CHEN Y, et al. LOT: a story-centric benchmark for evaluating Chinese long text understanding and generation [J]. Transactions of the Association for Computational Linguistics, 2022, 10: 434-451. |
| 21 | CUI Y, LIU T, CHEN Z, et al. Consensus attention-based neural networks for Chinese reading comprehension [EB/OL]. (2016-07-08) [2023-03-03]. . |
| 22 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg: ACL,2002: 311-318. |
| 23 | LI J, GALLEY M, BROKETT C, et al. A diversity-promoting objective function for neural conversation models [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg:ACL, 2016: 110-119. |
| 24 | BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]// Proceedings of the 2005 ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg: ACL, 2005: 65-72. |
| 25 | ZHANG T, KISHORE V, WU F, et al. BERTScore: evaluating text generation with BERT[EB/OL]. (2019-04-21) [2023-02-29]. . |
| 26 | LI C, GAO X, LI Y, et al. Optimus: organizing sentences via pre-trained modeling of a latent space [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 4678-4699. |
| 27 | FANG L, ZENG T, LIU C, et al. Transformer-based conditional variational autoencoder for controllable story generation [EB/OL]. [2023-09-22]. . |
| 28 | WANG T, WAN X. T-CVAE:Transformer-based conditioned variational autoencoder for story completion [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2019:5233-5239. |
| 29 | HUANG H, TANG C, LOAKMAN T, et al. Improving Chinese story generation via awareness of syntactic dependencies and semantics [C]// Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 178-185. |
| [1] | 李晨阳, 张龙, 郑秋生, 钱少华. 基于扩散序列的多元可控文本生成[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2414-2420. |
| [2] | 张全梅, 黄润萍, 滕飞, 张海波, 周南. 融合异构信息的自动国际疾病分类编码方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2476-2482. |
| [3] | 陆潜慧, 张羽, 王梦灵, 吴庭伟, 单玉忠. 基于改进循环池化网络的核电装备质量文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2034-2040. |
| [4] | 于右任, 张仰森, 蒋玉茹, 黄改娟. 融合多粒度语言知识与层级信息的中文命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1706-1712. |
| [5] | 刘耀, 李雨萌, 宋苗苗. 基于业务流程的认知图谱[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1699-1705. |
| [6] | 高龙涛, 李娜娜. 基于方面感知注意力增强的方面情感三元组抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1049-1057. |
| [7] | 杨先凤, 汤依磊, 李自强. 基于交替注意力机制和图卷积网络的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1058-1064. |
| [8] | 杨保山, 杨智, 陈性元, 韩冰, 杜学绘. Android应用敏感行为与隐私政策一致性分析[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 788-796. |
| [9] | 王楷天, 叶青, 程春雷. 基于异构图表示的中医电子病历分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 411-417. |
| [10] | 姜雨杉, 张仰森. 大语言模型驱动的立场感知事实核查[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3067-3073. |
| [11] | 冯程皓, 谢振平, 丁博文. 中文文本纠错软件测试用例的选择生成方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 101-112. |
| [12] | 周晓敏, 滕飞, 张艺. 基于元网络的自动国际疾病分类编码模型[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2721-2726. |
| [13] | 张心月, 刘蓉, 魏驰宇, 方可. 融合提示知识的方面级情感分析方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2753-2759. |
| [14] | 姜钧舰, 刘达维, 刘逸凡, 任酉贵, 赵志滨. 基于孪生网络的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2325-2329. |
| [15] | 陈克正, 郭晓然, 钟勇, 李振平. 基于负训练和迁移学习的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2426-2430. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||