


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (11): 3629-3638.DOI: 10.11772/j.issn.1001-9081.2023111712
余家宸1,2, 杨晔1,2( )
)
收稿日期:2023-12-11
修回日期:2024-03-09
接受日期:2024-03-14
发布日期:2024-03-22
出版日期:2024-11-10
通讯作者:
杨晔
作者简介:余家宸(1998—),男,浙江舟山人,硕士,CCF会员,主要研究方向:深度强化学习算法、机器人智能控制
基金资助:
Jiachen YU1,2, Ye YANG1,2()
Received:2023-12-11
Revised:2024-03-09
Accepted:2024-03-14
Online:2024-03-22
Published:2024-11-10
Contact:
Ye YANG
About author:YU Jiachen, born in 1998, M. S. His research interests include deep reinforcement learning algorithms, intelligent robot control.
Supported by:摘要:
为应对传统深度强化学习(DRL)算法在处理复杂场景,特别是在不规则物体抓取和软体机械臂应用中算法稳定性和学习率较差的问题,提出一种基于裁剪近端策略优化(CPPO)算法的软体机械臂控制策略。通过引入裁剪函数,该算法优化了近端策略优化(PPO)算法的性能,提升了它在高维状态空间的稳定性和学习效率。首先定义了软体机械臂的状态空间和动作空间,并设计了模仿八爪鱼触手的软体机械臂模型;其次利用Matlab的SoRoSim (Soft Robot Simulation)工具箱进行建模,同时定义了结合连续和稀疏函数的环境奖励函数;最后构建了基于Matlab的仿真平台,通过Python脚本和滤波器对不规则物体图像进行预处理,并利用Redis缓存高效传输处理后的轮廓数据至仿真平台。与TRPO (Trust Region Policy Optimization)和SAC (Soft Actor-Critic)算法的对比实验结果表明,CPPO算法在软体机械臂抓取不规则物体任务中达到了86.3%的成功率,比TRPO算法高出了3.6个百分点。这说明CPPO算法可以应用于软体机械臂控制,可在非结构化环境下为软体机械臂在复杂抓取任务中的应用提供重要参考。
中图分类号:
余家宸, 杨晔. 基于裁剪近端策略优化算法的软机械臂不规则物体抓取[J]. 计算机应用, 2024, 44(11): 3629-3638.
Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm[J]. Journal of Computer Applications, 2024, 44(11): 3629-3638.
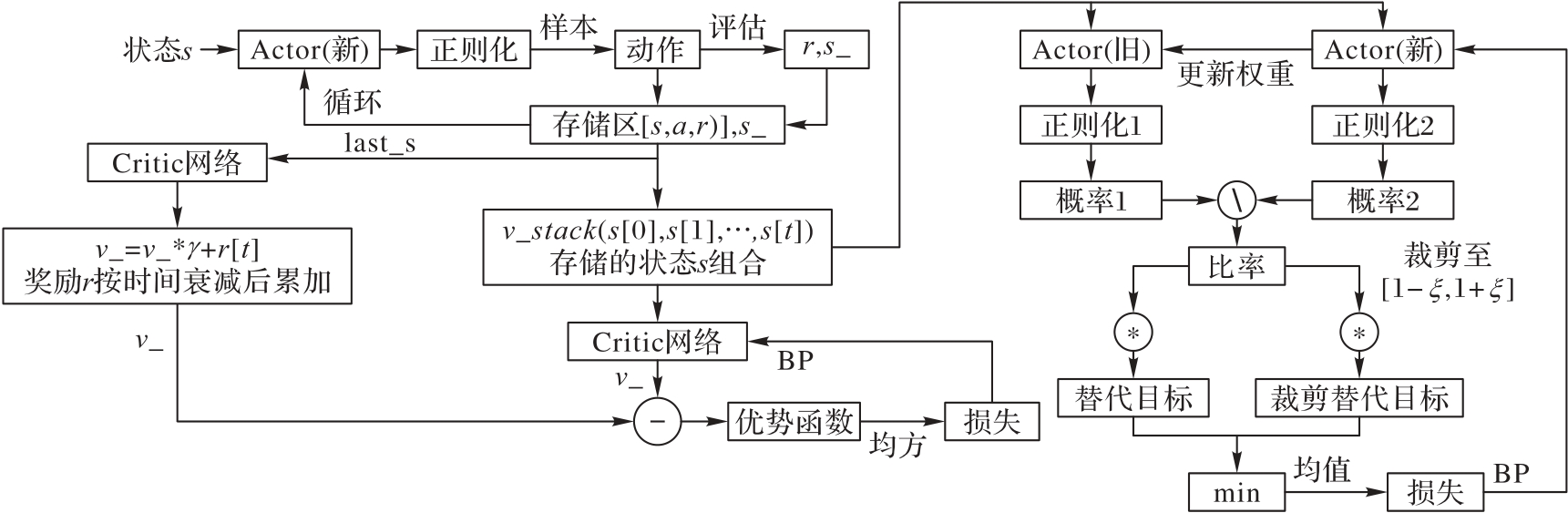
图1 CPPO算法流程
Fig. 1 Process of CPPO algorithm
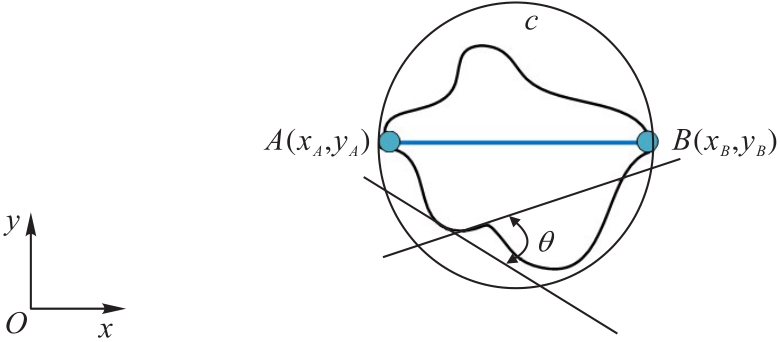
图2 不规则物体截面在直角坐标系中的表示
Fig. 2 Representation of irregular object cross-section in Cartesian coordinate system
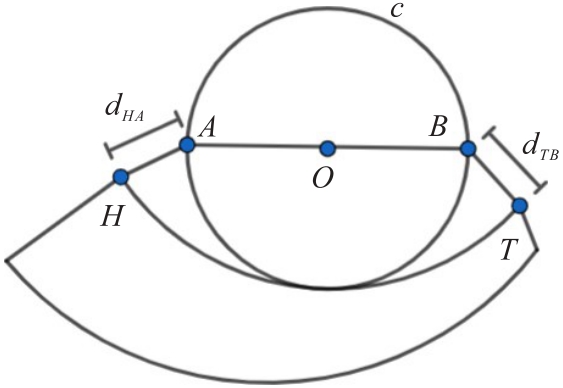
图3 规则物体成功抓取的判定示意图
Fig. 3 Determination diagram of successful grasping of irregular objects
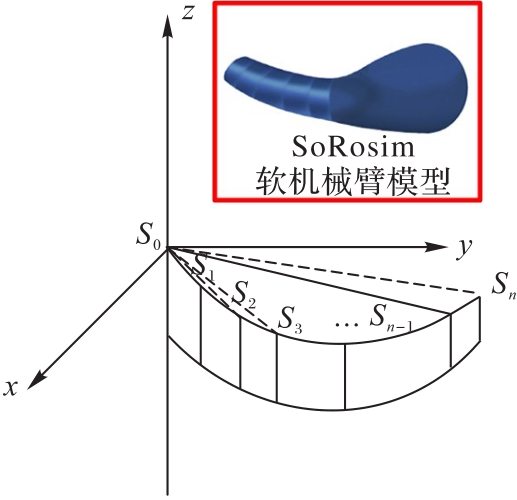
图4 软机械臂状态空间设计示意图
Fig. 4 Schematic diagram of state space design of soft robotic arm
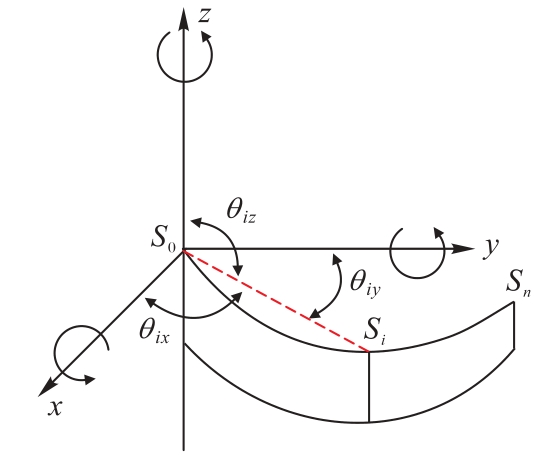
图5 关节点转动方向角的示意图
Fig. 5 Schematic diagram of rotation direction angle of joint point
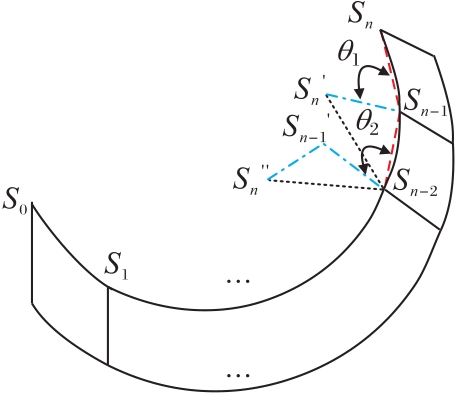
图6 第二类动作(关节点旋转)的示意图
Fig. 6 Schematic diagram of the second type of action (joint point rotation)
图7 软机械臂抓取不规则物体实验的总流程
Fig. 7 General flow of soft robotic arm grasping irregular object experiment

图8 不规则物体图像边缘检测示例
Fig. 8 Edge detection examples of irregular object images

图9 目标物体抓取点确定示例
Fig. 9 Examples of target object grasping point determination
| 参数 | 取值 |
|---|---|
| 采样时间 | 1 024个时间步 |
| Actor网络学习率 | 0.1 |
| Critic网络学习率 | 0.1 |
| 奖励折扣因子 | 0.99 |
| 裁剪因子 | 0.2 |
| 迭代周期 | 3 |
| 小批量更新规模 | 16 |
| 最大episode数 | 1 000 |
| 每个episode的最大步长 | 200 |
| 得分平均窗口长度 | 5 |
表1 CPPO算法关键初始参数的设置
Tab. 1 Setting of key initial parameters of CPPO algorithm
| 参数 | 取值 |
|---|---|
| 采样时间 | 1 024个时间步 |
| Actor网络学习率 | 0.1 |
| Critic网络学习率 | 0.1 |
| 奖励折扣因子 | 0.99 |
| 裁剪因子 | 0.2 |
| 迭代周期 | 3 |
| 小批量更新规模 | 16 |
| 最大episode数 | 1 000 |
| 每个episode的最大步长 | 200 |
| 得分平均窗口长度 | 5 |
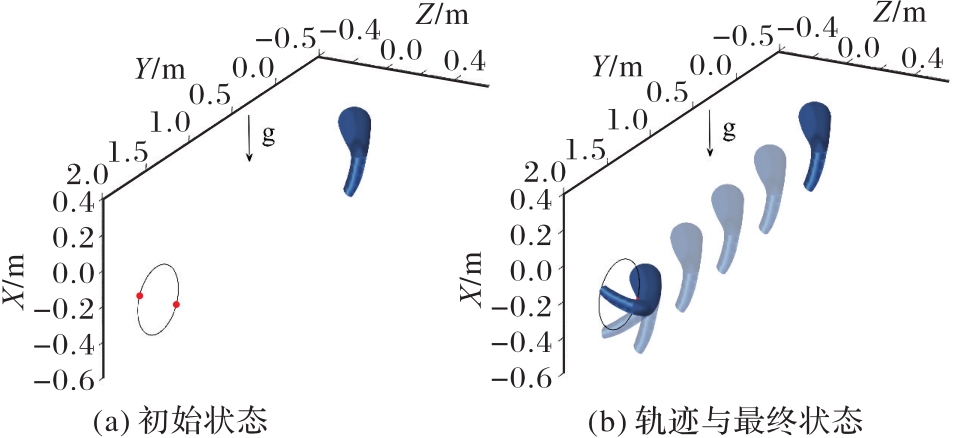
图10 SoRoSim软机械臂仿真环境
Fig. 10 SoRoSim soft robotic arm simulation environment
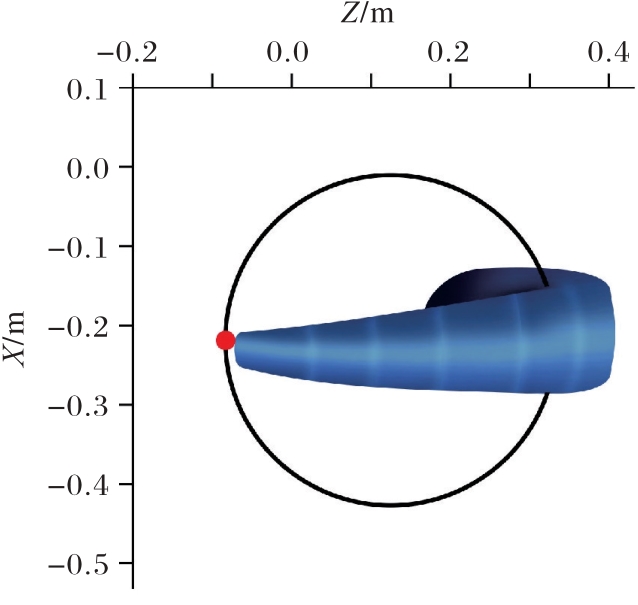
图11 目标物体与软机械臂在X?Z平面的投影
Fig. 11 Projection of target object and soft robotic arm on X?Z plane
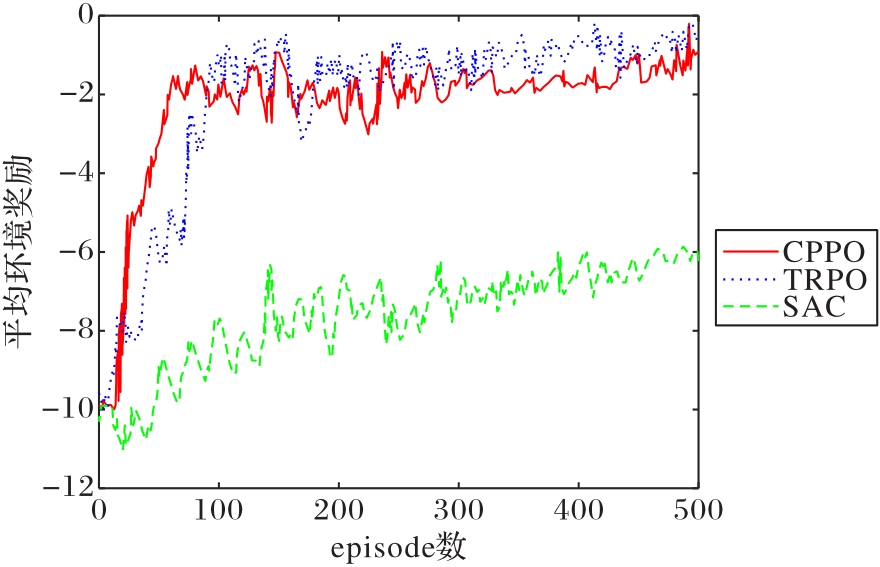
图12 3种算法在500个episode内的平均环境奖励
Fig. 12 Average environmental rewards of three algorithms within 500 episodes
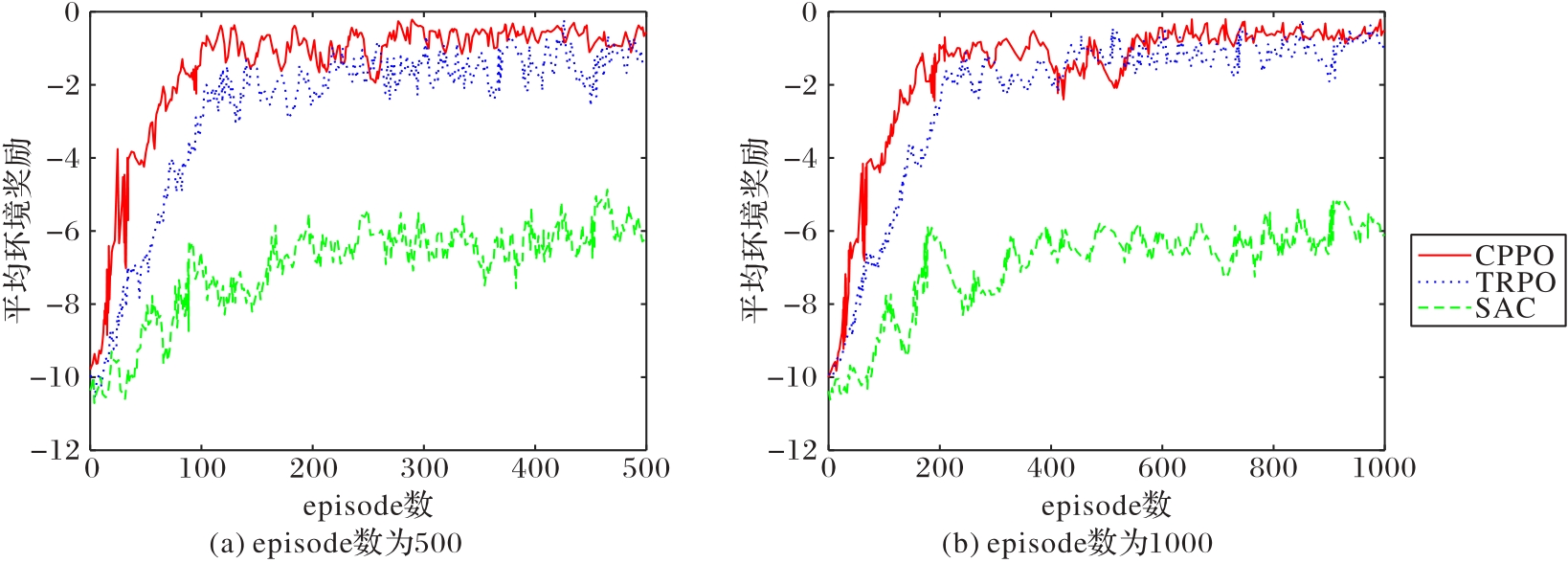
图13 小批量更新规模为128时3种算法的性能比较
Fig. 13 Performance comparison of three algorithms when mini-batch update size is 128
| 算法 | 小批量更新 规模 | 最大episode数 | 平均 奖励 | 平均奖励极限 近似值 | 平均 奖励 方差 | 训练 时间/h |
|---|---|---|---|---|---|---|
| CPPO | 16 | 500 | -2.039 9 | -0.5 | 1.384 6 | 0.90 |
| TRPO | 16 | 500 | -2.142 7 | -0.8 | 1.397 1 | 0.92 |
| SAC | 16 | 500 | -7.126 7 | -6.2 | 1.847 2 | 0.99 |
| CPPO | 128 | 500 | -1.731 9 | -0.4 | 1.212 1 | 0.52 |
| TRPO | 128 | 500 | -1.801 3 | -0.9 | 1.408 7 | 0.58 |
| SAC | 128 | 500 | -7.318 6 | -6.3 | 2.249 5 | 0.62 |
| CPPO | 128 | 1 000 | -1.643 8 | -0.3 | 1.206 4 | 0.92 |
| TRPO | 128 | 1 000 | -1.879 7 | -0.6 | 1.417 5 | 0.98 |
| SAC | 128 | 1 000 | -6.038 9 | -6.0 | 1.792 2 | 1.02 |
表2 不同实验条件下3种强化学习算法的训练结果
Tab.2 Training results of three reinforcement learning algorithms under various experimental conditions
| 算法 | 小批量更新 规模 | 最大episode数 | 平均 奖励 | 平均奖励极限 近似值 | 平均 奖励 方差 | 训练 时间/h |
|---|---|---|---|---|---|---|
| CPPO | 16 | 500 | -2.039 9 | -0.5 | 1.384 6 | 0.90 |
| TRPO | 16 | 500 | -2.142 7 | -0.8 | 1.397 1 | 0.92 |
| SAC | 16 | 500 | -7.126 7 | -6.2 | 1.847 2 | 0.99 |
| CPPO | 128 | 500 | -1.731 9 | -0.4 | 1.212 1 | 0.52 |
| TRPO | 128 | 500 | -1.801 3 | -0.9 | 1.408 7 | 0.58 |
| SAC | 128 | 500 | -7.318 6 | -6.3 | 2.249 5 | 0.62 |
| CPPO | 128 | 1 000 | -1.643 8 | -0.3 | 1.206 4 | 0.92 |
| TRPO | 128 | 1 000 | -1.879 7 | -0.6 | 1.417 5 | 0.98 |
| SAC | 128 | 1 000 | -6.038 9 | -6.0 | 1.792 2 | 1.02 |
| 算法 | 抓取成功数 | 抓取成功率/% |
|---|---|---|
| CPPO | 259 | 86.3 |
| TRPO | 248 | 82.7 |
| SAC | 220 | 73.3 |
表3 3种强化学习算法的抓取成功率
Tab.3 Grasping success rates of three reinforcement learning algorithms
| 算法 | 抓取成功数 | 抓取成功率/% |
|---|---|---|
| CPPO | 259 | 86.3 |
| TRPO | 248 | 82.7 |
| SAC | 220 | 73.3 |
| 1 | GU S, HOLLY E, LILLICRAP T, et al. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 3389-3396. |
| 2 | RAJESWARAN A, KUMAR V, GUPTA A, et al. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations[EB/OL]. [2024-03-05].. |
| 3 | DEISENROTH M P, NEUMANN G, PETERS J. A survey on policy search for robotics[J]. Foundations and Trends in Robotics, 2013, 2(1/2): 1-142. |
| 4 | DEISENROTH M P, RASMUSSEN C E. PILCO: a model-based and data-efficient approach to policy search[C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011: 465-472. |
| 5 | LEVINE S, ABBEEL P. Learning neural network policies with guided policy search under unknown dynamics[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2014: 1071-1079. |
| 6 | CHEBOTAR Y, KALAKRISHNAN M, YAHYA A, et al. Path integral guided policy search[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 3381-3388. |
| 7 | LEVINE S, PASTOR P, KRIZHEVSKY A, et al. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection[J]. The International Journal of Robotics Research, 2018, 37(4/5): 421-436. |
| 8 | KALASHNIKOV D, IRPAN A, PASTOR P, et al. Scalable deep reinforcement learning for vision-based robotic manipulation[C]// Proceedings of the 2nd Conference on Robot Learning. New York: JMLR.org, 2018: 651-673. |
| 9 | QUILLEN D, JANG E, NACHUM O, et al. Deep reinforcement learning for vision-based robotic grasping: a simulated comparative evaluation of off-policy methods[C]// Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2018: 6284-6291. |
| 10 | MARTÍN-MARTÍN R, LEE M A, GARDNER R, et al. Variable impedance control in end-effector space: an action space for reinforcement learning in contact-rich tasks[C]// Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2019: 1010-1017. |
| 11 | LENZ I, LEE H, SAXENA A. Deep learning for detecting robotic grasps[J]. The International Journal of Robotics Research, 2015, 34(4/5): 705-724. |
| 12 | VIERECK U, TEN PAS A, SAENKO K, et al. Learning a visuomotor controller for real world robotic grasping using simulated depth images[C]// Proceedings of the 1st Annual Conference on Robot Learning. New York: JMLR.org, 2017: 291-300. |
| 13 | SONG S, ZENG A, LEE J, et al. Grasping in the wild: learning 6DoF closed-loop grasping from low-cost demonstrations[J]. IEEE Robotics and Automation Letters, 2020, 5(3): 4978-4985. |
| 14 | SMITH L, KEW J C, PENG X B, et al. Legged robots that keep on learning: fine-tuning locomotion policies in the real world[C]// Proceedings of the 2022 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2022: 1593-1599. |
| 15 | TRIVEDI D, LOTFI A, RAHN C D. Geometrically exact models for soft robotic manipulators[J]. IEEE Transactions on Robotics, 2008, 24(4): 773-780. |
| 16 | PAI D K. STRANDS: interactive simulation of thin solids using Cosserat models[J]. Computer Graphics Forum, 2002, 21(3): 347-352. |
| 17 | RENDA F, GIORGIO-SERCHI F, BOYER F, et al. Modelling cephalopod-inspired pulsed-jet locomotion for underwater soft robots[J]. Bioinspiration and Biomimetics, 2015, 10(5): No.055005. |
| 18 | RENDA F, GIORGIO-SERCHI F, BOYER F, et al. A unified multi-soft-body dynamic model for underwater soft robots[J]. The International Journal of Robotics Research, 2018, 37(6): 648-666. |
| 19 | DAS R, BABU S P M, VISENTIN F, et al. An earthworm-like modular soft robot for locomotion in multi-terrain environments[J]. Scientific Reports volume, 2023, 13: No.1571. |
| 20 | WANG X, KANG H, ZHOU H, et al. Development and evaluation of a robust soft robotic gripper for apple harvesting[J]. Computers and Electronics in Agriculture, 2023, 204: No.107552. |
| 21 | YOON Y, PARK H, LEE J, et al. Bioinspired untethered soft robot with pumpless phase change soft actuators by bidirectional thermoelectrics[J]. Chemical Engineering Journal, 2023, 451(Pt 3): No.138794. |
| 22 | DURIEZ C. Control of elastic soft robots based on real-time finite element method[C]// Proceedings of the 2013 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2013: 3982-3987. |
| 23 | BARTLETT N W, TOLLEY M T, OVERVELDE J T B, et al. A 3D-printed, functionally graded soft robot powered by combustion[J]. Science, 2015, 349(6244):161-165. |
| 24 | POLYGERINOS P, WANG Z, OVERVELDE J T B, et al. Modeling of soft fiber-reinforced bending actuators[J]. IEEE Transactions on Robotics, 2015, 31(3): 778-789. |
| 25 | THURUTHEL T G, FALOTICO E, MANTI M, et al. Learning closed loop kinematic controllers for continuum manipulators in unstructured environments[J]. Soft Robotics, 2017, 4(3):285-296. |
| 26 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2024-01-22].. |
| 27 | HASEGAWA S, YAMAGUCHI N, OKADA K, et al. Online acquisition of close-range proximity sensor models for precise object grasping and verification[J]. IEEE Robotics and Automation Letters, 2020, 5(4): 5993-6000. |
| 28 | VECERIK M, HESTER T, SCHOLZ J, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards[EB/OL].[2024-04-11].. |
| 29 | OneOneLiu, GGCNN Cornell grasp dataset[DS/OL]. [2023-12-05].. |
| [1] | 周毅, 高华, 田永谌. 基于裁剪优化和策略指导的近端策略优化算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2334-2341. |
| [2] | 马天, 席润韬, 吕佳豪, 曾奕杰, 杨嘉怡, 张杰慧. 基于深度强化学习的移动机器人三维路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2055-2064. |
| [3] | 赵晓焱, 韩威, 张俊娜, 袁培燕. 基于异步深度强化学习的车联网协作卸载策略[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1501-1510. |
| [4] | 唐睿, 庞川林, 张睿智, 刘川, 岳士博. D2D通信增强的蜂窝网络中基于DDPG的资源分配[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1562-1569. |
| [5] | 秦鑫彤, 宋政育, 侯天为, 王飞越, 孙昕, 黎伟. 基于自适应p持续的移动自组网信道接入和资源分配算法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 863-868. |
| [6] | 邓辅秦, 官桧锋, 谭朝恩, 付兰慧, 王宏民, 林天麟, 张建民. 基于请求与应答通信机制和局部注意力机制的多机器人强化学习路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 432-438. |
| [7] | 李源潮, 陶重犇, 王琛. 基于最大熵深度强化学习的双足机器人步态控制方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 445-451. |
| [8] | 龙杰, 谢良, 徐海蛟. 集成的深度强化学习投资组合模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 300-310. |
| [9] | 王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2636-2643. |
| [10] | 王子腾, 于亚新, 夏子芳, 乔佳琪. 融合好奇心和策略蒸馏的稀疏奖励探索机制[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2082-2090. |
| [11] | 方和平, 刘曙光, 冉泳屹, 钟坤华. 基于深度强化学习的多数据中心一体化调度优化[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1884-1892. |
| [12] | 李校林, 江雨桑. 无人机辅助移动边缘计算中的任务卸载算法[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1893-1899. |
| [13] | 黄晓辉, 杨凯铭, 凌嘉壕. 基于共享注意力的多智能体强化学习订单派送[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1620-1624. |
| [14] | 曹腾飞, 刘延亮, 王晓英. 基于改进深度强化学习的边缘计算服务卸载算法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1543-1550. |
| [15] | 丁正凯, 傅启明, 陈建平, 陆悠, 吴宏杰, 方能炜, 邢镔. 结合注意力机制与深度强化学习的超短期光伏功率预测[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1647-1654. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||