


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (7): 2056-2069.DOI: 10.11772/j.issn.1001-9081.2024070952
• CCF第39届中国计算机应用大会 (CCF NCCA 2024) • 上一篇 下一篇
代震龙, 韩萌( ), 杨文艳, 朱诗能, 杨书蓉
), 杨文艳, 朱诗能, 杨书蓉
收稿日期:2024-07-09
修回日期:2024-09-25
接受日期:2024-10-09
发布日期:2025-07-10
出版日期:2025-07-10
通讯作者:
韩萌
作者简介:代震龙(2000—),男,山西运城人,硕士研究生,CCF会员,主要研究方向:大数据挖掘基金资助:
Zhenlong DAI, Meng HAN(), Wenyan YANG, Shineng ZHU, Shurong YANG
Received:2024-07-09
Revised:2024-09-25
Accepted:2024-10-09
Online:2025-07-10
Published:2025-07-10
Contact:
Meng HAN
About author:DAI Zhenlong, born in 2000, M. S. candidate. His research interests include big data mining.Supported by:摘要:
序列模式挖掘(SPM)旨在从数据库中发现有趣的模式或规律,从而为用户决策提供支持与指导。近年来,对SPM相关算法的研究日益深入。随着大规模数据的出现,已经提出许多适用于并行环境的序列算法。因此,对现有的串并行序列挖掘算法进行综述。首先,对于序列模式串行挖掘算法进行结构化的分类,即依据算法采用的数据结构将算法划分为树结构、列表结构和链式结构等,全面总结不同结构的优势与不足,并详细归纳各算法的优缺点;其次,对于序列模式并行挖掘算法,首次根据存储结构的不同特点对现有的分布式框架进行分类,分析不同分布式框架的优缺点,并依据框架对并行算法进行介绍与分析;最后,针对现有SPM算法的不足,讨论下一步的研究方向。
中图分类号:
代震龙, 韩萌, 杨文艳, 朱诗能, 杨书蓉. 序列模式挖掘综述[J]. 计算机应用, 2025, 45(7): 2056-2069.
Zhenlong DAI, Meng HAN, Wenyan YANG, Shineng ZHU, Shurong YANG. Survey of sequential pattern mining[J]. Journal of Computer Applications, 2025, 45(7): 2056-2069.
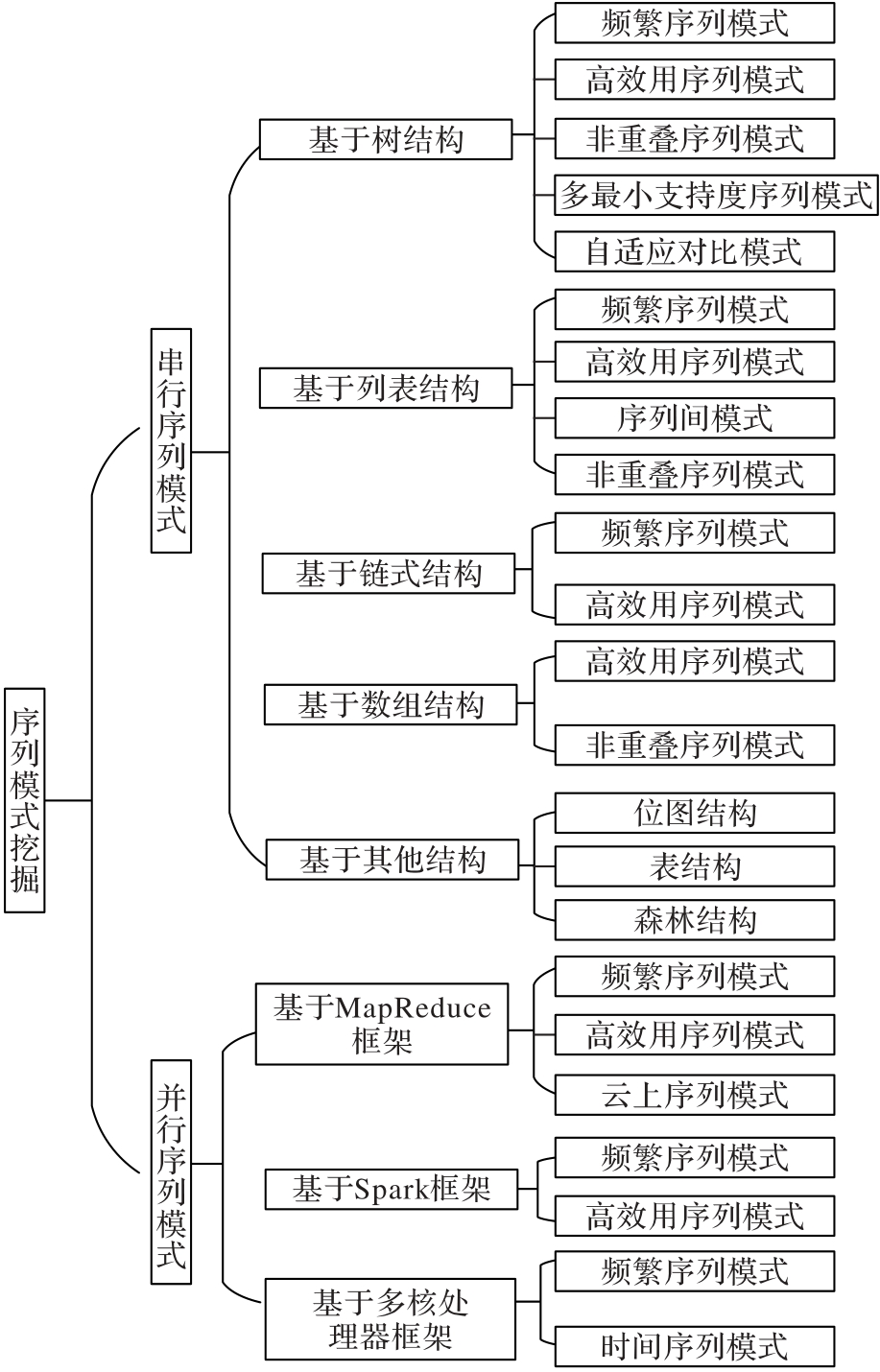
图1 总体框架
Fig. 1 Overall framework
| 序列 | |
|---|---|
表1 序列数据库示例
Tab. 1 Example of sequential database
| 序列 | |
|---|---|
| 定量序列 | |
|---|---|
表2 定量序列数据库示例
Tab. 2 Example of quantitative sequential database
| 定量序列 | |
|---|---|
| 项 | a | b | c | d | e | f | g |
|---|---|---|---|---|---|---|---|
| 价值 | 5 | 2 | 4 | 2 | 3 | 1 | 3 |
表3 外部效用表
Tab. 3 External utility table
| 项 | a | b | c | d | e | f | g |
|---|---|---|---|---|---|---|---|
| 价值 | 5 | 2 | 4 | 2 | 3 | 1 | 3 |
| 符号 | 说明 |
|---|---|
| SPM | 序列模式挖掘 |
| HUSP | 高效用序列模式 |
| SDB Minsup | 序列数据库最小支持阈值 |
| Minutil | 最小效用阈值 |
| LS-tree | 字典序列树 |
| S-step | 序列扩展序列 |
| I-step | 项集扩展序列 |
| Prefix-tree | 前缀树 |
| LQS-tree | 字典Q-序列树 |
| SWU | 序列加权效用 |
| Top-k | 挖掘前k个最频繁的模式 |
表4 符号说明
Tab. 4 Symbol explanation
| 符号 | 说明 |
|---|---|
| SPM | 序列模式挖掘 |
| HUSP | 高效用序列模式 |
| SDB Minsup | 序列数据库最小支持阈值 |
| Minutil | 最小效用阈值 |
| LS-tree | 字典序列树 |
| S-step | 序列扩展序列 |
| I-step | 项集扩展序列 |
| Prefix-tree | 前缀树 |
| LQS-tree | 字典Q-序列树 |
| SWU | 序列加权效用 |
| Top-k | 挖掘前k个最频繁的模式 |
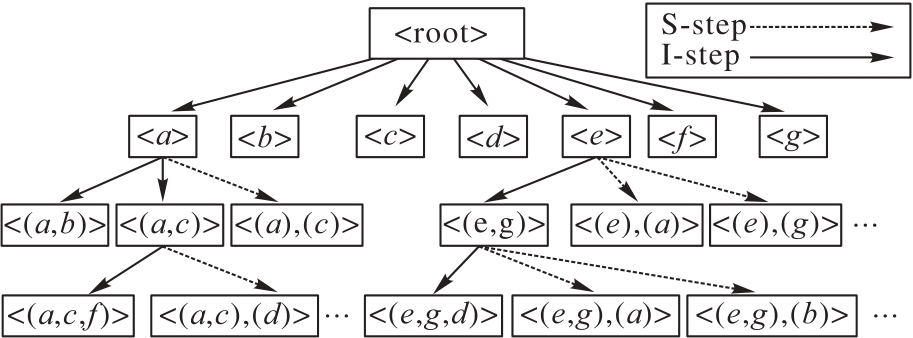
图2 LS-tree结构
Fig. 2 Structure of LS-tree
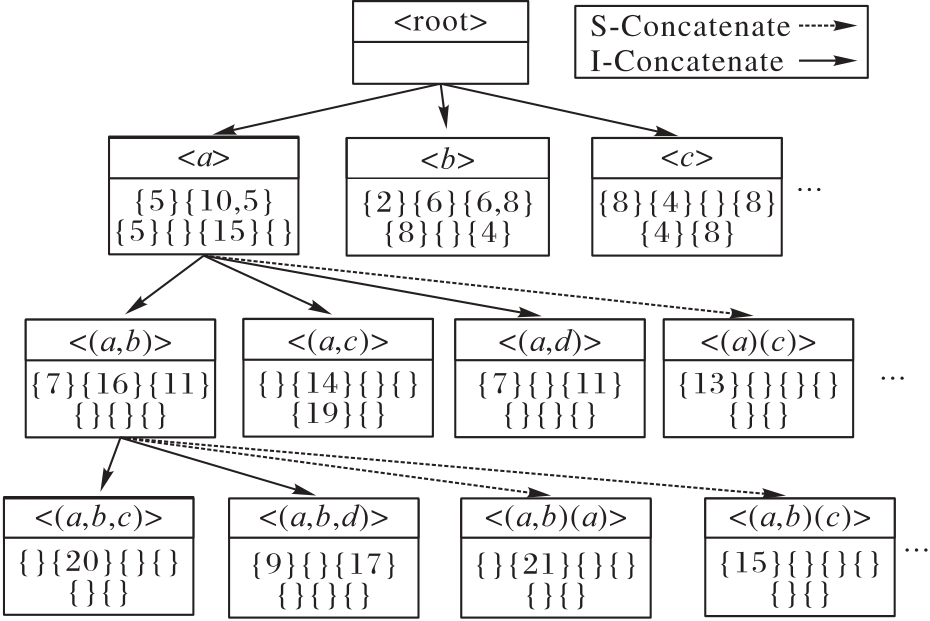
图3 LQS-tree结构
Fig. 3 Structure of LQS-tree
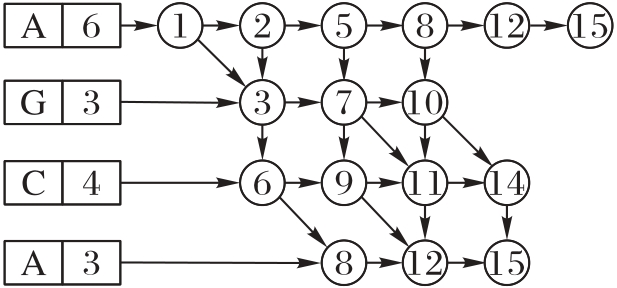
图4 Nettree结构
Fig. 4 Structure of Nettree
| 序列 | ||||||
|---|---|---|---|---|---|---|
| S1 | 1 | 1 | 1 | 1,3,4 | 1 | |
| S2 | 2 | 1 | 2 | 3 | 2 | 2 |
| S3 | 3 | 2 | 3 | 3 | 3 | |
| S4 | 4 | 2,4 | 4 | 4 | 2 | |
| S5 | 5 | 3 | 5 | 1,3 | 5 | 2,4 |
| S6 | 6 | 1 | 6 | 6 | 2 | |
表5 垂直序列数据库表示
Tab. 5 Representation of vertical sequential database
| 序列 | ||||||
|---|---|---|---|---|---|---|
| S1 | 1 | 1 | 1 | 1,3,4 | 1 | |
| S2 | 2 | 1 | 2 | 3 | 2 | 2 |
| S3 | 3 | 2 | 3 | 3 | 3 | |
| S4 | 4 | 2,4 | 4 | 4 | 2 | |
| S5 | 5 | 3 | 5 | 1,3 | 5 | 2,4 |
| S6 | 6 | 1 | 6 | 6 | 2 | |
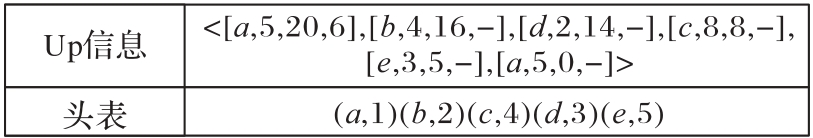
图5 UL-list结构
Fig. 5 Structure of UL-list
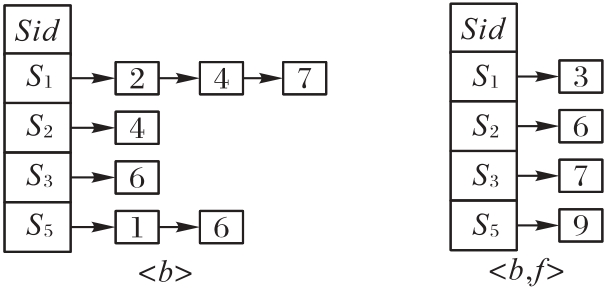
图6 序列链结构
Fig. 6 Structure of sequential chain
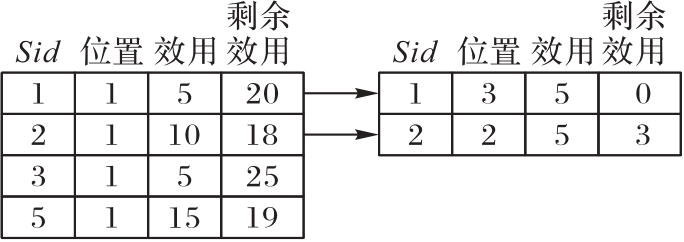
图7 效用链结构
Fig. 7 Structure of utility chain
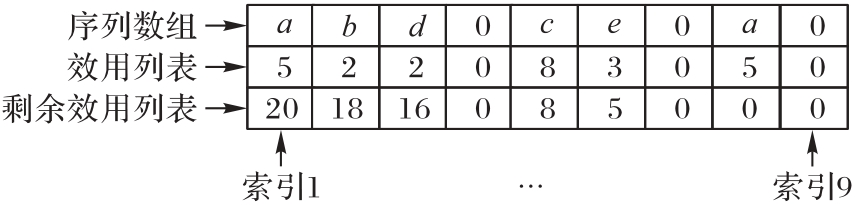
图8 数组结构
Fig. 8 Structure of array
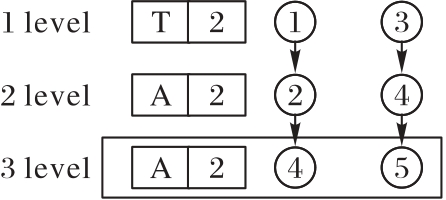
图9 单分支网络及其数组结构
Fig. 9 Structure of single-branch network and its array
| 算法 | 算法采用的结构 | 对比算法 | 优点 | 缺点 | 剪枝策略 | 发布年份 |
|---|---|---|---|---|---|---|
| Tree-miner | SP-tree | CM-SPADE、 CM-SPAM | 在处理动态数据库和基于滑动窗口的交互式挖掘问题方面具有优势 | 需要内存保存树结构与剪枝策略所用的共存项表,内存使用较多 | 基于共存项表的修剪、基于启发式列表的修剪 | 2020 |
| WSPM_PreTree | Prefix-tree | SPMW | 对稀疏数据集WSPM_PreTree有更好的时空效果 | 对于密集数据集算法使用的内存更多 | — | 2023 |
| nSP-DS | Prefix-tree | — | 具有良好的可扩展性 | 只适用于数据流中元素为1-size的序列 | 向下闭包 | 2023 |
| USpan | LQS-tree效用矩阵 | Prefixspan | 首次提出了LQS-tree结构,并首次提出了序列加权效用的概念 | 采用矩阵结构可能消耗较多内存 | 宽度剪枝与深度剪枝 | 2012 |
| HUSpan-MMU | LQS-tree | HUSpan-MMU | 建立了序列的多重最小效用 | 不适合处理较大数据集 | SPU、SWU | 2018 |
| PHUSPM | LQS-tree | Uspan | 定义了周期高效用序列模式 | 不能挖掘并行周期高效用序列模式 | SWU | 2017 |
| U-HUSPM | LS-tree | U-HUSPM | 设计了高效用概率序列模式挖掘框架 | 不能挖掘并行高效用概率序列模式 | SWU、HSWUPDC | 2019 |
| HUSP-Miner | ItemUtilLists、 HUSP-tree | USpan | 只需扫描一次数据库 | 需要为HUSP-tree非根节点设计额外字段 | TSWU、SFU | 2017 |
| NOSEP | Nettree | gd-DSPMiner | 首次采用Nettree结构挖掘非重叠序列模式 | 用户需要指定模式的间隙 | — | 2018 |
| TNOSP | Nettree | NOSTOPK | 可以挖掘所有符合条件的非重叠序列模式 | 在流数据集中还未能实现 | QMSP | 2023 |
| HANP-Miner | Nettree | NOSEP | 推导了一种基于平均效用上界的策略,并将它与模式连接策略结合起来生成候选模式 | 必须反复扫描SDB,算法效率不高 | Apriori | 2021 |
| NetBack | Nettree | INSGrow | 采用回溯策略迭代搜索最左孩子方式计算无重叠最小出现 | Nettree结构的创建过程较为复杂 | — | 2021 |
| NetNMSP | Nettree | NOSEP | 采用模式连接策略生成候选模式,并采用筛选方法查找频繁模式 | 不能处理大数据 | Apriori | 2022 |
| TALENT | Nettree | NOSEPta | 算法性能随着查询序列长度的增加和有效模式的减少而优化 | 当项目数量较少时,其BFS无法过滤大量待扩展的项目 | SPRP、IPRP | 2023 |
| SCP-Miner | Nettree | NOSEP | 不需要频繁阈值和不频繁阈值,比竞争算法更有效 | 为了更好的性能,需要选择最优参数 | Zero、Less | 2022 |
| OPP-Miner | Prefix-tree | FIM-SW | 采用过滤和验证策略计算支持度,并采用模式融合策略生成候选模式 | 不能进行多维数据挖掘 | — | 2023 |
| CUP | pseudo-IDList、 data IDList | SPAM、 CM-SPADE、 PrefixSpan | 通常在大型数据库上内存效率更高 | 直接进行序列模式挖掘并不能完全工作,并且可能产生错误的结果 | DUB | 2020 |
| SUI | pseudo-IDList、 data IDList | CM-SPADE、 PrefixSpan | 将pseudo-IDList结构运用到序列模式挖掘中 | data-idlist仍然存在一部分重复信息 | — | 2020 |
| EWSPM | WeightList | IUA、 FWSPM | 设计了2个新的严格上界MWEbound和MSRIWbound | 在大型数据集或非常低的阈值上的内存消耗显著增加 | MWEbound、 MSRIWbound | 2024 |
| HUSP-ULL | UL-list | Uspan、 HUS-span | 适合处理每个序列平均包含元素数多的数据集。 | 需要花费更多时间创建UL-list | LAR、IIP | 2021 |
| ISP-PI | pseudo-IDList | EISP-Miner | Pseudo-IDlist避免在挖掘过程中多次复制重复数据 | 修剪只考虑同一项集或事务中的项 | ISP-IC | 2024 |
| RNP-Miner | Position dictionary | NOSEP-RNP、 SNP-RNP | 提出了无希望项目修剪策略和无希望模式修剪策略 | 需要存储子模式的发生位置,导致内存占用增加 | PUI、PUP | 2023 |
| TCSPM | Sequence chain | CSPMpost | 将目标导向查询的概念集成到连续序列模式挖掘中 | 时间、空间复杂度在最坏情况下较高 | USFP、SCP | 2024 |
| HUS-Span | utility-chain | TUS SPAN | 开发了2个更紧密的效用上界,PEU和RSU | 在某些情况下,存在内存空间不足的问题 | PEU、RSU | 2016 |
| PUSOM | PUSP | HUS-Span | 提出了一种周期性高效用序列模式挖掘结构 | 可能占用较多内存 | PEU、SWU、MPP | 2018 |
| TKUS | utility-chain | TKHUS-Span | 能快速提高最小效用阈值,并有效地提取top-k HUSPS | 算法不适用于大数据中 | SUR、TDE、EUI | 2021 |
| AHUS-P | array | HUS-span | 采用了并行挖掘策略,可以地共享内存中的并行任务并发现模式 | 在有些小规模数据集上的内存使用率不佳 | PEU、RSU、EUU | 2018 |
| ProUM | utility-array | USpan、 HUS-Span | 利用效用数组数据结构,避免了对原始数据库的多次扫描 | 在合成数据集上,比USpan需要更多的内存 | PUO、PUK | 2020 |
| SNP-Miner | array | SNP-Miner | 使用存储在数组中的不完整网树结构,并对结构进行一次扫描,避免了冗余计算 | 是一种需要生成候选模式的两阶段算法 | — | 2022 |
| FUSP | USeq-Trie | FUSP | 使用USeq-Trie结构存储不确定序列并更新序列的加权期望支持度 | 可能使用较多内存 | expSupcap、wgtcap、wExpSupcap | 2021 |
| CM-SPADE | CMAP | GSP | 提出了一种新的共现信息存储结构CMAP对候选数据进行了裁剪 | 不能直接处理最大序列模式挖掘 | CMAP | 2014 |
| F-NSP | bitmap | e-NSP | 通过位运算获得NSCs的支持 | 在大数据集上表现不佳 | — | 2018 |
| TKCS | bitmap | TSP | 通过对项集进行升序排序,然后扩展支持值最高的项集来生成候选项集 | 在对与加权约束挖掘top-k序列模式中不能实现 | — | 2020 |
| sc-NSP | bitmap | f-NSP | 按位运算计算PSP和NSCs的支持度 | 可能不适合非常稀疏的数据 | — | 2023 |
| e-NSP | 哈希表 | NegGSP | 只涉及已识别的正序列模式来挖掘NSP | 采用表结构计算支持度需要更多时间 | — | 2011 |
| hDSP-Miner | 哈希表LS-tree | ConSGapMiner | 首次研究了在序列元素之间存在概念层次时识别序列模式的挖掘 | 不能直接运行在分布式框架中 | — | 2022 |
| NWP-Miner | NetWeak | NOSEP | 基于Net-Weak执行深度优先搜索和回溯策略计算模式的支持度 | 不适合处理较大数据集 | — | 2022 |
表6 各序列模式挖掘算法的对比
Tab. 6 Comparison of various sequential pattern mining algorithms
| 算法 | 算法采用的结构 | 对比算法 | 优点 | 缺点 | 剪枝策略 | 发布年份 |
|---|---|---|---|---|---|---|
| Tree-miner | SP-tree | CM-SPADE、 CM-SPAM | 在处理动态数据库和基于滑动窗口的交互式挖掘问题方面具有优势 | 需要内存保存树结构与剪枝策略所用的共存项表,内存使用较多 | 基于共存项表的修剪、基于启发式列表的修剪 | 2020 |
| WSPM_PreTree | Prefix-tree | SPMW | 对稀疏数据集WSPM_PreTree有更好的时空效果 | 对于密集数据集算法使用的内存更多 | — | 2023 |
| nSP-DS | Prefix-tree | — | 具有良好的可扩展性 | 只适用于数据流中元素为1-size的序列 | 向下闭包 | 2023 |
| USpan | LQS-tree效用矩阵 | Prefixspan | 首次提出了LQS-tree结构,并首次提出了序列加权效用的概念 | 采用矩阵结构可能消耗较多内存 | 宽度剪枝与深度剪枝 | 2012 |
| HUSpan-MMU | LQS-tree | HUSpan-MMU | 建立了序列的多重最小效用 | 不适合处理较大数据集 | SPU、SWU | 2018 |
| PHUSPM | LQS-tree | Uspan | 定义了周期高效用序列模式 | 不能挖掘并行周期高效用序列模式 | SWU | 2017 |
| U-HUSPM | LS-tree | U-HUSPM | 设计了高效用概率序列模式挖掘框架 | 不能挖掘并行高效用概率序列模式 | SWU、HSWUPDC | 2019 |
| HUSP-Miner | ItemUtilLists、 HUSP-tree | USpan | 只需扫描一次数据库 | 需要为HUSP-tree非根节点设计额外字段 | TSWU、SFU | 2017 |
| NOSEP | Nettree | gd-DSPMiner | 首次采用Nettree结构挖掘非重叠序列模式 | 用户需要指定模式的间隙 | — | 2018 |
| TNOSP | Nettree | NOSTOPK | 可以挖掘所有符合条件的非重叠序列模式 | 在流数据集中还未能实现 | QMSP | 2023 |
| HANP-Miner | Nettree | NOSEP | 推导了一种基于平均效用上界的策略,并将它与模式连接策略结合起来生成候选模式 | 必须反复扫描SDB,算法效率不高 | Apriori | 2021 |
| NetBack | Nettree | INSGrow | 采用回溯策略迭代搜索最左孩子方式计算无重叠最小出现 | Nettree结构的创建过程较为复杂 | — | 2021 |
| NetNMSP | Nettree | NOSEP | 采用模式连接策略生成候选模式,并采用筛选方法查找频繁模式 | 不能处理大数据 | Apriori | 2022 |
| TALENT | Nettree | NOSEPta | 算法性能随着查询序列长度的增加和有效模式的减少而优化 | 当项目数量较少时,其BFS无法过滤大量待扩展的项目 | SPRP、IPRP | 2023 |
| SCP-Miner | Nettree | NOSEP | 不需要频繁阈值和不频繁阈值,比竞争算法更有效 | 为了更好的性能,需要选择最优参数 | Zero、Less | 2022 |
| OPP-Miner | Prefix-tree | FIM-SW | 采用过滤和验证策略计算支持度,并采用模式融合策略生成候选模式 | 不能进行多维数据挖掘 | — | 2023 |
| CUP | pseudo-IDList、 data IDList | SPAM、 CM-SPADE、 PrefixSpan | 通常在大型数据库上内存效率更高 | 直接进行序列模式挖掘并不能完全工作,并且可能产生错误的结果 | DUB | 2020 |
| SUI | pseudo-IDList、 data IDList | CM-SPADE、 PrefixSpan | 将pseudo-IDList结构运用到序列模式挖掘中 | data-idlist仍然存在一部分重复信息 | — | 2020 |
| EWSPM | WeightList | IUA、 FWSPM | 设计了2个新的严格上界MWEbound和MSRIWbound | 在大型数据集或非常低的阈值上的内存消耗显著增加 | MWEbound、 MSRIWbound | 2024 |
| HUSP-ULL | UL-list | Uspan、 HUS-span | 适合处理每个序列平均包含元素数多的数据集。 | 需要花费更多时间创建UL-list | LAR、IIP | 2021 |
| ISP-PI | pseudo-IDList | EISP-Miner | Pseudo-IDlist避免在挖掘过程中多次复制重复数据 | 修剪只考虑同一项集或事务中的项 | ISP-IC | 2024 |
| RNP-Miner | Position dictionary | NOSEP-RNP、 SNP-RNP | 提出了无希望项目修剪策略和无希望模式修剪策略 | 需要存储子模式的发生位置,导致内存占用增加 | PUI、PUP | 2023 |
| TCSPM | Sequence chain | CSPMpost | 将目标导向查询的概念集成到连续序列模式挖掘中 | 时间、空间复杂度在最坏情况下较高 | USFP、SCP | 2024 |
| HUS-Span | utility-chain | TUS SPAN | 开发了2个更紧密的效用上界,PEU和RSU | 在某些情况下,存在内存空间不足的问题 | PEU、RSU | 2016 |
| PUSOM | PUSP | HUS-Span | 提出了一种周期性高效用序列模式挖掘结构 | 可能占用较多内存 | PEU、SWU、MPP | 2018 |
| TKUS | utility-chain | TKHUS-Span | 能快速提高最小效用阈值,并有效地提取top-k HUSPS | 算法不适用于大数据中 | SUR、TDE、EUI | 2021 |
| AHUS-P | array | HUS-span | 采用了并行挖掘策略,可以地共享内存中的并行任务并发现模式 | 在有些小规模数据集上的内存使用率不佳 | PEU、RSU、EUU | 2018 |
| ProUM | utility-array | USpan、 HUS-Span | 利用效用数组数据结构,避免了对原始数据库的多次扫描 | 在合成数据集上,比USpan需要更多的内存 | PUO、PUK | 2020 |
| SNP-Miner | array | SNP-Miner | 使用存储在数组中的不完整网树结构,并对结构进行一次扫描,避免了冗余计算 | 是一种需要生成候选模式的两阶段算法 | — | 2022 |
| FUSP | USeq-Trie | FUSP | 使用USeq-Trie结构存储不确定序列并更新序列的加权期望支持度 | 可能使用较多内存 | expSupcap、wgtcap、wExpSupcap | 2021 |
| CM-SPADE | CMAP | GSP | 提出了一种新的共现信息存储结构CMAP对候选数据进行了裁剪 | 不能直接处理最大序列模式挖掘 | CMAP | 2014 |
| F-NSP | bitmap | e-NSP | 通过位运算获得NSCs的支持 | 在大数据集上表现不佳 | — | 2018 |
| TKCS | bitmap | TSP | 通过对项集进行升序排序,然后扩展支持值最高的项集来生成候选项集 | 在对与加权约束挖掘top-k序列模式中不能实现 | — | 2020 |
| sc-NSP | bitmap | f-NSP | 按位运算计算PSP和NSCs的支持度 | 可能不适合非常稀疏的数据 | — | 2023 |
| e-NSP | 哈希表 | NegGSP | 只涉及已识别的正序列模式来挖掘NSP | 采用表结构计算支持度需要更多时间 | — | 2011 |
| hDSP-Miner | 哈希表LS-tree | ConSGapMiner | 首次研究了在序列元素之间存在概念层次时识别序列模式的挖掘 | 不能直接运行在分布式框架中 | — | 2022 |
| NWP-Miner | NetWeak | NOSEP | 基于Net-Weak执行深度优先搜索和回溯策略计算模式的支持度 | 不适合处理较大数据集 | — | 2022 |

图10 算法NOSEP与RNP-Miner的运行时间与内存使用对比
Fig. 10 Comparison of running time and memory usage between NOSEP and RNP-Miner algorithms
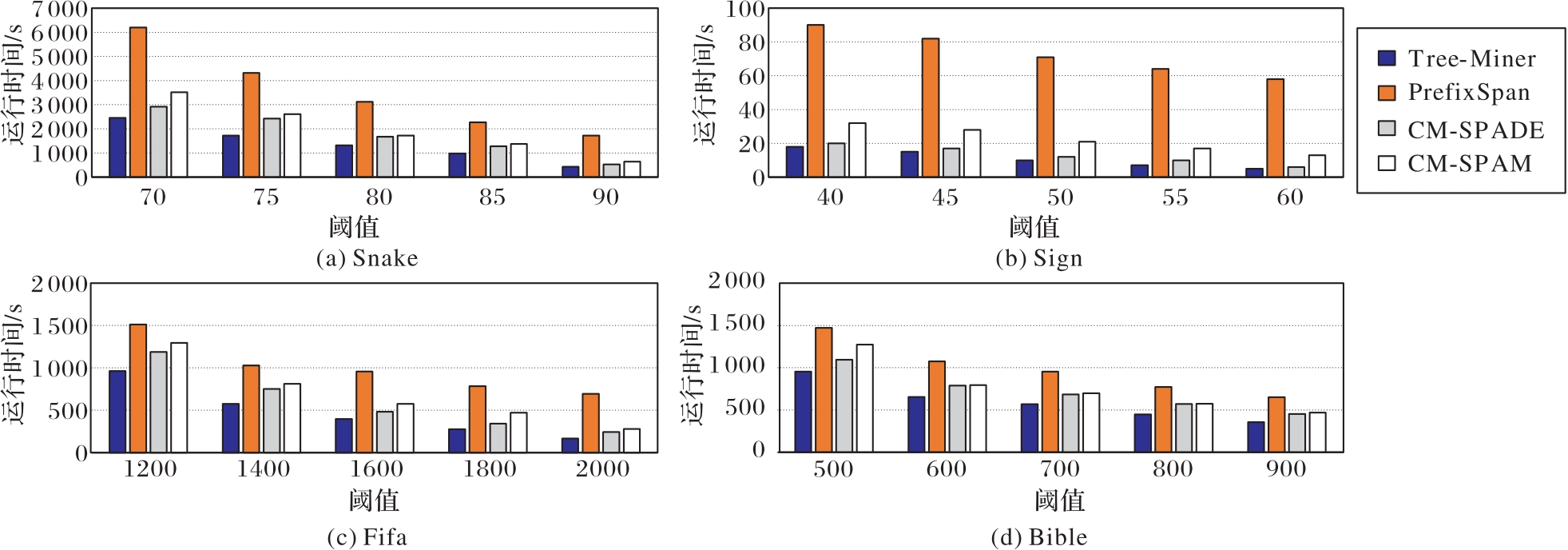
图11 各算法的运行时间对比
Fig. 11 Comparison of running time among various algorithms

图12 并行算法总结
Fig. 12 Summary of parallel algorithms
| [1] | 张光兰,杨秋辉,程雪梅,等.序列模式挖掘在通信网络告警预测中的应用[J].计算机科学,2018, 45(11A): 535-538. |
| ZHANG G L, YANG Q H, CHENG X M, et al. Application of sequential pattern mining in communication network alarm prediction [J]. Computer Science, 2018, 45(11A): 535-538. | |
| [2] | AI Z, YIN J, SI S, et al. Mining implicit behavioral patterns via attention networks for sequential recommendation [J]. Procedia Computer Science, 2023, 222: 177-186. |
| [3] | ZHOU H, ZHANG S, PENG J, et al. Informer: beyond efficient transformer for long sequence time-series forecasting [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 11106-11115. |
| [4] | FUMAROLA F, LANOTTE P F, CECI M, et al. CloFAST: closed sequential pattern mining using sparse and vertical id-lists [J]. Knowledge and Information Systems, 2016, 48(2): 429-463. |
| [5] | FOURNIER-VIGER P, WU C W, TSENG V C. Mining maximal sequential patterns without candidate maintenance [C]// Proceedings of the 2013 International Conference on Advanced Data Mining and Applications, LNCS 8346. Berlin: Springer, 2013: 169-180. |
| [6] | DONG X, ZHENG Z, CAO L, et al. e-NSP: Efficient negative sequential pattern mining based on identified positive patterns without database rescanning [C]// Proceedings of the 20th ACM International Conference on Information and Knowledge Management. New York: ACM, 2011: 825-830. |
| [7] | AGRAWAL R, SRIKANT R. Mining sequential patterns [C]// Proceedings of the 11th International Conference on Data Engineering. Piscataway: IEEE, 1995: 3-14. |
| [8] | SRIKANT R, AGRAWAL R. Mining sequential patterns: generalizations and performance improvements [C]// Proceedings of the 1996 International Conference on Extending Database Technology, LNCS 1057. Berlin: Springer, 1996: 1-17. |
| [9] | HAN J, PEI J, MORTAZAVI-ASL B, et al. FreeSpan: frequent pattern-projected sequential pattern mining [C]// Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2000: 355-359. |
| [10] | PEI J, HAN J, MORTAZAVI-ASL B, et al. Mining sequential patterns by pattern-growth: the PrefixSpan approach [J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(11): 1424-1440. |
| [11] | GAO X, GONG Y, XU T, et al. Toward better structure and constraint to mine negative sequential patterns [J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(2): 571-585. |
| [12] | YU X, LIU J, LIU X, et al. A MapReduce reinforced distributed sequential pattern mining algorithm [C]// Proceedings of the 2015 International Conference on Algorithms and Architectures for Parallel Processing, LNCS 9529. Cham: Springer, 2015: 183-197. |
| [13] | YU X, LI Q, LIU J. Scalable and parallel sequential pattern mining using Spark [J]. World Wide Web, 2019, 22(1): 295-324. |
| [14] | CONG S, HAN J, HOEFLINGER J, et al. A sampling-based framework for parallel data mining [C]// Proceedings of the 10th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. New York: ACM, 2005: 255-265. |
| [15] | ABBASGHORBANI S, TAVOLI R. Survey on sequential pattern mining algorithms [C]// Proceedings of the 2nd International Conference on Knowledge-Based Engineering and Innovation. Piscataway: IEEE, 2015: 1153-1164. |
| [16] | FOURNIER-VIGER P, LIN J C W, KIRAN R U, et al. A survey of sequential pattern mining [J]. Data Science and Pattern Recognition, 2017, 1(1): 54-77. |
| [17] | GAN W, LIN J C W, FOURNIER-VIGER P, et al. A survey of parallel sequential pattern mining [J]. ACM Transactions on Knowledge Discovery from Data, 2019, 13(3): No.25. |
| [18] | KUMAR S, MOHBEY K K. A review on big data based parallel and distributed approaches of pattern mining [J]. Journal of King Saud University — Computer and Information Sciences, 2022, 34(5): 1639-1662. |
| [19] | 满欣,陈华辉.序列模式中的生成序列模式挖掘综述[J].无线通信技术,2018, 27(4): 7-11, 16. |
| MAN X, CHEN H H. Survey of sequential generators mining [J]. Wireless Communication Technology, 2018, 27(4): 7-11, 16. | |
| [20] | ZHANG R, HAN M, HE F, et al. A survey of high utility sequential patterns mining methods [J]. Journal of Intelligent and Fuzzy Systems, 2023, 45(5): 8049-8077. |
| [21] | AYRES J, FLANNICK J, GEHRKE J, et al. Sequential pattern mining using a bitmap representation [C]// Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2002: 429-435. |
| [22] | YIN J, ZHENG Z, CAO L. USpan: an efficient algorithm for mining high utility sequential patterns [C]// Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012: 660-668. |
| [23] | RIZVEE R A, AREFIN M F, AHMED C F. Tree-miner: mining sequential patterns from SP-Tree [C]// Proceedings of the 2020 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 12085. Cham: Springer, 2020: 44-56. |
| [24] | PHAM T T, VU T D, NGUYEN T D, et al. Mining weighted sequential patterns based on prefix-tree and PRISM encoding [J]. Vietnam Journal of Computer Science, 2023, 10(3): 357-372. |
| [25] | ZHANG N, REN X, DONG X. An effective method for mining negative sequential patterns from data streams [J]. IEEE Access, 2023, 11: 31842-31854. |
| [26] | XU T, XU J, DONG X. Mining high utility sequential patterns using multiple minimum utility [J]. International Journal of Pattern Recognition and Artificial Intelligence, 2018, 32(10): No.1859017. |
| [27] | ZHANG B, LIN J C W, FOURNIER-VIGER P, et al. Mining of high utility-probability sequential patterns from uncertain databases [J]. PLoS ONE, 2017, 12(7): No.e0180931. |
| [28] | ZIHAYAT M, WU C W, AN A, et al. Efficiently mining high utility sequential patterns in static and streaming data [J]. Intelligent Data Analysis, 2017, 21(S1): S103-S135. |
| [29] | TANG H, LIU Y, WANG L. A new algorithm of mining high utility sequential pattern in streaming data [J]. International Journal of Computational Intelligence Systems, 2018, 12: 342-350. |
| [30] | 荀亚玲,任姿芊,闫海博.一种有效的周期高效用序列模式增量挖掘算法[J].计算机应用研究,2024, 41(8): 2301-2308. |
| XUN Y L, REN Z Q, YAN H B. Effective incremental mining algorithm for periodic high-utility sequential patterns [J]. Application Research of Computers, 2024, 41(8): 2301-2308. | |
| [31] | WU Y, TONG Y, ZHU X, et al. NOSEP: nonoverlapping sequence pattern mining with gap constraints [J]. IEEE Transactions on Cybernetics, 2018, 48(10): 2809-2822. |
| [32] | CHAI X, YANG D, LIU J, et al. Top-k sequence pattern mining with non-overlapping condition [J]. Filomat, 2018, 32(5): 1703-1710. |
| [33] | WU Y, GENG M, LI Y, et al. HANP-Miner: high average utility nonoverlapping sequential pattern mining [J]. Knowledge-Based Systems, 2021, 229: No.107361. |
| [34] | 武优西,刘茜,闫文杰,等.无重叠条件严格模式匹配的高效求解算法[J].软件学报,2021, 32(11): 3331-3350. |
| WU Y X, LIU X, YAN W J, et al. Efficient algorithm for solving strict pattern matching under nonoverlapping condition [J]. Journal of Software, 2021, 32(11): 3331-3350. | |
| [35] | LI Y, ZHANG S, GUO L, et al. NetNMSP: nonoverlapping maximal sequential pattern mining [J]. Applied Intelligence, 2022, 52(9): 9861-9884. |
| [36] | HU Y H, WU F, LIAO Y J. An efficient tree-based algorithm for mining sequential patterns with multiple minimum supports [J]. Journal of Systems and Software, 2013, 86(5): 1224-1238. |
| [37] | WU Y, WANG Y, LI Y, et al. Top-k self-adaptive contrast sequential pattern mining [J]. IEEE Transactions on Cybernetics, 2022, 52(11): 11819-11833. |
| [38] | KARSOUM S, BARRUS C, GRUENWALD L, et al. Minits-AllOcc: an efficient algorithm for mining timed sequential patterns [C]// Proceedings of the 2021 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 12712. Cham: Springer, 2021: 668-685. |
| [39] | ZAKI M J. SPADE: an efficient algorithm for mining frequent sequences [J]. Machine Learning, 2001, 42(1/2): 31-60. |
| [40] | HUYNH H M, NGUYEN L T T, VO B, et al. Efficient algorithms for mining clickstream patterns using pseudo-IDLists [J]. Future Generation Computer Systems, 2020, 107: 18-30. |
| [41] | CHEN S, CHEN J, WAN S. Efficient weighted sequential pattern mining [J]. Expert Systems with Applications, 2024, 243: No.122703. |
| [42] | GAN W, LIN J C W, ZHANG J, et al. Fast utility mining on sequence data [J]. IEEE Transactions on Cybernetics, 2021, 51(2): 487-500. |
| [43] | BUFFETT S. Candidate list maintenance in high utility sequential pattern mining [C]// Proceedings of the 2018 IEEE International Conference on Big Data. Piscataway: IEEE, 2018: 644-652. |
| [44] | XIE S, ZHAO L. An efficient algorithm for mining stable periodic high-utility sequential patterns [J]. Symmetry, 2022, 14(10): No.2032. |
| [45] | NGUYEN A, NGUYEN N T, NGUYEN L T T, et al. An efficient pruning method for mining inter-sequence patterns based on pseudo-IDList [J]. Expert Systems with Applications, 2024, 238(Pt B): No.121738. |
| [46] | GENG M, WU Y, LI Y, et al. RNP-Miner: repetitive nonoverlapping sequential pattern mining [J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(6): 4874-4889. |
| [47] | HU K, GAN W, HUANG S, et al. Targeted mining of contiguous sequential patterns [J]. Information Sciences, 2024, 653: No.119791. |
| [48] | WANG J Z, HUANG J L, CHEN Y C. On efficiently mining high utility sequential patterns [J]. Knowledge and Information Systems, 2016, 49(2): 597-627. |
| [49] | DINH D T, LE B, FOURNIER-VIGER P, et al. An efficient algorithm for mining periodic high-utility sequential patterns [J]. Applied Intelligence, 2018, 48(12): 4694-4714. |
| [50] | ZHANG C, DU Z, GAN W, et al. TKUS: mining top-k high utility sequential patterns [J]. Information Sciences, 2021, 570: 342-359. |
| [51] | LE B, HUYNH U, DINH D T. A pure array structure and parallel strategy for high-utility sequential pattern mining [J]. Expert Systems with Applications, 2018, 104: 107-120. |
| [52] | GAN W, LIN J C W, ZHANG J, et al. ProUM: projection-based utility mining on sequence data [J]. Information Sciences, 2020, 513: 222-240. |
| [53] | 杨克帅,武优西,耿萌,等.一次性条件下top-k高平均效用序列模式挖掘算法[J].计算机应用,2024, 44(2): 477-484. |
| YANG K S, WU Y X, GENG M, et al. Top-k high average utility sequential pattern mining algorithm under one-off condition [J]. Journal of Computer Applications, 2024, 44(2): 477-484. | |
| [54] | WANG Y, WU Y, LI Y, et al. Self-adaptive nonoverlapping sequential pattern mining [J]. Applied Intelligence, 2022: 1-16. |
| [55] | FOURNIER-VIGER P, GOMARIZ A, CAMPOS M, et al. Fast vertical mining of sequential patterns using co-occurrence information [C]// Proceedings of the 2014 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 8443. Cham: Springer, 2014: 40-52. |
| [56] | DONG X, GONG Y, CAO L. F-NSP+: a fast negative sequential patterns mining method with self-adaptive data storage [J]. Pattern Recognition, 2018, 84: 13-27. |
| [57] | SUN C, GONG Y, GUO Y, et al. SN-RNSP: mining self-adaptive nonoverlapping repetitive negative sequential patterns in transaction sequences [J]. Knowledge-Based Systems, 2024, 287: No.111449. |
| [58] | HE C, DUAN L, DONG G, et al. Efficient mining of concept-hierarchy aware distinguishing sequential patterns [J]. Knowledge-Based Systems, 2022, 255: No.109710. |
| [59] | WU Y, YUAN Z, LI Y, et al. NWP-Miner: nonoverlapping weak-gap sequential pattern mining [J]. Information Sciences, 2022, 588: 124-141. |
| [60] | DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(1): 107-113. |
| [61] | QIAO S, LI T, PENG J, et al. Parallel sequential pattern mining of massive trajectory data [J]. International Journal of Computational Intelligence Systems, 2010, 3(3): 343-356. |
| [62] | HUANG J W, LIN S C, CHEN M S. DPSP: distributed progressive sequential pattern mining on the cloud [C]// Proceedings of the 2010 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 6119. Berlin: Springer, 2010: 27-34. |
| [63] | MILIARAKI I, BERBERICH K, GEMULLA R, et al. Mind the gap: large-scale frequent sequence mining [C]// Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2013: 797-808. |
| [64] | BEEDKAR K, GEMULLA R. LASH: large-scale sequence mining with hierarchies [C]// Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2015: 491-503. |
| [65] | HOANG T, LE B, TRAN M T. Distributed algorithm for sequential pattern mining on a large sequence dataset [C]// Proceedings of the 9th International Conference on Knowledge and Systems Engineering. Piscataway: IEEE, 2017: 18-23. |
| [66] | SALETI S, SUBRAMANYAM R B V. A MapReduce solution for incremental mining of sequential patterns from big data [J]. Expert Systems with Applications, 2019, 133: 109-125. |
| [67] | SALETI S, SUBRAMANYAM R B V. A novel MapReduce algorithm for distributed mining of sequential patterns using co-occurrence information [J]. Applied Intelligence, 2019, 49(1): 150-171. |
| [68] | 程思远,马超,李聪聪.基于MapReduce的高效用序列模式挖掘算法[J].计算机系统应用,2015, 24(12): 228-232. |
| CHENG S Y, MA C, LI C C. High utility sequential pattern mining algorithm based on MapReduce [J]. Computer Systems and Applications, 2015, 24(12): 228-232. | |
| [69] | SUMALATHA S, SUBRAMANYAM R B V. Distributed mining of high utility time interval sequential patterns using MapReduce approach [J]. Expert Systems with Applications, 2020, 141: No.112967. |
| [70] | LIN J C W, DJENOURI Y, SRIVASTAVA G, et al. Scalable mining of high-utility sequential patterns with three-tier MapReduce model [J]. ACM Transactions on Knowledge Discovery from Data, 2022, 16(3): No.60. |
| [71] | SALETI S, LAKSHMI T J, AHMAD M W. Mining high utility time interval sequences using MapReduce approach: multiple utility framework [J]. IEEE Access, 2022, 10: 123301-123315. |
| [72] | WU J M T, LIU S, LIN J C W. Mining of high-utility sequence patterns in large-scale uncertain databases [C]// Proceedings of the 2022 IEEE International Conference on Dependable, Autonomic and Secure Computing/ IEEE International Conference on Pervasive Intelligence and Computing/ IEEE International Conference on Cloud and Big Data Computing/ IEEE Cyber Science and Technology Congress. Piscataway: IEEE, 2022: 1-7. |
| [73] | CHEN C C, TSENG C Y, CHEN M S. Highly scalable sequential pattern mining based on MapReduce model on the cloud [C]// Proceedings of the 2013 IEEE International Congress on Big Data. Piscataway: IEEE, 2013: 310-317. |
| [74] | CHEN C C, SHUAI H H, CHEN M S. Distributed and scalable sequential pattern mining through stream processing [J]. Knowledge and Information Systems, 2017, 53(2): 365-390. |
| [75] | ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing [C]// Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation. Berkeley: USENIX Association, 2012: 1-14. |
| [76] | QIN P, DUAN L, ZHANG T, et al. A parallel algorithm for mining density-aware distinguishing sequential patterns with Spark [C]// Proceedings of the 2016 International Conference on Advanced Cloud and Big Data. Piscataway: IEEE, 2016: 144-149. |
| [77] | STAMOULAKATOU E, GULINO A, PINOLI P. DLA: a distributed, location-based and Apriori-based algorithm for biological sequence pattern mining [C]// Proceedings of the 2018 IEEE International Conference on Big Data. Piscataway: IEEE, 2018: 1121-1126. |
| [78] | CHEN X, XIAO R, XIN D, et al. Constructing a novel spark-based distributed maximum frequent sequence pattern mining for IoT log [C]// Proceedings of the 8th International Conference on Communication and Network Security. New York: ACM, 2018: 112-116. |
| [79] | KIM B, YI G. Location-based parallel sequential pattern mining algorithm [J]. IEEE Access, 2019, 7: 128651-128658. |
| [80] | ZIHAYAT M, HUT Z Z, AN A, et al. Distributed and parallel high utility sequential pattern mining [C]// Proceedings of the 2016 IEEE International Conference on Big Data. Piscataway: IEEE, 2016: 853-862. |
| [81] | LIN J C W, LI Y, FOURNIER-VIGER P, et al. Mining high-utility sequential patterns from big datasets [C]// Proceedings of the 2019 IEEE International Conference on Big Data. Piscataway: IEEE, 2019: 2674-2680. |
| [82] | HUYNH B, VO B, SNASEL V. An efficient method for mining frequent sequential patterns using multi-core processors [J]. Applied Intelligence, 2017, 46(3): 703-716. |
| [1] | 杨克帅, 武优西, 耿萌, 刘靖宇, 李艳. 一次性条件下top-k高平均效用序列模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 477-484. |
| [2] | 黄硕, 李艳辉, 曹建秋. 本地化差分隐私下的频繁序列模式挖掘算法PrivSPM[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2057-2064. |
| [3] | 孟玉飞, 武优西, 王珍, 李艳. 对比保序模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3740-3746. |
| [4] | 吴军, 欧阳艾嘉, 张琳. 基于影响度的统计显著序列模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2713-2721. |
| [5] | 康军, 黄山, 段宗涛, 李宜修. 时空轨迹序列模式挖掘方法综述[J]. 《计算机应用》唯一官方网站, 2021, 41(8): 2379-2385. |
| [6] | 王淳颖, 张驯, 赵金雄, 袁晖, 李方军, 赵博, 朱小琴, 杨凡, 吕世超. 基于多源告警的攻击事件分析[J]. 计算机应用, 2020, 40(1): 123-128. |
| [7] | 韩萌, 丁剑. 数据流频繁模式挖掘综述[J]. 计算机应用, 2019, 39(3): 719-727. |
| [8] | 姚小强, 侯志森. 基于树结构长短期记忆神经网络的金融时间序列预测[J]. 计算机应用, 2018, 38(11): 3336-3341. |
| [9] | 温腊 芮建武 何婷婷 郭亮. 利用并行GPU对分层分布式狄利克雷分布算法加速[J]. 计算机应用, 2013, 33(12): 3313-3316. |
| [10] | 王继东 赵瑞斌 庞明勇. 基于特征草图和分形插值的可控真实感地形合成[J]. 计算机应用, 2013, 33(02): 519-542. |
| [11] | 李锐 李佳田 王华 蒲海霞 何育枫. 基于四叉树结构的加权Voronoi图生成算法[J]. 计算机应用, 2012, 32(11): 3078-3081. |
| [12] | 余莉 李佳田 李佳 段平 王华. 二维空间聚类的树ART2模型[J]. 计算机应用, 2011, 31(05): 1328-1330. |
| [13] | 张菁. 基于两代树的低密度校验码校验矩阵构造方法[J]. 计算机应用, 2011, 31(04): 945-947. |
| [14] | 张光建 刘政. 基于树结构的μC/OS-II任务栈空间计算方法及应用[J]. 计算机应用, 2009, 29(4): 1165-1167. |
| [15] | 昝鑫 郑庆华 范宇倩 韩九强. 攻击案例综合学习系统研究[J]. 计算机应用, 2007, 27(9): 2177-2179. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||