


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3146-3153.DOI: 10.11772/j.issn.1001-9081.2024101453
• 人工智能 • 上一篇
刘晋文1,2,3, 王磊1,2,3( ), 马博1,2,3, 董瑞1,2,3, 杨雅婷1,2,3, 艾合塔木江·艾合麦提1,2,3, 王欣乐4
), 马博1,2,3, 董瑞1,2,3, 杨雅婷1,2,3, 艾合塔木江·艾合麦提1,2,3, 王欣乐4
收稿日期:2024-10-14
修回日期:2024-12-05
接受日期:2024-12-09
发布日期:2024-12-23
出版日期:2025-10-10
通讯作者:
王磊
作者简介:刘晋文(1999—),女,山西吕梁人,硕士研究生,主要研究方向:有害信息检测基金资助:
Jinwen LIU1,2,3, Lei WANG1,2,3(), Bo MA1,2,3, Rui DONG1,2,3, Yating YANG1,2,3, Ahtamjan Ahmat1,2,3, Xinyue WANG4
Received:2024-10-14
Revised:2024-12-05
Accepted:2024-12-09
Online:2024-12-23
Published:2025-10-10
Contact:
Lei WANG
About author:LIU Jinwen, born in 1999, M. S. candidate. Her research interests include harmful information detection.Supported by:摘要:
社交媒体上多模态有害信息的泛滥不仅损害公众利益,还严重扰乱社会秩序,亟需有效的检测方法。现有研究依赖预训练模型提取与融合多模态特征,忽视了通用语义在有害信息检测任务中的局限性,且未能充分考虑有害信息复杂多变的组合形式。为此,提出一种基于弱监督模态语义增强的多模态有害信息检测方法(weak-S),所提方法通过引入弱监督模态信息辅助多模态特征的有害语义对齐,并设计一种低秩双线性池化的多模态门控集成机制,以区分不同信息的贡献度。实验结果表明,所提方法在Harm-P和MultiOFF数据集上的F1值相较于SOTA (State-Of-The-Art)模型分别提高了2.2和3.2个百分点,验证了弱监督模态语义在多模态有害信息检测中的重要性。此外,所提方法在多模态夸张检测任务上取得了泛化性能的提升。
中图分类号:
刘晋文, 王磊, 马博, 董瑞, 杨雅婷, 艾合塔木江·艾合麦提, 王欣乐. 基于弱监督模态语义增强的多模态有害信息检测方法[J]. 计算机应用, 2025, 45(10): 3146-3153.
Jinwen LIU, Lei WANG, Bo MA, Rui DONG, Yating YANG, Ahtamjan Ahmat, Xinyue WANG. Multimodal harmful content detection method based on weakly supervised modality semantic enhancement[J]. Journal of Computer Applications, 2025, 45(10): 3146-3153.
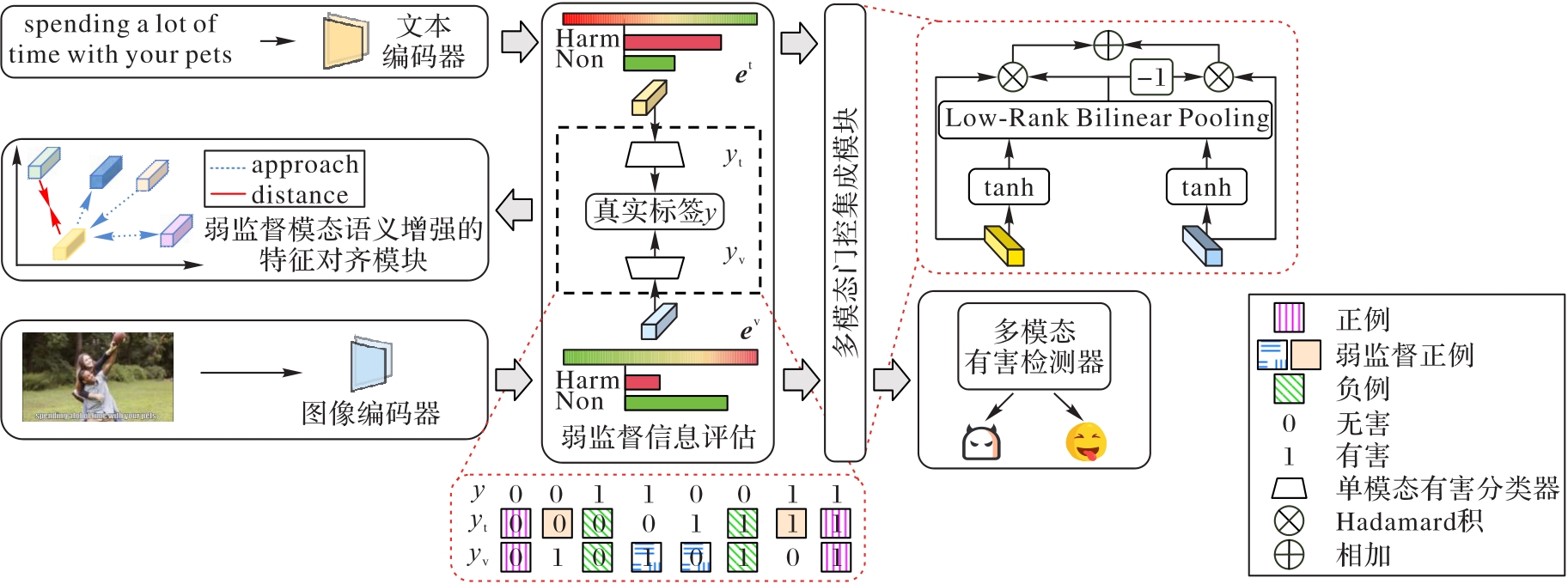
图1 弱监督模态语义增强模型
Fig. 1 Weakly supervised modality semantic enhancement model
| 数据集 | 有害性 | 样本数 | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 验证集 | ||
| Harm-P | Hate | 1 486 | 173 | 86 |
| Not-hate | 1 534 | 182 | 91 | |
| 合计 | 3 020 | 355 | 177 | |
| Harm-C | Hate | 1 064 | 124 | 61 |
| Not-hate | 1 949 | 230 | 116 | |
| 合计 | 3 013 | 354 | 177 | |
| MultiOFF | Offensive | 187 | 59 | 59 |
| Non-offensive | 258 | 90 | 90 | |
| 合计 | 445 | 149 | 149 | |
表1 数据分布与划分
Tab. 1 Data distribution and partitioning
| 数据集 | 有害性 | 样本数 | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 验证集 | ||
| Harm-P | Hate | 1 486 | 173 | 86 |
| Not-hate | 1 534 | 182 | 91 | |
| 合计 | 3 020 | 355 | 177 | |
| Harm-C | Hate | 1 064 | 124 | 61 |
| Not-hate | 1 949 | 230 | 116 | |
| 合计 | 3 013 | 354 | 177 | |
| MultiOFF | Offensive | 187 | 59 | 59 |
| Non-offensive | 258 | 90 | 90 | |
| 合计 | 445 | 149 | 149 | |
| 模型 | MultiOFF | |||
|---|---|---|---|---|
| Acc↑ | Pre↑ | Rec↑ | F1↑ | |
| Stacked LSTM+VGG16 | — | 0.400 | 0.660 | 0.500 |
| BiLSTM+VGG16 | — | 0.400 | 0.440 | 0.410 |
| CNNText+VGG16 | — | 0.380 | 0.670 | 0.480 |
| DisMultiHate | — | 0.645 | 0.651 | 0.646 |
| MeBERT | — | 0.670 | 0.671 | 0.671 |
| MemeFier | 0.685 | — | — | 0.625 |
| weak-S | 0.711 | 0.706 | 0.711 | 0.703 |
表2 不同模型在MultiOFF数据集上的检测效果对比
Tab. 2 Comparison of detection effects of different models on MultiOFF dataset
| 模型 | MultiOFF | |||
|---|---|---|---|---|
| Acc↑ | Pre↑ | Rec↑ | F1↑ | |
| Stacked LSTM+VGG16 | — | 0.400 | 0.660 | 0.500 |
| BiLSTM+VGG16 | — | 0.400 | 0.440 | 0.410 |
| CNNText+VGG16 | — | 0.380 | 0.670 | 0.480 |
| DisMultiHate | — | 0.645 | 0.651 | 0.646 |
| MeBERT | — | 0.670 | 0.671 | 0.671 |
| MemeFier | 0.685 | — | — | 0.625 |
| weak-S | 0.711 | 0.706 | 0.711 | 0.703 |
| 模型 | Harm-P | Harm-C | ||||
|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | |
| Late Fusion | 0.783 | 0.785 | 0.167 | 0.732 | 0.703 | 0.293 |
| MMBT | 0.825 | 0.802 | 0.141 | 0.735 | 0.671 | 0.326 |
Visual BERT COCO | 0.868 | 0.861 | 0.132 | 0.814 | 0.801 | 0.186 |
| CLIP | 0.879 | 0.879 | 0.121 | 0.825 | 0.816 | 0.165 |
| MOMENTA | 0.898 | 0.883 | 0.131 | 0.838 | 0.828 | 0.174 |
| PromptHate | 0.882 | 0.871 | — | 0.845 | 0.815 | — |
| ISSUES | 0.881 | 0.864 | 0.164 | 0.848 | 0.778 | 0.174 |
| Pro-Cap | — | — | — | 0.851 | 0.839 | — |
| MR.HARM | 0.896 | 0.896 | — | 0.861 | 0.854 | — |
| weak-S | 0.918 | 0.918 | 0.082 | 0.867 | 0.853 | 0.149 |
表3 不同模型在Harm-P和Harm-C数据集上的检测效果对比
Tab. 3 Comparison of detection effects of different models on Harm-P and Harm-C datasets
| 模型 | Harm-P | Harm-C | ||||
|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | |
| Late Fusion | 0.783 | 0.785 | 0.167 | 0.732 | 0.703 | 0.293 |
| MMBT | 0.825 | 0.802 | 0.141 | 0.735 | 0.671 | 0.326 |
Visual BERT COCO | 0.868 | 0.861 | 0.132 | 0.814 | 0.801 | 0.186 |
| CLIP | 0.879 | 0.879 | 0.121 | 0.825 | 0.816 | 0.165 |
| MOMENTA | 0.898 | 0.883 | 0.131 | 0.838 | 0.828 | 0.174 |
| PromptHate | 0.882 | 0.871 | — | 0.845 | 0.815 | — |
| ISSUES | 0.881 | 0.864 | 0.164 | 0.848 | 0.778 | 0.174 |
| Pro-Cap | — | — | — | 0.851 | 0.839 | — |
| MR.HARM | 0.896 | 0.896 | — | 0.861 | 0.854 | — |
| weak-S | 0.918 | 0.918 | 0.082 | 0.867 | 0.853 | 0.149 |
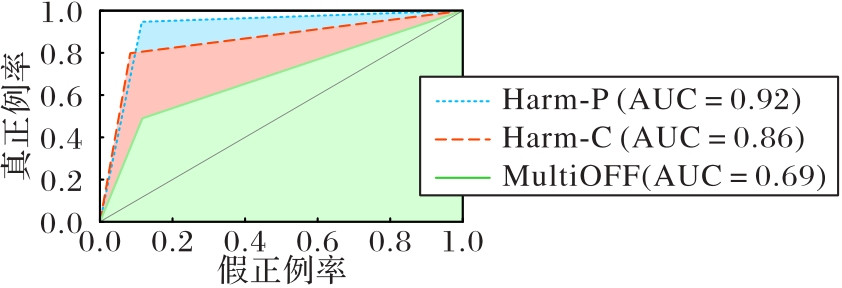
图2 实验结果的ROC曲线
Fig. 2 ROC curves of experimental results
| 方法 | Harm-C | Harm-P | MultiOFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | Pre↑ | Rec↑ | |
| weak-S | 0.867 | 0.853 | 0.149 | 0.918 | 0.918 | 0.082 | 0.711 | 0.703 | 0.706 | 0.711 |
| w/o | 0.841 | 0.819 | 0.191 | 0.886 | 0.886 | 0.113 | 0.672 | 0.654 | 0.665 | 0.671 |
| w/o | 0.846 | 0.828 | 0.179 | 0.889 | 0.889 | 0.110 | 0.664 | 0.666 | 0.668 | 0.664 |
| w/o MGI | 0.841 | 0.822 | 0.184 | 0.897 | 0.896 | 0.102 | 0.664 | 0.613 | 0.682 | 0.664 |
表4 消融实验结果
Tab. 4 Ablation experimental results
| 方法 | Harm-C | Harm-P | MultiOFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | Pre↑ | Rec↑ | |
| weak-S | 0.867 | 0.853 | 0.149 | 0.918 | 0.918 | 0.082 | 0.711 | 0.703 | 0.706 | 0.711 |
| w/o | 0.841 | 0.819 | 0.191 | 0.886 | 0.886 | 0.113 | 0.672 | 0.654 | 0.665 | 0.671 |
| w/o | 0.846 | 0.828 | 0.179 | 0.889 | 0.889 | 0.110 | 0.664 | 0.666 | 0.668 | 0.664 |
| w/o MGI | 0.841 | 0.822 | 0.184 | 0.897 | 0.896 | 0.102 | 0.664 | 0.613 | 0.682 | 0.664 |
| 模型 | Acc↑ | F1↑ | 模型 | Acc↑ | F1↑ |
|---|---|---|---|---|---|
| CLIP+prompt | 0.642 | 0.632 | BriVL+concat | 0.667 | 0.665 |
| CLIP+concat | 0.644 | 0.584 | BriVL+gate | 0.637 | 0.644 |
| CLIP+gate | 0.642 | 0.580 | weak-S | 0.684 | 0.675 |
| BriVL+prompt | 0.628 | 0.587 |
表5 多模态夸张检测效果的对比
Tab. 5 Comparison of multimodal exaggeration detection effects
| 模型 | Acc↑ | F1↑ | 模型 | Acc↑ | F1↑ |
|---|---|---|---|---|---|
| CLIP+prompt | 0.642 | 0.632 | BriVL+concat | 0.667 | 0.665 |
| CLIP+concat | 0.644 | 0.584 | BriVL+gate | 0.637 | 0.644 |
| CLIP+gate | 0.642 | 0.580 | weak-S | 0.684 | 0.675 |
| BriVL+prompt | 0.628 | 0.587 |
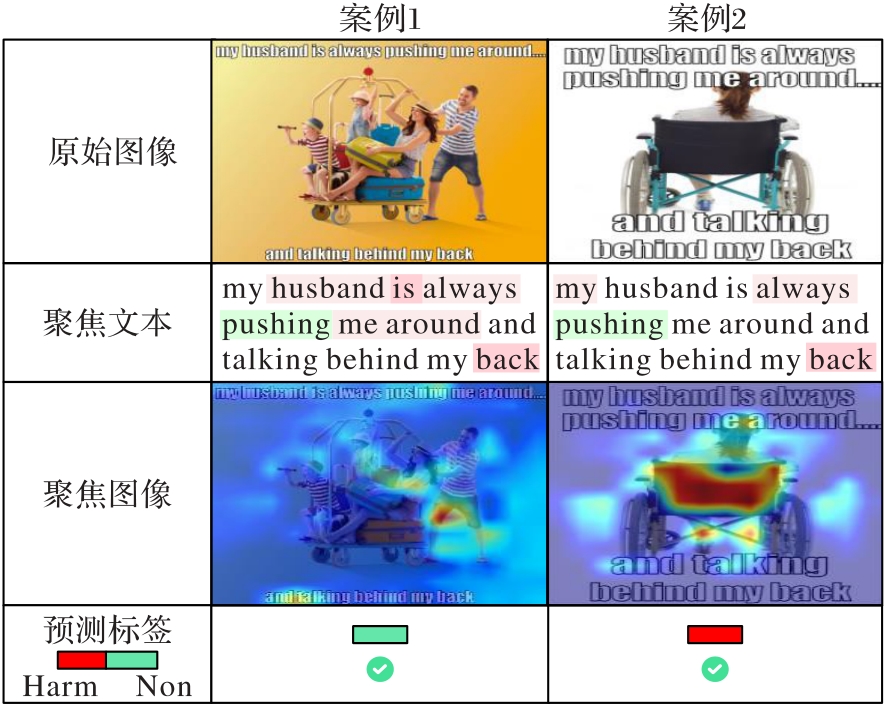
图3 多模态有害信息检测的案例分析
Fig. 3 Case analysis for multimodal harmful content detection
| [1] | PRAMANICK S, SHARMA S, DIMITROV D, et al. MOMENTA: a multimodal framework for detecting harmful memes and their targets[C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg: ACL, 2021: 4439-4455. |
| [2] | KIELA D, FIROOZ H, MOHAN A, et al. The hateful memes challenge: detecting hate speech in multimodal memes[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 2611-2624. |
| [3] | SHARMA S, ALAM F, AKHTAR M S, et al. Detecting and understanding harmful memes: a survey[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 5597-5606. |
| [4] | KOUTLIS C, SCHINAS M, PAPADOPOULOS S. MemeFier: dual-stage modality fusion for image meme classification[C]// Proceedings of the 2023 ACM International Conference on Multimedia Retrieval. New York: ACM, 2023: 586-591. |
| [5] | 孟杰,王莉,杨延杰,等. 基于多模态深度融合的虚假信息检测[J]. 计算机应用, 2022, 42(2):419-425. |
| MENG J, WANG L, YANG Y J, et al. Multi-modal deep fusion for false information detection[J]. Journal of Computer Applications, 2022, 42(2):419-425. | |
| [6] | LIN H, LUO Z, MA J, et al. Beneath the surface: unveiling harmful memes with multimodal reasoning distilled from large language models[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 9114-9128. |
| [7] | CAO R, LEE R K W, CHONG W H, et al. Prompting for multimodal hateful meme classification[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 321-332. |
| [8] | CAO R, HEE M S, KUEK A, et al. Pro-Cap: leveraging a frozen vision-language model for hateful meme detection[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 5244-5252. |
| [9] | WU F, GAO B, PAN X, et al. Fuser: an enhanced multimodal fusion framework with congruent reinforced perceptron for hateful memes detection[J]. Information Processing and Management, 2024, 61(4): No.103772. |
| [10] | LEE R K W, CAO R, FAN Z, et al. Disentangling hate in online memes[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 5138-5147. |
| [11] | 杜鹏飞. 多模态内容安全识别关键技术研究[D]. 北京:北京邮电大学, 2023. |
| DU P F. Research on key technologies of multimodal content security identification[D]. Beijing: Beijing University of Posts and Telecommunications, 2023. | |
| [12] | ZHONG Q, WANG Q, LIU J. Combining knowledge and multi-modal fusion for meme classification[C]// Proceedings of the 2022 International Conference on Multimedia Modeling, LNCS 13141. Cham: Springer, 2022: 599-611. |
| [13] | GOMEZ R, GIBERT J, GOMEZ L, et al. Exploring hate speech detection in multimodal publications[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 1459-1467. |
| [14] | SURYAWANSHI S, CHAKRAVARTHI B R, ARCAN M, et al. Multi modal meme dataset (MultiOFF) for identifying offensive content in image and text[C]// Proceedings of the 2nd Workshop on Trolling, Aggression and Cyberbullying. Stroudsburg: ACL, 2020: 32-41. |
| [15] | HOSSAIN E, SHARIF O, HOQUE M M, et al. Deciphering hate: identifying hateful memes and their targets[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 8347-8359. |
| [16] | KUMAR G K, NANDAKUMAR K. Hate-CLIPper: multimodal hateful meme classification based on cross-modal interaction of CLIP features[C]// Proceedings of the 2nd Workshop on NLP for Positive Impact. Stroudsburg: ACL, 2022: 171-183. |
| [17] | BURBI G, BALDRATI A, AGNOLUCCI L, et al. Mapping memes to words for multimodal hateful meme classification[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2023: 2824-2828. |
| [18] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [19] | MEI J, CHEN J, LIN W, et al. Improving hateful meme detection through retrieval-guided contrastive learning[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 5333-5347. |
| [20] | ZHANG Y, ZHANG H, ZHAN L M, et al. New intent discovery with pre-training and contrastive learning[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 256-269. |
| [21] | ZOU H, SHEN M, CHEN C, et al. UniS-MMC: multimodal classification via unimodality-supervised multimodal contrastive learning[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 659-672. |
| [22] | QU Y, HE X, PIERSON S, et al. On the evolution of (hateful) memes by means of multimodal contrastive learning[C]// Proceedings of the 2023 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2023: 293-310. |
| [23] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [24] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-12-04]. . |
| [25] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [26] | KIELA D, BHOOSHAN S, FIROOZ H, et al. Supervised multimodal bitransformers for classifying images and text[EB/OL]. [2024-12-04]. . |
| [27] | LU J, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13-23. |
| [28] | VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. [2024-12-04]. . |
| [29] | ZHANG H, WAN X. Image matters: a new dataset and empirical study for multimodal hyperbole detection[C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA and ICCL, 2024: 8652-8661. |
| [30] | HUO Y, ZHANG M, LIU G, et al. WenLan: bridging vision and language by large-scale multi-modal pre-training[EB/OL]. [2024-12-04]. . |
| [1] | 刘超, 余岩化. 融合降噪策略与多视图对比学习的知识感知推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2827-2837. |
| [2] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [3] | 黄锦阳, 崔丰麒, 马长秀, 樊文东, 李萌, 李经宇, 孙晓, 黄林生, 刘志. 基于通用手环的睡眠呼吸暂停检测[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3045-3056. |
| [4] | 殷兵, 凌震华, 林垠, 奚昌凤, 刘颖. 兼容缺失模态推理的情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2764-2772. |
| [5] | 王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506. |
| [6] | 谢劲, 褚苏荣, 强彦, 赵涓涓, 张华, 高勇. 用于胸片中硬负样本识别的双支分布一致性对比学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2369-2377. |
| [7] | 王震洲, 郭方方, 宿景芳, 苏鹤, 王建超. 面向智能巡检的视觉模型鲁棒性优化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2361-2368. |
| [8] | 王艺涵, 路翀, 陈忠源. 跨模态文本信息增强的多模态情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2237-2244. |
| [9] | 颜文婧, 王瑞东, 左敏, 张青川. 基于风味嵌入异构图层次学习的食谱推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1869-1878. |
| [10] | 吴宗航, 张东, 李冠宇. 基于联合自监督学习的多模态融合推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1858-1868. |
| [11] | 余明峰, 秦永彬, 黄瑞章, 陈艳平, 林川. 基于对比学习增强双注意力机制的多标签文本分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1732-1740. |
| [12] | 姜超英, 李倩, 刘宁, 刘磊, 崔立真. 基于图对比学习的再入院预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1784-1792. |
| [13] | 杨雅莉, 黎英, 章育涛, 宋佩华. 面向人脸识别的多模态研究方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1645-1657. |
| [14] | 田海燕, 黄赛豪, 张栋, 李寿山. 视觉指导的分词和词性标注[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1488-1495. |
| [15] | 龙雨菲, 牟宇辰, 刘晔. 基于张量化图卷积网络和对比学习的多源数据表示学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1372-1378. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||