


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3187-3194.DOI: 10.11772/j.issn.1001-9081.2024101445
• 人工智能 • 上一篇
况世雄, 姚俊波, 陆佳炜, 王琪冰, 肖刚( )
)
收稿日期:2024-10-14
修回日期:2024-12-30
发布日期:2025-01-06
出版日期:2025-10-10
通讯作者:
肖刚
作者简介:况世雄(2000—),男,湖北武汉人,硕士研究生,主要研究方向:数据增强、模式识别基金资助:
Shixiong KUANG, Junbo YAO, Jiawei LU, Qibing WANG, Gang XIAO()
Received:2024-10-14
Revised:2024-12-30
Online:2025-01-06
Published:2025-10-10
Contact:
Gang XIAO
About author:KUANG Shixiong, born in 2000, M. S. candidate. His research interests include data augmentation, pattern recognition.Supported by:摘要:
目前,因缺乏足够多样化的异常行为数据,电梯乘客异常行为的识别方法存在准确率不高和泛化性能较差的问题。为解决这个问题,提出一种基于动态图卷积网络的行为数据增强方法(DGCN-BA)。首先,构建一种动态图卷积网络,用于捕捉电梯乘客行为中不同人体关节之间的空间关系和运动关联性;其次,利用这些特征进行姿势增强,获取更丰富和合理的姿势序列;最后,利用姿势序列在虚拟电梯场景中构建人物动作,生成大量电梯乘客异常行为视频数据。在公开数据集Human3.6M、3DHP和MuPoTS-3D,以及自建数据集上验证DGCN-BA的有效性。实验结果表明,相较于JMDA(Joint Mixing Data Augmentation)、DDPMs(Denoising Diffusion Probabilistic Models)数据增强方法,DGCN-BA在Human3.6M数据集上的平均每个关节位置误差(MPJPE)分别降低了2.9 mm和1.5 mm。可见,DGCN-BA能够更有效完成姿势估计任务,生成合理多样的异常行为数据,从而明显改善基于视频的电梯乘客异常行为识别效果。
中图分类号:
况世雄, 姚俊波, 陆佳炜, 王琪冰, 肖刚. 基于动态图卷积网络的电梯乘客异常行为数据增强方法[J]. 计算机应用, 2025, 45(10): 3187-3194.
Shixiong KUANG, Junbo YAO, Jiawei LU, Qibing WANG, Gang XIAO. Data augmentation method for abnormal elevator passenger behaviors based on dynamic graph convolutional network[J]. Journal of Computer Applications, 2025, 45(10): 3187-3194.

图1 人体骨骼关键点的结构
Fig. 1 Structure of human skeletal keypoints
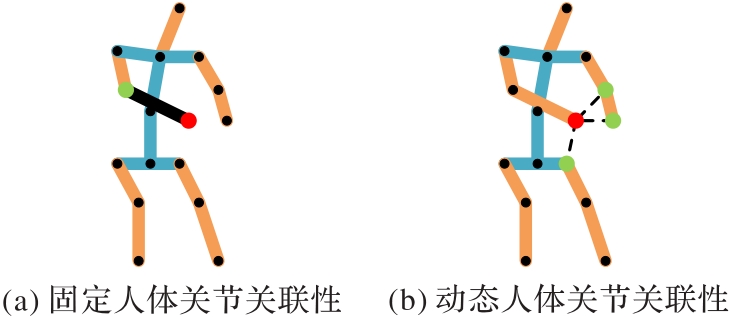
图2 人体关节的空间关联性
Fig. 2 Spatial correlation of human joints
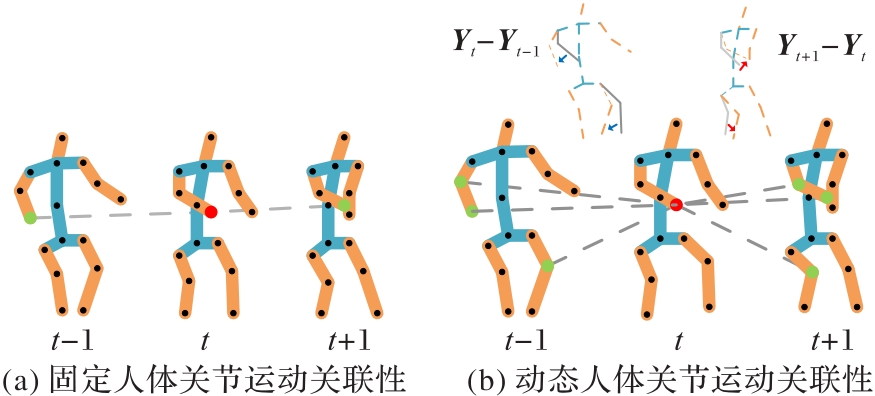
图3 人体关节的时间关联性
Fig. 3 Temporal correlation of human joints
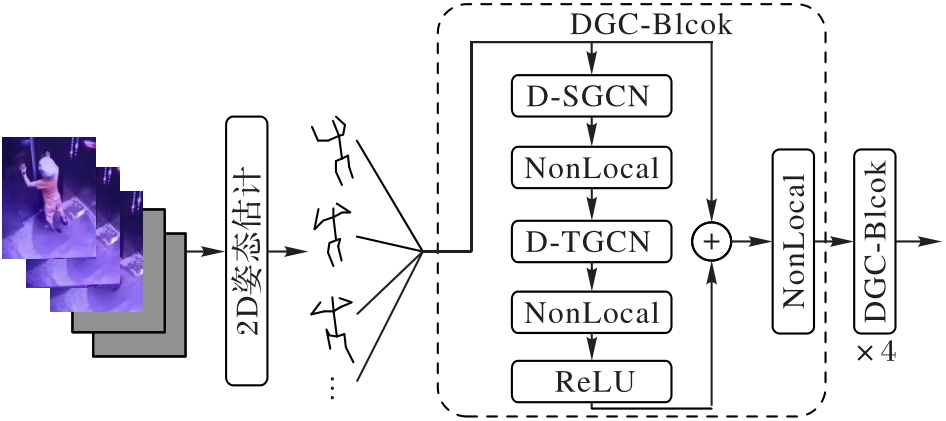
图4 动态图卷积网络的结构
Fig. 4 Structure of dynamic graph convolutional network
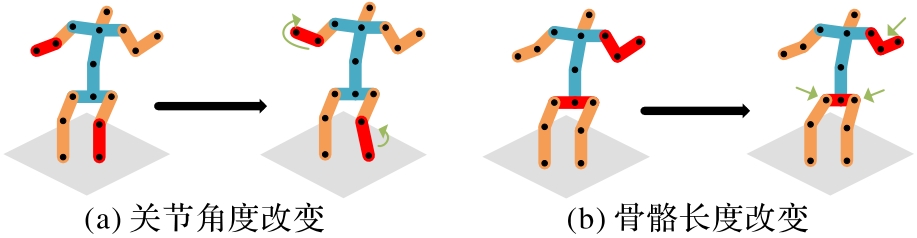
图5 姿势增强操作
Fig. 5 Pose augmentation operation
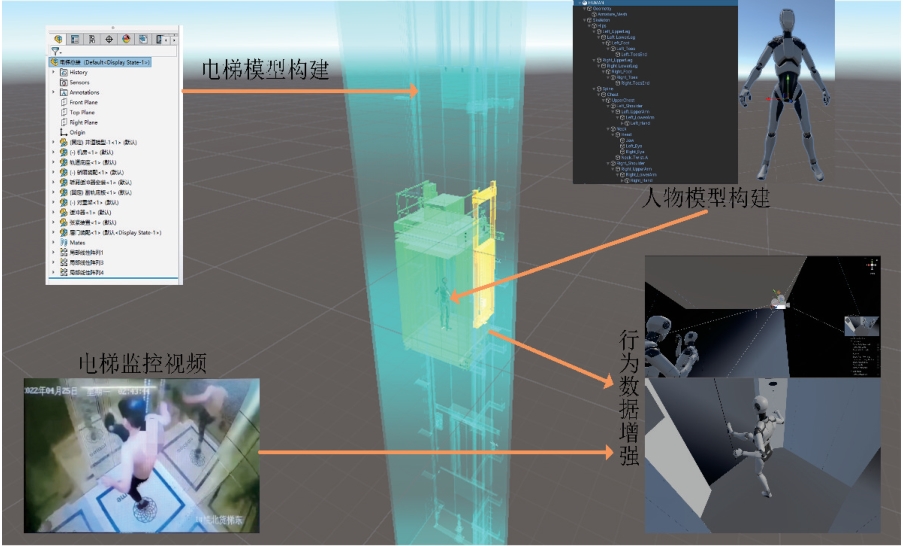
图6 虚拟电梯场景
Fig. 6 Virtual elevator scene
| 增强方法 | MPJPE | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 指引 | 讨论 | 吃饭 | 问候 | 打电话 | 拍照 | 摆姿势 | 购物 | 坐下 | 坐着 | 抽烟 | 等待 | 遛狗 | 走路 | 一起走 | 平均 | |
| 无 | 45.2 | 50.8 | 48.0 | 50.0 | 54.9 | 65.0 | 48.2 | 47.1 | 60.2 | 70.0 | 51.6 | 48.7 | 54.1 | 39.7 | 43.1 | 51.8 |
| Skelbumentations | 41.9 | 45.9 | 43.2 | 47.5 | 51.3 | 57.8 | 43.9 | 45.7 | 57.0 | 61.9 | 47.7 | 46.8 | 49.0 | 34.6 | 42.8 | 47.8 |
| JMDA | 40.0 | 46.8 | 41.7 | 45.8 | 49.4 | 58.4 | 41.4 | 46.0 | 53.4 | 59.3 | 47.8 | 44.9 | 48.3 | 31.8 | 43.0 | 46.5 |
| DDPMs | 37.9 | 44.2 | 42.1 | 46.1 | 48.9 | 56.5 | 40.2 | 44.3 | 52.8 | 57.9 | 45.5 | 45.8 | 44.6 | 29.9 | 39.7 | 45.1 |
| DGCN-BA | 37.3 | 43.1 | 42.9 | 43.9 | 47.4 | 57.9 | 37.2 | 43.9 | 50.0 | 53.2 | 44.3 | 42.0 | 45.1 | 26.8 | 38.6 | 43.6 |
表1 基于GraFormer的不同数据增强方法的姿势估计结果 (mm)
Tab. 1 Pose estimation results of different data augmentation methods based on GraFormer
| 增强方法 | MPJPE | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 指引 | 讨论 | 吃饭 | 问候 | 打电话 | 拍照 | 摆姿势 | 购物 | 坐下 | 坐着 | 抽烟 | 等待 | 遛狗 | 走路 | 一起走 | 平均 | |
| 无 | 45.2 | 50.8 | 48.0 | 50.0 | 54.9 | 65.0 | 48.2 | 47.1 | 60.2 | 70.0 | 51.6 | 48.7 | 54.1 | 39.7 | 43.1 | 51.8 |
| Skelbumentations | 41.9 | 45.9 | 43.2 | 47.5 | 51.3 | 57.8 | 43.9 | 45.7 | 57.0 | 61.9 | 47.7 | 46.8 | 49.0 | 34.6 | 42.8 | 47.8 |
| JMDA | 40.0 | 46.8 | 41.7 | 45.8 | 49.4 | 58.4 | 41.4 | 46.0 | 53.4 | 59.3 | 47.8 | 44.9 | 48.3 | 31.8 | 43.0 | 46.5 |
| DDPMs | 37.9 | 44.2 | 42.1 | 46.1 | 48.9 | 56.5 | 40.2 | 44.3 | 52.8 | 57.9 | 45.5 | 45.8 | 44.6 | 29.9 | 39.7 | 45.1 |
| DGCN-BA | 37.3 | 43.1 | 42.9 | 43.9 | 47.4 | 57.9 | 37.2 | 43.9 | 50.0 | 53.2 | 44.3 | 42.0 | 45.1 | 26.8 | 38.6 | 43.6 |
| 方法 | 3DHP | MuPoTS-3D | ||||||
|---|---|---|---|---|---|---|---|---|
| MPJPE | PA-MPJPE | MPJPE | PA-MPJPE | |||||
| 未使用 | 使用 | 未使用 | 使用 | 未使用 | 使用 | 未使用 | 使用 | |
| SemGCN | 110.3 | 99.7 | 74.2 | 66.5 | 160.3 | 148.7 | 112.0 | 102.6 |
| Baseline | 102.5 | 91.8 | 72.9 | 67.4 | 129.6 | 113.5 | 78.7 | 69.3 |
| TCN | 100.3 | 90.9 | 71.5 | 63.1 | 135.2 | 118.9 | 87.1 | 76.7 |
表2 在多种方法上运用DGCN-BA前后的姿势估计结果 (mm)
Tab. 2 Pose estimation results before and after using DGCN-BA on various methods
| 方法 | 3DHP | MuPoTS-3D | ||||||
|---|---|---|---|---|---|---|---|---|
| MPJPE | PA-MPJPE | MPJPE | PA-MPJPE | |||||
| 未使用 | 使用 | 未使用 | 使用 | 未使用 | 使用 | 未使用 | 使用 | |
| SemGCN | 110.3 | 99.7 | 74.2 | 66.5 | 160.3 | 148.7 | 112.0 | 102.6 |
| Baseline | 102.5 | 91.8 | 72.9 | 67.4 | 129.6 | 113.5 | 78.7 | 69.3 |
| TCN | 100.3 | 90.9 | 71.5 | 63.1 | 135.2 | 118.9 | 87.1 | 76.7 |
| 方法 | Human3.6M | |||
|---|---|---|---|---|
| MPJPE | PA-MPJPE | |||
| 实验组A | 51.0 | 36.7 | ||
| 实验组B | √ | 48.4 | 33.2 | |
| 实验组C | √ | 45.2 | 31.0 | |
| DGCN-BA | √ | √ | 43.6 | 29.8 |
表3 不同动态时空图卷积模块组合的表现 (mm)
Tab. 3 Performance of different combinations of dynamic spatio-temporal graph convolution modules
| 方法 | Human3.6M | |||
|---|---|---|---|---|
| MPJPE | PA-MPJPE | |||
| 实验组A | 51.0 | 36.7 | ||
| 实验组B | √ | 48.4 | 33.2 | |
| 实验组C | √ | 45.2 | 31.0 | |
| DGCN-BA | √ | √ | 43.6 | 29.8 |
| 方法 | Ⅰ | Ⅱ | Ⅲ | Human3.6M | MuPoTS-3D | ||
|---|---|---|---|---|---|---|---|
| MPJPE | PA-MPJPE | MPJPE | PA-MPJPE | ||||
| 实验组D | 51.8 | 37.1 | 82.7 | 69.1 | |||
| 实验组E | √ | √ | 45.5 | 30.8 | 76.3 | 63.2 | |
| 实验组F | √ | √ | 47.0 | 32.7 | 78.1 | 65.0 | |
| 实验组G | √ | √ | 46.5 | 31.6 | 74.7 | 60.6 | |
| DGCN-BA | √ | √ | √ | 43.6 | 29.8 | 72.9 | 59.5 |
表4 不同姿势增强模块组合的表现 (mm)
Tab. 4 Performance of different combinations of pose augmentation modules
| 方法 | Ⅰ | Ⅱ | Ⅲ | Human3.6M | MuPoTS-3D | ||
|---|---|---|---|---|---|---|---|
| MPJPE | PA-MPJPE | MPJPE | PA-MPJPE | ||||
| 实验组D | 51.8 | 37.1 | 82.7 | 69.1 | |||
| 实验组E | √ | √ | 45.5 | 30.8 | 76.3 | 63.2 | |
| 实验组F | √ | √ | 47.0 | 32.7 | 78.1 | 65.0 | |
| 实验组G | √ | √ | 46.5 | 31.6 | 74.7 | 60.6 | |
| DGCN-BA | √ | √ | √ | 43.6 | 29.8 | 72.9 | 59.5 |
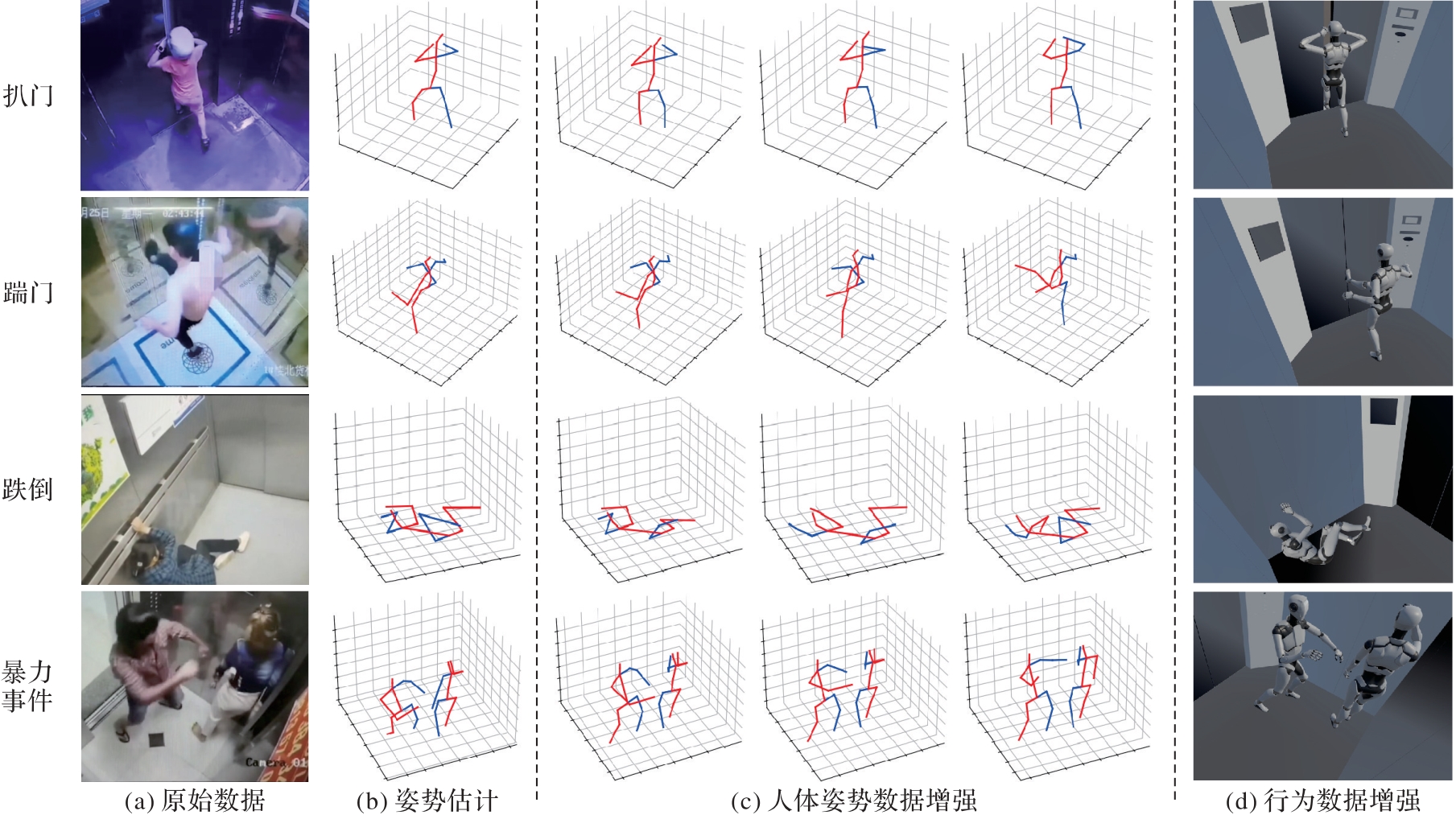
图7 电梯乘客异常行为数据增强
Fig. 7 Data augmentation for abnormal behaviors of elevator passengers
| 方法 | 准确率 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 跌倒 | 扒门 | 踹门 | 暴力事件 | 平均 | ||||||
| 原始 | 增强后 | 原始 | 增强后 | 原始 | 增强后 | 原始 | 增强后 | 原始 | 增强后 | |
| 文献[ | 96.2 | 97.9 | 93.4 | 95.1 | 91.9 | 93.6 | 89.3 | 92.2 | 92.7 | 94.7 |
| 文献[ | 96.9 | 98.1 | 95.1 | 96.0 | 94.7 | 96.2 | 90.9 | 94.5 | 94.4 | 96.2 |
| 文献[ | 97.9 | 99.0 | 95.4 | 96.5 | 97.8 | 98.3 | 95.7 | 97.0 | 96.7 | 97.7 |
表5 在多种方法上运用数据增强框架前后的行为识别结果 (%)
Tab. 5 Behavior recognition results before and after using data augmentation framework on various methods
| 方法 | 准确率 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 跌倒 | 扒门 | 踹门 | 暴力事件 | 平均 | ||||||
| 原始 | 增强后 | 原始 | 增强后 | 原始 | 增强后 | 原始 | 增强后 | 原始 | 增强后 | |
| 文献[ | 96.2 | 97.9 | 93.4 | 95.1 | 91.9 | 93.6 | 89.3 | 92.2 | 92.7 | 94.7 |
| 文献[ | 96.9 | 98.1 | 95.1 | 96.0 | 94.7 | 96.2 | 90.9 | 94.5 | 94.4 | 96.2 |
| 文献[ | 97.9 | 99.0 | 95.4 | 96.5 | 97.8 | 98.3 | 95.7 | 97.0 | 96.7 | 97.7 |
| [1] | 张连学,杜平虎.试谈电梯使用环节及相关环节的安全责任[J]. 中国电梯, 2020, 31(13):40-43. |
| ZHANG L X, DU P H. Discussion on safety responsibility of elevator use and related links[J]. China Elevator, 2020, 31(13): 40-43. | |
| [2] | ARROYO R, YEBES J J, BERGASA L M, et al. Expert video-surveillance system for real-time detection of suspicious behaviors in shopping malls[J]. Expert systems with Applications, 2015, 42(21): 7991-8005. |
| [3] | 吕蕾,庞辰. 基于图卷积网络的人体骨架行为识别方法综述[J]. 山东师范大学学报(自然科学版), 2024, 39(3):210-232. |
| LYU L, PANG C. A review of human skeleton action recognition methods based on graph convolutional network[J]. Journal of Shandong Normal University (Natural Sciences Edition), 2024, 39(3): 210-232. | |
| [4] | REN B, LIU M, DING R, et al. A survey on 3D skeleton-based action recognition using learning method[J]. Cyborg and Bionic Systems, 2024, 5: No.0100. |
| [5] | XU Q, ZHENG W, SONG Y, et al. Scene image and human skeleton-based dual-stream human action recognition[J]. Pattern Recognition Letters, 2021, 148: 136-145. |
| [6] | DAI C, LU S, LIU C, et al. A light-weight skeleton human action recognition model with knowledge distillation for edge intelligent surveillance applications[J]. Applied Soft Computing, 2024, 151: No.111166. |
| [7] | YANG M, WU C, GUO Y, et al. Transformer-based deep learning model and video dataset for unsafe action identification in construction projects[J]. Automation in Construction, 2023, 146: No.104703. |
| [8] | ALI R, HUTOMO I S, VAN L D, et al. A skeleton-based view-invariant framework for human fall detection in an elevator[C]// Proceedings of the 2022 IEEE International Conference on Industrial Technology. Piscataway: IEEE, 2022: 1-6. |
| [9] | LAN S, JIANG S, LI G. An elevator passenger behavior recognition method based on two-stream convolution neural network[J]. Journal of Physics: Conference Series, 2021, 1955: No.012089. |
| [10] | YANG J, WAN L, XU W, et al. 3D human pose estimation from a single image via exemplar augmentation[J]. Journal of Visual Communication Image Representation, 2019, 59: 371-379. |
| [11] | DU S, YUAN Z, LAI P, et al. JoyPose: jointly learning evolutionary data augmentation and anatomy-aware global-local representation for 3D human pose estimation[J]. Pattern Recognition Letters, 2024, 147: No.110116. |
| [12] | ALHAIJA H ABU, MUSTIKOVELA S K, MESCHEDER L, et al. Augmented reality meets computer vision: efficient data generation for urban driving scenes[J]. International Journal of Computer Vision, 2018, 126(9): 961-972. |
| [13] | PURKAIT P, ZHAO C, ZACH C. SPP-Net: deep absolute pose regression with synthetic views[EB/OL]. [2024-10-11].. |
| [14] | LI S, KE L, PRATAMA K, et al. Cascaded deep monocular 3D human pose estimation with evolutionary training data[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6172-6182. |
| [15] | GONG K, ZHANG J, FENG J. PoseAug: a differentiable pose augmentation framework for 3D human pose estimation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8571-8580. |
| [16] | ZHANG C, ZHU L, ZHANG S, et al. PAC-GAN: an effective pose augmentation scheme for unsupervised cross-view person re-identification[J]. Neurocomputing, 2020, 387: 22-39. |
| [17] | SHAH A, ROY A, SHAH K, et al. HaLP: hallucinating latent positives for skeleton-based self-supervised learning of actions[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 18846-18856. |
| [18] | ZHANG J, WANG Y, ZHOU Z, et al. Learning dynamical human-joint affinity for 3D pose estimation in videos[J]. IEEE Transactions on Image Processing, 2021, 30: 7914-7925. |
| [19] | WANDT B, ROSENHAHN B. RepNet: weakly supervised training of an adversarial reprojection network for 3D human pose estimation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7774-7783. |
| [20] | AKHTER I, BLACK M J. Pose-conditioned joint angle limits for 3D human pose reconstruction[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1446-1455. |
| [21] | LI R, LI X, HENG P A, et al. PointAugment: an auto-augmentation framework for point cloud classification[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6377-6386. |
| [22] | IONESCU C, PAPAVA D, OLARU V, et al. Human3.6M: large scale datasets and predictive methods for 3D human sensing in natural environments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1325-1339. |
| [23] | MEHTA D, RHODIN H, CASAS D, et al. Monocular 3D human pose estimation in the wild using improved CNN supervision[C]// Proceedings of the 2017 International Conference on 3D Vision. Piscataway: IEEE, 2017: 506-516. |
| [24] | MEHTA D, SOTNYCHENKO O, MUELLER F, et al. Single-shot multi-person 3D pose estimation from monocular RGB[C]// Proceedings of the 2018 International Conference on 3D Vision. Piscataway: IEEE, 2018: 120-130. |
| [25] | CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7103-7112. |
| [26] | ZHAO W, WANG W, TIAN Y. GraFormer: graph-oriented transformer for 3D pose estimation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 20406-20415. |
| [27] | CORMIER M, SCHMID Y, BEYERER J. Enhancing skeleton-based action recognition in real-world scenarios through realistic data augmentation[C]// Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2024: 300-309. |
| [28] | XIANG L, WANG Z. Joint mixing data augmentation for skeleton-based action recognition[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2025, 21(4): No.108. |
| [29] | JIANG Y, CHEN H, KO H. Spatial-temporal transformer-guided diffusion based data augmentation for efficient skeleton-based action recognition[EB/OL]. [2024-11-20].. |
| [30] | ZHAO L, PENG X, TIAN Y, et al. Semantic graph convolutional networks for 3D human pose regression[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3420-3430. |
| [31] | MARTINEZ J, HOSSAIN R, ROMERO J, et al. A simple yet effective baseline for 3D human pose estimation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2659-2668. |
| [32] | PAVLLO D, FEICHTENHOFER C, GRANGIER D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7745-7754. |
| [33] | SHI Y, GUO B, XU Y, et al. Recognition of abnormal human behavior in elevators based on CNN[C]// Proceedings of the 26th International Conference on Automation and Computing. Piscataway: IEEE, 2021: 1-6. |
| [34] | LEI J, SUN W, FANG Y, et al. A model for detecting abnormal elevator passenger behavior based on video classification[J]. Electronics, 2024, 13(13): No.2472. |
| [35] | SUN Z, XU B, WU D, et al. A real-time video surveillance and state detection approach for elevator cabs[C]// Proceedings of the 2019 International Conference on Control, Automation and Information Sciences. Piscataway: IEEE, 2019: 1-6. |
| [1] | 李莉, 宋涵, 刘培鹤, 陈汉林. 基于数据增强和残差网络的敏感信息命名实体识别[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2790-2797. |
| [2] | 梁一鸣, 范菁, 柴汶泽. 基于双向交叉注意力的多尺度特征融合情感分类[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2773-2782. |
| [3] | 石超, 周昱昕, 扶倩, 唐万宇, 何凌, 李元媛. 基于骨架和3D热图的注意缺陷多动障碍患者动作识别算法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3036-3044. |
| [4] | 王闯, 俞璐, 陈健威, 潘成, 杜文博. 开集域适应综述[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2727-2736. |
| [5] | 姜超英, 李倩, 刘宁, 刘磊, 崔立真. 基于图对比学习的再入院预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1784-1792. |
| [6] | 李道全, 徐正, 陈思慧, 刘嘉宇. 融合变分自编码器与自适应增强卷积神经网络的网络流量分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1841-1848. |
| [7] | 颜文婧, 王瑞东, 左敏, 张青川. 基于风味嵌入异构图层次学习的食谱推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1869-1878. |
| [8] | 李自亮, 朱广丽, 张玉雷, 刘佳佳, 焦熠璇, 张顺香. 集成句法与情感知识的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1724-1731. |
| [9] | 王泉, 陆啟想, 施珮. 用于交通流量预测的多图扩散注意力网络[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1472-1479. |
| [10] | 李雪莹, 杨琨, 涂国庆, 刘树波. 基于局部增强的时序数据对抗样本生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1573-1581. |
| [11] | 陈满, 杨小军, 杨慧敏. 基于图卷积网络和终点诱导的行人轨迹预测[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1480-1487. |
| [12] | 党伟超, 宋楚君, 高改梅, 刘春霞. 基于级联残差图卷积网络的多行为推荐[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1223-1231. |
| [13] | 田仁杰, 景明利, 焦龙, 王飞. 基于混合负采样的图对比学习推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1053-1060. |
| [14] | 孙海涛, 林佳瑜, 梁祖红, 郭洁. 结合标签混淆的中文文本分类数据增强技术[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1113-1119. |
| [15] | 盛坤, 王中卿. 基于大语言模型和数据增强的通感隐喻分析[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 794-800. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||