


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (4): 1113-1119.DOI: 10.11772/j.issn.1001-9081.2024040550
孙海涛1, 林佳瑜2( ), 梁祖红1,3, 郭洁1
), 梁祖红1,3, 郭洁1
收稿日期:2024-04-30
修回日期:2024-08-14
接受日期:2024-08-16
发布日期:2025-04-08
出版日期:2025-04-10
通讯作者:
林佳瑜
作者简介:孙海涛(1999—),男,湖南常德人,硕士研究生,CCF会员,主要研究方向:数据增强、数据挖掘;基金资助:
Haitao SUN1, Jiayu LIN2(), Zuhong LIANG1,3, Jie GUO1
Received:2024-04-30
Revised:2024-08-14
Accepted:2024-08-16
Online:2025-04-08
Published:2025-04-10
Contact:
Jiayu LIN
About author:SUN Haitao, born in 1999, M. S. candidate. His research interests include data augmentation, data mining.Supported by:摘要:
传统数据增强技术,如同义词替换、随机插入和随机删除等,可能改变文本的原始语义,甚至导致关键信息丢失。此外,在文本分类任务中,数据通常包含文本部分和标签部分,然而传统数据增强方法仅针对文本部分。为解决这些问题,提出一种结合标签混淆的数据增强(LCDA)技术,从文本和标签这2个基本方面入手,为数据提供全面的强化。在文本方面,通过对文本进行标点符号随机插入和替换以及句末标点符号补齐等增强,在保留全部文本信息和顺序的同时增加文本的多样性;在标签方面,采用标签混淆方法生成模拟标签分布替代传统的one-hot标签分布,以更好地反映实例和标签与标签之间的关系。在THUCNews(TsingHua University Chinese News)和Toutiao这2个中文新闻数据集构建的小样本数据集上分别结合TextCNN、TextRNN、BERT(Bidirectional Encoder Representations from Transformers)和RoBERTa-CNN(Robustly optimized BERT approach Convolutional Neural Network)文本分类模型的实验结果表明,与增强前相比,性能均得到显著提升。其中,在由THUCNews数据集构造的50-THU数据集上,4种模型结合LCDA技术后的准确率相较于增强前分别提高了1.19、6.87、3.21和2.89个百分点;相较于softEDA(Easy Data Augmentation with soft labels)方法增强的模型分别提高了0.78、7.62、1.75和1.28个百分点。通过在文本和标签这2个维度的处理结果可知,LCDA技术能显著提升模型的准确率,在数据量较少的应用场景中表现尤为突出。
中图分类号:
孙海涛, 林佳瑜, 梁祖红, 郭洁. 结合标签混淆的中文文本分类数据增强技术[J]. 计算机应用, 2025, 45(4): 1113-1119.
Haitao SUN, Jiayu LIN, Zuhong LIANG, Jie GUO. Data augmentation technique incorporating label confusion for Chinese text classification[J]. Journal of Computer Applications, 2025, 45(4): 1113-1119.
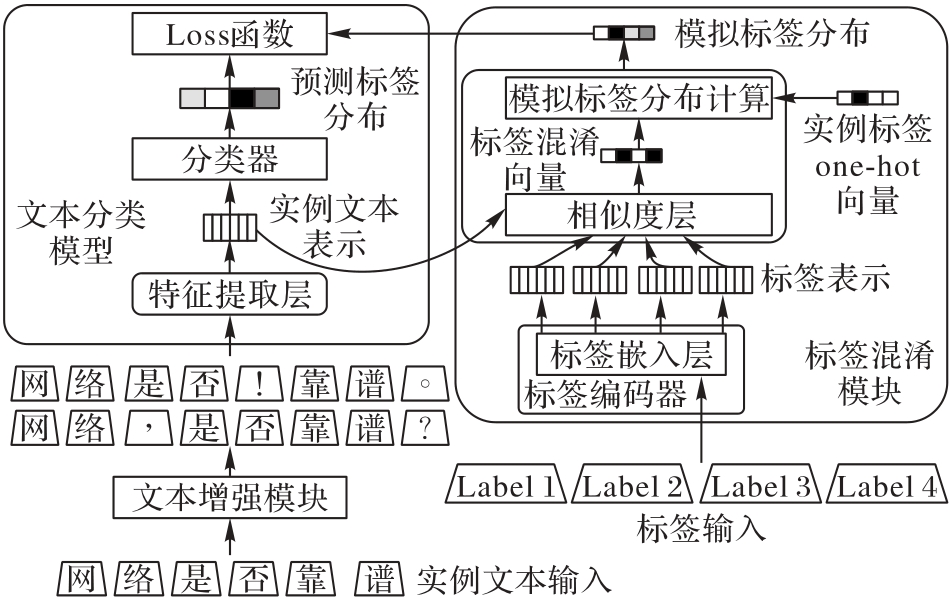
图1 LCDA整体框架
Fig. 1 Overall framework of LCDA
| 样本类型 | 样本内容 |
|---|---|
| 原始样本 | 两天价网站背后重重迷雾:做个网站究竟要多少钱 |
| 增强样本1 | 两:天价网站背后重重迷雾,,做个网站究竟要多少钱。 |
| 增强样本2 | 两!天价网站背后重!重迷雾:做个网站: 究竟要多少钱? |
| 增强样本3 | 两天价网。站背后重重迷,雾,;做个网站究竟要多少。 钱? |
| 增强样本4 | 两。天价网站背后重重迷雾:,做个?站究, 竟要多少钱? |
表1 使用文本增强后的示例
Tab. 1 Examples after text augmentation
| 样本类型 | 样本内容 |
|---|---|
| 原始样本 | 两天价网站背后重重迷雾:做个网站究竟要多少钱 |
| 增强样本1 | 两:天价网站背后重重迷雾,,做个网站究竟要多少钱。 |
| 增强样本2 | 两!天价网站背后重!重迷雾:做个网站: 究竟要多少钱? |
| 增强样本3 | 两天价网。站背后重重迷,雾,;做个网站究竟要多少。 钱? |
| 增强样本4 | 两。天价网站背后重重迷雾:,做个?站究, 竟要多少钱? |
| 错误样本 | 正确分类 | 错误分类 |
|---|---|---|
| 三联书店建起书香巷 | 科技 | 教育 |
| Google多项功能前晚集中“瘫痪” | 科技 | 社会 |
| 借款纠纷牵出房产商伪造公文开发楼盘案 | 社会 | 房地产 |
表2 分类错误样本的示例
Tab. 2 Examples of misclassified samples
| 错误样本 | 正确分类 | 错误分类 |
|---|---|---|
| 三联书店建起书香巷 | 科技 | 教育 |
| Google多项功能前晚集中“瘫痪” | 科技 | 社会 |
| 借款纠纷牵出房产商伪造公文开发楼盘案 | 社会 | 房地产 |
| 数据集 | 样本数 | 标签类别数 | ||
|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | ||
| THUCNews | 180 000 | 10 000 | 10 000 | 10 |
| 50-THU | 500 | 10 000 | 10 000 | 10 |
| 200-THU | 2 000 | 10 000 | 10 000 | 10 |
| 500-THU | 5 000 | 10 000 | 10 000 | 10 |
| Toutiao | 130 000 | 10 000 | 10 000 | 13 |
| 50-Toutiao | 650 | 10 000 | 10 000 | 13 |
| 200-Toutiao | 2 600 | 10 000 | 10 000 | 13 |
| 500-Toutiao | 6 500 | 10 000 | 10 000 | 13 |
表3 实验中使用的数据集
Tab. 3 Datasets used in experiments
| 数据集 | 样本数 | 标签类别数 | ||
|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | ||
| THUCNews | 180 000 | 10 000 | 10 000 | 10 |
| 50-THU | 500 | 10 000 | 10 000 | 10 |
| 200-THU | 2 000 | 10 000 | 10 000 | 10 |
| 500-THU | 5 000 | 10 000 | 10 000 | 10 |
| Toutiao | 130 000 | 10 000 | 10 000 | 13 |
| 50-Toutiao | 650 | 10 000 | 10 000 | 13 |
| 200-Toutiao | 2 600 | 10 000 | 10 000 | 13 |
| 500-Toutiao | 6 500 | 10 000 | 10 000 | 13 |
| 实际情况 | 预测正类 | 预测负类 |
|---|---|---|
| 实际正类 | 真正类 TP | 假负类 FN |
| 实际负类 | 假正类 FP | 真负类 TN |
表4 分类结果的混淆矩阵
Tab. 4 Confusion matrix of classification results
| 实际情况 | 预测正类 | 预测负类 |
|---|---|---|
| 实际正类 | 真正类 TP | 假负类 FN |
| 实际负类 | 假正类 FP | 真负类 TN |
| INSERT_PROB值 | 准确率/% | INSERT_PROB值 | 准确率/% |
|---|---|---|---|
| 0.1 | 83.99 | 0.4 | 82.69 |
| 0.2 | 84.26 | 0.5 | 83.11 |
| 0.3 | 83.69 |
表5 不同INSERT_PROB值的实验结果
Tab. 5 Experimental results of different INSERT_PROB values
| INSERT_PROB值 | 准确率/% | INSERT_PROB值 | 准确率/% |
|---|---|---|---|
| 0.1 | 83.99 | 0.4 | 82.69 |
| 0.2 | 84.26 | 0.5 | 83.11 |
| 0.3 | 83.69 |
| 扩充语句数 | THUCNews数据集准确率/% | ||
|---|---|---|---|
| 50-THU | 200-THU | 500-THU | |
| 0 | 62.30 | 73.12 | 80.27 |
| 1 | 66.47 | 76.48 | 81.63 |
| 2 | 67.28 | 77.87 | 81.20 |
| 4 | 69.17 | 77.48 | 80.64 |
表6 不同增强数量的实验结果
Tab. 6 Experimental results of different augmentation scales
| 扩充语句数 | THUCNews数据集准确率/% | ||
|---|---|---|---|
| 50-THU | 200-THU | 500-THU | |
| 0 | 62.30 | 73.12 | 80.27 |
| 1 | 66.47 | 76.48 | 81.63 |
| 2 | 67.28 | 77.87 | 81.20 |
| 4 | 69.17 | 77.48 | 80.64 |
| 平滑状态 | 标签向量 |
|---|---|
| 标签平滑前 | [1,0,0,0,0,0,0,0,0,0] |
| 标签平滑后 | [0.91,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.01] |
表7 使用标签平滑技术前后的标签
Tab. 7 Labels before and after applying label smoothing technique
| 平滑状态 | 标签向量 |
|---|---|
| 标签平滑前 | [1,0,0,0,0,0,0,0,0,0] |
| 标签平滑后 | [0.91,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.01] |
| 模型 | THUCNews数据集准确率 | ||
|---|---|---|---|
| 50-THU | 200-THU | 500-THU | |
| BERT | 81.05 | 87.21 | 88.91 |
| BERT+文本增强+LS | 83.27 | 87.74 | 89.28 |
| BERT+LCDA | 84.26 | 88.61 | 89.81 |
表8 标签混淆与标签平滑的对比实验结果 (%)
Tab. 8 Comparison experimental results of label confusion and label smoothing
| 模型 | THUCNews数据集准确率 | ||
|---|---|---|---|
| 50-THU | 200-THU | 500-THU | |
| BERT | 81.05 | 87.21 | 88.91 |
| BERT+文本增强+LS | 83.27 | 87.74 | 89.28 |
| BERT+LCDA | 84.26 | 88.61 | 89.81 |
| 模型 | 准确率 | |||||
|---|---|---|---|---|---|---|
| THUCNews数据集 | Toutiao数据集 | |||||
| 50-THU | 200-THU | 500-THU | 50-Toutiao | 200-Toutiao | 500-Toutiao | |
| TextCNN | 72.08 | 80.49 | 82.57 | 54.18 | 68.03 | 73.89 |
| TextCNN+AEDA | 72.55 | 79.99 | 82.32 | 55.24 | 68.23 | 74.25 |
| TextCNN+softEDA | 72.49 | 80.51 | 82.73 | 56.06 | 69.24 | 74.33 |
| TextCNN+LCDA | 73.27 | 80.89 | 82.84 | 57.13 | 69.22 | 74.47 |
| TextRNN | 62.30 | 73.12 | 80.27 | 41.76 | 60.95 | 68.15 |
| TextRNN+AEDA | 64.88 | 74.02 | 79.57 | 48.18 | 62.28 | 69.78 |
| TextRNN+softEDA | 61.55 | 74.45 | 78.72 | 44.58 | 61.72 | 70.22 |
| TextRNN+LCDA | 69.17 | 77.48 | 80.64 | 50.32 | 65.03 | 70.64 |
| BERT | 81.05 | 87.18 | 88.91 | 76.08 | 79.97 | 83.11 |
| BERT+AEDA | 81.31 | 87.21 | 87.52 | 76.69 | 80.35 | 82.43 |
| BERT+softEDA | 82.51 | 88.48 | 89.63 | 77.12 | 81.93 | 82.91 |
| BERT+LCDA | 84.26 | 88.61 | 89.81 | 78.98 | 83.15 | 84.33 |
| RoBERTa-CNN | 84.82 | 87.80 | 90.12 | 78.52 | 81.33 | 82.75 |
| RoBERTa-CNN+AEDA | 82.06 | 86.36 | 90.29 | 77.28 | 81.32 | 82.60 |
| RoBERTa-CNN+softEDA | 86.43 | 88.55 | 90.72 | 80.69 | 83.21 | 84.00 |
| RoBERTa-CNN+LCDA | 87.71 | 89.19 | 91.32 | 81.15 | 83.38 | 84.47 |
表9 不同数据增强方式的对比实验结果 (%)
Tab. 9 Comparison experimental results of different data augmentation methods
| 模型 | 准确率 | |||||
|---|---|---|---|---|---|---|
| THUCNews数据集 | Toutiao数据集 | |||||
| 50-THU | 200-THU | 500-THU | 50-Toutiao | 200-Toutiao | 500-Toutiao | |
| TextCNN | 72.08 | 80.49 | 82.57 | 54.18 | 68.03 | 73.89 |
| TextCNN+AEDA | 72.55 | 79.99 | 82.32 | 55.24 | 68.23 | 74.25 |
| TextCNN+softEDA | 72.49 | 80.51 | 82.73 | 56.06 | 69.24 | 74.33 |
| TextCNN+LCDA | 73.27 | 80.89 | 82.84 | 57.13 | 69.22 | 74.47 |
| TextRNN | 62.30 | 73.12 | 80.27 | 41.76 | 60.95 | 68.15 |
| TextRNN+AEDA | 64.88 | 74.02 | 79.57 | 48.18 | 62.28 | 69.78 |
| TextRNN+softEDA | 61.55 | 74.45 | 78.72 | 44.58 | 61.72 | 70.22 |
| TextRNN+LCDA | 69.17 | 77.48 | 80.64 | 50.32 | 65.03 | 70.64 |
| BERT | 81.05 | 87.18 | 88.91 | 76.08 | 79.97 | 83.11 |
| BERT+AEDA | 81.31 | 87.21 | 87.52 | 76.69 | 80.35 | 82.43 |
| BERT+softEDA | 82.51 | 88.48 | 89.63 | 77.12 | 81.93 | 82.91 |
| BERT+LCDA | 84.26 | 88.61 | 89.81 | 78.98 | 83.15 | 84.33 |
| RoBERTa-CNN | 84.82 | 87.80 | 90.12 | 78.52 | 81.33 | 82.75 |
| RoBERTa-CNN+AEDA | 82.06 | 86.36 | 90.29 | 77.28 | 81.32 | 82.60 |
| RoBERTa-CNN+softEDA | 86.43 | 88.55 | 90.72 | 80.69 | 83.21 | 84.00 |
| RoBERTa-CNN+LCDA | 87.71 | 89.19 | 91.32 | 81.15 | 83.38 | 84.47 |
| 模型 | 准确率 | 模型 | 准确率 |
|---|---|---|---|
| TextRNN | 62.30 | BERT | 81.05 |
| TextRNN+文本增强 | 65.88 | BERT+文本增强 | 83.25 |
| TextRNN+标签混淆 | 68.87 | BERT+标签混淆 | 83.17 |
| TextRNN+LCDA | 69.17 | BERT+LCDA | 84.26 |
表10 50-THU数据集上的消融实验结果 (%)
Tab. 10 Ablation experimental results on 50-THU dataset
| 模型 | 准确率 | 模型 | 准确率 |
|---|---|---|---|
| TextRNN | 62.30 | BERT | 81.05 |
| TextRNN+文本增强 | 65.88 | BERT+文本增强 | 83.25 |
| TextRNN+标签混淆 | 68.87 | BERT+标签混淆 | 83.17 |
| TextRNN+LCDA | 69.17 | BERT+LCDA | 84.26 |
| 1 | TANG D, QIN B, LIU T. Document modeling with gated recurrent neural network for sentiment classification[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1422-1432. |
| 2 | DING B, LIU L, BING L, et al. DAGA: data augmentation with a generation approach for low-resource tagging tasks[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 6045-6057. |
| 3 | KOBAYASHI S. Contextual augmentation: data augmentation by words with paradigmatic relations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) . Stroudsburg: ACL, 2018: 452-457. |
| 4 | CHEN H, HAN W, YANG D, et al. DoubleMix: simple interpolation-based data augmentation for text classification[C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 4622-4632. |
| 5 | 余新言,曾诚,王乾,等. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 计算机应用, 2024, 44(6): 1767-1774. |
| YU X Y, ZENG C, WANG Q, et al. Few-shot news topic classification method based on knowledge enhancement and prompt learning[J]. Journal of Computer Applications, 2024, 44(6): 1767-1774. | |
| 6 | SHORTEN C, KHOSHGOFTAAR T M, FURHT B. Text data augmentation for deep learning[J]. Journal of Big Data, 2021, 8: No.101. |
| 7 | MÜLLER R, KORNBLITH S, HINTON G E. When does label smoothing help?[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 4694-4703. |
| 8 | JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categorization[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2017: 562-570. |
| 9 | JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. Stroudsburg: ACL, 2016: 427-431. |
| 10 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 11 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]// Proceedings of the 34th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| 12 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2023-11-12].. |
| 13 | 姚迅,秦忠正,杨捷. 生成式标签对抗的文本分类模型[J]. 计算机应用, 2024, 44(6): 1781-1785. |
| YAO X, QIN Z Z, YANG J. Generative label adversarial text classification model[J]. Journal of Computer Applications, 2024, 44(6): 1781-1785. | |
| 14 | 张海丰,曾诚,潘列,等. 结合BERT和特征投影网络的新闻主题文本分类方法[J]. 计算机应用, 2022, 42(4): 1116-1124. |
| ZHANG H F, ZENG C, PAN L, et al. News topic text classification method based on BERT and feature projection network[J]. Journal of Computer Applications, 2022, 42(4): 1116-1124. | |
| 15 | ZOPH B, VASUDEVAN V, SHLENS J, et al. Learning transferable architectures for scalable image recognition[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8697-8710. |
| 16 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 17 | SONG Y, WANG J, JIANG T, et al. Targeted sentiment classification with attentional encoder network[C]// Proceedings of the 2019 International Conference on Artificial Neural Networks, LNCS 11730. Cham: Springer, 2019: 93-103. |
| 18 | LUKASIK M, BHOJANAPALLI S, MENON A K, et al. Does label smoothing mitigate label noise?[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 6448-6458. |
| 19 | GUO B, HAN S, HAN X, et al. Label confusion learning to enhance text classification models[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 12929-12936. |
| 20 | WEI J, ZOU K. EDA: easy data augmentation techniques for boosting performance on text classification tasks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 6382-6388. |
| 21 | KARIMI A, ROSSI L, PRATI A. AEDA: an easier data augmentation technique for text classification[C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg: ACL, 2021: 2748-2754. |
| 22 | WU X, GAO C, LIN M, et al. Text smoothing: enhance various data augmentation methods on text classification tasks[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 871-875. |
| 23 | LIU P, QIU X, HUANG X. Recurrent neural network for text classification with multi-task learning[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2016: 2873-2879. |
| 24 | KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1746-1751. |
| 25 | PUTRA D T, SETIAWAN E B. Sentiment analysis on social media with GloVe using combination CNN and RoBERTa[J]. Jurnal RESTI (Rekayasa Sistem dan Teknologi Informasi), 2023, 7(3): 457-563. |
| 26 | SEMARY N A, AHMED W, AMIN K, et al. Improving sentiment classification using a RoBERTa-based hybrid model[J]. Frontiers in Human Neuroscience, 2023, 17: No.1292010. |
| 27 | CHOI J, JIN K, LEE J, et al. softEDA: rethinking rule-based data augmentation with soft labels[EB/OL]. [2023-11-12].. |
| [1] | 田仁杰, 景明利, 焦龙, 王飞. 基于混合负采样的图对比学习推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1053-1060. |
| [2] | 杨杰, 尼玛扎西, 仁青东主, 祁晋东, 才让东知. 基于预训练模型标记器重构的藏文分词系统[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1199-1204. |
| [3] | 李嘉欣, 莫思特. 基于MiniRBT-LSTM-GAT与标签平滑的台区电力工单分类[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1356-1362. |
| [4] | 盛坤, 王中卿. 基于大语言模型和数据增强的通感隐喻分析[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 794-800. |
| [5] | 孙晨伟, 侯俊利, 刘祥根, 吕建成. 面向工程图纸理解的大语言模型提示生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 801-807. |
| [6] | 洪予晨, 李金龙. 基于预训练的符号化音乐生成[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 578-583. |
| [7] | 富坤, 应世聪, 郑婷婷, 屈佳捷, 崔静远, 李建伟. 面向小样本节点分类的图数据增强方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 392-402. |
| [8] | 严雪文, 黄章进. 基于对比学习的小样本图像分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 383-391. |
| [9] | 张嘉琳, 任庆桦, 毛启容. 利用全局-局部特征依赖的反欺骗说话人验证系统[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 308-317. |
| [10] | 杨莹, 郝晓燕, 于丹, 马垚, 陈永乐. 面向图神经网络模型提取攻击的图数据生成方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2483-2492. |
| [11] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [12] | 李晨阳, 张龙, 郑秋生, 钱少华. 基于扩散序列的多元可控文本生成[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2414-2420. |
| [13] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| [14] | 赵征宇, 罗景, 涂新辉. 基于多粒度语义融合的信息检索方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1775-1780. |
| [15] | 余新言, 曾诚, 王乾, 何鹏, 丁晓玉. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1767-1774. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||