《计算机应用》唯一官方网站 ›› 0, Vol. ›› Issue (): 55-60.DOI: 10.11772/j.issn.1001-9081.2024071061
吕晓斌, 黄浩森, 周鑫, 王近来, 何亚( )
)
Xiaobin LYU, Haosen HUANG, Xin ZHOU, Jinlai WANG, Ya HE()
摘要:
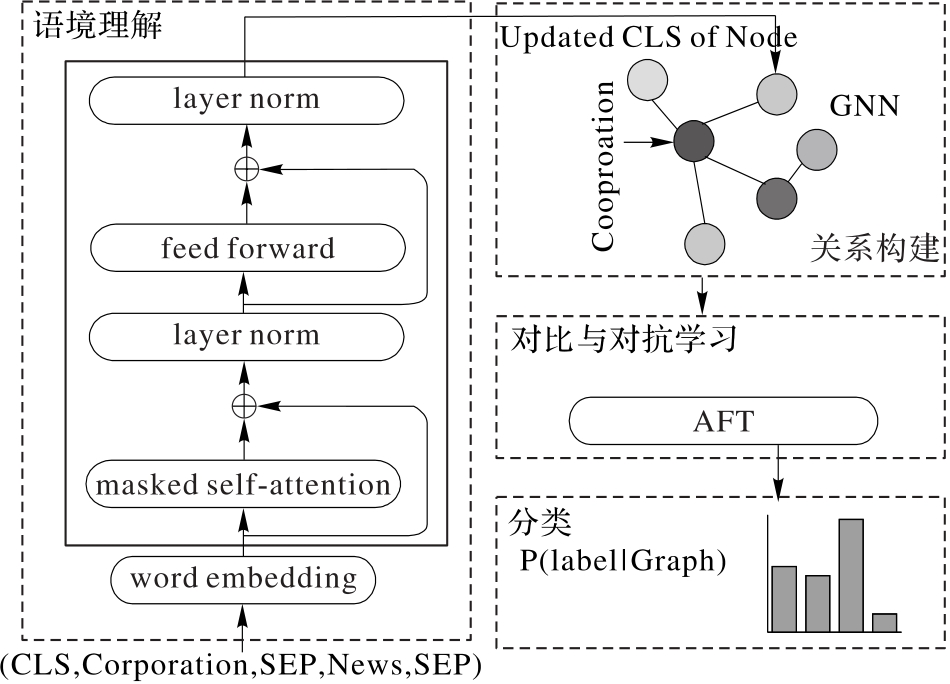
企业风险监测是维护区域经济稳定的重要保障。然而,经济数据结构复杂、逻辑关联多样,且涉及企业敏感信息,导致异构数据的获取与融合在风险分析中面临诸多挑战。此外,部分存在经营风险的企业可能谎报数据,这一行为严重削弱了风险识别的准确性和可靠性。为此,提出一种新的风险小样本学习方法——基于大语言模型的知识图谱对比学习(KGCLM)方法。首先,构建全面的企业风险知识图谱,涵盖风险事件、风险因子等多维语义信息,以全面刻画企业风险特征;其次,利用大语言模型(LLM)对风险知识进行词向量语义增强,从而一定程度上解决风险数据稀疏的问题,提升模型的语义理解能力;然后,设计异构图神经网络(GNN)模型对跨模态风险数据(包括企业注册、投资、司法、舆情等)进行统一建模和表征学习,实现多源异构数据的有效融合;最后,引入对比学习机制,通过构建正负样本对提升模型对相似样本的一致性表示能力和对不同样本的区分能力,显著增强模型在面对谎报数据时的鲁棒性。在中小企业风险数据集(SERD)和中国上市公司风险数据集(CERD)上的实验结果表明,KGCLM在准确率和各类F1分数均显著优于对比实验中的基线模型。在SERD上,KGCLM的准确率达到了90.37%;在CERD上,KGCLM的准确率为74.51%,验证了所提方法在处理数据稀缺和欺骗性数据干扰方面的优越性能。
中图分类号: