


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1264-1274.DOI: 10.11772/j.issn.1001-9081.2025050543
• 多媒体计算与计算机仿真 • 上一篇
张永兵1, 闫丽蓉1, 唐晓芬1,2( )
)
收稿日期:2025-05-19
修回日期:2025-07-25
接受日期:2025-08-01
发布日期:2025-08-08
出版日期:2026-04-10
通讯作者:
唐晓芬
作者简介:张永兵(1999—),男,甘肃天水人,硕士研究生,CCF会员,主要研究方向:域泛化目标检测基金资助:
Yongbing ZHANG1, Lirong YAN1, Xiaofen TANG1,2()
Received:2025-05-19
Revised:2025-07-25
Accepted:2025-08-01
Online:2025-08-08
Published:2026-04-10
Contact:
Xiaofen TANG
About author:ZHANG Yongbing, born in 1999, M. S. candidate. His research interests include domain generalized object detection.Supported by:摘要:
针对现有基于视觉语言的单域泛化模型采用固定的单向文本引导视觉局部对齐操作,导致局部?全局上下文建模能力不足的问题,提出一种渐进式双阶段模态交互(PDMI)框架。PDMI能够在模态内以多层次方式提取全局域不变特征,在模态间充分挖掘视觉和文本互补语义,以获得细粒度语义知识。首先,结合固定域无关提示和可学习的自适应域提示(ADP)引导样本获得对特定域的语义感知能力;同时,在视觉主干网络ResNet-101基础上,设计多层级的模态内交互(MIMI)模块,基于自适应视觉提示引导,对源域图像进行模态内Mamba交互(IMMI)以提取图像的全局域不变特征,改善视觉特征表示的分布。其次,提出跨模态双向交互融合(CMBIF)机制,提取并对齐细粒度的跨模态特征,以视觉或文本双向引导实现细粒度模态间交互。最后,采用跨模态自适应融合(CMAF)模块自动搜索模态间信息的最佳组合,进一步减小模态间交互的冗余特征。在3个具有挑战性的领域偏移数据集Diverse Weather、Virtual-to-Reality和UAV-OD上的实验结果显示:PDMI在目标域上的平均精度(mPT)比C-Gap、SRCD(Semantic Reasoning with Compound Domains)和FDD(Frequency Domain Disentanglement)方法分别平均提高了2.0、4.0和4.2个百分点。可见,PDMI能够有效提取全局?局部域不变特征提升对未见目标域的泛化能力,这对目标域和源域存在显著分布偏移且目标域数据受限的场景至关重要。
中图分类号:
张永兵, 闫丽蓉, 唐晓芬. 渐进式双阶段模态交互的单域泛化目标检测[J]. 计算机应用, 2026, 46(4): 1264-1274.
Yongbing ZHANG, Lirong YAN, Xiaofen TANG. Progressive dual-stage modality interaction for single-domain generalized object detection[J]. Journal of Computer Applications, 2026, 46(4): 1264-1274.
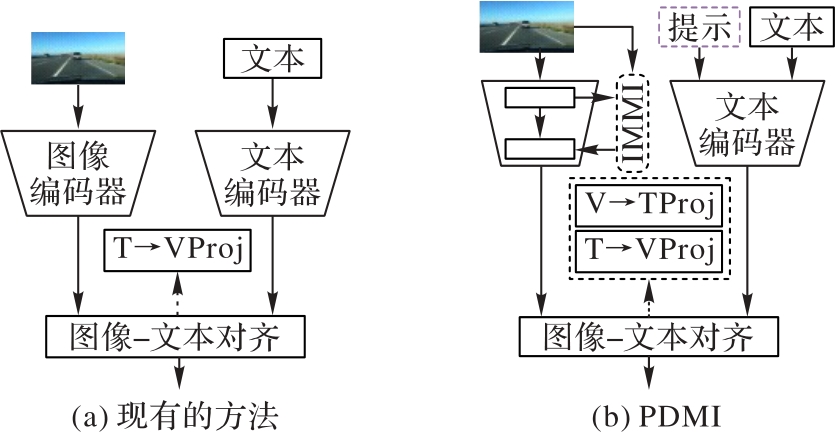
图1 现有方法与PDMI的对比
Fig. 1 Comparison between existing methods and PDMI
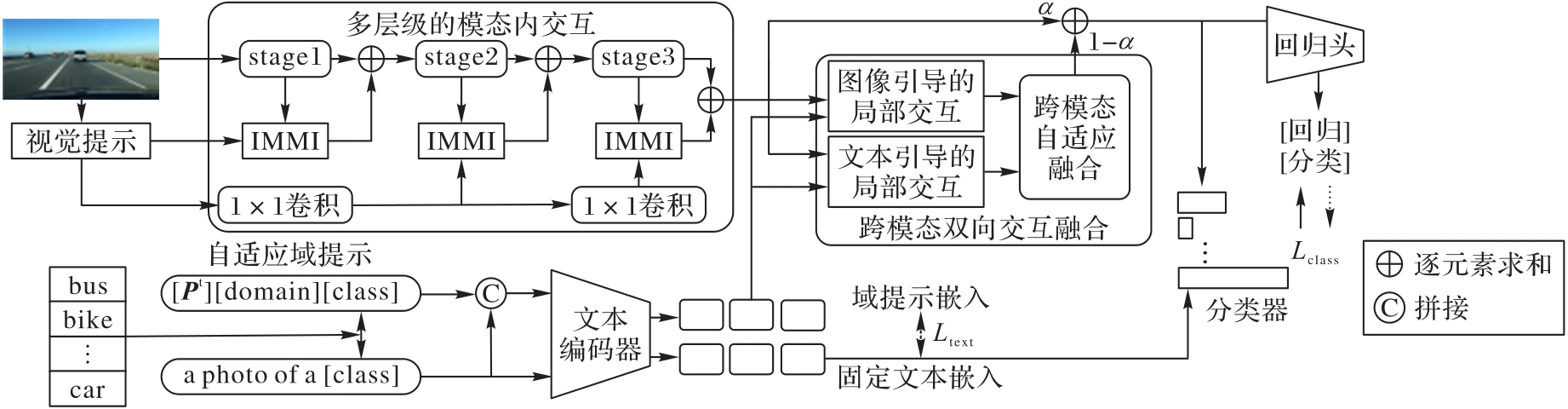
图2 PDMI的结构
Fig. 2 Structure of PDMI
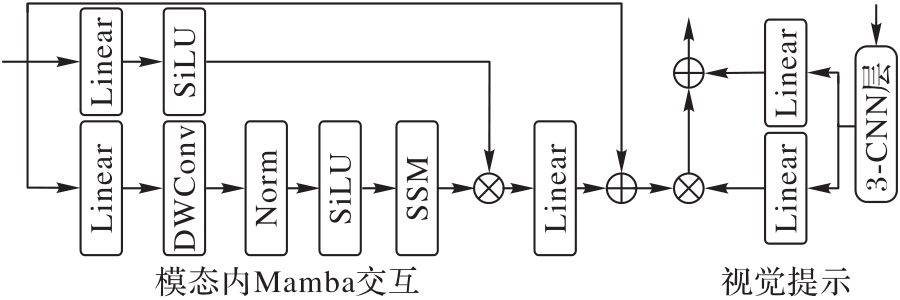
图3 图像提示引导的IMMI模块的结构
Fig. 3 Structure of visual prompt guided IMMI module
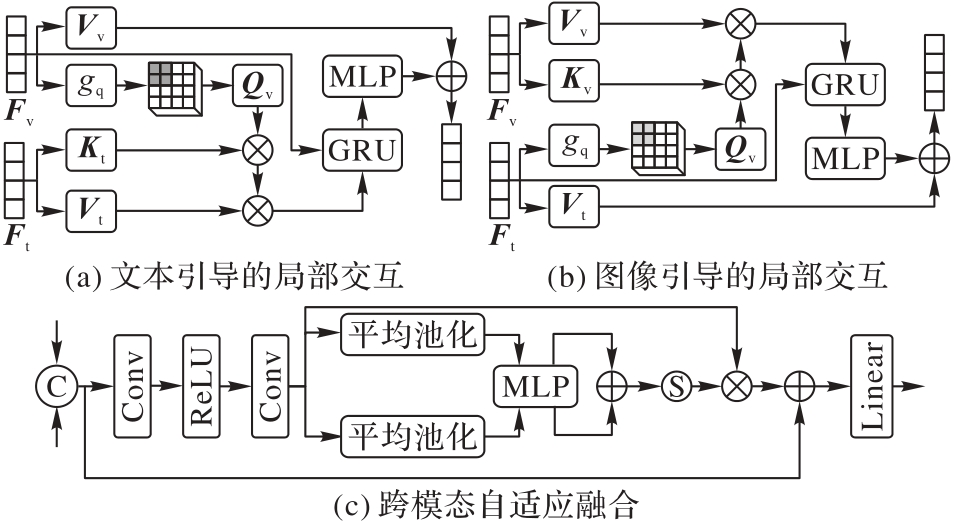
图4 CMBIF机制的结构
Fig. 4 Structure of CMBIF mechanism
| 方法 | mAP | mPT | ||||
|---|---|---|---|---|---|---|
| Daytime Clear | Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||
| Faster R-CNN[ | 48.1 | 34.4 | 26.0 | 12.4 | 32.0 | 26.2 |
| SW[ | 50.6 | 33.4 | 26.3 | 13.7 | 30.8 | 26.1 |
| IBN-Net[ | 49.7 | 32.1 | 26.1 | 14.3 | 29.6 | 25.5 |
| IterNorm[ | 43.9 | 29.6 | 22.8 | 12.6 | 28.4 | 23.4 |
| ISW[ | 51.3 | 33.2 | 25.9 | 14.1 | 31.8 | 26.3 |
| SHADE[ | — | 33.9 | 29.5 | 16.8 | 33.4 | 28.4 |
| CDSD[ | 56.1 | 36.6 | 28.2 | 16.6 | 33.5 | 28.7 |
| SRCD[ | — | 28.8 | 17.0 | 35.9 | 29.6 | |
| C-Gap*[ | 52.0 | 36.3 | ||||
| 本文方法 | 38.4 | 33.3 | 18.5 | 39.1 | 32.3 | |
表1 在Diverse Weather数据集上单域泛化目标检测性能比较 (%)
Tab. 1 Performance comparison of single-domain generalized object detection on Diverse Weather dataset
| 方法 | mAP | mPT | ||||
|---|---|---|---|---|---|---|
| Daytime Clear | Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||
| Faster R-CNN[ | 48.1 | 34.4 | 26.0 | 12.4 | 32.0 | 26.2 |
| SW[ | 50.6 | 33.4 | 26.3 | 13.7 | 30.8 | 26.1 |
| IBN-Net[ | 49.7 | 32.1 | 26.1 | 14.3 | 29.6 | 25.5 |
| IterNorm[ | 43.9 | 29.6 | 22.8 | 12.6 | 28.4 | 23.4 |
| ISW[ | 51.3 | 33.2 | 25.9 | 14.1 | 31.8 | 26.3 |
| SHADE[ | — | 33.9 | 29.5 | 16.8 | 33.4 | 28.4 |
| CDSD[ | 56.1 | 36.6 | 28.2 | 16.6 | 33.5 | 28.7 |
| SRCD[ | — | 28.8 | 17.0 | 35.9 | 29.6 | |
| C-Gap*[ | 52.0 | 36.3 | ||||
| 本文方法 | 38.4 | 33.3 | 18.5 | 39.1 | 32.3 | |
| 方法 | Night Sunny | Dusk Rainy | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP0.5 | mAP | AP0.5 | mAP | |||||||||||||
| bus | bike | car | mot. | pers. | rid. | tru. | bus | bike | car | mot. | pers. | rid. | tru. | |||
| Faster R-CNN[ | 34.7 | 32.0 | 56.6 | 13.6 | 37.4 | 27.6 | 38.6 | 34.4 | 28.5 | 20.3 | 58.2 | 6.5 | 23.4 | 11.3 | 33.9 | 26.0 |
| SW[ | 29.2 | 49.8 | 16.6 | 31.5 | 28.0 | 40.2 | 33.4 | 35.2 | 16.7 | 50.1 | 10.4 | 20.1 | 13.0 | 38.8 | 26.3 | |
| IBN-Net[ | 37.8 | 27.3 | 49.6 | 15.1 | 29.2 | 27.1 | 38.9 | 32.1 | 37.0 | 14.8 | 50.3 | 11.4 | 17.3 | 13.3 | 38.4 | 26.1 |
| IterNorm[ | 38.5 | 23.5 | 38.9 | 15.8 | 26.6 | 25.9 | 38.1 | 29.6 | 32.9 | 14.1 | 38.9 | 11.0 | 15.5 | 11.6 | 35.7 | 22.8 |
| ISW[ | 38.5 | 28.5 | 49.6 | 15.4 | 31.9 | 27.5 | 41.3 | 33.2 | 34.7 | 16.0 | 50.0 | 11.1 | 17.8 | 12.6 | 38.8 | 25.9 |
| CDSD[ | 40.6 | 35.1 | 50.7 | 19.7 | 34.7 | 32.1 | 36.6 | 37.1 | 19.6 | 50.9 | 19.7 | 16.3 | 28.2 | |||
| SRCD[ | 13.1 | 32.5 | 52.3 | 34.8 | 42.9 | 21.4 | 50.6 | 11.9 | 20.1 | 40.5 | 28.8 | |||||
| C-Gap*[ | 37.6 | 14.7 | 28.0 | 42.0 | 36.3 | 34.0 | 12.7 | 39.9 | ||||||||
| 本文方法 | 35.6 | 58.7 | 21.4 | 39.8 | 30.7 | 43.7 | 38.4 | 39.7 | 25.3 | 60.7 | 17.5 | 29.9 | 18.9 | 41.3 | 33.3 | |
表2 在目标域Night Sunny和Dusk Rainy上每个类别的检测性能比较 (%)
Tab. 2 Comparison of detection performance of each class on target domains Night Sunny and Dusk Rainy
| 方法 | Night Sunny | Dusk Rainy | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP0.5 | mAP | AP0.5 | mAP | |||||||||||||
| bus | bike | car | mot. | pers. | rid. | tru. | bus | bike | car | mot. | pers. | rid. | tru. | |||
| Faster R-CNN[ | 34.7 | 32.0 | 56.6 | 13.6 | 37.4 | 27.6 | 38.6 | 34.4 | 28.5 | 20.3 | 58.2 | 6.5 | 23.4 | 11.3 | 33.9 | 26.0 |
| SW[ | 29.2 | 49.8 | 16.6 | 31.5 | 28.0 | 40.2 | 33.4 | 35.2 | 16.7 | 50.1 | 10.4 | 20.1 | 13.0 | 38.8 | 26.3 | |
| IBN-Net[ | 37.8 | 27.3 | 49.6 | 15.1 | 29.2 | 27.1 | 38.9 | 32.1 | 37.0 | 14.8 | 50.3 | 11.4 | 17.3 | 13.3 | 38.4 | 26.1 |
| IterNorm[ | 38.5 | 23.5 | 38.9 | 15.8 | 26.6 | 25.9 | 38.1 | 29.6 | 32.9 | 14.1 | 38.9 | 11.0 | 15.5 | 11.6 | 35.7 | 22.8 |
| ISW[ | 38.5 | 28.5 | 49.6 | 15.4 | 31.9 | 27.5 | 41.3 | 33.2 | 34.7 | 16.0 | 50.0 | 11.1 | 17.8 | 12.6 | 38.8 | 25.9 |
| CDSD[ | 40.6 | 35.1 | 50.7 | 19.7 | 34.7 | 32.1 | 36.6 | 37.1 | 19.6 | 50.9 | 19.7 | 16.3 | 28.2 | |||
| SRCD[ | 13.1 | 32.5 | 52.3 | 34.8 | 42.9 | 21.4 | 50.6 | 11.9 | 20.1 | 40.5 | 28.8 | |||||
| C-Gap*[ | 37.6 | 14.7 | 28.0 | 42.0 | 36.3 | 34.0 | 12.7 | 39.9 | ||||||||
| 本文方法 | 35.6 | 58.7 | 21.4 | 39.8 | 30.7 | 43.7 | 38.4 | 39.7 | 25.3 | 60.7 | 17.5 | 29.9 | 18.9 | 41.3 | 33.3 | |
| 方法 | Night Rainy | Daytime Foggy | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP0.5 | mAP | AP0.5 | mAP | |||||||||||||
| bus | bike | car | mot. | pers. | rid. | tru. | bus | bike | car | mot. | pers. | rid. | tru. | |||
| Faster R-CNN[ | 16.8 | 6.9 | 26.3 | 0.6 | 11.6 | 9.4 | 15.4 | 12.4 | 28.1 | 29.7 | 49.7 | 26.3 | 33.2 | 35.5 | 21.5 | 32.0 |
| SW[ | 22.3 | 7.8 | 27.6 | 0.2 | 10.3 | 10.0 | 17.7 | 13.7 | 30.6 | 26.2 | 44.6 | 25.1 | 30.7 | 34.6 | 23.6 | 30.8 |
| IBN-Net[ | 10.0 | 28.4 | 0.9 | 8.3 | 9.8 | 18.1 | 14.3 | 29.9 | 26.1 | 44.5 | 24.4 | 26.2 | 33.5 | 22.4 | 29.6 | |
| IterNorm[ | 21.4 | 6.7 | 22.0 | 0.9 | 9.1 | 10.6 | 17.6 | 12.6 | 29.7 | 21.8 | 42.4 | 24.4 | 26.0 | 33.3 | 21.6 | 28.4 |
| ISW[ | 22.5 | 11.4 | 26.9 | 0.4 | 9.9 | 9.8 | 17.5 | 14.1 | 29.5 | 26.4 | 49.2 | 27.9 | 30.7 | 34.8 | 24.0 | 31.8 |
| CDSD[ | 24.4 | 11.6 | 29.5 | 10.5 | 11.4 | 19.2 | 16.6 | 32.9 | 28.0 | 48.8 | 29.8 | 32.5 | 38.2 | 24.1 | 33.5 | |
| SRCD[ | 26.5 | 0.8 | 10.2 | 24.0 | 17.0 | 36.4 | 30.1 | 52.4 | 31.3 | 33.4 | 40.1 | 35.9 | ||||
| C-Gap*[ | 23.5 | 10.8 | 32.0 | 9.0 | 12.9 | 20.4 | 21.8 | |||||||||
| 本文方法 | 23.9 | 15.1 | 33.7 | 9.9 | 12.9 | 12.4 | 18.5 | 35.3 | 33.7 | 58.8 | 34.8 | 39.7 | 43.5 | 27.9 | 39.1 | |
表3 在目标域Night Rainy和Daytime Foggy上每个类别的检测性能比较 (%)
Tab. 3 Comparison of detection performance of each class on target domains Night Rainy and Daytime Foggy
| 方法 | Night Rainy | Daytime Foggy | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP0.5 | mAP | AP0.5 | mAP | |||||||||||||
| bus | bike | car | mot. | pers. | rid. | tru. | bus | bike | car | mot. | pers. | rid. | tru. | |||
| Faster R-CNN[ | 16.8 | 6.9 | 26.3 | 0.6 | 11.6 | 9.4 | 15.4 | 12.4 | 28.1 | 29.7 | 49.7 | 26.3 | 33.2 | 35.5 | 21.5 | 32.0 |
| SW[ | 22.3 | 7.8 | 27.6 | 0.2 | 10.3 | 10.0 | 17.7 | 13.7 | 30.6 | 26.2 | 44.6 | 25.1 | 30.7 | 34.6 | 23.6 | 30.8 |
| IBN-Net[ | 10.0 | 28.4 | 0.9 | 8.3 | 9.8 | 18.1 | 14.3 | 29.9 | 26.1 | 44.5 | 24.4 | 26.2 | 33.5 | 22.4 | 29.6 | |
| IterNorm[ | 21.4 | 6.7 | 22.0 | 0.9 | 9.1 | 10.6 | 17.6 | 12.6 | 29.7 | 21.8 | 42.4 | 24.4 | 26.0 | 33.3 | 21.6 | 28.4 |
| ISW[ | 22.5 | 11.4 | 26.9 | 0.4 | 9.9 | 9.8 | 17.5 | 14.1 | 29.5 | 26.4 | 49.2 | 27.9 | 30.7 | 34.8 | 24.0 | 31.8 |
| CDSD[ | 24.4 | 11.6 | 29.5 | 10.5 | 11.4 | 19.2 | 16.6 | 32.9 | 28.0 | 48.8 | 29.8 | 32.5 | 38.2 | 24.1 | 33.5 | |
| SRCD[ | 26.5 | 0.8 | 10.2 | 24.0 | 17.0 | 36.4 | 30.1 | 52.4 | 31.3 | 33.4 | 40.1 | 35.9 | ||||
| C-Gap*[ | 23.5 | 10.8 | 32.0 | 9.0 | 12.9 | 20.4 | 21.8 | |||||||||
| 本文方法 | 23.9 | 15.1 | 33.7 | 9.9 | 12.9 | 12.4 | 18.5 | 35.3 | 33.7 | 58.8 | 34.8 | 39.7 | 43.5 | 27.9 | 39.1 | |
| 方法 | mAP | mPT | ||
|---|---|---|---|---|
| Cityscapes | BDD100K | KITTI | ||
| Faster R-CNN[ | 34.3 | 29.8 | 47.0 | 37.0 |
| SW[ | 34.5 | 30.0 | 47.2 | 37.2 |
| IBN-Net[ | 33.2 | 25.7 | 48.1 | 35.7 |
| IterNorm[ | 34.3 | 30.3 | 46.9 | 37.2 |
| ISW[ | 40.4 | 28.5 | 55.0 | 41.3 |
| SHADE[ | 40.9 | 30.3 | 55.6 | 42.3 |
| CDSD[ | 35.2 | 27.4 | 47.8 | 36.8 |
| SRCD[ | ||||
| 本文方法 | 48.4 | 34.9 | 63.8 | 49.0 |
表4 在Virtual-To-Reality数据集上单域泛化目标检测性能比较 (%)
Tab. 4 Performance comparison of single-domain generalized object detection on Virtual-To-Reality dataset
| 方法 | mAP | mPT | ||
|---|---|---|---|---|
| Cityscapes | BDD100K | KITTI | ||
| Faster R-CNN[ | 34.3 | 29.8 | 47.0 | 37.0 |
| SW[ | 34.5 | 30.0 | 47.2 | 37.2 |
| IBN-Net[ | 33.2 | 25.7 | 48.1 | 35.7 |
| IterNorm[ | 34.3 | 30.3 | 46.9 | 37.2 |
| ISW[ | 40.4 | 28.5 | 55.0 | 41.3 |
| SHADE[ | 40.9 | 30.3 | 55.6 | 42.3 |
| CDSD[ | 35.2 | 27.4 | 47.8 | 36.8 |
| SRCD[ | ||||
| 本文方法 | 48.4 | 34.9 | 63.8 | 49.0 |
| 方法 | UAVDT Nighttime | UAVDT Foggy | Visdrone Nighttime | mPT | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP0.5 | AP0.75 | AP | AP0.5 | AP0.75 | AP | AP0.5 | AP0.75 | AP | AP0.5 | AP0.75 | AP | |
| Faster R-CNN[ | 58.8 | 23.8 | 28.3 | 24.6 | 9.1 | 12.4 | 34.3 | 14.2 | 16.7 | 39.2 | 15.7 | 19.1 |
| SW[ | 55.7 | 21.1 | 26.0 | 23.9 | 8.6 | 11.4 | 32.8 | 13.6 | 15.0 | 37.5 | 14.4 | 17.5 |
| IBN-Net[ | 63.3 | 25.5 | 31.3 | 31.3 | 8.1 | 12.7 | 40.3 | 17.9 | 19.5 | 45.0 | 17.2 | 21.2 |
| IterNorm[ | 56.5 | 22.1 | 27.7 | 29.2 | 9.1 | 12.7 | 28.0 | 13.2 | 14.6 | 37.9 | 14.8 | 18.3 |
| JiGen[ | 58.6 | 24.1 | 29.2 | 27.9 | 9.1 | 12.3 | 34.5 | 14.5 | 17.6 | 40.3 | 15.9 | 19.7 |
| RSC[ | 50.6 | 12.7 | 21.0 | 21.4 | 9.1 | 9.5 | 27.2 | 11.3 | 13.6 | 33.1 | 11.0 | 14.7 |
| StableNet[ | 61.4 | 27.2 | 31.0 | 31.4 | 10.2 | 14.4 | 32.7 | 14.7 | 16.4 | 41.8 | 17.4 | 20.6 |
| FACT[ | 58.8 | 25.7 | 29.5 | 29.0 | 9.1 | 13.0 | 35.0 | 14.7 | 17.6 | 40.9 | 16.5 | 20.0 |
| DIDN[ | 63.5 | 29.2 | 32.4 | 35.4 | 10.8 | 34.8 | 15.3 | 18.2 | 44.6 | 18.4 | 22.0 | |
| CDSD[ | 61.5 | 26.8 | 30.9 | 29.7 | 9.1 | 14.5 | 34.4 | 15.0 | 17.9 | 41.9 | 16.9 | 21.1 |
| MAD[ | 64.4 | 27.4 | 33.6 | 30.2 | 9.1 | 14.8 | 40.3 | 19.3 | 21.0 | 45.0 | 18.6 | 23.1 |
| FDD[ | 32.4 | 16.8 | ||||||||||
| 本文方法 | 66.2 | 34.7 | 37.6 | 11.0 | 16.8 | 55.4 | 30.8 | 31.5 | 53.0 | 23.9 | 27.7 | |
表5 在UAV-OD数据集上单域泛化目标检测性能比较 (%)
Tab. 5 Performance comparison of single-domain generalized object detection on UAV-OD dataset
| 方法 | UAVDT Nighttime | UAVDT Foggy | Visdrone Nighttime | mPT | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP0.5 | AP0.75 | AP | AP0.5 | AP0.75 | AP | AP0.5 | AP0.75 | AP | AP0.5 | AP0.75 | AP | |
| Faster R-CNN[ | 58.8 | 23.8 | 28.3 | 24.6 | 9.1 | 12.4 | 34.3 | 14.2 | 16.7 | 39.2 | 15.7 | 19.1 |
| SW[ | 55.7 | 21.1 | 26.0 | 23.9 | 8.6 | 11.4 | 32.8 | 13.6 | 15.0 | 37.5 | 14.4 | 17.5 |
| IBN-Net[ | 63.3 | 25.5 | 31.3 | 31.3 | 8.1 | 12.7 | 40.3 | 17.9 | 19.5 | 45.0 | 17.2 | 21.2 |
| IterNorm[ | 56.5 | 22.1 | 27.7 | 29.2 | 9.1 | 12.7 | 28.0 | 13.2 | 14.6 | 37.9 | 14.8 | 18.3 |
| JiGen[ | 58.6 | 24.1 | 29.2 | 27.9 | 9.1 | 12.3 | 34.5 | 14.5 | 17.6 | 40.3 | 15.9 | 19.7 |
| RSC[ | 50.6 | 12.7 | 21.0 | 21.4 | 9.1 | 9.5 | 27.2 | 11.3 | 13.6 | 33.1 | 11.0 | 14.7 |
| StableNet[ | 61.4 | 27.2 | 31.0 | 31.4 | 10.2 | 14.4 | 32.7 | 14.7 | 16.4 | 41.8 | 17.4 | 20.6 |
| FACT[ | 58.8 | 25.7 | 29.5 | 29.0 | 9.1 | 13.0 | 35.0 | 14.7 | 17.6 | 40.9 | 16.5 | 20.0 |
| DIDN[ | 63.5 | 29.2 | 32.4 | 35.4 | 10.8 | 34.8 | 15.3 | 18.2 | 44.6 | 18.4 | 22.0 | |
| CDSD[ | 61.5 | 26.8 | 30.9 | 29.7 | 9.1 | 14.5 | 34.4 | 15.0 | 17.9 | 41.9 | 16.9 | 21.1 |
| MAD[ | 64.4 | 27.4 | 33.6 | 30.2 | 9.1 | 14.8 | 40.3 | 19.3 | 21.0 | 45.0 | 18.6 | 23.1 |
| FDD[ | 32.4 | 16.8 | ||||||||||
| 本文方法 | 66.2 | 34.7 | 37.6 | 11.0 | 16.8 | 55.4 | 30.8 | 31.5 | 53.0 | 23.9 | 27.7 | |
| 组号 | CMBIF | MIMI | ADP | mAP/% | mPT/% | |||
|---|---|---|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | |||||
| 1 | 36.3 | 30.1 | 17.2 | 37.7 | 30.3 | |||
| 2 | √ | 37.2 | 30.7 | 17.5 | 37.9 | 30.8 | ||
| 3 | √ | 37.1 | 31.7 | 17.2 | 39.1 | 31.3 | ||
| 4 | √ | √ | 32.3 | 17.9 | 38.0 | 31.5 | ||
| 5 | √ | √ | 37.6 | |||||
| 6 | √ | √ | √ | 38.4 | 33.3 | 18.5 | 39.1 | 32.3 |
表6 模型不同组件的消融实验结果
Tab. 6 Ablation experimental results of different components of model
| 组号 | CMBIF | MIMI | ADP | mAP/% | mPT/% | |||
|---|---|---|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | |||||
| 1 | 36.3 | 30.1 | 17.2 | 37.7 | 30.3 | |||
| 2 | √ | 37.2 | 30.7 | 17.5 | 37.9 | 30.8 | ||
| 3 | √ | 37.1 | 31.7 | 17.2 | 39.1 | 31.3 | ||
| 4 | √ | √ | 32.3 | 17.9 | 38.0 | 31.5 | ||
| 5 | √ | √ | 37.6 | |||||
| 6 | √ | √ | √ | 38.4 | 33.3 | 18.5 | 39.1 | 32.3 |
| 提示设计 | M | mAP/% | mPT/% | ||||
|---|---|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||||
| 固定域提示 | A photo of a | 0 | 37.4 | 30.9 | 17.7 | 37.7 | 30.9 |
| 域无关提示 | A photo of a | 0 | 37.9 | 32.4 | 17.5 | 38.3 | 31.5 |
| 可学习域无关提示 | 6 | 37.2 | 31.4 | 16.9 | 38.0 | 30.9 | |
| 自适应域提示 | 6 | 38.3 | 31.8 | 38.6 | 31.7 | ||
拼接域无关提示和 自适应域提示 | 拼接1 | 4 | 38.3 | 32.3 | 17.7 | 38.6 | 31.7 |
| 拼接2 | 8 | 38.6 | 32.5 | ||||
| 拼接3 | 10 | 38.3 | 17.6 | 38.6 | 31.8 | ||
| 拼接4 | 6 | 33.3 | 18.5 | 39.1 | 32.3 | ||
表7 不同提示设计的影响
Tab. 7 Impact of different prompt designs
| 提示设计 | M | mAP/% | mPT/% | ||||
|---|---|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||||
| 固定域提示 | A photo of a | 0 | 37.4 | 30.9 | 17.7 | 37.7 | 30.9 |
| 域无关提示 | A photo of a | 0 | 37.9 | 32.4 | 17.5 | 38.3 | 31.5 |
| 可学习域无关提示 | 6 | 37.2 | 31.4 | 16.9 | 38.0 | 30.9 | |
| 自适应域提示 | 6 | 38.3 | 31.8 | 38.6 | 31.7 | ||
拼接域无关提示和 自适应域提示 | 拼接1 | 4 | 38.3 | 32.3 | 17.7 | 38.6 | 31.7 |
| 拼接2 | 8 | 38.6 | 32.5 | ||||
| 拼接3 | 10 | 38.3 | 17.6 | 38.6 | 31.8 | ||
| 拼接4 | 6 | 33.3 | 18.5 | 39.1 | 32.3 | ||
| 方法 | mAP | mPT | |||
|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||
| Baseline(C-Gap) | 36.3 | 30.1 | 17.2 | 37.7 | 30.3 |
| +IMMI(stage1) | 31.6 | 16.8 | 37.4 | 30.8 | |
| +IMMI(stage2) | 32.3 | 17.2 | 38.5 | 31.4 | |
| +IMMI(stage3) | 37.3 | 18.9 | |||
| +IMMI(stage1、2、3) | 38.4 | 33.3 | 39.1 | 32.3 | |
表8 应用IMMI于ResNet-101不同阶段的影响 (%)
Tab. 8 Impact of applying IMMI to different stages of ResNet-101
| 方法 | mAP | mPT | |||
|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||
| Baseline(C-Gap) | 36.3 | 30.1 | 17.2 | 37.7 | 30.3 |
| +IMMI(stage1) | 31.6 | 16.8 | 37.4 | 30.8 | |
| +IMMI(stage2) | 32.3 | 17.2 | 38.5 | 31.4 | |
| +IMMI(stage3) | 37.3 | 18.9 | |||
| +IMMI(stage1、2、3) | 38.4 | 33.3 | 39.1 | 32.3 | |
| 方法 | mAP | mPT | |||
|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||
| Baseline(C-Gap) | 36.3 | 30.1 | 17.2 | 37.7 | 30.3 |
| Cross Attention | 38.7 | 31.9 | 17.4 | 38.2 | 30.8 |
| IGLI-only | 32.3 | 17.8 | |||
| TGLI-only | 37.8 | 31.9 | 17.1 | 38.0 | 31.2 |
| 加法融合 | 37.8 | 32.4 | 18.0 | 38.7 | 31.7 |
| 拼接融合 | 38.3 | 18.2 | 38.3 | ||
| 本文方法 | 38.4 | 33.3 | 18.5 | 39.1 | 32.3 |
表9 跨模态交互的影响 (%)
Tab. 9 Impact of cross-modal interaction
| 方法 | mAP | mPT | |||
|---|---|---|---|---|---|
| Night Sunny | Dusk Rainy | Night Rainy | Daytime Foggy | ||
| Baseline(C-Gap) | 36.3 | 30.1 | 17.2 | 37.7 | 30.3 |
| Cross Attention | 38.7 | 31.9 | 17.4 | 38.2 | 30.8 |
| IGLI-only | 32.3 | 17.8 | |||
| TGLI-only | 37.8 | 31.9 | 17.1 | 38.0 | 31.2 |
| 加法融合 | 37.8 | 32.4 | 18.0 | 38.7 | 31.7 |
| 拼接融合 | 38.3 | 18.2 | 38.3 | ||
| 本文方法 | 38.4 | 33.3 | 18.5 | 39.1 | 32.3 |
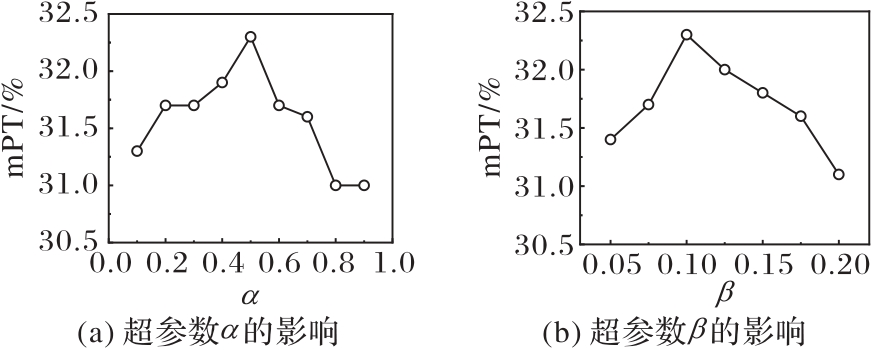
图5 超参数的消融实验结果
Fig. 5 Ablation study results of hyperparameters
| 方法 | Params/106 | GFLOPs | mPT/% |
|---|---|---|---|
| C-Gap | 146.2 | 387.5 | 30.3 |
| 本文方法 | 151.7 | 397.7 | 32.3 |
| 剪枝 | 109.3 | 278.4 | 31.9 |
表10 模型参数量和计算复杂度的比较
Tab. 10 Comparison of model parameters and computational complexity
| 方法 | Params/106 | GFLOPs | mPT/% |
|---|---|---|---|
| C-Gap | 146.2 | 387.5 | 30.3 |
| 本文方法 | 151.7 | 397.7 | 32.3 |
| 剪枝 | 109.3 | 278.4 | 31.9 |

图6 在Diverse Weather数据集中的目标域上进行目标检测的可视化
Fig. 6 Object detection visualization on target domains in Diverse Weather dataset
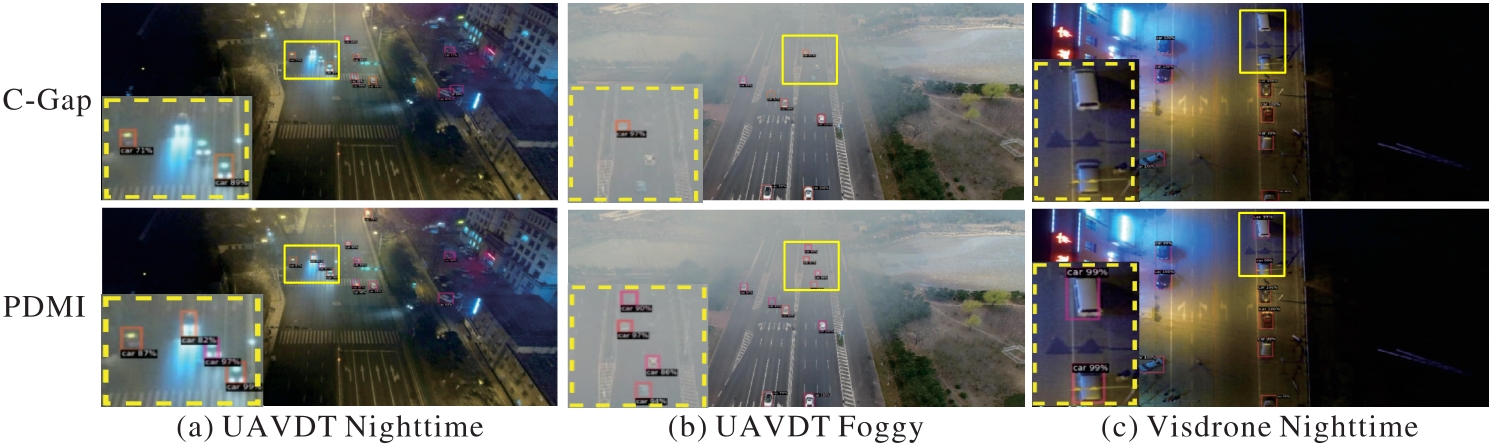
图7 在UAV-OD数据集中的目标域上进行目标检测的可视化
Fig. 7 Object detection visualization on target domains in UAV-OD dataset

图8 在Diverse Weather数据集中的目标域上热力图的可视化
Fig. 8 Heatmap visualization on target domains in Diverse Weather dataset
| [1] | LeCUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444. |
| [2] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015: 91-99. |
| [3] | WANG W, LI H, WANG C, et al. Deep label propagation with nuclear norm maximization for visual domain adaptation[J]. IEEE Transactions on Image Processing, 2025, 34: 1246-1258. |
| [4] | CHEN Y, LI W, SAKARIDIS C, et al. Domain adaptive Faster R-CNN for object detection in the wild[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3339-3348. |
| [5] | CHEN C, ZHENG Z, DING X, et al. Harmonizing transferability and discriminability for adapting object detectors[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8866-8875. |
| [6] | HSU C C, TSAI Y H, LIN Y Y, et al. Every pixel matters: center-aware feature alignment for domain adaptive object detector[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12354. Cham: Springer, 2020: 733-748. |
| [7] | ZHENG Y, HUANG D, LIU S, et al. Cross-domain object detection through coarse-to-fine feature adaptation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 13763-13772. |
| [8] | 桑雨,贡同,赵琛,等. 具有光度对齐的域适应夜间目标检测方法[J]. 计算机应用, 2026, 46(1): 242-251. |
| SANG Y, GONG T, ZHAO C, et al. Domain-adaptive nighttime object detection method with photometric alignment[J]. Journal of Computer Applications, 2026, 46(1): 242-251. | |
| [9] | LI H, PAN S J, WANG S, et al. Domain generalization with adversarial feature learning[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5400-5409. |
| [10] | CARLUCCI F M, D’INNOCENTE A, BUCCI S, et al. Domain generalization by solving jigsaw puzzles[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2224-2233. |
| [11] | ZHOU K, YANG Y, HOSPEDALES T, et al. Deep domain-adversarial image generation for domain generalization[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 13025-13032. |
| [12] | YUAN J, MA X, CHEN D, et al. Domain-specific bias filtering for single labeled domain generalization[J]. International Journal of Computer Vision, 2023, 131(2): 552-571. |
| [13] | ZHENG G, HUAI M, ZHANG A, et al. AdvST: revisiting data augmentations for single domain generalization[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 21832-21840. |
| [14] | SU Z, YAO K, YANG X, et al. Rethinking data augmentation for single-source domain generalization in medical image segmentation[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 2366-2374. |
| [15] | 史彩娟,郑远帆,任弼娟,等. 单域泛化X-ray乳腺肿瘤检测[J]. 中国图象图形学报, 2024, 29(3): 725-740. |
| SHI C J, ZHENG Y F, REN B J, et al. Single-domain generalized breast tumor detection in X-ray images[J]. Journal of Image and Graphics, 2024, 29(3): 725-740. | |
| [16] | WU A, DENG C. Single-domain generalized object detection in urban scene via cyclic-disentangled self-distillation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 837-846. |
| [17] | LIN C, YUAN Z, ZHAO S, et al. Domain-invariant disentangled network for generalizable object detection[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8751-8760. |
| [18] | 刘袁缘,王超凡,王文斌,等. 面向多种天气场景下目标检测的多域动态平均教师模型[J]. 计算机辅助设计与图形学学报, 2024, 36(3): 388-398. |
| LIU Y Y, WANG C F, WANG W B, et al. Multi-domain dynamic mean teacher for object detection in complex weather[J]. Journal of Computer-Aided Design and Computer Graphics, 2024, 36(3): 388-398. | |
| [19] | QI L, DONG P, XIONG T, et al. DoubleAUG: single-domain generalized object detector in urban via color perturbation and dual-style memory[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2024, 20(5): No.126. |
| [20] | FAN Q, SEGU M, TAI Y W, et al. Towards robust object detection invariant to real-world domain shifts[EB/OL]. [2024-04-22].. |
| [21] | RAO Z, GUO J, TANG L, et al. SRCD: semantic reasoning with compound domains for single-domain generalized object detection[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(7): 12497-12506. |
| [22] | LEE W, HONG D, LIM H, et al. Object-aware domain generalization for object detection[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 2947-2955. |
| [23] | ZHAO Y, ZHONG Z, ZHAO N, et al. Style-hallucinated dual consistency learning: a unified framework for visual domain generalization[J]. International Journal of Computer Vision, 2024, 132(3): 837-853. |
| [24] | VIDIT V, ENGILBERGE M, SALZMANN M. CLIP the gap: a single domain generalization approach for object detection[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 3219-3229. |
| [25] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [26] | DENG L, WU A, WANG Y, et al. Prompt-driven dynamic object-centric learning for single domain generalization[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 17606-17615. |
| [27] | LI H, WANG W, WANG C, et al. Phrase grounding-based style transfer for single-domain generalized object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2026, 36(1): 106-118. |
| [28] | ZHOU K, YANG J, LOY C C, et al. Learning to prompt for vision-language models[J]. International Journal of Computer Vision, 2022, 130(9): 2337-2348. |
| [29] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [30] | KONG X, DONG C, ZHANG L. Towards effective multiple-in-one image restoration: a sequential and prompt learning strategy[EB/OL]. [2024-04-22].. |
| [31] | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2980-2988. |
| [32] | YU F, CHEN H, WANG X, et al. BDD100K: a diverse driving dataset for heterogeneous multitask learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 2633-2642. |
| [33] | SAKARIDIS C, DAI D, VAN GOOL L. Semantic foggy scene understanding with synthetic data[J]. International Journal of Computer Vision, 2018, 126(9): 973-992. |
| [34] | HASSABALLAH M, KENK M A, MUHAMMAD K, et al. Vehicle detection and tracking in adverse weather using a deep learning framework[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(7): 4230-4242. |
| [35] | JOHNSON-ROBERSON M, BARTO C, MEHTA R, et al. Driving in the matrix: can virtual worlds replace human-generated annotations for real world tasks[EB/OL]. [2024-04-22].. |
| [36] | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223. |
| [37] | GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the KITTI vision benchmark suite[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2012: 3354-3361. |
| [38] | WANG K, FU X, GE C, et al. Towards generalized UAV object detection: a novel perspective from frequency domain disentanglement[J]. International Journal of Computer Vision, 2024, 132(11): 5410-5438. |
| [39] | DU D, ZHU P, WEN L, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop. Piscataway: IEEE, 2019: 213-226. |
| [40] | DU D, QI Y, YU H, et al. The unmanned aerial vehicle benchmark: object detection and tracking[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11214. Cham: Springer, 2018: 375-391. |
| [41] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [42] | PAN X, ZHAN X, SHI J, et al. Switchable whitening for deep representation learning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1863-1871. |
| [43] | PAN X, LUO P, SHI J, et al. Two at once: enhancing learning and generalization capacities via IBN-Net[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 484-500. |
| [44] | HUANG L, ZHOU Y, ZHU F, et al. Iterative normalization: beyond standardization towards efficient whitening[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4869-4878. |
| [45] | CHOI S, JUNG S, YUN H, et al. RobustNet: improving domain generalization in urban-scene segmentation via instance selective whitening[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11575-11585. |
| [46] | HUANG Z, WANG H, XING E P, et al. Self-challenging improves cross-domain generalization[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12347. Cham: Springer, 2020: 124-140. |
| [47] | ZHANG X, CUI P, XU R, et al. Deep stable learning for out-of-distribution generalization[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5368-5378. |
| [48] | XU Q, ZHANG R, ZHANG Y, et al. A Fourier-based framework for domain generalization[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 14378-14387. |
| [49] | XU M, QIN L, CHEN W, et al. Multi-view adversarial discriminator: mine the non-causal factors for object detection in unseen domains[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 8103-8112. |
| [1] | 李亚男, 郭梦阳, 邓国军, 陈允峰, 任建吉, 原永亮. 基于多模态融合特征的并分支发动机寿命预测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 305-313. |
| [2] | 王菲, 陶冶, 刘家旺, 李伟, 秦修功, 张宁. 面向智慧家庭空间的时空知识图谱的双模态融合构建方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 52-59. |
| [3] | 孙熠衡, 刘茂福. 基于知识提示微调的标书信息抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1169-1176. |
| [4] | 杨燕, 叶枫, 许栋, 张雪洁, 徐津. 融合大语言模型和提示学习的数字孪生水利知识图谱构建[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 785-793. |
| [5] | 马灿, 黄瑞章, 任丽娜, 白瑞娜, 伍瑶瑶. 基于大语言模型的多输入中文拼写纠错方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 849-855. |
| [6] | 蔡启健, 谭伟. 语义图增强的多模态推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 421-427. |
| [7] | 龚永罡, 陈舒汉, 廉小亲, 李乾生, 莫鸿铭, 刘宏宇. 基于大语言模型的中文开放领域实体关系抽取策略[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3121-3130. |
| [8] | 黄朋, 林佳瑜, 梁祖红. 基于互信息和提示学习的中文无监督对比学习方法[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3101-3110. |
| [9] | 李斌, 林民, 斯日古楞null, 高颖杰, 王玉荣, 张树钧. 基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 75-81. |
| [10] | 黄颖, 杨佳宇, 金家昊, 万邦睿. 用于RGBT跟踪的孪生混合信息融合算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2878-2885. |
| [11] | 游新冬, 问英姿, 佘鑫鹏, 吕学强. 面向煤矿机电设备领域的三元组抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2026-2033. |
| [12] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [13] | 魏超, 陈艳平, 王凯, 秦永彬, 黄瑞章. 基于掩码提示与门控记忆网络校准的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1713-1719. |
| [14] | 高颖杰, 林民, 斯日古楞null, 李斌, 张树钧. 基于片段抽取原型网络的古籍文本断句标点提示学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3815-3822. |
| [15] | 王春雷, 王肖, 刘凯. 多模态知识图谱表示学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 1-15. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||