


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 785-793.DOI: 10.11772/j.issn.1001-9081.2024050570
杨燕1, 叶枫1,2( ), 许栋2,3, 张雪洁1, 徐津2,3,4
), 许栋2,3, 张雪洁1, 徐津2,3,4
收稿日期:2024-05-09
修回日期:2024-08-03
接受日期:2024-08-08
发布日期:2025-03-17
出版日期:2025-03-10
通讯作者:
叶枫
作者简介:杨燕(1999—),女,江西宜春人,硕士研究生,CCF会员,主要研究方向:知识图谱构建、数据挖掘基金资助:
Yan YANG1, Feng YE1,2(), Dong XU2,3, Xuejie ZHANG1, Jin XU2,3,4
Received:2024-05-09
Revised:2024-08-03
Accepted:2024-08-08
Online:2025-03-17
Published:2025-03-10
Contact:
Feng YE
About author:YANG Yan, born in 1999, M. S. candidate. Her research interests include knowledge graph construction, data mining.Supported by:摘要:
构建数字孪生水利建设知识图谱挖掘水利建设对象之间的潜在关系能够帮助相关人员优化水利建设设计方案和决策。针对数字孪生水利建设的学科交叉和知识结构复杂的特性,以及通用知识抽取模型缺乏对水利领域知识的学习和知识抽取精度不足等问题,为提高知识抽取的精度,提出一种基于大语言模型的数字孪生水利建设知识抽取方法(DTKE-LLM)。该方法通过LangChain部署本地大语言模型(LLM)并集成数字孪生水利领域知识,基于提示学习微调LLM,LLM利用语义理解和生成能力抽取知识,同时,设计异源实体对齐策略优化实体抽取结果。在水利领域语料库上进行对比实验和消融实验,以验证所提方法的有效性。对比实验结果表明,相较于基于深度学习的双向长短期记忆条件随机场(BiLSTM-CRF)命名实体识别模型和通用信息抽取模型UIE(Universal Information Extraction),DTKE-LLM的精确率更优;消融实验结果表明,相较于ChatGLM2-6B(Chat Generative Language Model 2.6 Billion),DTKE-LLM的实体抽取和关系抽取F1值分别提高了5.5和3.2个百分点。可见,该方法在保障知识图谱构建质量的基础上,实现了数字孪生水利建设知识图谱的构建。
中图分类号:
杨燕, 叶枫, 许栋, 张雪洁, 徐津. 融合大语言模型和提示学习的数字孪生水利知识图谱构建[J]. 计算机应用, 2025, 45(3): 785-793.
Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning[J]. Journal of Computer Applications, 2025, 45(3): 785-793.
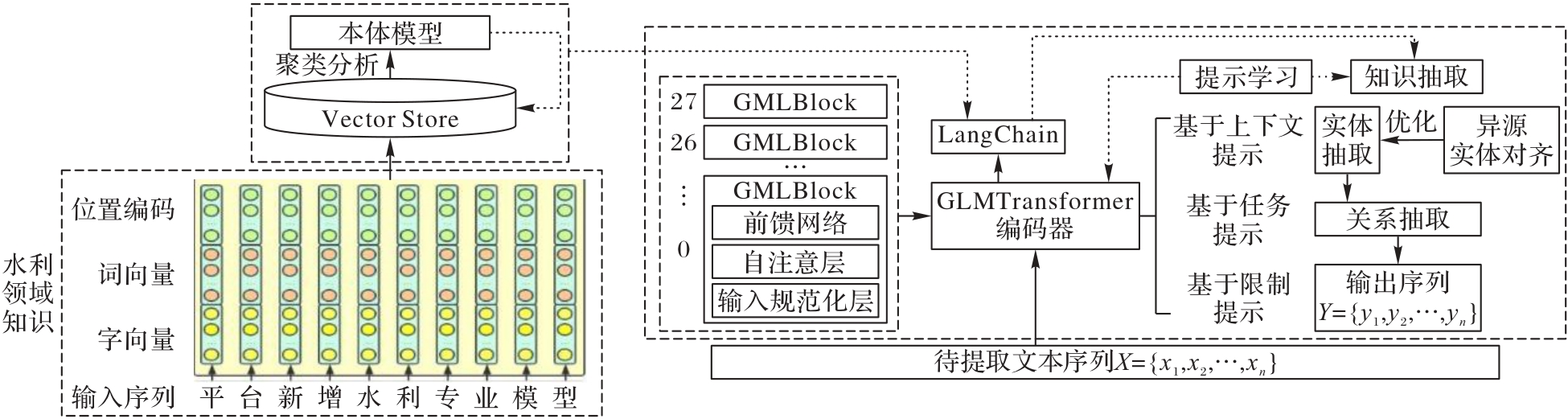
图1 DTKE-LLM整体框架
Fig. 1 Overall framework of DTKE-LLM
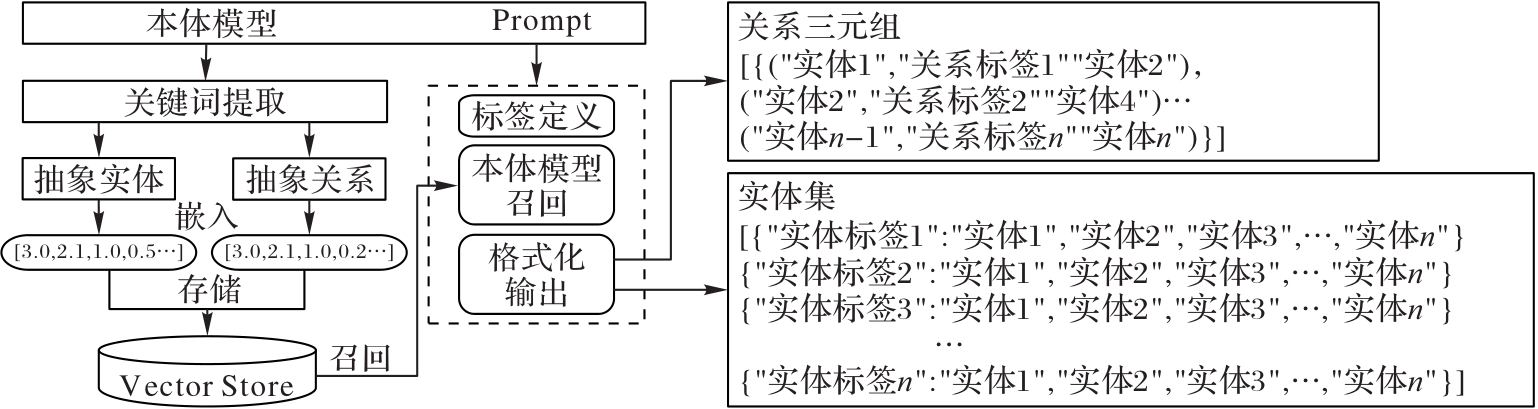
图2 联合策略框架
Fig. 2 Joint strategy framework
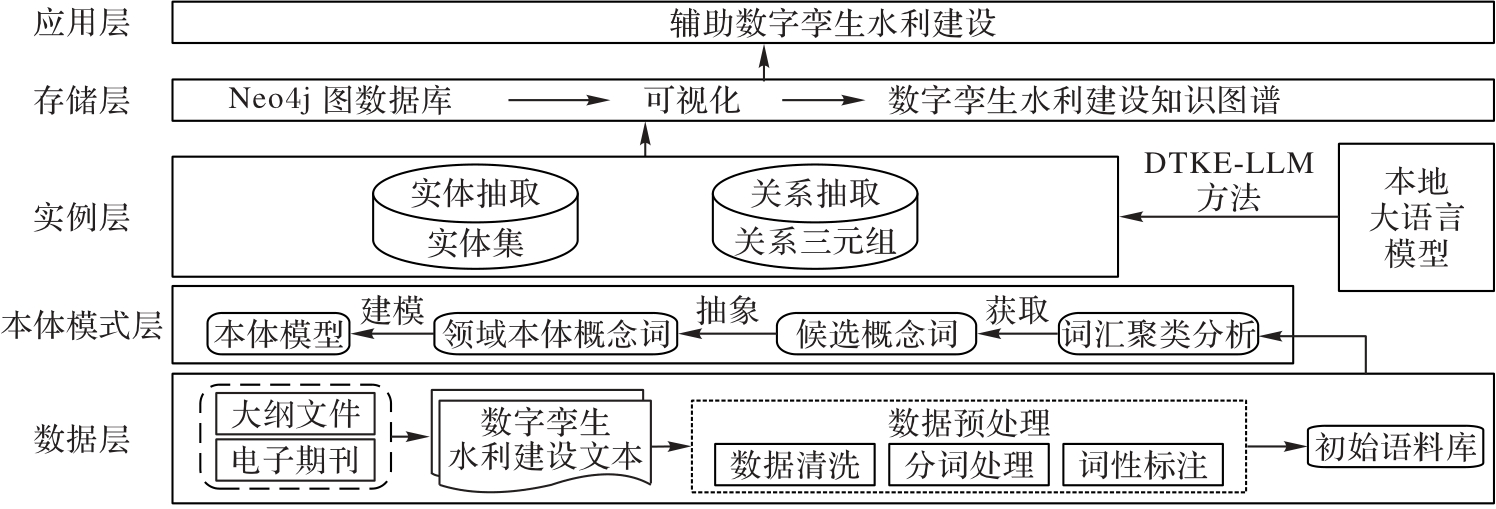
图3 知识图谱构建框架
Fig. 3 Knowledge graph construction framework

图4 文本预处理流程
Fig. 4 Text preprocessing flow
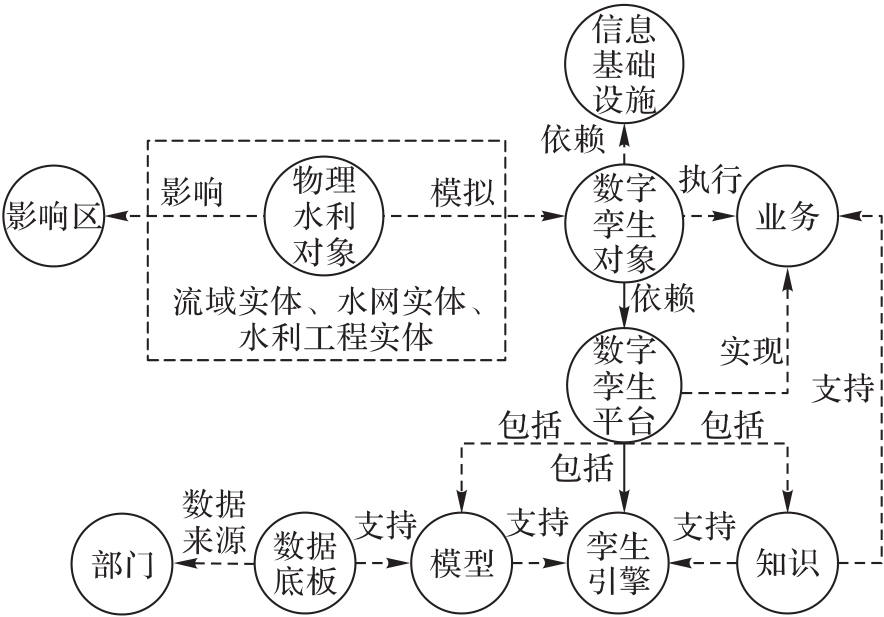
图5 本体模型的结构
Fig. 5 Structure of ontology model

图6 实体集和关系三元组(部分)
Fig. 6 Entity sets and relationship triplets (part)
| 标准实体 | 待融合实体 |
|---|---|
| GIS引擎 | GIS软件、地理信息系统软件、地理信息系统引擎 |
| 新安江模型 | 新安江水文模型、Xin’anjiang Model |
| 钱塘江流域 | 钱塘江水域、Qiantang River Basin |
表1 异源实体(部分)
Tab. 1 Heterologous entities (part)
| 标准实体 | 待融合实体 |
|---|---|
| GIS引擎 | GIS软件、地理信息系统软件、地理信息系统引擎 |
| 新安江模型 | 新安江水文模型、Xin’anjiang Model |
| 钱塘江流域 | 钱塘江水域、Qiantang River Basin |

图7 实例存储
Fig. 7 Instance storage
| 标签编号 | 标签名称 | 标记名称 | 标签编号 | 标签名称 | 标记名称 |
|---|---|---|---|---|---|
| 1 | 物理水利对象 | PO | 10 | 引擎 | ENG |
| 2 | 数字孪生对象 | DSO | 11 | 模拟 | SIM |
| 3 | 部门 | DEPT | 12 | 支持 | SUP |
| 4 | 业务 | BIZ | 13 | 包括 | INC |
| 5 | 信息基础设施 | INFO | 14 | 实现 | IMP |
| 6 | 平台 | PLT | 15 | 依赖 | DEP |
| 7 | 数据底板 | DATA | 16 | 执行 | EXE |
| 8 | 模型 | MOD | 17 | 来源 | ORIG |
| 9 | 知识 | KNOW | 18 | 影响 | INF |
表2 标签表
Tab. 2 Label table
| 标签编号 | 标签名称 | 标记名称 | 标签编号 | 标签名称 | 标记名称 |
|---|---|---|---|---|---|
| 1 | 物理水利对象 | PO | 10 | 引擎 | ENG |
| 2 | 数字孪生对象 | DSO | 11 | 模拟 | SIM |
| 3 | 部门 | DEPT | 12 | 支持 | SUP |
| 4 | 业务 | BIZ | 13 | 包括 | INC |
| 5 | 信息基础设施 | INFO | 14 | 实现 | IMP |
| 6 | 平台 | PLT | 15 | 依赖 | DEP |
| 7 | 数据底板 | DATA | 16 | 执行 | EXE |
| 8 | 模型 | MOD | 17 | 来源 | ORIG |
| 9 | 知识 | KNOW | 18 | 影响 | INF |
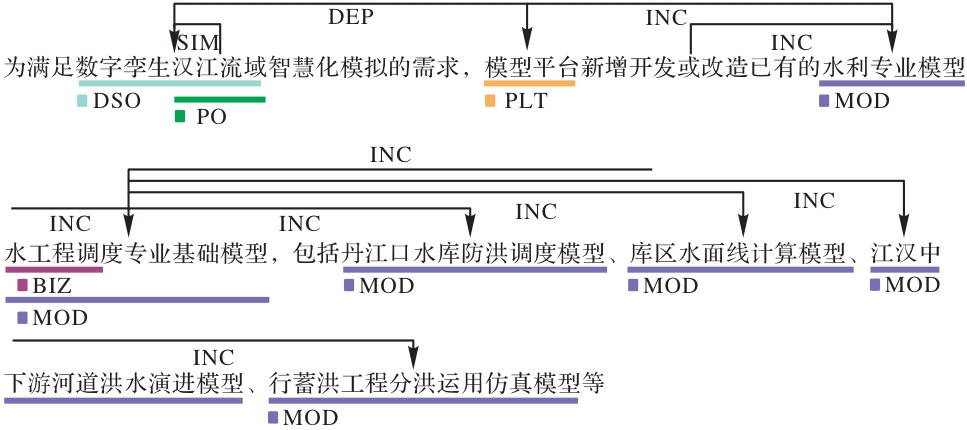
图8 语料标注实例
Fig. 8 Corpus annotation instance

图9 流域关联分析实例
Fig. 9 Watershed association analysis instance

图10 标签数量分布
Fig. 10 Label number distribution
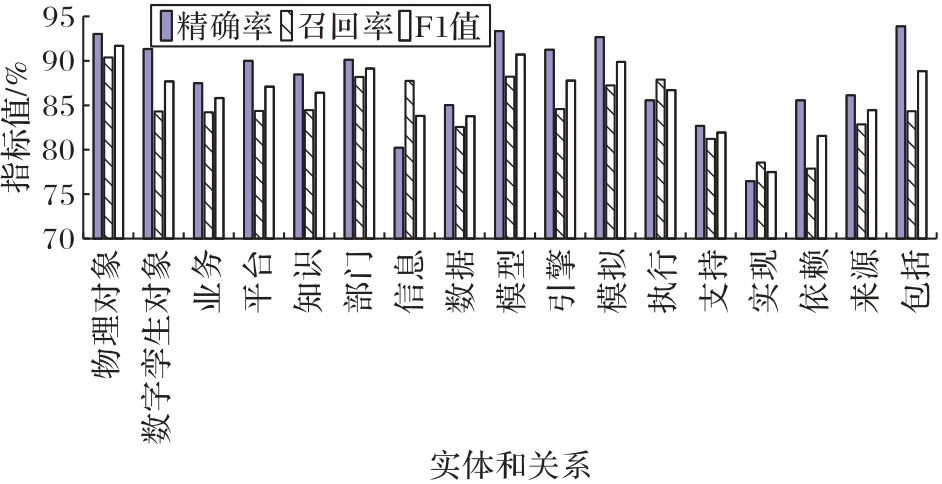
图11 实体和关系抽取结果评估
Fig. 11 Entity and relationship extraction result evaluation
| 任务 | 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|---|
实体 抽取 | BiLSTM-CRF | 76.280 | 71.775 | 73.959 |
| UIE-base | 82.082 | 80.077 | 81.067 | |
| ChatGLM2-6B | 84.661 | 81.572 | 83.088 | |
| DTKE-ChatGLM2-6B | 90.112 | 87.195 | 88.630 | |
关系 抽取 | UIE-base | 79.907 | 70.475 | 74.895 |
| ChatGLM2-6B | 81.554 | 80.970 | 81.261 | |
| DTKE-ChatGLM2-6B | 86.125 | 82.854 | 84.458 |
表3 不同模型在实体抽取和关系抽取任务中的性能对比 (%)
Tab. 3 Performance comparison of different models in entity extraction and relationship extraction tasks
| 任务 | 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|---|
实体 抽取 | BiLSTM-CRF | 76.280 | 71.775 | 73.959 |
| UIE-base | 82.082 | 80.077 | 81.067 | |
| ChatGLM2-6B | 84.661 | 81.572 | 83.088 | |
| DTKE-ChatGLM2-6B | 90.112 | 87.195 | 88.630 | |
关系 抽取 | UIE-base | 79.907 | 70.475 | 74.895 |
| ChatGLM2-6B | 81.554 | 80.970 | 81.261 | |
| DTKE-ChatGLM2-6B | 86.125 | 82.854 | 84.458 |
| 任务 | 操作 | 精确率 | 召回率 | F1值 |
|---|---|---|---|---|
实体 抽取 | 完整方法 | 90.112 | 87.195 | 88.630 |
| 不注入领域知识 | 88.291 | 87.055 | 87.669 | |
| 无知识抽取prompt | 85.276 | 84.332 | 84.801 | |
| 无实体对齐prompt | 89.157 | 86.002 | 87.551 | |
关系 抽取 | 完整方法 | 86.125 | 82.854 | 84.458 |
| 不注入领域知识 | 85.245 | 81.347 | 83.250 | |
| 无知识抽取prompt | 82.007 | 81.256 | 81.630 | |
| 无实体对齐prompt | 86.025 | 82.854 | 84.410 |
表4 实体抽取和关系抽取的消融实验结果 (%)
Tab. 4 Ablation experiment results of entity extraction andrelationship extraction
| 任务 | 操作 | 精确率 | 召回率 | F1值 |
|---|---|---|---|---|
实体 抽取 | 完整方法 | 90.112 | 87.195 | 88.630 |
| 不注入领域知识 | 88.291 | 87.055 | 87.669 | |
| 无知识抽取prompt | 85.276 | 84.332 | 84.801 | |
| 无实体对齐prompt | 89.157 | 86.002 | 87.551 | |
关系 抽取 | 完整方法 | 86.125 | 82.854 | 84.458 |
| 不注入领域知识 | 85.245 | 81.347 | 83.250 | |
| 无知识抽取prompt | 82.007 | 81.256 | 81.630 | |
| 无实体对齐prompt | 86.025 | 82.854 | 84.410 |
| 1 | 黄艳,喻杉,罗斌,等. 面向流域水工程防灾联合智能调度的数字孪生长江探索[J]. 水利学报, 2022, 53(3): 253-269. |
| HUANG Y, YU S, LUO B, et al. Development of the digital twin Changjiang River with the pilot system of joint and intelligent regulation of water projects for flood management [J]. Journal of Hydraulic Engineering, 2022, 53(3): 253-269. | |
| 2 | LI F L, CHEN H, XU G, et al. AliMeKG: domain knowledge graph construction and application in e-commerce [C]// Proceedings of the 29th ACM International Conference on Information and Knowledge Management. New York: ACM, 2020: 2581-2588. |
| 3 | NICHOLSON D N, GREENE C S. Constructing knowledge graphs and their biomedical applications [J]. Computational and Structural Biotechnology Journal, 2020, 18: 1414-1428. |
| 4 | ZEHRA S, MOHSIN S F M, WASI S, et al. Financial knowledge graph based financial report query system [J]. IEEE Access, 2021, 9: 69766-69782. |
| 5 | XU N, MA L, WANG L, et al. Extracting domain knowledge elements of construction safety management: rule-based approach using Chinese natural language processing [J]. Journal of Management in Engineering, 2021, 37(2): No.0000870. |
| 6 | DHAL P, AZAD C. A comprehensive survey on feature selection in the various fields of machine learning [J]. Applied Intelligence, 2022, 52(4): 4543-4581. |
| 7 | LUO L, YANG Z, CAO M, et al. A neural network-based joint learning approach for biomedical entity and relation extraction from biomedical literature [J]. Journal of Biomedical Informatics, 2020, 103: No.103384. |
| 8 | 张钦彤,王昱超,王鹤羲,等. 大语言模型微调技术的研究综述[J].计算机工程与应用, 2024, 60(17):17-33. |
| ZHANG Q T, WANG Y C, WANG H X, et al. Comprehensive review of large language model fine-tuning [J]. Computer Engineering and Applications, 2024, 60(17):17-33. | |
| 9 | 段浩,韩昆,赵红莉,等. 水利综合知识图谱构建研究[J]. 水利学报, 2021, 52(8): 948-958. |
| DUAN H, HAN K, ZHAO H L, et al. Research on water conservancy comprehensive knowledge graph construction [J]. Journal of Hydraulic Engineering, 2021, 52(8): 948-958. | |
| 10 | 冯钧,杭婷婷,陈菊,等. 领域知识图谱研究进展及其在水利领域的应用[J]. 河海大学学报(自然科学版), 2021, 49(1): 26-34. |
| FENG J, HANG T T, CHEN J, et al. Research status of domain knowledge graph and its application in water conservancy[J]. Journal of Hohai University (Natural Sciences), 2021, 49(1): 26-34. | |
| 11 | WANG Y, YE F, LI B, et al. UrbanFloodKG: an urban flood knowledge graph system for risk assessment [C]// Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. New York: ACM, 2023: 2574-2584. |
| 12 | 刘雪梅,卢汉康,李海瑞,等. 知识驱动的水利工程应急方案智能生成方法—以南水北调中线工程为例[J]. 水利学报, 2023, 54(6): 666-676. |
| LIU X M, LU H K, LI H R, et al. A knowledge-driven approach for intelligent generation of hydraulic engineering contingency plans: a case study of the Middle Route of South-to-North Water Diversion Project [J]. Journal of Hydraulic Engineering, 2023, 54(6): 666-676. | |
| 13 | MARTINEZ-RODRIGUEZ J L, HOGAN A, LOPEZ-AREVALO I. Information extraction meets the semantic Web: a survey [J]. Semantic Web, 2020, 11(2): 255-335. |
| 14 | 付雷杰,曹岩,白瑀,等. 国内垂直领域知识图谱发展现状与展望[J]. 计算机应用研究, 2021, 38(11):3201-3214. |
| FU L J, CAO Y, BAI Y, et al. Development status and prospect of vertical domain knowledge graph in China [J]. Application Research of Computers, 2021, 38(11): 3201-3214. | |
| 15 | GENG Z, CHEN G, HAN Y, et al. Semantic relation extraction using sequential and tree-structured LSTM with attention [J]. Information Sciences, 2020, 509: 183-192. |
| 16 | ZHANG S, LI Y, LI S, et al. Bi-LSTM-CRF network for clinical event extraction with medical knowledge features [J]. IEEE Access, 2022, 10: 110100-110109. |
| 17 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 18 | ROY A, PAN S. Incorporating medical knowledge in BERT for clinical relation extraction [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 5357-5366. |
| 19 | GOEL A, GUETA A, GILON O, et al. LLMs accelerate annotation for medical information extraction [C]// Proceedings of the 3rd Machine Learning for Health Symposium. New York: JMLR.org, 2023: 82-100. |
| 20 | CHODAK G, BŁAŻYCZEK K. Large language models for search engine optimization in e-commerce [C]// Proceedings of the 2023 International Advanced Computing Conference. Cham: Springer, 2024: 333-344. |
| 21 | 叶名玮,汤嘉,郭燕,等. 基于大语言模型的命名实体识别[J]. 计算机系统应用, 2024, 33(8): 257-263. |
| YE M W, TANG J, GUO Y, et al. Named entity recognition based on large language model [J]. Computer Systems and Applications, 2024, 33(8): 257-263. | |
| 22 | 裴炳森,李欣,蒋章涛,等. 基于大语言模型的公安专业小样本知识抽取方法研究[J]. 计算机科学与探索, 2024, 18(10): 2630-2642. |
| PEI B S, LI X, JIANG Z T, et al. Research on public security professional small sample knowledge extraction method based on large language model [J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(10): 2630-2642. | |
| 23 | 彭雪,李正华,张民. 基于语言模型微调的跨领域依存句法分析[J]. 计算机应用与软件, 2022, 39(7):141-146. |
| PENG X, LI Z H, ZHANG M. Cross domain dependency parsing based on fine tuning of language model [J]. Computer Applications and Software, 2022, 39(7):141-146. | |
| 24 | MALLADI S, GAO T, NICHANI E, et al. Fine-tuning language models with just forward passes [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 53038-53075. |
| 25 | MAYER C W F, LUDWIG S, BRANDT S. Prompt text classifications with transformer models! an exemplary introduction to prompt-based learning with large language models[J]. Journal of Research on Technology in Education, 2023, 55(1): 125-141. |
| 26 | WU H, MA B, LIU W, et al. Fast and constrained absent keyphrase generation by prompt-based learning [C]// Proceedings of the 26th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 11495-11503. |
| 27 | YE F, HUANG L, LIANG S, et al. Decomposed two-stage prompt learning for few-shot named entity recognition [J]. Information, 2023, 14(5): No.262. |
| 28 | CHEN X, ZHANG N, XIE X, et al. KnowPrompt: knowledge-aware prompt-tuning with synergistic optimization for relation extraction [C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2778-2788. |
| 29 | JEONG C. Generative AI service implementation using LLM application architecture: based on RAG model and LangChain framework [J]. Journal of Intelligence and Information Systems, 2023, 29(4): 129-164. |
| 30 | WANG H, WANG Y, LI J, et al. Degree aware based adversarial graph convolutional networks for entity alignment in heterogeneous knowledge graph [J]. Neurocomputing, 2022, 487: 99-109. |
| 31 | IKOTUN A M, EZUGWU A E, ABUALIGAH L, et al. K-means clustering algorithms: a comprehensive review, variants analysis, and advances in the era of big data [J]. Information Sciences, 2023, 622: 178-210. |
| 32 | 刘婧茹,宋阳,贾睿,等. 基于BiLSTM-CRF中文临床文本中受保护的健康信息识别[J]. 数据分析与知识发现, 2020, 4(10):124-133. |
| LIU J R, SONG Y, JIA R, et al. A BiLSTM-CRF model for protected health information in Chinese [J]. Data Analysis and Knowledge Discovery, 2020, 4(10): 124-133. | |
| 33 | FEI H, WU S, LI J, et al. LasUIE: unifying information extraction with latent adaptive structure-aware generative language model [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 15460-15475. |
| [1] | 秦小林, 古徐, 李弟诚, 徐海文. 大语言模型综述与展望[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 685-696. |
| [2] | 袁成哲, 陈国华, 李丁丁, 朱源, 林荣华, 钟昊, 汤庸. ScholatGPT:面向学术社交网络的大语言模型及智能应用[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 755-764. |
| [3] | 何静, 沈阳, 谢润锋. 大语言模型幻觉现象的识别与优化[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 709-714. |
| [4] | 张学飞, 张丽萍, 闫盛, 侯敏, 赵宇博. 知识图谱与大语言模型协同的个性化学习推荐[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 773-784. |
| [5] | 董艳民, 林佳佳, 张征, 程程, 吴金泽, 王士进, 黄振亚, 刘淇, 陈恩红. 个性化学情感知的智慧助教算法设计与实践[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 765-772. |
| [6] | 徐月梅, 叶宇齐, 何雪怡. 大语言模型的偏见挑战:识别、评估与去除[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 697-708. |
| [7] | 曹鹏, 温广琪, 杨金柱, 陈刚, 刘歆一, 季学纯. 面向测试用例生成的大模型高效微调方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 725-731. |
| [8] | 王猛, 张大千, 周冰艳, 马倩影, 吕继东. 基于时序知识图谱补全的CTCS-3级列控车载接口设备故障诊断方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 677-684. |
| [9] | 吕学强, 王涛, 游新冬, 徐戈. 层次融合多元知识的命名实体识别框架——HTLR[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 40-47. |
| [10] | 李斌, 林民, 斯日古楞null, 高颖杰, 王玉荣, 张树钧. 基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 75-81. |
| [11] | 程子栋, 李鹏, 朱枫. 物联网威胁情报知识图谱中潜在关系的挖掘[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 24-31. |
| [12] | 李瑞, 李贯峰, 胡德洲, 高文馨. 融合路径与子图特征的知识图谱多跳推理模型[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 32-39. |
| [13] | 薛桂香, 王辉, 周卫峰, 刘瑜, 李岩. 基于知识图谱和时空扩散图卷积网络的港口交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2952-2957. |
| [14] | 武杰, 张安思, 吴茂东, 张仪宗, 王从宝. 知识图谱在装备故障诊断领域的研究与应用综述[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2651-2659. |
| [15] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||