


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3121-3130.DOI: 10.11772/j.issn.1001-9081.2024101536
• 人工智能 • 上一篇
龚永罡, 陈舒汉( ), 廉小亲, 李乾生, 莫鸿铭, 刘宏宇
), 廉小亲, 李乾生, 莫鸿铭, 刘宏宇
收稿日期:2024-10-30
修回日期:2025-03-20
接受日期:2025-03-27
发布日期:2025-04-21
出版日期:2025-10-10
通讯作者:
陈舒汉
作者简介:龚永罡(1973—),男,河南洛阳人,副教授,博士,主要研究方向:大语言模型、物联网、自然语言处理基金资助:
Yonggang GONG, Shuhan CHEN(), Xiaoqin LIAN, Qiansheng LI, Hongming MO, Hongyu LIU
Received:2024-10-30
Revised:2025-03-20
Accepted:2025-03-27
Online:2025-04-21
Published:2025-10-10
Contact:
Shuhan CHEN
About author:GONG Yonggang, born in 1973, Ph. D., associate professor. His research interests include large language models, internet of things, natural language processing.Supported by:摘要:
大语言模型(LLM)在中文开放领域的实体关系抽取(ERE)任务中存在抽取性能不稳定的问题,对某些特定领域文本和标注类别的识别精准率较低。因此,提出一种基于LLM的中文开放领域实体关系抽取策略——基于LLM多级对话策略(MLDS-LLM)。该策略利用LLM优秀的语义理解和迁移学习能力,通过多轮不同任务的对话实现实体关系抽取。首先,基于开放领域文本结构化逻辑和思维链(CoT)机制,使用LLM生成结构化摘要,避免模型产生关系、事实幻觉和无法兼顾后文信息的问题;其次,通过文本简化策略并引入可替换词表,减少上下文窗口的限制;最后,基于结构化摘要和简化文本构建多级提示模板,使用LLaMA-2-70B模型探究参数temperature对实体关系抽取的影响。测试了LLaMA-2-70B在使用所提策略前后进行实体关系抽取的精准率、召回率、调和平均值(F1)和精确匹配(EM)值。实验结果表明,在CL-NE-DS、DiaKG和CCKS2021等5个不同领域的中文数据集上,所提策略提升了LLM在命名实体识别(NER)和关系抽取(RE)上的性能。特别是在专业性强且模型零样本测试结果不佳的DiaKG和IEPA数据集上,在应用所提策略后,相较于少样本提示测试,在NER上模型的精准率分别提升了9.3和6.7个百分点,EM值提升了2.7和2.2个百分点;在RE上模型的精准率分别提升了12.2和16.0个百分点,F1值分别提升了10.7和10.0个百分点。实验结果验证了所提策略能有效提升LLM实体关系抽取的效果并解决模型性能不稳定的问题。
中图分类号:
龚永罡, 陈舒汉, 廉小亲, 李乾生, 莫鸿铭, 刘宏宇. 基于大语言模型的中文开放领域实体关系抽取策略[J]. 计算机应用, 2025, 45(10): 3121-3130.
Yonggang GONG, Shuhan CHEN, Xiaoqin LIAN, Qiansheng LI, Hongming MO, Hongyu LIU. Entity-relation extraction strategy in Chinese open-domains based on large language model[J]. Journal of Computer Applications, 2025, 45(10): 3121-3130.
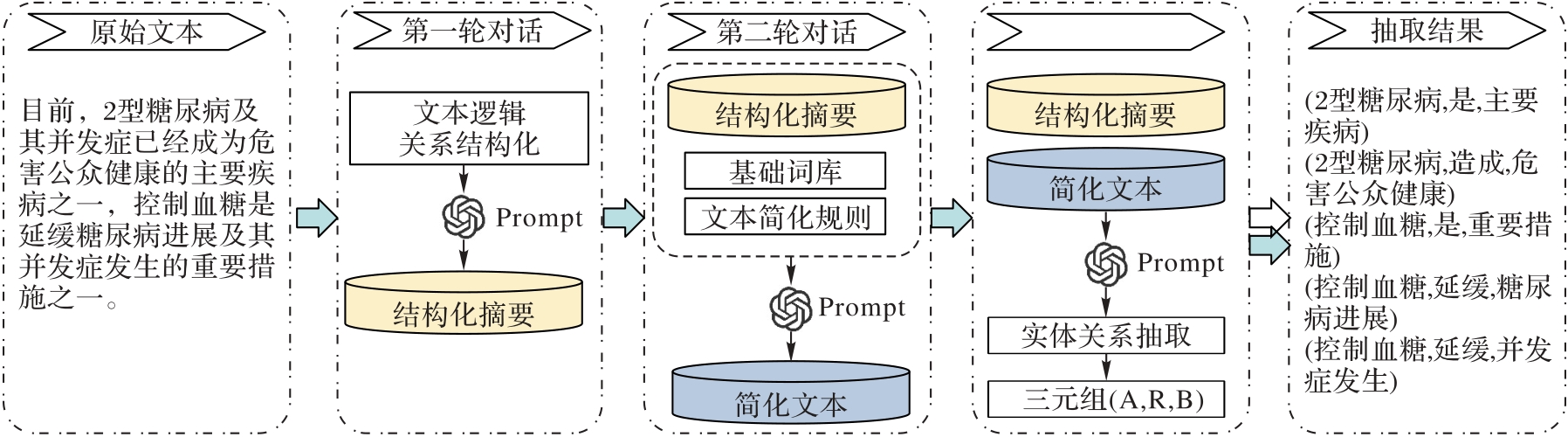
图1 MLDS-LLM的框架
Fig. 1 Framework of MLDS-LLM
| 文本结构 | 内容 | 逻辑关系 |
|---|---|---|
| 文本主要涉及领域 | 本文主要属于XX(医学、法学、灾害文本等)领域 | 文本主要涉及领域为文本提供了一个总的背景框架,而领域 文本类型则明确了文本在这个框架中的具体位置和功能 |
| 领域文本类型 | 本文属于XX领域下的xx(如:本文属于医学领域下的 外科手术事故报告) | |
| 主要论点 | 本文主要讨论了XX领域的……(如:本文主要讨论了 医学领域的一起外科手术事故) | 论点围绕着文本主要涉及的领域,并能够高度概括发生的 主要事件 |
| 发生事件 | 如:2024年1月1日,外科手术过程中,患者出现不明 原因的心脏骤停。主治医生立即采取紧急复苏措施…… | 发生事件导致了事件结果,多个发生事件共同构成文本主要 涉及领域 |
| 事件结果 | 如:患者经救治无生命危险,但是由于外科手术终止导致 患者留下后遗症…… |
表1 中文开放领域文本的结构化逻辑关系
Tab. 1 Structured logical relationships in Chinese open-domain texts
| 文本结构 | 内容 | 逻辑关系 |
|---|---|---|
| 文本主要涉及领域 | 本文主要属于XX(医学、法学、灾害文本等)领域 | 文本主要涉及领域为文本提供了一个总的背景框架,而领域 文本类型则明确了文本在这个框架中的具体位置和功能 |
| 领域文本类型 | 本文属于XX领域下的xx(如:本文属于医学领域下的 外科手术事故报告) | |
| 主要论点 | 本文主要讨论了XX领域的……(如:本文主要讨论了 医学领域的一起外科手术事故) | 论点围绕着文本主要涉及的领域,并能够高度概括发生的 主要事件 |
| 发生事件 | 如:2024年1月1日,外科手术过程中,患者出现不明 原因的心脏骤停。主治医生立即采取紧急复苏措施…… | 发生事件导致了事件结果,多个发生事件共同构成文本主要 涉及领域 |
| 事件结果 | 如:患者经救治无生命危险,但是由于外科手术终止导致 患者留下后遗症…… |
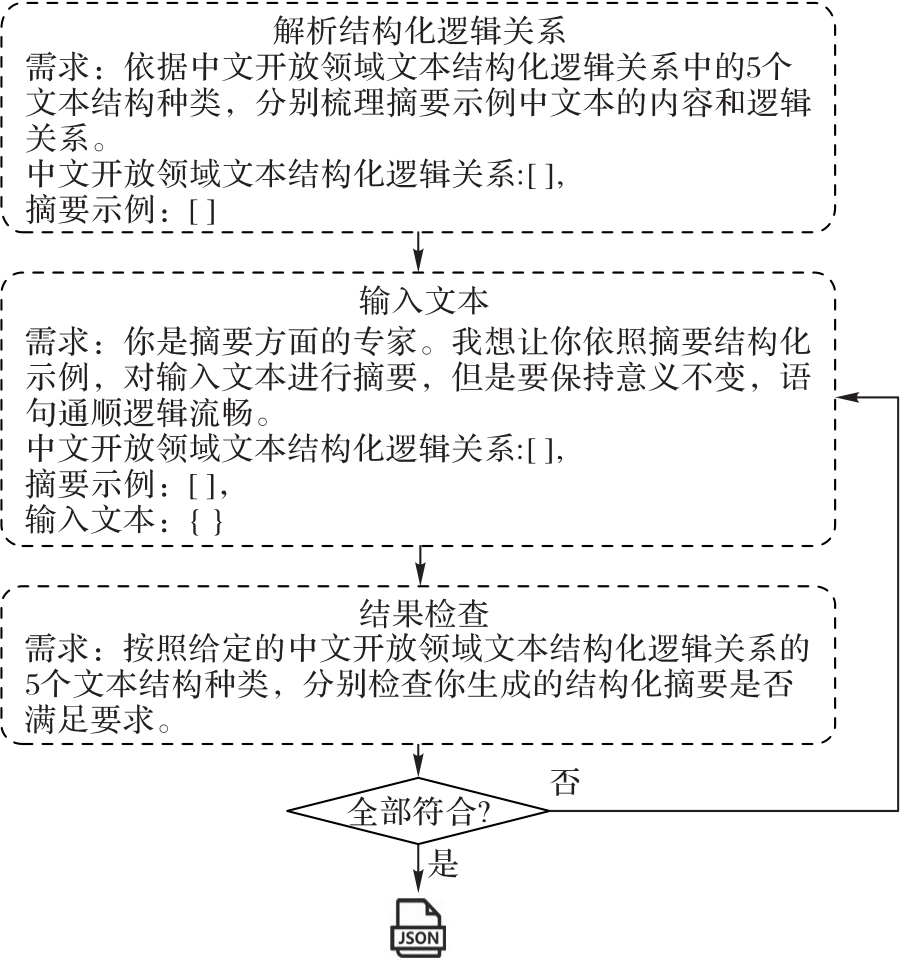
图2 基于CoT策略的结构化摘要机制
Fig. 2 Structured summary mechanism based on CoT strategy
| 简化规则 | 说明 |
|---|---|
简化文本,当出现无实体的修饰词或分句时,可以删除这句话 而不重构结构。全文的字数减少的幅度控制在15%内 | 在简化中首先删除了一些通常用处不大的信息,减少了文本冗余, 但仍然能保留大部分关键信息和原文的结构,防止过度删减导致 信息丢失;然后对句子结构进行中度简化,适量增加句子数量, 可以显著提高文本的易读性 |
简化语句结构,每句话只包括主语‒谓语‒宾语和少量其他信息, 句子长度尽量控制在15至25个字。将长句子拆分为多个简单句, 但句子总数的增加幅度要控制在20%以内 | |
在简化过程中不要用同义词替换,保证生成的简化文本和 原文本中的实词总数不要有明显下降 | 当词语属于词表提示中的“基础词”,且不为实词时,可以进行同义 替换,保证文本的连贯性与可读性 |
添加关联词句,在拆分了复杂句为多个简单句之后, 添加合适的关联词,确保文本的逻辑性、流畅性和易于理解 | 避免过度使用关联词,当段落语句逻辑清晰时不要加关联词 |
表2 文本简化规则及说明
Tab. 2 Text simplification rules and explanations
| 简化规则 | 说明 |
|---|---|
简化文本,当出现无实体的修饰词或分句时,可以删除这句话 而不重构结构。全文的字数减少的幅度控制在15%内 | 在简化中首先删除了一些通常用处不大的信息,减少了文本冗余, 但仍然能保留大部分关键信息和原文的结构,防止过度删减导致 信息丢失;然后对句子结构进行中度简化,适量增加句子数量, 可以显著提高文本的易读性 |
简化语句结构,每句话只包括主语‒谓语‒宾语和少量其他信息, 句子长度尽量控制在15至25个字。将长句子拆分为多个简单句, 但句子总数的增加幅度要控制在20%以内 | |
在简化过程中不要用同义词替换,保证生成的简化文本和 原文本中的实词总数不要有明显下降 | 当词语属于词表提示中的“基础词”,且不为实词时,可以进行同义 替换,保证文本的连贯性与可读性 |
添加关联词句,在拆分了复杂句为多个简单句之后, 添加合适的关联词,确保文本的逻辑性、流畅性和易于理解 | 避免过度使用关联词,当段落语句逻辑清晰时不要加关联词 |
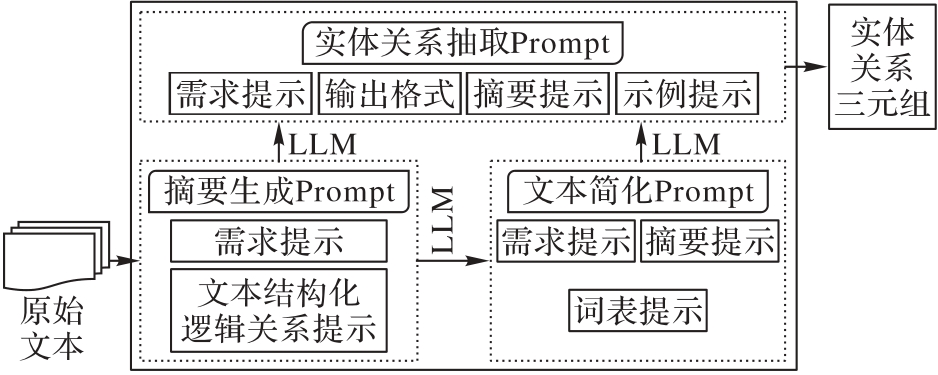
图3 MLDS-LLM的提示流程
Fig. 3 Prompt flow of MLDS-LLM

图4 结构化摘要Prompt模板
Fig. 4 Structured summary Prompt template

图5 文本简化Prompt模板
Fig. 5 Text simplification Prompt template

图6 实体关系抽取Prompt模板
Fig. 6 Entity-relation extraction Prompt template
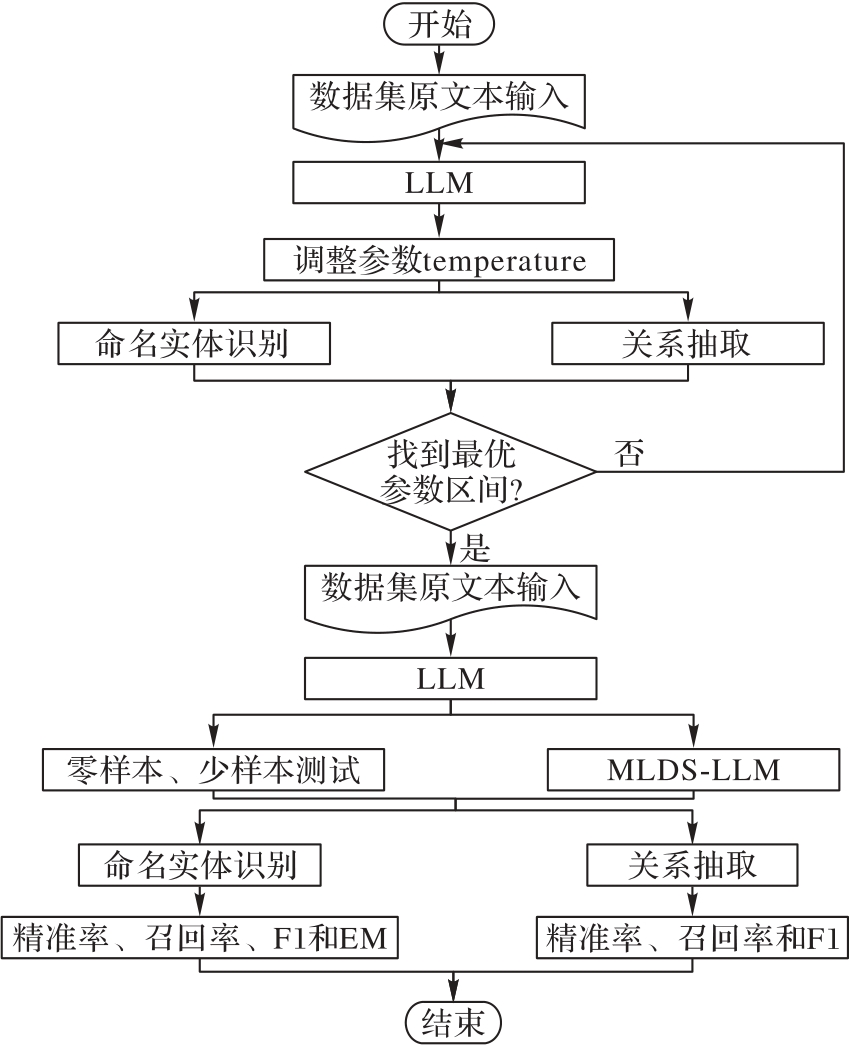
图7 实体关系抽取实验的流程
Fig. 7 Flow of entity-relation extraction experiment
| 数据集 | 所属领域 | 标注范围 |
|---|---|---|
| CL-NE-DS | 中国文学短篇 小说或文章 | 个人、代词、地点、组织、时间和杂项 实体等 |
| DiaKG | 医学 | 疾病、疾病的分期类型、病因和发病 机制等 |
| CCKS2021 | 金融 | 人物、时间、地点、事件和具体金融 数据等 |
| DulE | 媒体新闻 | 个人、地点、组织、时间、数值和事件等 |
| IEPA | 生物医学 | 蛋白质的名称、种类、说明和相互作用关系 |
表3 数据集概览
Tab. 3 Overview of datasets
| 数据集 | 所属领域 | 标注范围 |
|---|---|---|
| CL-NE-DS | 中国文学短篇 小说或文章 | 个人、代词、地点、组织、时间和杂项 实体等 |
| DiaKG | 医学 | 疾病、疾病的分期类型、病因和发病 机制等 |
| CCKS2021 | 金融 | 人物、时间、地点、事件和具体金融 数据等 |
| DulE | 媒体新闻 | 个人、地点、组织、时间、数值和事件等 |
| IEPA | 生物医学 | 蛋白质的名称、种类、说明和相互作用关系 |

图8 命名实体合并的示例图
Fig. 8 Example diagram of named entity merging
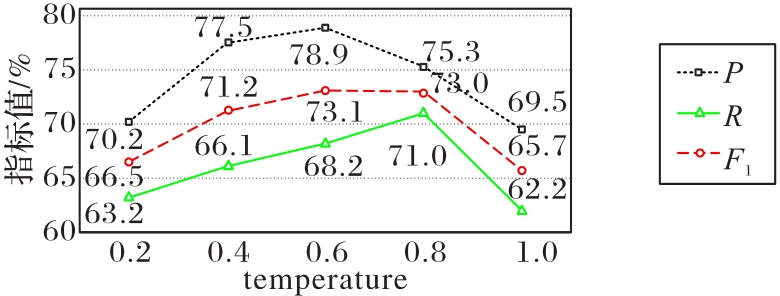
图9 LLaMA-2-70B模型在不同temperature下的实体关系抽取结果
Fig. 9 Entity-relation extraction results of LLaMA-2-70B model at different temperatures
| 摘要生成策略 | 综合评价得分 | ROUGE-1 | ROUGE-2 | ROUGE-L | 实体关系抽取F1值/% |
|---|---|---|---|---|---|
| 直接生成摘要 | 65.62 | 0.4 | 0.3 | 0.5 | 77.95 |
| 结构化摘要 | 79.64 | 0.6 | 0.3 | 0.6 | 80.83 |
表4 不同摘要生成策略效果对比
Tab. 4 Comparison of effects of different summary generation strategies
| 摘要生成策略 | 综合评价得分 | ROUGE-1 | ROUGE-2 | ROUGE-L | 实体关系抽取F1值/% |
|---|---|---|---|---|---|
| 直接生成摘要 | 65.62 | 0.4 | 0.3 | 0.5 | 77.95 |
| 结构化摘要 | 79.64 | 0.6 | 0.3 | 0.6 | 80.83 |
| 简化策略 | 平均字数 | 平均句数 | 一现词数 | 最大依存距离 | 实词重复率/% | 实体关系抽取F1值/% |
|---|---|---|---|---|---|---|
| 原文本 | 1 432.32 | 57.53 | 278.58 | 50.47 | 16.33 | 74.19 |
| LLM直接简化文本 | 937.58 | 46.47 | 256.09 | 42.47 | 16.92 | 65.46 |
| 词表+规则提示的简化文本 | 1 262.24 | 65.38 | 248.65 | 45.50 | 19.59 | 81.90 |
表5 文本简化前后的特征数值对比
Tab. 5 Comparison of feature values before and after text simplification
| 简化策略 | 平均字数 | 平均句数 | 一现词数 | 最大依存距离 | 实词重复率/% | 实体关系抽取F1值/% |
|---|---|---|---|---|---|---|
| 原文本 | 1 432.32 | 57.53 | 278.58 | 50.47 | 16.33 | 74.19 |
| LLM直接简化文本 | 937.58 | 46.47 | 256.09 | 42.47 | 16.92 | 65.46 |
| 词表+规则提示的简化文本 | 1 262.24 | 65.38 | 248.65 | 45.50 | 19.59 | 81.90 |
| 策略 | CL-NE-DS | DiaKG | CCKS2021 | DulE | IEPA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | EM | P | R | F1 | EM | P | R | F1 | EM | P | R | F1 | EM | P | R | F1 | EM | |
| 零样本测试 | 86.3 | 60.0 | 70.8 | 74.6 | 49.2 | 57.0 | 52.8 | 46.2 | 72.5 | 69.2 | 70.9 | 64.6 | 76.7 | 66.9 | 71.5 | 73.6 | 53.9 | 58.7 | 56.2 | 51.4 |
| 少样本测试 | 87.6 | 65.2 | 74.8 | 79.8 | 61.6 | 63.2 | 62.2 | 50.6 | 75.8 | 72.5 | 74.0 | 67.4 | 79.1 | 71.8 | 75.1 | 74.4 | 65.2 | 62.3 | 63.7 | 55.0 |
| MLDS-LLM | 87.4 | 71.9 | 78.9 | 82.6 | 70.9 | 72.3 | 71.8 | 53.3 | 79.5 | 78.6 | 78.9 | 69.9 | 83.9 | 72.5 | 77.8 | 80.1 | 71.9 | 61.7 | 66.3 | 57.2 |
表6 命名实体识别的实验结果 (%)
Tab. 6 Experimental results of named entity recognition
| 策略 | CL-NE-DS | DiaKG | CCKS2021 | DulE | IEPA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | EM | P | R | F1 | EM | P | R | F1 | EM | P | R | F1 | EM | P | R | F1 | EM | |
| 零样本测试 | 86.3 | 60.0 | 70.8 | 74.6 | 49.2 | 57.0 | 52.8 | 46.2 | 72.5 | 69.2 | 70.9 | 64.6 | 76.7 | 66.9 | 71.5 | 73.6 | 53.9 | 58.7 | 56.2 | 51.4 |
| 少样本测试 | 87.6 | 65.2 | 74.8 | 79.8 | 61.6 | 63.2 | 62.2 | 50.6 | 75.8 | 72.5 | 74.0 | 67.4 | 79.1 | 71.8 | 75.1 | 74.4 | 65.2 | 62.3 | 63.7 | 55.0 |
| MLDS-LLM | 87.4 | 71.9 | 78.9 | 82.6 | 70.9 | 72.3 | 71.8 | 53.3 | 79.5 | 78.6 | 78.9 | 69.9 | 83.9 | 72.5 | 77.8 | 80.1 | 71.9 | 61.7 | 66.3 | 57.2 |
| 策略 | CL-NE-DS | DiaKG | CCKS2021 | DulE | IEPA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| 零样本测试 | 77.5 | 71.0 | 74.1 | 48.8 | 61.6 | 52.8 | 66.8 | 69.6 | 68.2 | 74.2 | 70.8 | 72.5 | 46.3 | 61.8 | 54.5 |
| 少样本测试 | 80.3 | 74.7 | 77.4 | 60.2 | 67.8 | 63.6 | 71.5 | 74.3 | 73.0 | 77.6 | 69.0 | 73.1 | 53.2 | 64.1 | 58.1 |
| MLDS-LLM | 85.1 | 79.6 | 82.2 | 72.4 | 76.4 | 74.3 | 77.0 | 75.4 | 76.2 | 78.4 | 79.7 | 79.1 | 69.2 | 67.2 | 68.1 |
表7 关系抽取的实验结果 (%)
Tab. 7 Experimental results of relation extraction
| 策略 | CL-NE-DS | DiaKG | CCKS2021 | DulE | IEPA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| 零样本测试 | 77.5 | 71.0 | 74.1 | 48.8 | 61.6 | 52.8 | 66.8 | 69.6 | 68.2 | 74.2 | 70.8 | 72.5 | 46.3 | 61.8 | 54.5 |
| 少样本测试 | 80.3 | 74.7 | 77.4 | 60.2 | 67.8 | 63.6 | 71.5 | 74.3 | 73.0 | 77.6 | 69.0 | 73.1 | 53.2 | 64.1 | 58.1 |
| MLDS-LLM | 85.1 | 79.6 | 82.2 | 72.4 | 76.4 | 74.3 | 77.0 | 75.4 | 76.2 | 78.4 | 79.7 | 79.1 | 69.2 | 67.2 | 68.1 |

图10 不同模型策略在预训练前后的实体关系抽取F1值
Fig. 10 F1 values of entity-relation extraction of different model strategies before and after pre-training
| [1] | COHEN A M, HERSH W R. A survey of current work in biomedical text mining[J]. Briefings in Bioinformatics, 2005, 6(1): 57-71. |
| [2] | WANG Q, MAO Z, WANG B, et al. Knowledge graph embedding: a survey of approaches and applications[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2724-2743. |
| [3] | SHARMA Y, BHARGAVA R, TADIKONDA B V. Named entity recognition for code mixed social media sentences[J]. International Journal of Software Science and Computational Intelligence, 2021, 13(2): 23-36. |
| [4] | YAN R, JIANG X, DANG D. Named entity recognition by using XLNet-BiLSTM-CRF[J]. Neural Processing Letters, 2021, 53(5): 3339-3356. |
| [5] | SIDDHARTH L, LUO J. Retrieval augmented generation using engineering design knowledge[J]. Knowledge-Based Systems, 2024, 303: No.112410. |
| [6] | LEE J, HICKE Y, YU R, et al. The life cycle of large language models in education: a framework for understanding sources of bias[J]. British Journal of Educational Technology, 2024, 55(5): 1982-2002. |
| [7] | THIRUNAVUKARASU A J, TING D S J, ELANGOVAN K, et al. Large language models in medicine[J]. Nature Medicine, 2023, 29(8): 1930-1940. |
| [8] | 徐磊,胡亚豪,潘志松. 针对大语言模型的偏见性研究综述[J]. 计算机应用研究, 2024, 41(10): 2881-2892. |
| XU L, HU Y H, PAN Z S. Review of bias research on large language model[J]. Applications Research of Computers, 2024, 41(10): 2881-2892. | |
| [9] | 魏静,岳昆,段亮,等. 基于指代消解的民间文学文本实体关系抽取[J]. 河南师范大学学报(自然科学版), 2024, 52(1): 84-92. |
| WEI J, YUE K, DUAN L, et al. Coreference resolution for relation extraction in folk literature[J]. Journal of Henan Normal University (Natural Science Edition), 2024, 52(1): 84-92. | |
| [10] | 李丽双,郭瑞,黄德根,等. 基于迁移学习的蛋白质交互关系抽取[J].中文信息学报, 2016, 30(2):160-167. |
| LI L S, GUO R, HUANG D G, et al. Protein-protein interaction extraction based on transfer learning[J]. Journal of Chinese Information Processing, 2016, 30(2): 160-167. | |
| [11] | 周筠昌,陈振彬,陈珂. 基于深度神经网络的关系抽取研究综述[J]. 广东石油化工学院学报, 2022, 32(1): 31-35. |
| ZHOU J C, CHEN Z B, CHEN K. A review of relation extraction methods based on deep neural network mechanism[J]. Journal of Guangdong University of Petrochemical Technology, 2022, 32(1): 31-35. | |
| [12] | ZHANG Z, LI Z, LIU H, et al. Multi-scale dynamic convolutional network for knowledge graph embedding[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(5): 2335-2347. |
| [13] | MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data[C]// Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. Stroudsburg: ACL, 2009: 1003-1011. |
| [14] | HAN J, JIA K. Entity relation joint extraction method for manufacturing industry knowledge data based on improved BERT algorithm[J]. Cluster Computing, 2024, 27(6): 7941-7954. |
| [15] | SUI D, ZENG X, CHEN Y, et al. Joint entity and relation extraction with set prediction networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(9): 12784-12795. |
| [16] | 鄂海红,张文静,肖思琪,等. 深度学习实体关系抽取研究综述[J]. 软件学报, 2019, 30(6): 1793-1818. |
| E H H, ZHANG W J, XIAO S Q, et al. Survey of entity relationship extraction based on deep learning[J]. Journal of Software, 2019, 30(6): 1793-1818. | |
| [17] | WANG X, LI J, ZHENG Z, et al. Entity and relation extraction with rule-guided dictionary as domain knowledge[J]. Frontiers of Engineering Management, 2022, 9(4): 610-622. |
| [18] | 黄梅根,刘佳乐,刘川. 基于BERT的中文多关系抽取方法研究[J]. 计算机工程与应用, 2021, 57(21): 234-240. |
| HUANG M G, LIU J L, LIU C. Research on improved BERT’s Chinese multi-relation extraction method[J]. Computer Engineering and Applications, 2021, 57(21): 234-240. | |
| [19] | 张西硕,柳林,王海龙,等. 知识图谱中实体关系抽取方法研究[J]. 计算机科学与探索, 2024, 18(3): 574-596. |
| ZHANG X S, LIU L, WANG H L, et al. Survey of entity relationship extraction methods in knowledge graphs[J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(3): 574-596. | |
| [20] | LV P, ZHANG Q, WU M, et al. Intelligent extraction of medical entity relationship based on graph neural network and optimization strategy[J]. Knowledge-Based Systems, 2024, 294: No.111735. |
| [21] | MIN B, ROSS H, SULEM E, et al. Recent advances in natural language processing via large pre-trained language models: a survey[J]. ACM Computing Surveys, 2024, 56(2): No.30. |
| [22] | 鲍彤,章成志. ChatGPT中文信息抽取能力测评——以三种典型的抽取任务为例[J]. 数据分析与知识发现, 2023, 7(9):1-11. |
| BAO T, ZHANG C Z. Extracting Chinese information with ChatGPT: an empirical study by three typical tasks[J]. Data Analysis and Knowledge Discovery, 2023, 7(9): 1-11. | |
| [23] | YANG X, CHEN A, POURNEJATIAN N, et al. A large language model for electronic health records[J]. npj Digital Medicine, 2022, 5: No.194. |
| [24] | GUEVARA M, CHEN S, THOMAS S, et al. Large language models to identify social determinants of health in electronic health records[J]. npj Digital Medicine, 2024, 7: No.6. |
| [25] | DAGDELEN J, DUNN A, LEE S, et al. Structured information extraction from scientific text with large language models[J]. Nature Communications, 2024, 15: No.1418. |
| [26] | 杨燕,叶枫,许栋,等. 融合大语言模型和提示学习的数字孪生水利知识图谱构建[J]. 计算机应用, 2025, 45(3): 785-793. |
| YANG Y, YE F, XU D, et al. Construction of digital twin water conservancy knowledge graph integrating large language models and prompt learning[J]. Journal of Computer Applications, 2025, 45(3): 785-793. | |
| [27] | LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): No.195. |
| [28] | KOCOŃ J, CICHECKI I, KASZYCA O, et al. ChatGPT: jack of all trades, master of none[J]. Information Fusion, 2023, 99: No.101861. |
| [29] | PAN W, CHEN Q, XU X, et al. A preliminary evaluation of ChatGPT for zero-shot dialogue understanding[R/OL]. [2023-04-09].. |
| [30] | WANG S, SUN X, LI X, et al. GPT-NER: named entity recognition via large language models[C]// Findings of the Association for Computational Linguistics: NAACL 2025. Stroudsburg: ACL, 2025: 4257-4275. |
| [31] | 徐豪帅,洪亮,侯雯君. 基于提示集成的少样本关系抽取方法[J]. 数据分析与知识发现, 2024, 8(10):66-76. |
| XU H S, HONG L, HOU W J. Extracting few-shot relation based on prompt ensemble[J]. Data Analysis and Knowledge Discovery, 2024, 8(10): 66-76. | |
| [32] | 李斌,林民,斯日古楞,等. 基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法[J]. 计算机应用, 2025, 45(1): 75-81. |
| LI B, LIN M, SIRIGULENG, et al. Joint entity-relation extraction method for ancient Chinese books based on prompt learning and global pointer network[J]. Journal of Computer Applications, 2025, 45(1): 75-81. | |
| [33] | 赵建飞,陈挺,王小梅,等. 基于大语言模型知识自蒸馏的无标注专利关键信息抽取[J]. 数据分析与知识发现, 2024, 8(8/9):133-143. |
| ZHAO J F, CHEN T, WANG X M, et al. Extracting key information from unlabeled patents based on knowledge self-distillation of large language model[J]. Data Analysis and Knowledge Discovery, 2024, 8(8/9): 133-143. | |
| [34] | CHAKMA K, DAS A. A 5W1H based annotation scheme for semantic role labeling of English tweets[J]. Computación y Sistemas, 2018, 22(3): 747-755. |
| [35] | LI J, LI G, LI Y, et al. Structured chain-of-thought prompting for code generation[J]. ACM Transactions on Software Engineering and Methodology, 2025, 34(2): No.37. |
| [36] | 王楚童,李明达,孙孟轩,等. 融合大规模医学事实的跨语言双层知识图谱[J]. 软件学报, 2025, 36(3): 1240-1253. |
| WANG C T, LI M D, SUN M X, et al. Cross-language bilayer knowledge graph with large-scale medical facts[J]. Journal of Software, 2025, 36(3): 1240-1253. | |
| [37] | 肖蕾,陈镇家. 数据驱动的中文实体抽取方法综述[J]. 计算机工程与应用, 2024, 60(16): 34-48. |
| XIAO L, CHEN Z J. Review of data-driven approaches to Chinese entity extraction[J]. Computer Engineering and Applications, 2024, 60(16): 34-48. | |
| [38] | 张仰森,刘帅康,刘洋,等. 基于深度学习的实体关系联合抽取研究综述[J]. 电子学报, 2023, 51(4): 1093-1116. |
| ZHANG Y S, LIU S K, LIU Y, et al. Joint extraction of entities and relations based on deep learning: a survey[J]. Acta Electronica Sinica, 2023, 51(4): 1093-1116. |
| [1] | 张滨滨, 秦永彬, 黄瑞章, 陈艳平. 结合大语言模型与动态提示的裁判文书摘要方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2783-2789. |
| [2] | 任登燃, 王淑营. 基于差分边界增强的风电装备嵌套命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2798-2805. |
| [3] | 李莉, 宋涵, 刘培鹤, 陈汉林. 基于数据增强和残差网络的敏感信息命名实体识别[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2790-2797. |
| [4] | 余婧, 陈艳平, 扈应, 黄瑞章, 秦永彬. 结合实体边界偏移的序列标注优化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2522-2529. |
| [5] | 冯涛, 刘晨. 自动化偏好对齐的双阶段提示调优方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2442-2447. |
| [6] | 闫家鑫, 陈艳平, 杨卫哲, 黄瑞章, 秦永彬. 基于特征组合的异构图注意力网络关系抽取[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2470-2476. |
| [7] | 徐章杰, 陈艳平, 扈应, 黄瑞章, 秦永彬. 联合边界生成的多目标学习的嵌套命名实体识别[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2229-2236. |
| [8] | 张立孝, 马垚, 杨玉丽, 于丹, 陈永乐. 基于命名实体识别的大规模物联网二进制组件识别[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2288-2295. |
| [9] | 杨大伟, 徐西海, 宋威. 结合语义增强和感知注意力的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1801-1808. |
| [10] | 王海杰, 张广鑫, 史海, 陈树. 基于实体表示增强的文档级关系抽取[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1809-1816. |
| [11] | 胡婕, 吴翠, 孙军, 张龑. 基于回指与逻辑推理的文档级关系抽取模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1496-1503. |
| [12] | 胡婕, 武帅星, 曹芝兰, 张龑. 基于全域信息融合和多维关系感知的命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1511-1519. |
| [13] | 曾碧卿, 钟广彬, 温志庆. 基于分解式模糊跨度的小样本命名实体识别[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1504-1510. |
| [14] | 孙熠衡, 刘茂福. 基于知识提示微调的标书信息抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1169-1176. |
| [15] | 何静, 沈阳, 谢润锋. 大语言模型幻觉现象的识别与优化[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 709-714. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||