


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3101-3110.DOI: 10.11772/j.issn.1001-9081.2024101464
• 人工智能 • 上一篇
黄朋1, 林佳瑜2( ), 梁祖红1,3
), 梁祖红1,3
收稿日期:2024-10-21
修回日期:2025-01-17
接受日期:2025-01-22
发布日期:2025-10-14
出版日期:2025-10-10
通讯作者:
林佳瑜
作者简介:黄朋(2001—),男,广东深圳人,硕士研究生,CCF会员,主要研究方向:句子嵌入、数据增强、数据挖掘基金资助:
Peng HUANG1, Jiayu LIN2(), Zuhong LIANG1,3
Received:2024-10-21
Revised:2025-01-17
Accepted:2025-01-22
Online:2025-10-14
Published:2025-10-10
Contact:
Jiayu LIN
About author:HUANG Peng, born in 2001, M. S. candidate. His research interests include sentence embedding, data augmentation, data mining.Supported by:摘要:
中文无监督对比学习面临多重挑战:1)中文句子结构灵活多变,语义模糊性较高,使得模型难以准确捕捉深层语义特征;2)在小规模数据集上,对比学习模型的特征表达能力不足,难以充分学习到有效的语义表示;3)数据增强过程中可能引入多余噪声,进一步加剧训练的不稳定性。这些问题共同限制了模型在中文语义理解上的表现。为了解决这些问题,提出一种基于互信息(MI)和提示学习的中文无监督对比学习(CMIPL)方法。首先,采用提示学习的数据增强方式构建对比学习所需的样本对,在保留全部文本信息和顺序的同时增加文本多样性,规范样本的输入结构,并为输入样本提供提示模板作为上下文,引导模型更深入地学习细粒度语义;其次,在预训练语言模型输出表示的基础上,使用提示模板去噪方法去除数据增强所引入的多余噪声;最后,将正样本结构信息融入模型训练体系之中,计算增强视图的注意力张量的MI,再将注意力MI引入损失函数,通过最小化损失函数,优化模型注意力的分布,最大化增强视图结构的对齐,使模型更好地拉近正样本对的距离。在ATEC、BQ、PAWSX这3个公开中文文本相似度数据集构建的小样本数据上进行对比实验。结果表明,所提方法的平均性能最佳,特别是在训练集数据量较少的情况下,在使用1%和10%样本量的条件下,与基线对比学习模型SimCSE(Simple Contrastive learning of Sentence Embeddings)相比,CMIPL的平均准确率和斯皮尔曼等级相关系数(SR)分别提高了3.45、4.07和1.64、2.61个百分点,验证了CMIPL在小样本中文无监督对比学习领域的有效性。
中图分类号:
黄朋, 林佳瑜, 梁祖红. 基于互信息和提示学习的中文无监督对比学习方法[J]. 计算机应用, 2025, 45(10): 3101-3110.
Peng HUANG, Jiayu LIN, Zuhong LIANG. Unsupervised contrastive learning for Chinese with mutual information and prompt learning[J]. Journal of Computer Applications, 2025, 45(10): 3101-3110.
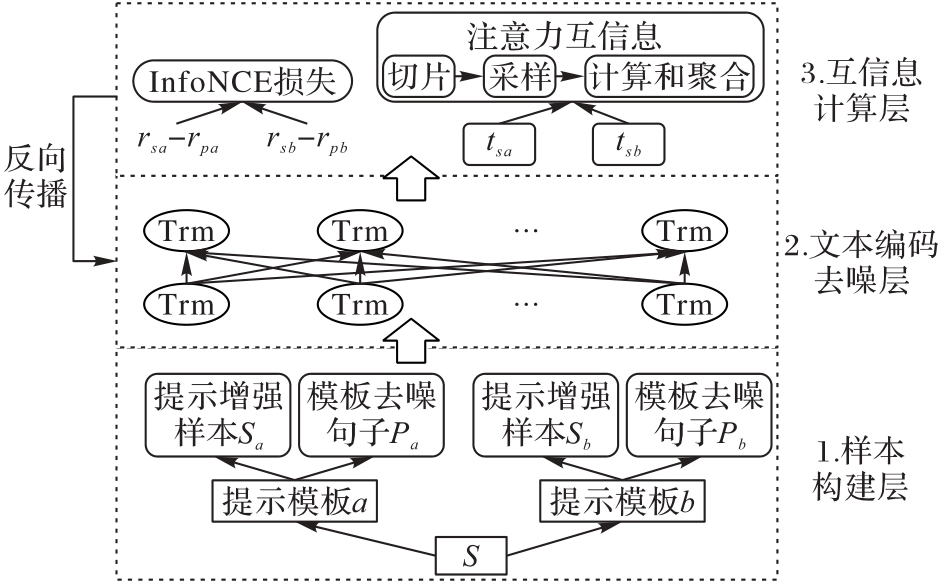
图 1 CMIPL的框架
Fig. 1 Architecture of CMIPL
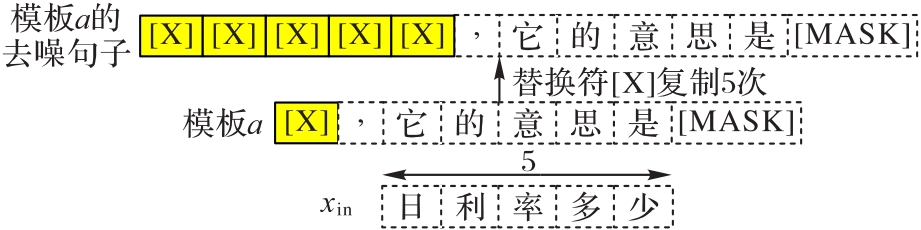
图2 模板去噪句子的构建
Fig. 2 Construction of template denoised sentence
| 项目 | 内容 |
|---|---|
| 原句 | 日利率多少 |
| 提示增强句子sai | 日利率多少,它的意思是[MASK] |
| 提示增强句子sbi | 日利率多少,这句话的含义是[MASK] |
| 去噪模板句子pai | [X][X][X][X][X],它的意思是[MASK] |
| 去噪模板句子pbi | [X][X][X][X][X],这句话的含义是[MASK] |
表1 句子构建实例
Tab. 1 Sentence construction instances
| 项目 | 内容 |
|---|---|
| 原句 | 日利率多少 |
| 提示增强句子sai | 日利率多少,它的意思是[MASK] |
| 提示增强句子sbi | 日利率多少,这句话的含义是[MASK] |
| 去噪模板句子pai | [X][X][X][X][X],它的意思是[MASK] |
| 去噪模板句子pbi | [X][X][X][X][X],这句话的含义是[MASK] |
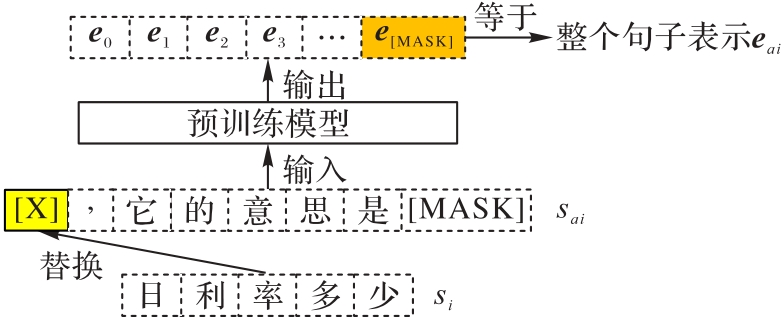
图3 使用提示模板获取句子嵌入的流程
Fig. 3 Flow of using prompt template to obtain sentence embedding
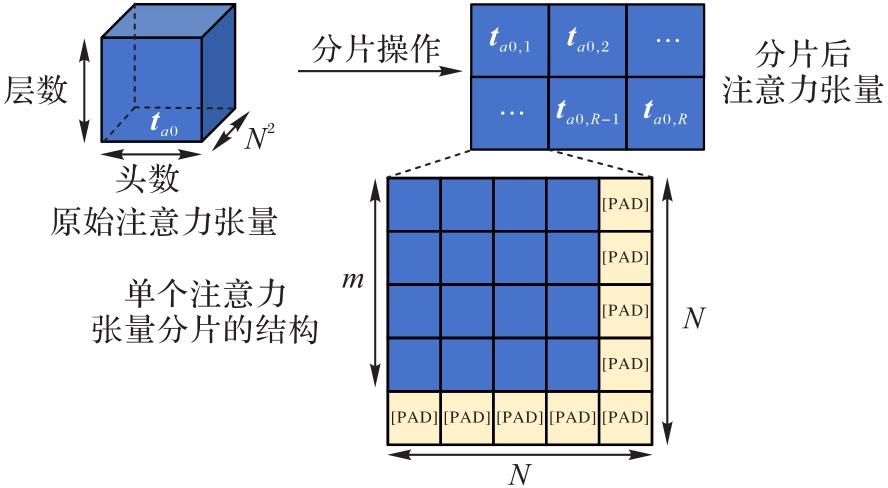
图4 注意力张量切片的示意图
Fig. 4 Schematic diagram of slicing attention tensor
| 数据集 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---|---|---|---|
| BQ | 100 000 | 10 000 | 10 000 |
| ATEC | 62 477 | 20 000 | 20 000 |
| PAWSX | 49 401 | 2 000 | 2 000 |
表2 数据集中数据的详细统计
Tab. 2 Detailed statistics of data in datasets
| 数据集 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---|---|---|---|
| BQ | 100 000 | 10 000 | 10 000 |
| ATEC | 62 477 | 20 000 | 20 000 |
| PAWSX | 49 401 | 2 000 | 2 000 |
| 层数 | ATEC/% | BQ/% | PAWSX/% | 平均值/% |
|---|---|---|---|---|
| 12 | 34.68 | 49.05 | 14.03 | 32.59 |
| [ | 34.52 | 49.12 | 14.17 | 32.60 |
| [ | 34.86 | 49.41 | 14.96 | 33.08 |
| [ | 35.06 | 49.80 | 15.33 | 33.40 |
| [ | 35.08 | 49.52 | 15.21 | 33.27 |
| [ | 35.03 | 49.95 | 15.38 | 33.45 |
表3 注意力层数选择的实验结果
Tab. 3 Experimental results of attention layer selection
| 层数 | ATEC/% | BQ/% | PAWSX/% | 平均值/% |
|---|---|---|---|---|
| 12 | 34.68 | 49.05 | 14.03 | 32.59 |
| [ | 34.52 | 49.12 | 14.17 | 32.60 |
| [ | 34.86 | 49.41 | 14.96 | 33.08 |
| [ | 35.06 | 49.80 | 15.33 | 33.40 |
| [ | 35.08 | 49.52 | 15.21 | 33.27 |
| [ | 35.03 | 49.95 | 15.38 | 33.45 |
| 样本数据量 | 模型 | ATEC | BQ | PAWSX | 平均值 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | SR | Acc | SR | Acc | SR | Acc | SR | ||
| 1 | Word2Vec | 31.02 | 16.13 | 26.15 | 23.55 | 20.21 | 7.56 | 25.79 | 15.75 |
| SimCSE | 38.95 | 30.77 | 56.65 | 43.42 | 45.65 | 9.59 | 47.08 | 27.93 | |
| GS-InfoNCE | 40.11 | 28.29 | 56.71 | 44.12 | 45.31 | 11.76 | 47.38 | 28.06 | |
| ESimCSE | 36.23 | 27.50 | 58.26 | 41.94 | 44.75 | 9.78 | 46.41 | 26.41 | |
| ConSERT | 33.39 | 25.93 | 57.50 | 38.54 | 45.80 | 7.96 | 45.56 | 24.14 | |
| CMIPL | 44.85 | 34.83 | 59.93 | 47.32 | 46.80 | 13.85 | 50.53 | 32.00 | |
| RC | 28.05 | 31.58 | 50.00 | 42.52 | 39.70 | 10.29 | 39.25 | 28.13 | |
| SimCSE(RC) | 40.21 | 33.75 | 57.66 | 44.63 | 46.21 | 10.65 | 48.03 | 29.61 | |
| CMIPL(RC) | 46.55 | 36.83 | 61.35 | 48.34 | 47.50 | 14.83 | 51.80 | 33.33 | |
| 10 | Word2Vec | 35.28 | 16.49 | 28.21 | 24.67 | 21.05 | 7.44 | 28.18 | 16.20 |
| SimCSE | 55.40 | 32.35 | 65.91 | 48.48 | 46.03 | 11.53 | 55.78 | 30.79 | |
| GS-InfoNCE | 53.29 | 28.97 | 63.26 | 46.32 | 45.81 | 12.76 | 54.12 | 29.35 | |
| ESimCSE | 51.15 | 31.84 | 64.40 | 48.07 | 45.85 | 10.18 | 53.80 | 30.03 | |
| ConSERT | 54.94 | 29.74 | 64.16 | 46.78 | 46.10 | 8.14 | 55.07 | 28.22 | |
| CMIPL | 57.92 | 35.06 | 67.07 | 49.80 | 47.28 | 15.33 | 57.42 | 33.40 | |
| RC | 31.03 | 33.03 | 49.21 | 44.13 | 40.21 | 11.93 | 40.15 | 29.70 | |
| SimCSE(RC) | 57.90 | 34.87 | 67.35 | 49.28 | 46.53 | 12.89 | 57.26 | 32.35 | |
| CMIPL(RC) | 59.03 | 38.81 | 68.12 | 50.17 | 47.61 | 16.98 | 58.25 | 35.32 | |
| 100 | Word2Vec | 34.56 | 16.08 | 27.63 | 23.56 | 24.15 | 7.30 | 28.78 | 15.65 |
| SimCSE | 77.10 | 38.69 | 67.69 | 50.96 | 48.50 | 21.67 | 64.43 | 37.11 | |
| GS-InfoNCE | 73.21 | 33.03 | 68.66 | 48.27 | 47.93 | 24.14 | 63.27 | 35.15 | |
| ESimCSE | 62.15 | 35.13 | 67.40 | 49.28 | 46.70 | 20.56 | 58.75 | 34.99 | |
| ConSERT | 74.94 | 31.98 | 69.84 | 49.51 | 47.75 | 18.75 | 64.18 | 33.41 | |
| CMIPL | 77.93 | 39.63 | 70.52 | 51.16 | 48.21 | 23.53 | 65.55 | 38.11 | |
| RC | 38.11 | 37.54 | 52.23 | 46.89 | 44.23 | 19.71 | 44.86 | 34.71 | |
| SimCSE(RC) | 78.65 | 40.98 | 70.24 | 51.72 | 49.23 | 22.24 | 66.04 | 38.31 | |
| CMIPL(RC) | 78.52 | 41.71 | 70.59 | 52.05 | 48.56 | 24.13 | 65.89 | 39.30 | |
表4 不同模型的对比实验结果 (%)
Tab. 4 Comparison experimental results of different models
| 样本数据量 | 模型 | ATEC | BQ | PAWSX | 平均值 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | SR | Acc | SR | Acc | SR | Acc | SR | ||
| 1 | Word2Vec | 31.02 | 16.13 | 26.15 | 23.55 | 20.21 | 7.56 | 25.79 | 15.75 |
| SimCSE | 38.95 | 30.77 | 56.65 | 43.42 | 45.65 | 9.59 | 47.08 | 27.93 | |
| GS-InfoNCE | 40.11 | 28.29 | 56.71 | 44.12 | 45.31 | 11.76 | 47.38 | 28.06 | |
| ESimCSE | 36.23 | 27.50 | 58.26 | 41.94 | 44.75 | 9.78 | 46.41 | 26.41 | |
| ConSERT | 33.39 | 25.93 | 57.50 | 38.54 | 45.80 | 7.96 | 45.56 | 24.14 | |
| CMIPL | 44.85 | 34.83 | 59.93 | 47.32 | 46.80 | 13.85 | 50.53 | 32.00 | |
| RC | 28.05 | 31.58 | 50.00 | 42.52 | 39.70 | 10.29 | 39.25 | 28.13 | |
| SimCSE(RC) | 40.21 | 33.75 | 57.66 | 44.63 | 46.21 | 10.65 | 48.03 | 29.61 | |
| CMIPL(RC) | 46.55 | 36.83 | 61.35 | 48.34 | 47.50 | 14.83 | 51.80 | 33.33 | |
| 10 | Word2Vec | 35.28 | 16.49 | 28.21 | 24.67 | 21.05 | 7.44 | 28.18 | 16.20 |
| SimCSE | 55.40 | 32.35 | 65.91 | 48.48 | 46.03 | 11.53 | 55.78 | 30.79 | |
| GS-InfoNCE | 53.29 | 28.97 | 63.26 | 46.32 | 45.81 | 12.76 | 54.12 | 29.35 | |
| ESimCSE | 51.15 | 31.84 | 64.40 | 48.07 | 45.85 | 10.18 | 53.80 | 30.03 | |
| ConSERT | 54.94 | 29.74 | 64.16 | 46.78 | 46.10 | 8.14 | 55.07 | 28.22 | |
| CMIPL | 57.92 | 35.06 | 67.07 | 49.80 | 47.28 | 15.33 | 57.42 | 33.40 | |
| RC | 31.03 | 33.03 | 49.21 | 44.13 | 40.21 | 11.93 | 40.15 | 29.70 | |
| SimCSE(RC) | 57.90 | 34.87 | 67.35 | 49.28 | 46.53 | 12.89 | 57.26 | 32.35 | |
| CMIPL(RC) | 59.03 | 38.81 | 68.12 | 50.17 | 47.61 | 16.98 | 58.25 | 35.32 | |
| 100 | Word2Vec | 34.56 | 16.08 | 27.63 | 23.56 | 24.15 | 7.30 | 28.78 | 15.65 |
| SimCSE | 77.10 | 38.69 | 67.69 | 50.96 | 48.50 | 21.67 | 64.43 | 37.11 | |
| GS-InfoNCE | 73.21 | 33.03 | 68.66 | 48.27 | 47.93 | 24.14 | 63.27 | 35.15 | |
| ESimCSE | 62.15 | 35.13 | 67.40 | 49.28 | 46.70 | 20.56 | 58.75 | 34.99 | |
| ConSERT | 74.94 | 31.98 | 69.84 | 49.51 | 47.75 | 18.75 | 64.18 | 33.41 | |
| CMIPL | 77.93 | 39.63 | 70.52 | 51.16 | 48.21 | 23.53 | 65.55 | 38.11 | |
| RC | 38.11 | 37.54 | 52.23 | 46.89 | 44.23 | 19.71 | 44.86 | 34.71 | |
| SimCSE(RC) | 78.65 | 40.98 | 70.24 | 51.72 | 49.23 | 22.24 | 66.04 | 38.31 | |
| CMIPL(RC) | 78.52 | 41.71 | 70.59 | 52.05 | 48.56 | 24.13 | 65.89 | 39.30 | |
| 样本数据量 | 模型 | Acc | SR |
|---|---|---|---|
| 1 | w/o DE | 57.69 | 46.60 |
| w/o AMI | 57.27 | 45.56 | |
| w/o AMI&DE | 56.74 | 45.26 | |
| RoBERTa | 34.15 | 27.95 | |
| CMIPL | 59.93 | 47.32 | |
| 10 | w/o DE | 66.21 | 48.76 |
| w/o AMI | 66.37 | 48.40 | |
| w/o AMI&DE | 65.93 | 47.32 | |
| RoBERTa | 33.18 | 30.77 | |
| CMIPL | 67.07 | 49.80 | |
| 100 | w/o DE | 69.73 | 50.26 |
| w/o AMI | 69.54 | 50.62 | |
| w/o AMI&DE | 68.87 | 50.61 | |
| RoBERTa | 36.56 | 29.03 | |
| CMIPL | 70.52 | 51.16 |
表5 消融实验结果 (%)
Tab. 5 Ablation experimental results
| 样本数据量 | 模型 | Acc | SR |
|---|---|---|---|
| 1 | w/o DE | 57.69 | 46.60 |
| w/o AMI | 57.27 | 45.56 | |
| w/o AMI&DE | 56.74 | 45.26 | |
| RoBERTa | 34.15 | 27.95 | |
| CMIPL | 59.93 | 47.32 | |
| 10 | w/o DE | 66.21 | 48.76 |
| w/o AMI | 66.37 | 48.40 | |
| w/o AMI&DE | 65.93 | 47.32 | |
| RoBERTa | 33.18 | 30.77 | |
| CMIPL | 67.07 | 49.80 | |
| 100 | w/o DE | 69.73 | 50.26 |
| w/o AMI | 69.54 | 50.62 | |
| w/o AMI&DE | 68.87 | 50.61 | |
| RoBERTa | 36.56 | 29.03 | |
| CMIPL | 70.52 | 51.16 |
| λ | SR/% | |||
|---|---|---|---|---|
| ATEC | BQ | PAWSX | 平均值 | |
| 100 | 33.62 | 47.85 | 12.65 | 31.37 |
| 33.92 | 48.03 | 13.75 | 31.90 | |
| 34.88 | 48.16 | 14.38 | 32.47 | |
| 35.06 | 49.80 | 15.33 | 33.40 | |
| 34.73 | 48.26 | 14.13 | 32.37 | |
| 34.63 | 48.45 | 13.80 | 32.29 | |
表6 粗网格的搜索结果
Tab. 6 Coarse grid search results
| λ | SR/% | |||
|---|---|---|---|---|
| ATEC | BQ | PAWSX | 平均值 | |
| 100 | 33.62 | 47.85 | 12.65 | 31.37 |
| 33.92 | 48.03 | 13.75 | 31.90 | |
| 34.88 | 48.16 | 14.38 | 32.47 | |
| 35.06 | 49.80 | 15.33 | 33.40 | |
| 34.73 | 48.26 | 14.13 | 32.37 | |
| 34.63 | 48.45 | 13.80 | 32.29 | |
| λ | SR/% | |||
|---|---|---|---|---|
| ATEC | BQ | PAWSX | 平均值 | |
| 34.80 | 47.32 | 14.56 | 32.23 | |
| 34.96 | 48.80 | 14.88 | 32.88 | |
| 35.06 | 49.80 | 15.33 | 33.40 | |
| 35.03 | 49.20 | 15.12 | 33.12 | |
| 34.73 | 47.32 | 14.93 | 32.33 | |
表7 细网格的搜索结果
Tab. 7 Fine grid search results
| λ | SR/% | |||
|---|---|---|---|---|
| ATEC | BQ | PAWSX | 平均值 | |
| 34.80 | 47.32 | 14.56 | 32.23 | |
| 34.96 | 48.80 | 14.88 | 32.88 | |
| 35.06 | 49.80 | 15.33 | 33.40 | |
| 35.03 | 49.20 | 15.12 | 33.12 | |
| 34.73 | 47.32 | 14.93 | 32.33 | |
| [1] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [2] | FLORIDI L, CHIRIATTI M. GPT-3: its nature, scope, limits, and consequences[J]. Minds and Machines, 2020, 30(4): 681-694. |
| [3] | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2024-09-20].. |
| [4] | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| [5] | HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9726-9735. |
| [6] | GAO T, YAO X, CHEN D. SimCSE: simple contrastive learning of sentence embeddings[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 6894-6910. |
| [7] | HE H, GIMPEL K, LIN J. Multi-perspective sentence similarity modeling with convolutional neural networks[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1576-1586. |
| [8] | WEI J, ZOU K. EDA: easy data augmentation techniques for boosting performance on text classification tasks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 6382-6388. |
| [9] | SENNRICH R, HADDOW B, BIRCH A. Improving neural machine translation models with monolingual data[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 86-96. |
| [10] | 孙海涛,林佳瑜,梁祖红,等. 结合标签混淆的中文文本分类数据增强技术[J]. 计算机应用, 2025, 45(4): 1113-1119. |
| SUN H T, LIN J Y, LIANG Z H, et al. Data augmentation technique incorporating label confusion for Chinese text classification[J]. Journal of Computer Applications, 2025, 45(4): 1113-1119. | |
| [11] | SHORTEN C, KHOSHGOFTAAR T M, FURHT B. Text data augmentation for deep learning[J]. Journal of Big Data, 2021, 8: No.101. |
| [12] | JIANG T, JIAO J, HUANG S, et al. PromptBERT: improving BERT sentence embeddings with prompts[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 8826-8837. |
| [13] | 严雪文,黄章进. 基于对比学习的小样本图像分类方法[J]. 计算机应用, 2025, 45(2): 383-391. |
| YAN X W, HUANG Z J. Few-shot image classification method based on contrast learning[J]. Journal of Computer Applications, 2025, 45(2): 383-391. | |
| [14] | ZHANG Y, ZHANG R, MENSAH S, et al. Unsupervised sentence representation via contrastive learning with mixing negatives[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 11730-11738. |
| [15] | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| [16] | 余新言,曾诚,王乾,等. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 计算机应用, 2024, 44(6): 1767-1774. |
| YU X Y, ZENG C, WANG Q, et al. Few-shot news topic classification method based on knowledge enhancement and prompt learning[J]. Journal of Computer Applications, 2024, 44(6): 1767-1774. | |
| [17] | GAO T, FISCH A, CHEN D. Making pre-trained language models better few-shot learners[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 3816-3830. |
| [18] | LESTER B, AL-RFOU R, CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 3045-3059. |
| [19] | XU J, SHAO W, CHEN L, et al. SimCSE++: improving contrastive learning for sentence embeddings from two perspective[C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 12028-12040. |
| [20] | SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 815-823. |
| [21] | HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554. |
| [22] | VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. [2024-09-20].. |
| [23] | SHANNON C E. A mathematical theory of communication[J]. Bell System Technical Journal, 1948, 27(3): 379-423. |
| [24] | WU X, GAO C, LIN Z, et al. InfoCSE: information-aggregated contrastive learning of sentence embeddings[C]// Findings of the Association for Computational Linguistics: EMNLP 2022. Stroudsburg: ACL, 2022: 3060-3070. |
| [25] | KLEIN T, NABI M. miCSE: mutual information contrastive learning for low-shot sentence embeddings[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 6159-6177. |
| [26] | FAN X, ZHANG S, CHEN B, et al. Bayesian attention modules[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 16362-16376. |
| [27] | VOITA E, TALBOT D, MOISEEV F, et al. Analyzing multi-head self-attention: specialized heads do the heavy lifting, the rest can be pruned[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 5797-5808. |
| [28] | CHURCH K W. Word2Vec[J]. Natural Language Engineering, 2017, 23(1): 155-162. |
| [29] | WU X, GAO C, SU Y, et al. Smoothed contrastive learning for unsupervised sentence embedding[C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 4902-4906. |
| [30] | WU X, GAO C, ZANG L, et al. ESimCSE: enhanced sample building method for contrastive learning of unsupervised sentence embedding[C]// Proceedings of the 29th International Conference on Computational Linguistics. [S. l. ]: International Committee on Computational Linguistics, 2022: 3898-3907. |
| [31] | YAN Y, LI R, WANG S, et al. ConSERT: a contrastive framework for self-supervised sentence representation transfer[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 5065-5075. |
| [1] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [2] | 刘超, 余岩化. 融合降噪策略与多视图对比学习的知识感知推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2827-2837. |
| [3] | 王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506. |
| [4] | 谢劲, 褚苏荣, 强彦, 赵涓涓, 张华, 高勇. 用于胸片中硬负样本识别的双支分布一致性对比学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2369-2377. |
| [5] | 王震洲, 郭方方, 宿景芳, 苏鹤, 王建超. 面向智能巡检的视觉模型鲁棒性优化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2361-2368. |
| [6] | 姜超英, 李倩, 刘宁, 刘磊, 崔立真. 基于图对比学习的再入院预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1784-1792. |
| [7] | 余明峰, 秦永彬, 黄瑞章, 陈艳平, 林川. 基于对比学习增强双注意力机制的多标签文本分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1732-1740. |
| [8] | 颜文婧, 王瑞东, 左敏, 张青川. 基于风味嵌入异构图层次学习的食谱推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1869-1878. |
| [9] | 黄颖, 高胜美, 陈广, 刘苏. 结合信噪比引导的双分支结构和直方图均衡的低照度图像增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1971-1979. |
| [10] | 李昕, 刘雯, 廖集秀, 杨宗驰. 面向机器理解的可视化交互信息重构方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1748-1755. |
| [11] | 何玉林, 李旭, 贺颖婷, 崔来中, 黄哲学. 基于最大均值差异的子空间高斯混合模型聚类集成算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1712-1723. |
| [12] | 罗蒙, 高超, 王震. 基于带约束谱聚类的启发式车辆路径规划算法优化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1387-1394. |
| [13] | 龙雨菲, 牟宇辰, 刘晔. 基于张量化图卷积网络和对比学习的多源数据表示学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1372-1378. |
| [14] | 胡文彬, 蔡天翔, 韩天乐, 仲兆满, 马常霞. 融合对比学习与情感分析的多模态反讽检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1432-1438. |
| [15] | 王文鹏, 秦寅畅, 师文轩. 工业缺陷检测无监督深度学习方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1658-1670. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||