


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (7): 2082-2090.DOI: 10.11772/j.issn.1001-9081.2022071116
Special Issue: 第39届CCF中国数据库学术会议(NDBC 2022)
• The 39th CCF National Database Conference (NDBC 2022) • Previous Articles Next Articles
Ziteng WANG1,2, Yaxin YU1,2( ), Zifang XIA1,2, Jiaqi QIAO1,2
), Zifang XIA1,2, Jiaqi QIAO1,2
Received:2022-07-12
Revised:2022-08-30
Accepted:2022-09-09
Online:2023-07-20
Published:2023-07-10
Contact:
Yaxin YU
About author:WANG Ziteng, born in 1998, M. S. candidate. His research interests include reinforcement learning, transfer learning.Supported by:
王子腾1,2, 于亚新1,2(), 夏子芳1,2, 乔佳琪1,2
通讯作者:
于亚新
作者简介:王子腾(1998—),男,辽宁大连人,硕士研究生,主要研究方向:强化学习、迁移学习;基金资助:CLC Number:
Ziteng WANG, Yaxin YU, Zifang XIA, Jiaqi QIAO. Sparse reward exploration mechanism fusing curiosity and policy distillation[J]. Journal of Computer Applications, 2023, 43(7): 2082-2090.
王子腾, 于亚新, 夏子芳, 乔佳琪. 融合好奇心和策略蒸馏的稀疏奖励探索机制[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2082-2090.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022071116
| 变量 | 描述 |
|---|---|
| RGNP预测网络输出值 | |
| RGNP目标网络输出值 | |
| 状态 | |
| 状态 | |
| RGNP-HCE构建的内在奖励 | |
| 环境反馈的外在奖励 | |
| IDF动作预测网络 | |
| PPO的策略网络 | |
| PPO的价值网络 | |
| 优势函数估计值 | |
| 重要性采样率 | |
| PPO策略网络的目标函数 | |
| PPO值函数的目标函数 | |
| “状态-动作”蒸馏的学生策略网络 | |
| 正则因子蒸馏的学生策略网络 | |
| 正则因子蒸馏的惩罚项 | |
| 正则因子蒸馏的目标函数 |
Tab. 1 Variable definitions of RGNP-HCE mechanism
| 变量 | 描述 |
|---|---|
| RGNP预测网络输出值 | |
| RGNP目标网络输出值 | |
| 状态 | |
| 状态 | |
| RGNP-HCE构建的内在奖励 | |
| 环境反馈的外在奖励 | |
| IDF动作预测网络 | |
| PPO的策略网络 | |
| PPO的价值网络 | |
| 优势函数估计值 | |
| 重要性采样率 | |
| PPO策略网络的目标函数 | |
| PPO值函数的目标函数 | |
| “状态-动作”蒸馏的学生策略网络 | |
| 正则因子蒸馏的学生策略网络 | |
| 正则因子蒸馏的惩罚项 | |
| 正则因子蒸馏的目标函数 |
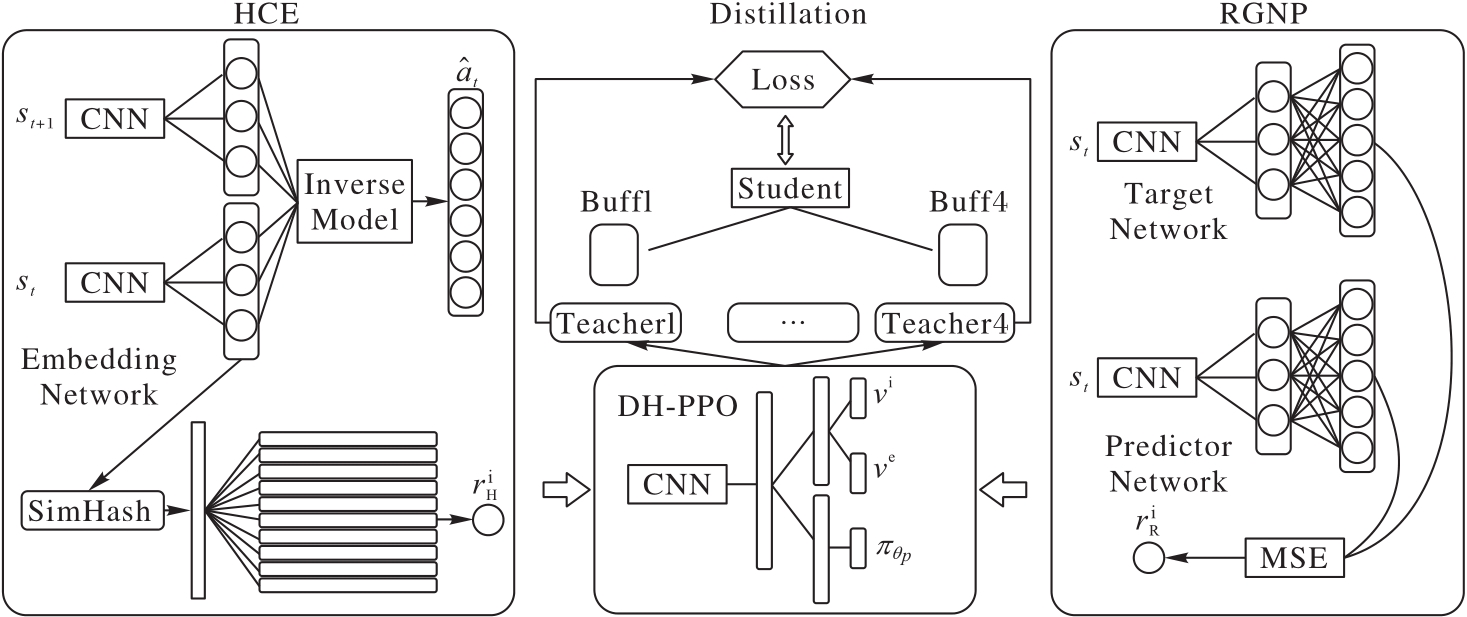
Fig. 1 Overall architecture of RGNP-HCE mechanism
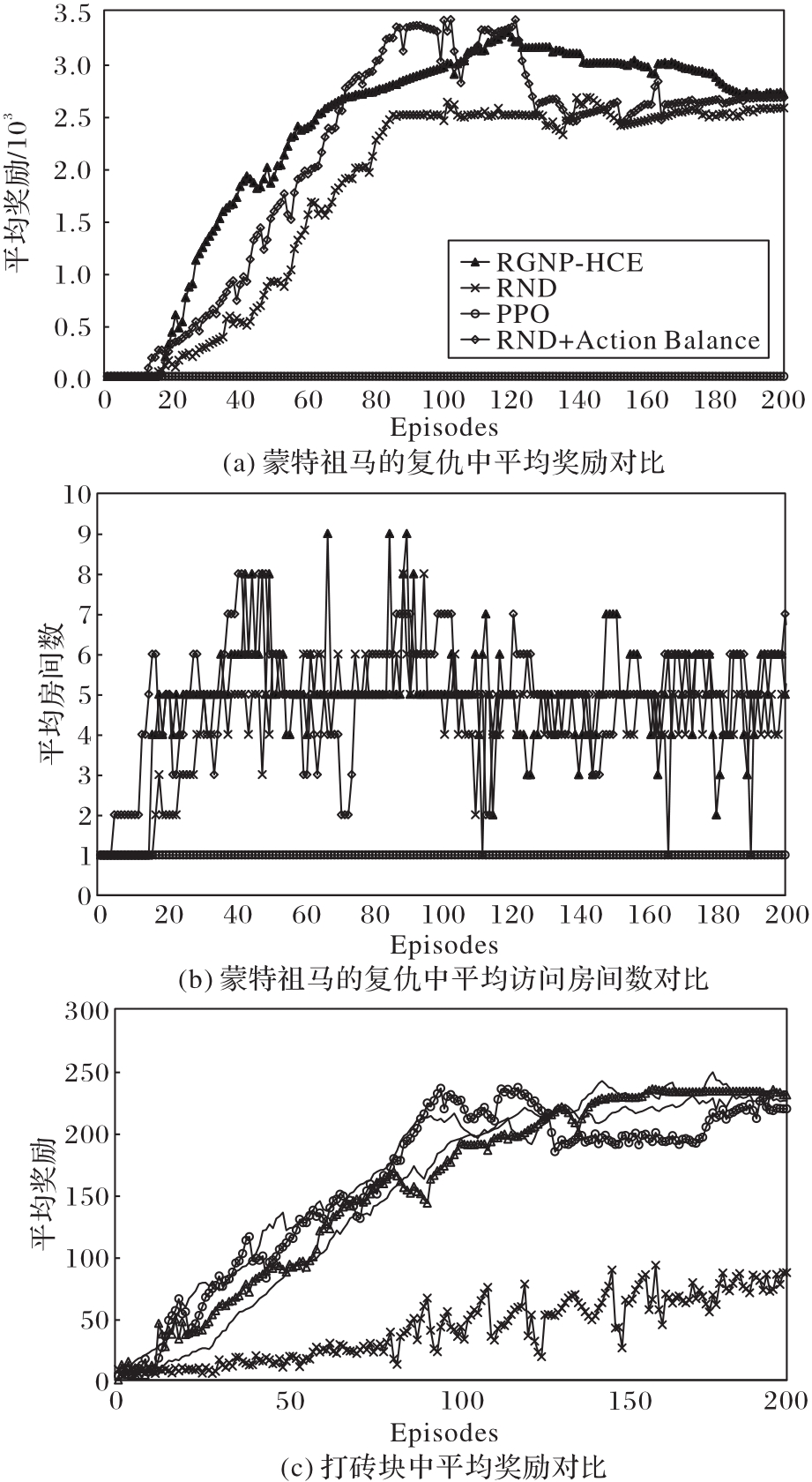
Fig. 2 Overall performance comparison
| 算法 | 蒙特祖马的复仇 | 打砖块 | |||
|---|---|---|---|---|---|
| 平均奖励 | 平均房间数 | 最大奖励 | 平均奖励 | 最大奖励 | |
| DQN | 0.00 | 1 | 0 | 86.75 | 95 |
| PPO | 0.00 | 1 | 0 | 233.44 | 238 |
| RND | 2 566.58 | 4 | 3 500 | 225.76 | 233 |
| RND+AB | 2 665.43 | 6 | 3 800 | 219.09 | 255 |
| RGNP-HCE | 2 699.72 | 6 | 3 300 | 230.39 | 240 |
| Distill | 2 800.68 | 7 | 3 200 | 254.29 | 266 |
| Distill-re | 2 782.14 | 6 | 2 900 | 251.35 | 261 |
Tab. 2 Performance comparison of algorithms
| 算法 | 蒙特祖马的复仇 | 打砖块 | |||
|---|---|---|---|---|---|
| 平均奖励 | 平均房间数 | 最大奖励 | 平均奖励 | 最大奖励 | |
| DQN | 0.00 | 1 | 0 | 86.75 | 95 |
| PPO | 0.00 | 1 | 0 | 233.44 | 238 |
| RND | 2 566.58 | 4 | 3 500 | 225.76 | 233 |
| RND+AB | 2 665.43 | 6 | 3 800 | 219.09 | 255 |
| RGNP-HCE | 2 699.72 | 6 | 3 300 | 230.39 | 240 |
| Distill | 2 800.68 | 7 | 3 200 | 254.29 | 266 |
| Distill-re | 2 782.14 | 6 | 2 900 | 251.35 | 261 |
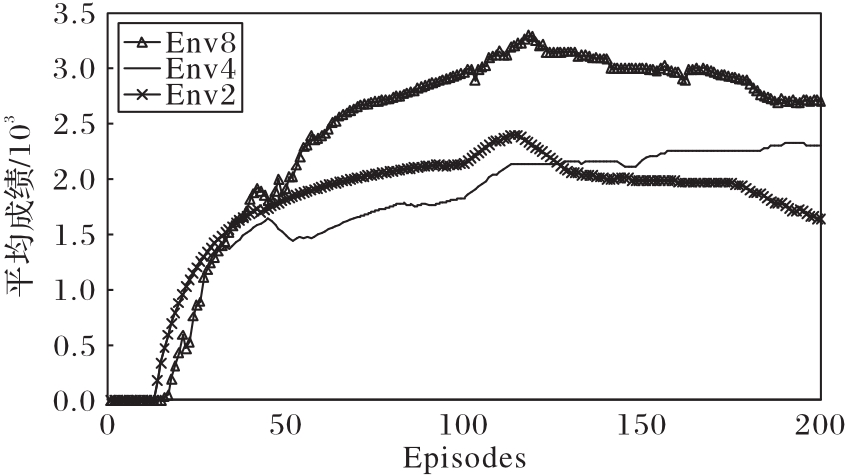
Fig. 3 Comparison of number of agents
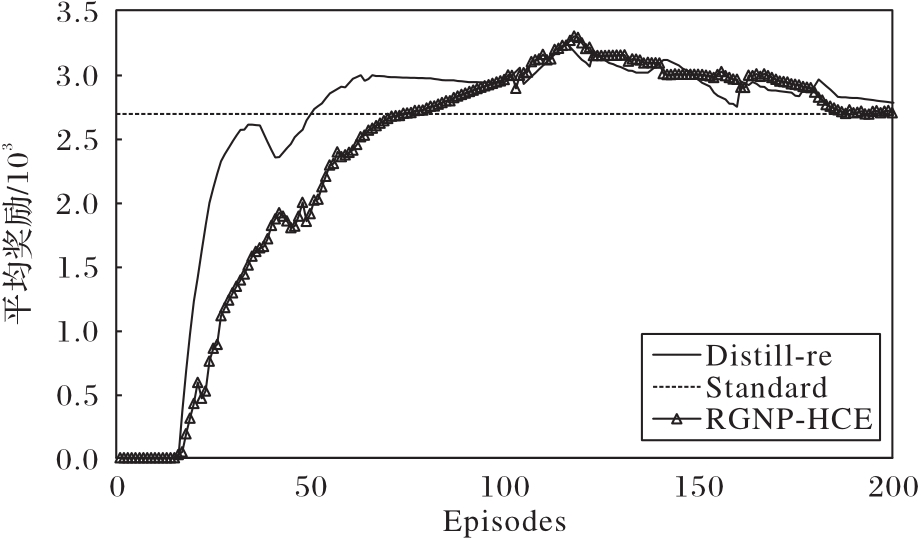
Fig. 4 Average reward comparison before and after regularization factor distillation

Fig. 5 “State- behavior pair” distillation compare regular factor distillation performance
| 算法 | 相对上栏提升/% | |
|---|---|---|
| 蒙特祖马的复仇 | 打砖块 | |
| PPO+RGNP | 1.00 | 1.00 |
| RGNP-HCE | 5.18 | 2.23 |
| 正则因子蒸馏 | 3.05 | 8.75 |
| 状态-动作对蒸馏 | 0.67 | 1.91 |
Tab. 3 Ablation experiment results
| 算法 | 相对上栏提升/% | |
|---|---|---|
| 蒙特祖马的复仇 | 打砖块 | |
| PPO+RGNP | 1.00 | 1.00 |
| RGNP-HCE | 5.18 | 2.23 |
| 正则因子蒸馏 | 3.05 | 8.75 |
| 状态-动作对蒸馏 | 0.67 | 1.91 |
| 1 | 杨瑞,严江鹏,李秀.强化学习稀疏奖励算法研究——理论与实验[J].智能系统学报, 2020, 15(5): 888-899. 10.11992/tis.202003031 |
| YANG R, YAN J P, LI X. Survey of sparse reward algorithms in reinforcement learning — theory and experiment[J]. CAAI Transactions on Intelligent Systems, 2020, 15(5): 888-899. 10.11992/tis.202003031 | |
| 2 | 李波,越凯强,甘志刚,等.基于MADDPG的多无人机协同任务决策[J].宇航学报, 2021, 42(6): 757-765. 10.3873/j.issn.1000-1328.2021.06.009 |
| LI B, YUE K Q, GAN Z G, et al. Multi-UAV cooperative autonomous navigation based on multi-agent deep deterministic policy gradient[J]. Journal of Astronautics, 2021, 42(6): 757-765. 10.3873/j.issn.1000-1328.2021.06.009 | |
| 3 | YE D H, CHEN G B, ZHANG W, et al. Towards playing full MOBA games with deep reinforcement learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 621-632. |
| 4 | LI Y X. Deep reinforcement learning: an overview[EB/OL]. (2018-11-26) [2021-10-11]. . 10.1109/tpami.2023.3285634/mm1 |
| 5 | BADIA A P, SPRECHMANN P, VITVITSKYI A, et al. Never give up: learning directed exploration strategies[EB/OL]. (2020-02-14) [2021-11-05]. . |
| 6 | PATHAK D, AGRAWAL P, EFROS A A, et al. Curiosity-driven exploration by self-supervised prediction [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 2778-2787. 10.1109/cvprw.2017.70 |
| 7 | OUDEYER P Y, KAPLAN F. How can we define intrinsic motivation?[C/OL]// Proceedings of the 8th International Conference on Epigenetic Robotics: Modeling Cognitive Development in Robotic Systems [2021-11-05]. . 10.1016/j.cogsys.2003.11.001 |
| 8 | STREHL A L, LITTMAN M L. An analysis of model-based Interval Estimation for Markov Decision Processes[J]. Journal of Computer and System Sciences, 2008, 74(8): 1309-1331. 10.1016/j.jcss.2007.08.009 |
| 9 | LAI T L, ROBBINS H. Asymptotically efficient adaptive allocation rules[J]. Advances in Applied Mathematics, 1985, 6(1): 4-22. 10.1016/0196-8858(85)90002-8 |
| 10 | OSTROVSKI G, BELLEMARE M G, A van den OORD, et al. Count-based exploration with neural density models [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 2721-2730. |
| 11 | BURDA Y, EDWARDS H, STORKEY A, et al. Exploration by random network distillation[EB/OL]. (2018-10-30) [2021-12-18]. . |
| 12 | TANG H R, HOUTHOOFT R, FOOTE D, et al. #Exploration: a study of count-based exploration for deep reinforcement learning [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 2750-2759. 10.1109/icccbda.2017.7951951 |
| 13 | PARISOTTO E, BA J, SALAKHUTDINOV R. Actor-mimic: deep multitask and transfer reinforcement learning[EB/OL]. (2016-02-22) [2020-11-09]. . |
| 14 | RUSU A A, COLMENAREJO S G, GÜLÇEHRE Ç, et al. Policy distillation[EB/OL]. (2016-01-07) [2020-09-07]. . |
| 15 | 姜玉斌,刘全,胡智慧.带最大熵修正的行动者评论家算法[J].计算机学报, 2020, 43(10): 1897-1908. 10.11897/SP.J.1016.2020.01897 |
| JIANG Y B, LIU Q, HU Z H. Actor-critic algorithm with maximum-entropy correction[J]. Chinese Journal of Computers, 2020, 43(10): 1897-1908. 10.11897/SP.J.1016.2020.01897 | |
| 16 | SUTTON R S, BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 1998: 75-76. |
| 17 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. 10.1038/nature14236 |
| 18 | WILLIAMS R J. Simple statistical gradient-following algorithms for connectionist reinforcement learning[J]. Machine Learning, 1992, 8(3/4): 229-256. 10.1007/bf00992696 |
| 19 | KONDA V R, TSITSIKLIS J N. Actor-critic algorithms [C]// Proceedings of the 12th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2000: 1008-1014. |
| 20 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning [C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1928-1937. |
| 21 | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1889-1897. |
| 22 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28) [2021-09-29]. . |
| 23 | THOMPSON W R. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples[J]. Biometrika, 1933, 25(3/4): 285-294. 10.1093/biomet/25.3-4.285 |
| 24 | HAARNOJA T, TANG H R, ABBEEL P, et al. Reinforcement learning with deep energy-based policies [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1352-1361. 10.1007/978-1-4899-7687-1_142 |
| 25 | OSBAND I, BLUNDELL C, PRITZEL A, et al. Deep exploration via bootstrapped DQN [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 4033-4041 |
| 26 | BELLEMARE M G, SRINIVASAN S, OSTROVSKI G, et al. Unifying count-based exploration and intrinsic motivation [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 1479-1487. |
| 27 | STADIE B C, LEVINE S, ABBEEL P. Incentivizing exploration in reinforcement learning with deep predictive models[EB/OL]. (2015-11-19) [2020-12-18]. . |
| 28 | BURDA Y, EDWARDS H, PATHAK D, et al. Large-scale study of curiosity-driven learning[EB/OL]. (2018-08-13) [2022-01-08]. . |
| 29 | SONG Y, CHEN Y F, HU Y J, et al. Exploring unknown states with action balance [C]// Proceedings of the 2020 IEEE Conference on Games. Piscataway: IEEE, 2020: 184-191. 10.1109/cog47356.2020.9231562 |
| 30 | HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. (2015-03-09) [2020-12-19]. . |
| 31 | CZARNECKI W M, PASCANU R, OSINDERO S, et al. Distilling policy distillation [C]// Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2019: 1331-1340. 10.24963/ijcai.2020/435 |
| [1] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [2] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [3] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [4] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [5] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [6] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [7] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [8] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [9] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [10] | Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN [J]. Journal of Computer Applications, 2023, 43(8): 2636-2643. |
| [11] | Xiaolin LI, Yusang JIANG. Task offloading algorithm for UAV-assisted mobile edge computing [J]. Journal of Computer Applications, 2023, 43(6): 1893-1899. |
| [12] | Heping FANG, Shuguang LIU, Yongyi RAN, Kunhua ZHONG. Integrated scheduling optimization of multiple data centers based on deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(6): 1884-1892. |
| [13] | Xiaohui HUANG, Kaiming YANG, Jiahao LING. Order dispatching by multi-agent reinforcement learning based on shared attention [J]. Journal of Computer Applications, 2023, 43(5): 1620-1624. |
| [14] | Tengfei CAO, Yanliang LIU, Xiaoying WANG. Edge computing and service offloading algorithm based on improved deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(5): 1543-1550. |
| [15] | Zhengkai DING, Qiming FU, Jianping CHEN, You LU, Hongjie WU, Nengwei FANG, Bin XING. Ultra-short-term photovoltaic power prediction by deep reinforcement learning based on attention mechanism [J]. Journal of Computer Applications, 2023, 43(5): 1647-1654. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||