


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (8): 2636-2643.DOI: 10.11772/j.issn.1001-9081.2022071069
Special Issue: 前沿与综合应用
• Frontier and comprehensive applications • Previous Articles Next Articles
Yu WANG( ), Tianjun REN, Zilin FAN
), Tianjun REN, Zilin FAN
Received:2022-07-23
Revised:2022-11-03
Accepted:2022-11-07
Online:2023-01-15
Published:2023-08-10
Contact:
Yu WANG
About author:REN Tianjun, born in 1995, M. S. candidate. His research interests include intelligent decision-making.Supported by:
王昱(), 任田君, 范子琳
通讯作者:
王昱
作者简介:任田君(1995—),男,山西运城人,硕士研究生,主要研究方向:智能决策基金资助:CLC Number:
Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN[J]. Journal of Computer Applications, 2023, 43(8): 2636-2643.
王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2636-2643.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022071069
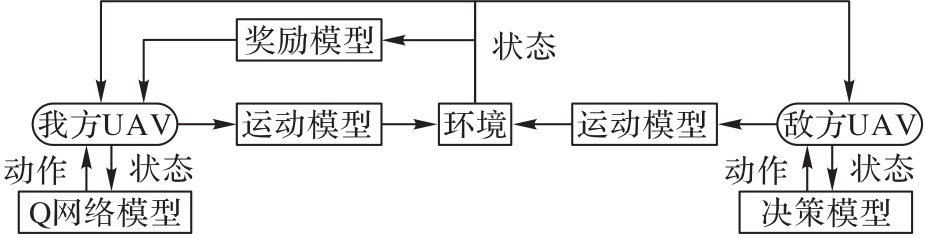
Fig.1 UAV combat decision-making system

Fig.2 UAV motion parameters
| 动作序号 | 动作名称 | 动作序号 | 动作名称 |
|---|---|---|---|
| 1 | 匀速直线运动 | 5 | 最大过载右转 |
| 2 | 最大加速运动 | 6 | 最大过载爬升 |
| 3 | 最大减速运动 | 7 | 最大过载俯冲 |
| 4 | 最大过载左转 |
Tab. 1 Maneuver motion classification
| 动作序号 | 动作名称 | 动作序号 | 动作名称 |
|---|---|---|---|
| 1 | 匀速直线运动 | 5 | 最大过载右转 |
| 2 | 最大加速运动 | 6 | 最大过载爬升 |
| 3 | 最大减速运动 | 7 | 最大过载俯冲 |
| 4 | 最大过载左转 |
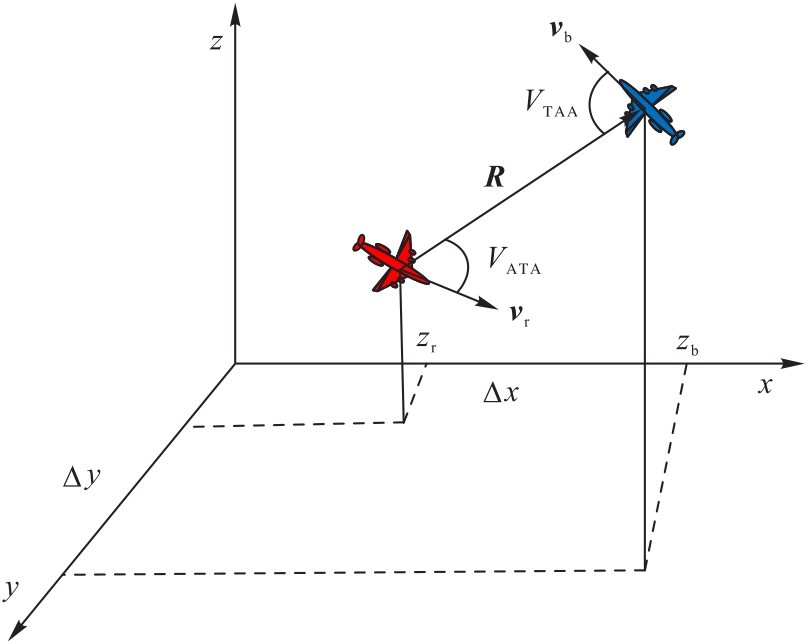
Fig.3 Relative state relationship of fighters of both sides
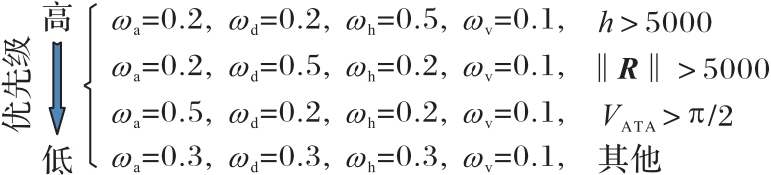
Fig.4 Weight assignment
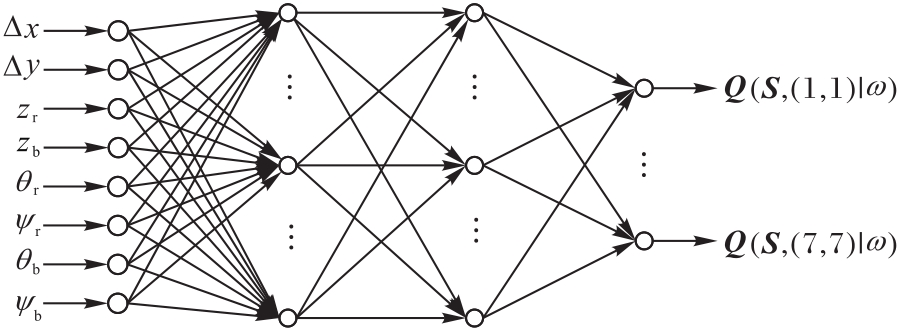
Fig.5 Q-network model

Fig. 6 Schematic diagram of guidance strategy
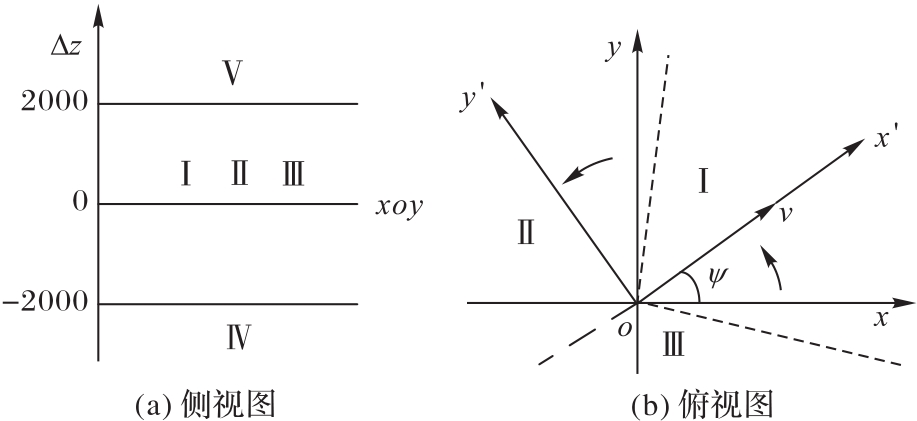
Fig. 7 Regional division of guidance strategy
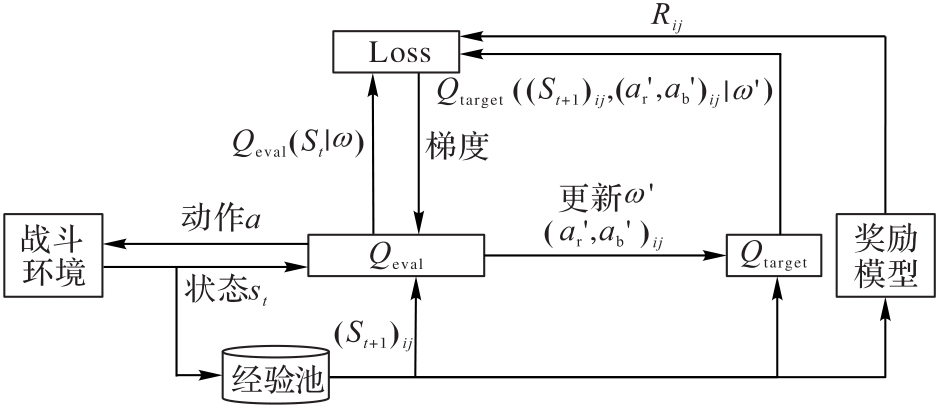
Fig. 8 DDQN decision-making algorithm
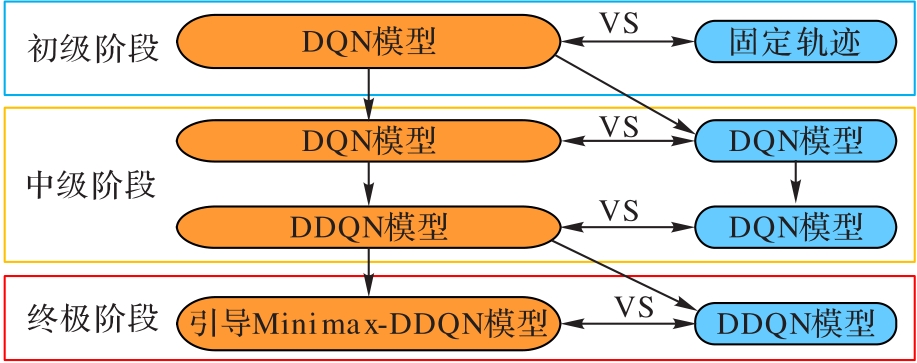
Fig. 9 Advanced three-stage network training method
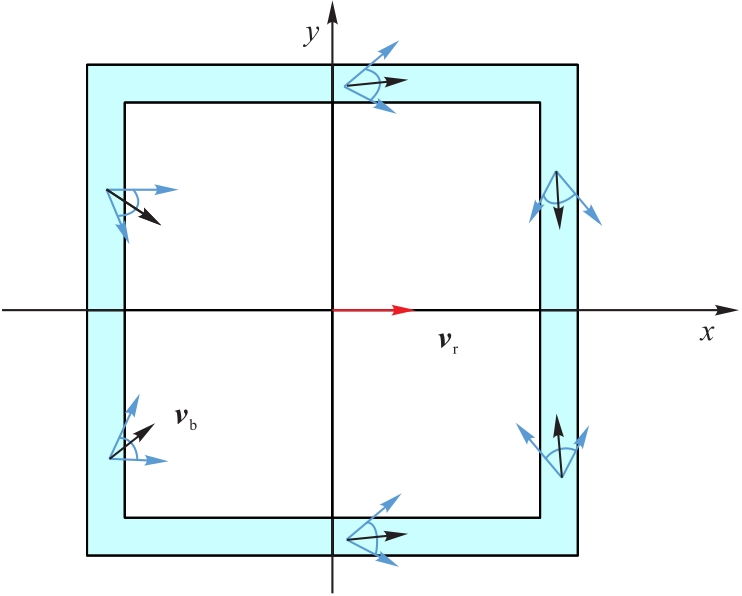
Fig.10 Schematic diagram of initial states of both sides (vertical view)
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| Rmin/m | 5 000 | Rmax/m | 10 000 |
| hmin /m | -4 000 | hmax /m | 4 000 |
| hop /m | 1 000 | vmin /(m·s-1) | 150 |
| g /(m·s-2) | 9.8 | vmax /(m·s-1) | 450 |
| ηxmax | 1.5 | ηx-max | -1 |
| ηzmax | 9 |
Tab. 2 Experimental parameters
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| Rmin/m | 5 000 | Rmax/m | 10 000 |
| hmin /m | -4 000 | hmax /m | 4 000 |
| hop /m | 1 000 | vmin /(m·s-1) | 150 |
| g /(m·s-2) | 9.8 | vmax /(m·s-1) | 450 |
| ηxmax | 1.5 | ηx-max | -1 |
| ηzmax | 9 |
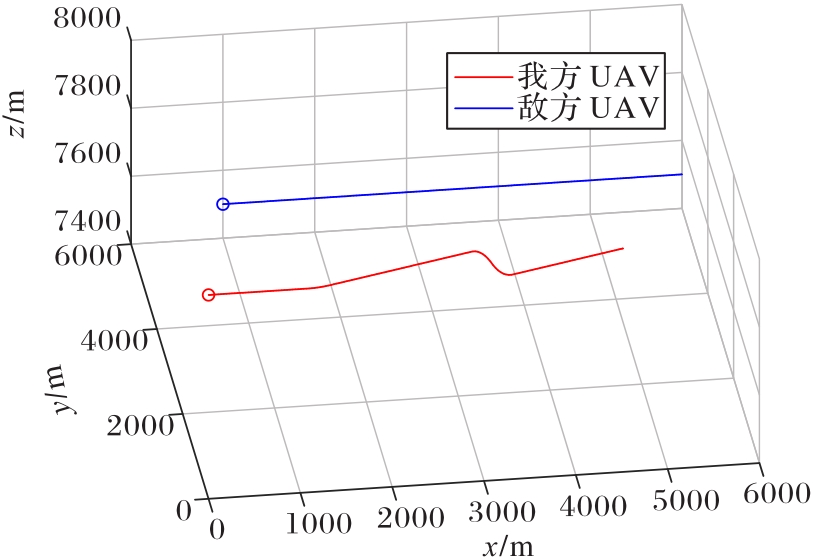
Fig.11 Confrontation trajectories of both sides with fixed initial states
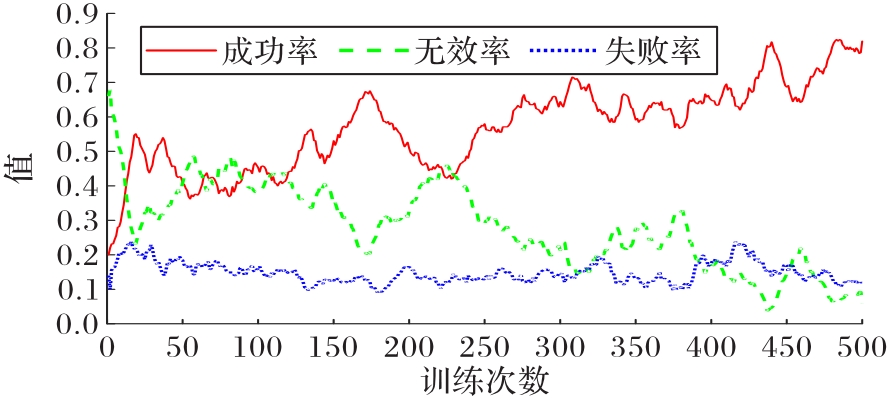
Fig.12 Winning rate changing curve of training in the first stage

Fig.13 Winning rate changing curve of DQN self-play in the second stage
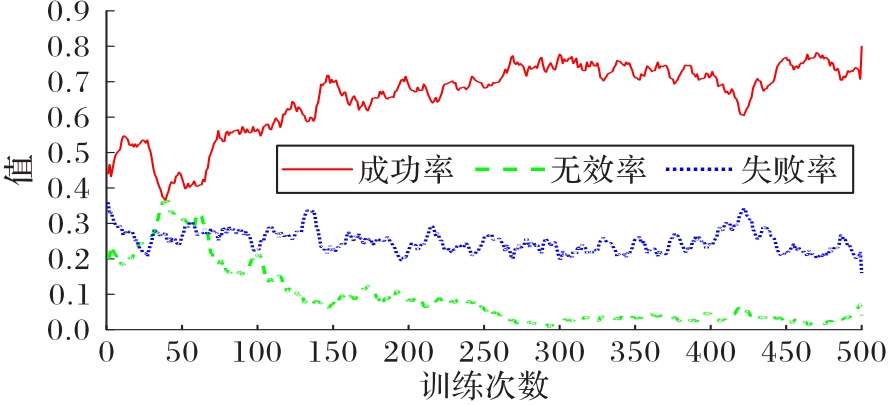
Fig.14 Winning rate changing curve of DDQN vs DQN in the second stage
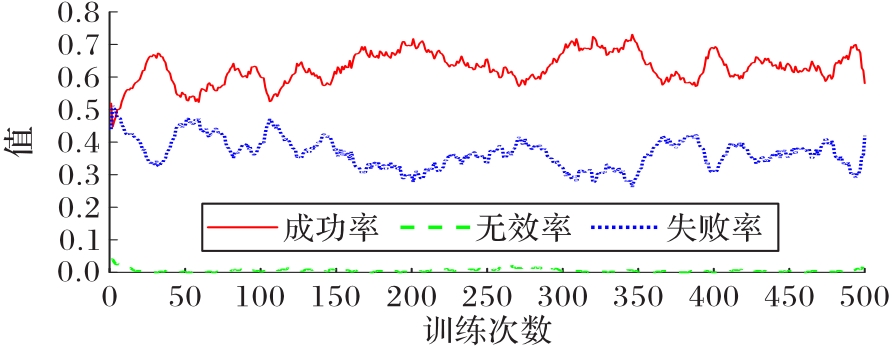
Fig.15 Winning rate changing curve in the third stage
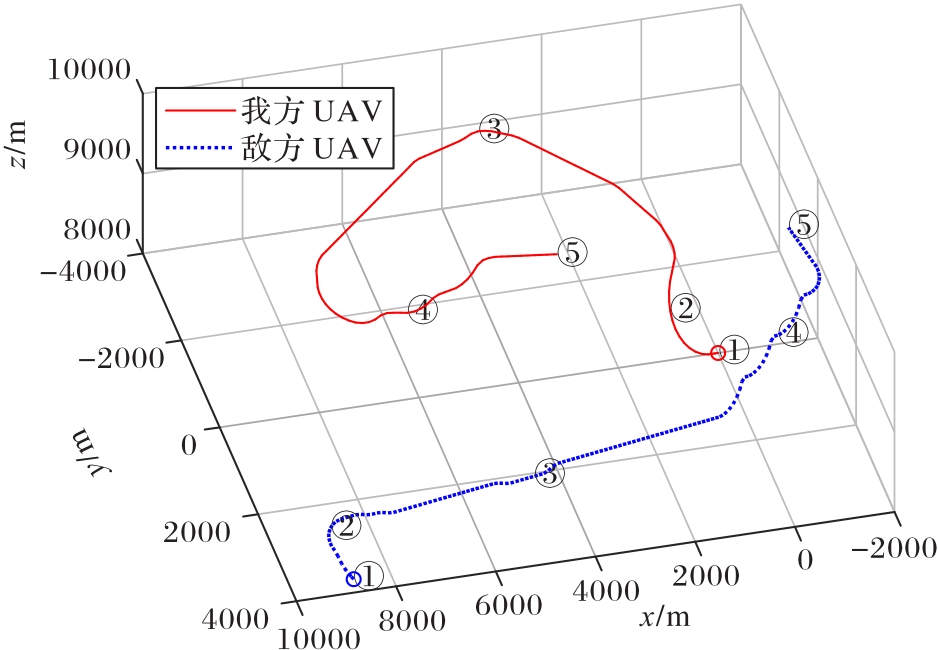
Fig.16 Confrontation trajectories of both sides in superior situation
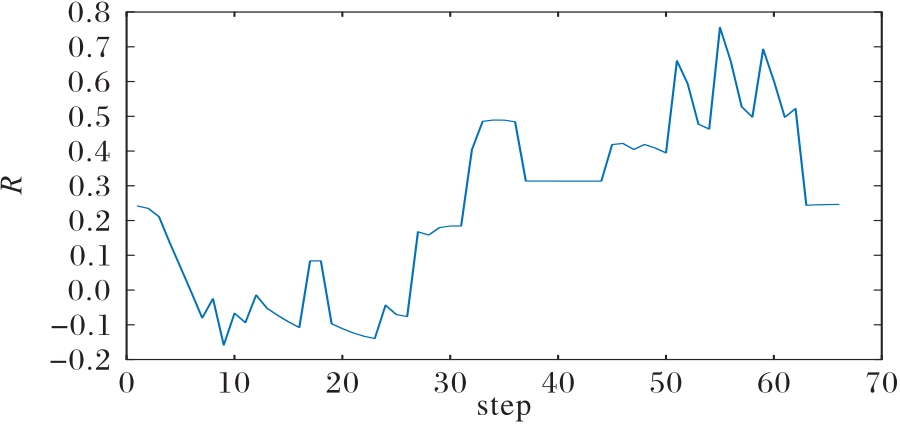
Fig.17 Advantage change curve in superior situation

Fig.18 Confrontation trajectories of both sides in equilibrium situation
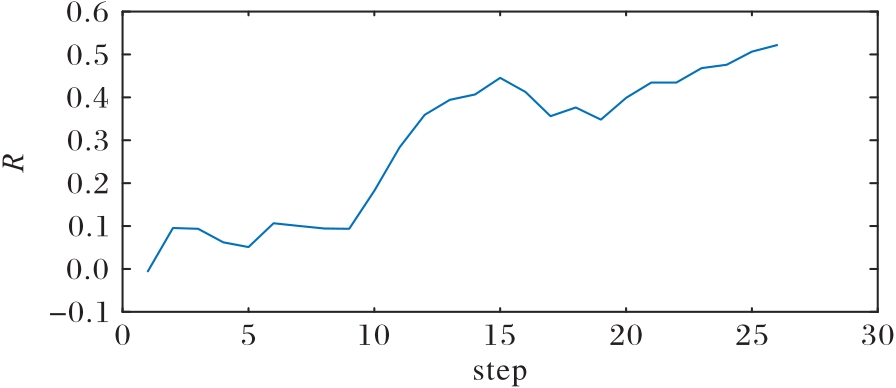
Fig.19 Advantage change curve in equilibrium situation

Fig.20 Confrontation trajectories of both sides in inferior situation
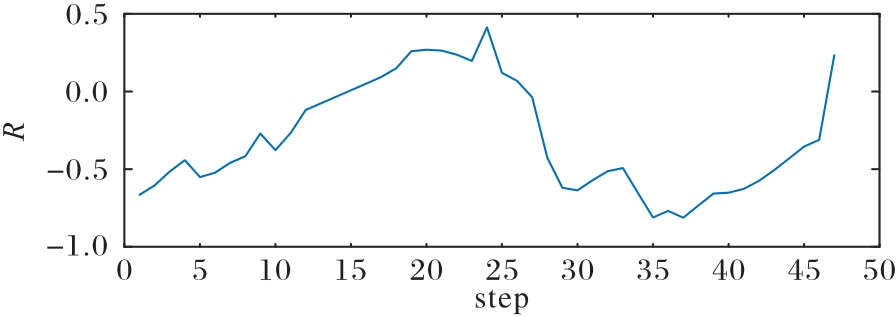
Fig.21 Advantage change curve in inferior situation

Fig.22 Comparison of winning curves of different algorithms
| 1 | 周新民,吴佳晖,贾圣德,等. 无人机空战决策技术研究进展[J]. 国防科技, 2021, 42(3):33-41. |
| ZHOU X M, WU J H, JIA S D, et al. Progress in research on combat decision-making technology in UAVs[J]. National Defense Technology, 2021, 42(3): 33-41. | |
| 2 | 张宏鹏,黄长强,轩永波,等. 基于深度神经网络的无人作战飞机自主空战机动决策[J]. 兵工学报, 2020, 41(8):1613-1622. 10.3969/j.issn.1000-1093.2020.08.016 |
| ZHANG H P, HUANG C Q, XUAN Y B, et al. Maneuver decision of autonomous air combat of unmanned combat aerial vehicle based on deep neural network[J]. Acta Armamentarii, 2020, 41(8): 1613-1622. 10.3969/j.issn.1000-1093.2020.08.016 | |
| 3 | ZHANG S, ZHOU Y Q, LI Z M, et al. Grey wolf optimizer for unmanned combat aerial vehicle path planning[J]. Advances in Engineering Software, 2016, 99: 121-136. 10.1016/j.advengsoft.2016.05.015 |
| 4 | ERNEST N, CARROLL D, SCHUMACHER C, et al. Genetic fuzzy based artificial intelligence for unmanned combat aerial vehicle control in simulated air combat missions[J]. Journal of Defense Management, 2016, 6(1): No.1000144. |
| 5 | HUANG C Q, DONG K S, HUANG H Q, et al. Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J]. Journal of Systems Engineering and Electronics, 2018, 29(1): 86-97. 10.21629/jsee.2018.01.09 |
| 6 | 杨萍,毕义明,刘卫东. 基于模糊马尔科夫理论的机动智能体决策模型[J]. 系统工程与电子技术, 2008, 30(3):511-514. 10.3321/j.issn:1001-506X.2008.03.030 |
| YANG P, BI Y M, LIU W D. Decision-making model of tactics maneuver agent based on fuzzy Markov decision theory[J]. Systems Engineering and Electronic, 2008, 30(3): 511-514. 10.3321/j.issn:1001-506X.2008.03.030 | |
| 7 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. (2013-12-19) [2022-04-15].. 10.1038/nature14236 |
| 8 | SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 2016, 529(7587): 484-489. 10.1038/nature16961 |
| 9 | 唐振韬,邵坤,赵冬斌,等. 深度强化学习进展:从AlphaGo到AlphaGo Zero[J]. 控制理论与应用, 2017, 34(12):1529-1546. |
| TANG Z T, SHAO K, ZHAO D B, et al. Recent progress of deep reinforcement learning: from AlphaGo to AlphaGo Zero[J]. Control Theory and Applications, 2017, 34(12): 1529-1546. | |
| 10 | 余伶俐,邵玄雅,龙子威,等. 智能车辆深度强化学习的模型迁移轨迹规划方法[J]. 控制理论与应用, 2019, 36(9):1409-1422. 10.7641/CTA.2018.80341 |
| YU L L, SHAO X Y, LONG Z W, et al. Intelligent land vehicle model transfer trajectory planning method of deep reinforcement learning[J]. Control Theory and Applications, 2019, 36(9): 1409-1422. 10.7641/CTA.2018.80341 | |
| 11 | DUAN J L, LI S E, GUAN Y, et al. Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data[J]. IET Intelligent Transport Systems, 2020, 14(5): 297-305. 10.1049/iet-its.2019.0317 |
| 12 | 张强,杨任农,俞利新,等. 基于Q-network强化学习的超视距空战机动决策[J]. 空军工程大学学报(自然科学版), 2018, 19(6):8-14. |
| ZHANG Q, YANG R N, YU L X, et al. BVR air combat maneuver decision by using Q-network reinforcement learning[J]. Journal of Air Force Engineering University (Natural Science Edition), 2018, 19(6): 8-14. | |
| 13 | 丁林静,杨啟明. 基于强化学习的无人机空战机动决策[J]. 航空电子技术, 2018, 49(2):29-35. 10.3969/j.issn.1006-141X.2018.02.06 |
| DING L J, YANG Q M. Research on air combat maneuver decision of UAVs based on reinforcement learning[J]. Avionics Technology, 2018, 49(2): 29-35. 10.3969/j.issn.1006-141X.2018.02.06 | |
| 14 | POPE A P, IDE J S, MIĆOVIĆ D, et al. Hierarchical reinforcement learning for air-to-air combat[C]// Proceedings of the 2021 International Conference on Unmanned Aircraft System. Piscataway: IEEE, 2021: 275-284. 10.1109/icuas51884.2021.9476700 |
| 15 | 马文,李辉,王壮,等. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2):443-451. 10.12305/j.issn.1001-506X.2021.02.19 |
| MA W, LI H, WANG Z, et al. Close air combat maneuver decision based on deep stochastic game[J]. Systems Engineering and Electronic, 2021, 43(2): 443-451. 10.12305/j.issn.1001-506X.2021.02.19 | |
| 16 | YANG Q M, ZHANG J D, SHI G Q, et al. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning[J]. IEEE Access, 2020, 8: 363-378. 10.1109/access.2019.2961426 |
| 17 | van HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 2094-2100. 10.1609/aaai.v30i1.10295 |
| 18 | 刘建伟,高峰,罗雄麟. 基于值函数和策略梯度的深度强化学习综述[J]. 计算机学报, 2019, 42(6):1406-1438. 10.11897/SP.J.1016.2019.01406 |
| LIU J W, GAO F, LUO X L. Survey of deep reinforcement learning based on value function and policy gradient[J]. Chinese Journal of Computers, 2019, 42(6): 1406-1438. 10.11897/SP.J.1016.2019.01406 | |
| 19 | GUO T, JIANG N, LI B Y, et al. UAV navigation in high dynamic environments: a deep reinforcement learning approach[J]. Chinese Journal of Aeronautics, 2021, 34(2): 479-489. 10.1016/j.cja.2020.05.011 |
| 20 | LI Y F, SHI J P, JIANG W, et al. Autonomous maneuver decision-making for a UCAV in short range aerial combat based on an MS-DDQN algorithm[J]. Defence Technology, 2022, 18(9): 1697-1714. 10.1016/j.dt.2021.09.014 |
| 21 | 李永丰,史静平,章卫国,等. 深度强化学习的无人作战飞机空战机动决策[J]. 哈尔滨工业大学学报, 2021, 53(12):33-41. 10.11918/202005108 |
| LI Y F, SHI J P, ZHANG W G, et al. Maneuver decision of UCAV in air combat based on deep reinforcement learning[J]. Journal of Harbin Institute of Technology, 2021, 53(12): 33-41. 10.11918/202005108 |
| [1] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [2] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [3] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [4] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [5] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [6] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [7] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [8] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [9] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [10] | Ziteng WANG, Yaxin YU, Zifang XIA, Jiaqi QIAO. Sparse reward exploration mechanism fusing curiosity and policy distillation [J]. Journal of Computer Applications, 2023, 43(7): 2082-2090. |
| [11] | Heping FANG, Shuguang LIU, Yongyi RAN, Kunhua ZHONG. Integrated scheduling optimization of multiple data centers based on deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(6): 1884-1892. |
| [12] | Xiaolin LI, Yusang JIANG. Task offloading algorithm for UAV-assisted mobile edge computing [J]. Journal of Computer Applications, 2023, 43(6): 1893-1899. |
| [13] | Xiaohui HUANG, Kaiming YANG, Jiahao LING. Order dispatching by multi-agent reinforcement learning based on shared attention [J]. Journal of Computer Applications, 2023, 43(5): 1620-1624. |
| [14] | Tengfei CAO, Yanliang LIU, Xiaoying WANG. Edge computing and service offloading algorithm based on improved deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(5): 1543-1550. |
| [15] | Zhengkai DING, Qiming FU, Jianping CHEN, You LU, Hongjie WU, Nengwei FANG, Bin XING. Ultra-short-term photovoltaic power prediction by deep reinforcement learning based on attention mechanism [J]. Journal of Computer Applications, 2023, 43(5): 1647-1654. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||