


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (1): 113-122.DOI: 10.11772/j.issn.1001-9081.2023060853
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Junhong ZHU1, Junyu LAI1,2( ), Lianqiang GAN1, Zhiyong CHEN1, Huashuo LIU1, Guoyao XU1
), Lianqiang GAN1, Zhiyong CHEN1, Huashuo LIU1, Guoyao XU1
Received:2023-06-30
Revised:2023-10-10
Accepted:2023-10-13
Online:2024-01-24
Published:2024-01-10
Contact:
Junyu LAI
About author:ZHU Junhong, born in 1998, M. S. candidate. His research interests include computer vision, video prediction.Supported by:
朱俊宏1, 赖俊宇1,2(), 甘炼强1, 陈智勇1, 刘华烁1, 徐国尧1
通讯作者:
赖俊宇
作者简介:朱俊宏(1998—),男,四川德阳人,硕士研究生,主要研究方向:计算机视觉、视频预测;基金资助:CLC Number:
Junhong ZHU, Junyu LAI, Lianqiang GAN, Zhiyong CHEN, Huashuo LIU, Guoyao XU. Video prediction model combining involution and convolution operators[J]. Journal of Computer Applications, 2024, 44(1): 113-122.
朱俊宏, 赖俊宇, 甘炼强, 陈智勇, 刘华烁, 徐国尧. 结合内卷与卷积算子的视频预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 113-122.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023060853
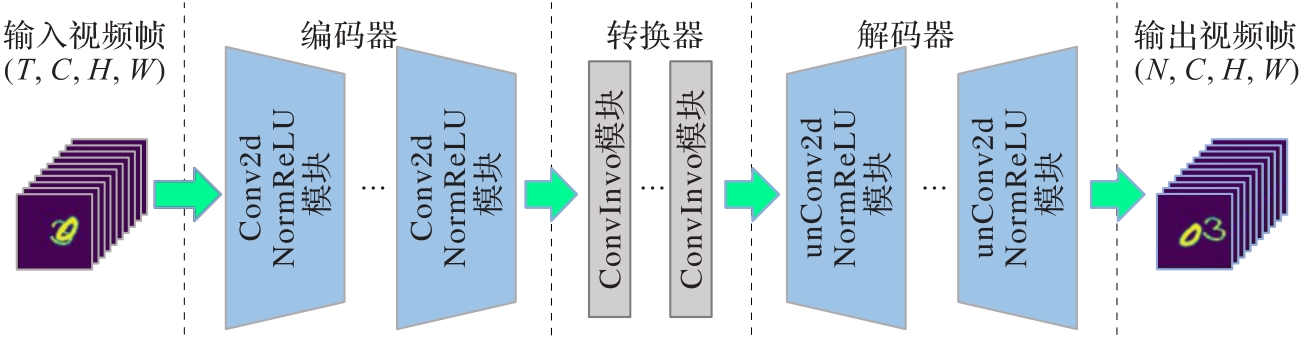
Fig. 1 Architecture of CICO-VP model
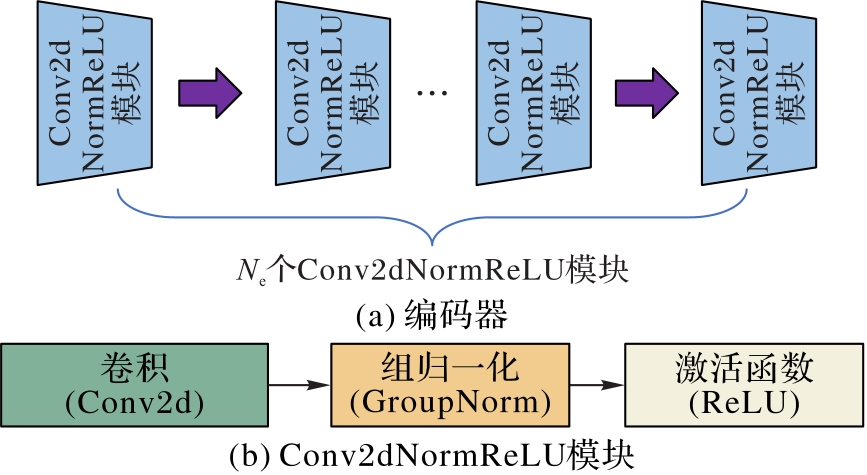
Fig. 2 Structure of encoder
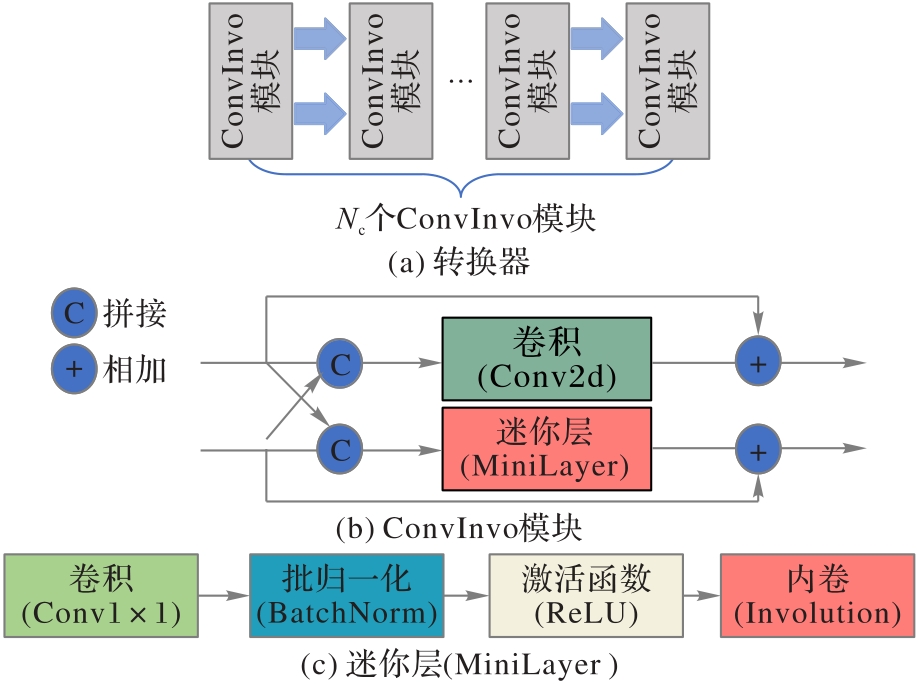
Fig. 3 Structure of convertor
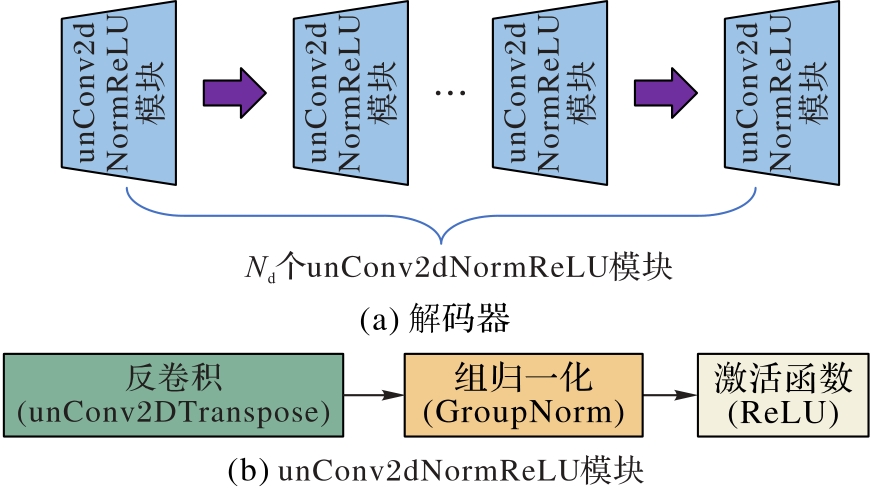
Fig. 4 Structure of decoder
| 数据集 | 训练样本数 | 测试样本数 | 图像规格 | 输入帧数 | 输出帧数 |
|---|---|---|---|---|---|
| 移动手写 | 10 000 | 10 000 | (1, 64, 64) | 10 | 10 |
| 北京交通 | 19 627 | 1 334 | (2, 32, 32) | 4 | 4 |
| 人体行为 | 5 200 | 3 167 | (1, 128, 128) | 10 | 20 |
Tab. 1 Experiment parameter settings for different datasets
| 数据集 | 训练样本数 | 测试样本数 | 图像规格 | 输入帧数 | 输出帧数 |
|---|---|---|---|---|---|
| 移动手写 | 10 000 | 10 000 | (1, 64, 64) | 10 | 10 |
| 北京交通 | 19 627 | 1 334 | (2, 32, 32) | 4 | 4 |
| 人体行为 | 5 200 | 3 167 | (1, 128, 128) | 10 | 20 |
| 数据集 | Ne和Nd | He和Hd | 卷积核大小 |
|---|---|---|---|
| 移动手写 | 4 | 64 | 3×3和5×5 |
| 北京交通 | 3 | 64 | 3×3和5×5 |
| 人体行为 | 3 | 32 | 3×3和5×5 |
Tab. 2 Hyper-parameter values of encoder and decoder for different datasets
| 数据集 | Ne和Nd | He和Hd | 卷积核大小 |
|---|---|---|---|
| 移动手写 | 4 | 64 | 3×3和5×5 |
| 北京交通 | 3 | 64 | 3×3和5×5 |
| 人体行为 | 3 | 32 | 3×3和5×5 |
| 数据集 | ConvInvo模块个数Nc | 转换器隐藏层数量Hc | 卷积算子核大小 | 内卷算子核大小 |
|---|---|---|---|---|
| 移动手写 | 4 | 512 | 3×3 | 11×11 |
| 北京交通 | 3 | 128 | 3×3 | 11×11 |
| 人体行为 | 4 | 256 | 3×3 | 11×11 |
Tab. 3 Hyper-parameter values of convertor for different datasets
| 数据集 | ConvInvo模块个数Nc | 转换器隐藏层数量Hc | 卷积算子核大小 | 内卷算子核大小 |
|---|---|---|---|---|
| 移动手写 | 4 | 512 | 3×3 | 11×11 |
| 北京交通 | 3 | 128 | 3×3 | 11×11 |
| 人体行为 | 4 | 256 | 3×3 | 11×11 |
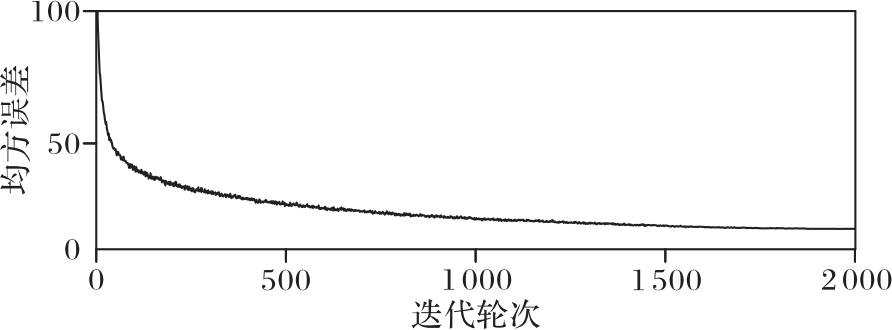
Fig. 5 Training process of CICO-VP on Moving MNIST dataset
| 模型 | MSE↓ | MAE↓ | SSIM↑ |
|---|---|---|---|
| ConvLSTM[ | 103.3 | 182.9 | 0.707 |
| MIM[ | 44.2 | 101.1 | 0.910 |
| PredRNN[ | 56.8 | 126.1 | 0.867 |
| CausalLSTM[ | 46.5 | 106.8 | 0.898 |
| E3D-LSTM[ | 41.3 | 86.4 | 0.910 |
| SimVP[ | 23.8 | 68.9 | 0.948 |
| PhyDNet[ | 24.4 | 70.3 | 0.947 |
| CICO-VP | 17.8 | 56.9 | 0.961 |
Tab. 4 Performance comparison of different models on Moving MNIST dataset
| 模型 | MSE↓ | MAE↓ | SSIM↑ |
|---|---|---|---|
| ConvLSTM[ | 103.3 | 182.9 | 0.707 |
| MIM[ | 44.2 | 101.1 | 0.910 |
| PredRNN[ | 56.8 | 126.1 | 0.867 |
| CausalLSTM[ | 46.5 | 106.8 | 0.898 |
| E3D-LSTM[ | 41.3 | 86.4 | 0.910 |
| SimVP[ | 23.8 | 68.9 | 0.948 |
| PhyDNet[ | 24.4 | 70.3 | 0.947 |
| CICO-VP | 17.8 | 56.9 | 0.961 |

Fig. 6 Experimental results on Moving MNIST dataset
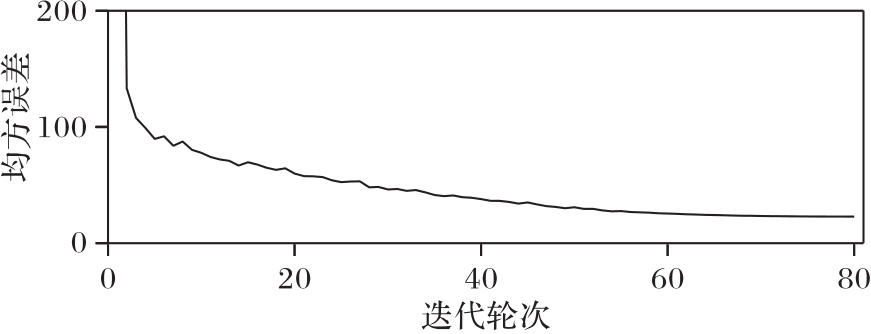
Fig. 7 Training process of CICO-VP on Traffic Beijing dataset
| 模型 | MSE×100↓ | MAE↓ | SSIM↑ |
|---|---|---|---|
| ConvLSTM[ | 48.5 | 17.7 | 0.978 |
| MIM[ | 42.9 | 16.6 | 0.971 |
| PredRNN[ | 46.4 | 17.1 | 0.971 |
| CausalLSTM[ | 44.8 | 16.9 | 0.977 |
| E3D-LSTM[ | 43.2 | 16.9 | 0.979 |
| SimVP[ | 41.4 | 16.2 | 0.982 |
| PhyDNet[ | 41.9 | 16.2 | 0.982 |
| CICO-VP | 40.9 | 16.2 | 0.982 |
Tab. 5 Performance comparison of different models on Traffic Beijing dataset
| 模型 | MSE×100↓ | MAE↓ | SSIM↑ |
|---|---|---|---|
| ConvLSTM[ | 48.5 | 17.7 | 0.978 |
| MIM[ | 42.9 | 16.6 | 0.971 |
| PredRNN[ | 46.4 | 17.1 | 0.971 |
| CausalLSTM[ | 44.8 | 16.9 | 0.977 |
| E3D-LSTM[ | 43.2 | 16.9 | 0.979 |
| SimVP[ | 41.4 | 16.2 | 0.982 |
| PhyDNet[ | 41.9 | 16.2 | 0.982 |
| CICO-VP | 40.9 | 16.2 | 0.982 |
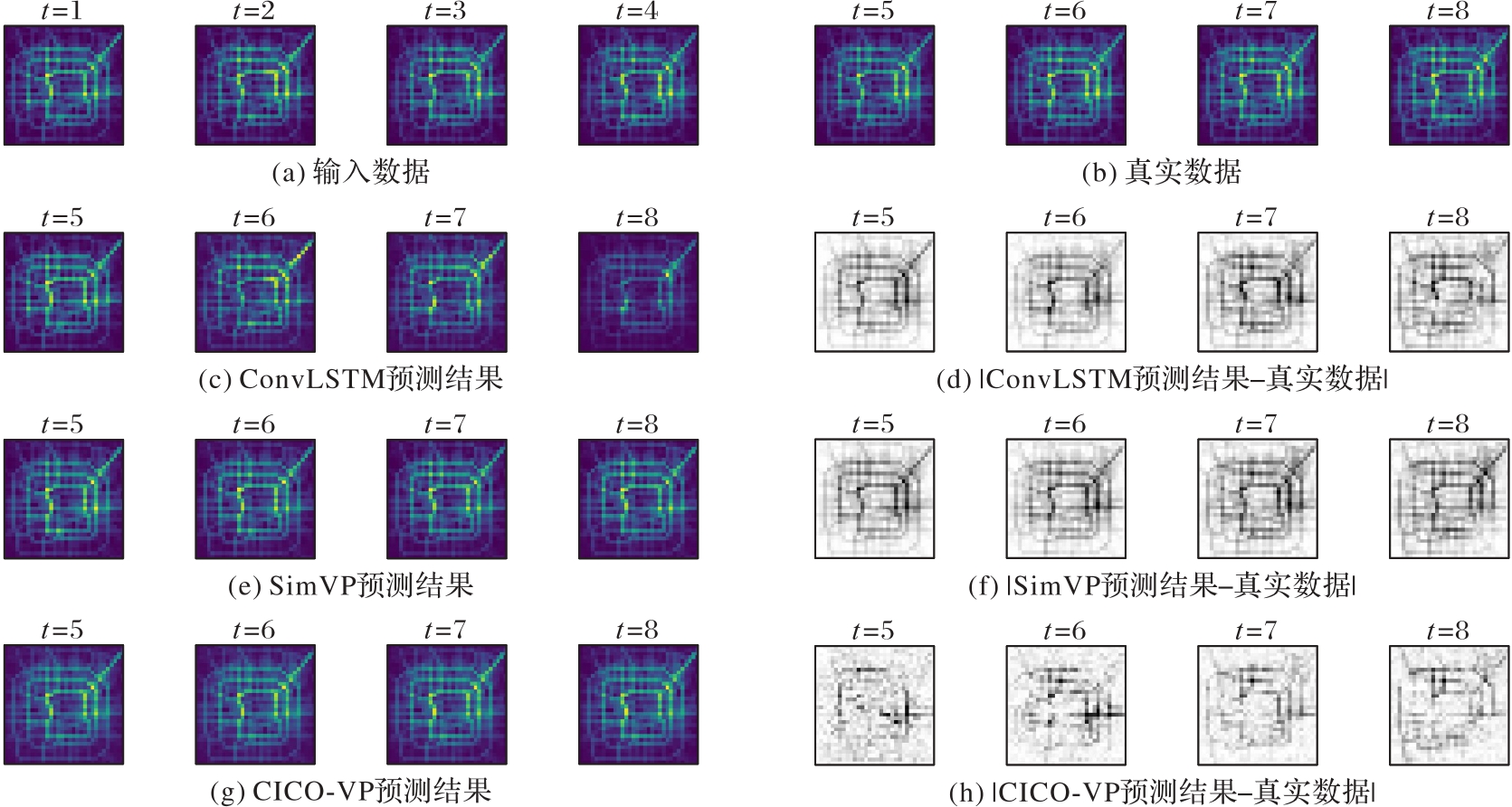
Fig. 8 Experimental results on Traffic Beijing dataset

Fig. 9 Training process of CICO-VP on KTH dataset
| 模型 | SSIM↑ | PSNR/dB↑ | 模型 | SSIM↑ | PSNR/dB↑ |
|---|---|---|---|---|---|
| ConvLSTM[ | 0.712 | 23.58 | SVAP-VAE[ | 0.852 | 27.77 |
| SV2P[ | 0.838 | 27.79 | VPN[ | 0.746 | 23.76 |
| PredRNN[ | 0.839 | 27.55 | DFN[ | 0.794 | 27.26 |
| PredRNN++[ | 0.865 | 28.47 | fRNN[ | 0.771 | 26.12 |
| E3d-LSTM[ | 0.879 | 29.31 | Znet[ | 0.817 | 27.50 |
| SimVP[ | 0.905 | 33.72 | VarNet[ | 0.843 | 28.48 |
| MCnet[ | 0.804 | 25.95 | STMFANet[ | 0.893 | 29.85 |
| SAVP[ | 0.746 | 25.38 | CICO-VP | 0.911 | 33.88 |
Tab. 6 Experiment results of KTH dataset
| 模型 | SSIM↑ | PSNR/dB↑ | 模型 | SSIM↑ | PSNR/dB↑ |
|---|---|---|---|---|---|
| ConvLSTM[ | 0.712 | 23.58 | SVAP-VAE[ | 0.852 | 27.77 |
| SV2P[ | 0.838 | 27.79 | VPN[ | 0.746 | 23.76 |
| PredRNN[ | 0.839 | 27.55 | DFN[ | 0.794 | 27.26 |
| PredRNN++[ | 0.865 | 28.47 | fRNN[ | 0.771 | 26.12 |
| E3d-LSTM[ | 0.879 | 29.31 | Znet[ | 0.817 | 27.50 |
| SimVP[ | 0.905 | 33.72 | VarNet[ | 0.843 | 28.48 |
| MCnet[ | 0.804 | 25.95 | STMFANet[ | 0.893 | 29.85 |
| SAVP[ | 0.746 | 25.38 | CICO-VP | 0.911 | 33.88 |

Fig. 10 Experimental results on KTH dataset

Fig. 11 Ablation experiment results on Moving MNIST dataset
| 1 | CHANG Z, ZHANG X, WANG S, et al. STRPM: A spatiotemporal residual predictive model for high-resolution video prediction [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 13926-13935. 10.1109/cvpr52688.2022.01356 |
| 2 | WU H, YAO Z, WANG J, et al. MotionRNN: A flexible model for video prediction with spacetime-varying motions [C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15435-15444. 10.1109/cvpr46437.2021.01518 |
| 3 | LIU B, CHEN Y, LIU S, et al. Deep learning in latent space for video prediction and compression [C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 701-710. 10.1109/cvpr46437.2021.00076 |
| 4 | SHI X, CHEN Z, WANG H, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 802-810. |
| 5 | BABAEIZADEH M, FINN C, ERHAN D, et al. Stochastic variational video prediction [EB/OL]. [2023-01-05]. . |
| 6 | MARTÍNEZ-GONZÁLEZ A, VILLAMIZAR M, CANÉVET O, et al. Efficient convolutional neural networks for depth-based multi-person pose estimation [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 30(11): 4207-4221. 10.1109/tcsvt.2019.2952779 |
| 7 | KONG Y, FU Y. Human action recognition and prediction: A survey [J]. International Journal of Computer Vision, 2022, 130: 1366-1401. 10.1007/s11263-022-01594-9 |
| 8 | WANG Y, ZHANG J, ZHU H, et al. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9146-9154. 10.1109/cvpr.2019.00937 |
| 9 | OPREA S, MARTINEZ-GONZALEZ P, GARCIA-GARCIA A, et al. A review on deep learning techniques for video prediction [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 2806-2826. 10.1109/tpami.2020.3045007 |
| 10 | KINGMA D P, WELLING M. Auto-encoding variational Bayes [C/OL]// Proceedings of the 2nd International Conference on Learning Representations. [2023-01-05]. . 10.1561/2200000056 |
| 11 | REZENDE D J, MOHAMED S, Stochastic WIERSTRA D.. backpropagation and approximate inference in deep generative models [C]// Proceedings of the 31st International Conference on Machine Learning. New York: JMLR.org, 2014: 1278-1286. |
| 12 | KIPF T N, WELLING M. Variational graph auto-encoders [EB/OL]. [2023-01-05]. . |
| 13 | RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks [C/OL]// Proceedings of the 2016 International Conference on Machine Learning. [2023-01-05]. . 10.1109/aiar.2018.8769811 |
| 14 | GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs [C]// Proceedings of the 2017 International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc, 2017: 5767-5777. |
| 15 | KARRAS T, AILA T, LAINE S, et al. Progressive growing of GANs for improved quality, stability, and variation [C/OL]// Proceedings of the 2018 International Conference on Learning Representations. [2023-01-05]. . 10.1109/cvpr42600.2020.00813 |
| 16 | BROCK A, DONAHUE J, SIMONYAN K. Large scale GAN training for high fidelity natural image synthesis [C/OL]// Proceedings of the 2019 International Conference on Learning Representations. [2023-01-05]. . |
| 17 | KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4396-4405. 10.1109/cvpr.2019.00453 |
| 18 | KARRAS T, AITTALA M, HELLSTEN J, et al. Training generative adversarial networks with limited data [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 12104-12114. |
| 19 | KARRAS T, AITTALA M, LAINE S, et al. Alias-free generative adversarial networks [C/OL]// Proceedings of the 35th International Conference on Neural Information Processing Systems. [2023-01-05]. . 10.1007/978-3-030-93158-2_7 |
| 20 | GU J T, LIU L J, WANG P, et al. StyleNeRF: A style-based 3d-aware generator for high-resolution image synthesis [C/OL]// Proceedings of the 2022 International Conference on Learning Representations. [2023-01-05]. . |
| 21 | CHAN E R, MONTEIRO M, KELLNHOFER P, et al. pi-GAN: Periodic implicit generative adversarial networks for 3D-aware image synthesis [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5795-5805. 10.1109/cvpr46437.2021.00574 |
| 22 | WALKER J, MARINO K, GUPTA A, et al. The pose knows: Video forecasting by generating pose futures [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3352-3361. 10.1109/iccv.2017.361 |
| 23 | HU Q Y, WAELCHLI A, PORTENIER T, et al. Video synthesis from a single image and motion stroke [EB/OL]. [2023-01-07]. . |
| 24 | WU B, NAIR S, MARTÍN-MARTÍN R, et al. Greedy hierarchical variational autoencoders for large-scale video prediction [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2318-2328. 10.1109/cvpr46437.2021.00235 |
| 25 | WEN S, LIU W, YANG Y, et al. Generating realistic videos from keyframes with concatenated GANs [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(8): 2337-2348. 10.1109/tcsvt.2018.2867934 |
| 26 | MATHIEU M, COUPRIE C, LeCUN Y. Deep multi-scale video prediction beyond mean square error [C/OL]// Proceedings of the 2016 International Conference on Learning Representations. [2023-01-05]. . |
| 27 | VONDRICK C, TORRALBA A. Generating the future with adversarial transformers [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2992-3000. 10.1109/cvpr.2017.319 |
| 28 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 29 | FINN C, GOODFELLOW I, LEVINE S. Unsupervised learning for physical interaction through video prediction [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc, 2016: 64-72. |
| 30 | WANG Y, LONG M, WANG J, et al. PredRNN: Recurrent neural networks for predictive learning using spatiotemporal LSTMs [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 879-888. |
| 31 | WANG Y, WU H, ZHANG J, et al. PredRNN: A recurrent neural network for spatiotemporal predictive learning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2208-2225. 10.1109/tpami.2022.3165153 |
| 32 | WANG Y, GAO Z, LONG M, et al. PredRNN++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning [C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 5123-5132. |
| 33 | LOTTER W, KREIMAN G, COX D. Deep predictive coding networks for video Prediction and unsupervised learning [C/OL]// Proceedings of the 2017 International Conference on Learning Representations. [2023-01-05]. . |
| 34 | WANG Y, JIANG L, YANG M-H, et al. Eidetic 3D LSTM: A model for video prediction and beyond [C/OL]// Proceedings of the 2018 International Conference on Learning Representations. [2023-01-05]. . |
| 35 | GAO Z, TAN C, WU L, et al. SimVP: Simpler yet better video prediction [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 3160-3170. 10.1109/cvpr52688.2022.00317 |
| 36 | 朱俊宏,赖俊宇,刘华烁,等.一种基于多层卷积结构的视频帧预测方法: CN116567258A [P]. 2023-08-08. |
| ZHU J H, LAI J Y, LIU H S, et al. A video frame prediction method based on multi-layer convolution structure: CN116567258A [P]. 2023-08-08. | |
| 37 | SRIVASTAVA N, MANSIMOV E, SALAKHUTDINOV R. Unsupervised learning of video representations using LSTMs [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 843-852. 10.1109/iccv.2015.320 |
| 38 | ZHANG J, ZHENG Y, QI D. Deep spatio-temporal residual networks for citywide crowd flows prediction [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 1655-1661. 10.1609/aaai.v31i1.10735 |
| 39 | SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions: a local SVM approach [C]// Proceedings of the 17th International Conference on Pattern Recognition. Piscataway: IEEE, 2004: 32-36. 10.1109/icpr.2004.1334462 |
| 40 | VILLEGAS R, YANG J, HONG S, et al. Decomposing motion and content for natural video sequence prediction [C/OL]// Proceedings of the 2017 International Conference on Learning Representations. [2023-01-05]. . |
| 41 | WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity [J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. 10.1109/tip.2003.819861 |
| 42 | LE GUEN V, THOME N. Disentangling physical dynamics from unknown factors for unsupervised video prediction [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11471-11481. 10.1109/cvpr42600.2020.01149 |
| 43 | LEE A X, ZHANG R, EBERT F, et al. Stochastic adversarial video prediction [EB/OL]. [2023-01-07]. . |
| 44 | KALCHBRENNER N, VAN DEN OORD A, SIMONYAN K, et al. Video pixel networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1771-1779. |
| 45 | DE BRABANDERE B, JIA X, TUYTELAARS T, et al. Dynamic filter networks [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc, 2016: 667-675. |
| 46 | OLIU M, SELVA J, ESCALERA S, et al. Folded recurrent neural networks for future video prediction [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 745-761. 10.1007/978-3-030-01264-9_44 |
| 47 | ZHANG J, WANG Y, LONG M, et al. Z-order recurrent neural networks for video prediction [C]// Proceedings of the 2019 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2019: 230-235. 10.1109/icme.2019.00048 |
| 48 | JIN B, HU Y, ZENG Y, et al. Exploring variations for unsupervised video prediction [C]// Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2018: 5801-5806. 10.1109/iros.2018.8594264 |
| 49 | JIN B, HU Y, TANG Q, et al. Exploring spatial-temporal multi-frequency analysis for high-fidelity and temporal-consistency video prediction [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4553-4562. 10.1109/cvpr42600.2020.00461 |
| [1] | Guixiang XUE, Hui WANG, Weifeng ZHOU, Yu LIU, Yan LI. Port traffic flow prediction based on knowledge graph and spatio-temporal diffusion graph convolutional network [J]. Journal of Computer Applications, 2024, 44(9): 2952-2957. |
| [2] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [3] | Chuanlin PANG, Rui TANG, Ruizhi ZHANG, Chuan LIU, Jia LIU, Shibo YUE. Distributed power allocation algorithm based on graph convolutional network for D2D communication systems [J]. Journal of Computer Applications, 2024, 44(9): 2855-2862. |
| [4] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [5] | Yun LI, Fuyou WANG, Peiguang JING, Su WANG, Ao XIAO. Uncertainty-based frame associated short video event detection method [J]. Journal of Computer Applications, 2024, 44(9): 2903-2910. |
| [6] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [7] | Jinjin LI, Guoming SANG, Yijia ZHANG. Multi-domain fake news detection model enhanced by APK-CNN and Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2674-2682. |
| [8] | Shunyong LI, Shiyi LI, Rui XU, Xingwang ZHAO. Incomplete multi-view clustering algorithm based on self-attention fusion [J]. Journal of Computer Applications, 2024, 44(9): 2696-2703. |
| [9] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [10] | Xiyuan WANG, Zhancheng ZHANG, Shaokang XU, Baocheng ZHANG, Xiaoqing LUO, Fuyuan HU. Unsupervised cross-domain transfer network for 3D/2D registration in surgical navigation [J]. Journal of Computer Applications, 2024, 44(9): 2911-2918. |
| [11] | Chunxue ZHANG, Liqing QIU, Cheng’ai SUN, Caixia JING. Purchase behavior prediction model based on two-stage dynamic interest recognition [J]. Journal of Computer Applications, 2024, 44(8): 2365-2371. |
| [12] | Yuhan LIU, Genlin JI, Hongping ZHANG. Video pedestrian anomaly detection method based on skeleton graph and mixed attention [J]. Journal of Computer Applications, 2024, 44(8): 2551-2557. |
| [13] | Yanjie GU, Yingjun ZHANG, Xiaoqian LIU, Wei ZHOU, Wei SUN. Traffic flow forecasting via spatial-temporal multi-graph fusion [J]. Journal of Computer Applications, 2024, 44(8): 2618-2625. |
| [14] | Qianhong SHI, Yan YANG, Yongquan JIANG, Xiaocao OUYANG, Wubo FAN, Qiang CHEN, Tao JIANG, Yuan LI. Multi-granularity abrupt change fitting network for air quality prediction [J]. Journal of Computer Applications, 2024, 44(8): 2643-2650. |
| [15] | Yubo ZHAO, Liping ZHANG, Sheng YAN, Min HOU, Mao GAO. Relation extraction between discipline knowledge entities based on improved piecewise convolutional neural network and knowledge distillation [J]. Journal of Computer Applications, 2024, 44(8): 2421-2429. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||