


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (8): 2626-2633.DOI: 10.11772/j.issn.1001-9081.2023081120
• Frontier and comprehensive applications • Previous Articles Next Articles
Haodong HE1, Hao FU1,2( ), Qiang WANG1, Shuai ZHOU1, Wei LIU1
), Qiang WANG1, Shuai ZHOU1, Wei LIU1
Received:2023-08-22
Revised:2023-11-16
Accepted:2023-11-24
Online:2023-12-18
Published:2024-08-10
Contact:
Hao FU
About author:HE Haodong, born in 1997, M. S. candidate. His research interests include multi-robot intelligent control, reinforcement learning.Supported by:
何浩东1, 符浩1,2(), 王强1, 周帅1, 刘伟1
通讯作者:
符浩
作者简介:何浩东(1997—),男,四川巴中人,硕士研究生,主要研究方向:多机器人智能控制、强化学习基金资助:CLC Number:
Haodong HE, Hao FU, Qiang WANG, Shuai ZHOU, Wei LIU. Multi-robot path following and formation based on deep reinforcement learning[J]. Journal of Computer Applications, 2024, 44(8): 2626-2633.
何浩东, 符浩, 王强, 周帅, 刘伟. 基于深度强化学习的多机器人路径跟随与编队[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2626-2633.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023081120

Fig. 1 Path following and formation environment

Fig. 2 Schematic diagram of virtual robot structure
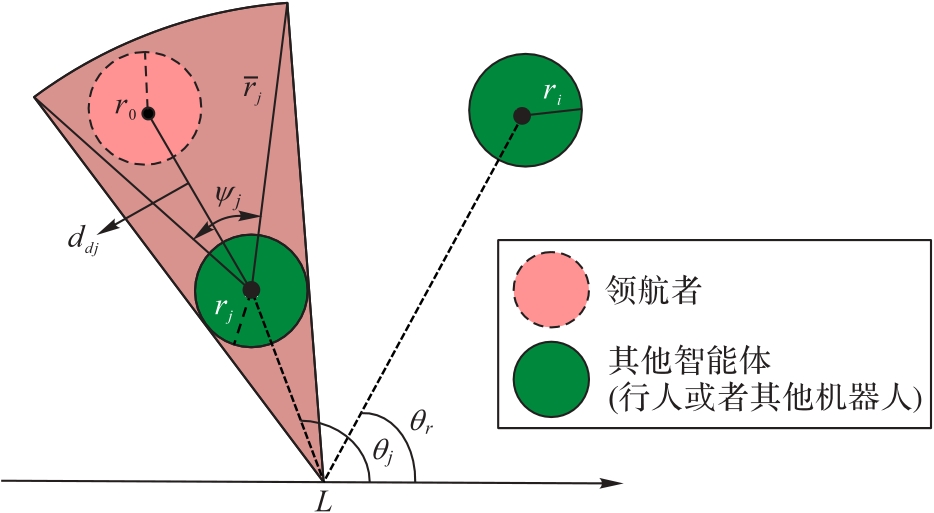
Fig. 3 Danger zone

Fig. 4 Value network model

Fig. 5 Framework of overall network
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 输入维度 | 14 | 全连接层 | (150,100,100) |
| 激活函数 | ReLU | 迭代次数 | 104 |
| 优化器 | Adam | 行人数 | 6 |
| 学习率 | 10-4 | 更新回合C | 1 |
| Nb | 128 | 机器人速度 | 0.3 m/s |
| LSTM隐层 | 50 | 行人速度 | 0.3 m/s |
Tab. 1 Experimental parameters
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 输入维度 | 14 | 全连接层 | (150,100,100) |
| 激活函数 | ReLU | 迭代次数 | 104 |
| 优化器 | Adam | 行人数 | 6 |
| 学习率 | 10-4 | 更新回合C | 1 |
| Nb | 128 | 机器人速度 | 0.3 m/s |
| LSTM隐层 | 50 | 行人速度 | 0.3 m/s |
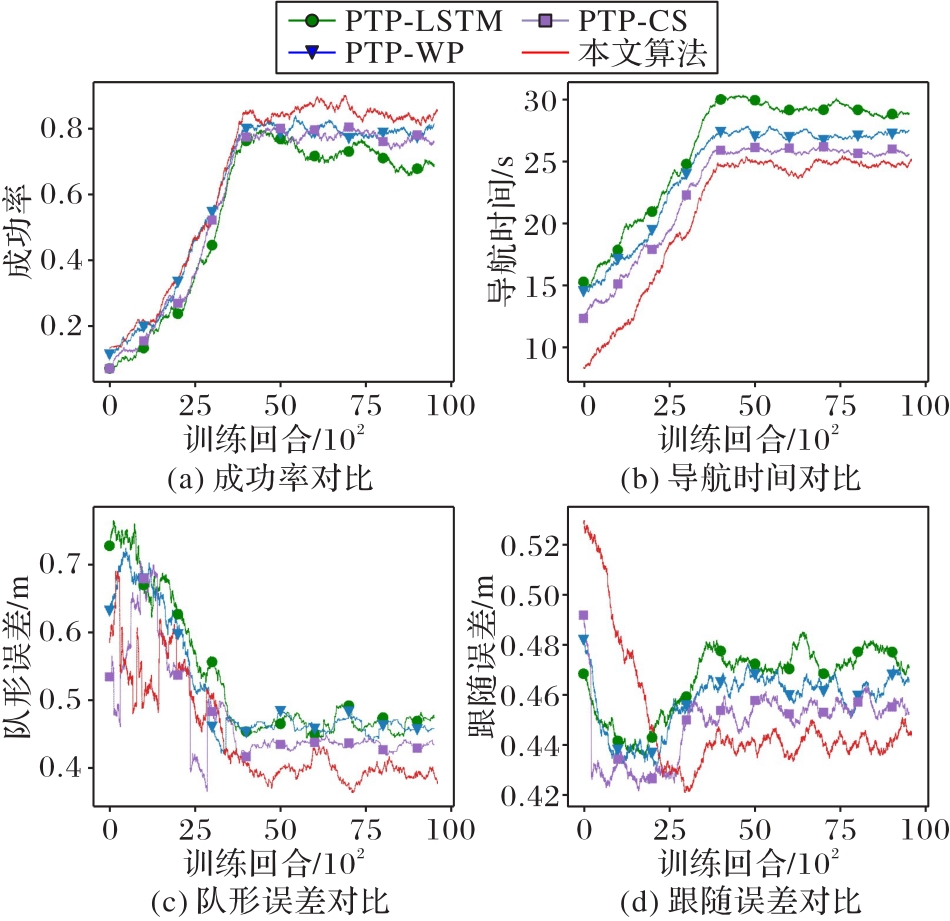
Fig. 6 Different metrics training curves of four algorithms
| 行人数 | 算法 | 成功率/% | 导航 时间/s | 队形 误差/m | 跟随 误差/m |
|---|---|---|---|---|---|
| 6 | PTP-LSTM | 76 | 29.8 | 0.435 | 0.484 |
| PTP-WP | 79 | 25.4 | 0.471 | 0.463 | |
| PTP-CS | 76 | 24.2 | 0.422 | 0.456 | |
| 本文算法 | 86 | 23.8 | 0.371 | 0.443 | |
| 8 | PTP-LSTM | 70 | 26.2 | 0.572 | 0.551 |
| PTP-WP | 73 | 27.8 | 0.532 | 0.612 | |
| PTP-CS | 71 | 27.4 | 0.490 | 0.578 | |
| 本文算法 | 82 | 24.6 | 0.414 | 0.461 | |
| 10 | PTP-LSTM | 63 | 28.4 | 0.681 | 0.614 |
| PTP-WP | 65 | 28.0 | 0.566 | 0.635 | |
| PTP-CS | 64 | 28.1 | 0.584 | 0.687 | |
| 本文算法 | 80 | 25.8 | 0.507 | 0.495 |
Tab. 2 Quantitative evaluation results
| 行人数 | 算法 | 成功率/% | 导航 时间/s | 队形 误差/m | 跟随 误差/m |
|---|---|---|---|---|---|
| 6 | PTP-LSTM | 76 | 29.8 | 0.435 | 0.484 |
| PTP-WP | 79 | 25.4 | 0.471 | 0.463 | |
| PTP-CS | 76 | 24.2 | 0.422 | 0.456 | |
| 本文算法 | 86 | 23.8 | 0.371 | 0.443 | |
| 8 | PTP-LSTM | 70 | 26.2 | 0.572 | 0.551 |
| PTP-WP | 73 | 27.8 | 0.532 | 0.612 | |
| PTP-CS | 71 | 27.4 | 0.490 | 0.578 | |
| 本文算法 | 82 | 24.6 | 0.414 | 0.461 | |
| 10 | PTP-LSTM | 63 | 28.4 | 0.681 | 0.614 |
| PTP-WP | 65 | 28.0 | 0.566 | 0.635 | |
| PTP-CS | 64 | 28.1 | 0.584 | 0.687 | |
| 本文算法 | 80 | 25.8 | 0.507 | 0.495 |

Fig. 7 Simulation results of PTP-LSTM

Fig. 8 Simulation results of PTP-WP
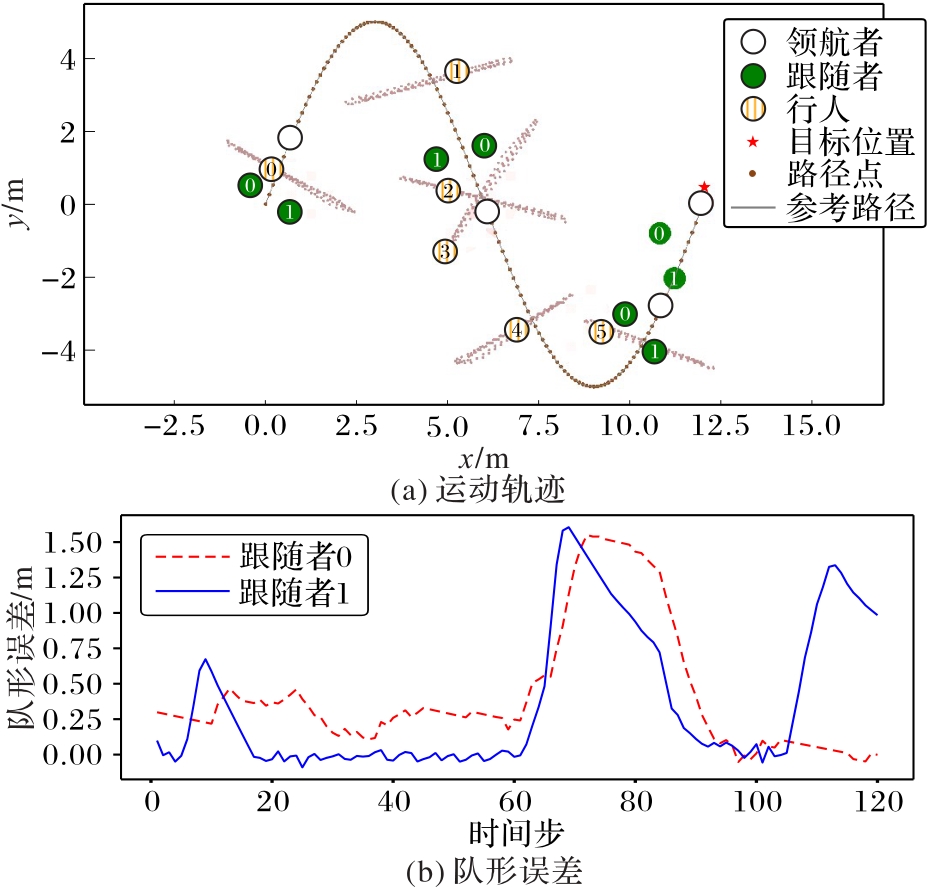
Fig. 9 Simulation results of PTP-CS
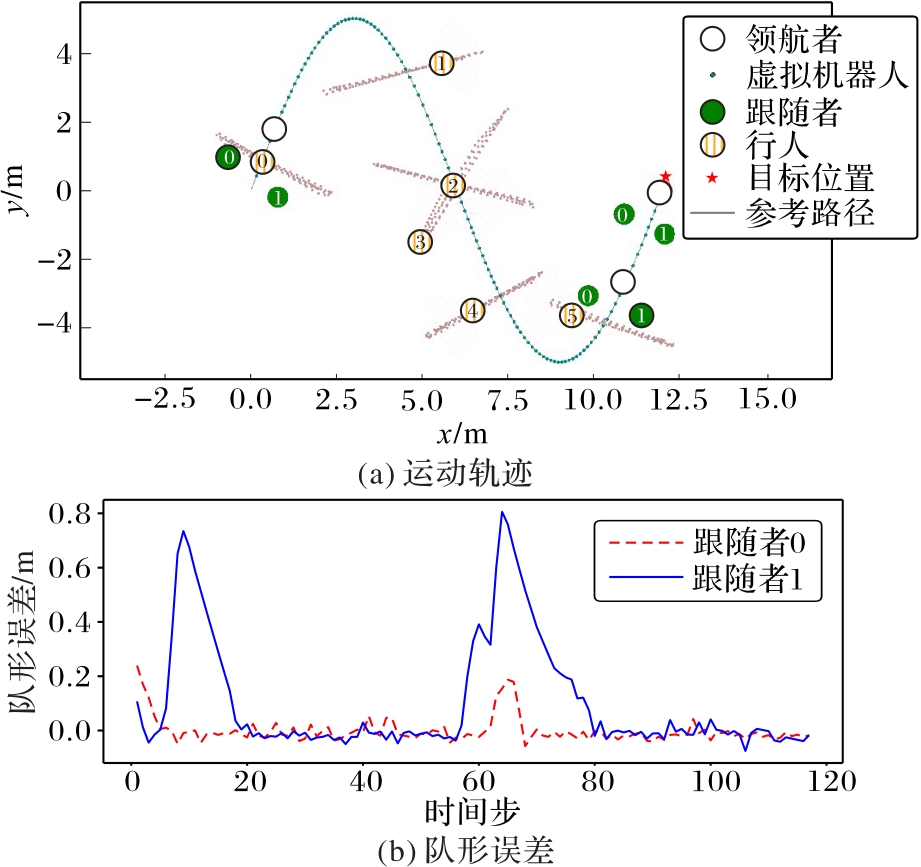
Fig. 10 Simulation results of proposed algorithm

Fig. 11 Diamond formation simulation results
| 1 | 陈佳盼,郑敏华.基于深度强化学习的机器人操作行为研究综述[J].机器人,2022, 44(2): 236-256. |
| CHEN J P, ZHENG M H. A survey of robot manipulation behavior research based on deep reinforcement learning [J]. Robot, 2022, 44(2): 236-256. | |
| 2 | 户晓玲,王健安.一种多机器人分布式编队策略与实现[J].计算机技术与发展,2019, 29(1): 21-25. |
| HU X L, WANG J A. A multi-robot distributed formation strategy and implementation [J]. Computer Technology and Development, 2019, 29(1): 21-25. | |
| 3 | 罗京,刘成林,刘飞.多移动机器人的领航-跟随编队避障控制[J].智能系统学报, 2017, 12(2): 202-212. |
| LUO J, LIU C L, LIU F. Pilot-following formation and obstacle avoidance control of multiple mobile robots [J]. CAAI Transactions on Intelligent Systems, 2017, 12(2): 202-212. | |
| 4 | 秦留界,宋光明,毛巨正,等. 基于手眼双模态人机接口的移动机器人编队共享控制[J].机器人, 2022, 44(3): 343-351. |
| QIN L J, SONG G M, MAO J Z, et al. Shared control of multi-robot formations based on the eye-hand dual-modal human-robot interface [J]. Robot, 2022, 44(3): 343-351. | |
| 5 | HACENE N, MENDIL B. Behavior-based autonomous navigation and formation control of mobile robots in unknown cluttered dynamic environments with dynamic target tracking [J]. International Journal of Automation and Computing, 2021, 18: 766-786. |
| 6 | 安永跃,李淑琴.基于行为规划的多机器鱼编队策略的研究[J].计算机仿真,2013,30(11):369-373. |
| AN Y Y, LI S Q. Study of multiple robotic fishes formation strategy based on behavior planning method [J]. Computer Simulation, 2013, 30(11): 369-373. | |
| 7 | LIU J, YIN T, YUE D, et al. Event-based secure leader-following consensus control for multiagent systems with multiple cyber attacks [J]. IEEE Transactions on Cybernetics, 2021, 51(1): 162-173. |
| 8 | DONG L, CHEN Y, QU X. Formation control strategy for nonholonomic intelligent vehicles based on virtual structure and consensus approach [J]. Procedia Engineering, 2016, 137: 415-424. |
| 9 | LEE G, CHWA D. Decentralized behavior-based formation control of multiple robots considering obstacle avoidance [J]. Intelligent Service Robotics, 2018, 11: 127-138. |
| 10 | LIU X, GE S S, C-H GOH. Vision-based leader-follower formation control of multiagents with visibility constraints [J]. IEEE Transactions on Control Systems Technology, 2019, 27(3): 1326-1333. |
| 11 | 李咏华,张立,刘嘉睿,等.领航-跟随型多移动小车滑模编队控制[J].重庆理工大学学报(自然科学版), 2022, 36(7): 18-27. |
| LI Y H, ZHANG L, LIU J R, et al. Sliding mode formation control of leader-follower multi-mobile cars [J]. Journal of Chongqing University of Technology (Natural Science), 2022, 36(7): 18-27. | |
| 12 | LIANG X, QU X, WANG N, et al. Swarm control with collision avoidance for multiple underactuated surface vehicles [J]. Ocean Engineering, 2019, 191: 106516. |
| 13 | PARK B S, YOO S J. Adaptive-observer-based formation tracking of networked uncertain underactuated surface vessels with connectivity preservation and collision avoidance [J]. Journal of the Franklin Institute, 2019, 356(15): 7947-7966. |
| 14 | 胡阳修,贺亮,赵长春,等.基于路径跟随的改进领航-跟随无人机协同编队方法[J].飞控与探测, 2021, 4(2):26-35. |
| HU Y X, HE L, ZHAO C C, et al. Improved method of leader-follower UAV coordinated formation based on path following[J]. Flight Control & Detection, 2021, 4(2): 26-35. | |
| 15 | PARK B S, YOO S J. An error transformation approach for connectivity-preserving and collision-avoiding formation tracking of networked uncertain underactuated surface vessels [J]. IEEE Transactions on Cybernetics, 2019, 49(8): 2955-2966. |
| 16 | QU X, LIANG X, HOU Y, et al. Fuzzy state observer-based cooperative path-following control of autonomous underwater vehicles with unknown dynamics and ocean disturbances [J]. International Journal of Fuzzy Systems, 2021, 23(6): 1849-1859. |
| 17 | MENDA K, CHEN Y-C, GRANA J, et al. Deep reinforcement learning for event-driven multi-agent decision processes [J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 20(4): 1259-1268. |
| 18 | ZHAO Y, QI X, MA Y, et al. Path following optimization for an underactuated USV using smoothly-convergent deep reinforcement learning [J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(10): 6208-6220. |
| 19 | ZHAO Y, MA Y, HU S. USV formation and path-following control via deep reinforcement learning with random braking [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(12): 5468-5478. |
| 20 | HE Z, SONG C, DONG L. Multi-robot social-aware cooperative planning in pedestrian environments using multi-agent reinforcement learning [EB/OL]. (2022-11-29)[2023-08-01]. . |
| 21 | CUI Y, HUANG X, WANG Y, et al. Socially-aware multi-agent following with 2D laser scans via deep reinforcement learning and potential field [C]// Proceedings of the 2021 IEEE International Conference on Real-time Computing and Robotics. Piscataway: IEEE, 2021: 515-520. |
| 22 | PÉREZ-D’ARPINO C, LIU C, GOEBEL P, et al. Robot navigation in constrained pedestrian environments using reinforcement learning [C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 1140-1146. |
| 23 | KÄSTNER L, ZHAO X, SHEN Z, et al. Obstacle-aware waypoint generation for long-range guidance of deep-reinforcement-learning-based navigation approaches [EB/OL]. (2021-09-23)[2023-08-01]. . |
| 24 | CHEN Y F, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning [C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 285-292. |
| 25 | SAMSANI S S, MUHAMMAD M S. Socially compliant robot navigation in crowded environment by human behavior resemblance using deep reinforcement learning [J]. IEEE Robotics and Automation Letters, 2021, 6(3): 5223-5230. |
| 26 | EVERETT M, CHEN Y F, HOW J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning [C]// Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2018: 3052-3059. |
| 27 | VAN DEN BERG J, GUY S J, LIN M, et al. Reciprocal n-body collision avoidance [C]// Proceedings of the 14th International Symposium on Robotics Research. Berlin: Springer, 2011: 3-19. |
| [1] | Hailin XIAO, Tianyi HUANG, Qiuxiang DAI, Yuejun ZHANG, Zhongshan ZHANG. Safe reinforcement learning method for decision making of autonomous lane changing based on trajectory prediction [J]. Journal of Computer Applications, 2024, 44(9): 2958-2963. |
| [2] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [3] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [4] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [5] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [6] | Fatang CHEN, Miao HUANG, Yufeng JIN. Resource allocation algorithm for low earth orbit satellites oriented to user demand [J]. Journal of Computer Applications, 2024, 44(4): 1242-1247. |
| [7] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [8] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [9] | Ziyang SONG, Junhuai LI, Huaijun WANG, Xin SU, Lei YU. Path planning algorithm of manipulator based on path imitation and SAC reinforcement learning [J]. Journal of Computer Applications, 2024, 44(2): 439-444. |
| [10] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [11] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [12] | Yu WANG, Zhihui GUAN, Yuanpeng LI. Distributed UAV cluster pursuit decision-making based on trajectory prediction and MADDPG [J]. Journal of Computer Applications, 2024, 44(11): 3623-3628. |
| [13] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [14] | Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN [J]. Journal of Computer Applications, 2023, 43(8): 2636-2643. |
| [15] | Ziteng WANG, Yaxin YU, Zifang XIA, Jiaqi QIAO. Sparse reward exploration mechanism fusing curiosity and policy distillation [J]. Journal of Computer Applications, 2023, 43(7): 2082-2090. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||