


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1560-1567.DOI: 10.11772/j.issn.1001-9081.2025050631
• Multimedia computing and computer simulation • Previous Articles
Wenchao MING, Suzhen LIN( ), Zanxia JIN
), Zanxia JIN
Received:2025-06-06
Revised:2025-07-14
Accepted:2025-08-08
Online:2025-08-15
Published:2026-05-10
Contact:
Suzhen LIN
About author:MING Wenchao, born in 1999, M. S. candidate. His research interests include image captioning.Supported by:
明文超, 蔺素珍(), 晋赞霞
通讯作者:
蔺素珍
作者简介:明文超(1999—),男,山东济南人,硕士研究生,CCF会员,主要研究方向:图像描述基金资助:CLC Number:
Wenchao MING, Suzhen LIN, Zanxia JIN. Multi-band image captioning method based on scene concept-guided feature fusion[J]. Journal of Computer Applications, 2026, 46(5): 1560-1567.
明文超, 蔺素珍, 晋赞霞. 基于场景概念引导特征融合的多波段图像描述生成方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1560-1567.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050631
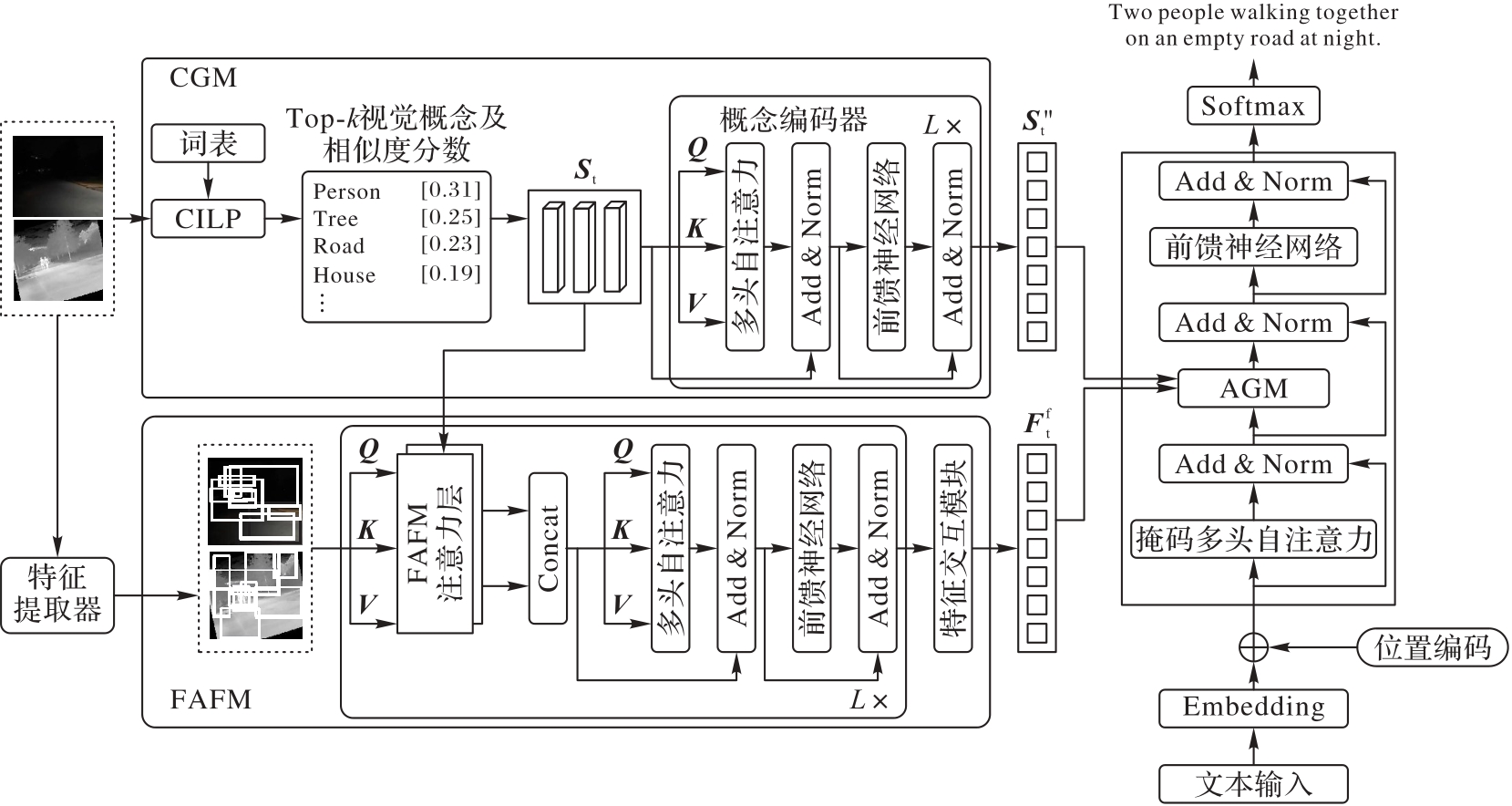
Fig. 1 Overall framework of proposed method
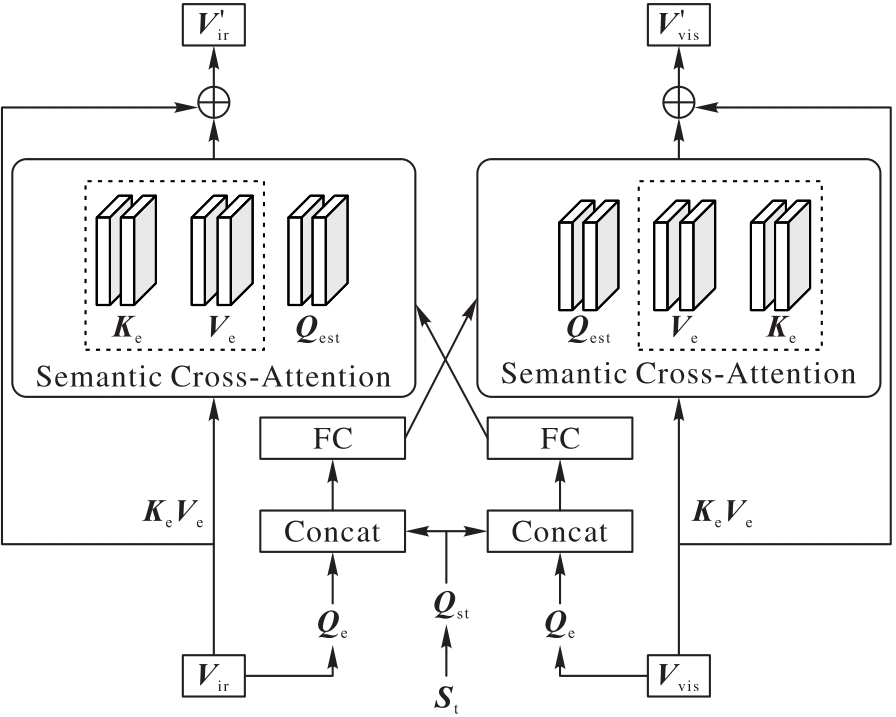
Fig.2 FAFM attention layer structure
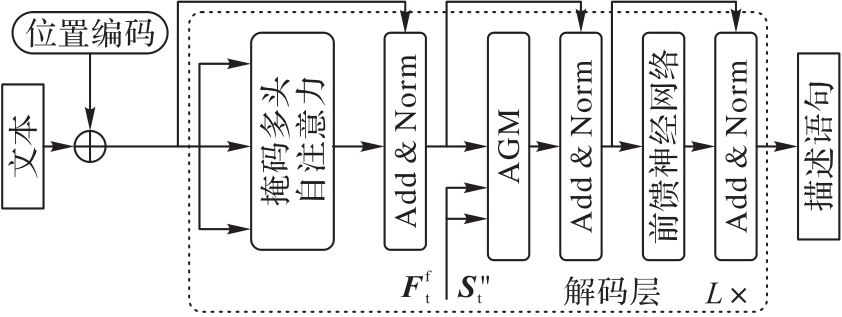
Fig.3 Decoder framework
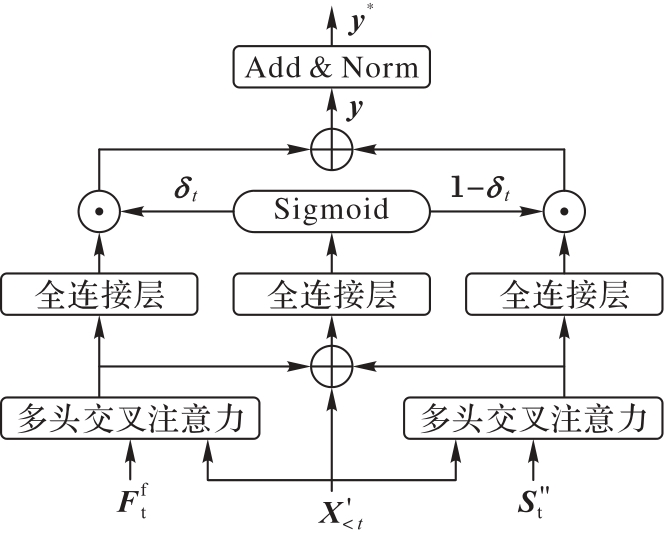
Fig.4 AGM network structure
| 视觉概念数 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| 5 | 79.9 | 70.2 | 61.8 | 54.8 | 35.4 | 68.0 | 117.0 |
| 10 | 80.0 | 70.7 | 62.4 | 55.6 | 35.9 | 68.0 | 118.9 |
| 15 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| 20 | 79.6 | 70.4 | 62.4 | 55.6 | 35.6 | 67.8 | 118.5 |
| 25 | 79.7 | 70.3 | 62.1 | 55.3 | 35.7 | 68.0 | 116.9 |
| 30 | 79.6 | 70.2 | 61.9 | 55.0 | 35.7 | 68.0 | 116.1 |
Tab. 1 Impact of visual concept number on model performance
| 视觉概念数 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| 5 | 79.9 | 70.2 | 61.8 | 54.8 | 35.4 | 68.0 | 117.0 |
| 10 | 80.0 | 70.7 | 62.4 | 55.6 | 35.9 | 68.0 | 118.9 |
| 15 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| 20 | 79.6 | 70.4 | 62.4 | 55.6 | 35.6 | 67.8 | 118.5 |
| 25 | 79.7 | 70.3 | 62.1 | 55.3 | 35.7 | 68.0 | 116.9 |
| 30 | 79.6 | 70.2 | 61.9 | 55.0 | 35.7 | 68.0 | 116.1 |
| FAFM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 78.8 | 69.5 | 61.7 | 55.4 | 35.2 | 67.8 | 117.3 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
Tab. 2 Results of ablation experiment on FAFM
| FAFM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 78.8 | 69.5 | 61.7 | 55.4 | 35.2 | 67.8 | 117.3 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| CGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 69.8 | 61.4 | 54.6 | 35.5 | 67.5 | 116.4 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
Tab. 3 Results of ablation experiment on CGM
| CGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 69.8 | 61.4 | 54.6 | 35.5 | 67.5 | 116.4 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| AGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 70.1 | 61.9 | 55.1 | 35.5 | 67.7 | 117.9 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
Tab. 4 Results of ablation experiment on AGM
| AGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 70.1 | 61.9 | 55.1 | 35.5 | 67.7 | 117.9 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| 方法 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| SCST[ | 58.9 | 48.4 | 31.7 | 25.9 | 23.2 | 41.7 | 55.2 |
| Up-Down[ | 57.6 | 47.2 | 31.0 | 24.2 | 22.5 | 40.8 | 51.7 |
| AoA[ | 61.2 | 50.1 | 34.7 | 27.8 | 23.7 | 47.4 | 60.3 |
| ORT[ | 59.1 | 44.7 | 32.8 | 25.9 | 23.2 | 46.3 | 55.8 |
| M2[ | 79.2 | 69.5 | 61.1 | 54.1 | 35.3 | 67.4 | 114.5 |
| RSTNet[ | 78.1 | 68.7 | 60.4 | 53.6 | 34.9 | 66.8 | 112.9 |
| DLCT[ | 77.1 | 68.1 | 60.4 | 54.1 | 34.5 | 66.2 | 113.0 |
| VisualGPT[ | 79.3 | 69.7 | 62.2 | 54.8 | 35.6 | 67.5 | 115.2 |
| DRET[ | 79.0 | 69.2 | 61.3 | 53.8 | 35.2 | 67.9 | 115.5 |
| GSSF[ | 79.3 | 70.4 | 62.4 | 54.3 | 35.1 | 66.8 | 116.3 |
| MBIC[ | 81.2 | 70.1 | 62.3 | 55.3 | 34.0 | 66.8 | 111.3 |
| FFIC[ | 79.2 | 70.0 | 62.0 | 55.6 | 35.7 | 67.9 | 116.6 |
| 本文方法 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
Tab. 5 Performance comparison of proposed method and representative methods
| 方法 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| SCST[ | 58.9 | 48.4 | 31.7 | 25.9 | 23.2 | 41.7 | 55.2 |
| Up-Down[ | 57.6 | 47.2 | 31.0 | 24.2 | 22.5 | 40.8 | 51.7 |
| AoA[ | 61.2 | 50.1 | 34.7 | 27.8 | 23.7 | 47.4 | 60.3 |
| ORT[ | 59.1 | 44.7 | 32.8 | 25.9 | 23.2 | 46.3 | 55.8 |
| M2[ | 79.2 | 69.5 | 61.1 | 54.1 | 35.3 | 67.4 | 114.5 |
| RSTNet[ | 78.1 | 68.7 | 60.4 | 53.6 | 34.9 | 66.8 | 112.9 |
| DLCT[ | 77.1 | 68.1 | 60.4 | 54.1 | 34.5 | 66.2 | 113.0 |
| VisualGPT[ | 79.3 | 69.7 | 62.2 | 54.8 | 35.6 | 67.5 | 115.2 |
| DRET[ | 79.0 | 69.2 | 61.3 | 53.8 | 35.2 | 67.9 | 115.5 |
| GSSF[ | 79.3 | 70.4 | 62.4 | 54.3 | 35.1 | 66.8 | 116.3 |
| MBIC[ | 81.2 | 70.1 | 62.3 | 55.3 | 34.0 | 66.8 | 111.3 |
| FFIC[ | 79.2 | 70.0 | 62.0 | 55.6 | 35.7 | 67.9 | 116.6 |
| 本文方法 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |

Fig. 5 Visual analysis results by different methods
| [1] | SHARMA H, PADHA D. Domain-specific image captioning: a comprehensive review[J]. International Journal of Multimedia Information Retrieval, 2024, 13: No.20. |
| [2] | GHANDI T, POURREZA H, MAHYAR H. Deep learning approaches on image captioning: a review[J]. ACM Computing Surveys, 2024, 56(3): No.62. |
| [3] | ALEISSAEE A A, KUMAR A, ANWER R M, et al. Transformers in remote sensing: a survey[J]. Remote Sensing, 2023, 15(7): No.1860. |
| [4] | 朱翌,李秀.医学图像描述综述:编码、解码及最新进展[J].中国图象图形学报,2023,28(7):1990-2010. |
| ZHU Y, LI X. A survey of medical image captioning technique: encoding, decoding and latest advance[J]. Journal of Image and Graphics, 2023, 28(7): 1990-2010. | |
| [5] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [6] | 贺姗,蔺素珍,王彦博,等. 基于特征融合的多波段图像描述生成方法[J]. 计算机工程, 2024, 50(6): 236-244. |
| HE S, LIN S Z, WANG Y B, et al. Multi-band image caption generation method based on feature fusion[J]. Computer Engineering, 2024, 50(6): 236-244. | |
| [7] | 顾梦瑶,蔺素珍,晋赞霞,等.基于特征对齐融合的双波段图像描述生成方法[J].现代电子技术,2025,48(7):65-71. |
| GU M Y, LIN S Z, JIN Z X, et al. Dual-band image captioning generation method based on feature alignment fusion[J]. Modern Electronic Technique, 2025, 48(7): 65-71. | |
| [8] | 贺姗. 面向可见光和红外同步探测的图像描述方法研究[D]. 太原:中北大学, 2024. |
| HE S. Research on image caption method for visible and infrared synchronous detection[D]. Taiyuan: North University of China, 2024. | |
| [9] | WANG Y, LOU S, WANG K, et al. Automatic captioning based on visible and infrared images[C]// Proceedings of the 2024 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2024: 11312-11318. |
| [10] | STEFANINI M, CORNIA M, BARALDI L, et al. From show to tell: a survey on deep learning-based image captioning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 539-559. |
| [11] | 周峻宇,施水才,王洪俊. 基于深度学习的图像字幕生成综述[J]. 软件导刊, 2025, 24(1): 211-220. |
| ZHOU J Y, SHI S C, WANG H J. An overview of deep learning-based image caption generation[J]. Software Guide, 2025, 24(1): 211-220. | |
| [12] | XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 2048-2057. |
| [13] | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1179-1195. |
| [14] | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. |
| [15] | HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4633-4642. |
| [16] | PAN Y, YAO T, LI Y, et al. X-Linear attention networks for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10968-10977. |
| [17] | GAO C, BIAN G, DONG Y, et al. Infrared image captioning based on unsupervised learning and reinforcement learning[C]// Proceedings of the 2022 International Conference on Automation, Robotics and Computer Engineering. Piscataway: IEEE, 2022: 1-4. |
| [18] | YANG X, TANG K, ZHANG H, et al. Auto-encoding scene graphs for image captioning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10677-10686. |
| [19] | YANG X, LIU Y, WANG X. ReFormer: the relational Transformer for image captioning[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 5398-5406. |
| [20] | HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: transforming objects into words[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 11137-11147. |
| [21] | CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory Transformer for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10575-10584. |
| [22] | ZHANG J, FANG Z, SUN H, et al. Adaptive semantic-enhanced Transformer for image captioning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(2): 1785-1796. |
| [23] | 白雪冰,车进,吴金蔓,等. 基于Transformer视觉特征融合的图像描述方法[J]. 计算机工程, 2024, 50(8): 229-238. |
| BAI X B, CHE J, WU J M, et al. Image captioning method based on Transformer visual features fusion[J]. Computer Engineering, 2024, 50(8): 229-238. | |
| [24] | FANG Z, WANG J, HU X, et al. Injecting semantic concepts into end-to-end image captioning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17988-17998. |
| [25] | CHEN J, GUO H, YI K, et al. VisualGPT: data-efficient adaptation of pretrained language models for image captioning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18009-18019. |
| [26] | 王子怡,李卫军,刘雪洋,等. 基于Swin Transformer与多尺度特征融合的图像描述方法[J]. 计算机应用, 2025, 45(10): 3154-3160. |
| WANG Z Y, LI W J, LIU X Y, et al. Image caption method based on Swin Transformer and multi-scale feature fusion[J]. Journal of Computer Applications, 2025, 45(10): 3154-3160. | |
| [27] | LV J, HUI T, ZHI Y, et al. Infrared image caption based on object-oriented attention[J]. Entropy, 2023, 25(5): No.826. |
| [28] | GEBHARDT E, WOLF M. Camel dataset for visual and thermal infrared multiple object detection and tracking[C]// Proceedings of the 15th IEEE International Conference on Advanced Video and Signal based Surveillance. Piscataway: IEEE, 2018: 1-6. |
| [29] | LI C, CHENG H, HU S, et al. Learning collaborative sparse representation for grayscale-thermal tracking[J]. IEEE Transactions on Image Processing, 2016, 25(12): 5743-5756. |
| [30] | LI C, LIANG X, LU Y, et al. RGB-T object tracking: benchmark and baseline[J]. Pattern Recognition, 2019, 96: No.106977. |
| [31] | CHENG C, XU T, WU X J, et al. TextFusion: unveiling the power of textual semantics for controllable image fusion[J]. Information Fusion, 2025, 117: No.102790. |
| [32] | LI H, XU T, WU X J, et al. LRRNet: a novel representation learning guided fusion network for infrared and visible images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(9): 11040-11052. |
| [33] | ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15460-15469. |
| [34] | LUO Y, JI J, SUN X, et al. Dual-level collaborative Transformer for image captioning[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 2286-2293. |
| [35] | ZHOU W, SONG C, CHEN D, et al. From multi-scale grids to dynamic regions: dual-relation enhanced Transformer for image captioning[J]. Knowledge-Based Systems, 2025, 311: No.113127. |
| [36] | PARSEH M J, GHADIRI S. Graph-based image captioning with semantic and spatial features[J]. Signal Processing: Image Communication, 2025, 133: No.117273. |
| [1] | Yuqian HUANG, Hui HUANG, Yongbin QIN, Ruizhang HUANG, Yanping CHEN, Yulin ZHOU, Qian SUN. Judicial element extraction method by integrating global and local semantics [J]. Journal of Computer Applications, 2026, 46(5): 1460-1467. |
| [2] | Jiali ZHENG, Gang ZHOU, Jing CHEN, Shunhang LI. Adaptive multi-feature fusion detection method for AI-generated text [J]. Journal of Computer Applications, 2026, 46(5): 1433-1440. |
| [3] | Wenhao LI, Yinzhang GUO. Urban traffic flow prediction based on dual-layer multi-scale dynamic graph convolutional network model [J]. Journal of Computer Applications, 2026, 46(4): 1323-1333. |
| [4] | Huanxian LIU, Hongtao WANG, Xian’ao WANG, Hongmei WANG, Weifeng XU. Multimodal fact verification with cross-modal semantic association [J]. Journal of Computer Applications, 2026, 46(4): 1069-1076. |
| [5] | Shuai HE, Chunhua DENG. Object detection algorithm with few-shot learning based on YOLO-World [J]. Journal of Computer Applications, 2026, 46(4): 1275-1282. |
| [6] | Xinyi YAN, Linglong ZHU, Yonghong ZHANG. CDC-DETR: multi-scale real-time human-vehicle detection method for complex traffic scenarios [J]. Journal of Computer Applications, 2026, 46(4): 1283-1291. |
| [7] | Hanqing LIU, Guoming SANG, Yijia ZHANG. Remote sensing image captioning model combining dense multi-scale feature fusion and feature knowledge-enhanced Transformer [J]. Journal of Computer Applications, 2026, 46(3): 741-749. |
| [8] | Jincheng FU, Shiyou YANG. Short-term wind power prediction using hybrid model based on Bayesian optimization and feature fusion [J]. Journal of Computer Applications, 2026, 46(2): 652-658. |
| [9] | Feng HAN, Yongfeng BU, Haoxiang LIANG, Shuwen HUANG, Zhaoyang ZHANG, Shijie SUN. Vehicle trajectory anomaly detection based on multi-level spatio-temporal interaction dependency [J]. Journal of Computer Applications, 2026, 46(2): 604-612. |
| [10] | Jinyu LIANG, Hongjuan GAO, Xiaofei DU. 3D face generation method based on latent feature enhancement for disentanglement [J]. Journal of Computer Applications, 2026, 46(1): 216-223. |
| [11] | Zhihui ZAN, Yajing WANG, Ke LI, Zhixiang YANG, Guangyu YANG. Multi-feature fusion speech emotion recognition method based on SAA-CNN-BiLSTM network [J]. Journal of Computer Applications, 2026, 46(1): 69-76. |
| [12] | Ning CAO, Xin WEN, Yanrong HAO, Rui CAO. Lightweight motor imagery electroencephalogram decoding neural network with multi-domain feature fusion [J]. Journal of Computer Applications, 2026, 46(1): 289-296. |
| [13] | Yiming LIANG, Jing FAN, Wenze CHAI. Multi-scale feature fusion sentiment classification based on bidirectional cross attention [J]. Journal of Computer Applications, 2025, 45(9): 2773-2782. |
| [14] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [15] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||