


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (6): 1965-1972.DOI: 10.11772/j.issn.1001-9081.2025060763
• Multimedia computing and computer simulation • Previous Articles
Jinxiao ZHANG1, Chenglong LI1( ), Xinyan GAO2, Ming ZHANG1
), Xinyan GAO2, Ming ZHANG1
Received:2025-07-12
Revised:2025-08-11
Accepted:2025-08-15
Online:2025-08-27
Published:2026-06-10
Contact:
Chenglong LI
About author:ZHANG Jinxiao, born in 1999, M. S. candidate. His research interests include computer vision, human pose estimation.Supported by:
张金萧1, 李成龙1(), 高新燕2, 张铭1
通讯作者:
李成龙
作者简介:张金萧(1999—),男,河南驻马店人,硕士研究生,主要研究方向:计算机视觉、人体姿态估计基金资助:CLC Number:
Jinxiao ZHANG, Chenglong LI, Xinyan GAO, Ming ZHANG. 3D human pose estimation model based on temporal-spatial feature pyramid network and multi-hypothesis interaction mechanism[J]. Journal of Computer Applications, 2026, 46(6): 1965-1972.
张金萧, 李成龙, 高新燕, 张铭. 基于时空特征金字塔网络与多假设交互机制的三维人体姿态估计模型[J]. 《计算机应用》唯一官方网站, 2026, 46(6): 1965-1972.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025060763
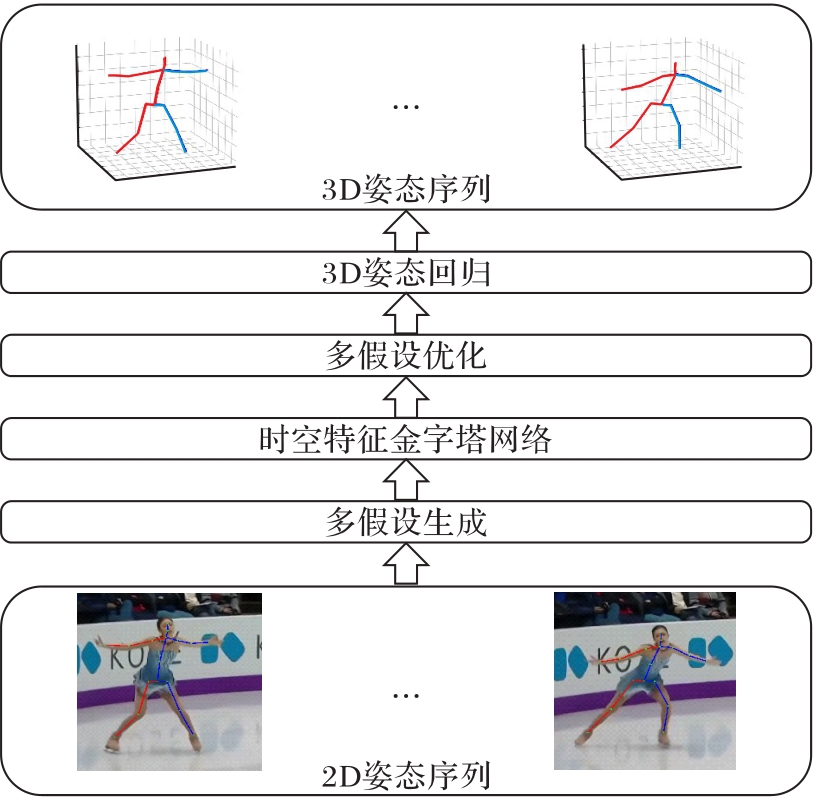
Fig. 1 Overall architecture of TSP-FPN-MHFormer
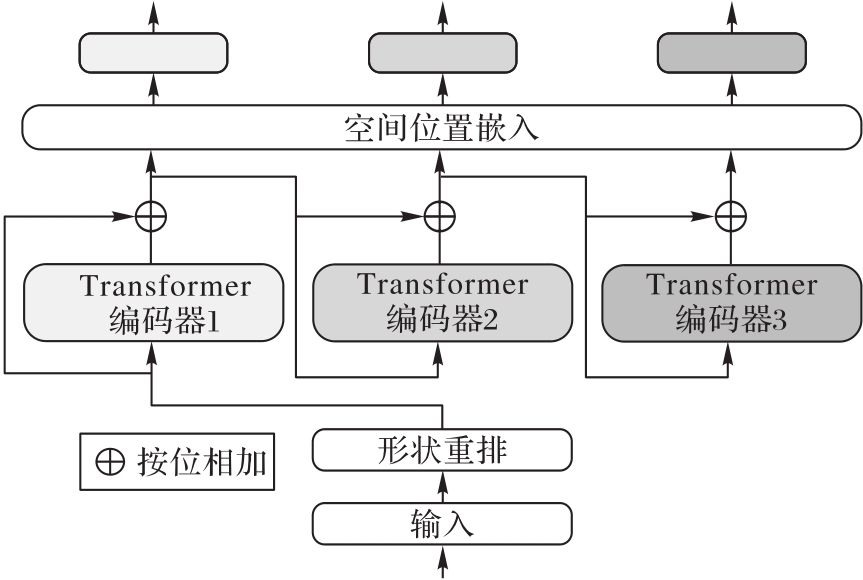
Fig. 2 Structure of multi-hypothesis generation module
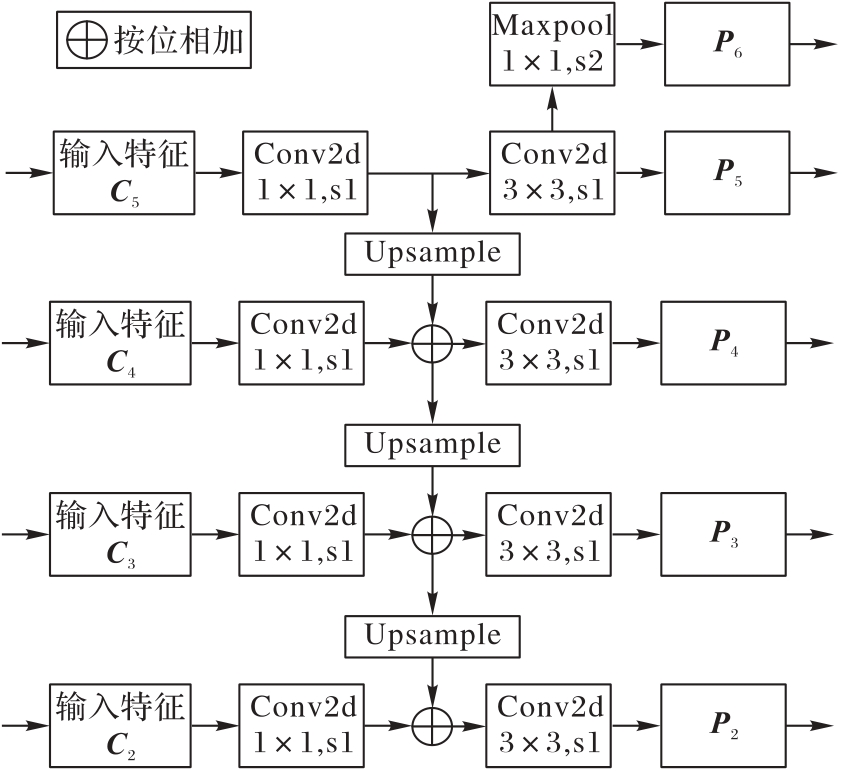
Fig. 3 Structure of FPN
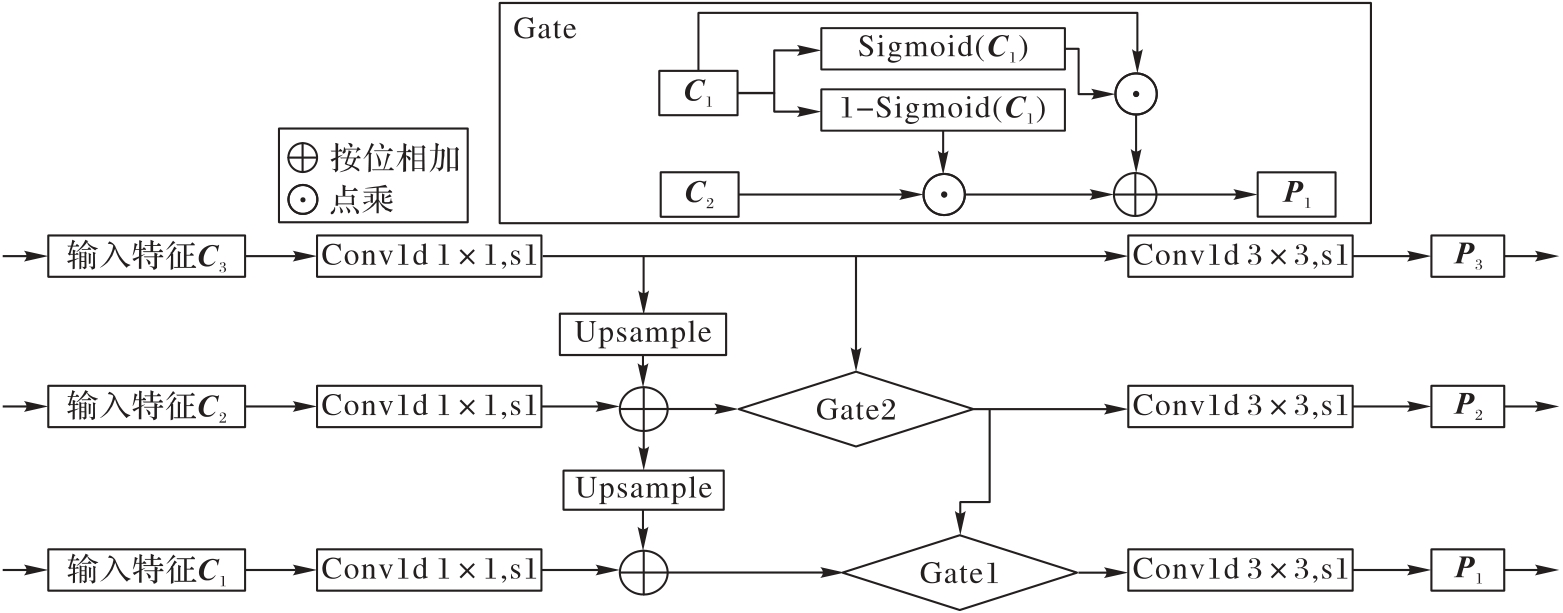
Fig. 4 Structure of TSP-FPN
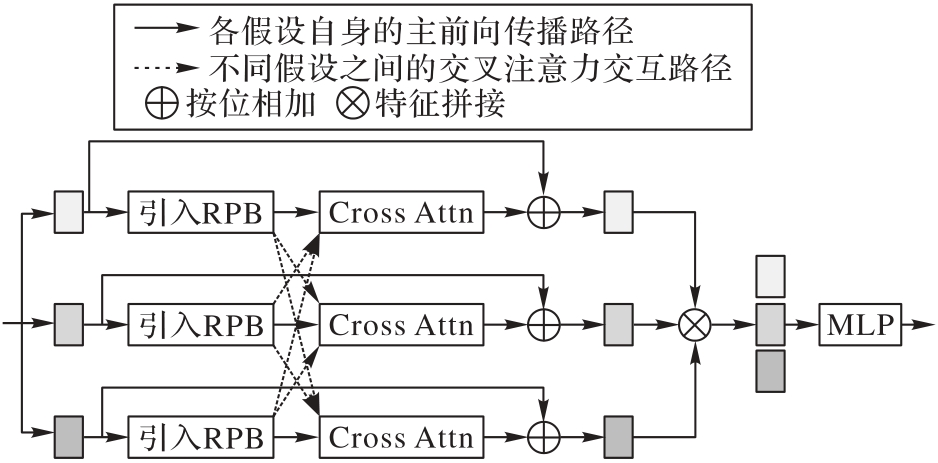
Fig. 5 Structure of multi-hypothesis optimization module
| 评价指标 | 模型 | Dir. | Disc. | Eat | Gre. | Phon. | Phot. | Pose | Pur. | Sit | SitD. | Smo. | Wait | W.D. | Walk | W.T. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MPJPE | 文献[ | 50.1 | 54.3 | 57.0 | 57.1 | 66.6 | 73.3 | 53.4 | 55.7 | 72.8 | 88.6 | 60.3 | 57.7 | 62.7 | 47.5 | 50.6 | 60.4 |
| 文献[ | 45.2 | 49.9 | 47.5 | 50.9 | 54.9 | 66.1 | 48.5 | 46.3 | 59.7 | 71.5 | 51.4 | 48.6 | 53.9 | 39.9 | 44.1 | 51.9 | |
| 文献[ | 45.4 | 49.2 | 45.7 | 49.4 | 50.4 | 58.2 | 47.9 | 46.0 | 57.5 | 63.0 | 49.7 | 46.6 | 52.2 | 38.9 | 40.8 | 49.4 | |
| 文献[ | 44.6 | 47.4 | 45.6 | 48.8 | 50.8 | 59.0 | 47.2 | 43.9 | 57.9 | 61.9 | 49.7 | 46.6 | 51.3 | 37.1 | 39.4 | 48.8 | |
| 文献[ | 45.2 | 46.7 | 43.3 | 45.6 | 48.1 | 55.1 | 44.6 | 44.3 | 57.3 | 65.8 | 47.1 | 44.0 | 49.0 | 32.8 | 33.9 | 46.8 | |
| 文献[ | 41.3 | 43.9 | 44.0 | 42.2 | 48.0 | 57.1 | 42.2 | 43.2 | 57.3 | 61.3 | 47.0 | 43.5 | 47.0 | 32.6 | 31.8 | 45.6 | |
| 文献[ | 41.8 | 44.8 | 41.1 | 44.9 | 47.4 | 54.1 | 43.4 | 42.2 | 56.2 | 63.6 | 45.3 | 43.5 | 45.3 | 31.3 | 32.2 | 45.1 | |
| 文献[ | 41.5 | 44.8 | 42.5 | 46.5 | 42.1 | 42.0 | 53.3 | 60.7 | 45.5 | 43.3 | 46.1 | 31.8 | 32.2 | 44.3 | |||
| 文献[ | 41.4 | 43.2 | 40.1 | 42.9 | 46.6 | 51.9 | 41.7 | 42.3 | 53.9 | 60.2 | 45.4 | 41.7 | 46.0 | 31.5 | 32.7 | 44.1 | |
| 文献[ | 41.7 | 38.1 | 44.2 | 52.5 | 41.3 | 42.6 | 52.7 | 56.8 | 45.3 | 41.5 | 42.9 | 28.8 | 29.6 | ||||
| 文献[ | 40.0 | 44.2 | 39.9 | 43.4 | 46.5 | 52.2 | 42.3 | 55.8 | 59.5 | 45.0 | 42.1 | 45.1 | 29.5 | 43.8 | |||
| 文献[ | 43.1 | 40.1 | 40.9 | 44.9 | 51.2 | 41.3 | 53.5 | 60.3 | 43.7 | 43.8 | 29.8 | 30.6 | 43.0 | ||||
| 本文模型(†) | 38.4 | 41.9 | 39.4 | 51.7 | 40.1 | 40.4 | 40.2 | 30.6 | 42.3 | ||||||||
| P-MPJPE | 文献[ | 38.2 | 41.7 | 43.7 | 44.9 | 48.5 | 55.3 | 40.2 | 38.2 | 54.5 | 64.4 | 47.2 | 44.3 | 47.3 | 36.7 | 41.7 | 45.7 |
| 文献[ | 33.9 | 37.2 | 36.8 | 38.1 | 38.7 | 43.5 | 37.8 | 35.0 | 47.2 | 53.8 | 40.7 | 38.3 | 41.8 | 30.1 | 31.4 | 39.0 | |
| 文献[ | 35.7 | 37.8 | 36.9 | 40.7 | 39.6 | 45.2 | 37.4 | 34.5 | 46.9 | 50.1 | 40.5 | 36.1 | 41.0 | 29.6 | 33.2 | 39.0 | |
| 文献[ | 34.1 | 36.1 | 34.4 | 37.2 | 36.4 | 42.2 | 34.4 | 33.6 | 45.0 | 52.5 | 37.4 | 33.8 | 37.8 | 25.6 | 27.3 | 36.5 | |
| 文献[ | 31.0 | 34.7 | 34.4 | 36.2 | 43.9 | 31.6 | 33.5 | 42.3 | 49.0 | 37.1 | 33.0 | 39.1 | 26.9 | 31.9 | 36.2 | ||
| 文献[ | 32.3 | 35.2 | 33.3 | 35.8 | 35.9 | 41.5 | 33.2 | 32.7 | 44.6 | 50.9 | 37.0 | 37.0 | 25.2 | 27.2 | 35.6 | ||
| 文献[ | 32.9 | 35.2 | 35.6 | 34.4 | 36.4 | 42.7 | 31.2 | 32.5 | 45.6 | 50.2 | 37.3 | 32.8 | 36.3 | 26.0 | 23.9 | 35.5 | |
| 文献[ | 32.6 | 35.1 | 35.4 | 36.3 | 40.4 | 32.4 | 32.3 | 49.0 | 36.8 | 36.0 | 24.9 | 26.5 | 35.0 | ||||
| 文献[ | 32.5 | 32.6 | 34.6 | 35.3 | 39.5 | 32.1 | 32.0 | 42.8 | 34.8 | 35.3 | 24.5 | 26.0 | 34.6 | ||||
| 文献[ | 32.4 | 35.3 | 32.6 | 34.2 | 42.1 | 32.1 | 45.5 | 49.5 | 36.1 | 35.6 | 34.8 | ||||||
| 文献[ | 31.5 | 34.9 | 35.3 | 32.0 | 32.2 | 43.5 | 48.7 | 36.4 | 32.6 | 34.3 | 23.9 | 25.1 | |||||
| 本文模型(†) | 34.4 | 33.0 | 32.4 | 34.6 | 39.9 | 31.3 | 43.9 | 48.3 | 32.1 | 23.3 | 24.8 | 34.0 |
Tab. 1 Comparison of experimental results of MPJPE and P-MPJPE of different models on Human 3.6M dataset
| 评价指标 | 模型 | Dir. | Disc. | Eat | Gre. | Phon. | Phot. | Pose | Pur. | Sit | SitD. | Smo. | Wait | W.D. | Walk | W.T. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MPJPE | 文献[ | 50.1 | 54.3 | 57.0 | 57.1 | 66.6 | 73.3 | 53.4 | 55.7 | 72.8 | 88.6 | 60.3 | 57.7 | 62.7 | 47.5 | 50.6 | 60.4 |
| 文献[ | 45.2 | 49.9 | 47.5 | 50.9 | 54.9 | 66.1 | 48.5 | 46.3 | 59.7 | 71.5 | 51.4 | 48.6 | 53.9 | 39.9 | 44.1 | 51.9 | |
| 文献[ | 45.4 | 49.2 | 45.7 | 49.4 | 50.4 | 58.2 | 47.9 | 46.0 | 57.5 | 63.0 | 49.7 | 46.6 | 52.2 | 38.9 | 40.8 | 49.4 | |
| 文献[ | 44.6 | 47.4 | 45.6 | 48.8 | 50.8 | 59.0 | 47.2 | 43.9 | 57.9 | 61.9 | 49.7 | 46.6 | 51.3 | 37.1 | 39.4 | 48.8 | |
| 文献[ | 45.2 | 46.7 | 43.3 | 45.6 | 48.1 | 55.1 | 44.6 | 44.3 | 57.3 | 65.8 | 47.1 | 44.0 | 49.0 | 32.8 | 33.9 | 46.8 | |
| 文献[ | 41.3 | 43.9 | 44.0 | 42.2 | 48.0 | 57.1 | 42.2 | 43.2 | 57.3 | 61.3 | 47.0 | 43.5 | 47.0 | 32.6 | 31.8 | 45.6 | |
| 文献[ | 41.8 | 44.8 | 41.1 | 44.9 | 47.4 | 54.1 | 43.4 | 42.2 | 56.2 | 63.6 | 45.3 | 43.5 | 45.3 | 31.3 | 32.2 | 45.1 | |
| 文献[ | 41.5 | 44.8 | 42.5 | 46.5 | 42.1 | 42.0 | 53.3 | 60.7 | 45.5 | 43.3 | 46.1 | 31.8 | 32.2 | 44.3 | |||
| 文献[ | 41.4 | 43.2 | 40.1 | 42.9 | 46.6 | 51.9 | 41.7 | 42.3 | 53.9 | 60.2 | 45.4 | 41.7 | 46.0 | 31.5 | 32.7 | 44.1 | |
| 文献[ | 41.7 | 38.1 | 44.2 | 52.5 | 41.3 | 42.6 | 52.7 | 56.8 | 45.3 | 41.5 | 42.9 | 28.8 | 29.6 | ||||
| 文献[ | 40.0 | 44.2 | 39.9 | 43.4 | 46.5 | 52.2 | 42.3 | 55.8 | 59.5 | 45.0 | 42.1 | 45.1 | 29.5 | 43.8 | |||
| 文献[ | 43.1 | 40.1 | 40.9 | 44.9 | 51.2 | 41.3 | 53.5 | 60.3 | 43.7 | 43.8 | 29.8 | 30.6 | 43.0 | ||||
| 本文模型(†) | 38.4 | 41.9 | 39.4 | 51.7 | 40.1 | 40.4 | 40.2 | 30.6 | 42.3 | ||||||||
| P-MPJPE | 文献[ | 38.2 | 41.7 | 43.7 | 44.9 | 48.5 | 55.3 | 40.2 | 38.2 | 54.5 | 64.4 | 47.2 | 44.3 | 47.3 | 36.7 | 41.7 | 45.7 |
| 文献[ | 33.9 | 37.2 | 36.8 | 38.1 | 38.7 | 43.5 | 37.8 | 35.0 | 47.2 | 53.8 | 40.7 | 38.3 | 41.8 | 30.1 | 31.4 | 39.0 | |
| 文献[ | 35.7 | 37.8 | 36.9 | 40.7 | 39.6 | 45.2 | 37.4 | 34.5 | 46.9 | 50.1 | 40.5 | 36.1 | 41.0 | 29.6 | 33.2 | 39.0 | |
| 文献[ | 34.1 | 36.1 | 34.4 | 37.2 | 36.4 | 42.2 | 34.4 | 33.6 | 45.0 | 52.5 | 37.4 | 33.8 | 37.8 | 25.6 | 27.3 | 36.5 | |
| 文献[ | 31.0 | 34.7 | 34.4 | 36.2 | 43.9 | 31.6 | 33.5 | 42.3 | 49.0 | 37.1 | 33.0 | 39.1 | 26.9 | 31.9 | 36.2 | ||
| 文献[ | 32.3 | 35.2 | 33.3 | 35.8 | 35.9 | 41.5 | 33.2 | 32.7 | 44.6 | 50.9 | 37.0 | 37.0 | 25.2 | 27.2 | 35.6 | ||
| 文献[ | 32.9 | 35.2 | 35.6 | 34.4 | 36.4 | 42.7 | 31.2 | 32.5 | 45.6 | 50.2 | 37.3 | 32.8 | 36.3 | 26.0 | 23.9 | 35.5 | |
| 文献[ | 32.6 | 35.1 | 35.4 | 36.3 | 40.4 | 32.4 | 32.3 | 49.0 | 36.8 | 36.0 | 24.9 | 26.5 | 35.0 | ||||
| 文献[ | 32.5 | 32.6 | 34.6 | 35.3 | 39.5 | 32.1 | 32.0 | 42.8 | 34.8 | 35.3 | 24.5 | 26.0 | 34.6 | ||||
| 文献[ | 32.4 | 35.3 | 32.6 | 34.2 | 42.1 | 32.1 | 45.5 | 49.5 | 36.1 | 35.6 | 34.8 | ||||||
| 文献[ | 31.5 | 34.9 | 35.3 | 32.0 | 32.2 | 43.5 | 48.7 | 36.4 | 32.6 | 34.3 | 23.9 | 25.1 | |||||
| 本文模型(†) | 34.4 | 33.0 | 32.4 | 34.6 | 39.9 | 31.3 | 43.9 | 48.3 | 32.1 | 23.3 | 24.8 | 34.0 |
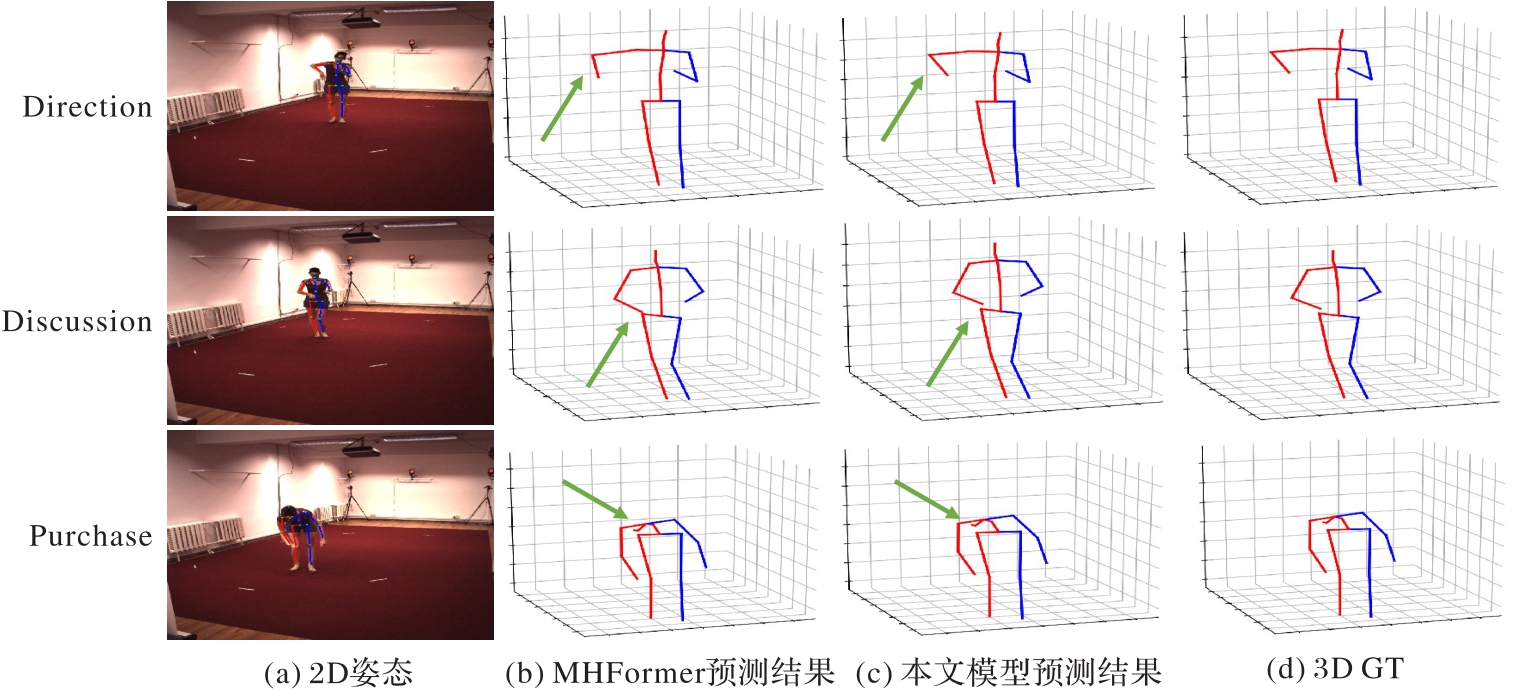
Fig. 6 Qualitative comparison on Human3.6M dataset
| 模型 | MPJPE均值 |
|---|---|
| R-TSP-FPN-MHFormer | 42.9 |
| T-TSP-FPN-MHFormer | 43.4 |
| TSP-FPN-MHFormer | 42.3 |
Tab. 2 Ablation study results
| 模型 | MPJPE均值 |
|---|---|
| R-TSP-FPN-MHFormer | 42.9 |
| T-TSP-FPN-MHFormer | 43.4 |
| TSP-FPN-MHFormer | 42.3 |
| [1] | SUDHAKARAN S, ESCALERA S, LANZ O. Gate-shift networks for video action recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1099-1108. |
| [2] | WANG P, LI W, GAO Z, et al. Depth pooling based large-scale 3-D action recognition with convolutional neural networks[J]. IEEE Transactions on Multimedia, 2018, 20(5): 1051-1061. |
| [3] | SRIDHAR S, FEIT A M, THEOBALT C, et al. Investigating the dexterity of multi-finger input for mid-air text entry[C]// Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. New York: ACM, 2015: 3643-3652. |
| [4] | LIU Q, LIU Z, XIONG B, et al. Deep reinforcement learning-based safe interaction for industrial human-robot collaboration using intrinsic reward function[J]. Advanced Engineering Informatics, 2021, 49: No.101360. |
| [5] | CHESSA M, MAIELLO G, KLEIN L K, et al. Grasping objects in immersive virtual reality[C]// Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces. Piscataway: IEEE, 2019: 1749-1754. |
| [6] | CHEN C H, RAMANAN D. 3D human pose estimation = 2D pose estimation + matching[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5759-5767. |
| [7] | XU T, TAKANO W. Graph stacked hourglass networks for 3D human pose estimation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 16100-16109. |
| [8] | 马金林,崔琦磊,马自萍,等. 预加权调制密集图卷积网络三维人体姿态估计[J]. 计算机科学与探索, 2024, 18(4): 963-977. |
| MA J L, CUI Q L, MA Z P, et al. Pre-weighted modulated dense graph convolutional networks for 3D human pose estimation[J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(4): 963-977. | |
| [9] | ZOU Z, TANG W. Modulated graph convolutional network for 3D human pose estimation[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 11457-11467. |
| [10] | LI W, LIU H, DING R, et al. Exploiting temporal contexts with Strided Transformer for 3D human pose estimation[J]. IEEE Transactions on Multimedia, 2023, 25: 1282-1293. |
| [11] | CHEN H, HE J Y, XIANG W, et al. HDFormer: high-order directed Transformer for 3D human pose estimation[C]// Proceedings of the 32nd International Joint Conference on Artificial Intelligence. California: ijcai.org, 2023: 581-589. |
| [12] | HU W, ZHANG C, ZHAN F, et al. Conditional directed graph convolution for 3D human pose estimation[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 602-611. |
| [13] | ZHENG C, ZHU S, MENDIETA M, et al. 3D human pose estimation with spatial and temporal Transformers[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 11636-11645. |
| [14] | LI W, LIU H, TANG H, et al. MHFormer: multi-hypothesis Transformer for 3D human pose estimation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 13137-13146. |
| [15] | SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 464-468 . |
| [16] | TEKIN B, KATIRCIOGLU I, SALZMANN M, et al. Structured prediction of 3D human pose with deep neural networks[C]// Proceedings of the 2016 British Machine Vision Conference. Durham: BMVA Press, 2016: No.130. |
| [17] | LUVIZON D C, PICARD D, TABIA H. 2D/3D pose estimation and action recognition using multitask deep learning[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5137-5146. |
| [18] | MARTINEZ J, HOSSAIN R, ROMERO J, et al. A simple yet effective baseline for 3D human pose estimation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2659-2668. |
| [19] | PAVLLO D, FEICHTENHOFER C, GRANGIER D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7745-7754. |
| [20] | CHEN T, FANG C, SHEN X, et al. Anatomy-aware 3D human pose estimation with bone-based pose decomposition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(1): 198-209. |
| [21] | CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7103-7112. |
| [22] | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. |
| [23] | IONESCU C, PAPAVA D, OLARU V, et al. Human3.6M: large scale datasets and predictive methods for 3D human sensing in natural environments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1325-1339. |
| [24] | FANG H S, XU Y, WANG W, et al. Learning pose grammar to encode human body configuration for 3D pose estimation[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 6821-6828. |
| [25] | CAI Y, GE L, LIU J, et al. Exploiting spatial temporal relationships for 3D pose estimation via graph convolutional networks[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2272-2281. |
| [26] | ZENG A, SUN X, YANG L, et al. Learning skeletal graph neural networks for hard 3D pose estimation[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 11416-11425. |
| [27] | XU J, YU Z, NI B, et al. Deep kinematics analysis for monocular 3D human pose estimation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 896-905. |
| [28] | YU B X B, ZHANG Z, LIU Y, et al. GLA-GCN: global local adaptive graph convolutional network for 3D human pose estimation from monocular video[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 8784-8795. |
| [29] | LI W, LIU M, LIU H, et al. GraphMLP: a graph MLP-like architecture for 3D human pose estimation[J]. Pattern Recognition, 2025, 158: No.110925. |
| [30] | WANG J, YAN S, XIONG Y, et al. Motion guided 3D pose estimation from videos[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12358. Cham: Springer, 2020: 764-780. |
| [31] | LIU R, SHEN J, WANG H, et al. Attention mechanism exploits temporal contexts: real time 3D human pose reconstruction[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5063-5072. |
| [32] | ZHANG Y, LU Y, LIU B, et al. EvoPose: a recursive Transformer for 3D human pose estimation with kinematic structure priors[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [1] | Yunping HE, Leichun WANG, Ruirui SONG, Xiangfeng LU, Jinxiang WEI, Xiaomeng LIU. Dual-channel multimodal sentiment analysis model based on contrast invariance and reinforcement specificity [J]. Journal of Computer Applications, 2026, 46(6): 1767-1775. |
| [2] | Liwan YAO, Hailong LIU, Zhangfan ZENG. Frequency-domain driven and diffusion-based fusion for sonar image enhancement algorithm [J]. Journal of Computer Applications, 2026, 46(6): 1947-1955. |
| [3] | Yasong ZHANG, Bihui CONG, Shuang XU. Graph neural network node classification model incorporating clustering coefficients [J]. Journal of Computer Applications, 2026, 46(6): 1855-1862. |
| [4] | Ying JING, Ran LI, Zhuo JIANG, Ziyang FU, Jingyi DU, Qi LIU, Jihang LIU. SAM Meibomian gland unified dense segmentation method with introduction of automatic prompt encoder [J]. Journal of Computer Applications, 2026, 46(5): 1667-1676. |
| [5] | Baoyuan ZHENG, Chaobo HE. Graph convolutional network enhanced by graph diffusion and dual-view feature learning [J]. Journal of Computer Applications, 2026, 46(5): 1370-1377. |
| [6] | Ruirui SONG, Leichun WANG, Yunping HE, Jinxiang WEI, Xiangfeng LU, Xiaomeng LIU. Long time series prediction based on hybrid self-attention and differentiated normalization [J]. Journal of Computer Applications, 2026, 46(5): 1499-1506. |
| [7] | Hongrui ZHANG, Weiming FENG, Luxia YANG, Yongjie MA. CSAF-YOLO: improved YOLO11 algorithm for underwater small object detection [J]. Journal of Computer Applications, 2026, 46(5): 1578-1585. |
| [8] | Qianfei WANG, Yang LI, Deyu LI, Suge WANG. Dual-channel feature fusion representation method for short-text clustering based on large language model [J]. Journal of Computer Applications, 2026, 46(5): 1441-1449. |
| [9] | Jing HU, Shikun CHEN, Fang WANG, Rui ZHANG, Yong WANG. Ore image segmentation with linear deformable convolution and dual-domain synergistic dynamic attention [J]. Journal of Computer Applications, 2026, 46(5): 1692-1702. |
| [10] | Huijie GUO, Tianfeng DOU, Zhenlin ZHANG, Kaiyuan QI, Dong WU, Zhijian QU, Zhao LI, Chongguang REN. Time-interdependency-aware dynamic Bayesian network for traffic prediction [J]. Journal of Computer Applications, 2026, 46(5): 1507-1517. |
| [11] | Wen PENG, Bokai ZHANG, Jinwei LIN. Chromosome cascaded classification framework integrating image texture enhancement and super-resolution [J]. Journal of Computer Applications, 2026, 46(5): 1647-1657. |
| [12] | Xumeng DOU, Bin XIE, Zhaohui ZHANG, Zhengang ZHAO, Hanyu DUAN, Aolei GUO. Drug-target interaction prediction based on structure-network collaborative features and grid-attention enhanced Kolmogorov-Arnold network [J]. Journal of Computer Applications, 2026, 46(4): 1344-1353. |
| [13] | Huanxian LIU, Hongtao WANG, Xian’ao WANG, Hongmei WANG, Weifeng XU. Multimodal fact verification with cross-modal semantic association [J]. Journal of Computer Applications, 2026, 46(4): 1069-1076. |
| [14] | Xiang BAI, Juchuan LI, Huimin WANG, Chao JING, Jian NIU, Xingzhong ZHANG, Yongqiang CHENG. Power image retrieval method based on improved Swin Transformer [J]. Journal of Computer Applications, 2026, 46(4): 1334-1343. |
| [15] | Chuandong QIN, Zhiqiang SUO. Skin cancer classification integrating improved ResNet50 with ensemble classifier [J]. Journal of Computer Applications, 2026, 46(4): 1354-1362. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||