


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (1): 308-317.DOI: 10.11772/j.issn.1001-9081.2023121877
• Multimedia computing and computer simulation • Previous Articles Next Articles
Jialin ZHANG1, Qinghua REN1, Qirong MAO1,2( )
)
Received:2024-01-06
Revised:2024-02-27
Accepted:2024-03-04
Online:2024-04-01
Published:2025-01-10
Contact:
Qirong MAO
About author:ZHANG Jialin, born in 1998, M. S. candidate. His research interests include synthetic speech detection.Supported by:
张嘉琳1, 任庆桦1, 毛启容1,2()
通讯作者:
毛启容
作者简介:张嘉琳(1998—),男,山东莱州人,硕士研究生,主要研究方向:合成语音检测;基金资助:CLC Number:
Jialin ZHANG, Qinghua REN, Qirong MAO. Speaker verification system utilizing global-local feature dependency for anti-spoofing[J]. Journal of Computer Applications, 2025, 45(1): 308-317.
张嘉琳, 任庆桦, 毛启容. 利用全局-局部特征依赖的反欺骗说话人验证系统[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 308-317.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023121877

Fig. 1 Overall flowchart
| 符号 | 含义 |
|---|---|
| 输入的语音信号 | |
| 输入语音信号的标签 | |
| 滤波器组的滤波操作 | |
| 滤波分支数 | |
| 频带增强过程中的混合语音 | |
| 频带增强过程中的混合权重 | |
| 频带增强后的语音 | |
| 特征的批量值和通道数 | |
| 信道的权重 | |
| 频率维度的权重 | |
| 时间维度的权重 | |
| 表示Sigmoid操作 | |
| 表示两次全连接层的计算 | |
| 表示特征的时间维数和频率维数 | |
| ReLU函数的计算 | |
| 频带增强的次数 | |
| 欺骗语音检测模型 | |
| 调节得分占比的权重因子 | |
| 平衡分类损失和一致性损失的调节因子 |
Tab. 1 Symbols and their meanings
| 符号 | 含义 |
|---|---|
| 输入的语音信号 | |
| 输入语音信号的标签 | |
| 滤波器组的滤波操作 | |
| 滤波分支数 | |
| 频带增强过程中的混合语音 | |
| 频带增强过程中的混合权重 | |
| 频带增强后的语音 | |
| 特征的批量值和通道数 | |
| 信道的权重 | |
| 频率维度的权重 | |
| 时间维度的权重 | |
| 表示Sigmoid操作 | |
| 表示两次全连接层的计算 | |
| 表示特征的时间维数和频率维数 | |
| ReLU函数的计算 | |
| 频带增强的次数 | |
| 欺骗语音检测模型 | |
| 调节得分占比的权重因子 | |
| 平衡分类损失和一致性损失的调节因子 |
| 模块名称 | 模块内容 | 输出 |
|---|---|---|
| Sinc卷积层 | 一维卷积+BN+SeLU | (1,23,32 090) |
| 残差块1 | BN+多维全局注意力+ 二维卷积+SeLU+BN+ 二维卷积 | (32,23,10 696) |
| 残差模块2~6 | BN+二维卷积+ SeLU+BN+二维卷积 | (64,23,44) |
| 时频图注意力模块 | 图注意力层+图池化+ 异构图注意力层 | (20,32) |
| Dropout | (1,32) | |
| 全连接层 | (1) |
Tab. 2 MA-AASIST network structure
| 模块名称 | 模块内容 | 输出 |
|---|---|---|
| Sinc卷积层 | 一维卷积+BN+SeLU | (1,23,32 090) |
| 残差块1 | BN+多维全局注意力+ 二维卷积+SeLU+BN+ 二维卷积 | (32,23,10 696) |
| 残差模块2~6 | BN+二维卷积+ SeLU+BN+二维卷积 | (64,23,44) |
| 时频图注意力模块 | 图注意力层+图池化+ 异构图注意力层 | (20,32) |
| Dropout | (1,32) | |
| 全连接层 | (1) |
| 模块序号 | 模块名称 | 输出 |
|---|---|---|
| 1 | 一维卷积+BN+ReLU | 128 |
| 2 | SPD-TDNN | 192 |
| SPD-TDNN | 256 | |
| SPD-TDNN | 320 | |
| SPD-TDNN | 384 | |
| SPD-TDNN | 448 | |
| SPD-TDNN | 512 | |
| 一维卷积+BN+ReLU | 256 | |
| SPD-TDNN | 320 | |
| SPD-TDNN | 384 | |
| SPD-TDNN | 448 | |
| SPD-TDNN | 512 | |
| SPD-TDNN | 576 | |
| SPD-TDNN | 640 | |
| SPD-TDNN | 704 | |
| SPD-TDNN | 768 | |
| SPD-TDNN | 832 | |
| SPD-TDNN | 896 | |
| SPD-TDNN | 960 | |
| SPD-TDNN | 1 024 | |
| 一维卷积+BN+ReLU | 512 | |
| 3 | 统计池化+BN | 1 024 |
| 4 | 全连接层+BN | 128 |
Tab. 3 Convolutional channel numbers of layers in SPD-TDNN
| 模块序号 | 模块名称 | 输出 |
|---|---|---|
| 1 | 一维卷积+BN+ReLU | 128 |
| 2 | SPD-TDNN | 192 |
| SPD-TDNN | 256 | |
| SPD-TDNN | 320 | |
| SPD-TDNN | 384 | |
| SPD-TDNN | 448 | |
| SPD-TDNN | 512 | |
| 一维卷积+BN+ReLU | 256 | |
| SPD-TDNN | 320 | |
| SPD-TDNN | 384 | |
| SPD-TDNN | 448 | |
| SPD-TDNN | 512 | |
| SPD-TDNN | 576 | |
| SPD-TDNN | 640 | |
| SPD-TDNN | 704 | |
| SPD-TDNN | 768 | |
| SPD-TDNN | 832 | |
| SPD-TDNN | 896 | |
| SPD-TDNN | 960 | |
| SPD-TDNN | 1 024 | |
| 一维卷积+BN+ReLU | 512 | |
| 3 | 统计池化+BN | 1 024 |
| 4 | 全连接层+BN | 128 |
| 数据集 | 训练集 | 验证集 | 测试集 | |||
|---|---|---|---|---|---|---|
| 真实 | 欺骗 | 真实 | 欺骗 | 真实 | 欺骗 | |
| ASVspoof2019 | 2 580 | 22 800 | 2 548 | 22 296 | 7 355 | 63 882 |
| ASVspoof2021 | 2 580 | 22 800 | 2 548 | 22 296 | 14 816 | 133 360 |
Tab. 4 ASVspoof dataset used in experiments
| 数据集 | 训练集 | 验证集 | 测试集 | |||
|---|---|---|---|---|---|---|
| 真实 | 欺骗 | 真实 | 欺骗 | 真实 | 欺骗 | |
| ASVspoof2019 | 2 580 | 22 800 | 2 548 | 22 296 | 7 355 | 63 882 |
| ASVspoof2021 | 2 580 | 22 800 | 2 548 | 22 296 | 14 816 | 133 360 |
| EER/% | EER/% | ||
|---|---|---|---|
| 100 | 0.53 | 10-3 | 0.39 |
| 10-1 | 0.36 | 0 | 0.55 |
| 10-2 | 0.43 |
Tab. 5 Ablation experimental results about λ on ASVspoof2019 dataset
| EER/% | EER/% | ||
|---|---|---|---|
| 100 | 0.53 | 10-3 | 0.39 |
| 10-1 | 0.36 | 0 | 0.55 |
| 10-2 | 0.43 |
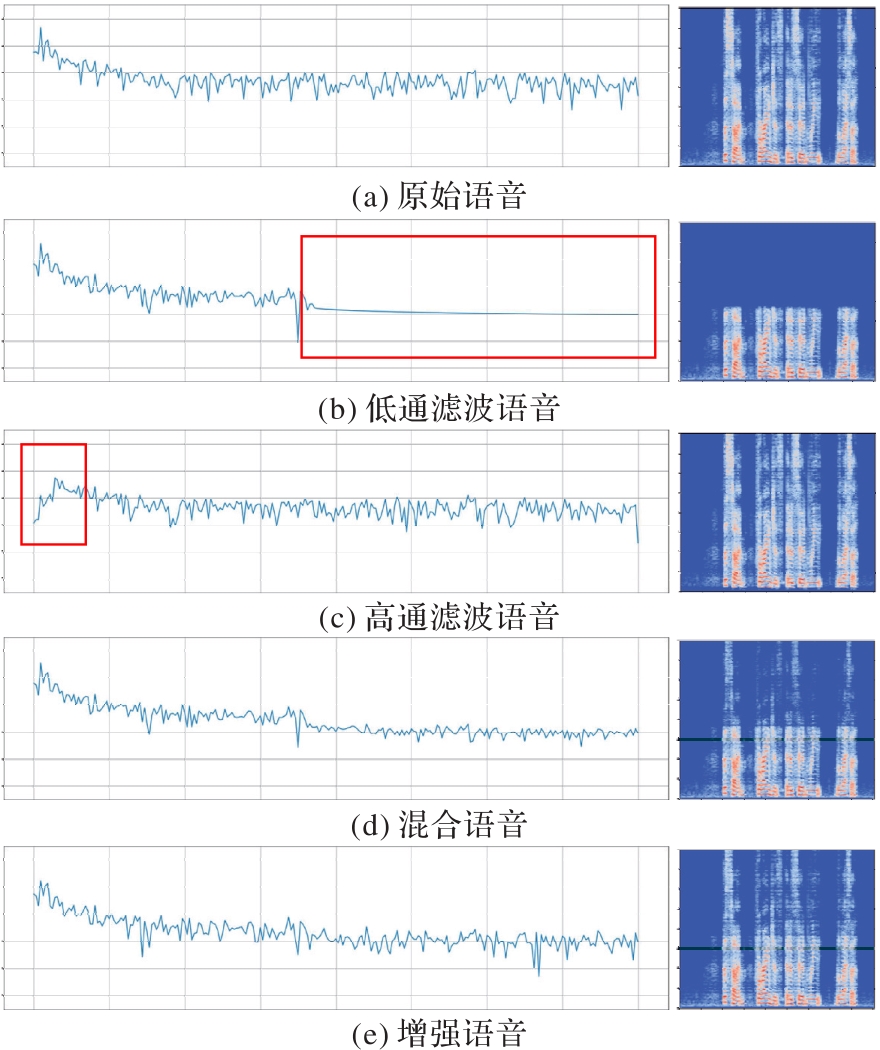
Fig. 2 Frequency map and spectrogram of speech in frequency enhancement process (low-pass and high-pass combinations)
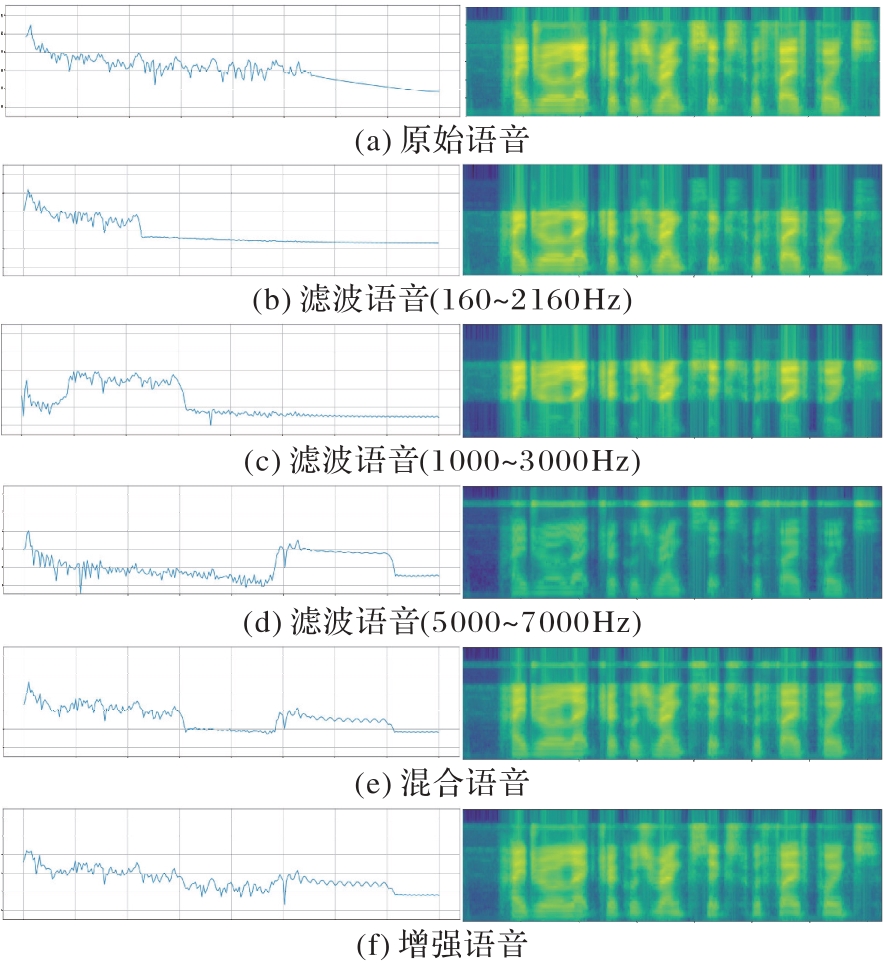
Fig. 3 Frequency map and FBank feature map of speech in frequency enhancement process (band-pass combination)
| 系统 | 增强手段 | 损失函数 | ASVspoof2019 | ASVspoof2021 | |||||
|---|---|---|---|---|---|---|---|---|---|
| 无 | 仅滤波 (带通) | 滤波后混合 (带通) | 完整频带增强 (带通/低通高通) | 一致性损失 | EER/% | t-DCF | EER/% | t-DCF | |
| AASIST[ | ✓ | 1.04 | 0.031 7 | 6.24 | 0.342 8 | ||||
| ✓ | 0.84 | 0.023 5 | 4.25 | 0.276 8 | |||||
| ✓ | 0.84 | 0.026 0 | 3.74 | 0.268 4 | |||||
| ✓(带通) | 0.57 | 0.019 3 | 4.25 | 0.291 3 | |||||
| AASIST | ✓(带通) | ✓ | 0.38 | 0.012 0 | 3.29 | 0.270 7 | |||
| MA-AASIST | ✓(带通) | ✓ | 0.36 | 0.011 4 | 4.63 | 0.302 6 | |||
| AASIST | ✓(低通高通) | ✓ | 0.51 | 0.016 6 | 3.07 | 0.264 6 | |||
| MA-AASIST | ✓(低通高通) | ✓ | 0.49 | 0.014 9 | 2.68 | 0.251 4 | |||
Tab. 6 Results of ablation experiments
| 系统 | 增强手段 | 损失函数 | ASVspoof2019 | ASVspoof2021 | |||||
|---|---|---|---|---|---|---|---|---|---|
| 无 | 仅滤波 (带通) | 滤波后混合 (带通) | 完整频带增强 (带通/低通高通) | 一致性损失 | EER/% | t-DCF | EER/% | t-DCF | |
| AASIST[ | ✓ | 1.04 | 0.031 7 | 6.24 | 0.342 8 | ||||
| ✓ | 0.84 | 0.023 5 | 4.25 | 0.276 8 | |||||
| ✓ | 0.84 | 0.026 0 | 3.74 | 0.268 4 | |||||
| ✓(带通) | 0.57 | 0.019 3 | 4.25 | 0.291 3 | |||||
| AASIST | ✓(带通) | ✓ | 0.38 | 0.012 0 | 3.29 | 0.270 7 | |||
| MA-AASIST | ✓(带通) | ✓ | 0.36 | 0.011 4 | 4.63 | 0.302 6 | |||
| AASIST | ✓(低通高通) | ✓ | 0.51 | 0.016 6 | 3.07 | 0.264 6 | |||
| MA-AASIST | ✓(低通高通) | ✓ | 0.49 | 0.014 9 | 2.68 | 0.251 4 | |||
| EER/% | ||
|---|---|---|
| ASVspoof2019测试集 | ASVspoof2021测试集 | |
| 0 | 1.04 | 6.24 |
| 1 | 0.42 | 4.13 |
| 2 | 0.53 | 4.13 |
| 3 | 0.38 | 3.29 |
| 4 | 0.97 | 4.82 |
Tab. 7 Selection of filter branch number K
| EER/% | ||
|---|---|---|
| ASVspoof2019测试集 | ASVspoof2021测试集 | |
| 0 | 1.04 | 6.24 |
| 1 | 0.42 | 4.13 |
| 2 | 0.53 | 4.13 |
| 3 | 0.38 | 3.29 |
| 4 | 0.97 | 4.82 |
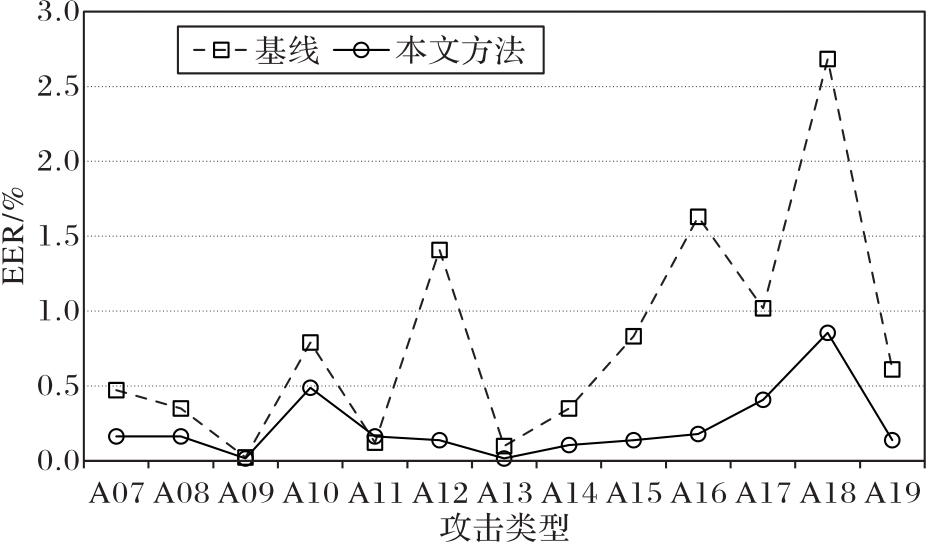
Fig. 4 Detection effects of models on various kinds of speech spoofing
| 系统 | ASVspoof2019 | ASVspoof2021 | ||
|---|---|---|---|---|
| EER/% | t-DCF | EER/% | t-DCF | |
| MA-AASIST(带通) | 0.36 | 0.011 4 | 4.63 | 0.302 6 |
| MA-AASIST(低通高通) | 0.49 | 0.014 9 | 2.68 | 0.251 4 |
| DFSincNet[ | 0.52 | 0.017 6 | 3.05 | 0.260 1 |
| GST+GCN[ | 0.58 | 0.016 6 | ||
| Rawformer[ | 0.59 | 0.018 4 | 4.53 | 0.308 8 |
| To-AASIST[ | 1.02 | |||
| To-RawNet[ | 3.58 | |||
| CNN+Transformer[ | 1.61 | 0.048 1 | ||
Tab. 8 Comparison of proposed spoofing detection system with current advanced models
| 系统 | ASVspoof2019 | ASVspoof2021 | ||
|---|---|---|---|---|
| EER/% | t-DCF | EER/% | t-DCF | |
| MA-AASIST(带通) | 0.36 | 0.011 4 | 4.63 | 0.302 6 |
| MA-AASIST(低通高通) | 0.49 | 0.014 9 | 2.68 | 0.251 4 |
| DFSincNet[ | 0.52 | 0.017 6 | 3.05 | 0.260 1 |
| GST+GCN[ | 0.58 | 0.016 6 | ||
| Rawformer[ | 0.59 | 0.018 4 | 4.53 | 0.308 8 |
| To-AASIST[ | 1.02 | |||
| To-RawNet[ | 3.58 | |||
| CNN+Transformer[ | 1.61 | 0.048 1 | ||
| 系统 | SASV_EER | SV_EER | SPF_EER |
|---|---|---|---|
| MA-AASIST | 25.14 | 49.49 | 0.29 |
| SPD-TDNN | 24.37 | 0.63 | 32.26 |
| MA-AASIST+SPD-TDNN | 0.64 | 0.87 | 0.28 |
| MA-AASIST+SPD-TDNN(std)+权重规整 | 0.54 | 0.74 | 0.19 |
| I_Aug[ | 0.73 | 1.10 | 0.42 |
| End-to-End SASV[ | 6.83 | 4.43 | 8.36 |
| SA-SASV[ | 4.86 | 8.06 | 0.50 |
| TDT-1[ | 4.78 | 6.24 | 1.73 |
| TAP-1024[ | 0.97 | 1.15 | 0.56 |
| CLIPS System[ | 1.36 | 1.75 | 0.76 |
Tab. 9 Score fusion results of speaker verification system for anti-spoofing
| 系统 | SASV_EER | SV_EER | SPF_EER |
|---|---|---|---|
| MA-AASIST | 25.14 | 49.49 | 0.29 |
| SPD-TDNN | 24.37 | 0.63 | 32.26 |
| MA-AASIST+SPD-TDNN | 0.64 | 0.87 | 0.28 |
| MA-AASIST+SPD-TDNN(std)+权重规整 | 0.54 | 0.74 | 0.19 |
| I_Aug[ | 0.73 | 1.10 | 0.42 |
| End-to-End SASV[ | 6.83 | 4.43 | 8.36 |
| SA-SASV[ | 4.86 | 8.06 | 0.50 |
| TDT-1[ | 4.78 | 6.24 | 1.73 |
| TAP-1024[ | 0.97 | 1.15 | 0.56 |
| CLIPS System[ | 1.36 | 1.75 | 0.76 |
| 1 | JUNG J W, TAK H, SHIM H J, et al. SASV 2022: the first spoofing-aware speaker verification challenge [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 2893-2897. |
| 2 | TA B T, NGUYEN T L, DANG D S, et al. A multi-task conformer for spoofing aware speaker verification [C]// Proceedings of the IEEE 9th International Conference on Communications and Electronics. Piscataway: IEEE, 2022: 306-310. |
| 3 | KANG W, ALAM M J, FATHAN A. End-to-end framework for spoof-aware speaker verification [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4362-4366. |
| 4 | HE K, WANG Z, FU Y, et al. Adaptively weighted multi-task deep network for person attribute classification [C]// Proceedings of the 25th ACM International Conference on Multimedia. New York: ACM, 2017: 1636-1644. |
| 5 | ZHANG L, LI Y, ZHAO H, et al. Backend ensemble for speaker verification and spoofing countermeasure [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4381-4385. |
| 6 | ZHANG P, HU P, ZHANG X. Norm-constrained score-level ensemble for spoofing aware speaker verification [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4371-4375. |
| 7 | TODISCO M, DELGADO H, LEE K A, et al. Integrated presentation attack detection and automatic speaker verification: common features and Gaussian back-end fusion [C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 77-81. |
| 8 | DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3830-3834. |
| 9 | YU Y Q, LI W J. Densely connected time delay neural network for speaker verification [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 921-925. |
| 10 | ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs [EB/OL]. [2023-12-01]. . |
| 11 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| 12 | JUNG J W, HEO H S, TAK H, et al. AASIST: audio anti-spoofing using integrated spectro-temporal graph attention networks [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6367-6371. |
| 13 | 方昕,黄泽鑫,张聿晗,等.基于时域波形的半监督端到端虚假语音检测方法[J].计算机应用, 2023, 43(1): 227-231. |
| FANG X, HUANG Z X, ZHANG Y H, et al. Semi-supervised end-to-end fake speech detection method based on time-domain waveforms [J]. Journal of Computer Applications, 2023, 43(1): 227-231. | |
| 14 | ZHANG Y, WANG W, ZHANG P. The effect of silence and dual-band fusion in anti-spoofing system [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 4279-4283. |
| 15 | HUANG B, CUI S, HUANG J, et al. Discriminative frequency information learning for end-to-end speech anti-spoofing [J]. IEEE Signal Processing Letters, 2023, 30: 185-189. |
| 16 | WAN Z K, REN Q H, QIN Y C, et al. Statistical pyramid dense time delay neural network for speaker verification [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7532-7536. |
| 17 | CHEN F, DENG S, ZHENG T, et al. Graph-based spectro-temporal dependency modeling for anti-spoofing [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 18 | LIU X, LIU M, WANG L, et al. Leveraging positional-related local-global dependency for synthetic speech detection [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 19 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 20 | TAK H, KAMBLE M, PATINO J, et al. RawBoost: a raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6382-6386. |
| 21 | DAS R K, YANG J, LI H. Data augmentation with signal companding for detection of logical access attacks [C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6349-6353. |
| 22 | ZHANG Y, LI Z, WANG W, et al. SASV based on pre-trained ASV system and integrated scoring module [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4376-4380. |
| 23 | WANG X, QIN X, WANG Y, et al. The DKU-OPPO system for the 2022 spoofing-aware speaker verification challenge [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4396-4400. |
| 24 | KARAM L J, McCLELLAN J H. A multiple exchange Remez algorithm for complex FIR filter design in the Chebyshev sense [C]// Proceedings of the 1994 IEEE International Symposium on Circuits and Systems — Volume 2. Piscataway: IEEE, 1994: 517-520. |
| 25 | 江苏大学.一种多重注意力特征融合的说话人识别方法: 202110986397.6 [P]. 2021-12-07. |
| Jiangsu University. A speaker recognition method based on multiple attention feature fusion: 202110986397.6 [P]. 2021-12-07. | |
| 26 | NAGRANI A, CHUNG J S, ZISSERMAN A. VoxCeleb: a large-scale speaker identification dataset [C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 2616-2620. |
| 27 | CHUNG J S, NAGRANI A, ZISSERMAN A. VoxCeleb2: deep speaker recognition [C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 1086-1090. |
| 28 | WANG X, YAMAGISHI J, TODISCO M, et al. ASVspoof 2019: a large-scale public database of synthesized, converted and replayed speech [J]. Computer Speech and Language, 2020, 64: No.101114. |
| 29 | YAMAGISHI J, WANG X, TODISCO M, et al. ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection [C]// Proceedings of the 2021 Automatic Speaker Verification and Spoofing Countermeasures Challenge. [S.l.]: International Speech Communication Association, 2021: 47-54. |
| 30 | 徐童心,黄俊.基于CNN-Transformer的欺骗语音检测[J].无线电工程, 2024, 54(5): 1091-1098. |
| XU T X, HUANG J. Spoofed speech detection based on CNN-Transformer [J]. Radio Engineering, 2024, 54(5): 1091-1098. | |
| 31 | WANG C, YI J, TAO J, et al. TO-RawNet: improving RawNet with TCN and orthogonal regularization for fake audio detection [C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 3137-3141. |
| 32 | TENG Z, FU Q, WHITE J, et al. SA-SASV: an end-to-end spoof-aggregated spoofing-aware speaker verification system [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4391-4395. |
| 33 | WU H, MENG L, KANG J, et al. Spoofing-aware speaker verification by multi-level fusion [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4357-4361. |
| 34 | LIN J, CHEN T, HUANG J, et al. The CLIPS system for 2022 spoofing-aware speaker verification challenge [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4367-4370. |
| [1] | Lifang WANG, Jingshuang WU, Pengliang YIN, Lihua HU. Action recognition algorithm based on attention mechanism and energy function [J]. Journal of Computer Applications, 2025, 45(1): 234-239. |
| [2] | Ying HUANG, Changsheng LI, Hui PENG, Su LIU. Dual-branch network guided by local entropy for dynamic scene high dynamic range imaging [J]. Journal of Computer Applications, 2025, 45(1): 204-213. |
| [3] | Jie XU, Yong ZHONG, Yang WANG, Changfu ZHANG, Guanci YANG. Facial attribute estimation and expression recognition based on contextual channel attention mechanism [J]. Journal of Computer Applications, 2025, 45(1): 253-260. |
| [4] | Junying CHEN, Shijie GUO, Lingling CHEN. Lightweight human pose estimation based on decoupled attention and ghost convolution [J]. Journal of Computer Applications, 2025, 45(1): 223-233. |
| [5] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [6] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [7] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [8] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [9] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [10] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [11] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [12] | Wu XIONG, Congjun CAO, Xuefang SONG, Yunlong SHAO, Xusheng WANG. Handwriting identification method based on multi-scale mixed domain attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2225-2232. |
| [13] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [14] | Dianhui MAO, Xuebo LI, Junling LIU, Denghui ZHANG, Wenjing YAN. Chinese entity and relation extraction model based on parallel heterogeneous graph and sequential attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2018-2025. |
| [15] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||