


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (10): 3146-3153.DOI: 10.11772/j.issn.1001-9081.2024101453
• Artificial intelligence • Previous Articles
Jinwen LIU1,2,3, Lei WANG1,2,3( ), Bo MA1,2,3, Rui DONG1,2,3, Yating YANG1,2,3, Ahtamjan Ahmat1,2,3, Xinyue WANG4
), Bo MA1,2,3, Rui DONG1,2,3, Yating YANG1,2,3, Ahtamjan Ahmat1,2,3, Xinyue WANG4
Received:2024-10-14
Revised:2024-12-05
Accepted:2024-12-09
Online:2024-12-23
Published:2025-10-10
Contact:
Lei WANG
About author:LIU Jinwen, born in 1999, M. S. candidate. Her research interests include harmful information detection.Supported by:
刘晋文1,2,3, 王磊1,2,3(), 马博1,2,3, 董瑞1,2,3, 杨雅婷1,2,3, 艾合塔木江·艾合麦提1,2,3, 王欣乐4
通讯作者:
王磊
作者简介:刘晋文(1999—),女,山西吕梁人,硕士研究生,主要研究方向:有害信息检测基金资助:CLC Number:
Jinwen LIU, Lei WANG, Bo MA, Rui DONG, Yating YANG, Ahtamjan Ahmat, Xinyue WANG. Multimodal harmful content detection method based on weakly supervised modality semantic enhancement[J]. Journal of Computer Applications, 2025, 45(10): 3146-3153.
刘晋文, 王磊, 马博, 董瑞, 杨雅婷, 艾合塔木江·艾合麦提, 王欣乐. 基于弱监督模态语义增强的多模态有害信息检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3146-3153.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024101453
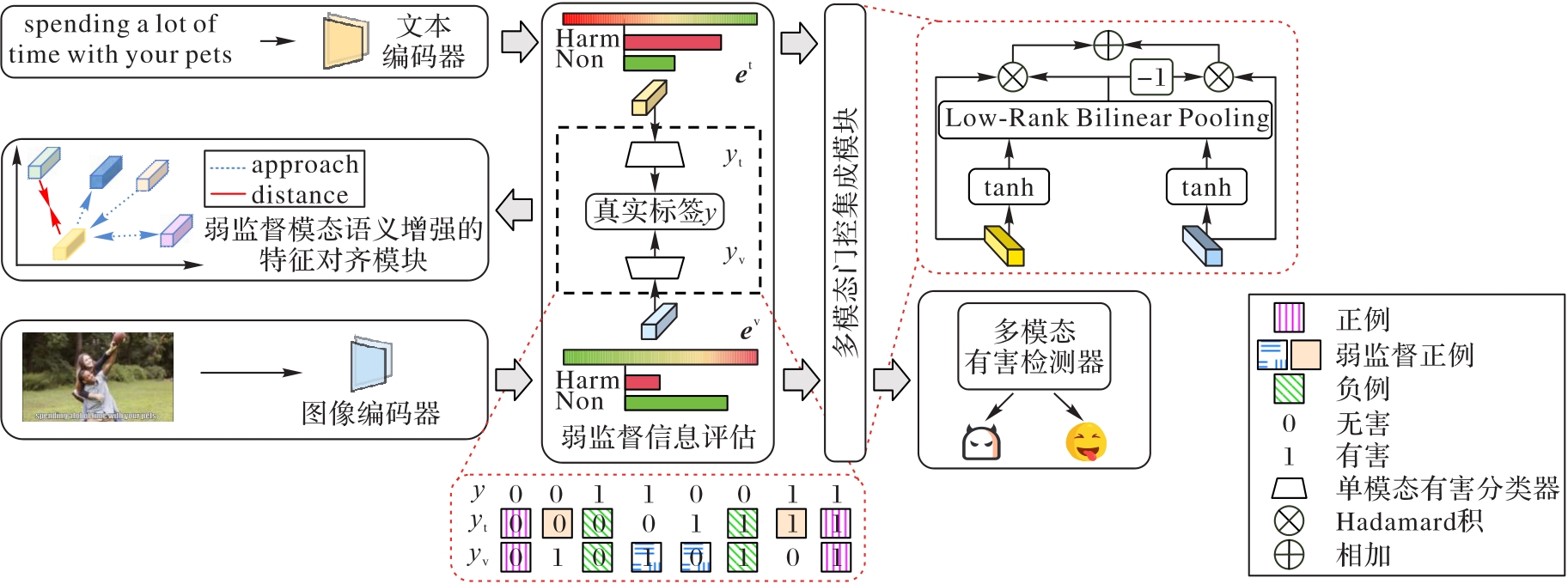
Fig. 1 Weakly supervised modality semantic enhancement model
| 数据集 | 有害性 | 样本数 | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 验证集 | ||
| Harm-P | Hate | 1 486 | 173 | 86 |
| Not-hate | 1 534 | 182 | 91 | |
| 合计 | 3 020 | 355 | 177 | |
| Harm-C | Hate | 1 064 | 124 | 61 |
| Not-hate | 1 949 | 230 | 116 | |
| 合计 | 3 013 | 354 | 177 | |
| MultiOFF | Offensive | 187 | 59 | 59 |
| Non-offensive | 258 | 90 | 90 | |
| 合计 | 445 | 149 | 149 | |
Tab. 1 Data distribution and partitioning
| 数据集 | 有害性 | 样本数 | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 验证集 | ||
| Harm-P | Hate | 1 486 | 173 | 86 |
| Not-hate | 1 534 | 182 | 91 | |
| 合计 | 3 020 | 355 | 177 | |
| Harm-C | Hate | 1 064 | 124 | 61 |
| Not-hate | 1 949 | 230 | 116 | |
| 合计 | 3 013 | 354 | 177 | |
| MultiOFF | Offensive | 187 | 59 | 59 |
| Non-offensive | 258 | 90 | 90 | |
| 合计 | 445 | 149 | 149 | |
| 模型 | MultiOFF | |||
|---|---|---|---|---|
| Acc↑ | Pre↑ | Rec↑ | F1↑ | |
| Stacked LSTM+VGG16 | — | 0.400 | 0.660 | 0.500 |
| BiLSTM+VGG16 | — | 0.400 | 0.440 | 0.410 |
| CNNText+VGG16 | — | 0.380 | 0.670 | 0.480 |
| DisMultiHate | — | 0.645 | 0.651 | 0.646 |
| MeBERT | — | 0.670 | 0.671 | 0.671 |
| MemeFier | 0.685 | — | — | 0.625 |
| weak-S | 0.711 | 0.706 | 0.711 | 0.703 |
Tab. 2 Comparison of detection effects of different models on MultiOFF dataset
| 模型 | MultiOFF | |||
|---|---|---|---|---|
| Acc↑ | Pre↑ | Rec↑ | F1↑ | |
| Stacked LSTM+VGG16 | — | 0.400 | 0.660 | 0.500 |
| BiLSTM+VGG16 | — | 0.400 | 0.440 | 0.410 |
| CNNText+VGG16 | — | 0.380 | 0.670 | 0.480 |
| DisMultiHate | — | 0.645 | 0.651 | 0.646 |
| MeBERT | — | 0.670 | 0.671 | 0.671 |
| MemeFier | 0.685 | — | — | 0.625 |
| weak-S | 0.711 | 0.706 | 0.711 | 0.703 |
| 模型 | Harm-P | Harm-C | ||||
|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | |
| Late Fusion | 0.783 | 0.785 | 0.167 | 0.732 | 0.703 | 0.293 |
| MMBT | 0.825 | 0.802 | 0.141 | 0.735 | 0.671 | 0.326 |
Visual BERT COCO | 0.868 | 0.861 | 0.132 | 0.814 | 0.801 | 0.186 |
| CLIP | 0.879 | 0.879 | 0.121 | 0.825 | 0.816 | 0.165 |
| MOMENTA | 0.898 | 0.883 | 0.131 | 0.838 | 0.828 | 0.174 |
| PromptHate | 0.882 | 0.871 | — | 0.845 | 0.815 | — |
| ISSUES | 0.881 | 0.864 | 0.164 | 0.848 | 0.778 | 0.174 |
| Pro-Cap | — | — | — | 0.851 | 0.839 | — |
| MR.HARM | 0.896 | 0.896 | — | 0.861 | 0.854 | — |
| weak-S | 0.918 | 0.918 | 0.082 | 0.867 | 0.853 | 0.149 |
Tab. 3 Comparison of detection effects of different models on Harm-P and Harm-C datasets
| 模型 | Harm-P | Harm-C | ||||
|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | |
| Late Fusion | 0.783 | 0.785 | 0.167 | 0.732 | 0.703 | 0.293 |
| MMBT | 0.825 | 0.802 | 0.141 | 0.735 | 0.671 | 0.326 |
Visual BERT COCO | 0.868 | 0.861 | 0.132 | 0.814 | 0.801 | 0.186 |
| CLIP | 0.879 | 0.879 | 0.121 | 0.825 | 0.816 | 0.165 |
| MOMENTA | 0.898 | 0.883 | 0.131 | 0.838 | 0.828 | 0.174 |
| PromptHate | 0.882 | 0.871 | — | 0.845 | 0.815 | — |
| ISSUES | 0.881 | 0.864 | 0.164 | 0.848 | 0.778 | 0.174 |
| Pro-Cap | — | — | — | 0.851 | 0.839 | — |
| MR.HARM | 0.896 | 0.896 | — | 0.861 | 0.854 | — |
| weak-S | 0.918 | 0.918 | 0.082 | 0.867 | 0.853 | 0.149 |
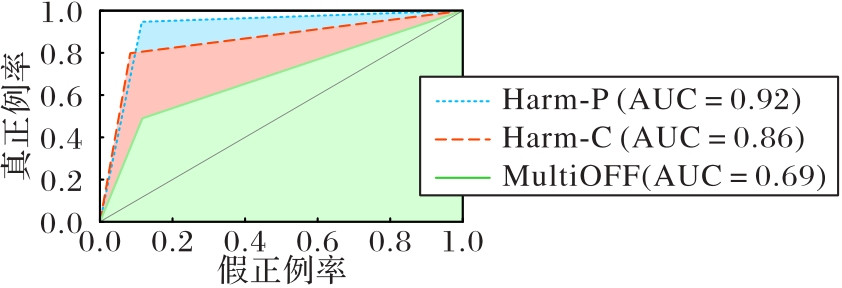
Fig. 2 ROC curves of experimental results
| 方法 | Harm-C | Harm-P | MultiOFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | Pre↑ | Rec↑ | |
| weak-S | 0.867 | 0.853 | 0.149 | 0.918 | 0.918 | 0.082 | 0.711 | 0.703 | 0.706 | 0.711 |
| w/o | 0.841 | 0.819 | 0.191 | 0.886 | 0.886 | 0.113 | 0.672 | 0.654 | 0.665 | 0.671 |
| w/o | 0.846 | 0.828 | 0.179 | 0.889 | 0.889 | 0.110 | 0.664 | 0.666 | 0.668 | 0.664 |
| w/o MGI | 0.841 | 0.822 | 0.184 | 0.897 | 0.896 | 0.102 | 0.664 | 0.613 | 0.682 | 0.664 |
Tab. 4 Ablation experimental results
| 方法 | Harm-C | Harm-P | MultiOFF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | MMAE↓ | Acc↑ | F1↑ | Pre↑ | Rec↑ | |
| weak-S | 0.867 | 0.853 | 0.149 | 0.918 | 0.918 | 0.082 | 0.711 | 0.703 | 0.706 | 0.711 |
| w/o | 0.841 | 0.819 | 0.191 | 0.886 | 0.886 | 0.113 | 0.672 | 0.654 | 0.665 | 0.671 |
| w/o | 0.846 | 0.828 | 0.179 | 0.889 | 0.889 | 0.110 | 0.664 | 0.666 | 0.668 | 0.664 |
| w/o MGI | 0.841 | 0.822 | 0.184 | 0.897 | 0.896 | 0.102 | 0.664 | 0.613 | 0.682 | 0.664 |
| 模型 | Acc↑ | F1↑ | 模型 | Acc↑ | F1↑ |
|---|---|---|---|---|---|
| CLIP+prompt | 0.642 | 0.632 | BriVL+concat | 0.667 | 0.665 |
| CLIP+concat | 0.644 | 0.584 | BriVL+gate | 0.637 | 0.644 |
| CLIP+gate | 0.642 | 0.580 | weak-S | 0.684 | 0.675 |
| BriVL+prompt | 0.628 | 0.587 |
Tab. 5 Comparison of multimodal exaggeration detection effects
| 模型 | Acc↑ | F1↑ | 模型 | Acc↑ | F1↑ |
|---|---|---|---|---|---|
| CLIP+prompt | 0.642 | 0.632 | BriVL+concat | 0.667 | 0.665 |
| CLIP+concat | 0.644 | 0.584 | BriVL+gate | 0.637 | 0.644 |
| CLIP+gate | 0.642 | 0.580 | weak-S | 0.684 | 0.675 |
| BriVL+prompt | 0.628 | 0.587 |
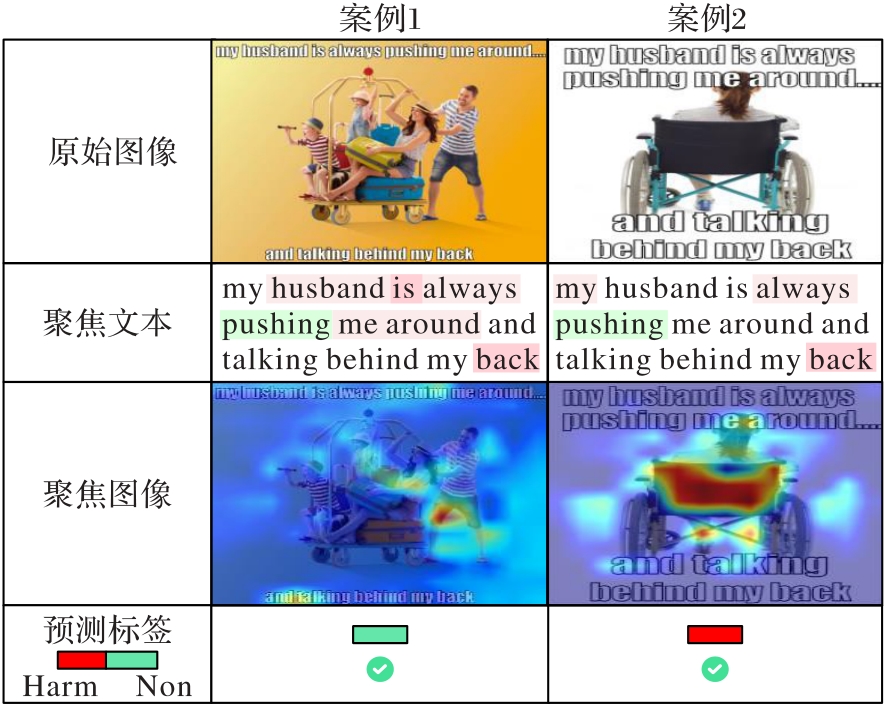
Fig. 3 Case analysis for multimodal harmful content detection
| [1] | PRAMANICK S, SHARMA S, DIMITROV D, et al. MOMENTA: a multimodal framework for detecting harmful memes and their targets[C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg: ACL, 2021: 4439-4455. |
| [2] | KIELA D, FIROOZ H, MOHAN A, et al. The hateful memes challenge: detecting hate speech in multimodal memes[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 2611-2624. |
| [3] | SHARMA S, ALAM F, AKHTAR M S, et al. Detecting and understanding harmful memes: a survey[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 5597-5606. |
| [4] | KOUTLIS C, SCHINAS M, PAPADOPOULOS S. MemeFier: dual-stage modality fusion for image meme classification[C]// Proceedings of the 2023 ACM International Conference on Multimedia Retrieval. New York: ACM, 2023: 586-591. |
| [5] | 孟杰,王莉,杨延杰,等. 基于多模态深度融合的虚假信息检测[J]. 计算机应用, 2022, 42(2):419-425. |
| MENG J, WANG L, YANG Y J, et al. Multi-modal deep fusion for false information detection[J]. Journal of Computer Applications, 2022, 42(2):419-425. | |
| [6] | LIN H, LUO Z, MA J, et al. Beneath the surface: unveiling harmful memes with multimodal reasoning distilled from large language models[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 9114-9128. |
| [7] | CAO R, LEE R K W, CHONG W H, et al. Prompting for multimodal hateful meme classification[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 321-332. |
| [8] | CAO R, HEE M S, KUEK A, et al. Pro-Cap: leveraging a frozen vision-language model for hateful meme detection[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 5244-5252. |
| [9] | WU F, GAO B, PAN X, et al. Fuser: an enhanced multimodal fusion framework with congruent reinforced perceptron for hateful memes detection[J]. Information Processing and Management, 2024, 61(4): No.103772. |
| [10] | LEE R K W, CAO R, FAN Z, et al. Disentangling hate in online memes[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 5138-5147. |
| [11] | 杜鹏飞. 多模态内容安全识别关键技术研究[D]. 北京:北京邮电大学, 2023. |
| DU P F. Research on key technologies of multimodal content security identification[D]. Beijing: Beijing University of Posts and Telecommunications, 2023. | |
| [12] | ZHONG Q, WANG Q, LIU J. Combining knowledge and multi-modal fusion for meme classification[C]// Proceedings of the 2022 International Conference on Multimedia Modeling, LNCS 13141. Cham: Springer, 2022: 599-611. |
| [13] | GOMEZ R, GIBERT J, GOMEZ L, et al. Exploring hate speech detection in multimodal publications[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 1459-1467. |
| [14] | SURYAWANSHI S, CHAKRAVARTHI B R, ARCAN M, et al. Multi modal meme dataset (MultiOFF) for identifying offensive content in image and text[C]// Proceedings of the 2nd Workshop on Trolling, Aggression and Cyberbullying. Stroudsburg: ACL, 2020: 32-41. |
| [15] | HOSSAIN E, SHARIF O, HOQUE M M, et al. Deciphering hate: identifying hateful memes and their targets[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 8347-8359. |
| [16] | KUMAR G K, NANDAKUMAR K. Hate-CLIPper: multimodal hateful meme classification based on cross-modal interaction of CLIP features[C]// Proceedings of the 2nd Workshop on NLP for Positive Impact. Stroudsburg: ACL, 2022: 171-183. |
| [17] | BURBI G, BALDRATI A, AGNOLUCCI L, et al. Mapping memes to words for multimodal hateful meme classification[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2023: 2824-2828. |
| [18] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [19] | MEI J, CHEN J, LIN W, et al. Improving hateful meme detection through retrieval-guided contrastive learning[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 5333-5347. |
| [20] | ZHANG Y, ZHANG H, ZHAN L M, et al. New intent discovery with pre-training and contrastive learning[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 256-269. |
| [21] | ZOU H, SHEN M, CHEN C, et al. UniS-MMC: multimodal classification via unimodality-supervised multimodal contrastive learning[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 659-672. |
| [22] | QU Y, HE X, PIERSON S, et al. On the evolution of (hateful) memes by means of multimodal contrastive learning[C]// Proceedings of the 2023 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2023: 293-310. |
| [23] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [24] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-12-04]. . |
| [25] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [26] | KIELA D, BHOOSHAN S, FIROOZ H, et al. Supervised multimodal bitransformers for classifying images and text[EB/OL]. [2024-12-04]. . |
| [27] | LU J, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13-23. |
| [28] | VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. [2024-12-04]. . |
| [29] | ZHANG H, WAN X. Image matters: a new dataset and empirical study for multimodal hyperbole detection[C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA and ICCL, 2024: 8652-8661. |
| [30] | HUO Y, ZHANG M, LIU G, et al. WenLan: bridging vision and language by large-scale multi-modal pre-training[EB/OL]. [2024-12-04]. . |
| [1] | Chao LIU, Yanhua YU. Knowledge-aware recommendation model combining denoising strategy and multi-view contrastive learning [J]. Journal of Computer Applications, 2025, 45(9): 2827-2837. |
| [2] | Jinyang HUANG, Fengqi CUI, Changxiu MA, Wendong FAN, Meng LI, Jingyu LI, Xiao SUN, Linsheng HUANG, Zhi LIU. Sleep apnea detection based on universal wristband [J]. Journal of Computer Applications, 2025, 45(9): 3045-3056. |
| [3] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [4] | Zhiyuan WANG, Tao PENG, Jie YANG. Integrating internal and external data for out-of-distribution detection training and testing [J]. Journal of Computer Applications, 2025, 45(8): 2497-2506. |
| [5] | Yihan WANG, Chong LU, Zhongyuan CHEN. Multimodal sentiment analysis model with cross-modal text information enhancement [J]. Journal of Computer Applications, 2025, 45(7): 2237-2244. |
| [6] | Jin XIE, Surong CHU, Yan QIANG, Juanjuan ZHAO, Hua ZHANG, Yong GAO. Dual-branch distribution consistency contrastive learning model for hard negative sample identification in chest X-rays [J]. Journal of Computer Applications, 2025, 45(7): 2369-2377. |
| [7] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| [8] | Jiaqi CHEN, Yulin HE, Yingchao CHENG, Zhexue HUANG. Semi-EM algorithm for solving Gamma mixture model of multimodal probability distribution [J]. Journal of Computer Applications, 2025, 45(7): 2153-2161. |
| [9] | Wenjing YAN, Ruidong WANG, Min ZUO, Qingchuan ZHANG. Recipe recommendation model based on hierarchical learning of flavor embedding heterogeneous graph [J]. Journal of Computer Applications, 2025, 45(6): 1869-1878. |
| [10] | Zonghang WU, Dong ZHANG, Guanyu LI. Multimodal fusion recommendation algorithm based on joint self-supervised learning [J]. Journal of Computer Applications, 2025, 45(6): 1858-1868. |
| [11] | Mingfeng YU, Yongbin QIN, Ruizhang HUANG, Yanping CHEN, Chuan LIN. Multi-label text classification method based on contrastive learning enhanced dual-attention mechanism [J]. Journal of Computer Applications, 2025, 45(6): 1732-1740. |
| [12] | Chaoying JIANG, Qian LI, Ning LIU, Lei LIU, Lizhen CUI. Readmission prediction model based on graph contrastive learning [J]. Journal of Computer Applications, 2025, 45(6): 1784-1792. |
| [13] | Qing ZHANG, Fan YANG, Yuhan FANG. Chinese spelling correction algorithm based on multi-modal information fusion [J]. Journal of Computer Applications, 2025, 45(5): 1528-1534. |
| [14] | Wenbin HU, Tianxiang CAI, Tianle HAN, Zhaoman ZHONG, Changxia MA. Multimodal sarcasm detection model integrating contrastive learning with sentiment analysis [J]. Journal of Computer Applications, 2025, 45(5): 1432-1438. |
| [15] | Yufei LONG, Yuchen MOU, Ye LIU. Multi-source data representation learning model based on tensorized graph convolutional network and contrastive learning [J]. Journal of Computer Applications, 2025, 45(5): 1372-1378. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||