


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1482-1489.DOI: 10.11772/j.issn.1001-9081.2025050567
• Data science and technology • Previous Articles
Xipei TAO1, Hengrong JU1,2( ), Xiaoxue FAN1, Xiaoyang ZOU1, Weiping DING1
), Xiaoxue FAN1, Xiaoyang ZOU1, Weiping DING1
Received:2025-05-22
Revised:2025-06-19
Accepted:2025-06-26
Online:2025-07-08
Published:2026-05-10
Contact:
Hengrong JU
About author:TAO Xipei, born in 2001, M. S. candidate. His research interests include granular computing, rough set.Supported by:
陶西沛1, 鞠恒荣1,2(), 樊晓雪1, 邹晓阳1, 丁卫平1
通讯作者:
鞠恒荣
作者简介:陶西沛(2001—),男,江苏连云港人,硕士研究生,主要研究方向:粒计算、粗糙集基金资助:CLC Number:
Xipei TAO, Hengrong JU, Xiaoxue FAN, Xiaoyang ZOU, Weiping DING. Distributed multi-label feature selection method with feature-label neighborhood collaborative correlation[J]. Journal of Computer Applications, 2026, 46(5): 1482-1489.
陶西沛, 鞠恒荣, 樊晓雪, 邹晓阳, 丁卫平. 特征-标记邻域协同相关的分布式多标记特征选择方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1482-1489.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050567

Fig. 1 Overall framework of DML-FNCC
| U | a1 | a2 | a3 | a4 | a5 | l1 | l2 | l3 | l4 | l5 |
|---|---|---|---|---|---|---|---|---|---|---|
| x1 | 0.57 | 0.61 | 0.21 | 0.32 | 0.42 | 1 | 1 | 0 | 1 | 0 |
| x2 | 0.48 | 0.42 | 0.33 | 0.01 | 0.71 | 1 | 1 | 0 | 0 | 0 |
| x3 | 0.35 | 0.42 | 0.27 | 0.59 | 0.63 | 0 | 0 | 1 | 0 | 1 |
| x4 | 0.29 | 0.57 | 0.60 | 0.98 | 0.42 | 0 | 0 | 1 | 1 | 1 |
| x5 | 0.18 | 0.70 | 0.47 | 0.51 | 0.57 | 1 | 1 | 0 | 1 | 0 |
| x6 | 0.35 | 0.85 | 0.43 | 0.59 | 0.90 | 1 | 1 | 1 | 0 | 1 |
| x7 | 0.26 | 0.20 | 0.31 | 0.93 | 0.56 | 1 | 0 | 1 | 0 | 1 |
Tab. 1 Multi-label examples
| U | a1 | a2 | a3 | a4 | a5 | l1 | l2 | l3 | l4 | l5 |
|---|---|---|---|---|---|---|---|---|---|---|
| x1 | 0.57 | 0.61 | 0.21 | 0.32 | 0.42 | 1 | 1 | 0 | 1 | 0 |
| x2 | 0.48 | 0.42 | 0.33 | 0.01 | 0.71 | 1 | 1 | 0 | 0 | 0 |
| x3 | 0.35 | 0.42 | 0.27 | 0.59 | 0.63 | 0 | 0 | 1 | 0 | 1 |
| x4 | 0.29 | 0.57 | 0.60 | 0.98 | 0.42 | 0 | 0 | 1 | 1 | 1 |
| x5 | 0.18 | 0.70 | 0.47 | 0.51 | 0.57 | 1 | 1 | 0 | 1 | 0 |
| x6 | 0.35 | 0.85 | 0.43 | 0.59 | 0.90 | 1 | 1 | 1 | 0 | 1 |
| x7 | 0.26 | 0.20 | 0.31 | 0.93 | 0.56 | 1 | 0 | 1 | 0 | 1 |
| 数据集 | 样本数 | 特征数 | 标记数 | 领域 | ||
|---|---|---|---|---|---|---|
| 总计 | 训练集 | 测试集 | ||||
| Emotions | 593 | 391 | 202 | 72 | 6 | Music |
| Yeast | 2 417 | 1 500 | 917 | 103 | 14 | Biology |
| Medical | 978 | 333 | 645 | 1 449 | 45 | Health |
| Science | 5 000 | 2 000 | 3 000 | 743 | 40 | Research |
| Recreation | 5 000 | 2 000 | 3 000 | 606 | 22 | Leisure |
| Cal500 | 502 | 350 | 152 | 68 | 174 | Music |
| Health | 5 000 | 2 000 | 3 000 | 612 | 32 | Health |
| Business | 5 000 | 2 000 | 3 000 | 438 | 30 | Economy |
| Scene | 2 407 | 1 211 | 196 | 294 | 6 | Image |
| Computer | 5 000 | 2 000 | 3 000 | 681 | 33 | Technology |
| Flags | 194 | 129 | 65 | 19 | 7 | Culture |
| Educations | 5 000 | 2 000 | 3 000 | 550 | 33 | Education |
Tab. 2 Characteristics of experimental datasets
| 数据集 | 样本数 | 特征数 | 标记数 | 领域 | ||
|---|---|---|---|---|---|---|
| 总计 | 训练集 | 测试集 | ||||
| Emotions | 593 | 391 | 202 | 72 | 6 | Music |
| Yeast | 2 417 | 1 500 | 917 | 103 | 14 | Biology |
| Medical | 978 | 333 | 645 | 1 449 | 45 | Health |
| Science | 5 000 | 2 000 | 3 000 | 743 | 40 | Research |
| Recreation | 5 000 | 2 000 | 3 000 | 606 | 22 | Leisure |
| Cal500 | 502 | 350 | 152 | 68 | 174 | Music |
| Health | 5 000 | 2 000 | 3 000 | 612 | 32 | Health |
| Business | 5 000 | 2 000 | 3 000 | 438 | 30 | Economy |
| Scene | 2 407 | 1 211 | 196 | 294 | 6 | Image |
| Computer | 5 000 | 2 000 | 3 000 | 681 | 33 | Technology |
| Flags | 194 | 129 | 65 | 19 | 7 | Culture |
| Educations | 5 000 | 2 000 | 3 000 | 550 | 33 | Education |
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.25 | 3.00 | 4.92 | 3.25 | 2.58 |
| Emotions | 0.776 7 | 0.694 3 | 0.639 9 | 0.735 7 | 0.766 6 |
| Yeast | 0.733 5 | 0.696 8 | 0.685 0 | 0.671 6 | 0.730 6 |
| Medical | 0.757 8 | 0.708 0 | 0.468 3 | 0.744 2 | 0.742 2 |
| Science | 0.417 1 | 0.411 9 | 0.399 6 | 0.471 1 | 0.322 0 |
| Recreation | 0.425 3 | 0.380 5 | 0.369 9 | 0.413 1 | 0.346 8 |
| Cal500 | 0.486 8 | 0.478 6 | 0.442 2 | 0.485 5 | 0.475 4 |
| Health | 0.660 5 | 0.636 2 | 0.613 0 | 0.625 7 | 0.607 7 |
| Business | 0.867 4 | 0.855 7 | 0.860 2 | 0.861 1 | 0.768 8 |
| Scene | 0.781 8 | 0.507 0 | 0.704 3 | 0.472 7 | 0.601 8 |
| Computer | 0.607 9 | 0.595 8 | 0.558 9 | 0.603 2 | 0.551 7 |
| Flags | 0.794 4 | 0.780 9 | 0.769 5 | 0.788 5 | 0.794 2 |
| Educations | 0.488 8 | 0.473 5 | 0.480 0 | 0.484 1 | 0.475 9 |
Tab. 3 Average precisions of five algorithms on twelve datasets
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.25 | 3.00 | 4.92 | 3.25 | 2.58 |
| Emotions | 0.776 7 | 0.694 3 | 0.639 9 | 0.735 7 | 0.766 6 |
| Yeast | 0.733 5 | 0.696 8 | 0.685 0 | 0.671 6 | 0.730 6 |
| Medical | 0.757 8 | 0.708 0 | 0.468 3 | 0.744 2 | 0.742 2 |
| Science | 0.417 1 | 0.411 9 | 0.399 6 | 0.471 1 | 0.322 0 |
| Recreation | 0.425 3 | 0.380 5 | 0.369 9 | 0.413 1 | 0.346 8 |
| Cal500 | 0.486 8 | 0.478 6 | 0.442 2 | 0.485 5 | 0.475 4 |
| Health | 0.660 5 | 0.636 2 | 0.613 0 | 0.625 7 | 0.607 7 |
| Business | 0.867 4 | 0.855 7 | 0.860 2 | 0.861 1 | 0.768 8 |
| Scene | 0.781 8 | 0.507 0 | 0.704 3 | 0.472 7 | 0.601 8 |
| Computer | 0.607 9 | 0.595 8 | 0.558 9 | 0.603 2 | 0.551 7 |
| Flags | 0.794 4 | 0.780 9 | 0.769 5 | 0.788 5 | 0.794 2 |
| Educations | 0.488 8 | 0.473 5 | 0.480 0 | 0.484 1 | 0.475 9 |
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.33 | 4.08 | 3.50 | 3.25 | 2.83 |
| Emotions | 0.242 5 | 0.311 8 | 0.271 8 | 0.301 3 | 0.266 7 |
| Yeast | 0.212 7 | 0.295 3 | 0.224 5 | 0.231 2 | 0.218 3 |
| Medical | 0.016 2 | 0.019 7 | 0.018 8 | 0.017 9 | 0.027 6 |
| Science | 0.035 3 | 0.035 6 | 0.067 8 | 0.036 9 | 0.063 3 |
| Recreation | 0.064 6 | 0.180 5 | 0.067 8 | 0.064 9 | 0.100 1 |
| Cal500 | 0.139 6 | 0.144 1 | 0.143 7 | 0.144 2 | 0.139 8 |
| Health | 0.046 8 | 0.049 3 | 0.047 5 | 0.051 1 | 0.027 6 |
| Business | 0.028 3 | 0.029 0 | 0.031 0 | 0.029 1 | 0.058 9 |
| Scene | 0.122 3 | 0.186 4 | 0.131 5 | 0.167 9 | 0.165 9 |
| Computer | 0.041 7 | 0.044 7 | 0.046 1 | 0.043 2 | 0.069 3 |
| Flags | 0.690 1 | 0.525 2 | 0.301 5 | 0.331 9 | 0.294 1 |
| Educations | 0.044 3 | 0.071 8 | 0.062 4 | 0.044 7 | 0.047 0 |
Tab. 4 Hamming losses of five algorithms on twelve datasets
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.33 | 4.08 | 3.50 | 3.25 | 2.83 |
| Emotions | 0.242 5 | 0.311 8 | 0.271 8 | 0.301 3 | 0.266 7 |
| Yeast | 0.212 7 | 0.295 3 | 0.224 5 | 0.231 2 | 0.218 3 |
| Medical | 0.016 2 | 0.019 7 | 0.018 8 | 0.017 9 | 0.027 6 |
| Science | 0.035 3 | 0.035 6 | 0.067 8 | 0.036 9 | 0.063 3 |
| Recreation | 0.064 6 | 0.180 5 | 0.067 8 | 0.064 9 | 0.100 1 |
| Cal500 | 0.139 6 | 0.144 1 | 0.143 7 | 0.144 2 | 0.139 8 |
| Health | 0.046 8 | 0.049 3 | 0.047 5 | 0.051 1 | 0.027 6 |
| Business | 0.028 3 | 0.029 0 | 0.031 0 | 0.029 1 | 0.058 9 |
| Scene | 0.122 3 | 0.186 4 | 0.131 5 | 0.167 9 | 0.165 9 |
| Computer | 0.041 7 | 0.044 7 | 0.046 1 | 0.043 2 | 0.069 3 |
| Flags | 0.690 1 | 0.525 2 | 0.301 5 | 0.331 9 | 0.294 1 |
| Educations | 0.044 3 | 0.071 8 | 0.062 4 | 0.044 7 | 0.047 0 |
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.25 | 3.58 | 3.08 | 2.50 | 4.58 |
| Emotions | 0.306 9 | 0.396 0 | 0.351 1 | 0.513 2 | 0.317 8 |
| Yeast | 0.261 7 | 0.271 5 | 0.263 9 | 0.268 1 | 0.276 9 |
| Medical | 0.286 8 | 0.350 3 | 0.638 7 | 0.381 2 | 0.753 5 |
| Science | 0.340 3 | 0.643 3 | 0.470 7 | 0.648 9 | 0.865 1 |
| Recreation | 0.737 3 | 0.760 9 | 0.809 3 | 0.771 3 | 0.842 0 |
| Cal500 | 0.115 0 | 0.144 1 | 0.127 1 | 0.120 1 | 0.125 3 |
| Health | 0.442 1 | 0.467 3 | 0.494 0 | 0.484 5 | 0.506 0 |
| Business | 0.132 2 | 0.141 6 | 0.136 6 | 0.135 6 | 0.134 4 |
| Scene | 0.340 3 | 0.708 9 | 0.470 7 | 0.760 2 | 0.606 7 |
| Computer | 0.470 6 | 0.482 3 | 0.490 3 | 0.472 5 | 0.653 3 |
| Flags | 0.215 3 | 0.246 1 | 0.261 5 | 0.220 1 | 0.222 2 |
| Educations | 0.670 6 | 0.643 3 | 0.678 3 | 0.679 3 | 0.806 5 |
Tab. 5 One errors of five algorithms on twelve datasets
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.25 | 3.58 | 3.08 | 2.50 | 4.58 |
| Emotions | 0.306 9 | 0.396 0 | 0.351 1 | 0.513 2 | 0.317 8 |
| Yeast | 0.261 7 | 0.271 5 | 0.263 9 | 0.268 1 | 0.276 9 |
| Medical | 0.286 8 | 0.350 3 | 0.638 7 | 0.381 2 | 0.753 5 |
| Science | 0.340 3 | 0.643 3 | 0.470 7 | 0.648 9 | 0.865 1 |
| Recreation | 0.737 3 | 0.760 9 | 0.809 3 | 0.771 3 | 0.842 0 |
| Cal500 | 0.115 0 | 0.144 1 | 0.127 1 | 0.120 1 | 0.125 3 |
| Health | 0.442 1 | 0.467 3 | 0.494 0 | 0.484 5 | 0.506 0 |
| Business | 0.132 2 | 0.141 6 | 0.136 6 | 0.135 6 | 0.134 4 |
| Scene | 0.340 3 | 0.708 9 | 0.470 7 | 0.760 2 | 0.606 7 |
| Computer | 0.470 6 | 0.482 3 | 0.490 3 | 0.472 5 | 0.653 3 |
| Flags | 0.215 3 | 0.246 1 | 0.261 5 | 0.220 1 | 0.222 2 |
| Educations | 0.670 6 | 0.643 3 | 0.678 3 | 0.679 3 | 0.806 5 |
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.25 | 3.75 | 3.08 | 2.58 | 4.33 |
| Emotions | 0.184 8 | 0.265 5 | 0.359 2 | 0.341 1 | 0.193 5 |
| Yeast | 0.190 5 | 0.222 8 | 0.254 0 | 0.202 1 | 0.191 1 |
| Medical | 0.060 9 | 0.084 8 | 0.140 8 | 0.061 3 | 0.143 6 |
| Science | 0.150 9 | 0.134 5 | 0.143 2 | 0.134 1 | 0.167 6 |
| Recreation | 0.205 8 | 0.405 4 | 0.233 6 | 0.225 6 | 0.232 8 |
| Cal500 | 0.186 6 | 0.198 1 | 0.225 6 | 0.183 1 | 0.189 5 |
| Health | 0.068 9 | 0.080 2 | 0.084 4 | 0.078 1 | 0.147 2 |
| Business | 0.044 7 | 0.057 1 | 0.049 5 | 0.049 6 | 0.285 5 |
| Scene | 0.148 7 | 0.386 7 | 0.189 9 | 0.436 9 | 0.274 0 |
| Computer | 0.099 2 | 0.108 9 | 0.101 1 | 0.103 0 | 0.113 0 |
| Flags | 0.241 1 | 0.264 3 | 0.262 8 | 0.275 6 | 0.216 3 |
| Educations | 0.106 6 | 0.113 5 | 0.109 5 | 0.107 4 | 0.126 5 |
Tab. 6 Ranking losses of five algorithms on twelve datasets
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.25 | 3.75 | 3.08 | 2.58 | 4.33 |
| Emotions | 0.184 8 | 0.265 5 | 0.359 2 | 0.341 1 | 0.193 5 |
| Yeast | 0.190 5 | 0.222 8 | 0.254 0 | 0.202 1 | 0.191 1 |
| Medical | 0.060 9 | 0.084 8 | 0.140 8 | 0.061 3 | 0.143 6 |
| Science | 0.150 9 | 0.134 5 | 0.143 2 | 0.134 1 | 0.167 6 |
| Recreation | 0.205 8 | 0.405 4 | 0.233 6 | 0.225 6 | 0.232 8 |
| Cal500 | 0.186 6 | 0.198 1 | 0.225 6 | 0.183 1 | 0.189 5 |
| Health | 0.068 9 | 0.080 2 | 0.084 4 | 0.078 1 | 0.147 2 |
| Business | 0.044 7 | 0.057 1 | 0.049 5 | 0.049 6 | 0.285 5 |
| Scene | 0.148 7 | 0.386 7 | 0.189 9 | 0.436 9 | 0.274 0 |
| Computer | 0.099 2 | 0.108 9 | 0.101 1 | 0.103 0 | 0.113 0 |
| Flags | 0.241 1 | 0.264 3 | 0.262 8 | 0.275 6 | 0.216 3 |
| Educations | 0.106 6 | 0.113 5 | 0.109 5 | 0.107 4 | 0.126 5 |
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.75 | 3.33 | 3.25 | 2.83 | 4.83 |
| Emotions | 1.847 1 | 2.430 6 | 2.841 5 | 2.412 5 | 1.949 7 |
| Yeast | 7.641 2 | 7.306 4 | 8.247 5 | 7.819 0 | 7.718 5 |
| Medical | 5.396 1 | 5.451 1 | 7.082 1 | 6.156 3 | 7.617 2 |
| Science | 7.629 5 | 7.663 0 | 7.646 3 | 6.717 0 | 8.139 2 |
| Recreation | 5.645 0 | 4.942 0 | 5.254 6 | 5.714 2 | 5.923 5 |
| Cal500 | 129.100 0 | 142.300 0 | 129.400 0 | 129.700 0 | 131.610 0 |
| Health | 3.781 0 | 3.975 0 | 4.108 6 | 3.931 3 | 4.612 2 |
| Business | 2.591 2 | 2.967 3 | 2.608 3 | 2.661 3 | 2.831 8 |
| Scene | 2.030 9 | 2.029 1 | 1.739 9 | 2.289 0 | 1.459 1 |
| Computer | 4.565 9 | 5.100 6 | 4.595 5 | 4.651 0 | 5.056 5 |
| Flags | 4.630 7 | 4.211 2 | 3.812 1 | 4.031 1 | 3.812 9 |
| Educations | 3.890 1 | 3.921 0 | 4.046 1 | 4.481 2 | 5.081 2 |
Tab. 7 Coverages of five algorithms on twelve datasets
| 数据集 | DML-FNCC | PMLFS | WFDP | MLFRS | MLCA |
|---|---|---|---|---|---|
| 平均排名 | 1.75 | 3.33 | 3.25 | 2.83 | 4.83 |
| Emotions | 1.847 1 | 2.430 6 | 2.841 5 | 2.412 5 | 1.949 7 |
| Yeast | 7.641 2 | 7.306 4 | 8.247 5 | 7.819 0 | 7.718 5 |
| Medical | 5.396 1 | 5.451 1 | 7.082 1 | 6.156 3 | 7.617 2 |
| Science | 7.629 5 | 7.663 0 | 7.646 3 | 6.717 0 | 8.139 2 |
| Recreation | 5.645 0 | 4.942 0 | 5.254 6 | 5.714 2 | 5.923 5 |
| Cal500 | 129.100 0 | 142.300 0 | 129.400 0 | 129.700 0 | 131.610 0 |
| Health | 3.781 0 | 3.975 0 | 4.108 6 | 3.931 3 | 4.612 2 |
| Business | 2.591 2 | 2.967 3 | 2.608 3 | 2.661 3 | 2.831 8 |
| Scene | 2.030 9 | 2.029 1 | 1.739 9 | 2.289 0 | 1.459 1 |
| Computer | 4.565 9 | 5.100 6 | 4.595 5 | 4.651 0 | 5.056 5 |
| Flags | 4.630 7 | 4.211 2 | 3.812 1 | 4.031 1 | 3.812 9 |
| Educations | 3.890 1 | 3.921 0 | 4.046 1 | 4.481 2 | 5.081 2 |
| 评价指标 | 临界值 | |
|---|---|---|
| 平均精度 | 14.303 5 | 2.583 6 |
| 汉明损失 | 6.292 6 | |
| 单错误率 | 10.878 5 | |
| 排序损失 | 6.483 4 | |
| 覆盖度 | 2.469 4 |
Tab. 8 Test statistics (k=5, N=12) and critical value for evaluation metrics
| 评价指标 | 临界值 | |
|---|---|---|
| 平均精度 | 14.303 5 | 2.583 6 |
| 汉明损失 | 6.292 6 | |
| 单错误率 | 10.878 5 | |
| 排序损失 | 6.483 4 | |
| 覆盖度 | 2.469 4 |
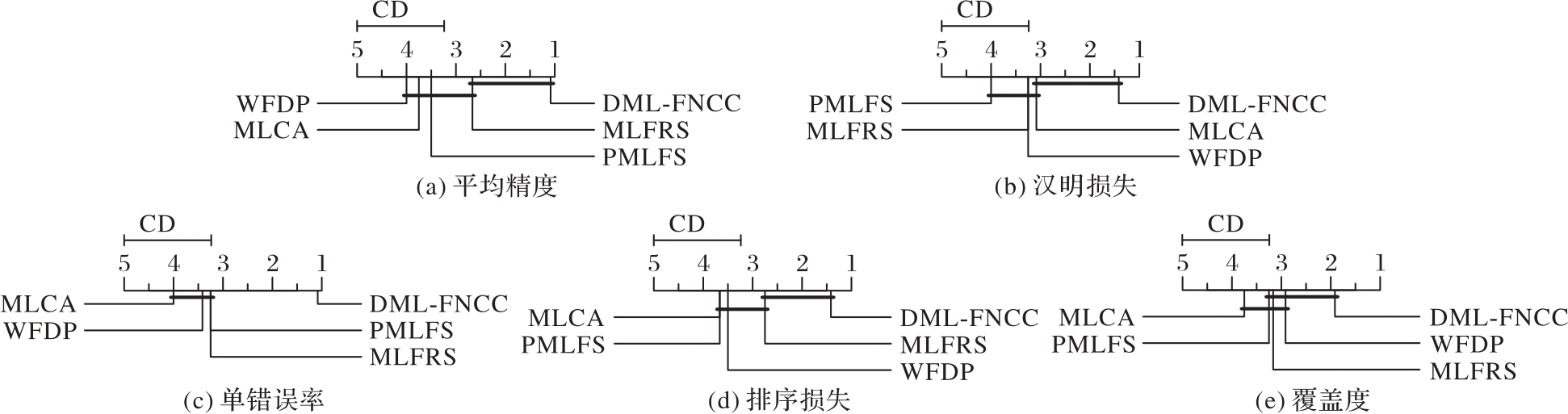
Fig. 2 Bonferroni-Dunn test results for five methods under MLKNN
| [1] | ZHANG M L, ZHOU Z H. A review on multi-label learning algorithms[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(8): 1819-1837. |
| [2] | WANG Q, WU W, QI Y, et al. Deep Bayesian active learning for learning to rank: a case study in answer selection[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(11): 5251-5262. |
| [3] | SHARMA P, SHAKYA A, JOSHI B, et al. Hierarchical multi label classification of news articles using RNN, CNN and HAN[C]// ICT with Intelligent Applications: Proceedings of ICTIS 2021, Volume 1, SIST 248 . Singapore: Springer, 2022: 499-506. |
| [4] | PANDA R, MALHEIRO R, PAIVA R P. Audio features for music emotion recognition: a survey[J]. IEEE Transactions on Affective Computing, 2023, 14(1): 68-88. |
| [5] | HUANG J, LI G, HUANG Q, et al. Learning label specific features for multi-label classification[C]// Proceedings of the 2015 IEEE International Conference on Data Mining. Piscataway: IEEE, 2015: 181-190. |
| [6] | ZHAO Z, LIU H. Spectral feature selection for supervised and unsupervised learning[C]// Proceedings of the 24th International Conference on Machine Learning. New York: ACM, 2007: 1151-1157. |
| [7] | DONOHO D L. High-dimensional data analysis: the curses and blessings of dimensionality[EB/OL]. [2025-03-09].. |
| [8] | GUYON I, WESTON J, BARNHILL S, et al. Gene selection for cancer classification using support vector machines[J]. Machine Learning, 2002, 46(1/2/3): 389-422. |
| [9] | SPOLAÔR N, CHERMAN E A, MONARD M C, et al. A comparison of multi-label feature selection methods using the problem transformation approach[J]. Electronic Notes in Theoretical Computer Science, 2013, 292: 135-151. |
| [10] | PENG H, LONG F, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238. |
| [11] | ZHANG Y, ZHOU Z H. Multilabel dimensionality reduction via dependence maximization[J]. ACM Transactions on Knowledge Discovery from Data, 2010, 4(3): No.14. |
| [12] | ZHANG M L, PEÑA J M, ROBLES V. Feature selection for multi-label Naive Bayes classification[J]. Information Sciences, 2009, 179(19): 3218-3229. |
| [13] | PAWLAK Z. Rough sets[J]. International Journal of Computer and Information Sciences, 1982, 11: 341-356. |
| [14] | HU Q, YU D, XIE Z. Neighborhood classifiers[J]. Expert Systems with Applications, 2008, 34(2): 866-876. |
| [15] | 孙林,潘俊方,张霄雨,等.一种基于邻域粗糙集的多标记专属特征选择方法[J].计算机科学,2018,45(1):173-178. |
| SUN L, PAN J F, ZHANG X Y, et al. Multi-label-specific feature selection method based on neighborhood rough set[J]. Computer Science, 2018, 45(1): 173-178. | |
| [16] | 段洁,胡清华,张灵均,等.基于邻域粗糙集的多标记分类特征选择算法[J].计算机研究与发展,2015,52(1):56-65. |
| DUAN J, HU Q H, ZHANG L J, et al. Feature selection for multi-label classification based on neighborhood rough sets[J]. Journal of Computer Research and Development, 2015, 52(1): 56-65. | |
| [17] | LI J, MEI C, XU W, et al. Concept learning via granular computing: a cognitive viewpoint[J]. Information Sciences, 2015, 298: 447-467. |
| [18] | 樊晓雪,尹涛,陆杨,等.融合稀疏约束的双向k近邻粗糙集模型[J].小型微型计算机系统,2024,45(10):2370-2377. |
| FAN X X, YIN T, LU Y, et al. Mutual k-nearest neighborhood-based rough set model fusing with sparsity constraint[J]. Journal of Chinese Computer Systems, 2024, 45(10): 2370-2377. | |
| [19] | 鞠恒荣,单婷婷,刘克宇,等.粒-组协同的双向模糊粒舱并行属性约简加速方法[J].系统工程理论与实践,2025,45(3): 1029-1046. |
| JU H R, SHAN T T, LIU K Y, et al. Bi-directional fuzzy granular cabin parallel attribute reduction acceleration method with granular-group collaboration[J]. Systems Engineering — Theory and Practice, 2025, 45(3): 1029-1046. | |
| [20] | ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C]// Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation. Berkeley: USENIX Association, 2012: 1-14. |
| [21] | ARMBRUST M, XIN R S, LIAN C, et al. Spark SQL: relational data processing in Spark[C]// Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2015: 1383-1394. |
| [22] | MENG X, BRADLEY J, YAVUZ B, et al. MLlib: machine learning in Apache Spark[J]. Journal of Machine Learning Research, 2016, 17: 1-7. |
| [23] | ZHANG J, ZHOU K, LI Y, et al. Optimizing lineage-driven fault tolerance in Apache Spark[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 31(5): 1074-1088. |
| [24] | SCHAPIRE R E, SINGER Y. BoosTexter: a boosting-based system for text categorization[J]. Machine Learning, 2000, 39(2/3): 135-168. |
| [25] | TROHIDIS K, TSOUMAKAS G, ALLIRIS G, et al. Multilabel classification of music into emotions[EB/OL]. [2025-01-21].. |
| [26] | WANG J, LI P, YU K. Partial multi-label feature selection[C]// Proceedings of the 2022 International Joint Conference on Neural Networks. Piscataway: IEEE, 2022: 1-9. |
| [27] | DAI J, LI M, ZHANG C. Multi-label feature selection with missing labels by weak-label fusion fuzzy discernibility pair[J]. Information Fusion, 2025, 117: No.102921. |
| [28] | LIN Y, LI Y, WANG C, et al. Attribute reduction for multi-label learning with fuzzy rough set[J]. Knowledge-Based Systems, 2018, 152: 51-61. |
| [29] | MASUYAMA N, NOJIMA Y, LOO C K, et al. Multi-label classification via adaptive resonance theory-based clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(7): 8696-8712. |
| [30] | THEODORSSON-NORHEIM E. Friedman and Quade tests: BASIC computer program to perform nonparametric two-way analysis of variance and multiple comparisons on ranks of several related samples[J]. Computers in Biology and Medicine, 1987, 17(2): 85-99. |
| [31] | DUNN O J. Multiple comparisons among means[J]. Journal of the American Statistical Association, 1961, 56(293): 52-64. |
| [1] | Hao YU, Jing FAN, Yihang SUN, Hua DONG, Enkang XI. Survey of statistical heterogeneity in federated learning [J]. Journal of Computer Applications, 2025, 45(9): 2737-2746. |
| [2] | Jun WU, Aijia OUYANG, Ya WANG. Non-redundant and statistically significant discriminative high utility pattern mining algorithm [J]. Journal of Computer Applications, 2025, 45(8): 2572-2581. |
| [3] | Lanhao LI, Haojun YAN, Haoyi ZHOU, Qingyun SUN, Jianxin LI. Multi-scale information fusion time series long-term forecasting model based on neural network [J]. Journal of Computer Applications, 2025, 45(6): 1776-1783. |
| [4] | Meng LUO, Chao GAO, Zhen WANG. Improvement method of heuristic vehicle routing algorithm based on constrained spectral clustering [J]. Journal of Computer Applications, 2025, 45(5): 1387-1394. |
| [5] | Yan LI, Guanhua YE, Yawen LI, Meiyu LIANG. Enterprise ESG indicator prediction model based on richness coordination technology [J]. Journal of Computer Applications, 2025, 45(2): 670-676. |
| [6] | Dixin WANG, Jiahao WANG, Min LI, Hao CHEN, Guangyao HU, Yu GONG. Abnormal attack detection for underwater acoustic communication network [J]. Journal of Computer Applications, 2025, 45(2): 526-533. |
| [7] | Lixia XIE, Jiamin WANG, Hongyu YANG, Ze HU, Xiang CHENG. Low-latency DDoS attack detection based on hybrid feature selection [J]. Journal of Computer Applications, 2025, 45(10): 3231-3240. |
| [8] | Hong CHEN, Bing QI, Haibo JIN, Cong WU, Li’ang ZHANG. Class-imbalanced traffic abnormal detection based on 1D-CNN and BiGRU [J]. Journal of Computer Applications, 2024, 44(8): 2493-2499. |
| [9] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [10] | Yao DONG, Yixue FU, Yongfeng DONG, Jin SHI, Chen CHEN. Survey of incomplete multi-view clustering [J]. Journal of Computer Applications, 2024, 44(6): 1673-1682. |
| [11] | Mingzhu LEI, Hao WANG, Rong JIA, Lin BAI, Xiaoying PAN. Oversampling algorithm based on synthesizing minority class samples using relationship between features [J]. Journal of Computer Applications, 2024, 44(5): 1428-1436. |
| [12] | Lin GAO, Yu ZHOU, Tak Wu KWONG. Evolutionary bi-level adaptive local feature selection [J]. Journal of Computer Applications, 2024, 44(5): 1408-1414. |
| [13] | Lin SUN, Menghan LIU. K-means clustering based on adaptive cuckoo optimization feature selection [J]. Journal of Computer Applications, 2024, 44(3): 831-841. |
| [14] | Dapeng XU, Xinmin HOU. Feature selection method for graph neural network based on network architecture design [J]. Journal of Computer Applications, 2024, 44(3): 663-670. |
| [15] | Shengjie MENG, Wanjun YU, Ying CHEN. Feature selection algorithm for high-dimensional data with maximum correlation and maximum difference [J]. Journal of Computer Applications, 2024, 44(3): 767-771. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||