


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (7): 2043-2051.DOI: 10.11772/j.issn.1001-9081.2021050799
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Rongyuan CHEN1, Jianmin YAO1,2, Qun YAN1,2( ), Zhixian LIN1
), Zhixian LIN1
Received:2021-05-17
Revised:2021-10-14
Accepted:2021-10-18
Online:2021-10-14
Published:2022-07-10
Contact:
Qun YAN
About author:CHEN Rongyuan, born in 1994, M. S. candidate. His research interests include deep learning, video semantic understanding.Supported by:
陈荣源1, 姚剑敏1,2, 严群1,2(), 林志贤1
通讯作者:
严群
作者简介:陈荣源(1994—),男,福建三明人,硕士研究生,主要研究方向:深度学习、视频语义理解基金资助:CLC Number:
Rongyuan CHEN, Jianmin YAO, Qun YAN, Zhixian LIN. Video playback speed recognition based on deep neural network[J]. Journal of Computer Applications, 2022, 42(7): 2043-2051.
陈荣源, 姚剑敏, 严群, 林志贤. 基于深度神经网络的视频播放速度识别[J]. 《计算机应用》唯一官方网站, 2022, 42(7): 2043-2051.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021050799
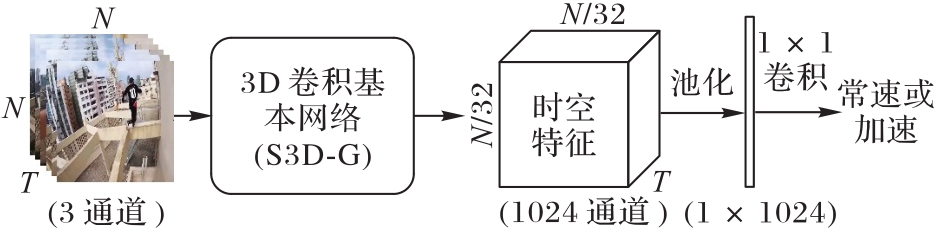
Fig. 1 SpeedNet basic structure
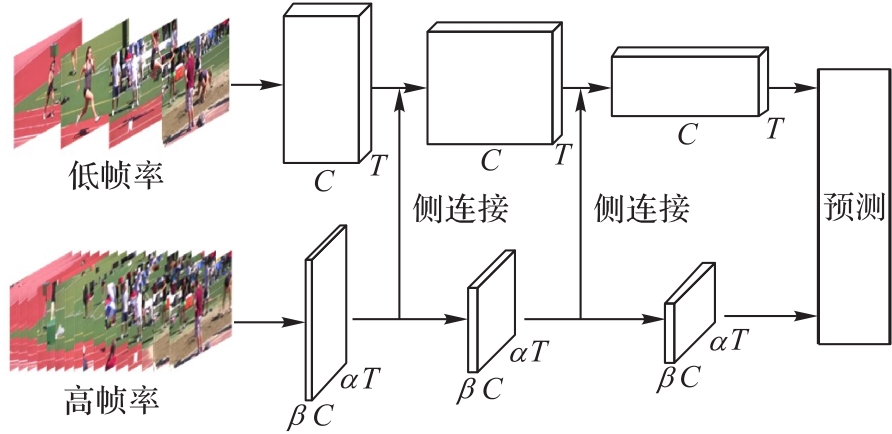
Fig. 2 SlowFast network basic structure
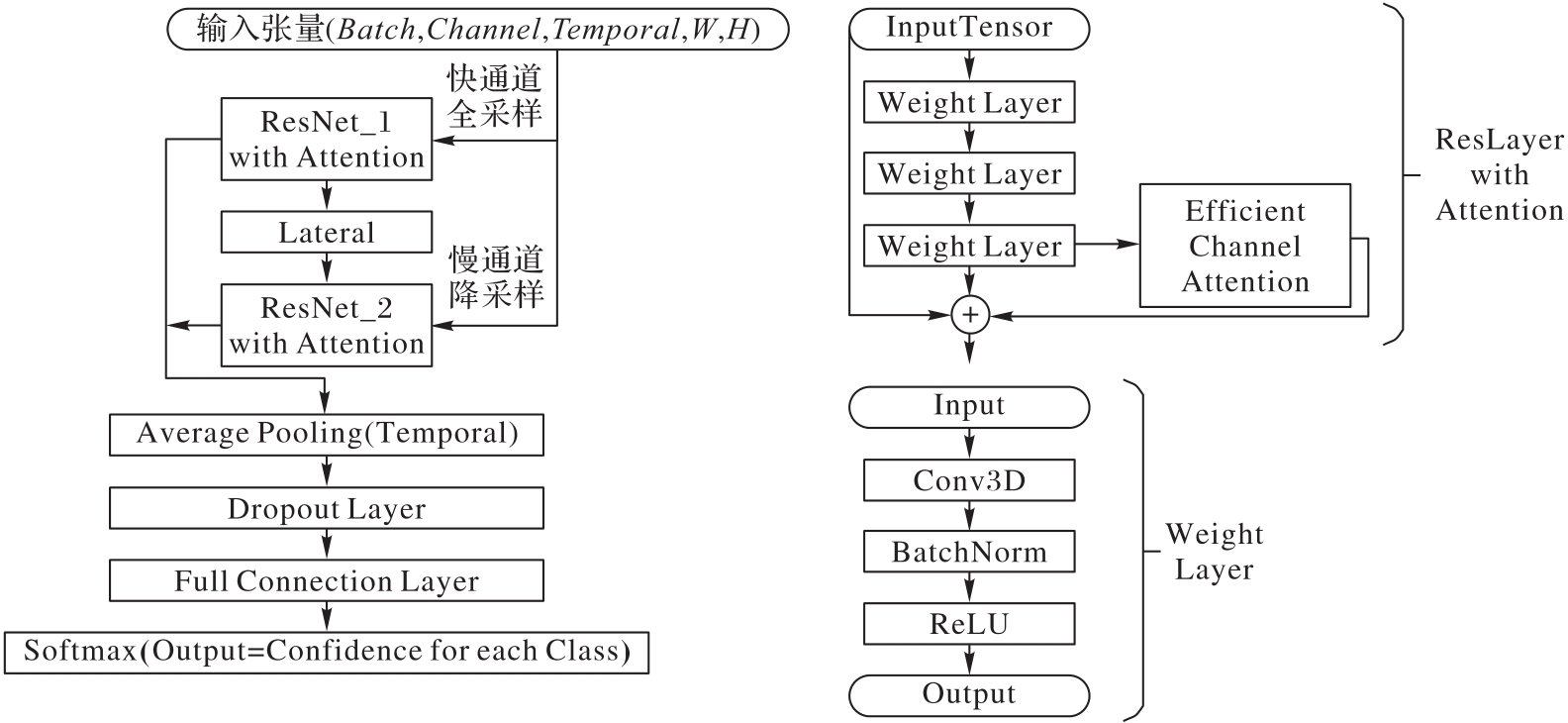
Fig. 3 Framework of video playback speed recognition network
| stage | Slow pathway | Fast pathway | Output sizes T×S2 |
|---|---|---|---|
| raw clip | — | — | 32×1682 |
| conv1 | 1×72,8 stride 2,22 | 5×72,8 stride 1,22 | Slow:16×842 Fast:32×842 |
| pool1 | 1×32,max stride 1,22 | 1×32,max stride 1,22 | Slow:16×422 Fast:32×422 |
| res2 | Slow:16×422 Fast:32×422 | ||
| res3 | Slow:16×212 Fast:32×212 | ||
| res4 | Slow:16×112 Fast:32×112 | ||
| res5 | Slow:16×62 Fast:32×62 |
Tab.1 Instance parameters of video playback speed recognition network
| stage | Slow pathway | Fast pathway | Output sizes T×S2 |
|---|---|---|---|
| raw clip | — | — | 32×1682 |
| conv1 | 1×72,8 stride 2,22 | 5×72,8 stride 1,22 | Slow:16×842 Fast:32×842 |
| pool1 | 1×32,max stride 1,22 | 1×32,max stride 1,22 | Slow:16×422 Fast:32×422 |
| res2 | Slow:16×422 Fast:32×422 | ||
| res3 | Slow:16×212 Fast:32×212 | ||
| res4 | Slow:16×112 Fast:32×112 | ||
| res5 | Slow:16×62 Fast:32×62 |
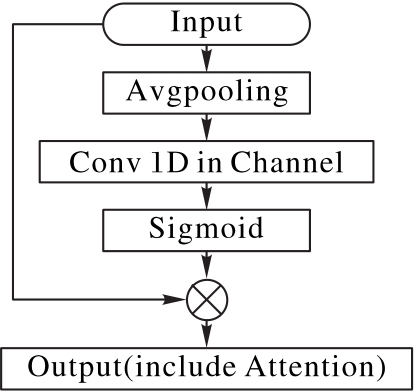
Fig. 4 Efficient channel attention module
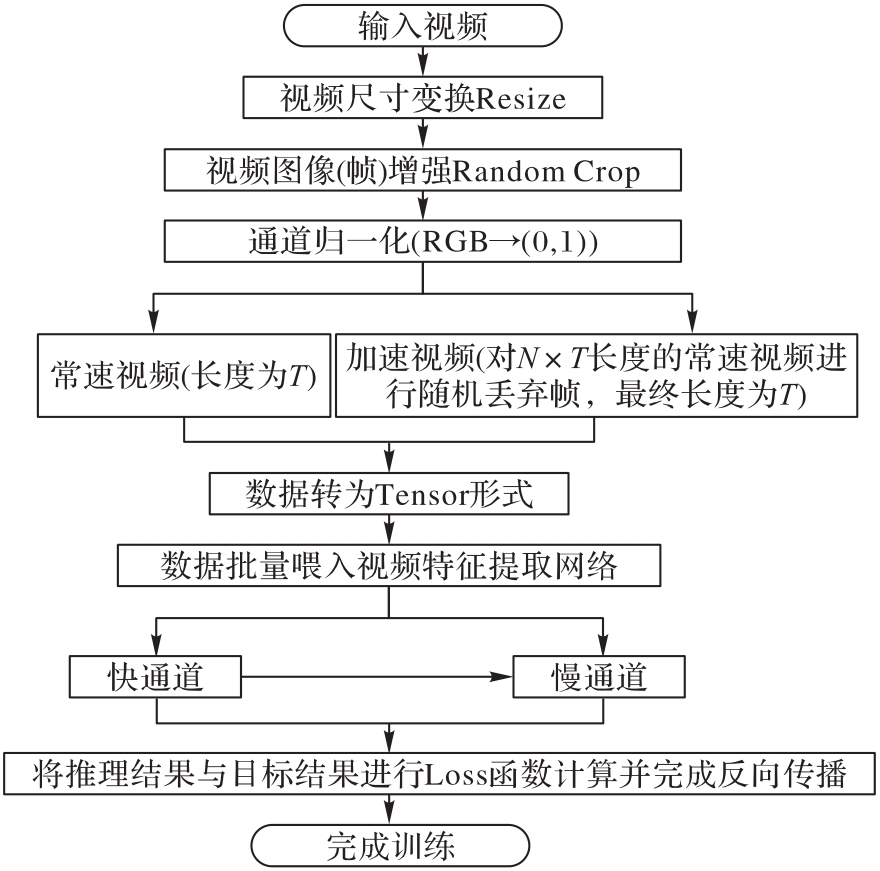
Fig. 5 Training flow of network

Fig. 6 Samples of Kinetics-400 dataset
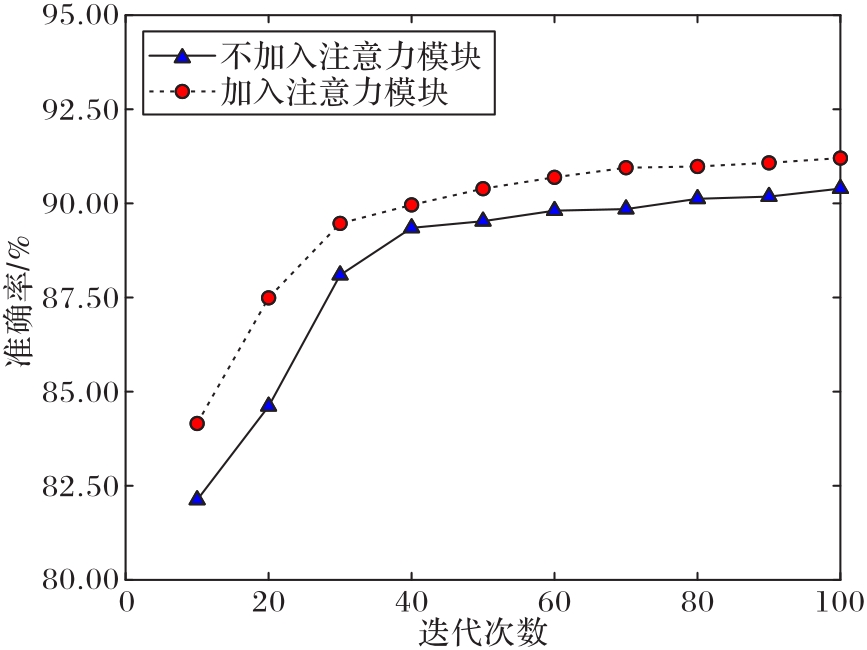
Fig. 7 Comparison of training accuracy of two groups

Fig. 8 Comparison of class activation maps of two groups
| 模型 | 参数量/M | 浮点运算数/GFLOPs | 模型大小/MB | 训练(验证)样本数 | 准确率/% |
|---|---|---|---|---|---|
| S3D-G (official) | 11.56 | 71.38 | 31.91 | 1 200(验证集) | 75.6 |
| SlowFast (official) | 34.52 | 39.84 | 128.39 | 1 200(验证集) | 72.5 |
| 本文模型 | 1.33 | 5.36 | 5.47 | 120 000(训练集) | 91.2 |
| 本文模型 | 1.33 | 5.36 | 5.47 | 1 200(验证集) | 75.3 |
Tab.2 Performance comparison of different models
| 模型 | 参数量/M | 浮点运算数/GFLOPs | 模型大小/MB | 训练(验证)样本数 | 准确率/% |
|---|---|---|---|---|---|
| S3D-G (official) | 11.56 | 71.38 | 31.91 | 1 200(验证集) | 75.6 |
| SlowFast (official) | 34.52 | 39.84 | 128.39 | 1 200(验证集) | 72.5 |
| 本文模型 | 1.33 | 5.36 | 5.47 | 120 000(训练集) | 91.2 |
| 本文模型 | 1.33 | 5.36 | 5.47 | 1 200(验证集) | 75.3 |
| 1 | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 4489-4497. 10.1109/iccv.2015.510 |
| 2 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 3 | KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics human action video dataset[EB/OL]. (2017-05-19) [2021-05-18].. |
| 4 | WANG L, LIU X, LIN S, et al. Generic slow-motion replay detection in sports video[C]// Proceedings of the 2004 International Conference on Image Processing. Piscataway: IEEE, 2004: 1585-1588. |
| 5 | CHEN C M, CHEN L H. A novel method for slow motion replay detection in broadcast basketball video[J]. Multimedia Tools and Applications, 2015, 74(21): 9573-9593. 10.1007/s11042-014-2137-5 |
| 6 | JAVED A, BAJWA K B, MALIK H, et al. An efficient framework for automatic highlights generation from sports videos[J]. IEEE Signal Processing Letters, 2016, 23(7): 954-958. 10.1109/lsp.2016.2573042 |
| 7 | KIANI V, POURREZA H R. An effective slow-motion detection approach for compressed soccer videos[J]. International Scholarly Research Notices, 2012, 2012: No.959508. 10.5402/2012/959508 |
| 8 | BENAIM S, EPHRAT A, LANG O, et al. SpeedNet: learning the speediness in videos[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9919-9928. 10.1109/cvpr42600.2020.00994 |
| 9 | XIE S N, SUN C, HUANG J, et al. Rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11219. Cham: Springer, 2018: 318-335. |
| 10 | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 568-576. |
| 11 | FEICHTENHOFER C, PINZ F, WILDES R P. Spatiotemporal residual networks for video action recognition[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 3476-3484. 10.1109/cvpr.2017.787 |
| 12 | FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1933-1941. 10.1109/cvpr.2016.213 |
| 13 | WANG L M, XIONG Y J, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 20-36. |
| 14 | 石仕伟. 基于深度学习的视频行为识别研究[D]. 杭州:浙江大学, 2018: 21-67. |
| SHI S W. Research on deep learning-based video action recognition[D]. Hangzhou: Zhejiang University, 2018: 21-67. | |
| 15 | 张聪聪,何宁. 基于关键帧的双流卷积网络的人体动作识别方法[J]. 南京信息工程大学学报(自然科学版), 2019, 11(6):716-721. |
| ZHANG C C, HE N. Human motion recognition based on key frame two-stream convolutional network[J]. Journal of Nanjing University of Information Science and Technology (Natural Science Edition), 2019, 11(6):716-721. | |
| 16 | FEICHTENHOFER C, FAN H Q, MALIK J, et al. SlowFast networks for video recognition[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6201-6210. 10.1109/iccv.2019.00630 |
| 17 | GALASSI A, LIPPI M, TORRONI P. Attention in natural language processing[J]. IEEE Transactions on Neural Networks and Learning System, 2021, 32(10): 4291-4308. 10.1109/tnnls.2020.3019893 |
| 18 | LI H F, QIU K J, CHEN L, et al. SCAttNet: semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(5): 905-909. 10.1109/lgrs.2020.2988294 |
| 19 | LIU Z, MOCK J, HUANG Y, et al. Predicting auditory spatial attention from EEG using single- and multi-task convolutional neural networks[C]// Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics. Piscataway: IEEE, 2019: 1298-1303. 10.1109/smc.2019.8913910 |
| 20 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 21 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 22 | WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. 10.1109/cvpr42600.2020.01155 |
| 23 | 韩兴,张红英,张媛媛. 基于高效通道注意力网络的人脸表情识别[J]. 传感器与微系统, 2021, 40(1):118-121. |
| HAN X, ZHANG H Y, ZHANG Y Y. Facial expression recognition based on high efficient channel attention network[J]. Transducer and Microsystem Technologies, 2021, 40(1):118-121. | |
| 24 | 屈震,李堃婷,冯志玺. 基于有效通道注意力的遥感图像场景分类[J]. 计算机应用,2022,42(5):1431-1439. |
| QU Z, LI K T, FENG Z X. Remote sensing image scene classification based on effective channel attention[J]. Journal of Computer Applications, 2022,42(5):1431-1439. | |
| 25 | JING L L, TIAN Y L. Self-supervised visual feature learning with deep neural networks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(11): 4037-4058. 10.1109/tpami.2020.2992393 |
| 26 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Volume 1: Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2015: 4171-4186. |
| 27 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C/OL]// Proceedings of the 34th Conference on Neural Information Processing Systems. [2021-05-18].. 10.18653/v1/2021.emnlp-main.734 |
| 28 | CHEN H T, WANG Y H, GUO T Y, et al. Pre-trained image processing transformer[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12294-12305. 10.1109/cvpr46437.2021.01212 |
| 29 | MISRA I, ZITNICK C L, HEBERT M. Shuffle and learn: unsupervised learning using temporal order verification[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 527-544. |
| 30 | DWIBEDI D, AYTAR Y, TOMPSON J, et al. Temporal cycle-consistency learning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1801-1810. 10.1109/cvpr.2019.00190 |
| [1] | Tong CHEN, Fengyu YANG, Yu XIONG, Hong YAN, Fuxing QIU. Construction method of voiceprint library based on multi-scale frequency-channel attention fusion [J]. Journal of Computer Applications, 2024, 44(8): 2407-2413. |
| [2] | Rui SHI, Yong LI, Yanhan ZHU. Adversarial sample attack algorithm of modulation signal based on equalization of feature gradient [J]. Journal of Computer Applications, 2024, 44(8): 2521-2527. |
| [3] | Yuan TANG, Yanping CHEN, Ying HU, Ruizhang HUANG, Yongbin QIN. Relation extraction model based on multi-scale hybrid attention convolutional neural networks [J]. Journal of Computer Applications, 2024, 44(7): 2011-2017. |
| [4] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [5] | Mei WANG, Xuesong SU, Jia LIU, Ruonan YIN, Shan HUANG. Time series classification method based on multi-scale cross-attention fusion in time-frequency domain [J]. Journal of Computer Applications, 2024, 44(6): 1842-1847. |
| [6] | Bin XIAO, Mo YANG, Min WANG, Guangyuan QIN, Huan LI. Domain generalization method of phase-frequency fusion from independent perspective [J]. Journal of Computer Applications, 2024, 44(4): 1002-1009. |
| [7] | Boyue WANG, Yingxiang LI, Jiandan ZHONG. Segmentation network for day and night ground-based cloud images based on improved Res-UNet [J]. Journal of Computer Applications, 2024, 44(4): 1310-1316. |
| [8] | Zijie HUANG, Yang OU, Degang JIANG, Cailing GUO, Bailin LI. Lightweight deep learning algorithm for weld seam surface quality detection of traction seat [J]. Journal of Computer Applications, 2024, 44(3): 983-988. |
| [9] | Mengmei YAN, Dongping YANG. Review of mean field theory for deep neural network [J]. Journal of Computer Applications, 2024, 44(2): 331-343. |
| [10] | Wenze CHAI, Jing FAN, Shukui SUN, Yiming LIANG, Jingfeng LIU. Overview of deep metric learning [J]. Journal of Computer Applications, 2024, 44(10): 2995-3010. |
| [11] | Xujian ZHAO, Hanglin LI. Deep neural network compression algorithm based on hybrid mechanism [J]. Journal of Computer Applications, 2023, 43(9): 2686-2691. |
| [12] | Mengmeng CHEN, Zhiwei QIAO. Sparse reconstruction of CT images based on Uformer with fused channel attention [J]. Journal of Computer Applications, 2023, 43(9): 2948-2954. |
| [13] | Yunfei SHEN, Fei SHEN, Fang LI, Jun ZHANG. Deep neural network model acceleration method based on tensor virtual machine [J]. Journal of Computer Applications, 2023, 43(9): 2836-2844. |
| [14] | Xiaolin LI, Songjia YANG. Hybrid beamforming for multi-user mmWave relay networks using deep learning [J]. Journal of Computer Applications, 2023, 43(8): 2511-2516. |
| [15] | Kansong CHEN, Yuan ZHENG, Lijun XU, Zhouyu WANG, Zhe ZHANG, Fujuan YAO. ShuffaceNet: face recognition neural network based on ThetaMEX global pooling [J]. Journal of Computer Applications, 2023, 43(8): 2572-2580. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||